
Chapter 7. Cleaning Your Dirty Data
So far in this book we’ve ignored the problem of badly formatted data by using generally well-formatted data sources, dropping data entirely if it deviated from what we were expecting. But often, in web scraping, you can’t be too picky about where you get your data from.
Due to errant punctuation, inconsistent capitalization, line breaks, and misspellings, dirty data can be a big problem on the Web. In this chapter, I’ll cover a few tools and techniques to help you prevent the problem at the source by changing the way you write code, and clean the data once it’s in the database.
Cleaning in Code
Just as you write code to handle overt exceptions, you should practice defensive coding to handle the unexpected.
In linguistics, an n-gram is a sequence of n words used in text or speech. When doing natural-language analysis, it can often be handy to break up a piece of text by looking for commonly used n-grams, or recurring sets of words that are often used together.
In this section, we will focus on obtaining properly formatted n-grams rather than using them to do any analysis. Later, in Chapter 8, you can see 2-grams and 3-grams in action to do text summarization and analysis.
The following will return a list of 2-grams found in the Wikipedia article on the Python programming language:
fromurllib.requestimporturlopenfrombs4importBeautifulSoupdefngrams(input,n):input=input.split(' ')output=[]foriinrange(len(input)-n+1):output.append(input[i:i+n])returnoutputhtml=urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")bsObj=BeautifulSoup(html)content=bsObj.find("div",{"id":"mw-content-text"}).get_text()ngrams=ngrams(content,2)(ngrams)("2-grams count is: "+str(len(ngrams)))
The ngrams function takes in an input string, splits it into a sequence of words (assuming all words are separated by spaces), and adds the n-gram (in this case, a 2-gram) that each word starts into an array.
This returns some genuinely interesting and useful 2-grams from the text:
['of', 'free'], ['free', 'and'], ['and', 'open-source'], ['open-source', 'softwa re']
but also a lot of junk:
['software Outline SPDX Operating', 'system families AROS BSD Darwin eCos FreeDOS GNU Haiku Inferno Linux Mach MINIX OpenS olaris Plan'], ['system families AROS BSD Darwin eCos FreeDOS GNU nHaiku Inferno Linux Mach MINIX OpenSolaris Plan', '9 ReactOS TUD:OS Development Basic'], ['9 ReactOS TUD:OS Development Basic', 'For']
In addition, because there is a 2-gram created for each and every word encountered (except for the last one), there are 7,411 2-grams in the article at the time of this writing. Not a very manageable dataset!
Using some regular expressions to remove escape characters (such as
) and filtering to remove any Unicode characters, we can clean up the output somewhat:
defngrams(input,n):content=re.sub('+'," ",content)content=re.sub(' +'," ",content)content=bytes(content,"UTF-8")content=content.decode("ascii","ignore")(content)input=input.split(' ')output=[]foriinrange(len(input)-n+1):output.append(input[i:i+n])returnoutput
This first replaces all instances of the newline character (or multiple newline characters) with a space, then replaces all instances of multiple spaces in a row with a single space, ensuring that all words have one space between them. Then, escape characters are eliminated by encoding the content with UTF-8.
These steps greatly improve the output of the function, but there are still some issues:
['Pythoneers.[43][44]', 'Syntax'], ['7', '/'], ['/', '3'], ['3', '=='], ['==', ' 2']
At this point, the decisions that need to be made in order to process this data become more interesting. There are a few more rules we can add to get closer to ideal data:
- Single character “words” should be discarded, unless that character is “i” or “a”
- Wikipedia citation marks (numbers enclosed in brackets) should be discarded
- Punctuation marks should be discarded (note: this rule is somewhat of a simplification and will be explored in greater detail in Chapter 9, but is fine for the purpose of this example)
Now that the list of “cleaning tasks” is getting longer, it’s best to move these out and put them in a separate function, cleanInput:
fromurllib.requestimporturlopenfrombs4importBeautifulSoupimportreimportstringdefcleanInput(input):input=re.sub('+'," ",input)input=re.sub('[[0-9]*]',"",input)input=re.sub(' +'," ",input)input=bytes(input,"UTF-8")input=input.decode("ascii","ignore")cleanInput=[]input=input.split(' ')foritemininput:item=item.strip(string.punctuation)iflen(item)>1or(item.lower()=='a'oritem.lower()=='i'):cleanInput.append(item)returncleanInputdefngrams(input,n):input=cleanInput(input)output=[]foriinrange(len(input)-n+1):output.append(input[i:i+n])returnoutput
Note the use of import string and string.punctuation to get a list of all punctuation characters in Python. You can view the output of string.punctuation from a Python terminal:
>>> import string
>>> print(string.punctuation)
!"#$%&'()*+,-./:;<=>?@[]^_`{|}~
By using item.strip(string.punctuation) inside a loop iterating through all words in the content, any punctuation characters on either side of the word will be stripped, although hyphenated words (where the punctuation character is bounded by letters on either side) will remain untouched.
The output of this effort results in much cleaner 2-grams:
['Linux', 'Foundation'], ['Foundation', 'Mozilla'], ['Mozilla', 'Foundation'], [ 'Foundation', 'Open'], ['Open', 'Knowledge'], ['Knowledge', 'Foundation'], ['Fou ndation', 'Open'], ['Open', 'Source']
Data Normalization
Everyone has encountered a poorly designed web form: “Enter your phone number. Your phone number must be in the form ‘xxx-xxx-xxxx’.”
As a good programmer, you will likely think to yourself, “Why don’t they just strip out the non-numeric characters I put in there and do it themselves?” Data normalization is the process of ensuring that strings that are linguistically or logically equivalent to each other, such as the phone numbers “(555) 123-4567” and “555.123.4567,” are displayed, or at least compared, as equivalent.
Using the n-gram code from the previous section, we can add on some data normalization features.
One obvious problem with this code is that it contains many duplicate 2-grams. Every 2-gram it encounters gets added to the list, with no record of its frequency. Not only is it interesting to record the frequency of these 2-grams, rather than just their existence, but it can be useful in charting the effects of changes to the cleaning and data normalization algorithms. If data is normalized successfully, the total number of unique n-grams will be reduced, while the total count of n-grams found (i.e., the number of unique or non-unique items identified as a n-gram) will not be reduced. In other words, there will be fewer “buckets” for the same number of n-grams.
Unfortunately for the purposes of this exercise, Python dictionaries are unsorted. “Sorting a dictionary” doesn’t make any sense, unless you are copying the values in the dictionary to some other content type and sorting that. An easy solution to this problem is the OrderedDict, from Python’s collections library:
from collections import OrderedDict ... ngrams = ngrams(content, 2) ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True)) print(ngrams)
Here I’m taking advantage of Python’s sorted function in order to put the items into a new OrderedDict object, sorted by the value. The results:
("['Software', 'Foundation']", 40), ("['Python', 'Software']", 38), ("['of', 'th
e']", 35), ("['Foundation', 'Retrieved']", 34), ("['of', 'Python']", 28), ("['in
', 'the']", 21), ("['van', 'Rossum']", 18)
As of this writing, there are 7,696 total 2-grams and 6,005 unique 2-grams, with the most popular 2-gram being “Software Foundation,” followed by “Python Software.” However, analysis of the results shows that “Python Software” actually appears in the form of “Python software” an additional two times. Similarly, both “van Rossum” and “Van Rossum” make an appearance in the list separately.
Adding the line:
input = input.upper()
to the cleanInput function keeps the total number of 2-grams found steady at 7,696, while decreasing the number of unique 2-grams to 5,882.
Beyond this, it’s usually good to stop and consider how much computing power you want to expend normalizing data. There are a number of situations in which different spellings of words are equivalent, but in order to resolve this equivalency you need to run a check on every single word to see if it matches any of your preprogrammed equivalencies.
For example, “Python 1st” and “Python first” both appear in the list of 2-grams. However, to make a blanket rule that says “All ‘first,’ ’second,’ ‘third,’ etc. will be resolved to 1st, 2nd, 3rd, etc. (or vice versa)” would result in an additional 10 or so checks per word.
Similarly, the inconsistent use of hyphens (“co-ordinated” versus “coordinated”), misspellings, and other natural language incongruities will affect the groupings of n-grams, and might muddy the results of the output if the incongruities are common enough.
One solution, in the case of hyphenated words, might be to remove hyphens entirely and treat the word as a single string, which would require only a single operation. However, this would also mean that hyphenated phrases (an all-too-common occurrence) will be treated as a single word. Going the other route and treating hyphens as spaces might be a better option. Just be prepared for the occasional “co ordinated” and “ordinated attack” to slip in!
Cleaning After the Fact
There is only so much you can, or want to do, in code. In addition, you might be dealing with a dataset that you didn’t create, or a dataset that would be a challenge to even know how to clean without seeing it first.
A knee-jerk reaction that many programmers have in this sort of situation is “write a script,” which can be an excellent solution. However, there are also third-party tools, such as OpenRefine, that are capable of not only cleaning data quickly and easily, but allow your data to be easily seen and used by nonprogrammers.
OpenRefine
OpenRefine is an open source project started by a company called Metaweb in 2009. Google acquired Metaweb in 2010, changing the name of the project from Freebase Gridworks to Google Refine. In 2012, Google dropped support for Refine and changed the name again, to OpenRefine, where anyone is welcome to contribute to the development of the project.
Installation
OpenRefine is unusual in that although its interface is run in a browser, it is technically a desktop application that must be downloaded and installed. You can download the application for Linux, Windows, and Mac OS X from its website.
Note
If you’re a Mac user and run into any trouble opening the file, go to System Preferences → Security & Privacy → General → and check “Anywhere” under “Allow apps downloaded from.” Unfortunately, during the transition from a Google project to an open source project, OpenRefine appears to have lost its legitimacy in the eyes of Apple.
In order to use OpenRefine, you’ll need to save your data as a CSV (file refer back to “Storing Data to CSV” in Chapter 5 if you need a refresher on how to do this). Alternatively, if you have your data stored in a database, you might be able to export it to a CSV file.
Using OpenRefine
In the following examples, we’ll use data scraped from Wikipedia’s “Comparison of Text Editors” table; see Figure 7-1. Although this table is relatively well formatted, it contains many edits by people over a long time, so it has a few minor formatting inconsistencies. In addition, because its data is meant to be read by humans rather than machines, some of the formatting choices (e.g., using “Free” rather than “$0.00”) is inappropriate for programming inputs.
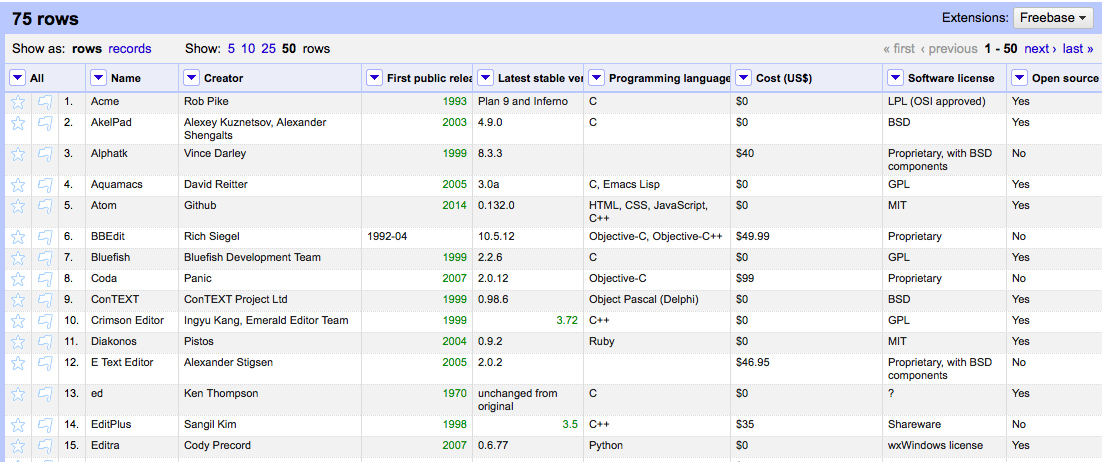
Figure 7-1. Data from Wikipedia’s “comparison of text editors” as shown in the main OpenRefine screen
The first thing to note about OpenRefine is that each column label has an arrow next to it. This arrow provides a menu of tools that can be used with that column for filtering, sorting, transforming, or removing data.
Filtering
Data filtering can be performed using two methods: filters and facets. Filters are good for using regular expressions to filter the data; for example, “Only show me data that contains four or more comma-seperated programming languages in the Programming language column,” seen in Figure 7-2.
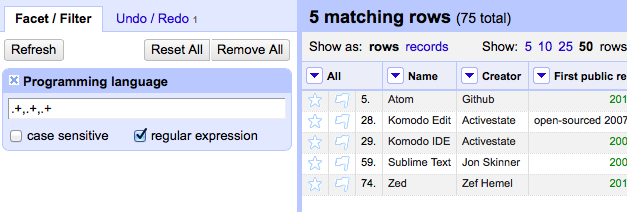
Figure 7-2. The regular expression “.+,.+,.+” selects for values that have at least three comma-separated items
Filters can be combined, edited, and added easily by manipulating the blocks in the righthand column. They also can be combined with facets.
Facets are great for including or excluding data based on the entire contents of the column. (e.g., “Show all rows that use the GPL or MIT license, and were first released after 2005,” seen in Figure 7-3). They have built-in filtering tools. For instance, filtering on a numeric value provides you with slide bars to select the value range that you want to include.
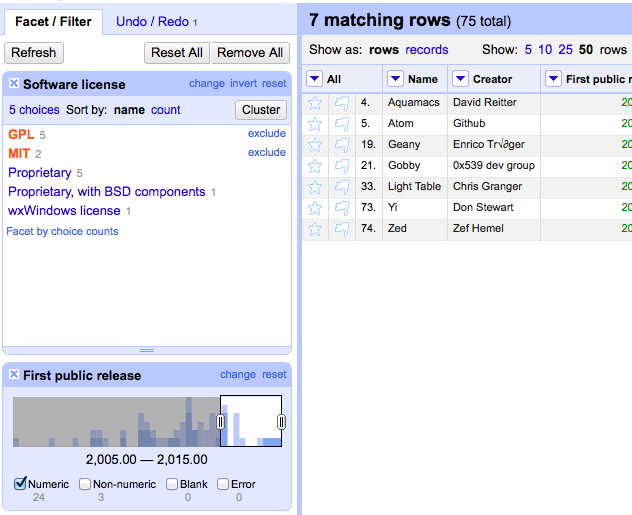
Figure 7-3. This displays all text editors using the GPL or MIT license that had their first public release after 2005
However you filter your data, it can be exported at any point to one of several types of formats that OpenRefine supports. This includes CSV, HTML (an HTML table), Excel, and several other formats.
Cleaning
Data filtering can be done successfully only if the data is relatively clean to start with. For instance, in the facet example in the previous section, a text editor that had a release date of “01-01-2006” would not have been selected in the “First public release” facet, which was looking for a value of “2006” and ignoring values that didn’t look like that.
Data transformation is performed in OpenRefine using the OpenRefine Expression Language, called GREL (the “G” is left over from OpenRefine’s previous name, Google Refine). This language is used to create short lambda functions that transform the values in the cells based on simple rules. For example:
if(value.length() != 4, "invalid", value)
When this function is applied to the “First stable release” column, it preserves the values of the cells where the date is in a “YYYY” format, and marks all other columns as “invalid.”
Arbitrary GREL statements can be applied by clicking the down arrow next to any column’s label and going to edit cells → transform.
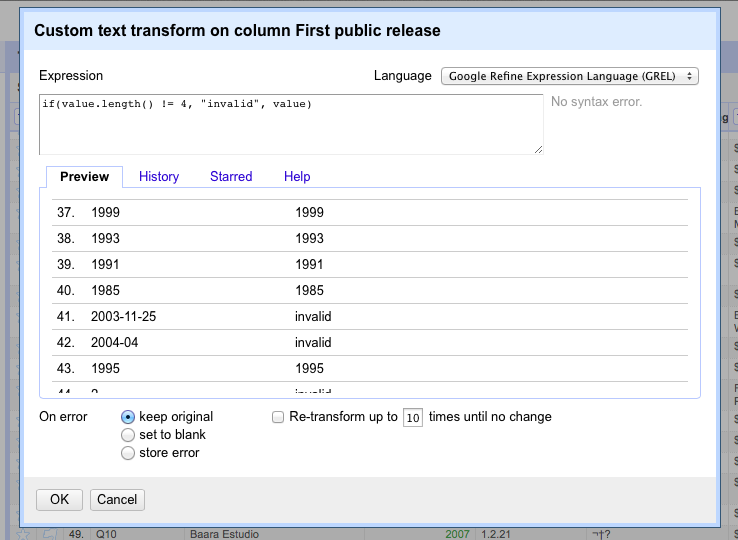
Figure 7-4. Inserting a GREL statement into a project (a preview display is shown below the statement)
However, marking all less than ideal values as invalid, while making them easy to spot, doesn’t do us much good. We’d rather try to salvage information from the badly formatted values if possible. This can be done using GREL’s match function:
value.match(".*([0-9]{4}).*").get(0)
This attempts to match the string value against the regular expression given. If the regular expression matches the string, an array is returned. Any substrings that match the “capture group” in the regular expression (demarcated by the parentheses in the expression, in this example, “[0-9]{4}”) are returned as array values.
This code, in effect, finds all instances of four decimals in a row and returns the first one. This is usually sufficient to extract years from text or badly formatted dates. It also has the benefit of returning “null” for nonexistent dates. (GREL does not throw a null pointer exception when performing operations on a null variable)
Many other data transformations are possible with cell editing and GREL. A complete guide to the language can be found on OpenRefine’s GitHub page.