
Defining a Meta-Directory
When discussing a meta-directory strategy, it is important not to confuse the concept of a meta-directory with that of directory coexistence. In the case of a true meta-directory, there is a single directory (the meta-directory) that is integrated with other directories and that is the single point of contact for all directory clients—whether they be users, applications, or hardware. Figure 3.1 illustrates a meta-directory integrated into an infrastructure that includes other directories. The meta-directory is the single point of contact for all these directory users. The meta-directory then references the other directories to gain the necessary data.
This chapter primarily focuses on examples in which Active Directory is the meta-directory in a directory coexistence (or synchronization) configuration.
Directory integration is not restricted to classic directories. It is also possible to configure a meta-directory system that includes both directories and other data sources. For example, Active Directory might be used to integrate application data between a Human Resources (HR) application and Microsoft Exchange. In Figure 3.2, Active Directory is the intersection between the two disparate data sources. A Web application that integrates information from both the HR application and Microsoft Exchange can query the Active Directory for the information, rather than having to query both Microsoft Exchange and the HR application.
Figure 3.1. In the case of a true meta-directory strategy, multiple directories might contain information required by network users, applications, or network hosts.

Figure 3.2. Active Directory can serve as a central point of contact for applications seeking data from distributed data sources.

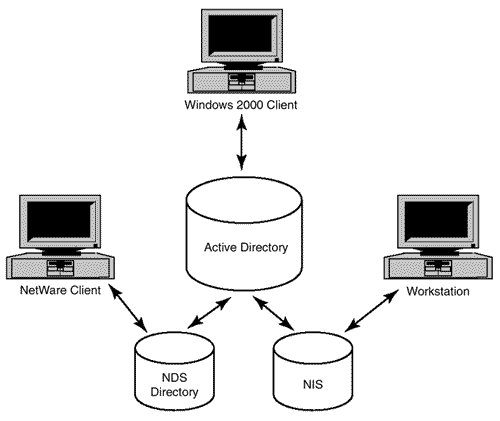
This type of directory integration should not be confused with the concept of directory coexistence. Directory coexistence exists if two or more directories synchronize data or share data elements while, at the same time, servicing their own directory clients. For example, Active Directory might be an intersection point for Windows NT 4.0, NetWare with NDS, and UNIX Network Information Service (NIS) directories, as in Figure 3.3. However, each of the respective network clients and users do not access Active Directory for their network authentication information. Instead, they access their own native directory. Directory-coexistence strategies are discussed in Chapter 6, "Planning for Coexistence."
Figure 3.3. Active Directory can also be used as a central element in a directory-coexistence scheme. This should not be confused with a meta-directory strategy as previously outlined.
A meta-directory is a central repository for many types of data, such as telephone numbers, user network logon names and passwords, manager's names, office locations, and so on. Because there are so many different types of data that can be stored in a meta-directory, it is critical that the structure of the directory schema be planned carefully. In some cases, the data might not actually be stored in the directory. Instead, there might be pointers in the directory to data that is stored in other databases or directories. For example, Active Directory could include a Globally Unique Identifier (GUID) and a Lightweight Directory Access Protocol (LDAP) query string that identifies a specific set of data in a HR database that is accessible by using the LDAP Application Programming Interface (API) . In this way, the HR department would not have to modify the data in Active Directory, but it could simply modify the data in the local application. If a directory client queries Active Directory for the data string, the meta-directory issues a LDAP query to the HR application, which then returns the data to Active Directory and finally to the client.
Figure 3.4 illustrates a meta-directory that is accessing information stored in both SQL Server and Oracle. Active Directory, as a meta-directory, can be used to access and integrate data from a wide range of back-end data sources.
Figure 3.4. A meta-directory accessing information from both SQL Server and Oracle.

A meta-directory can contain pointers to data in other directories, thus distributing the required space for data storage, as well as the administration requirements. It is important to note that other types of data do not belong in a directory. Stock quotes, for example, represent data that is so dynamic that storing them in a directory is not practical. Stock quote information changes so often that the replication traffic caused by the system trying to replicate changes between directory servers would, in most cases, bring the system down. Stock ticker symbols, however, represent data that is static in nature and that users can use as a reference to query other data sources.
Integration
As you begin to plan the structure of your directory, you must take into account all the different types of data you want to include, as well as all the different sources of that data. Active Directory is simply another database in your Information Technology (IT) infrastructure. You need to employ the same planning methods that you would to deploy a new SQL database. In the case of our sample company, Wadeware, many different types of data will eventually be included in Active Directory, after it is established as the central directory in a meta-directory architecture. The sales force uses a sales-force automation tool that requires a separate user name and password. This information is stored in Active Directory. One of the subsidiaries of Wadeware currently uses NetWare as a primary network operating system (NOS). There is a requirement to synchronize network authentication information between Active Directory and NDS on NetWare.
Determining all the data that needs to go in to Active Directory can be overwhelming. The best way to start is to develop a table that contains all the data elements that you plan to include in Active Directory. You want to capture several properties for each data element. These include
Data Type— The type of data that is in the field. This is defined as ASCII, binary large object (BLOB), numeric, alphabetic, currency, and so on. This determines the formatting of the field and the configuration of how the data should be presented.
Field Length— The size of the data field is important to determine at the outset. When determining the length of the data filed, it is extremely important to take in to account all the possible configurations of the data. For example, a phone number might be represented as 425-555-1212, (425) 555-1212, + 1 (425) 555-1212, or even 1.425.555.1212. Each one of these configurations represents a different requirement for the length of the data field. Another way to control the length of the data entered in any specific field is to provide a field mask for the data. In the case of the phone number previously listed, you could provide a mask that exposed only the character places required for the area code and the seven digit phone number. You could then present the data in any format you wanted.
Current Source of Data— When establishing a new meta-directory, you should always identify the current source of the data that you put in the directory. This helps you to determine data synchronization requirements.
Data Owner— It is important to determine at the outset who is the owner of the data. In large organizations, it is typical for multiple people to claim ownership of data. When considering your design for a meta-directory solution using Active Directory, it is critical that you determine who owns what data so that you assign the correct administrative rights to the individuals or departments for changing the data in the directory.
Synchronization Method— There are several ways to design synchronization in a meta-directory environment. The easiest way to jumpstart data synchronization between two directory systems is a one-time data extraction from a legacy data source. This is adequate for dealing with a legacy data source that will be retired as soon as the meta-directory is in production. It is obviously not adequate for synchronizing data between a legacy data source and the meta- directory in a situation in which the legacy data source coexist with Active Directory for an extended period of time. Although it is possible to conduct on-going data extractions from a legacy data source by using a batch process, those processes are often cumbersome and time-consuming. In addition, when large blocks of data are added wholesale to a directory, it can significantly affect the amount of replication traffic between directory servers on the network.
Table 3.1 is representative of one used for developing a meta-directory architecture.
| Data Type | Field Length (chars) | Current Source | Data Owner | Synchronization Method |
|---|---|---|---|---|
| User Name | 50 | NDS | NetWare Admin | MS Directory Synchronization (DirSync) |
| Access Authentication Level | 2 | Siebel Sales Force Automation | Sales IT Admin | ADSI Script |
Extensibility
For a directory to meet the requirements of a meta-directory, it must be extensible. In the case of Active Directory, it is possible to extend the schema by using the directory snap-in for the Microsoft Management Console (MMC) or programmatically by using a script. The extensibility of a meta-directory is important for external applications to take advantage of the directory as a repository for application data or as a pointer to external sources for the data. In the case of the next version of Microsoft Exchange, for example, the Active Directory schema is modified significantly to provide directory services for Exchange.
The schema in Active Directory is fully extensible and can be used as an object store for data, or as a store for pointers to other data locations. However, although the schema can be extended (if needed), it is important that Active Directory administrators fully understand the implications of extending the schema and develop a schema modification policy. Because schema extensions can have a dramatic impact on performance of Active Directory, it is well worth your time expanding on schema management at this point. When discussing schema extensibility, it is important to understand
How to modify the schema
When to modify the schema
How to develop a policy for modifying the schema
How to Modify the Schema
The Active Directory schema is comprised of components. These components are classes, attributes, and syntax. It is important to note that when a new user is added to the directory, the schema is not modified; in other words, a new component is not added. Instead, an object of the User class is created. New objects in Active Directory should be a relatively routine task for administrators. Modifying the schema should be a task that happens rarely—and one that is done only with a significant amount of consideration.
Classes in the schema are groupings of objects that share a set of attributes, such as Users or Computers. Attributes are the data elements that collectively define an object. In the case of a user, the attributes would include displayName and name. These attributes are also referred to as properties (see Figure 3.5).
Figure 3.5. Attribute objects within the directory schema can be modified by using Active Directory schema in MMC.
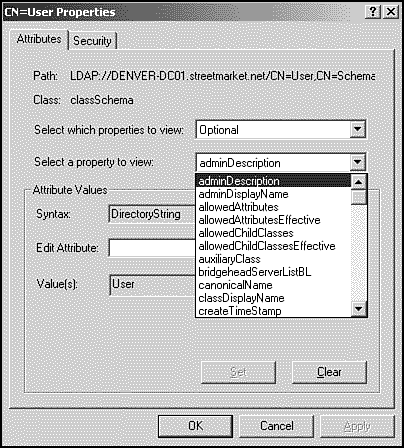
Each one of these attributes also contains a definition for syntax. The syntax of an attribute determines the type and format of the data that is required. For example, the syntax rules for the attribute displayName might require that the value be alpha, rather than numeric. The syntax rules for the attribute Telephone-Number might require a numeric value.
The schema can be modified by using the Active Directory schema snap-in found in MMC. Members of the Schema Admins group can use the snap-in to manage the schema by creating, deactivating, and modifying classes and attributes. It is extremely important to note that after a schema extension has been enacted, it is not possible to delete it. It is possible to deactivate classes and attributes, but not to delete them.
Scripting is also a possible method for modifying the schema. By using ADSI, a script can perform all the same schema modification tasks as the schema snap-in.
There is also a third way to modify the schema. When new applications are installed, the installation process can modify the schema based upon the needs of the application. If an application is installed that requires a modification to the schema, it is necessary for a member of the Schema Admins group to perform the installation.
Not all schema objects can be modified. Any classes and attributes defined as systems cannot be modified or deactivated. In addition, certain restrictions are enforced if the classes or attributes are part of the default schema configuration. Objects that are in deactivated classes still appear in directory searches. Consequently, to eliminate deactivated objects from search results, you must search for all objects in deactivated classes and then delete the objects themselves.
When to Modify the Schema
Deciding when to modify the schema is an important decision because of the dramatic impact on performance that a schema modification can have. Because of the large number and the range of classes and attributes in the default schema, modifications should be a rare occurrence. However, there might be times at which the default schema does not meet your needs. The following are some situations in which the schema might need to be modified:
No existing class meets your needs— There might be times when there is no existing class that meets your needs in the default schema. This might be the case if you are creating a new, homegrown application or installing an application that does not include schema modification as part of the installation process. In these cases, you should add an entire new class to the schema.
An existing class lacks attributes— An existing class might nearly fit your needs, but it might lack specific attributes that you need. In this case, you can add new attributes to the existing call or derive a child class from the existing class and add attributes as needed.
A set of unique attributes is needed— There might be times that a unique set of attributes is needed, but an entire new class or child class is not required. In these cases, you can create an auxiliary class that is connected to the original class.
Classes or attributes are no longer needed— In the case where a class or attribute is no longer needed, use the snap-in or a script to deactivate the class or attribute.
Regardless of how the schema is modified, it is important to always consider the concept of inheritance between classes. Classes inherit the properties of the classes from which they are derived. The parent class from which a child class is derived affects all future objects created in that class type. Consequently, it is important to plan correctly when deriving new child classes.
Policy for Schema Modification
Developing a policy for schema modification is less about technology than it is about good project management and planning. Schema modifications can have widespread effects that might impair or disable Active Directory across entire organizations. Consequently, it is important to follow a rigid set of steps if reviewing and approving modifications. These steps might include
Initiating modification request— Requests for any schema modification should be reviewed by a committee that represents all the stakeholders in the organization. Any group that is affected by the schema modification should have a say in the review process. After the request is reviewed and validated, the committee is the body to approve the request.
Planning implementation— After the modification is approved, a plan must be developed for implementing the modification. The plan should include testing to ensure that the modification meets the requirements of the requestor. The plan should also ensure that an effective roll-back process is in place.
Modification— Modification of the schema should also be tested in a lab environment first. The lab should be completely separated from the production environment. The lab schema should accurately represent the production schema.
Reliability
Reliability is a critical feature for any directory—and even more so for a meta- directory. A meta-directory by definition is used by multiple applications, systems, network services, and other directories. Consequently, any directory outage can have a significant impact on business performance and, ultimately, on the bottom-line revenue of the company.
Several levels of fault-tolerance can be implemented so that Active Directory is highly available. Because it is a multi-master directory, it can withstand Domain Controller (DC) outages by having multiple DCs located in strategic locations around the organization. As a best practice, DCs should be located on every major segment of the network. In addition, the physical layer configuration of the network should provide for multiple path connectivity between DCs whenever possible. This type of configuration, enables continued directory replication if a single network segment fails. In Figure 3.6, if one WAN segment fails, connectivity between DCs is still possible by using a secondary link. In this example, any one of the three sites has two network paths to the other two sites.

In addition to providing multi-master replication between DCs within Active Directory, each Active Directory DC can function as a zone-master domain name system (DNS) server to external clients and other DNS servers. This is radically different from the standard configuration of DNS, which has only one zone master and multiple secondary, or caching, servers. Configuration of DNS as part of Active Directory is covered in more depth in Chapter 8, "Designing the DNS Namespace."
In addition to directory reliability and redundancy, Active Directory leverages Windows 2000 Advanced Server clustering, which provides an additional level of reliability. Advanced Server and Data Center Server provide hardware clustering services for two-node and multi-node systems, respectively. Active Directory is used to publish information about the cluster configuration.
Scalability
Scalability is another critical aspect of a meta-directory. Active Directory provides for scalability through multi-master domains, multi-domain trees, and multi- tree Forests. This is a marked contrast to Windows NT 4.0, which had a practical limitations on the number of domains that could be linked together by using explicit trust relationships. With Active Directory, it is possible to configure the domain environment in a way that matches business needs, rather than having to force business requirements into an inferior domain design, as was often the case with Windows NT 3.51 or 4.0.
As discussed at length earlier in this chapter, Active Directory also meets scalability requirements through an extensible schema and a fault-tolerant schema. Unlike earlier versions of Windows NT, Active Directory does not have a specific limitation on the size of the directory database. However, although there is no specific limitation on the size of the database, there are practical limits. The speed of connectivity between DCs both within the same site and in different sites, limits the actual size of the directory database.