
Chapter 20. Surreal HTML
If you’ve poked around the eg directory in
old Perl distributions, you might have noticed a small program called
travesty. This program takes any regular text file,
processes it, and spews out a curious parody of the original. For
example, here’s a small part of what you get when you feed it this
article:
Travesty achieves this by calling the Perl distribution's eg directory, you may have noticed a small program called travesty. This program takes any regular text file, processes it, and spews out a curious parody of the number of words to generate (lines 81 to 82). Travesty::regurgitate returns a parse tree in turn, calling ref to determine whether the node is any of the tree by returning a value of 0 from the LWP modules, as well as back to Mangler's fill-out form.
Travesty’s output is almost, but not quite, English. Reasonable phrases and sometimes whole sentences pop out, but the whole makes no sense at all. However, if you were to analyze the word frequency of the output, you’d find it identical to the original. Furthermore, if you were to count the frequency of word pairs, you’d find them the same as well. Travesty achieves this by using the original text to create a lookup table of word triples (A,B,C), in which C is indexed on the (A,B) pair. After creating this table, it spews out a parody of the text using a Markov chain: the program chooses a random (A,B) pair and uses the lookup table to pick a C. The new (B,C) pair is now used to look up the fourth word, and this process continues ad infinitum.
This article presents the Mangler, a CGI script that runs any web
page on the Internet through the travesty program and
returns the result.
How It Works
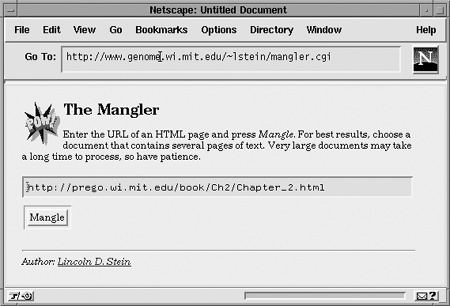
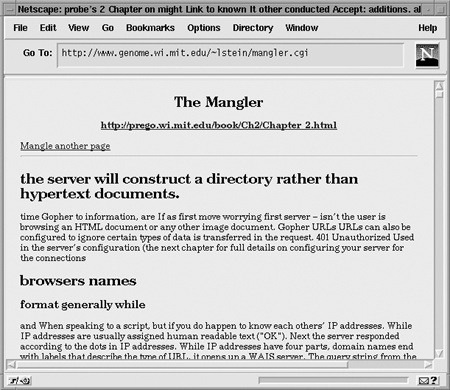
You can see Mangler’s entry page in Figure 20-1. When the user connects, she’s shown a page that prompts her to type in the URL for a web page with text. When she presses the “Mangle” button, the script extracts the text from that page, slices and dices it with the travesty algorithm, and displays the result, shown in Figure 20-2.
The Mangler uses routines from the LWP modules (described in Scripting the Web with LWP), as well as from the CGI.pm module discussed in CGI Programming. Both of these libraries are available from CPAN, and the full source code is shown in Example 20-1.
0 #!/usr/bin/perl
1 # File: mangler.cgi
2
3 use LWP::UserAgent;
4 use HTML::Parse;
5 use HTTP::Status;
6 use CGI qw(:standard :html3);
7 $ICON = "pow.gif";
8
9 srand();
10
11 $url_to_mangle = param('mangle') if request_method( ) eq 'POST';
12
13
14 print header();
15
16 if ($url_to_mangle && mangle($url_to_mangle)) {
17 ; # nothing to do
18 } else {
19 prompt_for_url();
20 }
21
22 # ---------------------------------------------------
23 # THIS SECTION IS WHERE URLs ARE FETCHED AND MANGLED
24 # ---------------------------------------------------
25 sub mangle {
26 my $url = shift;
27 my $agent = new LWP::UserAgent;
28 my $request = new HTTP::Request('GET', $url);
29 my $response = $agent->request($request);
30
31 unless ($response->isSuccess) {
32 print h1('Error Fetching URL'),
33 "An error occurred while fetching the document located at ",
34 a({href=>$url},"$url."),
35 p(),
36 "The error was ",strong(statusMessage($response->code)),".",
37 hr();
38 return undef;
39 }
40
41 # Make sure that it's an HTML document!
42 my $type = $response->header('Content-type'),
43 unless ($type eq 'text/html') {
44 print h1("Document isn't an HTML File!"),
45 "The URL ",a({href=>$url},"$url"),
46 " is a document of type ",em($type),". ",
47 "Please choose an HTML file to mangle.",
48 hr();
49 return undef;
50 }
51
52 print start_html(-title => 'Mangled Document',
53 -xbase => $url),
54 div({ -align => CENTER },
55 h1("The Mangler"),
56 strong( a({-href => $url},$url) )
57 ),
58 p(),
59 a( {-href => self_url() },"Mangle another page"), hr();
60
61 my $parse_tree = parse_html($response->content);
62 $parse_tree->traverse(&swallow);
63 $parse_tree->traverse(®urgitate);
64 $parse_tree->delete();
65 1;
66 }
67
68 sub swallow {
69 my ($node, $start, $depth) = @_;
70 return 1 if ref($node);
71 return &Travesty::swallow($node);
72 }
73
74 sub regurgitate {
75 my ($node, $start, $depth) = @_;
76 if (ref($node)) {
77 return 1 if $node->tag =~ /^(html|head|body)/i;
78 return 0 if $node->isInside('head'),
79 &Travesty::reset() if $start;
80 print $node->starttag if $start;
81 print $node->endtag unless $start;
82 } else {
83 my @words = split(/s+/,$node);
84 print &Travesty::regurgitate(scalar(@words));
85 }
86 1;
87 }
88
89 # ---------------------------------------------------
90 # THIS SECTION IS WHERE THE PROMPT IS CREATED
91 # ---------------------------------------------------
92 sub prompt_for_url {
93 print start_html('The Mangler'),
94 -e $ICON ? img({-src=>$ICON,-align=>LEFT}) : '',
95 h1('The Mangler'), "Enter the URL of an HTML page and press ",
96 em("Mangle. "), "For best results, choose a document containing ",
97 "several pages of text. Very large documents may take a long ",
98 "time to process, so have patience.",
99
100 start_form(),
101 textfield(-name => 'mangle', -size => 60),
102 submit(-value => 'Mangle'),
103 end_form(),
104 hr(),
105 address("Author: ",
106 a( { -href => 'http://www.genome.wi.mit.edu/~lstein/' },
107 'Lincoln D. Stein'),
108 ),
109 end_html();
110 }
111
112 # derived from the code in Perl's eg/ directory
113 package Travesty;
114
115 sub swallow {
116 my $string = shift;
117 $string =~ tr/
/ /s;
118
119 push(@ary, split(/s+/, $string));
120 while ($#ary > 1) {
121 $a = $p;
122 $p = $n;
123 $w = shift(@ary);
124 $n = $num{$w};
125 if ($n eq '') {
126 push(@word, $w);
127 $n = pack('S', $#word);
128 $num{$w} = $n;
129 }
130 $lookup{$a . $p} .= $n;
131 }
132 1;
133 }
134
135 sub reset {
136 my ($key) = each(%lookup);
137 ($a,$p) = (substr($key,0,2), substr($key,2,2));
138 }
139
140 sub regurgitate {
141 my $words = shift;
142 my $result = '';
143 while (--$words >= 0) {
144
145 $n = $lookup{$a . $p};
146 ($foo, $n) = each(%lookup) if $n eq '';
147 $n = substr($n,int(rand(length($n))) & 0177776, 2);
148 $a = $p;
149 $p = $n;
150 ($w) = unpack('S', $n);
151 $w = $word[$w];
152
153 # Most of this formatting is only for <PRE> text.
154 # We'll leave it in for that purpose.
155 $col += length($w) + 1;
156 if ($col >= 65) {
157 $col = 0;
158 $result .= "
";
159 } else {
160 $result .= ' ';
161 }
162 $result .= $w;
163 if ($w =~ /.$/) {
164 if (rand() < .1) {
165 $result .= "
";
166 $col = 80;
167 }
168 }
169
170 }
171 return $result;
172 }Prompting the User
The Mangler uses CGI.pm to parse the CGI parameters and create the
fill-out form. We pull in CGI.pm on line 6 and import both the
standard and HTML3-specific subroutines. On line 11 we look for a
parameter named “mangle.” If defined, we call the
mangle subroutine (line 16). Otherwise, we call
prompt_for_url. As an aside, line 11 shows a
technique for initializing field values in a fill-out form. Only if
the request method is a POST resulting from the user pressing the
“Mangle” button do we actually do the work. Otherwise, if the request
method is a GET, we ignore it and let CGI.pm’s “sticky” behavior
initialize the text field automatically. This allows you to create a
default URL for Mangler by creating a link to it like this one:
<A HREF="/cgi-bin/mangler?mangle=http://www.microsoft.com/"> Mangle Uncle Bill </A>
The prompt_for_url routine is defined in
lines 92 through 110. It follows the form that should be familiar to
readers of my previous columns. Using CGI.pm’s fill-out form and HTML
shortcuts, we create a form containing a single text field labeled
“mangle” and a submit button.
Fetching the Document
The first half of the mangle subroutine
(lines 25–50) does the work of fetching the remote document. We use
the LWP::UserAgent library to create an HTTP request and to retrieve
the document across the net. Several things may go wrong at this
point. For example, the user may have typed in an invalid URL, or the
remote server may be down. On line 31, we check the success status of
the transfer. If the transfer fails, the subroutine prints out the
nature of the error using LWP’s statusMessage
subroutine and returns. When the script sees that the subroutine has
returned a false value, it regenerates the fill-out form by invoking
prompt_for_url again.
Next, we extract the retrieved document’s MIME type from its
Content-type header field. We get the field on line
42 by making a call to the LWP::Response header
method. We can only process HTML files, so if the type turns out not
to be “text/html” we print an error message and again return
false.
If all has gone well so far, we print out a small preamble
before the mangled document itself (lines 52–59). The preamble creates
a title for the page, a descriptive header, and links to the original
document location and to Mangler’s fill-out form. One interesting
question: How do we ensure that the document’s relative URLs and
in-line images work properly? We set the document’s
BASE attribute to the URL of the unmodified
document by passing -xbase to the
start_html method in CGI.pm.
Running the Travesty Algorithm
This is the most interesting part of the program. If we were to
pipe the retrieved HTML through the travesty
generator, it would scramble the tags with the text, creating an
illegible mess. We want to mangle the text of the file but leave its
HTML structure, including tags and in-line images, intact.
We do this using the HTML manipulation routines defined in LWP.
On line 61, we call parse_html, a routine defined
in HTML::Parse. This parses the HTML document and returns a parse tree
object, which we store in the scalar
$parse_tree.
On line 62, we make the first of two calls to the parse tree’s
traverse method. This method performs a depth-first
traversal of the parse tree, calling the subroutine of our choosing
for each element of the tree. In this case, we pass it a reference to
our swallow subroutine (lines 68–72).
swallow examines each node in turn and extracts the
ones that contain straight text, passing them to the travesty
algorithm. There are two types of node to worry about: those that are
branches in the tree (tag pairs surrounding content), and those that
are leaves (plain text). We can distinguish between branches and
leaves by calling Perl’s ref function on the node.
If the node is a reference, it’s a branch and we return immediately.
Otherwise we know that the node is a leaf. We pass its text to the
subroutine Travesty::swallow which breaks up the
string into an array of words using split and adds
them to the travesty algorithm’s lookup table.
The travesty algorithm itself is defined in the last sixty lines of the Mangler. The code here is a slight modification of the original code in Perl’s eg directory, and I won’t go into the details here. It’s worth studying, particularly if you’re interested in entering the Obfuscated Perl contest.
Printing the Mangled Document
The last task is to print out the mangled document. In line 61,
we make the second call to traverse, this time
passing it a reference to the regurgitate
subroutine (lines 74–87). As before, the subroutine examines each node
of the parse tree in turn, calling ref to determine
whether the node is a leaf or a branch. If the node is a branch
corresponding to any of the tags <HTML>,
<HEAD>, or <BODY> we skip it
completely—we’ve already begun to create the HTML document and we
don’t need to repeat these sections. Similarly, we skip the entire
contents of the HTML head section by asking the parse tree’s
isInside method (line 78) whether the node lies
within a <HEAD> tag. If it does, we abort the
traversal of this part of the tree by having
regurgitate return 0. Otherwise, we print out the
tag, using the node’s starttag and
endtag methods to produce the appropriate opening
and closing tags.
Whenever we encounter a leaf node containing text, we pass the
number of desired words we’d like ($words) to
Travesty::regurgitate (lines 83 to 84). It returns
a series of scrambled words, which we simply print out. That’s
it!