
Chapter 2. Streaming Data Using Apache Flume
Pushing data to HDFS and similar storage systems using an intermediate system is a very common use case. There are several systems, like Apache Flume, Apache Kafka, Facebook’s Scribe, etc., that support this use case. Such systems allow HDFS and HBase clusters to handle sporadic bursts of data without necessarily having the capacity to handle that rate of writes continuously. These systems act as a buffer between the data producers and the final destination. By virtue of being buffers, they are able to balance out the impedance mismatch between the producers and consumers, thus providing a steady state of flow. Scaling these systems is often far easier than scaling HDFS or HBase clusters. Such systems also allow the applications to push data without worrying about having to buffer the data and retry in case of HDFS downtime, etc.
Most such systems have some fundamental similarities. Usually, these systems have components that are responsible for accepting the data from the producer, through an RPC call or HTTP (which may be exposed via a client API). They also have components that act as buffers where the data is stored until it is removed by the components that move the data to the next hop or destination. In this chapter, we will discuss the basic architecture of a Flume agent and how to configure Flume agents to move data from various applications to HDFS or HBase.
Apache Hadoop is becoming a standard data processing framework in large enterprises. Applications often produce massive amounts of data that get written to HDFS, the distributed file system that forms the base of Hadoop. Apache Flume was conceived as a system to write data to Apache Hadoop and Apache HBase in a reliable and scalable fashion. As a result, Flume’s HDFS and HBase Sinks provide a very rich set of features that makes it possible to write data in any format that is supported by these systems and in a MapReduce/Hive/Impala/Pig–friendly way. In this book, we will discuss why we need a system like Flume, its design and implementation, and the various features of Flume that make it highly scalable, flexible, and reliable.
The Need for Flume
Why do we really need a system like Flume? Why not simply write data directly to HDFS from every application server that produces data? In this section, we will discuss why we need such a system, and what it adds to the architecture.
Messaging systems that isolate systems from each other have existed for a long time—Flume does this in the Hadoop context. Flume is specifically designed to push data from a massive number of sources to the various storage systems in the Hadoop ecosystem, like HDFS and HBase.
In general, when there is enough data to be processed on a Hadoop cluster, there is usually a large number of servers producing the data. This number could be in the hundreds or even thousands of servers. Such a huge number of servers trying to write data to an HDFS or HBase cluster can cause major problems, for multiple reasons.
HDFS requires that exactly one client writes to a file—as a result, there could be thousands of files being written to at the same time. Each time a file is created or a new block is allocated, there is a complex set of operations that takes place on the name node. Such a huge number of operations happening simultaneously on a single server can cause the server to come under severe stress. Also, when thousands of machines are writing a large amount of data to a small number of machines, the network connecting these machines may get overwhelmed and start experiencing severe latency.
In many cases, application servers residing in multiple data centers aggregate data in a single data center that hosts the Hadoop cluster, which means the applications have to write data over a wide area network (WAN). In all these cases, applications might experience severe latency when attempting to write to HDFS or HBase. If the number of servers hosting the applications or the number of applications writing data increases, the latency and failure rate are likely to increase. As a result, considering HDFS cluster and network latencies becomes an additional concern while designing the software that is writing to HDFS.
Most applications see production traffic in predictable patterns, with a few hours of peak traffic per day and much less traffic during the rest of the day. To ensure an application that is writing directly to HDFS or HBase does not lose data or need to buffer a lot of data, the HDFS or HBase cluster needs to be configured to be able to handle peak traffic with little or no latency. All these cases make it clear that it is important to isolate the production applications from HDFS or HBase and ensure that production applications push data to these systems in a controlled and organized fashion.
Flume is designed to be a flexible distributed system that can scale out very easily and is highly customizable. A correctly configured Flume agent and a pipeline of Flume agents created by connecting agents with each other is guaranteed to not lose data, provided durable channels are used.
The simplest unit of Flume deployment is a Flume agent. It is possible to connect one Flume agent to one or more other agents. It is also possible for an agent to receive data from one or more agents. By connecting multiple Flume agents to each other, a flow is established. This chain of Flume agents can be used to move data from one location to another—specifically, from applications producing data to HDFS, HBase, etc.
By having a number of Flume agents receive data from application servers, which then write the data to HDFS or HBase (either directly or via other Flume agents), it is possible to scale the number of servers and the amount of data that can be written to HDFS by simply adding more Flume agents.
Each Flume agent has three components: the source, the channel, and the sink. The source is responsible for getting events into the Flume agent, while the sink is responsible for removing the events from the agent and forwarding them to the next agent in the topology, or to HDFS, HBase, Solr, etc. The channel is a buffer that stores data that the source has received, until a sink has successfully written the data out to the next hop or the eventual destination.
In effect, the data flow in a Flume agent works in the following way: the source produces/receives the data and writes it to one or more channels, and one or more sinks read these events from the channels and push them out to the next agent or to a storage or indexing system.
Flume agents can be configured to send data from one agent to another to form a pipeline before the data is written out to the destination. The durability of the data once the data has reached a Flume agent depends completely upon the durability guarantees of the channel used by the agent. In general, when a Flume agent is configured to use any of the built-in sources or sinks together with one of the durable channels, the agent is guaranteed to not lose data. By virtue of individual agents not losing data, it is guaranteed that a Flume pipeline will not lose data either.
Flume, though, can cause duplicate data to eventually be written out, if there are unexpected errors/timeouts and retries in the Flume pipeline. If disks that hold the durable channel fail irrecoverably, Flume might lose data because of the disk failures. Flume does allow users to replicate events across redundant flows to ensure that disk and agent failures are handled, though this might cause duplicates. Therefore, users might have to do some post-processing to ensure that duplicates are taken care of.
Is Flume a Good Fit?
Flume represents data as events. Events are very simple data structures, with a body and a set of headers. The body of the event is a byte array that usually is the payload that Flume is transporting. The headers are represented as a map with string keys and string values. Headers are not meant to transfer data, but for routing purposes and to keep track of priority, severity of events being sent, etc. The headers can be used to add event IDs or UUIDs to events as well.
Each event must essentially be an independent record, rather than a part of a record. This also imposes the requirement that each event be able to fit in the memory of the Flume agent JVM. If a File Channel is being used, then there should be enough disk space to accommodate this. If data cannot be represented as multiple individual records, Flume might not be a good fit for the use case.
Flume is primarily meant to push data from a large number of production servers to HDFS, HBase, etc. In cases where Flume is not a good fit, there is often an easier method, like Web HDFS or the HBase HTTP API, that can be used to write data. If there are only a handful of production servers producing data and the data does not need to be written out in real time, then it might also make sense to just move the data to HDFS via Web HDFS or NFS, especially if the amount of data being written out is relatively small—a few files of a few GB every few hours will not hurt HDFS. In this case, planning, configuring, and deploying Flume may not be worth it. Flume is really meant to push events in real time where the stream of data is continuous and its volume reasonably large.
As noted earlier, the simplest unit of deployment of Flume is called a Flume agent. An agent is a Java application that receives or generates data and buffers it until it is eventually written to the next agent or to a storage or indexing system. We will discuss the three main components of Flume agents (sources, channels, and sinks) in the next section.
Inside a Flume Agent
As discussed earlier, each Flume agent consists of three major components: sources, channels, and sinks. In this section, we will describe these and other components and how they work together.
Sources are active components that receive data from some other application that is producing the data. There are sources that produce data themselves, though such sources are mostly used for testing purposes. Sources can listen to one or more network ports to receive data or can read data from the local file system. Each source must be connected to at least one channel. A source can write to several channels, replicating the events to all or some of the channels, based on some criteria.
Channels are, in general, passive components (though they may run their own threads for cleanup or garbage collection) that buffer data that has been received by the agent, but not yet written out to another agent or to a storage system. Channels behave like queues, with sources writing to them and sinks reading from them. Multiple sources can write to the same channel safely, and multiple sinks can read from the same channel. Each sink, though, can read from only exactly one channel. If multiple sinks read from the same channel, it is guaranteed that exactly one sink will read (and commit—more about this in Chapter 4) a specific event from the channel.
Sinks poll their respective channels continuously to read and remove events. The sinks push events to the next hop (in the case of RPC sinks), or to the final destination. Once the data is safely at the next hop or at its destination, the sinks inform the channels, via transaction commits, that those events can now be deleted from the channels.
Figure 2-1 shows a simple Flume agent with a single source, channel, and sink.
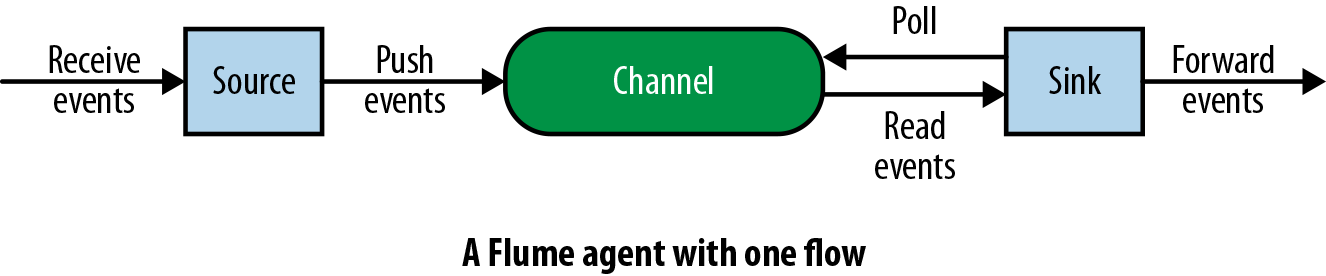
Figure 2-1. A simple Flume agent with one source, channel, and sink
Flume itself does not restrict the number of sources, channels, and sinks in an agent. Therefore, it is possible for Flume sources to receive events and, through configuration, replicate the events to multiple destinations. This is made possible by the fact that sources actually write data to channels via channel processors, interceptors, and channel selectors.
Each source has its own channel processor. Each time the source writes data to the channels, it does so by delegating this task to its channel processor. The channel processor then passes these events to one or more interceptors configured for the source.
An interceptor is a piece of code that can read the event and modify or drop the event based on some processing it does. Interceptors can be used to drop events based on some criteria, like a regex, add new headers to events or remove existing ones, etc. Each source can be configured to use multiple interceptors, which are called in the order defined by the configuration, with the result of one interceptor passed to the next in the chain. This is called the chain-of-responsibility design pattern. Once the interceptors are done processing the events, the list of events returned by the interceptor chain is passed to the list of channels selected for every event in the list by the channel selector.
A source can write to multiple channels via the processor-interceptor-selector route. Channel selectors are the components that decide which channels attached to this source each event must be written to. Interceptors can thus be used to insert or remove data from events so that channel selectors may apply some criteria on these events to decide which channels the events must be written to. Channel selectors can apply arbitrary filtering criteria to events to decide which channels each event must be written to, and which channels are required and optional.
A failure to write to a required channel causes the channel processor to throw a ChannelException to indicate that the source must retry the event (all events that are in that transaction, actually), while a failure to write to an optional channel is simply ignored. Once the events are written out, the processor indicates success to the source, which may send out an acknowledgment (ACK) to the system that sent the event and continue accepting more events. Figure 2-2 shows this workflow.
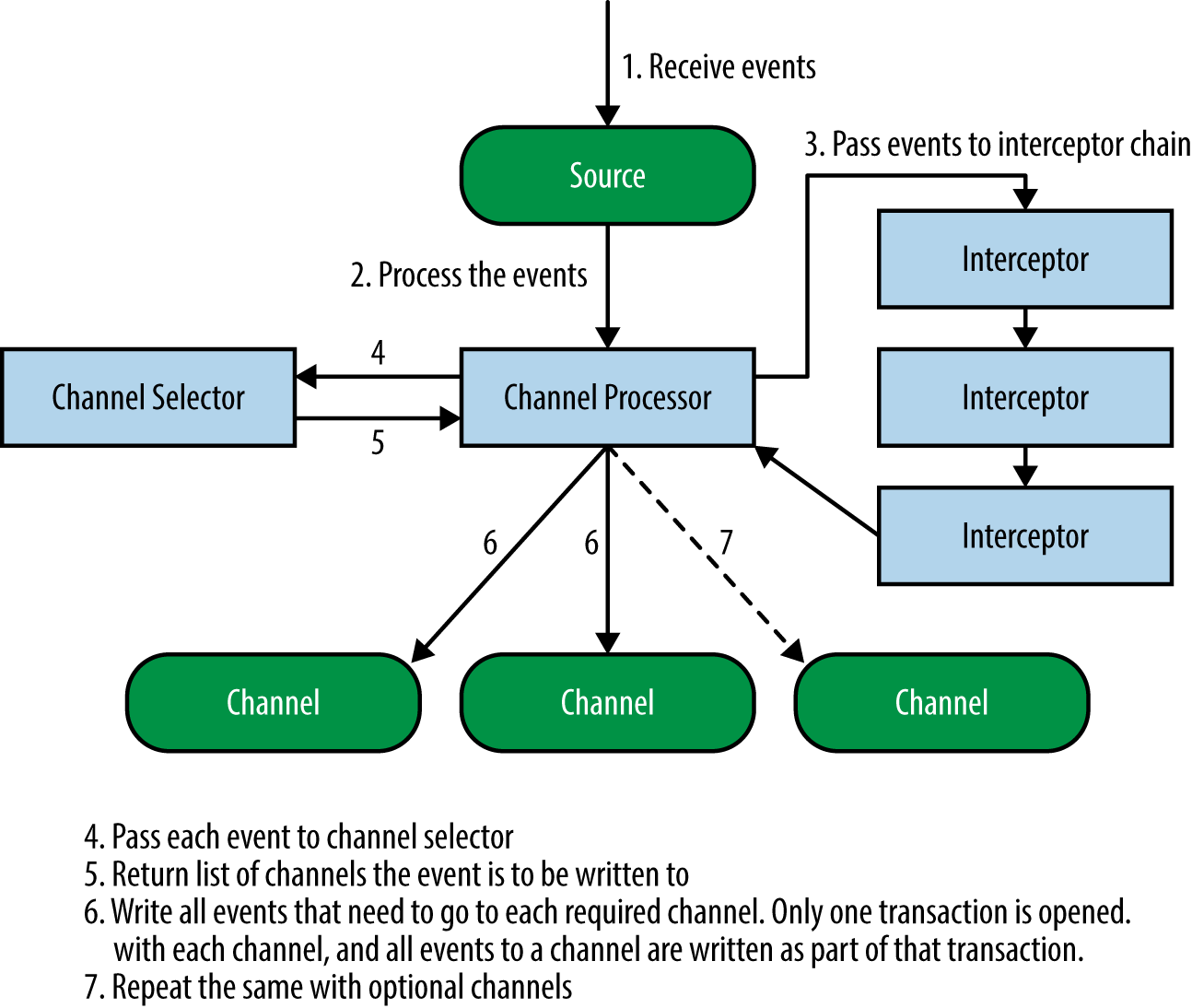
Figure 2-2. Interaction between sources, channel processors, interceptors, and channel selectors
Sink runners run a sink group, which may contain one or more sinks. If there is only one sink in a group, it is more efficient to not have a group at all. The sink runner is simply a thread that asks the sink group (or the sink) to process the next batch of events. Each sink group has a sink processor that selects one of the sinks in the group to process the next set of events. Each sink can take data from exactly one channel, though multiple sinks could take data from the same channel. The sink selected (or the lone sink, if there is no group) takes events from the channel and writes them to the next hop or final destination. This is shown in Figure 2-3.
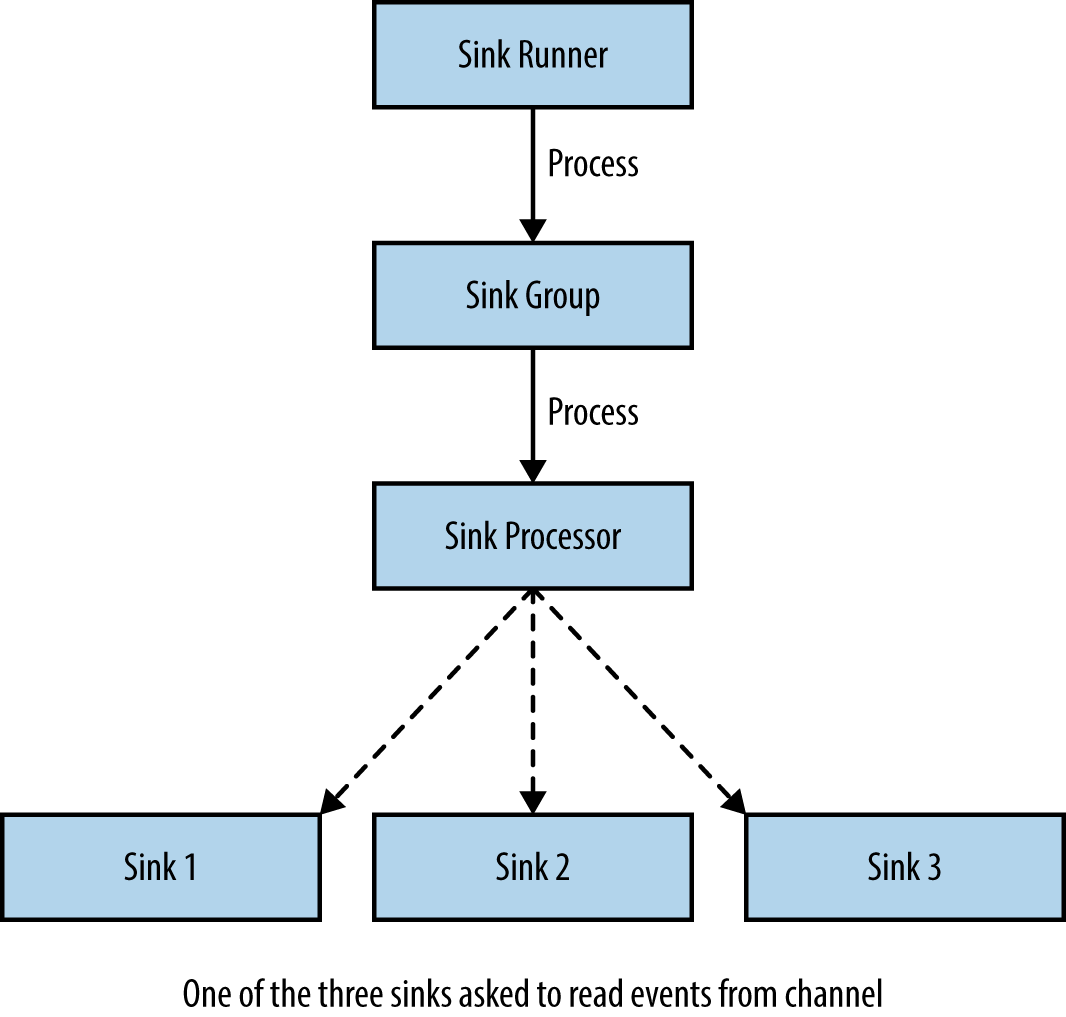
Figure 2-3. Sinks, sink runners, sink groups, and sink processors
Configuring Flume Agents
Flume agents are configured using plain-text configuration files. Flume configuration uses the properties file format, which is simply a plain-text file with newline-separated key-value pairs. An example of a properties file is shown here:
key1 = value1 key2 = value2
By using this format, Flume makes it easy to pass configuration into an agent and its various components. In the configuration file, Flume follows a hierarchical structure. Each Flume agent has a name, which is set when the Flume agent is started using the flume-ng command (described in “Running a Flume Agent”). The configuration file can contain configurations for several Flume agents, but only the configuration of the agent whose name is specified in the flume-ng command is actually loaded.
There are some components that can have several instances of that type in a Flume agent, like sources, sinks, channels, etc. To be able to identify the configuration of each of these components, they are named. The configuration file must list the names of the sources, sinks, channels, and sink groups in an agent in the following format, called the active list:
agent1.sources = source1 source2 agent1.sinks = sink1 sink2 sink3 sink4 agent1.sinkgroups = sg1 sg2 agent1.channels = channel1 channel2
This configuration snippet represents a Flume agent named agent1, with two sources, two sink groups, two channels, and four sinks. Even if there are configuration parameters listed for some component, if they are not in the active list for that agent they are not created, configured, or started. Other components, such as interceptors and channel selectors, need not be present in the active list. They are automatically created and activated when the component (source, sink, etc.) they’re associated with is activated.
For each component to be configured, the configuration for that component is passed in with a prefix in the following format:
<agent-name>.<component-type>.<component-name>.<configuration-parameter> = <value>
The <component-type> for sources is sources, sinks is sinks, channels is channels, and sinkgroups is sinkgroups. Components such as interceptors, channel selectors, and sink processors are tied to a single top-level component and are anchored to these components in the same configuration pattern.
Component names are namespaced based on their component type. Therefore, it is possible to have multiple components with the same name, as long as their component type is different. Components like interceptors are also namespaced to individual sources, so it is possible, though not recommended, to have multiple interceptors with the same name as long as each one is configured to a different source.
For example, configuration could be passed to source1 in the following format:
agent1.sources.source1.port = 4144 agent1.sources.source1.bind = avro.domain.com
For each component, the prefix of the configuration parameter key is removed (including the component name). Only the actual parameter and its value are passed in, via a Context class instance passed in to the configure method. Context is a Map-like key-value store, with some slightly more complex methods. So, in this case the source gets only two parameters with keys port and bind and values 4144 and avro.domain.com, respectively, in the Context instance (and not the entire configuration line). When we discuss the configuration for each component, the tables will show only the actual parameters passed to the components and not the entire lines from the configuration file.
The Flume configuration uses the type parameter for all sources, sinks, channels, and interceptors to instantiate the component. The type parameter can be the fully qualified class name (FQCN), or the alias for built-in components. An example of specifying the type parameter follows:
agent1.sources.source1.type = avro
The Flume configuration system also ensures that the correct channels are set for each source, by creating the channel processor and setting the correct channels for each source’s processor. It also handles interceptor initialization so that the correct channel processors from the correct sources pass the events to the correct interceptors (though from the configuration, it might seem like interceptors are subcomponents of sources—the sources actually don’t need to create or configure interceptors). Similarly, the channel for each sink is also set by the configuration system. The configuration system adds sinks to the correct sink groups and also configures the sink processors for the groups.
Any component that needs to get a configuration from the Flume configuration system must implement the Configurable interface, shown in Example 2-1.
Example 2-1. Configurable interface
package org.apache.flume.conf;
public interface Configurable {
public void configure(Context context);
}
Components can have subcomponents, which can also be configurable. Each component must either configure its subcomponents or pass the subcomponent configuration to the subcomponents, which must then configure themselves. Though each subcomponent can be configured in any way that the component implementation specifies, it is a good practice to implement the Configurable interface. Using the Context class method getSubProperties, subproperties specific to the subcomponent can be passed to it.
An example of configurable subcomponents is HDFS serializers, which are described in detail in “Controlling the Data Format Using Serializers*”. Serializers are configured by the HDFS Sink, using the Configurable interface and the getSubProperties method. Serializers can be configured using the suffix serializer. to the hdfsSink, and the serializer gets the key as the substring following the serializer. in the configuration. In the following example, the serializer would get a Context instance with one key-value pair. The key would be bufferSize and the value would be 4096:
agent.sinks.hdfsSink.serializer.bufferSize = 4096
All Flume components with configurable subcomponents follow this pattern, with each subcomponent getting just its own parameters with all prefixes removed. This is true for even subcomponents of subcomponents, if any exist.
Example 2-2 shows an example of a Flume agent that has multiple components, with some of them having subcomponents. In this agent there is one source, two channels, and two sinks. The source is an HTTP Source, which is named httpSrc. This source writes to two memory channels, memory1 and memory2—this is set by the configuration system in the channel processor, and source implementations need not worry about setting the channels. Multiple parameters—bind, port, ssl, keystore, keystore-password, handler, and handler.insertTimestamp—and their values are available in the Context instance passed to the configure method. It is up to the source implementation to decide what to do with any configuration parameters passed to it.
For this configuration file, the configuration system also creates an interceptor to which all events received by the HTTP Source are forwarded. In this example, the HTTP Source does not need to bother about any special handling of the interceptor creation or configuration. Creation and configuration of interceptors is handled by the channel processor. Similarly, all other components get the parameters and their values via the configure method, including the ones meant for subcomponents.
Example 2-2. A typical Flume agent configuration
agent.sources = httpSrc
agent.channels = memory1 memory2
agent.sinks = hdfsSink hbaseSink
agent.sources.httpSrc.type = http
agent.sources.httpSrc.channels = memory1 memory2
# Bind to all interfaces
agent.sources.httpSrc.bind = 0.0.0.0
agent.sources.httpSrc.port = 4353
# Removing this line will disable SSL
agent.sources.httpSrc.ssl = true
agent.sources.httpSrc.keystore = /tmp/keystore
agent.sources.httpSrc.keystore-password = UsingFlume
agent.sources.httpSrc.handler = usingflume.ch03.HTTPSourceXMLHandler
agent.sources.httpSrc.handler.insertTimestamp = true
agent.sources.httpSrc.interceptors = hostInterceptor
agent.sources.httpSrc.interceptors.hostInterceptor.type = host
# Initializes a memory channel with default configuration
agent.channels.memory1.type = memory
# Initializes a memory channel with default configuration
agent.channels.memory2.type = memory
# HDFS Sink
agent.sinks.hdfsSink.type = hdfs
agent.sinks.hdfsSink.channel = memory1
agent.sinks.hdfsSink.hdfs.path = /Data/UsingFlume/%{topic}/%Y/%m/%d/%H/%M
agent.sinks.hdfsSink.hdfs.filePrefix = UsingFlumeData
agent.sinks.hbaseSink.type = asynchbase
agent.sinks.hbaseSink.channel = memory2
agent.sinks.hbaseSink.serializer = usingflume.ch05.AsyncHBaseDirectSerializer
agent.sinks.hbaseSink.table = usingFlumeTable
Getting Flume Agents to Talk to Each Other
As we will see in the following sections, there is almost always a need for one Flume agent to send data to another. To achieve this goal, specialized RPC sink–source pairs come bundled with Flume. The preferred RPC sink–RPC source pair for agent-to-agent communication is the Avro Sink–Avro Source pair.
To receive data from other Flume agents or from clients, the agents receiving the data can be configured to use Avro Sources and the agents sending the data must be configured to run Avro Sinks. The Avro Sink is a specialized sink that can send events to the Avro Source. In addition to the Avro Sink, the Flume RPC client can also send events to the Avro Source. Avro Sources receive data from other Flume agents or applications running Flume RPC clients via the Avro RPC protocol. A single Avro Source can receive data from a large number of clients or Flume agents. Even though a single Avro Sink can send data to only one Avro Source, it is possible to send data from one agent to many other agents, using sink groups and sink processors we will discuss in “Sink Groups and Sink Processors”.
We will discuss this in more detail in “Sink-to-Source Communication”. For now, it is just important to understand that it is possible to send data from one Flume agent to another and from custom applications to Flume agents via a client API (which we will discuss in Chapter 7).
Complex Flows
As explained earlier, it is possible for Flume agents to have several sources, sinks, and channels, though the number of these components in a single agent must be carefully managed to ensure that hardware is not overwhelmed. Since each source can actually write to multiple channels, events can easily be replicated to make sure that each event goes to more than one destination. Sinks can then remove data from channels to push data to various destinations.
A flow is a series of one or more agents that push data to one another and eventually to a storage or indexing system. In reality, flows can be arbitrarily more complex, with each of the three components being part of multiple flows, and flows including multiple source-channel-sink triplets.
In general, Flume is meant to push data in from a very large number of servers to send data to a single HDFS cluster. Flume comes bundled with Avro and Thrift sink–source pairs, which can be used to send data from one Flume agent to another. This allows the user to design a fan-in–style flow from a large number of data-producing applications. It is important to restrict the number of applications writing data to any storage system to ensure that the storage system scales with the amount of data being written and can handle bursty data writes.
There are multiple ways in which Flume agents can be organized within a cluster. The first and the simplest one is to deploy a single tier of Flume agents to receive data from the application servers and have the same agents write the data directly to the storage system. Such a system isolates applications from a storage system failure and allows the storage system to handle periodic bursts by absorbing the increasing input rate. Flume will adjust the rate of writes to the storage system by backing off for increasing amounts of time every time a write fails (up to some maximum period), so as to not overwhelm the storage system if the capacity is lower than what is required to handle the current write rate.
The number of Flume agents within this single tier usually needs to be only a fraction of the total number of application servers, since Flume’s Avro Source and Thrift Source are designed to receive a large amount of data from a large number of servers, though each agent will have a maximum capacity that depends on the exact hardware deployed, the network, the latency requirements, etc. Such a topology can be designed as shown in Figure 2-4.
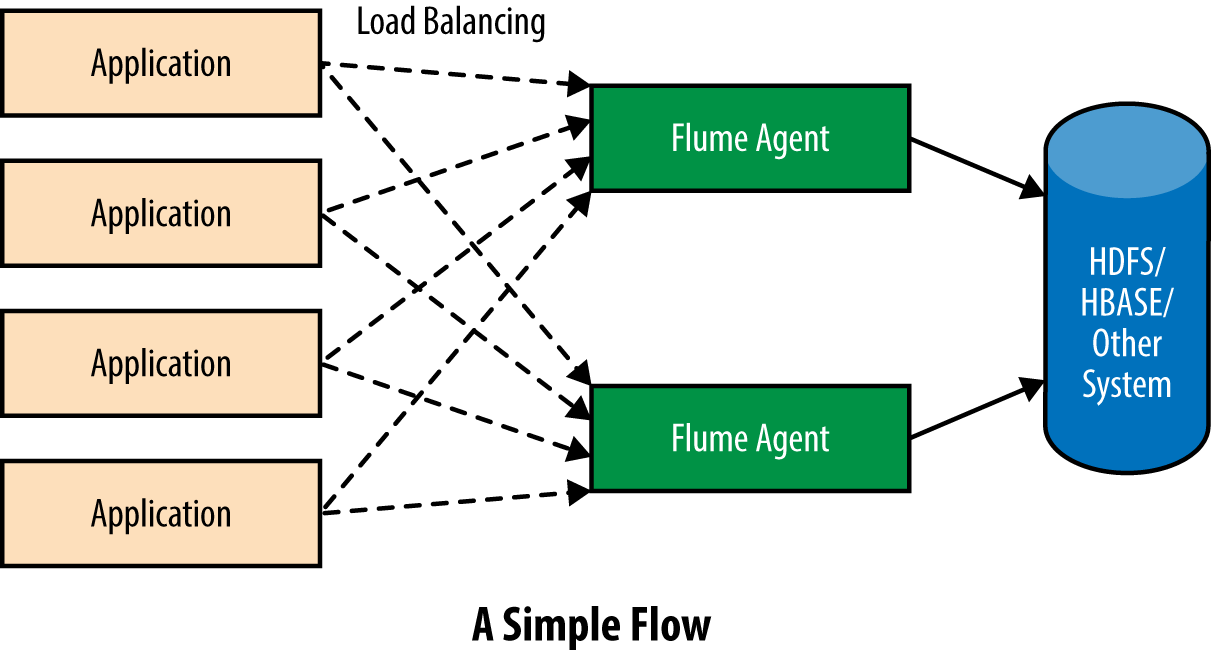
Figure 2-4. Aggregating data from a large number of application servers to HDFS using Flume
To design a fan-in topology, there needs to be a number of Flume agents receiving data from the applications producing the data while a few agents write data to the storage system. Depending on how many servers are producing how much data, the agents could be organized into one, two, or more tiers, with agents from each tier forwarding data from one tier to the next using an RPC sink–RPC source combination.
As shown in Figure 2-5, the outermost tier has the maximum number of agents to receive data from the application, though the number of Flume agents is usually only a small fraction of the number of application servers; the exact number depends on a variety of factors including the network, the hardware, and the amount of data. When the application produces more data or more servers are added, it is easy to scale out by simply adding more agents to the outermost tier and having them configured to write data to the machines in the second tier.
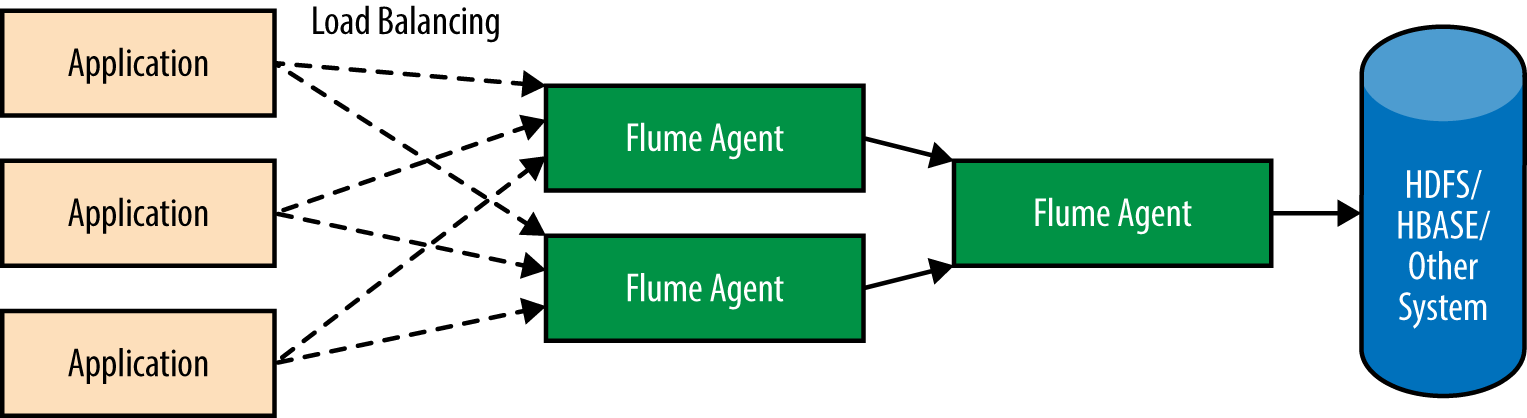
Figure 2-5. A fan-in flow
Often the second tier can be scaled out with more agents much more slowly than the outermost tier, since the number of servers writing the data to the second tier (the number of Flume agents in the outermost tier) needs to grow much more slowly than the number of application servers. This is because the first tier of Flume agents will absorb much of the impact caused by the increase in application servers.
This kind of topology allows Flume to control the rate of writes to the storage system by backing off as needed, while also allowing the application to write data without any worry. Such a topology is also often used when the application producing the data is deployed in many different data centers, and data is being aggregated to one cluster. By writing to a Flume agent within the same data center, the application can avoid having to write data across a cross–data center WAN link, yet ensure that the data will eventually get persisted to the storage system. The communication between Flume agents can be configured to allow higher cross–data center latency to ensure that the agent-to-agent communication can complete successfully without timeouts.
Having more tiers allows for absorbing longer and larger spikes in load, by not overwhelming any one agent or tier and draining out data from each tier as soon as possible. Therefore, the number of tiers required is primarily decided by the amount of data being pushed into the Flume deployment. Since the outermost tier receives data from the largest number of machines, this tier should have the maximum number of agents to scale the networking architecture. As we move further into the Flume topology, the number of agents can reduce significantly.
If the number of servers producing data consistently increases, the number of Flume agents in the tier receiving data from the application servers also needs to increase. This means that at some point, it may be required to increase subsequent tiers, though the number of agents in subsequent tiers can be increased at a far slower rate than in the outer tiers. This also ensures increased buffering capacity within the Flume setup, to accommodate the increase in data production. An example of such a flow is shown in Figure 2-6.
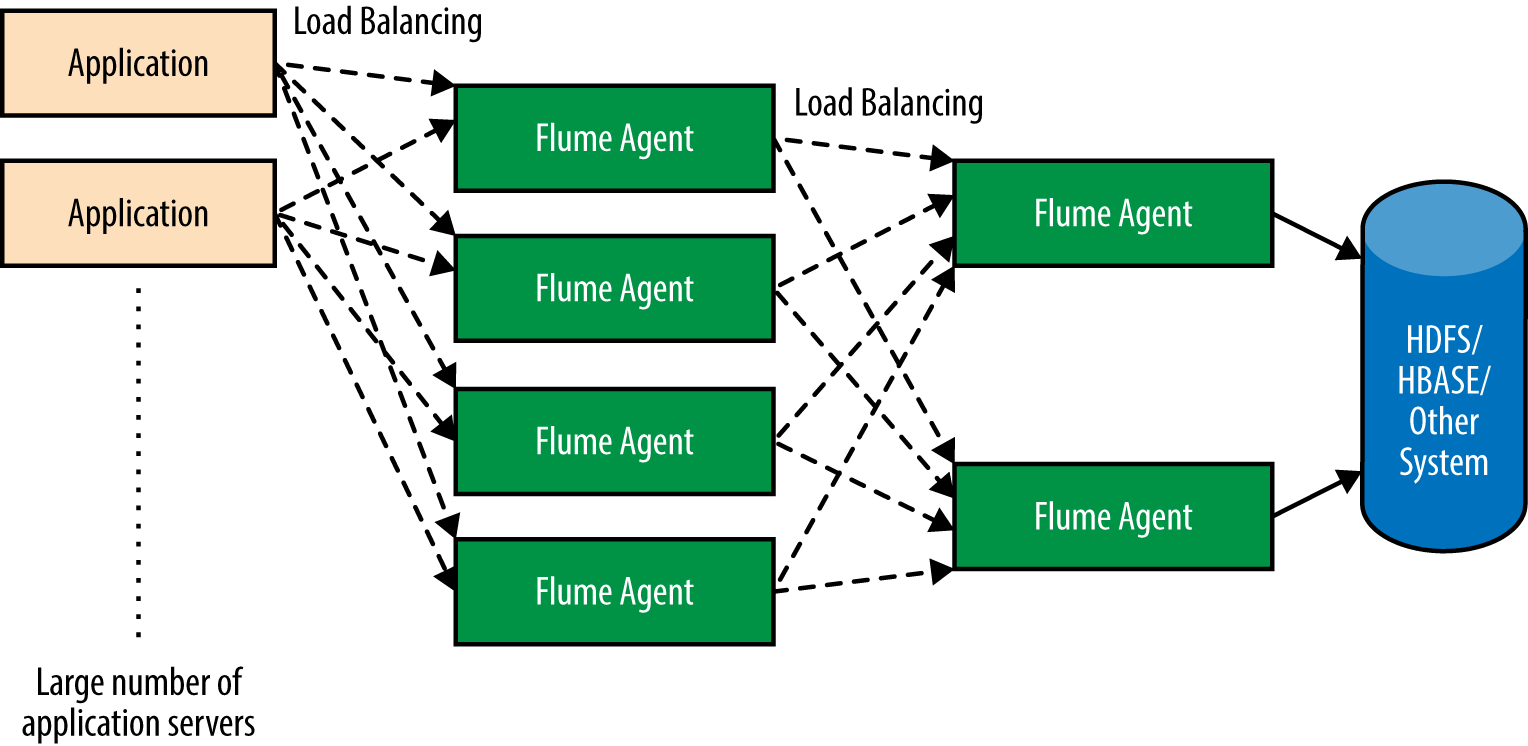
Figure 2-6. A large, complex topology supporting a large number of application servers and providing a lot of buffering
In most cases, communications between applications and Flume agents and between Flume agents themselves have to be resilient to agent or machine failure. Even if data on a failed machine is unavailable while the machine is still down, this should not cause backlogs if capacity has not been exhausted. Flume has features allowing applications that use the Flume API to automatically load balance between multiple Flume agents (this would be a subset of the outermost tier of Flume agents), and also allows sinks to load balance between multiple agents in the next tier via a sink processor. These two combined ensure that data flow continues if there is capacity remaining in tiers following the failed agent.
Replicating Data to Various Destinations
Very often, event counters are aggregated in HBase together with some metadata for real-time querying from user applications, while the actual data is written to HDFS for detailed processing and analysis. Flume allows such topologies, too. An example of this is shown in Figure 2-7.
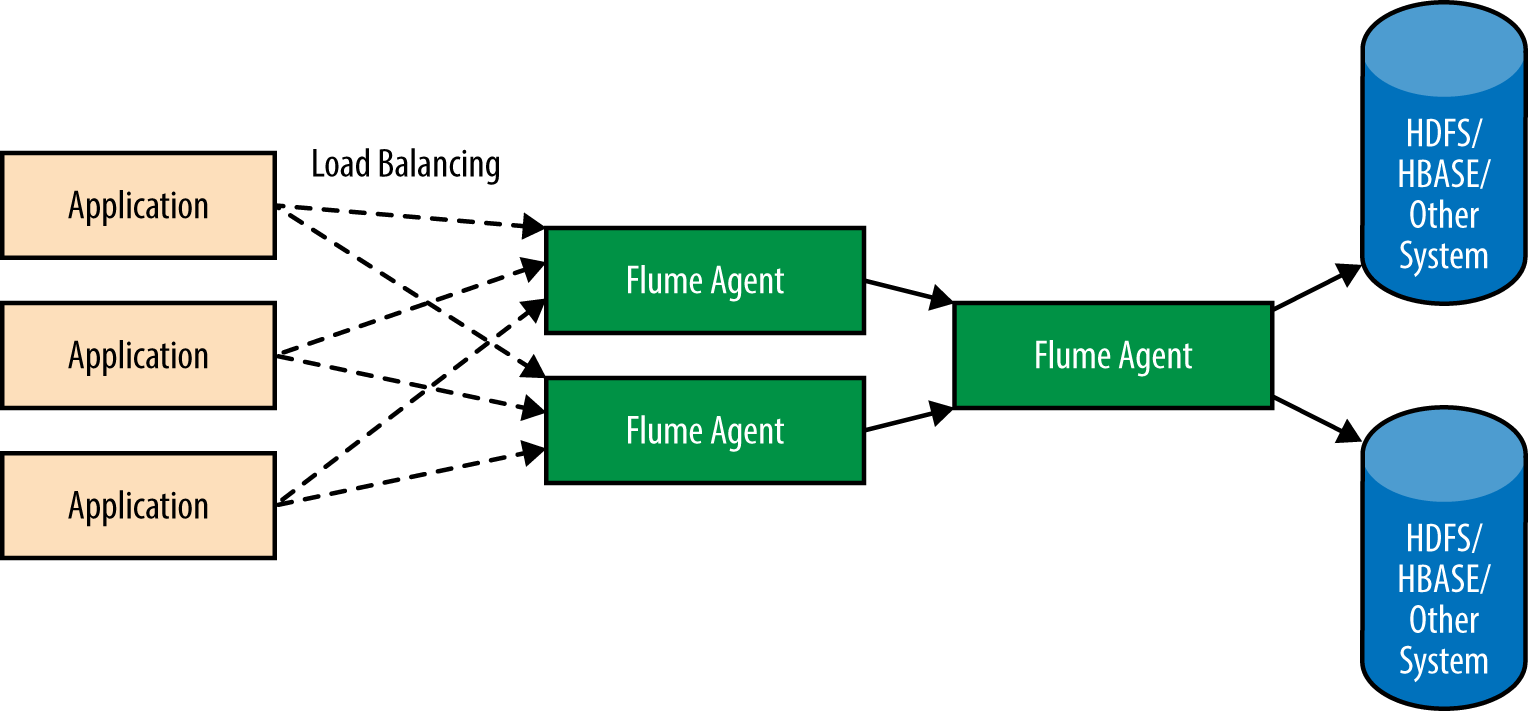
Figure 2-7. Replicating data to various destinations
Accomplishing this is fairly simple. To do this, the Avro Source should be configured to write to the channels that the HDFS and HBase Sinks read from. Since more than one sink can read from a single channel, more HDFS and HBase Sinks can be configured, each reading from the channels feeding HDFS and HBase, respectively. A sample configuration for such an agent is shown here (configuration parameters specific to each component are omitted for clarity):
agent.sources.avro.type = avro # The following line causes the Avro Source # to replicate data to channels feeding HDFS and HBase agent.sources.avro.channels = hdfsChannel hbaseChannel agent.channels.hdfsChannel.type = file agent.channels.hbaseChannel.type = file agent.sinks.hdfsSink1.type = hdfs agent.sinks.hdfsSink1.channel = hdfsChannel agent.sinks.hdfsSink2.type = hdfs agent.sinks.hdfsSink2.channel = hdfsChannel agent.sinks.hbaseSink2.type = hbase agent.sinks.hbaseSink2.channel = hbaseChannel
Dynamic Routing
An important feature of Flume is dynamic routing. Event data coming in is often not of the same priority, or does not need to go to the same data store—some might need to go to HDFS only, while other events may be destined for HDFS and HBase, or the data may go to different clusters based on the priority or some other criterion. In any of these cases, events must be routed based on some criteria. Flume supports this using the multiplexing channel selector. The multiplexing channel selector is a channel selector that inspects every event that passes through it for the value of a specific header; based on this value, it selects a set of channels that the event has to get written to, as illustrated in Figure 2-8. This is built into Flume, and the header, the values, and the channels to select are configurable. Configuring dynamic routing is a bit more involved, so we will discuss it in more detail in “Channel Selectors”.
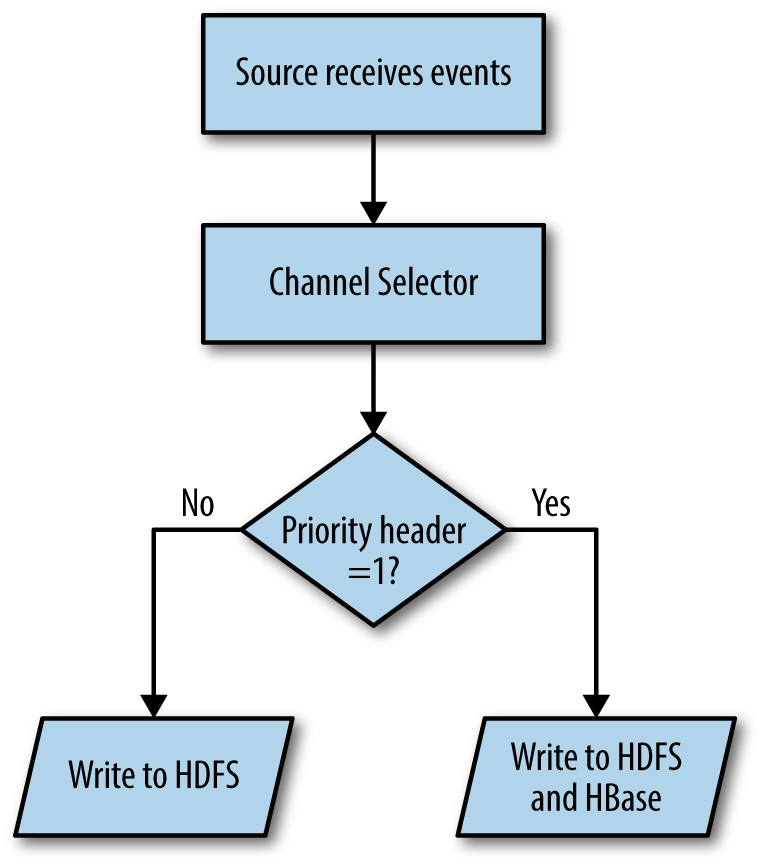
Figure 2-8. Dynamic routing
Intermediate tiers are important when dynamic routing is being configured. Having an additional tier after the tier that does the dynamic routing ensures that once the flow is bifurcated, each new flow does not hit the destination directly and gets buffered on one more tier.
Flume’s No Data Loss Guarantee, Channels, and Transactions
Flume provides guarantees of no data loss, if configured properly. Of course, once the combined capacity of all Flume agents in the pipeline is used up, Flume will no longer accept data from clients. At this point, the client needs to buffer the data, or else data could be lost. Thus, it is extremely important to configure the pipeline to be able to handle the maximum expected downtime. We will discuss configuring Flume pipelines in Chapter 8.
Flume’s durability guarantees depend on the durability guarantees of the channel used. Flume comes bundled with two channels: the Memory Channel and the File Channel. The Memory Channel is an in-memory buffer, and thus any data in the buffer will be lost if the Java Virtual Machine (JVM) or the machine is restarted. The File Channel, on the other hand, is on disk. The File Channel does not lose data even when the JVM or machine is restarted, as long as the disk(s) on which the data is stored is still functioning and accessible. Any data stored on the File Channel will eventually be accessible once the machine and the agent start running.
Channels are transactional in nature. A transaction in this context is different from a database transaction. Each Flume transaction represents a batch of events written to or removed from a channel atomically. Whenever a source writes events to the channel or a sink takes events from a channel, it must do so within the purview of a transaction.
Flume guarantees that the events will reach their destination at least once. Flume strives to write data only once, and in the absence of any kind of failure the events are only written once. Errors like network timeouts or partial writes to storage systems could cause events to get written more than once, though, since Flume will retry writes until they are completely successful. A network timeout might indicate a failure to write or just a slow machine. If it is a slow machine, when Flume retries this will cause duplicates. Therefore, it is often a good idea to make sure each event has some sort of unique identifier that can eventually be used to deduplicate the event data, if required.
Transactions in Flume Channels
Transactional semantics are key to the “no data loss” guarantees made by Flume. When each source (or sink) writes or reads data to or from a channel, it starts a transaction with the channel. For all channels that come bundled with Flume, each transaction is thread-local. For this reason, transaction handling in different types of sources and sinks differs slightly, though the basic idea is the same: each thread should run its own transaction. For all pollable sources and all sinks—which, as described earlier, are driven by runner threads—each process call should start only one transaction and throw an exception if the transaction is rolled back, to inform the runner thread to back off for a bit. Even if the source or sink spawns multiple new threads for I/O, it is best to follow this protocol, to avoid ambiguity if one of the many transactions initiated from the process method fails.
When sources write events to a channel, the transactions are handled by the channel processor, so sources don’t have to handle the transactions by themselves. The channel processor commits the transaction only when the events are successfully written out to the channel; otherwise, it rolls back the transaction and closes it. Since it is possible for each source to write to multiple channels, the channel processor for the source writes events and commits them to one channel at a time. Therefore, it is possible for the data to be written out and committed to some channels but not others. In this case, Flume cannot roll back the transactions that were committed, but to ensure that the data is written out to all channels successfully, Flume will retry writes to all channels, including the ones where the writes were successful previously; this may cause duplicates.
In the case of terminal sinks, a transaction should be committed only when the data is safely written out to the storage system. Once the data is safe at the eventual destination, the transaction can be committed and the channel can delete the events in that transaction. If the write fails, the sink must roll back the transaction to ensure that the events are not lost. All sinks bundled with Flume work this way, and ensure that the data is on HDFS, HBase, Solr, Elastic Search, etc. before the transaction is committed. If the write fails or times out, the transaction is rolled back, and then this or another sink reading from the channel will try to write the events again.
The technique discussed earlier ensures that the data is written out by the terminal sinks in a durable way, but what about an agent-to-Flume agent or a client-to-Flume agent communication? For communication between RPC sinks and RPC sources, the RPC sink sends events out in a batch—these are all read as part of the same transaction from the channel, which are written to its channel(s) by the source in a single transaction. Once the source successfully commits the transaction with its channel(s), it sends an acknowledgment (ACK) to the sink that sent the events indicating that the events are now safe in the receiving agent’s channels. When the sink receives this ACK, the sink commits the transaction it opened when it reads the events from the channel, indicating that the events can now be removed from the channel.
If the source takes too long to send the ACK or there is some network issue that causes the sink to time out, then the sink assumes that the write failed, and it rolls back the transaction and repeats the whole process again (this or another sink connected to this channel could read the same events). This method of overlapping transactions guarantees that events are safely in one of the channels at any point in time. Figure 2-9 shows the timeline of how the RPC sinks and RPC sources guarantee that the events are safely in at least one of the agents at any point.
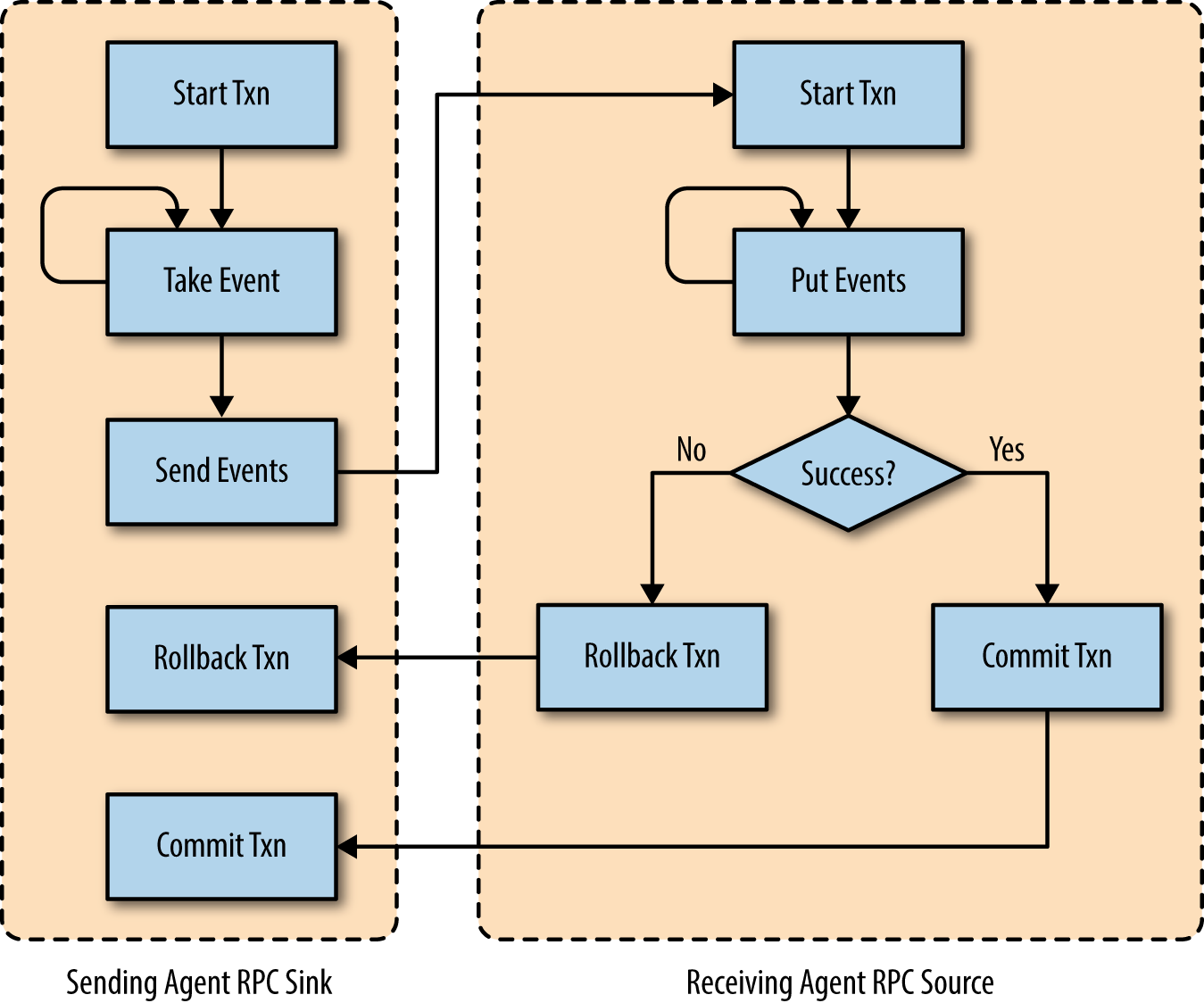
Figure 2-9. RPC sinks and sources guarantee that each event is at least in one agent’s channel by overlapping transactions
Agent Failure and Data Loss
What happens if one of the agents fails, or if the storage system becomes unreachable? When an agent or the eventual destination becomes unreachable, the agent(s) writing to that location will end up seeing errors at the sink. The sink will either see connection failures or missing ACKs from the next hop or the storage system (or the storage system’s client API throwing exceptions). When the sink hits an exception that indicates that the data may not have been written, the sink rolls back the transaction with the channel. Since the incoming data flow has not stopped, this causes the channel size to increase, eventually filling up the channel. When this agent’s channel fills up, the Avro Source (or any other source writing the data to this channel) starts getting ChannelExceptions on Puts to the channel, causing the source to push back to the previous hop by returning an error. This in turn causes the previous hop’s sink to roll back its transaction, causing the channel size on that hop to grow. This scenario is shown in Figure 2-10.
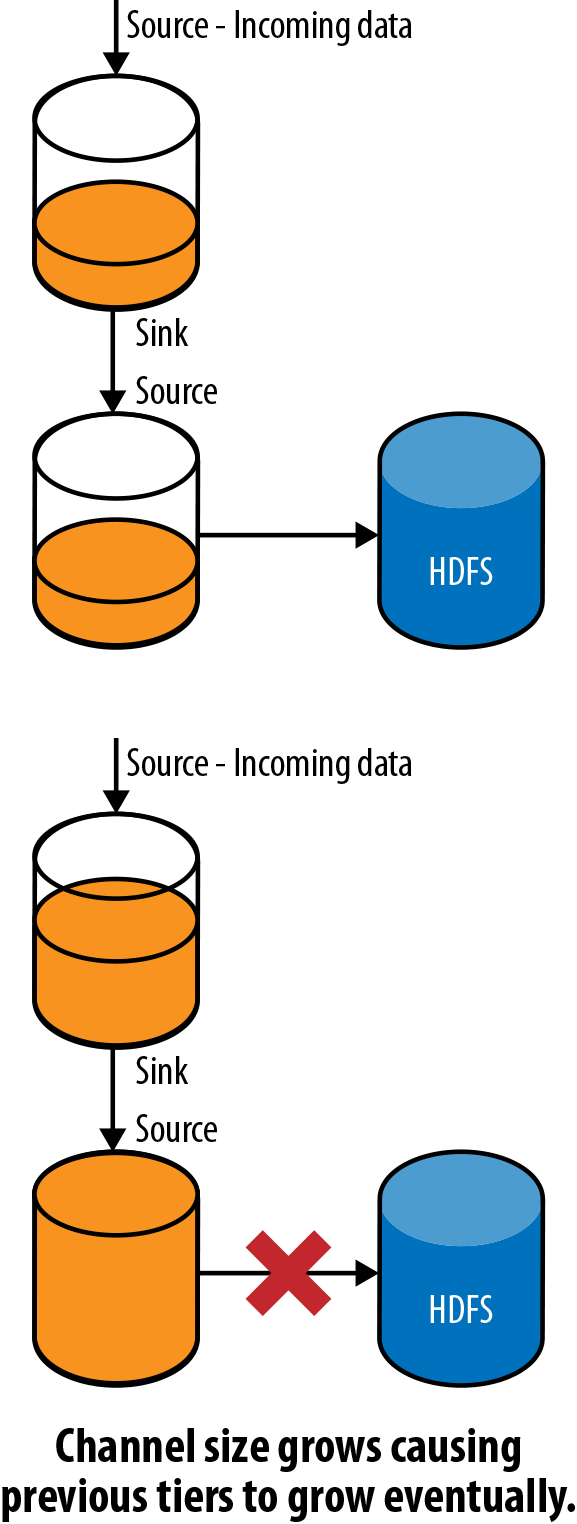
Figure 2-10. Failure causes channels to fill up
As is evident, the failure now causes each tier to buffer data until the channels are full, at which point it starts pushing back on the previous tier, until all tiers are full. At this point, the client starts seeing errors, which the client must now handle by buffering the data or dropping it, causing data loss. Capacity must be planned in such a way that downtime should never create a situation where this happens. We will talk about planning capacity in Chapter 8.
The Importance of Batching
When events are sent to a source that receives data over the network from an RPC sink or a remote client, the source writes out all events in this batch in a single transaction by delegating this task to the channel processor.
In case of the File Channel, which is the persistent channel implementation, each transaction commit causes an fsync [fsync]. fsync is a system call defined by the POSIX standard that tells the operating system to flush all of its internal buffers for a specific file descriptor to disk. If the amount of data written per transaction is small, the overhead cost (in terms of time taken and resources consumed) of initiating a system call, switching to kernel space, and flushing all buffers before actually syncing to disk becomes a very high fraction of the total cost of the fsync call itself.
In the case of the Memory Channel, which is the in-memory channel implementation, there is a cost with regard to synchronization across the channel that comes into play during a commit, but this is far smaller than the overhead of an fsync call.
RPC calls have an additional overhead due to metadata associated with the actual call and all of the additional TCP overheads. When the amount of data sent is really small, these overheads end up being a large fraction of the cost of each RPC call, causing unnecessary network utilization, etc. To avoid such overhead, it is always a good idea to batch several events (unless of course each event is large by itself) into a single RPC call or write from a remote client.
Even though Flume’s RPC client and RPC sinks support writing events without batching or with a batch size of 1, it is almost always a good idea to bundle events into reasonably sized batches to avoid paying the additional overhead cost more times than necessary. The ideal batch size would depend on the specific use case, but for events of up to a few kilobytes, batch sizes between 100 and 1,000 usually work well (though specific hardware, network, and other considerations affect this value, and it should be finally set after testing various values and finding one that matches the performance requirements).
Batching affects the performance of RPC sinks and any other sinks that write data over the network. RPC sink performance is affected for multiple reasons, as mentioned earlier. Even for the HDFS Sink, Flume flushes events to the memory of all data nodes when each batch gets committed. Therefore, it is always a good idea to use reasonably large batch sizes for all sinks.
There are sources that control batch sizes, like the Exec Source, JMS Source, etc. These sources should also batch events for performance, for the same reasons. Sources write events to channels, and they should be written out in reasonably large batches to avoid the fsync or synchronization issues discussed earlier in this section. So, even for sources that control their own batch sizes, it is important that they be configured to use batch sizes that are reasonably large.
What Is a Reasonable Batch Size?
Well, it depends on the deployment, hardware, and several other factors. Batch sizes should not be finalized without a good deal of trial-and-error testing, since having batches that are huge also causes its own problems—like too much fragmentation over the network, etc. Also, having batches that are too large increases the risk of duplication of events, because each batch failing could end up causing a massive number of events to get written again, and if some of the events were successfully written out to HDFS, these events will end up getting written all over again.
To choose the correct batch size for RPC and terminal sinks, start with something like the equivalent of a few hundred KB to 1 MB, and then work up or down from there based on what timeouts you see, and what rate of duplicates you see. If there are too many duplicates or many timeouts, you have to reduce your batch size; in the opposite case, increase it until timeouts start appearing. Once you see the timeouts, you have hit the threshold, and you should reduce it a few percentage points from there.
What About Duplicates?
Flume provides at-least-once guarantees, which basically means that any event sent via Flume to a storage system will get stored at least once. Flume, though, may end up storing the data more than once. There are numerous scenarios that can cause duplicates, some due to errors, others due to configuration.
Since each agent-to-agent RPC call has a configurable timeout, it is possible that even though an RPC did not fail, the sending agent might think it failed if it did not get a response within the timeout, triggering a retry. If the RPC did not fail, this retry will cause the same event to be sent again, causing duplicates. Such a scenario could happen on terminal sinks, such as the HDFS or HBase Sink.
Also, since Flume sources can write to more than one channel, the same event can essentially get duplicated if multiple channels are configured for the same source. If the sinks reading from the channels eventually push the events to the same storage system, this can cause duplicates.
If the use case is duplicate-sensitive, it is usually a good idea to insert unique identifiers in events. These identifiers can be used by a post-processing job to remove duplicates, using Spark, MapReduce, etc.
Running a Flume Agent
This section assumes that the Flume directory structure is not changed and the current working directory is the top level of the Flume directory structure. Each Flume agent is started from the command line using the flume-ng command. This command takes in several parameters—the name of the Flume agent being started, the configuration file to use, and the configuration directory to use.
The Flume configuration file can contain configuration for multiple Flume agents, each identified by a unique name. When a Flume agent is started, this name is passed in to the flume-ng script as the value of the -n command-line switch. Flume’s configuration system will load the configuration parameters associated with the specific agent’s own name only. Because the configuration of multiple agents can be in a single file, it is easy to deploy the same file to multiple tiers, each with a different configuration. In most cases, since all agents in one tier communicate with the same set of agents in the next tier, each agent in that tier can have an identical configuration. Using the same name and the same configuration file for all agents in a tier makes deployment of tiers extremely easy to automate. The configuration file is passed to the Flume agent using the -f command-line switch.
The configuration directory, whose path can be passed to the Flume agent using the -c command-line switch, is home to two important files: flume-env.sh and log4j.properties. When a Flume agent is started, the agent initialization script will source the flume-env.sh script. This file must contain any environment variables that need to be passed to the flume-ng script. The most common environment variables that are initialized using the flume-env.sh file are listed in Table 2-1.
| Environment variable | Description |
|---|---|
|
|
Classpath to be passed to the Flume agent in addition to the Flume lib and plugins.d directories, which are automatically added |
|
|
Any Java-specific options to be passed to the JVM, including the |
|
|
Directory where Hadoop is installed ($HADOOP_PREFIX/bin contains the Hadoop executable) |
|
|
Directory where HBase is installed ($HBASE_HOME/bin contains the HBase executable) |
The FLUME_CLASSPATH environment variable is a list of directories (separated by :) in addition to Flume’s lib and plugins.d directories, which are added to the classpath for the Flume agent. The plugins.d directory is the directory where custom component JARs (Java Archive files) can be dropped in, so Flume can use those to load the custom components.
JAVA_OPTS is a set of arguments that are to be passed directly to the JVM. The most commonly used are the parameters used to modify the heap size allocated to the JVM: -Xms and -Xmx. You can read about them and the other options that can go into JAVA_OPTS in the Java documentation [java-commandline].
HADOOP_PREFIX (and equivalently HADOOP_HOME in the older Hadoop version 1) is the directory where Hadoop is installed. If the hadoop command is the PATH, Flume will simply use that if HADOOP_PREFIX is not set. HBASE_HOME accomplishes the same for HBase.
To run a Flume agent named usingFlumeAgent, which uses a Flume configuration /home/usingflume/flume/flume.conf and a configuration directory /home/usingflume/flume/conf, the following command can be used (assuming that the current working directory is the directory in which Flume is installed):
bin/flume-ng agent -n usingFlumeAgent -f /home/usingflume/flume/flume.conf -c /home/usingflume/flume/conf
The agent will read the log4j.properties file in the configuration directory and log according to the specification in that file. log4j configuration details can be found in the log4j documentation [log4j]. Once the agent starts, it keeps running until it is killed by a SIGTERM or its equivalent, causing the agent to shut down. The agent does all the logging to the log4j logs (it might look like the agent is stuck, even though it is actually running and doing what it is supposed to; nothing gets logged to the console).
The flume-ng script accepts a lot more parameters, which are described in Table 2-2.
| Parameter | Description |
|---|---|
|
|
Agent name to use. This must be placed after |
|
|
Configuration file (without this the agent will not run). |
|
|
Configuration directory to use (if not specified, ./conf is used). |
|
|
List of directories to be appended to the classpath. These can be specifed in |
|
|
Dry run only. This will print out the entire command that Flume will use if run without this switch. |
|
|
If ./plugins.d is not to be used as the directory where JARs containing custom classes are, the value of this parameter is checked for the plug-ins. |
|
|
This will print out detailed help. |
Even though Flume can accept parameters to pass to the JVM via the command line, it is recommended to use JAVA_OPTS to set these parameters, and thus they are not listed here.
To find out the exact version and revision information for the version of Flume that is being used, run:
bin/flume-ng version
Summary
In this chapter, we discussed the basics of Flume and its design, its various components, and how to configure it. Finally, we looked at how to run a Flume agent once its configuration and components have been decided.
Chapter 3, Chapter 4, and Chapter 5 will cover sources, channels, and sinks, respectively. Chapter 6 will cover other components—interceptors, channel selectors, sink groups, and sink processors. Chapter 7 will explain how to get data into Flume using the Flume software development kit (SDK) and the Embedded Agent API. The last chapter, Chapter 8, will cover details on how to plan with, deploy, and monitor Flume.
References
-
[java-commandline] Java command-line arguments, http://bit.ly/1p9NzQX
-
[log4j] log4j documentation, https://logging.apache.org/log4j/1.2/manual.html
-
[fsync]
fsyncsystem call, http://bit.ly/1p9Nzk3