
 From Denmark with love
From Denmark with love
Generic Collections from .NET and Power Collections offer great abstraction over very low-level implementations. You can use a dictionary to represent an indexed, associative list; however, you will have no idea what the internal data structure under the hood is, and if you don't like the internal implementation of dictionary, you don't have any other option than to come up with your own Generic Collection, which is a lot of work. Seriously!
The fine folks at IT University of Copenhagen thought about it a lot and have come up with a brilliant Generic Collection API known as C5. C5 is not an acronym to be exact. However, the creators of the API termed this and it could possibly be Copenhagen Comprehensive Collection Classes for C#. However, this API can also be used from VB.NET. This comes as a loaded third-party API in Mono project, which is a .NET port for Linux systems.
The most basic goal of this API is to allow users to choose different concrete classes for the same type of abstraction depending on the need. For example, there are dictionary abstractions where the interface is almost similar to System.Collections.Generic.Dictionary<TKey, TValue>; however, these dictionaries in C5 have two variants; namely hash based and tree based
, giving us more control over the selection of the data structure. Again, the point is, most of these can be conceptually duplicated using Generic Collections available from the System.Collections.Generic namespace; but these let the user decide whether they want a hash-based, tree-based, array-based, and/or LinkedList-based container.
In this chapter, we will deal with some real-world problems using C5, Power Collection, and LINQ. Along the way, we will learn about some of the following collection classes and how to use them wisely. Collections that conceptually belong to the same family, such as HashBag and TreeBag, LinkedList and ArrayList can be used interchangeably with some modifications.

The goal is to learn how they fit into our real-world problem-solving strategy. These collections offer some really cool methods that will otherwise be quite some work on the client code developer's part. So, the stress will be more towards exploring these.
Hash-based collections use a hashing method to store the elements. So, checking whether an item is available in such a collection is a constant time operation O(1). However, the order of insertions is not preserved in these collections. So, you can't expect to get the elements in the same location as you added them. Apart from HashSet, other hash-based collections allow duplicate items.
Tree-based collections use Red Black Tree, which is a variation of the balanced binary search tree to store the elements. So, for primitive data types, items always get added in a sorted fashion. Accessing elements is also fast, O(logn), but not as fast as in hash-based collections. IntervalHeap is a heap-based implementation of Priority Queue.
In Chapter 9, Patterns, Practices, and Performance we shall see how these containers perform against containers in the System.Collections.Generic namespace
Get the C5 binaries from http://www.itu.dk/research/c5/Release1.1/C5.bin.zip.
You need to attach C5.dll to the project's reference.
Gender Genie (http://bookblog.net/gender/genie.php) is an online web application that tries to guess the gender of the author from a digital content. I always wanted to use this offline. Few methods and collection classes of C5 make it really simple.
Create a Windows application and attach
C5.dllandPowerCollections.dllto the project's reference (instructions on How to get Power Collections can be found in Chapter 7, Power Collections).Add the following
usingdirectives to the project:using C5; using Wintellect.PowerCollections;
Add the following variables:
C5.ArrayList<string> femaleWords = new ArrayList<string>() {"with", "if", "not", "where", "be", "when", "your", "her", "we", "should", "she", "and", "me", "myself", "hers", "was"}; C5.ArrayList<int> femaleWordPoints = new ArrayList<int>() {52, 47, 27, 18, 17, 17, 17, 9, 8, 7, 6, 4, 4, 4, 3, 1}; C5.ArrayList<string> maleWords = new ArrayList<string>() {"around", "what", "more", "are", "as", "who", "below", "is", "these", "the", "a", "at", "it", "many", "said", "above", "to"}; C5.ArrayList<int> maleWordPoints = new ArrayList<int>() {42, 35, 34, 28, 23, 19, 8, 8, 8, 7, 6, 6, 6, 6, 5, 4, 2};Add the following controls on the form, as shown in the following screenshot:
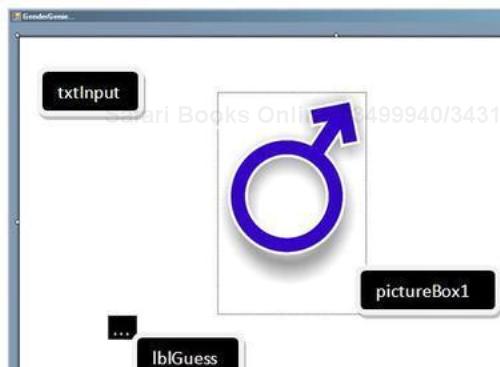
Add the following code to the click event of
btnGuess:private void btnGuess_Click(object sender, EventArgs e) { int maleScore = 0; int femaleScore = 0; C5.ArrayList<string> words = new ArrayList<string>(); words.AddAll(txtInput.Text.ToLower().Split(newchar[]{' ',' ',' ','.','?','!',';',',','''}, StringSplitOptions.RemoveEmptyEntries)); //Generating word histogram that stores words and their //frequency. var histogram = words.ItemMultiplicities(); //Copying only those words that are mostly used by women var femaleDic = histogram.Filter(c => femaleWords.Contains(c.Key.ToLower())); //Copying only those words that are mostly used by men var maleDic = histogram.Filter(c => maleWords.Contains(c.Key.ToLower())); //Calculating female score. This measure is an indication that //the document is written by a lady Algorithms.ForEach ( femaleDic, c => femaleScore += femaleWordPoints[femaleWords.IndexOf(c.Key.ToLower())] * c.Value ); //Calculating male score. This measure is an indication that //the document is written by a gentleman Algorithms.ForEach ( maleDic, c => maleScore += maleWordPoints[maleWords.IndexOf(c.Key.ToLower())] * c.Value ); //Show the response if (maleScore > femaleScore) { pictureBox1.ImageLocation = Application.StartupPath + "\male.bmp"; lblGuess.Text = "The Author of this document is probably a gentleman"; } else { pictureBox1.ImageLocation = Application.StartupPath + "\female.bmp"; lblGuess.Text = "The Author of this document is probably a lady"; } lblGuess.Visible = true; pictureBox1.Visible = true; }To hide the response, add the following code to the click event of
pictureBox1:private void pictureBox1_Click(object sender, EventArgs e) { pictureBox1.Visible = false; lblGuess.Visible = false; }Run the app, and paste some text copied from anywhere. It will try to predict whether the author of the document is a man or a woman, as shown in the following screenshot:
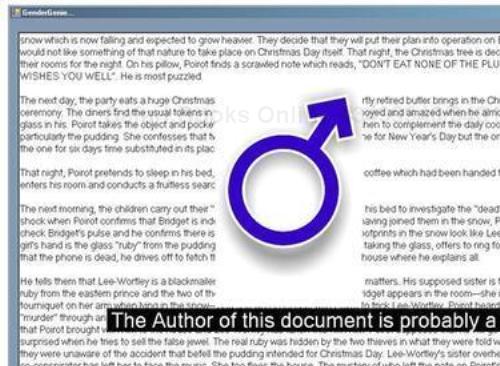
You can see this application in action at http://sudipta.posterous.com/gender-genie-clone.
The following line:
var histogram = words.ItemMultiplicities();
generates a histogram for words. ItemMultiplicities() is a method of the C5. ArrayList class that returns the elements in the array list along with their frequency. The return type of this method is ICollectionValue<C5.KeyValuePair<string,int>> for this case because words is a collection of the string type.
To understand how the values are stored in a histogram conceptually, I applied the ToList() LINQ operator and the result looked similar to the following screenshot:
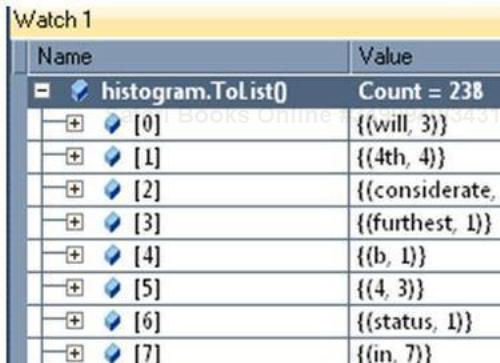
This means the word "in" occurred seven times. If you dig one level deep, you can see a result similar to the following screenshot:

This means the word "in" occurred seven times in the input text.
The following line creates a dictionary instance on the fly that will have only those words that are available in both the collections femaleWords array and the input:
var femaleDic = histogram.Filter(c => femaleWords.Contains(c.Key.ToLower()));
Note that the Filter() method is used as the LINQ Standard Query Operator Where(). C5 came into existence before LINQ. You can use Where() too. The
Filter() method expects an argument of type of the function delegate so that the Lambda expressions fit nicely.
In the next line:
Algorithms.ForEach ( femaleDic, c => femaleScore += femaleWordPoints[femaleWords.IndexOf(c.Key.ToLower())] * c.Value );
the ForEach() algorithm in the Power Collection takes an action delegate to perform on each element of the passed collection; femaleDic in this case.
So, this statement calculates the femaleScore, which is a measure of the probability that the document is written by a female author. If this score is more than maleScore, then the document is probably authored by a woman.
The
c.Key.ToLower() method returns the key of the current element in the femaleDic dictionary instance. femaleWords.IndexOf(c.Key.ToLower()) returns the index of this word in the femaleWords array.
Thus, femaleWordPoints[femaleWords.IndexOf(c.Key.ToLower())] returns the weight of this word and c.Value is the frequency of occurrence of this word in the dictionary. So, by multiplying the weight and the frequency we get the score contribution of this word towards the total female score.
There is another very interesting generic method called, UnsequencedEquals(), which is available on the C5.ArrayList<T> class. Using this method, we can easily check whether two words are anagrams of each other or not. Let's see how:
Create a console application. Make sure you attach
C5.dllto the reference of the project.Write the following code inside
Main():static void Main(string[] args) { Console.WriteLine("Enter two phrases "); string first = Console.ReadLine(); string second = Console.ReadLine(); C5.ArrayList<char> charsFirst = new C5.ArrayList<char>(); charsFirst.AddAll(first.ToCharArray()); C5.ArrayList<char> charsSecond = new C5.ArrayList<char>(); charsSecond.AddAll(second.ToCharArray()); bool isAna = charsFirst.UnsequencedEquals(charsSecond); if (isAna) Console.WriteLine(@"The words {0} and {1} are anagrams of each other.", """ + first + """, """ + second + """); else Console.WriteLine(@"The words {0} and {1} are not anagrams of each other.", """ + first + """, """ + second + """); Console.ReadKey(); }Following is a sample run of the application:

Finding whether two phrases are anagrams of each other or not is equivalent to finding out whether these two phrases have the same word histogram or not. A word histogram is like a dictionary where words are stored as the keys and the frequency of their occurrence is the value of the dictionary.
The method UnsequencedEquals() checks whether two collections have the same elements or not, disregarding the order of elements in the collections. This is exactly what we want to do to find out whether two phrases are anagrams or not. In our case, in the previous program, we wanted to check whether two words are anagrams of each other or not. So, checking the similarity of their character histogram would be sufficient.
Google Sets (http://labs.google.com/sets) is a nice piece of software when one wants to know what a few words mean. Given a few items, Google Sets returns similar items. In this example, we will build a small prototype that will reveal the possible data structure behind Google Sets. In the example, users will enter a few programming language keywords. The program will interpret the programming language from which these keywords are taken and then generate random small or large sets of similar keywords.
Create a Windows form application and place controls on it, as shown in the following screenshot:
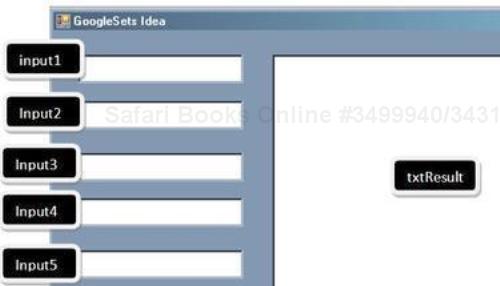
Add a C5 and Power Collection reference to the project:
using C5; using Wintellect.PowerCollections;
Add the following variables to the
Form:enum SetType {Small, Large}; string[] smallSet; string[] largeSet; HashDictionary<string, HashBag<string>> languageKeywordMap = new HashDictionary<string, HashBag<string>>();Add the following method to load language keywords:
private void LoadKeywords(string lang,string fileName) { //Need to import using System.IO; to use StreamReader StreamReader creader = new StreamReader(fileName); string[] all = creader.ReadToEnd().Split(new char[] {' ', ' ', ' ' }, StringSplitOptions.RemoveEmptyEntries); creader.Close(); HashBag<string> allKeyWords = new HashBag<string>(); allKeyWords.AddAll(all); languageKeywordMap.Add(lang, allKeyWords); }Call the preceding method to load several programming language keywords on
Form_Load:private void Form1_Load(object sender, EventArgs e) { PopulateCKeywords(); PopulateCPPKeywords(); PopulatePythonKeywords(); PopulateRubyKeywords(); PopulateJavaKeywords(); } private void PopulatePythonKeywords() { LoadKeywords("Python","PyKeys.txt"); } private void PopulateCPPKeywords() { LoadKeywords("CPP", "CPPKeys.txt"); } private void PopulateCKeywords() { LoadKeywords("C", "CKeys.txt"); } private void PopulateRubyKeywords() { LoadKeywords("Ruby", "RubyKeys.txt"); } private void PopulateJavaKeywords() { LoadKeywords("Java", "JavaKeys.txt"); }Add the following code to generate and show a similar small set of 15 items:
private void btnSmallSet_Click(object sender, EventArgs e): { txtResult.Clear(); HashSet<string> samples = new HashSet<string>(); samples.Add(input1.Text); samples.Add(input2.Text); samples.Add(input3.Text); samples.Add(input4.Text); samples.Add(input5.Text); foreach (string key in languageKeywordMap.Keys) { if(Algorithms.EqualSets(languageKeywordMap[key].Intersect(samples),samples)) { smallSet = Algorithms.RandomSubset(languageKeywordMap[key], 15); Show(key, SetType.Small); break; } } }Add the following code to generate and show a larger set of 30 items or as many as are available (if there are less than 30):
private void btnLargeSet_Click(object sender, EventArgs e) { //List<string> samples = new List<string>(); txtResult.Clear(); HashSet<string> samples = new HashSet<string>(); samples.Add(input1.Text); samples.Add(input2.Text); samples.Add(input3.Text); samples.Add(input4.Text); samples.Add(input5.Text); foreach (string key in languageKeywordMap.Keys) { if(Algorithms.EqualSets(languageKeywordMap[key].Intersect(samples), samples)) { int bigCount = languageKeywordMap[key].Count > 30 ? 30 : languageKeywordMap[key].Count; largeSet = Algorithms.RandomSubset(languageKeywordMap[key], bigCount); Show(key,SetType.Large); break; } } }Add the following method to show the results:
private void Show(string key,SetType whichOne) { lblIdentity.Text = "These are " + key + " Keywords"; lblIdentity.Visible = true; if(whichOne == SetType.Small) foreach (string s in smallSet) txtResult.Text = txtResult.Text + s +Environment.NewLine; if(whichOne == SetType.Large) foreach (string s in largeSet) txtResult.Text = txtResult.Text + s + Environment.NewLine; }We are all set to test this! The following is the output of a sample run:
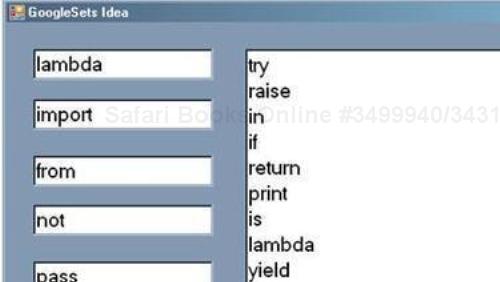
You can check out the program in action at http://sudipta.posterous.com/google-sets-clone-mini-but-the-idea-is-correc.
The following code:
HashDictionary<string, HashBag<string>> languageKeywordMap = new HashDictionary<string, HashBag<string>>();
creates a HashDictionary where keys are stored as Hash. The value for this dictionary is a HashBag, which is just conceptually similar to a list where all the elements are hashed for a constant time availability/membership check.
In button-click events (btnSmallSet_Click and btnLargeSet_Click), a HashSet is created to capture user inputs. A set is used to remove any duplicate entries. Inside the loop, within these event handlers, every entry in the dictionary is iterated using the dictionary keys.
languageKeywordMap[key] returns the associated HashBag<string> that has all the keywords associated with the language "key".
languageKeywordMap[key].Intersect(samples) returns the intersection set for the associated HashBag<string> and user input values. Now, if all entries of samples do exist in the intersection, this means samples is equal to the intersection set. Algorithms.EqualSets checks whether these two are equal or not. If they are, then we have hit a match.
Algorithms.RandomSubset returns a random subset from the given set (which is passed as the first argument).
In this example, we could have used TreeBag, TreeDictionary, and TreeSet also instead of the hash-based versions.
This means the following internal data structure:
HashDictionary<string, HashBag<string>> languageKeywordMap = new HashDictionary<string, HashBag<string>>();
could have been as follows:
TreeDictionary<string, TreeBag<string>> languageKeywordMap = new TreeDictionary<string, TreeBag<string>>();
or similar to the following:
TreeDictionary<string, TreeSet<string>> languageKeywordMap = new TreeDictionary<string, TreeSet<string>>();
Or you can choose to use a mix of these data structures. However, as the internal storage mechanisms of these data structures vary, we will have to change our calling code a little bit to make sure it still works.
For example, if you use the first alternative, then you have to change all instances of HashBag to TreeBag. However, if you use ICollection<string> as the value in the languageKeywordMap dictionary, then you can use any of these (either TreeBag or HashBag or HashSet) interchangeably as they are all ICollection<T> implementations. So, if you use TreeBag, you have to change the following line:
if(Algorithms.EqualSets(languageKeywordMap[key].Intersect(samples), samples))
to:
if(Algorithms.EqualSets(languageKeywordMap[key].ToArray().Intersect(samples), samples))
However, if you choose to use the second alternative, you don't have to make any changes apart from changing every instance of HashSet<string> to TreeSet<string>.
However, finding one keyword from a given list of words can be very time consuming due to the linear search in list-based collections, such as an ArrayList. In this situation, either a tree-based or a hash-based collection is ideal. List-based collections offer the slowest lookup speed, which is linear O(n), while tree-based collections offer logarithmic time O(n log n) and hash-based collections offer a constant time lookup O(1).

The local departmental store wants to start a dynamic display system that will show high-in-demand items in each of its departments. It has a rather social impact. People shopping trust fellow shoppers more than advertisements; so, they want to know what others are buying or looking at.
In this example, we will create a generic data structure that can keep track of elements and their sale count very efficiently. At any point in time, this data structure can be queried about the top n (user can decide the value of n) items in demand. On demand, it can show how many times an item was in demand in constant time:
Create a class library project. Name it
MyDSand change the name ofClass1toMTFList.Add
C5.dllto the reference of the project and add theusingdirective:Change the class header as follows:
public class MTFList<T> where T:IComparable
Add the following code:
///<summary> ///Internal Data Structure ///</summary> HashDictionary<T, int> _innerDS; public MTFList() { _innerDS = new HashDictionary<T, int>(); } ///<summary> ///Adds one item to the list ///</summary> ///<param name="item">item to be added</param> public void Add(T item) { _innerDS.Add(item, 1); } ///<summary> ///Checks whether the item is in the list or not ///</summary> ///<param name="item">item for which availability has to be ///checked. </param> ///<returns>true if the item is present, false otherwise</returns> private bool Contains(T item) { return _innerDS.Contains(item); } ///<summary> ///Searches for the item and increments its sought after count by ///unity ///</summary> ///<param name="item">item being sought</param> ///<returns>true if the item is present, false otherwise</returns> public bool Search(T item) { if (Contains(item)) { _innerDS[item]++; return true; } return false; } ///<summary> ///Returns the item which is highest in demand ever. ///</summary> public T Top { get { return _innerDS.Filter(c=>c.Value == _innerDS.Values.Max()).Select(c=>c.Key).ElementAt(0); } } ///<summary> ///Returns a list of top n items ///</summary> ///<param name="n">value of n</param> ///<returns>a list of top n items in demand</returns> public IEnumerable<T> TopN(int n) { if (_innerDS.Count < n) return new ArrayList<T>(); else { return _innerDS.OrderByDescending(c => c.Value).Select(c=>c.Key).ToList().Take(n); } }At this point, we are done with the design of this structure. Time to consume it!
In the next few steps, we will see how to use this
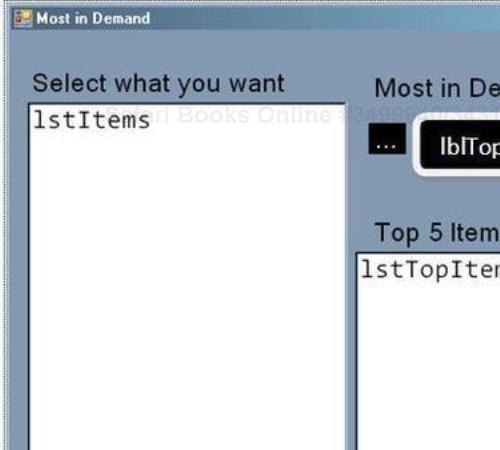
MTFList<T>to find the most in-demand item in a store.Add the following controls to the Windows form, as shown in the following screenshot:
Add a reference of the class library in this project and make sure you add the
usingdirective:using MyDS;
Add the following variable to hold the most in-demand items:
MTFList<string> wantedGarments = new MTFList<string>();
Load this list with some values when the form loads and also add them to the list:
private void Form1_Load(object sender, EventArgs e) { //Add using System.IO; for using StreamReader class. StreamReader itemReader = new StreamReader("garments.txt"); string[] clothes = itemReader.ReadToEnd().Split(new char[] { ',' }, StringSplitOptions.RemoveEmptyEntries); clothes.ToList().ForEach(c => lstItems.Items.Add(c.Trim())); clothes.ToList().ForEach(c => wantedGarments.Add(c.Trim())); }Deal with the button click:
private void btnWant_Click(object sender, EventArgs e) { lstTopItems.Items.Clear(); wantedGarments.Search(lstItems.Items[lstItems.SelectedIndex] .ToString()); lblTop.Text = wantedGarments.Top; List<string> top5 = wantedGarments.TopN(5).ToList(); foreach (string t in top5) lstTopItems.Items.Add(t); }Following is the output of a sample run of the program:
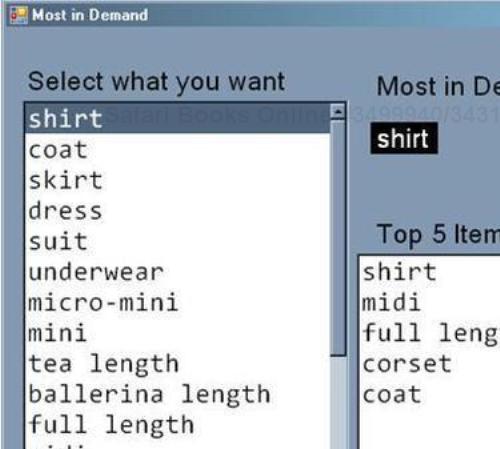
You will understand how it behaves better if you take a look at the video on my blog http://sudipta.posterous.com/move-to-front-list-most-in-demand-demo.
I highly recommend you see the video before you read the next section What just happened?
Unlike other search methods, the
Search() method for this Generic Collection is active. Instead of just searching and returning true or false, it also increments the count associated with that element by unity every time that item is sought by the code line _innerDS[item]++;.
HashDictionary is used because it is the fastest of its kind—especially for strings—when localization can make actual key comparison-based structures such as TreeDictionary slow. HashDictionary offers a constant time lookup O(1) whereas TreeDictionary takes O(log n) for lookup where n is the number of elements in the dictionary.
To find the top-most item in demand, we are using the following code:
return _innerDS.Filter(c=>c.Value == _innerDS.Values.Max()).Select(c=>c.Key).ElementAt(0);
The Lambda expression c=>c.Value == _innerDS.Values.Max() tells the
Filter() method to find the element with the maximum value from the dictionary.
_innerDS is a dictionary and has keys and values. c.Key returns the key associated with a particular entry. As there can be many such elements, it will be sufficient to find the first one.
In the method, TopN(), as you can see, the dictionary is sorted by the values in descending order starting with the highest value.
If you need some efficient sorting algorithm wrapped in a generic method, C5 has some in store for you. It has three sorting algorithms exposed as static methods of the class Sorting, which are as follows:
IntroSortHeapSortInsertionSort
All these sorting mechanisms operate on an array of T, and all of these algorithms operate in-place. This means once you operate them on an array, you will be left with the sorted array and will lose the original unsorted array. We can use them to sort different collections as follows:
IntroSort is an unstable version of QuickSort that can be used in situations where QuickSort fails to offer high performance, such as in the case of almost sorted collections. HeapSort is also as efficient as IntroSort. However, in practice, it is a little slower than IntroSort:
int[] a = new int[]{1, 42, 32, 22, -1, 0};
Console.WriteLine("Before Sorting");
a.ToList().ForEach(c => Console.Write(c + " "));
C5.Sorting.IntroSort(a);
Console.WriteLine("
After Sorting");
a.ToList().ForEach(c=>Console.Write(c + " "));
Console.ReadLine();This will generate the following output:
Before Sorting 1 42 32 22 -1 0 After Sorting -1 0 1 22 32 42
Everything will remain the same. Just the call to IntroSort should use the overloaded version as follows:
C5.Sorting.IntroSort(a, 0, 5, Comparer<int>.Default);
This change in the preceding code snippet will generate the following output. Note that only the first five elements of the array were sorted. This is somewhat close to the partial_sort() method available in STL in C++:
Before Sorting 1 42 32 22 -1 0 After Sorting -1 1 22 32 42 0
The other two sorting algorithms only offer the overload matching the second version.
Ideally, this is the same as Pattern 1; however, it shows how to use a custom comparer:
List<string> names = new List<string>() {"A", "C", "B", "D"};
string[] nameArray = names.ToArray();
C5.Sorting.IntroSort(nameArray, 0, nameArray.Length-1, Comparer<string>.Default);As these methods sort in-place, an extra array is required to sort generic non-array collections.
Now, using the MergeSorted() method of the PowerCollections library, we can merge two sorted arrays as shown next:
int[] a = new int[] { 1, -1, 0, 4, 44, 22, 12 };
int[] b = new int[] { 2, -3, 3, 34, 14, 21, 11 };
int[] merged = Algorithms.MergeSorted(a, b).ToArray();
C5.Sorting.IntroSort(a);
C5.Sorting.IntroSort(b);
Console.WriteLine("Before sorting and merging");
Algorithms.ForEach(merged, c => Console.Write(c + " "));
Console.WriteLine("
After sorting and merging");
merged = Algorithms.MergeSorted(a, b).ToArray();
Algorithms.ForEach(merged, c => Console.Write(c + " "));This will generate the following output:
Before Sorting and Merging 1 -1 0 2 -3 3 4 34 14 21 11 44 22 12
After Sorting and Merging -3 -1 0 1 2 3 4 11 12 14 21 22 34 44
These sorting methods can be applied to any type of collection as they have overloaded versions where you can pass an IEqualityComparer<T>. The preceding example uses integers as it is easy for most people to get the idea.
So far, we have learned all the .NET Generic classes and related algorithms. In the next and final chapter, we will discuss best practices and performance analysis; this will help you pick the correct tool (I mean correct Generic Collection and correct Generic Algorithm implementation) for efficiently solving a problem.