
Chapter 13. Repository Management
This chapter describes how to publish Git repositories and then presents two approaches to managing and publishing repositories for cooperative development. One approach centralizes the repository; the other distributes the repository. Each solution has its place, and which is right for you and your project depends on your requirements and philosophy.
However, no matter which approach you adopt, Git implements a distributed development model. For example, even if your team centralizes the repository, each developer has a complete, private copy of that repository and can work independently. The work is distributed, yet it is coordinated through a central, shared repository. The repository model and the development model are orthogonal characteristics.
A Word About Servers
The word “server” gets used liberally and loosely for a variety of meanings. Neither Git nor this book will be an exception, so let’s clarify some aspects of what a server may or may not be, might or might not do, and just how Git might use one.
Technically, Git doesn’t need a server. In contrast to other VCSs, where a centralized server is often required, there is no need to hang onto the mindset that one is required to host Git repositories.
Having a server in the context of a Git repository is often little more than establishing a convenient, fixed, or known location from which repositories are obtained or updates are exchanged. The Git server might also provide some form of authentication or access control.
Git is happy to exchange files directly with a peer repository on the same machine without the need for some server to broker the deal, or with different machines via a variety of protocols none of which enforces a superior server to exist.
Instead, the word “server” here is more loose. On one hand, it may be just “some other computer willing to interact with us.” On the other hand, it could be some rack-mounted, highly available, well-connected, centralized server with a lot of computational power. So, this whole notion of setting up a server needs to be understood in the context of “if that’s how you want to do it.” You be the judge of your requirements here.
Publishing Repositories
Whether you are setting up an open source development environment in which many people across the Internet might develop a project or establishing a project for internal development within a private group, the mechanics of collaboration are essentially the same. The main difference between the two scenarios is the location of the repository and access to it.
Note
The phrase “commit rights” is really sort of a misnomer in Git. Git doesn’t try to manage access rights, leaving that issue to other tools, such as SSH, which are more suited to the task. You can always commit in any repository to which you have (Unix) access, either via SSH and cding to that repository, or to which you have direct rwx-mode access.
The concept might better be paraphrased as “Can I update the published repository?” In that expression, you can see the issue is really the question, “Can I push changes to the published repository?”
Earlier, in Referring to Remote Repositories,
you were cautioned about using the remote repository URL form /path/to/repo.git because it might exhibit
problems characteristic of repositories that use shared files. On the
other hand, setting up a common depot containing several similar
repositories is a common situation where you would want to use a shared,
underlying object store. In this case, you expect the repositories to be
monotonically increasing in size without objects and refs being removed
from them. This situation can benefit from large-scale sharing of the
object store by many repositories, thus saving tremendous volumes of disk
space. To achieve this space savings, consider using the
--reference , the
repository--local, or the --shared options during the
initial bare repository clone setup step for your published
repositories.
In any situation where you publish a repository, we strongly advise that you publish a bare one.
Repositories with Controlled Access
As mentioned earlier in the chapter, it might be sufficient for your project to publish a bare repository in a known location on a filesystem inside your organization that everyone can access.
Naturally, access in this context means that all developers can see the filesystem on their machines and have traditional Unix ownership and read/write permissions. In these scenarios, using a filename URL such as /path/to/Depot/project.git or file://path/to/Depot/project.git might suffice. Although the performance might be less than ideal, an NFS-mounted filesystem can provide such sharing support.
Slightly more complex access is called for if multiple development machines are used. Within a corporation, for example, the IT department might provide a central server for the repository depot and keep it backed up. Each developer might then have a desktop machine for development. If direct filesystem access such as NFS is not available, you could use repositories named with SSH URLs, but this still requires each developer to have an account on the central server.
In the following example, the same repository published in /tmp/Depot/public_html.git earlier in this chapter is accessed by a developer who has SSH access to the hosting machine:
desktop$desktop$cd /tmpgit clone ssh://example.com/tmp/Depot/public_html.gitInitialize public_html/.git Initialized empty Git repository in /tmp/public_html/.git/ [email protected]'s password: remote: Counting objects: 27, done. Receiving objects: 100% (27/27), done.objects: 3% (1/27) Resolving deltas: 100% (7/7), done. remote: Compressing objects: 100% (23/23), done. remote: Total 27 (delremote: ta 7), reused 0 (delta 0)
When that clone is made, it records the source repository using
the following URL: ssh://example.com/tmp/Depot/public_html.git.
Similarly, other commands such as git fetch and git push can now be used across the network:
desktop$ git push
[email protected]'s password:
Counting objects: 5, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 385 bytes, done.
Total 3 (delta 1), reused 0 (delta 0)
To ssh://example.com/tmp/Depot/public_html.git
55c15c8..451e41c master -> masterIn both of these examples, the password requested is the normal Unix login password for the remote hosting machine.
Tip
If you need to provide network access with authenticated developers but are not willing to provide login access to the hosting server, check out the Gitolite project. Start here:
$ git clone git://github.com/sitaramc/gitoliteAgain, depending on the desired scope of access, such SSH access to machines may be entirely within a group or corporate setting or may be available across the entire Internet.
Repositories with Anonymous Read Access
If you want to share code, then you’ll probably want to set up a hosting server to publish repositories and allow others to clone them. Anonymous, read-only access is often all that developers need to clone or fetch from these repositories. A common and easy solution is to export them using git-daemon and also perhaps an HTTP daemon.
Again, the actual realm across which you can publish your repository is as limited or as broad as access to your HTTP pages or your git-daemon. That is, if you host these commands on a public-facing machine, then anyone can clone and fetch from your repositories. If you put it behind a corporate firewall, only those people inside the corporation will have access (in the absence of security breaches).
Publishing repositories using git-daemon
Setting up git-daemon allows you to export your repositories using the Git-native protocol.
You must mark repositories as “OK to be exported” in some way. Typically, this is done by creating the file git-daemon-export-ok in the top-level directory of the bare repository. This mechanism gives you fine-grained control over which repositories the daemon can export.
Instead of marking each repository individually, you can
also run git-daemon with the
--export-all option to publish all identifiable (by
having both an objects and a
refs subdirectory) repositories
found in its list of directories. There are
many git-daemon options that limit
and configure which repositories will be exported.
One common way to set up the git-daemon on a server is to enable it as an inetd service. This involves ensuring that your /etc/services has an entry for Git. The default port is 9418, though you may use any port you like. A typical entry might be:
git 9418/tcp # Git Version Control System
Once you add that line to /etc/services, you must set up an entry in your /etc/inetd.conf to specify how the git-daemon should be invoked.
A typical entry might look like this:
# Place on one long line in /etc/inetd.conf
git stream tcp nowait nobody /usr/bin/git-daemon
git-daemon --inetd --verbose --export-all
--base-path=/pub/gitUsing xinetd instead of inetd, place a similar configuration in the file /etc/xinetd.d/git-daemon:
# description: The git server offers access to git repositories
service git
{
disable = no
type = UNLISTED
port = 9418
socket_type = stream
wait = no
user = nobody
server = /usr/bin/git-daemon
server_args = --inetd --export-all --base-path=/pub/git
log_on_failure += USERID
}You can make it look as if repositories are located on separate hosts, even though they’re just in separate directories on a single host, through a trick supported by git-daemon. The following example entry allows a server to provide multiple, virtually hosted Git daemons:
# Place on one long line in /etc/inetd.conf
git stream tcp nowait nobody /usr/bin/git-daemon
git-daemon --inetd --verbose --export-all
--interpolated-path=/pub/%H%DIn the command shown, git-daemon will fill in the %H with a fully qualified hostname and
%D with the repository’s directory
path. Because %H can be a logical
hostname, different sets of repositories can be offered by one
physical server.
Typically, an additional level of directory structure, such as
/software or /scm, is used to organize the advertised
repositories. If you combine the
--interpolated-path=/pub/%H%D with a /software repository directory path, then
the bare repositories to be published will be physically present on
the server, in directories such as:
/pub/git.example.com/software/
/pub/www.example.org/software/You would then advertise the availability of your repositories at URLs such as:
git://git.example.com/software/repository.gitgit://www.example.org/software/repository.git
Here, the %H is replaced by
the host git.example.com or
www.example.org and the %D is replaced by full repository names,
such as /software/.repository.git
The important point of this example is that it shows how a single git-daemon can be used to maintain and publish multiple, separate collections of Git repositories that are physically hosted on one server but presented as logically separate hosts. Those repositories available from one host might be different from those offered by a different host.
Publishing repositories using an HTTP daemon
Sometimes, an easier way to publish repositories with anonymous read access is to simply make them available through an HTTP daemon. If you also set up gitweb, then visitors can load a URL into their web browsers, see an index listing of your repository, and negotiate using familiar clicks and the browser Back button. Visitors do not need to run Git in order to download files.
You will need to make one configuration adjustment to your bare Git repository before it can be properly served by an HTTP daemon: enable the hooks/post-update option as follows:
$cd /path/to/bare/repo.git$mv hooks/post-update.sample hooks/post-update
Verify that the post-update script is executable, or use chmod 755 on it just to be sure. Finally, copy that bare Git repository into a directory served by your HTTP daemon. You can now advertise that your project is available using a URL such as:
http://www.example.org/software/repository.gitPublishing a repository using Smart HTTP
Publishing a repository via the newer, so-called Smart HTTP mechanism is pretty simple in principle, but you may want to consult the full online documentation for the process as found in the manual page of the git-http-backend command. What follows here is a simplified extraction of some of that material that should get you started.
First, this setup is really geared for use with Apache. Thus,
the examples that follow show how to modify Apache configuration
files. On a Ubuntu system, these are found in /etc/apache2. Second, some mapping from
your advertised repository names to the repository layout on the disk
as made available to Apache needs to be defined. As with the git-http-backend documentation, the mapping
here makes http://$hostname/git/foo/bar.git correspond
to /var/www/git/foo/bar.git under
Apache’s file view. Third, several Apache modules are required and
must be enabled: mod_cgi, mod_alias, and mod_env.
Define some variables and a script alias that points to the git-http-backend command like this:
SetEnv GIT_PROJECT_ROOT /var/www/git
SetEnv GIT_HTTP_EXPORT_ALL
ScriptAlias /git/ /usr/libexec/git-core/git-http-backend/The location of your git-http-backend may be different. For example, Ubuntu places it in /usr/lib/git-core/git-http-backend.
Now you have a choice: you can allow anonymous read access but require authenticated write access to your repository, or you can require authentication for read and write.
For anonymous read access, set up a LocationMatch directive:
<LocationMatch "^/git/.*/git-receive-pack$">
AuthType Basic
AuthName "Git Access"
Require group committers
...
</LocationMatch>For authenticated read access, set up a Location directive for the repository or a
parent directory of the repository:
<Location /git/private>
AuthType Basic
AuthName "Private Git Access"
Require group committers
...
</Location>Further recipes exist within the manual page to set up coordinated gitweb access, and show how to serve multiple repositories namespaces and configure accelerated access to static pages.
Publishing via Git and HTTP daemons
Although using a web server and browser is certainly convenient, think carefully about how much traffic you plan to handle on your server. Development projects can become large, and HTTP is less efficient than the native Git protocol.
You can provide both HTTP and Git daemon access, but it might
take some adjusting and coordination between your Git daemon and your
HTTP daemon. Specifically, it may require a mapping with the
--interpolated-path option to git-daemon and an Alias option to Apache to provide seamless
integration of the two views of the same data. Further details on the
--interpolated-path are available in the git daemon manual page, whereas details
about the Apache Alias option can
be found in the Apache documentation or its configuration file,
/etc/apache2/mods-available/alias.conf.
Repositories with Anonymous Write Access
Technically, you may use the Git native protocol URL
forms to allow anonymous write access into repositories served by
git-daemon. To do so requires you to
enable the receivepack option in the
published repositories:
[daemon]
receivepack = trueYou might do this on a private LAN where every developer is trusted, but it is not considered best practice. Instead, you should consider tunneling your Git push needs over an SSH connection.
Publishing Your Repository to GitHub
We’ll assume you have a repository with some commits and have already established a GitHub account. With these prerequisites established, the next step is creating a repository to accept your commits at GitHub.
- Creating the GitHub Repository
Sign in to GitHub and begin at your personal dashboard. You can access this personal dashboard at any time by clicking the GitHub logo. Next, click the “New repository” button.
- Supplying the New Repository Name
The only required field is the “Project Name” and it will be the last part of the URL at which you’ll access your repository. For example, if your GitHub username was
jonl, a Project Name ofgitbookwould appear athttps://github.com/jonl/gitbook.- Choosing the Access Control Level
There are two choices for access control at this juncture. One is to allow anyone to access the repository’s contents. The other is to specify a list of GitHub users that are permitted to access it. GitHub, in its mission to foster more open source projects, allows for unlimited public repositories at no cost. Closed repositories, being more likely business focused, are charged on a monthly or annual subscription plan basis. Click “Create repository” to continue.
- Initializing the Repository
The repository has now been created, but doesn’t yet have any contents. GitHub provides users with stepwise instructions from which we’ll follow the “Existing Git Repo” process. At a shell prompt in your local existing Git repository, we’ll add the GitHub remote and push the contents.
- Adding the Remote
First, type git remote add origin
githubrepoaddress. This registers a remote destination to which Git can push contents. The specificgithubrepoaddressand initialization instructions are repeatedly provided on the GitHub page for the project after creating the repository but before it has any contents.- Pushing the Contents
Second, type git push -u origin master if you wish to selectively publish your
masterbranch. If you wish to publish all your local branches and tags, you can alternatively (one time only) issue the git push --mirror origin command. Subsequent invocations would less desirably push remote-tracking branches that are not intended to be pushed.- View the site
That’s all there is to publishing a Git repository to GitHub. You can now refresh the project page and, in place of the initialization instructions, the project’s README and directory and file structure will be shown in a web-navigable view.
Repository Publishing Advice
Before you go wildly setting up server machines and hosting services just to host Git repositories, consider what your needs really are and why you want to offer Git repositories. Perhaps your needs are already satisfied by existing companies, websites, or services.
For private code or even public code where you place a premium on the value of service, you might consider using a commerical Git hosting service.
If you are offering an open source repository and have minimal service needs or expectations, there are a multitude of Git hosting services available. Some offer upgrades to supported services as well.
The more complicated situations arise when you have private code that you want to keep in house and therefore must set up and maintain your own master depot for repository hosting. Oh, and don’t forget your own backups!
In this case, the usual approach is to use the Git-over-SSH
protocol and require all users of the repository to have SSH access to the
hosting server. On the server itself, a semi-generic user account and
group (e.g., git or gituser) are usually created. All repositories
are group owned by this user and typically live in some filespace (e.g.,
/git, /opt/git, or /var/git) set aside for this purpose. Here’s
the key: that directory must be owned by your gituser group, be writable by that group, and it
must have the sticky group bit set.
Now, when you want to create a new, hosted repository called
newrepo.git on your server, just
ssh into the server and do this:
$ssh git.my-host.example.com$cd /git$mkdir newrepo.git$cd newrepo.git$git init --shared --bare
Those last four commands can be simplified as follows:
$ git --git-dir /git/newrepo.git init --sharedAt this point, the bare repository structure exists, but it remains empty. The important aspect of this repository, though, is that it is now receptive to a push of initial content from any user authorized to connect with the server.
# from some client
$ cd /path/to/existing/initial/repo.git
$ git push git+ssh://git.my-host.example.com/git/newrepo.git masterThe whole process of executing that git init on the server in such a way that subsequent pushes will work is at the heart of the Git web hosting services. That command is essentially what happens when you click on the GitHub “New Repo” button.
Repository Structure
The Shared Repository Structure
Some VCSs use a centralized server to maintain a repository. In this model, every developer is a client of the server, which maintains the authoritative version of the repository. Given the server’s jurisdiction, almost every versioning operation must contact the server to obtain or update repository information. Thus, for two developers to share data, all information must pass through the centralized server; no direct sharing of data between developers is possible.
With Git, in contrast, a shared, authoritative, and centralized repository is merely a convention. Each developer still has a clone of the depot’s repository, so there’s no need for every request or query to go to a centralized server. For instance, simple log history queries can be made privately and offline by each developer.
One of the reasons that some operations can be performed locally is that a checkout retrieves not just the particular version you ask for, the way most centralized VCSs operate, but the entire history. Hence, you can reconstruct any version of a file from the local repository.
Furthermore, nothing prevents a developer from either establishing an alternate repository and making it available on a peer-to-peer basis with other developers, or from sharing content in the form of patches and branches.
In summary, Git’s notion of a shared, centralized repository model is purely one of social convention and agreement.
Distributed Repository Structure
Large projects often have a highly distributed development model consisting of a central, single, yet logically segmented repository. Although the repository still exists as one physical unit, logical portions are relegated to different people or teams that work largely or wholly independently.
Note
When it’s said that Git supports a distributed repository model, this doesn’t mean that a single repository is broken up into separate pieces and spread around many hosts. Instead, the distributed repository is just a consequence of Git’s distributed development model. Each developer has her own repository that is complete and self-contained. Each developer and her respective repository might be spread out and distributed around the network.
How the repository is partitioned or allocated to different maintainers is largely immaterial to Git. The repositories might have a deeply nested directory structure or they might be more broadly structured. For example, different development teams might be responsible for certain portions of a code base along submodule, library, or functional lines. Each team might raise a champion to be the maintainer, or steward, of its portion of the code base, and agree as a team to route all changes through this appointed maintainer.
The structure may even evolve over time as different people or groups become involved in the project. Furthermore, a team could likely form intermediate repositories that contain combinations of other repositories, with or without further development. There may be specific stable or release repositories, for instance, each with an attendant development team and a maintainer.
It may be a good idea to allow the large-scale repository iteration and dataflow to grow naturally and according to peer review and suggestion rather than impose a possibly artificial layout in advance. Git is flexible, so if development in one layout or flow doesn’t seem to work, it is quite easy to change it to a better one.
How the repositories of a large project are organized, or how they coalesce and combine, is again largely immaterial to the workings of Git; Git supports any number of organizational models. Remember that the repository structure is not absolute. Moreover, the connection between any two repositories is not prescribed. Git repositories are peers.
So how is a repository structure maintained over time if no technical measures enforce the structure? In effect, the structure is a web of trust for the acceptance of changes. Repository organization and dataflow between repositories is guided by social or political agreements.
The question is, “Will the maintainer of a target repository allow your changes to be accepted?” Conversely, do you have enough trust in the source repository’s data to fetch it into your own repository?
Repository Structure Examples
The Linux Kernel project is the canonical example of a highly distributed repository and development process. In each Linux Kernel release, there are roughly 1,000 to 1,300 individual contributors from approximately 200 companies. Over the last 20 kernel releases (2.6.24 through 3.3), the corp of developers averaged just over 10,000 commits per release. Releases were made on an average 82-day cycle. That’s between four and six commits per hour, every development hour, somewhere on the planet. The rate-of-change trend is upward still.[27]
Although Linus Torvalds does maintain an official repository at the top of the heap that most people consider authoritative, there are still many, many derived second-tier repositories in use. For example, many of the Linux distribution vendors take Linus’s official tagged release, test it, apply bug fixes, tweak it for their distribution, and publish it as their official release. (With any luck, bug fixes are sent back and applied to Linus’s Linux repository so that all may benefit.)
During a kernel development cycle, hundreds of
repositories are published and moderated by hundreds of maintainers and
used by thousands of developers to gather changes for the release. The
main kernel website, http://kernel.org/, alone publishes about 500
Linux Kernel–related repositories with roughly 150 individual
maintainers.
There are certainly thousands, perhaps tens of thousands, of clones of these repositories around the world that form the basis of individual contributor patches or uses.
Short of some fancy snapshot technology and some statistical analysis, there isn’t really a good way to tell how all these repositories interconnect. It is safe to say it is a mesh, or network, that is not strictly hierarchical at all.
Curiously, though, there is a sociological drive to get patches and changes into Linus’s repository, thus effectively treating it like it is the top of the heap! If Linus himself had to accept each and every patch or change one at a time into his repository, there would simply be no way he could keep up. Linus, it is rumored, just doesn’t scale up well. Remember, changes are collectively going into his tree at a rate of about one every 10 to 15 minutes throughout a release’s entire development cycle.
It is only through the maintainers—who moderate, collect, and apply patches to subrepositories—that Linus can keep up at all. It is as if the maintainers create a pyramid-like structure of repositories that funnel patches toward Linus’s conventional master repository.
In fact, below the maintainers but still near the top of the Linux repository structure are many sub-maintainers and individual developers who act in the role of maintainer and developer peer as well. The Linux Kernel effort is a large, multilayered mesh of cooperating people and repositories.
The point isn’t that this is a phenomenally large code base that exceeds the grasp of a few individuals or teams. The point is that those many teams are scattered around the world and yet manage to coordinate, develop, and merge a common code base toward a fairly consistent long-term goal, all using Git’s facilities for distributed development.
At the other end of the spectrum, Freedesktop.org
development is done entirely using a shared, centralized repository
model powered by Git. In this development model, each developer is
trusted to push changes straight into a repository, as found on git.freedesktop.org.
The X.org project itself has roughly 350 X-related
repositories available on gitweb.freedesktop.org, with hundreds more for
individual users. The majority of the X-related repositories are various
submodules from the entire X project, representing a functional
breakdown of applications, X servers, different fonts, and so on.
Individual developers are also encouraged to create branches for features that are not ready for a general release. These branches allow the changes (or proposed changes) to be made available for other developers to use, test, and improve. Eventually, when the new feature branches are ready for general use, they are merged into their respective mainline development branches.
A development model that allows individual developers to directly push changes into a repository runs some risk, though. Without any formal review process prior to a push, it is possible for bad changes to be quietly introduced into a repository and to go unnoticed for quite some time.
Mind you, there is no real fear of losing data or of being unable to recover a good state again because the complete repository history is still available. The issue is that it would take time to discover the problem and correct it.
As Keith Packard wrote:[28]
We are slowly teaching people to post patches to the xorg mailing list for review, which happens sometimes. And, sometimes we just back stuff out. Git is robust enough that we never fear losing data, but the state of the top of the tree isn’t always ideal.
Living with Distributed Development
Changing Public History
Once you have published a repository from which others might make a clone, you should consider it static and refrain from rewriting the history of any branch. Although this is not an absolute guideline, avoiding rewinds and alterations of published history simplifies the life of anyone who clones your repository.
Let’s say you publish a repository that has a branch with commits
A, B, C, and
D. Anyone who clones your repository
gets those commits. Suppose Alice clones your repository and heads off
to do some development based on your branch.
In the meantime you decide, for whatever reason, to fix something
in commit C. Commits A and B
remain the same, but starting with commit C, the branch’s notion of commit history
changes. You could slightly alter C
or make some totally new commit, X.
In either case, republishing the repository leaves the commits A and B as
they were but will now offer, say, X
and then Y instead of C and D.
Alice’s work is now greatly affected. Alice cannot send you
patches, make a pull request, or push her changes to your repository
because her development is based on commit D.
Patches won’t apply because they’re based on commit D. Suppose Alice issues a pull request and you
attempt to pull her changes; you may be able to fetch them into your
repository (depending on your tracking branches for Alice’s remote
repository), but the merges will almost certainly have conflicts. The
failure of this push is due to a non–fast-forward push problem.
In short, the basis for Alice’s development has been altered. You have pulled the commit rug out from underneath her development feet.
The situation is not irrecoverable, though. Git can help Alice, especially if she uses the git rebase --onto command to relocate her changes onto your new branch after fetching the new branch into her repository.
Also, there are times when it is appropriate to have a
branch with a dynamic history. For example, within the Git repository
itself there is a so-called proposed updates branch, pu, which is specifically labeled and
advertised as being rewound, rebased, or rewritten frequently. You, as a
cloner, are welcome to use that branch as the basis for your
development, but you must remain conscious of the branch’s purpose and
take special effort to use it effectively.
So why would anyone publish a branch with a dynamic commit history? One common reason is specifically to alert other developers about possible and fast-changing directions some other branch might take. You can also create such a branch for the sole purpose of making available, even temporarily, a published changeset that other developers can use.
Separate Commit and Publish Steps
One of the clear advantages of a distributed VCS is the separation of commit and publish. A commit just saves a state in your private repository; publishing through patches or push/pull makes the change public, which effectively freezes the repository history. Other VCSs, such as CVS or SVN, have no such conceptual separation. To make a commit, you must publish it simultaneously.
By making commit and publish separate steps, a developer is much more likely to make precise, mindful, small, and logical steps with patches. Indeed, any number of small changes can be made without affecting any other repository or developer. The commit operation is offline in the sense that it requires no network access to record positive, forward steps within your own repository.
Git also provides mechanisms for refining and improving commits into nice, clean sequences prior to making them public. Once you are ready, the commits can be made public in a separate operation.
No One True History
Development projects within a distributed environment have a few quirks that might not be obvious at first. And although these quirks might initially be confusing and their treatment often differs from other nondistributed VCSs, Git handles them in a clear and logical manner.
As development takes place in parallel among different developers of a project, each has created what he believes to be the correct history of commits. As a result, there is my repository and my commit history, your repository and your commit history, and possibly several others being developed, simultaneously or otherwise.
Each developer has a unique notion of history, and each history is correct. There is no one true history. You cannot point to one and say: “This is the real history.”
Presumably, the different development histories have formed for a reason, and ultimately the various repositories and different commit histories will be merged into one common repository. After all, the intent is likely to be advancement toward a common goal.
When various branches from the different repositories are merged, all of the variations are present. The merged result states, effectively, “The merged history is better than any one independently.”
Git expresses this history ambivalence toward branch variations when it traverses the commit DAG. So if Git, when trying to linearize the commit sequence, reaches a merge commit, then it must select one branch or the other first. What criteria would it use to favor or select one branch over another? The spelling of the author’s last name? Perhaps the time stamp of a commit? That might be useful.
Even if you decide to use time stamps and agree to use Coordinated Universal Time (UTC) and extremely precise values, it doesn’t help. Even that recipe turns out to be completely unreliable! (The clocks on a developer’s computer can be wrong either intentionally or accidentally.)
Fundamentally, Git doesn’t care what came first. The only real, reliable relationship that can be established between commits is the direct parent relationship recorded in the commit objects. At best, the time stamps offer a secondary clue, usually accompanied by various heuristics to allow for errors such as unset clocks.
In short, neither time nor space operates in well-defined ways, so Git must allow for the effects of quantum physics.
Knowing Your Place
When participating in a distributed development project, it is important to know how you, your repository, and your development efforts fit into the larger picture. Besides the obvious potential for development efforts in different directions and the requirement for basic coordination, the mechanics of how you use Git and its features can greatly affect how smoothly your efforts align with other developers working on the project.
These issues can be especially problematic in a large-scale distributed development effort, as is often found in open source projects. By identifying your role in the overall effort and understanding who the consumers and producers of changes are, many of the issues can be easily managed.
Upstream and Downstream Flows
There isn’t a strict relationship between two repositories that have been cloned one from the other. However, it’s common to refer to the parent repository as being “upstream” from the new, cloned repository. Reflexively, the new, cloned repository is often described as being “downstream” from the original parent repository.
Furthermore, the upstream relationship extends “up” from the parent repository to any repository from which it might have been cloned. It also extends “down” past your repository to any that might be cloned from yours.
However, it is important to recognize that this notion of upstream and downstream is not directly related to the clone operation. Git supports a fully arbitrary network between repositories. New remote connections can be added and your original clone remote can be removed to create arbitrary new relationships between repositories.
If there is any established hierarchy, it is purely one of convention. Bob agrees to send his changes to you; in turn, you agree to send your changes on to someone further upstream; and so forth.
The important aspect of the repository relationship is how data is exchanged between them. That is, any repository to which you send changes is usually considered upstream of you. Similarly, any repository that relies on yours for its basis is usually considered downstream of yours.
It’s purely subjective but conventional. Git itself doesn’t care and doesn’t track the stream notion in any way. Upstream and downstream simply help us visualize where patches are going.
Of course, it’s possible for repositories to be true peers. If two developers exchange patches or push and fetch from each other’s repositories, then neither is really upstream or downstream from the other.
The Maintainer and Developer Roles
Two common roles are the maintainer and the developer. The maintainer serves primarily as an integrator or moderator, and the developer primarily generates changes. The maintainer gathers and coordinates the changes from multiple developers and ensures that all are acceptable with respect to some standard. In turn, the maintainer makes the whole set of updates available again. That is, the maintainer is also the publisher.
The maintainer’s goal should be to collect, moderate, accept or reject changes, and then ultimately publish branches that project developers can use. To ensure a smooth development model, maintainers should not alter a branch once it has been published. In turn, a maintainer expects to receive changes from developers that are relevant and that apply to published branches.
A developer’s goal, beyond improving the project, is to get her changes accepted by the maintainer. After all, changes kept in a private repository do no one else any good. The changes need to be accepted by the maintainer and made available for others to use and exploit. Developers need to base their work on the published branches in the repositories that the maintainer offers.
In the context of a derived clone repository, the maintainer is usually considered to be upstream from developers.
Because Git is fully symmetric, there is nothing to prevent a developer from considering herself a maintainer for other developers further downstream. But she must now understand that she is in the middle of both an upstream and a downstream dataflow and must adhere to the maintainer and developer contract (see the next section) in this dual role.
Because this dual or mixed-mode role is possible, upstream and downstream is not strictly correlated to being a producer or consumer. You can produce changes with the intent of them going either upstream or downstream.
Maintainer–Developer Interaction
The relationship between a maintainer and a developer is often loose and ill-defined, but there is an implied contract between them. The maintainer publishes branches for the developer to use as her basis. Once published, though, the maintainer has an unspoken obligation not to change the published branches because this would disturb the basis upon which development takes place.
In the opposite direction, the developer, by using the published branches as her basis, ensures that when her changes are sent to the maintainer for integration they apply cleanly without problems, issues, or conflicts.
It may seem as if this makes for an exclusive, lock-step process. Once published, the maintainer can’t do anything until the developer sends in changes. And then, after the maintainer applies updates from one developer, the branch will necessarily have changed and thus will have violated the “won’t change the branch” contract for some other developers. If this were true then truly distributed, parallel, and independent work could never really take place.
Thankfully, it is not that grim at all! Instead, Git is able to look back through the commit history on the affected branches, determine the merge basis that was used as the starting point for a developer’s changes, and apply them even though other changes from other developers may have been incorporated by the maintainer in the meantime.
With multiple developers making independent changes and with all of them being brought together and merged into a common repository, conflicts are still possible. It is up to the maintainer to identify and resolve such problems. The maintainer can either resolve these conflicts directly or reject changes from a developer if they would create conflicts.
Role Duality
There are two basic mechanisms for transferring commits between an upstream and a downstream repository.
The first uses git push or git pull to directly transfer commits, whereas the second uses git format-patch and git am to send and receive representations of commits. The method that you use is primarily dictated by agreement within your development team and, to some extent, direct access rights as discussed in Chapter 12.
Using git format-patch and git am to apply patches achieves the exact same blob and tree object content as if the changes had been delivered via a git push or incorporated with a git pull. However, the actual commit object will be different because the metadata information for the commit will be different between a push or pull and a corresponding application of a patch.
In other words, using push or pull to propagate a change from one repository to another copies that commit exactly, whereas patching copies only the file and directory data exactly. Furthermore, push and pull can propagate merge commits between repositories. Merge commits cannot be sent as patches.
Because it compares and operates on the tree and blob objects, Git is able to understand that two different commits for the same underlying change in two different repositories, or even on different branches within the same repository, really represent the same change. Thus, it is no problem for two different developers to apply the same patch sent via email to two different repositories. As long as the resulting content is the same, Git treats the repositories as having the same content.
Let’s see how these roles and dataflows combine to form a duality between upstream and downstream producers and consumers.
- Upstream Consumer
An upstream consumer is a developer upstream from you who accepts your changes either as patch sets or as pull requests. Your patches should be rebased to the consumer’s current branch
HEAD. Your pull requests should either be directly mergeable or already merged by you in your repository. Merging prior to the pull ensures that conflicts are resolved correctly by you, relieving the upstream consumer of that burden. This upstream consumer role could be a maintainer who turns around and publishes what he has just consumed.- Downstream Consumer
A downstream consumer is a developer downstream from you who relies on your repository as the basis for work. A downstream consumer wants solid, published topic branches. You shouldn’t rebase, modify, or rewrite the history of any published branch.
- Upstream Producer/Publisher
An upstream publisher is a person upstream from you who publishes repositories that are the basis for your work. This is likely to be a maintainer with the tacit expectation that he will accept your changes. The upstream publisher’s role is to collect changes and publish branches. Again, those published branches should not have their histories altered, given that they are the basis for further downstream development. A maintainer in this role expects developer patches to apply and expects pull requests to merge cleanly.
- Downstream Producer/Publisher
A downstream producer is a developer downstream from you who has published changes either as a patch set or as a pull request. The goal of a downstream producer is to have changes accepted into your repository. A downstream producer consumes topic branches from you and wants those branches to remain stable, with no history rewrites or rebases. Downstream producers should regularly fetch updates from upstream and should also regularly merge or rebase development topic branches to ensure they apply to the local upstream branch
HEADs. A downstream producer can rebase her own local topic branches at any time, because it doesn’t matter to an upstream consumer that it took several iterations for this developer to make a good patch set that has a clean, uncomplicated history.
Working with Multiple Repositories
Your Own Workspace
As the developer of content for a project using Git, you should create your own private copy, or clone, of a repository to do your development. This development repository should serve as your own work area where you can make changes without fear of colliding with, interrupting, or otherwise interfering with another developer.
Furthermore, because each Git repository contains a complete copy of the entire project, as well as the entire history of the project, you can feel free to treat your repository as if it is completely and solely yours. In effect, it actually is!
One benefit of this paradigm is that it allows each developer complete control within her working directory area to make changes to any part, or even to the whole system, without worrying about interaction with other development efforts. If you need to change a part, you have the part and can change it in your repository without affecting other developers. Likewise, if you later realize that your work is not useful or relevant, then you can throw it away without affecting anyone else or any other repository.
As with any software development, this is not an endorsement to conduct wild experimentation. Always consider the ramifications of your changes, because ultimately you may need to merge your changes into the master repository. It will then be time to pay the piper, and any arbitrary changes may come back to haunt you.
Where to Start Your Repository
Faced with a wealth of repositories that ultimately contribute to one project, it may seem difficult to determine where you should begin your development. Should your contributions be based on the main repository directly, or perhaps on the repository where other people are focused on some particular feature? Or maybe a stable branch of a release repository somewhere?
Without a clear sense of how Git can access, use, and alter repositories, you may be caught in some form of the “can’t get started for fear of picking the wrong starting point” dilemma. Or perhaps you have already started your development in a clone based on some repository you picked but now realize that it isn’t the right one. Sure, it’s related to the project and may even be a good starting point, but maybe there is some missing feature found in a different repository. It may even be hard to tell until well into your development cycle.
Another frequent starting point dilemma comes from a need for project features that are being actively developed in two different repositories. Neither of them is, by itself, the correct clone basis for your work.
You could just forge ahead with the expectation that your work and the work in the various repositories will all be unified and merged into one master repository. You are certainly welcome to do so, of course. But remember that part of the gain from a distributed development environment is the ability to do concurrent development. Take advantage of the fact that the other published repositories with early versions of their work are available.
Another pitfall comes if you start with a repository that is at the cutting edge of development and find that it is too unstable to support your work, or that it is abandoned in the middle of your work.
Fortunately, Git supports a model where you can essentially pick any arbitrary repository from a project as your starting point, even if it is not the perfect one, and then convert, mutate, or augment that repository until it does contain all the right features.
If you later wanted to separate your changes back out to different respective upstream repositories, you may have to make judicious and meticulous use of separate topic branches and merges to keep it all straight.
On the one hand, you can fetch branches from multiple remote repositories and combine them into your own, yielding the right mix of features that are available elsewhere in existing repositories. On the other hand, you can reset the starting point in your repository back to a known stable point earlier in the history of the project’s development.
Converting to a Different Upstream Repository
The first and simplest kind of repository mixing and matching is to switch the basis (usually called the clone origin) repository, the one you regard as your origin and with which you synchronize regularly.
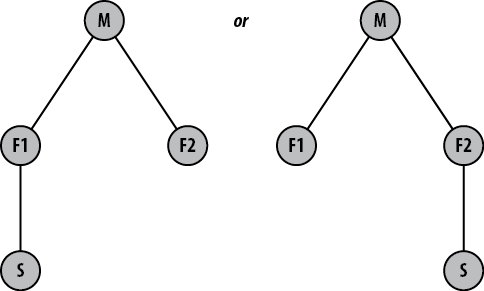
For example, suppose you need to work on feature F and you decide to clone your repository from
the mainline, M, as shown in Figure 13-1.
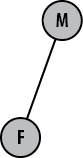
You work for a while before learning that there is a better
starting point closer to what you would really like, but it is in
repository P. One reason you might
want to make this sort of change is to gain functionality or feature
support that is already in repository P.
Another reason stems from longer term planning. Eventually, the
time will come when you need to contribute the development that you have
done in repository F back to some
upstream repository. Will the maintainer of repository M accept your changes directly? Perhaps not.
If you are confident that the maintainer of repository P will accept them, then you should arrange
for your patches to be readily applicable to that repository
instead.
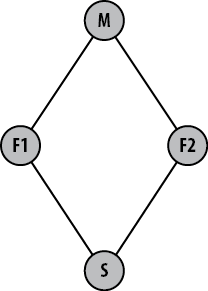
Presumably, P was once cloned
from M, or vice versa, as shown in
Figure 13-2. Ultimately, P and M are
based on the same repository for the same project at some point in the
past.
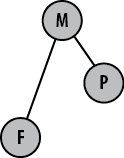
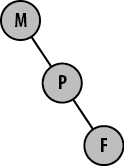
The question often asked is whether repository F, originally based on M, can now be converted so that it is based on
repository P, as shown in Figure 13-3. This is easy to do using
Git, because it supports a peer-to-peer relationship between
repositories and provides the ability to readily rebase branches.
As a practical example, the kernel development for a particular architecture could be done right off of the mainline Linus Kernel repository. But Linus won’t take it. If you started working on, say, PowerPC®[29] changes and did not know that, then you would likely have a difficult time getting your changes accepted.
However, the PowerPC architecture is currently maintained by Ben Herrenschmidt; he is responsible for collecting all PowerPC-specific changes and in turn sending them upstream to Linus. To get your changes into the mainline repository, you must go through Ben’s repository first. You should therefore arrange to have your patches be directly applicable to his repository instead, and it’s never too late to do that.
In a sense, Git knows how to make up the difference from one repository to the next. Part of the peer-to-peer protocol to fetch branches from another repository is an exchange of information stating what changes each repository has or is missing. As a result, Git is able to fetch just the missing or new changes and bring them into your repository.
Git is also able to review the history of the branches and determine where the common ancestors from the different branches are, even if they are brought in from different repositories. If they have a common commit ancestor, then Git can find it and construct a large, unified view of the commit history with all the repository changes represented.
Using Multiple Upstream Repositories
As another example, suppose that the general repository
structure looks like Figure 13-4.
Here, some mainline repository, M,
will ultimately collect all the development for two different features
from repositories F1 and F2.
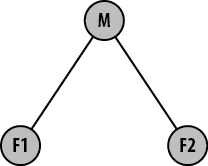
However, you need to develop some super feature, S, that involves using aspects of features
found in only F1 and F2. You could wait until F1 is merged into M and then wait for F2 to also be merged into M. That way, you will then have a repository
with the correct, total basis for your work. But unless the project
strictly enforces some project life cycle that requires merges at known
intervals, there is no telling how long this process might take.
You might start your repository, S, based off of the features found in F1 or, alternatively, off of F2 (see Figure 13-5). However, with Git it is
possible to instead construct a repository, S, that has both F1 and F2
in it; this is shown in Figure 13-6.
In these pictures, it is unclear whether repository S is composed of the entirety of F1 and F2
or just some part of each. In fact, Git supports both scenarios. Suppose
repository F2 has branches F2A and F2B
with features A and B, respectively, as shown in Figure 13-7. If your development
needs feature A, but not B, then you can selectively fetch just that
F2A branch into your repository
S along with whatever part of
F1 is also needed.
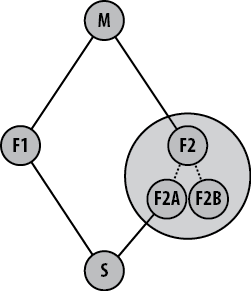
Again, the structure of the Linux Kernel exhibits this property. Let’s say you’re working on a new network driver for a new PowerPC board. You will likely have architecture-specific changes for the board that will need code in the PowerPC repository maintained by Ben. Furthermore, you will likely need to use the Networking Development “netdev” repository maintained by Jeff Garzik. Git will readily fetch and make a union repository with branches from both Ben’s and Jeff’s branches. With both basis branches in your repository, you will then be able to merge them and develop them further.
Forking Projects
Anytime you clone a repository, the action can be viewed as forking the project. Forking is functionally equivalent to “branching” in some other VCSs, but Git has a separate concept called “branching,” so don’t call it that. Unlike a branch, a Git fork doesn’t exactly have a name. Instead, you simply refer to it by the filesystem directory (or remote server, or URL) into which you cloned.
The term “fork” comes from the idea that when you create a fork, you create two simultaneous paths that the development will follow. It’s like a fork in the road of development. As you might imagine, the term “branch” is based on a similar analogy involving trees. There’s no inherent difference between the “branching” and “forking” metaphors—the terms simply capture two intents. Conceptually, the difference is that branching usually occurs within a single repository, whereas forking usually occurs at the whole repository level.
Although you can fork a project readily with Git, doing so may be more of a social or political choice than a technical one. For public or open source projects, having access to a copy or clone of the entire repository, complete with its history, is both an enabler of and a deterrent to forking.
Tip
GitHub.com, an online
Git hosting service, takes this idea to the logical extreme:
everybody’s version is considered a fork, and all
the forks are shown together in the same place.
Isn’t forking a project bad?
Historically, forking a project was often motivated by perceptions of a power grab, a reluctance to cooperate, or the abandonment of a project. A difficult person at the hub of a centralized project can effectively grind things to a halt. A schism may develop between those “in charge” of a project and those who are not. Often, the only perceived solution is to effectively fork a new project. In such a scenario, it may be difficult to obtain a copy of the history of the project and start over.
Forking is the traditional term for what happens when one developer of an open source project becomes unhappy with the main development effort, takes a copy of the source code, and starts maintaining his own version.
Forking, in this sense, has traditionally been considered a negative thing; it means the unhappy developer couldn’t find a way to get what he wanted from the main project. So he goes off and tries to do it better by himself, but now there are two projects that are almost the same. Obviously neither one is good enough for everybody, or one of them would be abandoned. So most open source projects make heroic efforts to avoid forking.
Forking may or may not be bad. On the one hand, perhaps an alternate view and new leadership is exactly what is needed to revitalize a project. On the other hand, it may simply contribute to strife and confusion on a development effort.
Reconciling forks
In contrast, Git tries to remove the stigma of forking. The real problem with forking a project is not the creation of an alternate development path. Every time a developer downloads or clones a copy of a project and starts hacking on it, she has created an alternative development path, if only temporarily.
In his work on the Linux Kernel, Linus Torvalds eventually realized that forking is only a problem if the forks don’t eventually merge back together. Thus, he designed Git to look at forking totally differently: Git encourages forking. But Git also makes it easy for anyone to merge two forks whenever they want.
Technically, reconciling a forked project with Git is facilitated by its support for large-scale fetching and importing one repository into another and for extremely easy branch merging.
Although many social issues may remain, fully distributed repositories seem to reduce tensions by lessening the perceived importance of the person at the center of a project. Because an ambitious developer can easily inherit a project and its complete history, he may feel it is enough to know that, if needed, the person at the center could be replaced and development could still continue!
Forking projects at GitHub
Many people in the software community have a dislike for the phrase “forking.” But if we investigate why, it is because it usually results in infinitely diverging copies of the software. Our focus should not be on the dislike for the concept of forks, but rather on the quantity of divergence before bringing the two lines of code back together again.
Forking at GitHub typically has a far more positive connotation. Much of the site is built around the premise of short-lived forks. Any drive-by developer can make a copy (fork) of a public repository, make code changes she thinks are appropriate, and then offer them back to the core project owner.
The forks offered back to the core project are called “pull requests.” Pull requests afford a visibility to forks and facilitate smart management of these diverging branches. A conversation can be attached to a pull request, thus providing context as to why a request was accepted or returned to sender for additional polish.
Well-maintained projects have the attribute of a frequently maintained pull request queue. Project contributors should process through the pull request queue, either accepting, commenting on, or rejecting all pull requests. This signals a level of care about and active maintenance of the code base and the greater community surrounding the project.
Although GitHub has been intentionally designed to facilitate a good use of forks, it cannot inherently enforce good behavior. The negative form of forking—hostile wrangling of the code base in an isolationist direction—is still possible on GitHub. However, there is a notably low volume of this misbehavior. It can be attributed in large part to the visibility of forks and their potential divergence from the primary code base in the network commit graph.
[27] Kernel statistics from the Linux Foundation
Publications link http://go.linuxfoundation.org/who-writes-linux-2012
for the Linux Foundation report by Jonathan Corbet, et al., titled
“Linux Kernel Development.”
[28] Private email, March 23, 2008.
[29] PowerPC® is a trademark of International Business Machines Corporation in the United States, other countries, or both.