
Chapter 8. Diffs
A diff is a compact summary of the
differences (hence the name “diff”) between two items. For
example, given two files, the Unix and Linux diff command compares the files line by line and
summarizes the deviations in a diff, as shown in Example 8-1. In the example, initial is one version of some prose and
rewrite is a subsequent revision. The
-u option produces a unified diff, a
standardized format used widely to share modifications.
$cat initial$cat rewriteNow is the time Today is the time For all good men For all good men To come to the aid And women Of their country. To come to the aid Of their country. $diff -u initial rewrite--- initial 1867-01-02 11:22:33.000000000 -0500 +++ rewrite 2000-01-02 11:23:45.000000000 -0500 @@ -1,4 +1,5 @@ -Now is the time +Today is the time For all good men +And women To come to the aid Of their country.
Let’s look at the diff in detail. In the header, the original
file is denoted by --- and the new file
by +++. The @@ line provides line number context for both file
versions. A line prefixed with a minus sign (–) must be removed from the original file to
produce the new file. Conversely, a line with a leading plus sign (+) must be added to the original file to produce
the new file. A line that begins with a space is the same in both files and
is provided by the -u option as context.
By itself, a diff offers no reason or rationale for a change, nor does it justify the initial or final state. However, a diff offers more than just a digest of how files differ. It provides a formal description of how to transform one file to the other. (You’ll find such instructions useful when applying or reverting changes.) In addition, diff can be extended to show differences among multiple files and entire directory hierarchies.
The Unix diff command can compute the differences of all pairs of files found in two directory hierarchies. The command diff -r traverses each hierarchy in tandem, twins files by pathname (say, original/src/main.c and new/src/main.c), and summarizes the differences between each pair. Using diff -r -u produces a set of unified diffs comparing two hierarchies.
Git has its own diff facility and can likewise produce a digest of differences. The command git diff can compare files much akin to Unix’s diff command. Moreover, like diff -r, Git can traverse two tree objects and generate a representation of the variances. But git diff also has its own nuances and powerful features tailored to the particular needs of Git users.
Note
Technically, a tree object represents only one directory level in the repository. It contains information on the directory’s immediate files and immediate subdirectories, but it does not catalog the complete contents of all subdirectories. However, because a tree object references the tree objects for each subdirectory, the tree object at the root of the project effectively represents the entire project at a moment in time. Hence, we can paraphrase and say git diff traverses “two” trees.
In this chapter, we’ll cover some of the basics of git diff and some of its special capabilities. You will learn how to use Git to show editorial changes in your working directory as well as arbitrary changes between any two commits within your project history. You will see how Git’s diff can help you make well-structured commits during your normal development process and you will also learn how to produce Git patches, which are described in detail in Chapter 14.
Forms of the git diff Command
If you pick two different root-level tree objects for comparison, git diff yields all deviations between the two project states. That’s powerful. You could use such a diff to convert wholesale from one project state to another. For example, if you and a co-worker are developing code for the same project, a root-level diff could effectively sync the repositories at any time.
There are three basic sources for tree or treelike objects to use with git diff:
Any tree object anywhere within the entire commit graph
Your working directory
The index
Typically, the trees compared in a git diff command are named via commits, branch names, or tags, but any commit name discussed in Identifying Commits of Chapter 6 suffices. Also, both the file and directory hierarchy of your working directory, as well as the complete hierarchy of files staged in the index, can be treated as trees.
The git diff command can perform four fundamental comparisons using various combinations of those three sources.
- git diff
git diff shows the difference between your working directory and the index. It exposes what is dirty in your working directory and is thus a candidate to stage for your next commit. This command does not reveal differences between what’s in your index and what’s permanently stored in the repository (not to mention remote repositories you might be working with).
- git diff
commit This form summarizes the differences between your working directory and the given
commit. Common variants of this command nameHEADor a particular branch name as thecommit.- git diff --cached
commit This command shows the differences between the staged changes in the index and the given
commit. A common commit for the comparison—and the default if no commit is specified—isHEAD. WithHEAD, this command shows you how your next commit will alter the current branch.If the option
--cacheddoesn’t make sense to you, perhaps the synonym--stagedwill. It is available in Git version 1.6.1 and later.- git diff
commit1commit2 If you specify two arbitrary commits, the command displays the differences between the two. This command ignores the index and working directory, and it is the workhorse for arbitrary comparisons between two trees that are already in your object store.
The number of parameters on the command line determines what fundamental form is used and what is compared. You can compare any two commits or trees. What’s being compared need not have a direct or even an indirect parent–child relationship. If you don’t supply a tree object or two, then git diff compares implied sources, such as your index or working directory.
Let’s examine how these different forms apply to Git’s object model. The example in Figure 8-1 shows a project directory with two files. The file file1 has been modified in the working directory, changing its content from “foo” to “quux.” That change has been staged in the index using git add file1, but it is not yet committed.

A version of the file file1
from each of your working directory, the index, and the HEAD have been identified. Even though the
version of file1 that is in the
index, bd71363, is actually stored as a
blob object in the object store, it is indirectly referenced through the
virtual tree object that is the index. Similarly, the HEAD version of the file, a23bf, is also indirectly referenced through
several steps.
This example nominally demonstrates the changes within file1. The bold arrows in the figure point to the tree or virtual tree objects to remind you that the comparison is actually based on complete trees and not just on individual files.
From Figure 8-1, you can see how using git diff without arguments is a good technique for verifying the readiness of your next commit. As long as that command emits output, you have edits or changes in your working directory that are not yet staged. Check the edits on each file. If you are satisfied with your work, use git add to stage the file. Once you stage a changed file, the next git diff no longer yields diff output for that file. In this way, you can step progressively through each dirty file in your working directory until the differences disappear, meaning that all files are staged in your index. Don’t forget to check for new or deleted files, too. At any time during the staging process, the command git diff --cached shows the complementary changes, or those changes already staged in the index that will be present in your next commit. When you’re finished, git commit captures all changes in your index into a new commit.
You are not required to stage all the changes from your working directory for a single commit. In fact, if you find you have conceptually different changes in your working directory that should be made in different commits, you can stage one set at a time, leaving the other edits in your working directory. A commit captures only your staged changes. Repeat the process, staging the next set of files appropriate for a subsequent commit.
The astute reader might have noticed that, although there are four fundamental forms of the git diff command, only three are highlighted with bold arrows in Figure 8-1. So, what is the fourth? There is only one tree object represented by your working directory, and there is only one tree object represented by the index. In the example, there is one commit in the object store along with its tree. However, the object store is likely to have many commits named by different branches and tags, all of which have trees that can be compared with git diff. Thus, the fourth form of git diff simply compares any two arbitrary commits (trees) already stored within the object store.
In addition to the four basic forms of git diff, there are myriad options as well. Here are a few of the more useful ones.
-MThe
-Moption detects renames and generates a simplified output that simply records the file rename rather than the complete removal and subsequent addition of the source file. If the rename is not a pure rename but also has some additional content changes, Git calls those out.-wor--ignore-all-spaceBoth
-wand--ignore-all-spacecompare lines without considering changes in whitespace as significant.--statThe
--statoption adds statistics about the difference between any two tree states. It reports in a compact syntax how many lines changed, how many were added, and how many were elided.--colorThe
--coloroption colorizes the output; a unique color represents each of the different types of changes present in the diff.
Finally, the git diff may be limited to show diffs for a specific set of files or directories.
Simple git diff Example
Here we construct the scenario presented in Figure 8-1, run through the scenario, and watch the various forms of git diff in action. First, let’s set up a simple repository with two files in it.
$mkdir /tmp/diff_example$cd /tmp/diff_example$git initInitialized empty Git repository in /tmp/diff_example/.git/ $echo "foo" > file1$echo "bar" > file2$git add file1 file2$git commit -m "Add file1 and file2"[master (root-commit)]: created fec5ba5: "Add file1 and file2" 2 files changed, 2 insertions(+), 0 deletions(-) create mode 100644 file1 create mode 100644 file2
Next, let’s edit file1 by replacing the word “foo” with “quux.”
$ echo "quux" > file1The file1 has been modified in
the working directory but has not been staged. This state is not yet the
situation depicted in Figure 8-1, but you can
still make a comparison. You should expect output if you compare the
working directory with the index or the existing HEAD versions. However, there should be no
difference between the index and the HEAD because nothing has been staged. (In other
words, what is staged is the current HEAD tree still.)
# working directory versus index
$ git diff
diff --git a/file1 b/file1
index 257cc56..d90bda0 100644
--- a/file1
+++ b/file1
@@ -1 +1 @@
-foo
+quux
# working directory versus HEAD
$ git diff HEAD
diff --git a/file1 b/file1
index 257cc56..d90bda0 100644
--- a/file1
+++ b/file1
@@ -1 +1 @@
-foo
+quux
# index vs HEAD, identical still
$ git diff --cached
$Applying the maxim just given, git diff produced output and so file1 could be staged. Let’s do this now.
$git add file1$git status# On branch master # Changes to be committed: # (use "git reset HEAD <filed>..." to unstage) # # modified: file1
Here you have exactly duplicated the situation described by Figure 8-1. Because file1 is now staged, the working directory and
the index are synchronized and should not show any differences. However,
there are now differences between the HEAD version and both the working directory and
the staged version in the index.
# working directory versus index
$ git diff
# working directory versus HEAD
$ git diff HEAD
diff --git a/file1 b/file1
index 257cc56..d90bda0 100644
--- a/file1
+++ b/file1
@@ -1 +1 @@
-foo
+quux
# index vs HEAD
$ git diff --cached
diff --git a/file1 b/file1
index 257cc56..d90bda0 100644
--- a/file1
+++ b/file1
@@ -1 +1 @@
-foo
+quuxIf you ran git commit now, the new commit would capture the staged changes shown by the last command, git diff --cached (which, as mentioned before, has the new synonym git diff --staged).
Now, to throw a monkey wrench in the works, what would happen if you edited file1 before making a commit? Let’s see!
$echo "baz" > file1# wd versus index $git diffdiff --git a/file1 b/file1 index d90bda0..7601807 100644 --- a/file1 +++ b/file1 @@ -1 +1 @@ -quux +baz # wd versus HEAD $git diff HEADdiff --git a/file1 b/file1 index 257cc56..7601807 100644 --- a/file1 +++ b/file1 @@ -1 +1 @@ -foo +baz # index vs HEAD $git diff --cacheddiff --git a/file1 b/file1 index 257cc56..d90bda0 100644 --- a/file1 +++ b/file1 @@ -1 +1 @@ -foo +quux
All three diff operations show some form of difference now! But which version will be committed? Remember, git commit captures the state present in the index. And what’s in the index? It’s the content revealed by git diff --cached or git diff --staged command, or the version of file1 that contains the word “quux”!
$ git commit -m "quux uber alles"
[master]: created f8ae1ec: "quux uber alles"
1 files changed, 1 insertions(+), 1 deletions(-)Now that the object store has two commits in it, let’s try the general form of the git diff command.
# Previous HEAD version versus current HEAD
$ git diff HEAD^ HEAD
diff --git a/file1 b/file1
index 257cc56..d90bda0 100644
--- a/file1
+++ b/file1
@@ -1 +1 @@
-foo
+quuxThis diff confirms that the previous commit changed file1 by replacing “foo” with “quux.”
So is everything synchronized now? No. The working directory copy of file1 contains “baz.”
$ git diff
diff --git a/file1 b/file1
index d90bda0..7601807 100644
--- a/file1
+++ b/file1
@@ -1 +1 @@
-quux
+bazgit diff and Commit Ranges
There are two additional forms of git diff that bear some explanation, especially in contrast to git log.
The git diff command supports a double-dot syntax to represent the difference between two commits. Thus, the following two commands are equivalent:
$git diff master bug/pr-1$git diff master..bug/pr-1
Unfortunately, the double-dot syntax in git diff means something quite different from the same syntax in git log, which you learned about in Chapter 6. It’s worth comparing git diff and git log in this regard because doing so highlights the relationship of these two commands to changes made in repositories. Some points to keep in mind for the following example:
git diff doesn’t care about the history of the files it compares or anything about branches
git log is extremely conscious of how one file changed to become another—for example, when two branches diverged and what happened on each branch
The log and diff commands perform two fundamentally different operations. Whereas log operates on a set of commits, diff operates on two different end points.
Imagine the following sequence of events:
Someone creates a new branch off the
masterbranch to fix bugpr-1, calling the new branchbug/pr-1.The same developer adds the line “Fix Problem report 1” to a file in the
bug/pr-1branch.Meanwhile, another developer fixes bug
pr-3in themasterbranch, adding the line “Fix Problem report 3” to the same file in themasterbranch.
In short, one line was added to a file in each branch. If you look
at the changes to branches at a high level, you can see when the bug/pr-1 branch was launched and when each
change was made:
$ git show-branch master bug/pr-1
* [master] Added a bug fix for pr-3.
! [bug/pr-1] Fix Problem Report 1
--
* [master] Added a bug fix for pr-3.
+ [bug/pr-1] Fix Problem Report 1
*+ [master^] Added Bob's fixes.If you type git log -p
master..bug/pr-1, you will see one commit, because the syntax
master..bug/pr-1 represents all those
commits in bug/pr-1 that are not also
in master. The command traces back to
the point where bug/pr-1 diverged from
master, but it does not look at
anything that happened to master since
that point.
$ git log -p master..bug/pr-1
commit 8f4cf5757a3a83b0b3dbecd26244593c5fc820ea
Author: Jon Loeliger <[email protected]>
Date: Wed May 14 17:53:54 2008 -0500
Fix Problem Report 1
diff --git a/ready b/ready
index f3b6f0e..abbf9c5 100644
--- a/ready
+++ b/ready
@@ -1,3 +1,4 @@
stupid
znill
frot-less
+Fix Problem report 1In contrast, git diff
master..bug/pr-1 shows the total set of differences between the
two trees represented by the heads of the master and bug/pr-1 branches. History doesn’t matter; only
the current state of the files does.
$ git diff master..bug/pr-1
diff --git a/ready b/ready
index f3b6f0e..abbf9c5 100644
--- a/ready
+++ b/ready
@@ -1,4 +1,4 @@
stupid
znill
frot-less
-Fix Problem report 3
+Fix Problem report 1To paraphrase the git diff
output, you can change the file in the master branch to the version in the bug/pr-1 branch by removing the line “Fix
Problem report 3” and then adding the line “Fix Problem
report 1” to the file.
As you can see, this diff includes commits from both branches. This may not seem crucial with this small example, but consider the example in Figure 8-2 with more expansive lines of development on two branches.
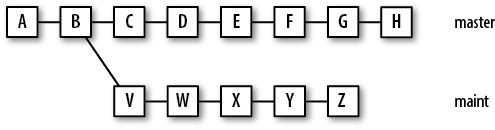
In this case, git log
master..maint represents the five individual commits V, W, ...,
Z. On the other hand, git diff master..maint represents the
differences in the trees at H and
Z, an accumulated 11 commits: C, D, ...,
H and V, ..., Z.
Similarly, both git log
and git diff accept the form
to produce a symmetrical difference. As
before, however, git log
commit1...commit2
commit1...commit2
and git diff
commit1...commit2
yield different results.
As discussed in Commit Ranges of Chapter 6, the command git log
commit1...commit2
displays the commits reachable from either commit but not both.
Thus, git log master...maint in the
previous example would yield C,
D, ..., H and V, ...,
Z.
The symmetric difference in git
diff shows the differences between a commit that is a common
ancestor (or merge base) of
commit1 and commit2.
Given the same genealogy in Figure 8-2,
git diff master...maint combines the
changes in the commits V, W, ..., Z.
git diff with Path Limiting
By default, the command git diff operates on the entire directory structure rooted at a given tree object. However, you can leverage the same path limiting technique employed by git log to limit the output of git diff to a subset of the repository.
For example, at one point[18] in the development of the Git’s own repository, git diff --stat displayed this:
$ git diff --stat master~5 master
Documentation/git-add.txt | 2 +-
Documentation/git-cherry.txt | 6 +++++
Documentation/git-commit-tree.txt | 2 +-
Documentation/git-format-patch.txt | 2 +-
Documentation/git-gc.txt | 2 +-
Documentation/git-gui.txt | 4 +-
Documentation/git-ls-files.txt | 2 +-
Documentation/git-pack-objects.txt | 2 +-
Documentation/git-pack-redundant.txt | 2 +-
Documentation/git-prune-packed.txt | 2 +-
Documentation/git-prune.txt | 2 +-
Documentation/git-read-tree.txt | 2 +-
Documentation/git-remote.txt | 2 +-
Documentation/git-repack.txt | 2 +-
Documentation/git-rm.txt | 2 +-
Documentation/git-status.txt | 2 +-
Documentation/git-update-index.txt | 2 +-
Documentation/git-var.txt | 2 +-
Documentation/gitk.txt | 2 +-
builtin-checkout.c | 7 ++++-
builtin-fetch.c | 6 ++--
git-bisect.sh | 29 ++++++++++++--------------
t/t5518-fetch-exit-status.sh | 37 ++++++++++++++++++++++++++++++++++
23 files changed, 83 insertions(+), 40 deletions(-)To limit the output to just Documentation changes, you could instead use git diff --stat master~5 master Documentation:
$ git diff --stat master~5 master Documentation
Documentation/git-add.txt | 2 +-
Documentation/git-cherry.txt | 6 ++++++
Documentation/git-commit-tree.txt | 2 +-
Documentation/git-format-patch.txt | 2 +-
Documentation/git-gc.txt | 2 +-
Documentation/git-gui.txt | 4 ++--
Documentation/git-ls-files.txt | 2 +-
Documentation/git-pack-objects.txt | 2 +-
Documentation/git-pack-redundant.txt | 2 +-
Documentation/git-prune-packed.txt | 2 +-
Documentation/git-prune.txt | 2 +-
Documentation/git-read-tree.txt | 2 +-
Documentation/git-remote.txt | 2 +-
Documentation/git-repack.txt | 2 +-
Documentation/git-rm.txt | 2 +-
Documentation/git-status.txt | 2 +-
Documentation/git-update-index.txt | 2 +-
Documentation/git-var.txt | 2 +-
Documentation/gitk.txt | 2 +-
19 files changed, 25 insertions(+), 19 deletions(-)Of course, you can view the diffs for a single file, too.
$ git diff master~5 master Documentation/git-add.txt
diff --git a/Documentation/git-add.txt b/Documentation/git-add.txt
index bb4abe2..1afd0c6 100644
--- a/Documentation/git-add.txt
+++ b/Documentation/git-add.txt
@@ -246,7 +246,7 @@ characters that need C-quoting. `core.quotepath` configuration can be
used to work this limitation around to some degree, but backslash,
double-quote and control characters will still have problems.
-See Also
+SEE ALSO
--------
linkgit:git-status[1]
linkgit:git-rm[1]In the following example, also taken from Git’s own repository, the
-S"string" searches the past
50 commits to the master branch for
changes containing string.
$ git diff -S"octopus" master~50
diff --git a/Documentation/RelNotes-1.5.5.3.txt b/Documentation/RelNotes-1.5.5.3.txt
new file mode 100644
index 0000000..f22f98b
--- /dev/null
+++ b/Documentation/RelNotes-1.5.5.3.txt
@@ -0,0 +1,12 @@
+GIT v1.5.5.3 Release Notes
+==========================
+
+Fixes since v1.5.5.2
+--------------------
+
+ * "git send-email --compose" did not notice that non-ascii contents
+ needed some MIME magic.
+
+ * "git fast-export" did not export octopus merges correctly.
+
+Also comes with various documentation updates.Used with -S, often called the
pickaxe, Git lists the diffs that contain a change
in the number of times the given string is used
in the diff. Conceptually, you can think of this as “Where is the
given string either introduced or
removed?” You can find an example of the pickaxe used with git log in Using Pickaxe of Chapter 6.
Comparing How Subversion and Git Derive diffs
Most systems, such as CVS or SVN, track a series of revisions and store just the changes between each pair of files. This technique is meant to save storage space and overhead.
Internally, such systems spend a lot of time thinking about things
like “the series of changes between A and B.” When you update
your files from the central repository, for example, SVN remembers that
the last time you updated the file you were at revision r1095, but now the repository is at revision
r1123. Thus, the server must send you
the diff between r1095 and r1123. Once your SVN client has these diffs, it
can incorporate them into your working copy and produce r1123. (That’s how SVN avoids sending you all
the contents of all files every time you update.)
To save disk space, SVN also stores its own repository as a series
of diffs on the server. When you ask for the diffs between r1095 and r1123, it looks up all the individual diffs for
each version between those two versions, merges them together into one
large diff, and sends you the result. But Git doesn’t work like
that.
In Git, as you’ve seen, each commit contains a tree, which is a list of files contained by that commit. Each tree is independent of all other trees. Git users still talk about diffs and patches, of course, because these are still extremely useful. Yet, in Git, a diff and a patch are derived data, not the fundamental data they are in CVS or SVN. If you look in the .git directory, you won’t find a single diff; if you look in a SVN repository, it consists mostly of diffs.
Just as SVN is able to derive the complete set of differences
between r1095 and r1123, Git can retrieve and derive the
differences between any two arbitrary states. But SVN must look at each
version between r1095 and r1123, whereas Git doesn’t care about the
intermediate steps.
Each revision has its own tree, but Git doesn’t require those to generate the diff; Git can operate directly on snapshots of the complete state at each of the two versions. This simple difference in storage systems is one of the most important reasons that Git is so much faster than other RCSs.