
An accounting system for the US market is obviously not going to function well, for example, in the Norwegian market. For one thing, the formatting of date, number and currency are not the same—not to mention that the languages in the two markets are different. Adapting programs so that they have global awareness of such differences is called internationalization (a.k.a., “in8ln”). A locale represents a specific geographical, political, or cultural region. Its two most important attributes are language and country. Certain classes in the Java Standard Library provide locale-sensitive operations. For example, they provide methods to format values that represent dates, currency and numbers according to a specific locale. Developing programs that are responsive to a specific locale is called localization.
A locale is represented by an instance of the class java.util.Locale. Many locale-sensitive methods require such an instance for their operation. A locale object can be created using the following constructors:
Locale(String language)
Locale(String language, String country)
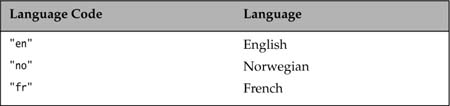
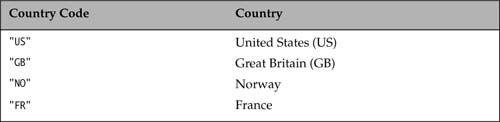
The language argument is an ISO-639-1 Language Code (which uses two lowercase letters), and the country argument is an ISO-3166 Country Code (which uses two uppercase letters).
Examples of selected language codes and country codes are given in Table 12.1 and Table 12.2, respectively.
The Locale class also has predefined locales for certain languages, irrespective of the region where they are spoken (see Table 12.3).

The Locale class also has predefined locales for certain combinations of countries and languages (see Table 12.4).

Normally a program uses the default locale on the platform to provide localization. The Locale class provides a get and set method to manipulate the default locale.
static Locale getDefault()
static void setDefault(Locale newLocale)
The first method returns the current value of the default locale, and the second one sets a specific locale as the default locale.
String getDisplayCountry()
String getDisplayCountry(Locale inLocale)
Returns a name for the locale’s country that is appropriate for display to the user, depending on the default locale in the first method or the inLocale argument in the second method.
String getDisplayLanguage()
String getDisplayLanguage(Locale inLocale)
Returns a name for the locale’s language that is appropriate for display to the user, depending on the default locale in the first method or the inLocale argument in the second method.
String getDisplayName()
String getDisplayName(Locale inLocale)
Returns a name for the locale that is appropriate for display.
A locale is an immutable object, having two sets of get methods to return the display name of the country and the language in the locale. The first set returns the display name of the current locale according to the default locale, while the second set returns the display name of the current locale according to the locale specified as argument in the method call.
Example 12.1 illustrates the use of the get methods in the Locale class. The method call locNO.getDisplayCountry() returns the country display name (Norwegian) of the Norwegian locale according to the default locale (which is the United Kingdom), whereas the method call locNO.getDisplayCountry(locFR) returns the country display name (Norvège) of the Norwegian locale according to the French locale.
Example 12.1 Understanding Locales
import java.util.Locale;
public class LocalesEverywhere {
public static void main(String[] args) {
Locale locDF = Locale.getDefault();
Locale locNO = new Locale("no", "NO"); // Locale: Norwegian/Norway
Locale locFR = new Locale("fr", "FR"); // Locale: French/France
// Display country name for Norwegian locale:
System.out.println("In " + locDF.getDisplayCountry() + "(default)" +
": " + locNO.getDisplayCountry());
System.out.println("In " + locNO.getDisplayCountry() +
": " + locNO.getDisplayCountry(locNO));
System.out.println("In " + locFR.getDisplayCountry() +
": " + locNO.getDisplayCountry(locFR));
// Display language name for Norwegian locale:
System.out.println("In " + locDF.getDisplayCountry() + "(default)" +
": " + locNO.getDisplayLanguage());
System.out.println("In " + locNO.getDisplayCountry() +
": " + locNO.getDisplayLanguage(locNO));
System.out.println("In " + locFR.getDisplayCountry() +
": " + locNO.getDisplayLanguage(locFR));
}
}
Output from the program:
In United Kingdom(default): Norway
In Norway: Norge
In France: Norvège
In United Kingdom(default): Norwegian
In Norway: norsk
In France: norvégien
The Date class represents time as a long integer which is the number of milliseconds measured from January 1, 1970 00:00:00.000 GMT. This starting point is called the epoch. The long value used to represent a point in time comprises both the date and the time of day. The Date class provides the following constructors:
Date()
Date(long milliseconds)
The default constructor returns the current date and time of day. The second constructor returns the date/time corresponding to the specified milliseconds after the epoch.
Some selected methods from the date class are shown below. The Date class has mostly deprecated methods, and provides date operations in terms of milliseconds only. However, it is useful for printing the date value in a standardized long format, as the following example shows:
Tue Mar 04 17:22:37 EST 2008
The Date class is not locale-sensitive, and has been replaced by the Calendar and DateFormat classes. The class overrides the methods clone(), equals(), hashCode(), and toString() from the Object class, and implements the Comparable<Date> interface.
public String toString()
Returns the value of the current Date object in a standardized long format and, if necessary, adjusted to the default time zone.
long getTime()
void setTime(long milliseconds)
The first method returns the value of the current Date object as the number of milliseconds after the epoch. The second method sets the date in the current Date object, measured in milliseconds after the epoch.
boolean after(Date date)
boolean before(Date date)
The methods determine whether the current date is strictly after or before a specified date, respectively.
Example 12.2 illustrates using the Date class. The toString() method (called implicitly in the print statements) prints the date value in a long format. The date value can be manipulated as a long integer, and a negative long value can be used to represent a date before the epoch.
Example 12.2 Using the Date class
import java.util.Date;
public class UpToDate {
public static void main(String[] args) {
// Get the current date:
Date currentDate = new Date();
System.out.println("Date formatted: " + currentDate);
System.out.println("Date value in milliseconds: " + currentDate.getTime());
// Create a Date object with a specific value of time measured
// in milliseconds from the epoch:
Date date1 = new Date(1200000000000L);
// Change the date in the Date object:
System.out.println("Date before adjustment: " + date1);
date1.setTime(date1.getTime() + 1000000000L);
System.out.println("Date after adjustment: " + date1);
// Compare two dates:
String compareStatus = currentDate.after(date1) ? "after" : "before";
System.out.println(currentDate + " is " + compareStatus + " " + date1);
// Set a date before epoch:
date1.setTime(-1200000000000L);
System.out.println("Date before epoch: " + date1);
}
}
Output from the program:
Date formatted: Wed Mar 05 00:37:28 EST 2008
Date value in milliseconds: 1204695448609
Date before adjustment: Thu Jan 10 16:20:00 EST 2008
Date after adjustment: Tue Jan 22 06:06:40 EST 2008
Wed Mar 05 00:37:28 EST 2008 is after Tue Jan 22 06:06:40 EST 2008
Date before epoch: Tue Dec 22 21:40:00 EST 1931
A calendar represents a specific instant in time that comprises a date and a time of day. The abstract class java.util.Calendar provides a rich set of date operations to represent and manipulate many variations on date/time representation. However, the locale-sensitive formatting of the calendar is delegated to the DateFormat class (see Section 12.4).
The following factory methods of the Calendar class create and return an instance of the GregorianCalendar class that represents the current date/time.
Interoperability with the Date class is provided by the following two methods:
Information in a calendar is accessed via a field number. The Calendar class defines field numbers for the various fields (e.g., year, month, day, hour, minutes, seconds) in a calendar. Selected field numbers are shown in Table 12.5. For example, the constant Calendar.Year is the field number that indicates the field with the value of the year in a calendar.
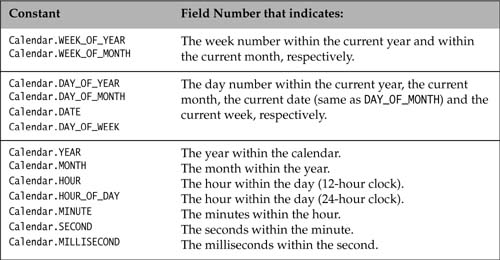
The get() method returns the value of the field designated by the field number passed as argument. The return value of a field is an int. Table 12.6 shows some selected field values that are represented as constants. The first day of the month or year has the value 1. The value of the first day of the week depends on the locale. However, the first month of the year, i.e., Calendar.JANUARY, has the value 0.
Calendar calendar = Calendar.getInstance();
out.println(calendar.getTime()); // Wed Mar 05 16:20:36 EST 2008
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH);
int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH);
out.printf("%4d-%02d-%02d%n", year, month + 1, dayOfMonth); // 2008-03-05

We have added 1 to the month in the last statement, before printing the date.
Particular fields in a calendar can be set to a specific value, or they can be cleared. Many set operations can be done without recomputing and normalizing the values in a calendar. In the code below, the values in the calendar are first recomputed and normalized when the get operation is performed in (3). Note how the day and the month has changed from the values in (1).
out.println(calendar.getTime()); // (1) Wed Mar 05 21:51:57 EST 2008
calendar.set(Calendar.DAY_OF_MONTH, 33); // (2) Set day of month to 33
calendar.set(Calendar.MONTH, Calendar.OCTOBER); // (3) Set month to October.
out.println(calendar.getTime()); // (4) Sun Nov 02 21:51:57 EST 2008
Since not all locales start the week on the same day of the week, the Calendar class provides methods to set and get the first day of the week in a calendar.
out.println(calendar.getFirstDayOfWeek()); // 1
int get(int fieldNumber)
Returns the value of the given calendar field. See Table 12.5 for fields that can be specified.
void set(int fieldNUmber, int fieldValue)
void set(int year, int month, int dayOfMonth)
void set(int year, int month, int dayOfMonth, int hourOfDay, int minute)
void set(int year, int month, int dayOfMonth, int hourOfDay,
int minute, int second)
The first method sets the specified calendar field to the given value. See Table 12.5 for fields that can be specified. See Table 12.6 for values that can be specified for certain fields. The other methods set particular fields. The calendar’s date/time value in milliseconds is not recomputed until the next get operation is performed.
void clear()
void clear(int fieldNumber)
Clear all fields or designated field in the calendar, i.e., sets the field(s) as undefined.
int getFirstDayOfWeek()
void setFirstDayOfWeek(int value)
The first method returns which day of the week is the first day of the week in the calendar. The second method sets a particular day as the first day of the week (see Table 12.6 for valid values).
The following code illustrates how the add() method works. Note how, when we added 13 months to the calendar, the number of months is normalized and the year has been incremented, as 13 months is 1 year and 1 month.
out.println(calendar.getTime()); // Wed Mar 05 22:03:29 EST 2008
calendar.add(Calendar.MONTH, 13); // Add 13 more months
out.println(calendar.getTime()); // Sun Apr 05 22:03:29 EDT 2009
The following code illustrates how the roll() method is different from the add() method. Note how, when we added 13 months to the calendar now, only the number of months is normalized but the year is not incremented, i.e., the roll() method does not recompute larger fields as a consequence of normalizing smaller fields.
out.println(calendar.getTime()); // Wed Mar 05 22:03:29 EST 2008
calendar.roll(Calendar.MONTH, 13); // Add 13 more months
out.println(calendar.getTime()); // Sat Apr 05 22:03:29 EDT 2008
void add(int field, int amount)
This is equivalent to calling set(field, get(field) + amount). All fields are recomputed.
void roll(int field, int amount)
This is equivalent to calling add(field,amount), but larger fields are unchanged. A positive amount means rolling up, a negative amount means rolling down.
int compareTo(Calendar anotherCalendar)
Implements Comparable<Calendar>, thus calendars can be compared (as offsets in milliseconds from the epoch).
Example 12.3 shows further examples of using the methods in the Calendar class. It is instructive to compare the code with the output from the program.
Example 12.3 Using the Calendar Class
import java.util.Calendar;
import java.util.Date;
public class UsingCalendar {
public static void main(String[] args) {
// Get a calendar with current time and print its date:
Calendar calendar = Calendar.getInstance();
printDate("The date in the calendar: ", calendar);
// Convert to Date:
Date date1 = calendar.getTime();
System.out.println("The date in the calendar: " + date1);
// Set calendar according to a Date:
Date date2 = new Date(1200000000000L);
System.out.println("The date is " + date2);
calendar.setTime(date2);
printDate("The date in the calendar: ", calendar);
// Set values in a calendar
calendar.set(Calendar.DAY_OF_MONTH, 33);
calendar.set(Calendar.MONTH, 13);
calendar.set(Calendar.YEAR, 2010);
printDate("After setting: ", calendar);
// Adding to a calendar
calendar.add(Calendar.MONTH, 13);
printDate("After adding: ", calendar);
// Rolling a calendar
calendar.roll(Calendar.MONTH, 13);
printDate("After rolling: ", calendar);
// First day of the week.
System.out.println((calendar.SUNDAY == calendar.getFirstDayOfWeek() ?
"Sunday is" : "Sunday is not" ) +
" the first day of the week.");
}
static private void printDate(String prompt, Calendar calendar) {
System.out.print(prompt);
System.out.printf("%4d/%02d/%02d%n",
calendar.get(Calendar.YEAR),
(calendar.get(Calendar.MONTH) + 1), // Adjust for month
calendar.get(Calendar.DAY_OF_MONTH));
}
}
Output from the program:
The date in the calendar: 2008/03/05
The date in the calendar: Wed Mar 05 21:31:26 EST 2008
The date is Thu Jan 10 16:20:00 EST 2008
The date in the calendar: 2008/01/10
After setting: 2011/02/10
After adding: 2012/03/10
After rolling: 2012/04/10
Sunday is not the first day of the week.
For dealing with text issues like formatting and parsing dates, time, currency and numbers, the Java Standard Library provides the java.text package. The abstract class DateFormat in this package provides methods for formatting and parsing dates and time.
See also the discussion in Section 12.7, Formatting Values, p. 593.
The class DateFormat provides formatters for dates, time of day, and combinations of date and time for the default locale or for a specified locale. The factory methods provide a high degree of flexibility when it comes to mixing and matching different formatting styles and locales. However, the formatting style and the locale cannot be changed after the formatter is created. The factory methods generally return an instance of the concrete class SimpleDateFormat, which is a subclass of DateFormat.
static DateFormat getInstance()
Returns a default date/time formatter that uses the DateFormat.SHORT style for both the date and the time (see also See Table 12.7).
static DateFormat getDateInstance()
static DateFormat getDateInstance(int dateStyle)
static DateFormat getDateInstance(int dateStyle, Locale loc)
static DateFormat getTimeInstance()
static DateFormat getTimeInstance(int timeStyle)
static DateFormat getTimeInstance(int timeStyle, Locale loc)
static DateFormat getDateTimeInstance()
static DateFormat getDateTimeInstance(int dateStyle, int timeStyle)
static DateFormat getDateTimeInstance(int dateStyle, int timeStyle,
Locale loc)
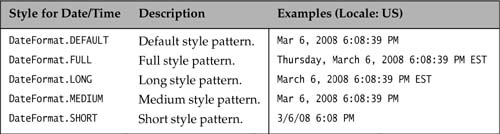
The first three methods return a formatter for dates. The next three methods return a formatter for time of day. The last three methods return a formatter for date and time. The no-argument methods return a formatter in default style(s) and in default locale.
The arguments dateStyle and timeStyle specify the style that should be used for formatting. See Table 12.7 for formatting styles. The styles DateFormat.DEFAULT and DateFormat.MEDIUM are equivalent.
A date/time formatter can be applied to a Date object by calling the format() method. The value of the Date object is formatted according to the formatter used.
Example 12.4 shows the result of formatting the current date/time with the same formatting style for both the date and the time, according to the US locale.
Example 12.4 Formatting Date/Time
import java.text.DateFormat;
import java.util.Date;
import java.util.Locale;
class UsingDateFormat {
public static void main(String[] args) {
// Create some date/time formatters:
DateFormat[] dateTimeFormatters = new DateFormat[] {
DateFormat.getDateTimeInstance(DateFormat.FULL, DateFormat.FULL,
Locale.US),
DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG,
Locale.US),
DateFormat.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM,
Locale.US),
DateFormat.getDateTimeInstance(DateFormat.SHORT, DateFormat.SHORT,
Locale.US)
};
// Style names:
String[] styles = { "FULL", "LONG", "MEDIUM", "SHORT" };
// Format current date/time using different date formatters:
Date date = new Date();
int i = 0;
for(DateFormat dtf : dateTimeFormatters)
System.out.printf("%-6s: %s%n", styles[i++], dtf.format(date));
}
}
Output from the program:
FULL : Thursday, March 6, 2008 6:08:39 PM EST
LONG : March 6, 2008 6:08:39 PM EST
MEDIUM: Mar 6, 2008 6:08:39 PM
SHORT : 3/6/08 6:08 PM
Although we have called it a date/time formatter, the instance returned by the factory methods mentioned earlier is also a parser that converts strings into date/time values. Example 12.5 illustrates the parsing of strings to date/time values. It uses the Norwegian locale defined at (1). Four locale-specific date formatters are created at (2). Each one is used to format the current date and the resulting string is parsed back to a Date object:
String strDate = df.format(date); // (4)
Date parsedDate = df.parse(strDate); // (5)
The string is parsed according to the locale associated with the formatter. Being lenient during parsing means allowing values that are incorrect or incomplete. Lenient parsing is illustrated at (6):
System.out.println("32.01.08|" + dateFormatters[0].parse("32.01.08|"));
The string "32.01.08|" is parsed by the date formatter according to the Norwegian locale. Although the value 32 is invalid for the number of days in a month, the output shows that it was normalized correctly. A strict formatter would have thrown a ParseException. Since the string was parsed to a date, default values for the time are set in the Date object. Also, trailing characters in the string after the date are ignored. The formatting style in the date formatter (in this case, DateFormat.SHORT) and the contents of the input string (in this case, "32.01.08") must be compatible with each other. Note that in the print statement, the Date object from the parsing is converted to a string according to the default locale:
32.01.08|Fri Feb 01 00:00:00 EST 2008
Date parse(String str) throws ParseException
Parses the specified string for date/time. No leading white space is allowed. Trailing characters after the date are ignored. Throws java.text.ParseException if unsuccessful.
void setLenient(boolean lenient)
boolean isLenient()
Sets or gets the status whether parsing should be lenient or strict. Default behavior is lenient parsing.
Example 12.5 Using the DateFormat class
import java.text.DateFormat;
import java.text.ParseException;
import java.util.Date;
import java.util.Locale;
class FormattingDates {
public static void main(String[] args) throws ParseException {
// Locale to use:
Locale localeNOR = new Locale("no", "NO"); // (1) Norway
// Create some date formatters: (2)
DateFormat[] dateFormatters = new DateFormat[] {
DateFormat.getDateInstance(DateFormat.SHORT, localeNOR),
DateFormat.getDateInstance(DateFormat.MEDIUM,localeNOR),
DateFormat.getDateInstance(DateFormat.LONG, localeNOR),
DateFormat.getDateInstance(DateFormat.FULL, localeNOR)
};
// Parsing the date: (3)
System.out.println("Parsing:");
Date date = new Date();
for(DateFormat df : dateFormatters)
try {
String strDate = df.format(date); // (4)
Date parsedDate = df.parse(strDate); // (5)
System.out.println(strDate + "|" + df.format(parsedDate));
} catch (ParseException pe) {
System.out.println(pe);
}
// Leniency: (6)
System.out.println("Leniency:");
System.out.println("32.01.08|" + dateFormatters[0].parse("32.01.08|"));
}
}
Output from the program:
Parsing:
07.03.08|07.03.08
07.mar.2008|07.mar.2008
7. mars 2008|7. mars 2008
7. mars 2008|7. mars 2008
Leniency:
32.01.08|Fri Feb 01 00:00:00 EST 2008
Each date/time formatter has a Calendar that is used to produce the date/time values from the Date object. In addition, a formatter has a number formatter (NumberFormat, Section 12.5) that is used to format the date/time values. The calendar and the number formatter are associated when the date/time formatter is created, but they can also be set programmatically by using the methods shown below.
The abstract class NumberFormat provides methods for formatting and parsing numbers and currency values. Using a NumberFormat is in many ways similar to using a DateFormat.
See also the discussion in Section 12.7, Formatting Values, p. 593.
The NumberFormat class provides factory methods for creating locale-sensitive formatters for numbers and currency values. However, the locale cannot be changed after the formatter is created. The factory methods return an instance of the concrete class java.text.DecimalFormat or an instance of the final class java.util.Currency for formatting numbers or currency values, respectively. Although we have called the instance a formatter, it is also a parser—analogous to using a date/time formatter.
static NumberFormat getNumberInstance()
static NumberFormat getNumberInstance(Locale loc)
static NumberFormat getCurrencyInstance()
static NumberFormat getCurrencyInstance(Locale loc)
The first two methods return a general formatter for numbers, i.e., a number formatter. The next two methods return a formatter for currency amounts, i.e., a currency formatter.
A number formatter can be used to format a double or a long value. Depending on the number formatter, the formatting is locale-sensitive: either default or specific.
The following code shows how we can create a number formatter for the Norwegian locale and use it to format numbers according to this locale. Note the grouping of the digits and the decimal sign used in formatting according to this locale.
Double num = 12345.6789;
Locale locNOR = new Locale("no", "NO"); // Norway
NumberFormat nfNOR = NumberFormat.getNumberInstance(locNOR);
String formattedNumStr = nfNOR.format(num);
System.out.println(formattedNumStr); // 12 345,679
The following code shows how we can create a currency formatter for the Norwegian locale, and use it to format currency values according to this locale. Note the currency symbol and the grouping of the digits, with the amount being rounded to two decimal places.
NumberFormat cfNOR = NumberFormat.getCurrencyInstance(locNOR);
String formattedCurrStr = cfNOR.format(num);
System.out.println(formattedCurrStr); // kr 12 345,68
String format(double d)
String format(long l)
Formats the specified number and returns the resulting string.
Currency getCurrency()
void setCurrency(Currency currency)
The first method returns the currency object used by the formatter. The last method allows the currency symbol to be set explicitly in the currency formatter, according to the ISO 4217 currency codes. For example, we can set the Euro symbol in a fr_France currency formatter with this method.
A number formatter can be used to parse strings that are textual representations of numeric values. The following code shows the Norwegian number formatter from above being used to parse strings. In (1), the result is a long value because the dot (.) in the input string is not a legal character according to the number format used in the Norwegian locale. In (2), the result is a double value because the comma (,) in the input string is the decimal sign in the Norwegian locale. Note that the print statement prints the resulting number according to the default locale.
out.println(nfNOR.parse("9876.598")); // (1) 9876
out.println(nfNOR.parse("9876,598")); // (2) 9876.598
The following code demonstrates using a currency formatter as a parser. Note that the currency symbol is interpreted according to the locale in the currency parser. In (3), although a space is a grouping character in the Norwegian locale when formatting currency values, it is a delimiter in the input string.
out.println(cfNOR.parse("kr 9876.598")); // 9876
out.println(cfNOR.parse("kr 9876,598")); // 9876.598
out.println(cfNOR.parse("kr 9 876,59")); // (3) 9
Number parse(String str) throws ParseException
Parses the specified string either to a Double or Long. No leading white space is allowed. Trailing characters after the number are ignored. Throws java.text.ParseException if unsuccessful.
void setParseIntegerOnly(boolean intOnly)
boolean isParseIntegerOnly()
Sets or gets the status whether this formatter should only parse integers.
The following methods allow the formatting of numbers to be further refined by setting the number of digits to be allowed in the integer and the decimal part of a number. However, a concrete number formatter can enforce certain limitations on these bounds.
void setMinimumIntegerDigits(int n)
int getMinimumIntegerDigits()
void setMaximumIntegerDigits(int n)
int getMaximumIntegerDigits()
void setMinimumFractionDigits(int n)
int getMinimumFractionDigits()
void setMaximumFractionDigits(int n)
int getMaximumFractionDigits()
Sets or gets the minimum or maximum number of digits to be allowed in the integer or decimal part of a number.
Example 12.6 further demonstrates the usage of number/currency formatters/ parsers. It uses two methods: runFormatters() and runParsers() declared at (1) and(2), respectively. The first one runs formatters supplied in an array on a specified numeric value, and the second one runs the formatters supplied in an array as parsers on an input string. Since the NumberFormat class does not provide a method for determining the locale of a formatter, an array of locales is used to supply this information. Note that the parsing succeeds if the input string is conducive to the locale used by the parser.
Example 12.6 Using the NumberFormat class
import java.text.NumberFormat;
import java.text.ParseException;
import java.util.Locale;
import static java.lang.System.out;
public class FormattingNumbers {
public static void main(String[] args) {
// Create an array of locales:
Locale[] locales = {
Locale.getDefault(), // Default: GB/UK
new Locale("no", "NO"), // Norway
Locale.JAPAN // Japan
};
// Create an array of number formatters:
NumberFormat[] numFormatters = new NumberFormat[] {
NumberFormat.getNumberInstance(), // Default: GB/UK
NumberFormat.getNumberInstance(locales[1]), // Norway
NumberFormat.getNumberInstance(locales[2]) // Japan
};
// Create an array of currency formatters:
NumberFormat[] currFormatters = new NumberFormat[] {
NumberFormat.getCurrencyInstance(), // Default: GB/UK
NumberFormat.getCurrencyInstance(locales[1]), // Norway
NumberFormat.getCurrencyInstance(locales[2]) // Japan
};
// Number to format:
double number = 9876.598;
// Format a number by different number formatters:
out.println("Formatting the number: " + number);
runFormatters(number, numFormatters, locales);
// Set the max decimal digits to 2 for number formatters:
for (NumberFormat nf : numFormatters) {
nf.setMaximumFractionDigits(2);
}
out.println("
Formatting the number " + number + " (to 2 dec. places):");
runFormatters(number, numFormatters, locales);
// Format a currency amount by different currency formatters:
out.println("
Formatting the currency amount: " + number);
runFormatters(number, currFormatters, locales);
// Parsing a number:
runParsers("9876.598", numFormatters, locales);
runParsers("9876,598", numFormatters, locales);
runParsers("9876@598", numFormatters, locales);
runParsers("@9876598", numFormatters, locales); // Input error
// Parsing a currency amount:
runParsers("£9876.598", currFormatters, locales);
runParsers("kr 9876,598", currFormatters, locales);
runParsers("JPY 98@76598", currFormatters, locales);
runParsers("@9876598", currFormatters, locales); // Input error
}
/** Runs the formatters on the value. */
static void runFormatters(double value, NumberFormat[] formatters, // (1)
Locale[] locales) {
for(int i = 0; i < formatters.length; i++)
out.printf("%-24s: %s%n", locales[i].getDisplayName(),
formatters[i].format(value));
}
/** Runs the parsers on the input string. */
static void runParsers(String inputString, NumberFormat[] formatters, // (2)
Locale[] locales) {
out.println("
Parsing: " + inputString);
for(int i = 0; i < formatters.length; i++)
try {
out.printf("%-24s: %s%n", locales[i].getDisplayName(),
formatters[i].parse(inputString));
} catch (ParseException pe) {
out.println(pe);
}
}
}
Formatting the number: 9876.598
English (United Kingdom) : 9,876.598
Norwegian (Norway) : 9 876,598
Japanese (Japan) : 9,876.598
Formatting the number 9876.598 (to 2 dec. places):
English (United Kingdom) : 9,876.6
Norwegian (Norway) : 9,876,6
Japanese (Japan) : 9,876.6
Formatting the currency amount: 9876.598
English (United Kingdom) : £9,876.60
Norwegian (Norway) : kr 9 876,60
Japanese (Japan) : JPY 9,877
Parsing: 9876.598
English (United Kingdom) : 9876.598
Norwegian (Norway) : 9876
Japanese (Japan) : 9876.598
Parsing: 9876,598
English (United Kingdom) : 9876598
Norwegian (Norway) : 9876.598
Japanese (Japan) : 9876598
Parsing: 9876@598
English (United Kingdom) : 9876
Norwegian (Norway) : 9876
Japanese (Japan) : 9876
Parsing: @9876598
java.text.ParseException: Unparseable number: "@9876598"
java.text.ParseException: Unparseable number: "@9876598"
java.text.ParseException: Unparseable number: "@9876598"
Parsing: £9876.598
English (United Kingdom): 9876.598
java.text.ParseException : Unparseable number: "£9876.598"
java.text.ParseException : Unparseable number: "£9876.598"
Parsing: kr 9876,598
java.text.ParseException: Unparseable number: "kr 9876,598"
Norwegian (Norway) : 9876.598
java.text.ParseException: Unparseable number: "kr 9876,598"
Parsing: JPY 98@76598
java.text.ParseException: Unparseable number: "JPY 98@76598"
java.text.ParseException: Unparseable number: "JPY 98@76598"
Japanese (Japan) : 98
Parsing: @9876598
java.text.ParseException: Unparseable number: "@9876598"
java.text.ParseException: Unparseable number: "@9876598"
java.text.ParseException: Unparseable number: "@9876598"
12.1 The language and the country of the UK locale are "anglais" and "Royaume-Uni" in the France locale, respectively, and the language and the country of the France locale are "French" and "France" in the UK locale, respectively. What will the following program print when compiled and run?
public class LocaleInfo {
public static void main(String[] args) {
printLocaleInfo(Locale.UK, Locale.FRANCE);
printLocaleInfo(Locale.FRANCE, Locale.UK);
}
public static void printLocaleInfo(Locale loc1, Locale loc2) {
System.out.println(loc1.getDisplayLanguage(loc2) + ", " +
loc2.getDisplayCountry(loc1));
}
}
Select the one correct answer.
(a) French, Royaume-Uni
anglais, France
(b) anglais, Royaume-Uni
French, France
(c) anglais, France
French, Royaume-Uni
(d) French, France
anglais, Royaume-Uniint i = 0;
12.2 Which statements are not true about the java.util.Date class?
Select the two correct answers.
(a) The java.util.Date class implements the Comparable<Date> interface.
(b) The java.util.Date class is locale-sensitive.
(c) The default constructor of the java.util.Date class returns the current date/ time.
(d) The non-default constructor of the java.util.Date class throws an IllegalArgumentException if the argument value is negative.
12.3 Which code, when inserted at (1), will not set the date to 1. January 2009?
public class ChangingDate {
public static void main(String[] args) {
// Create a calendar that is set to 31. December 2008:
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.DAY_OF_MONTH, 31);
calendar.set(Calendar.MONTH, Calendar.DECEMBER);
calendar.set(Calendar.YEAR, 2008);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.HOUR_OF_DAY, 0);
// (1) INSERT CODE HERE ...
System.out.println(calendar.getTime());
}
}
Select the two correct answers.
(a) calendar.set(Calendar.DAY_OF_MONTH, 1);
(b) calendar.set(Calendar.MONTH, Calendar.JANUARY);
(c) calendar.set(Calendar.YEAR, 2009);
(d) calendar.set(Calendar.DAY_OF_MONTH, 1);
(e) calendar.set(Calendar.MONTH, 12);
(f) calendar.add(Calendar.DAY_OF_MONTH, 1);
(g) calendar.roll(Calendar.DAY_OF_MONTH, 1);
(h) calendar.set(2009, 0, 1);
(i) calendar.set(2009, 1, 1);
12.4 Which code, when inserted at (1), will make the program compile and execute normally?
public class Dating {
public static void main(String[] args) {
Date date = new Date();
// (1) INSERT CODE HERE ...
}
}
Select the one correct answer.
(a) DateFormat df = new DateFormat(Locale.US);
System.out.println(df.format(date));
(b) DateFormat df = new DateFormat(DateFormat.FULL, Locale.US);
System.out.println(df.format(date));
(c) DateFormat df = DateFormat.getDateTimeInstance(DateFormat.FULL, Locale.US);
System.out.println(df.format(date));
(d) DateFormat df = DateFormat.getDateTimeInstance(date);
System.out.println(df.format(DateFormat.FULL, Locale.US));
(e) DateFormat df = DateFormat.getDateInstance(DateFormat.FULL, Locale.US);
System.out.println(df.format(date));
12.5 Which code, when inserted at (1), will not make the program compile and execute normally? Assume that the order of the values in a date is according to the US locale: month, day of month, and year, respectively.
public class ParsingDates {
public static void main(String[] args) throws ParseException {
// (1) INSERT DECLARATION HERE ...
System.out.println(parseDate(inputStr));
}
public static Date parseDate(String inputString) throws ParseException {
DateFormat dfUS = DateFormat.getDateInstance(DateFormat.SHORT, Locale.US);
return dfUS.parse(inputString);
}
}
Select the one correct answer.
(a) String inputStr = "3/7/08";
(b) String inputStr = "03/07/08";
(c) String inputStr = "3/37/08";
(d) String inputStr = "13/07/08";
(e) String inputStr = "3/07/08/2008";
(f) String inputStr = " 3/07/08 ";
(g) String inputStr = "Mar 7, 2008";
12.6 Which statement is true about the program? Assume that the decimal sign is a dot (.) and the grouping character is a comma (,) for the US locale.
public class ParsingNumbers {
public static void main(String[] args) {
// (1) DECLARATION INSERTED HERE ...
System.out.println(parseNumber(inputStr));
}
public static Number parseNumber(String inputString) {
NumberFormat nfUS = NumberFormat.getNumberInstance(Locale.US);
Double num = nfUS.parse(inputString);
return num;
}
}
Select the one correct answer.
(a) The following declaration, when inserted at (1), will result in the program compiling without errors and executing normally:
String inputStr = "1234.567";
(b) The following declaration, when inserted at (1), will result in the program compiling without errors and executing normally:
String inputStr = "0.567";
(c) The following declaration, when inserted at (1), will result in the program compiling without errors and executing normally:
String inputStr = "1234..";
(d) The following declaration, when inserted at (1), will result in the program compiling without errors and executing normally:
String inputStr = "1,234.567";
(e) The following declaration, when inserted at (1), will result in the program compiling without errors and executing normally:
String inputStr = "1 234.567";
(f) Regardless of which declaration from (a) to (e) is inserted for the input reference at (1), the program will not compile.
(g) Regardless of which declaration from (a) to (e) is inserted for the input reference at (1), the program will compile, but result in an exception at runtime.
Using patterns to search for sequences of characters (i.e., strings) in the input is a powerful technique that can be used to search, modify, and maintain text-based data (e.g., XML data, log files, comma-separated values (CSV)). The java.util.regex package in the Java Standard Library provides support for string pattern matching that is based on regular expressions. Such an expression is specified using a special notation, which is precisely defined. A regular expression thus defines a pattern that represents a set of strings that we are interested in matching against characters in the input. We will use the term regular expression and pattern synonymously.
Before we can do string pattern matching with a regular expression, we have to compile it, i.e., turn it into a representation that can be used with an engine (also called an automaton) that can read the characters in the input and match them against the pattern. As we shall see, the java.util.Pattern class allows us to compile a regular expression, and the java.util.Matcher class allows us to create an engine for string pattern matching with the compiled regular expression.
The description of regular expressions presented here is by no means exhaustive. It should be regarded as a basic introduction, providing the fundamentals to go forth and explore the exciting world of regular expressions.
The simplest form of a pattern is a character or a sequence of characters that matches itself. The pattern o, comprising the character o, will only match itself in the target string (i.e., the input).
Index: 01234567890123456789012345678901234567
Target: All good things come to those who wait
Pattern: o
Match: (5,5:o)(6,6:o)(17,17:o)(22,22:o)(26,26:o)(32,32:o)
The characters in the target are read from left to right sequentially and matched against the pattern. A match is announced when the pattern matches a particular occurrence of (zero or more) characters in the target. Six matches were found for the pattern o in the given target. A match is shown in the following notation:
(start_index,end_index:group)
where start_index and end_index are indices in the target indicating where a pattern match was found, and group comprises the character(s) delineated by the two indices in the target, that matched the pattern. (Example 12.8, p. 568, was used to generate all regular expression examples presented in this subsection.)
The example below searches for the pattern who in the given target, showing that three matches were found:
Index: 012345678901234567890123456789012345678
Target: Interrogation with who, whose and whom.
Pattern: who
Match: (19,21:who)(24,26:who)(34,36:who)
The regular expression notation uses a number of metacharacters (, [], -, ^, $, ., ?, *, +, (), |) to define its constructs, i.e., these characters have a special meaning when used in a regular expression. A character is often called a non-metacharacter when it is not supposed to have any special meaning.
Table 12.8 shows regular expressions for matching a single character in the input. Examples of regular expressions with non-metacharacters were shown earlier. Such regular expressions match themselves in the input.

The pattern will match a tab character in the input, and the pattern
will match a newline in the input. Since the backslash () is a metacharacter, we need to escape it (\) in order to use it as a non-metacharacter in a pattern. Any metacharacter in a pattern can be escaped with a backslash (). Note the similarity with escape sequences in Java strings, which also use the character as the escape character.
The notation [] can be used to define a pattern that represents a set of characters, called a character class. Table 12.9 shows examples of such patterns. A ^ character is interpreted as a metacharacter when specified immediately after the [ character. In this context, it negates all the characters in the set. Anywhere else in the [] construct, it is a non-metacharacter. The pattern [^aeiouAEIOU] represents the set of all characters that excludes all vowels, i.e., it matches any character that is not a vowel.
Index: 012345678901
Target: I said I am.
Pattern: [^aeiouAEIOU]
Match: (1,1: )(2,2:s)(5,5:d)(6,6: )(8,8: )(10,10:m)(11,11:.)

The - character is used to specify intervals inside the [] notation. If the interval cannot be determined for a - character, it is treated as a non-metacharacter. For example, in the pattern [-A-Z], the first - character is interpreted as a non-metacharacter, but the second occurrence is interpreted as a metacharacter that represents an interval.
Index: 0123456789012
Target: I-love-REGEX.
Pattern: [-A-Z]
Match: (0,0:I)(1,1:-)(6,6:-)(7,7:R)(8,8:E)(9,9:G)(10,10:E)(11,11:X)
Except for the metacharacter which retains its meaning, the other metacharacters $, ., ?, *, +, (, ) and | are recognized as non-metacharacters in a [] construct.
Table 12.10 shows a shorthand for writing some selected character classes. Note that a character class matches one single character at a time in the output, and not a sequence of characters (unless it has only one character). The metacharacter . should be paid special attention to, as it will match one occurrence of any single character.
Index: 0123456789012345678901234567890123456789012345678901234567890
Target: Who is who? Whose is it? To whom it may concern. How are you?
Pattern: .[Hh]o
Match: (0,2:Who)(7,9:who)(12,14:Who)(28,30:who)(48,50: Ho)

Here is another example, using a predefined character class in a pattern to recognize a date or time format:
Index: 012345678901234567890
Target: 01-03-49 786 09-09-09
Pattern: dd-dd-dd
Match: (0,7:01-03-49)(13,20:09-09-09)
Sometimes we are interested in finding a pattern match at either the beginning or the end of a string/line. This can be achieved by using boundary matchers (also called anchors), as shown in Table 12.11. Here is an example of a simple pattern to determine if the input ends in a ? character. We have to escape the ? character in order to use it as a non-metacharacter in the pattern. Note that, except for the ? character at the end of the input, the other ? characters in the input are not recognized.
Index: 01234567890123456789012345678
Target: Who is who? Who me? Who else?
Pattern: ?$
Match: (28,28:?)
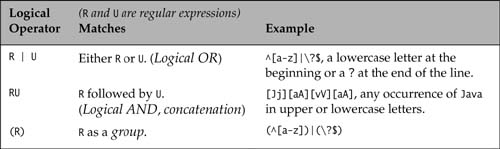
Table 12.12 shows logical operators that we can use to create more complex regular expressions. The logical operators are shown in increasing order of precedence, analogous to the logical operators in boolean expressions. Here is an example that uses all three logical operators for recognizing any case-insensitive occurrence of Java or C++ in the input:
Index: 01234567890123456789012345678901
Target: JaVA jAvA C++ jAv c+++1 javan C+
Pattern: ([Jj][aA][vV][aA])|([Cc]++)
Match: (0,3:JaVA)(5,8:jAvA)(10,12:C++)(18,20:c++)(24,27:java)
Quantifiers are powerful operators that repeatedly try to match a regular expression with the remaining characters in the input. These quantifiers (also called repetition operators) are defined as follows:
• R?, that matches the regular expression R zero or one time.
• R*, that matches the regular expression R zero or more times.
• R+, that matches the regular expression R one or more times.
The pattern a? is matched with a target string in the following example:
Index: 012345
Target: banana
Pattern: a?
Match: (0,0:)(1,1:a)(2,2:)(3,3:a)(4,4:)(5,5:a)(6,6:)
The pattern a? is interpreted as an a or as the empty string. There is a match with the pattern a? at every character in the target. When the current character is not an a in the target, the empty string is returned as the match. We can regard this as the engine inserting empty strings in the input to match the pattern a?. This behavior does not alter the target.
The pattern dd?-dd?-dd? is used as a simplified date format in the following example. The regular expression dd? represents any one or any two digits.
Index: 01234567890123456789012345678901
Target: 01-3-49 23-12 9-09-09 01-01-2010
Pattern: dd?-dd?-dd?
Match: (0,6:01-3-49)(14,20:9-09-09)(22,29:01-01-20)
The pattern a* is interpreted as a non-zero sequence of a’s or as the empty string (meaning no a’s). The engine returns an empty string as the match, when the character in the input cannot be a part of a sequence of a’s.
Index: 01234567
Target: baananaa
Pattern: a*
Match: (0,0:)(1,2:aa)(3,3:)(4,4:a)(5,5:)(6,7:aa)(8,8:)
The pattern (0|[1-9]d*).dd recognizes all non-zero-leading, positive floating-point numbers that have at least one digit in the integral part and exactly two decimal places. Note that the regular expression d* is equivalent to the regular expression [0-9]*.
Index: 0123456789012345678901234567890
Target: .50 1.50 0.50 10.50 00.50 1.555
Pattern: (0|[1-9]d*).dd
Match: (4,7:1.50)(9,12:0.50)(14,18:10.50)(21,24:0.50)(26,29:1.55)
The regular expression d* used in the above pattern represents a sequence of digits or the empty string. A sequence of digits is some permutation of the digits from 0 to 9. In other words, the regular expression d* represents all permutations of digits, which is also all non-negative integers, plus the empty string.
The pattern a+ is interpreted as a non-zero sequence of a’s, i.e., at least one a. Compare the results below with the results for using the pattern a* above on the same target. No empty strings are returned when an a cannot be matched in the target.
Index: 01234567
Target: baananaa
Pattern: a+
Match: (1,2:aa)(4,4:a)(6,7:aa)
The regular expression d+ represents all permutations of digits. The pattern d+.d+ represents all positive floating-point numbers that have at least one digit in the integral part and at least one digit in the fraction part. Note that d+ is equivalent to [0-9]+.
Index: 01234567890123456789012345678
Target: .50 1.50 0. 10.50 00.50 1.555
Pattern: d+.d+
Match: (4,7:1.50)(12,16:10.50)(18,22:00.50)(24,28:1.555)
The quantifiers presented above are called greedy quantifiers. Such a quantifier reads as much input as possible, and backtracks if necessary, to match as much of the input as possible. In other words, it will return the longest possible match. An engine for a greedy quantifier is eager to return a match. If it backtracks, it will do so until it finds the first valid match.
The example below illustrates greediness. The pattern <.+> is supposed to recognize a tag, i.e., a non-zero sequence of characters enclosed in angle brackets (< >). The example below shows that only one tag is found in the target. The greedy quantifier + returns the longest possible match in the input.
Index: 012345678901234567890123456789012345678901234
Target: My <>very<> <emphasis>greedy</emphasis> regex
Pattern: <.+>
Match: (3,38:<>very<> <emphasis>greedy</emphasis>)
There are counterparts to the greedy quantifiers called the reluctant and the possessive quantifiers (see Table 12.12). A reluctant quantifier (also called lazy quantifier) only reads enough of the input to match the pattern. Such a quantifier will apply its regular expression as few times as possible, only expanding the match as the engine backtracks to find a match for the overall regular expression. In other words, it will return the shortest possible match.

The example below illustrates reluctantness/laziness. The pattern <.+?> uses the reluctant quantifier +?, and is supposed to recognize a tag as before. The example below shows the result of applying the pattern to a target. The reluctant quantifier +? returns the shortest possible match for each tag recognized in the input.
Index: 012345678901234567890123456789012345678901234567
Target: My <>very<> <emphasis>reluctant</emphasis> regex
Pattern: <.+?>
Match: (3,10:<>very<>)(12,21:<emphasis>)(31,41:</emphasis>)
The result is certainly better with the reluctant quantifier. We can improve the matching by using the trick shown in this pattern: <[^>]+>. Since the match has two enclosing angle brackets, the pattern negates the end angle bracket, creating a character class that excludes the end angle bracket. The engine can keep expanding the tag name as long as no end angle bracket is found in the input. When this bracket is found in the input, a match can be announced, without incurring the penalty of backtracking. Note that the pattern below is using the greedy quantifier +.
Index: 01234567890123456789012345678901234567890123456
Target: My <>very<> <emphasis>powerful</emphasis> regex
Pattern: <[^>]+>
Match: (12,21:<emphasis>)(30,40:</emphasis>)
Lastly, there are the possessive quantifiers that always consume the entire input, and then go for one make-or-break attempt to find a match. A possessive quantifier never backtracks, even if doing so would succeed in finding a match. There are certain situations where possessive quantifiers can outperform the other types of quantifiers, but we will not pursue the subject any further in this book.
A regular expression can be specified as a string expression in a Java program. In the declaration below, the string literal "who" contains the pattern who.
String p1 = "who"; // regex: who
The pattern d represents a single digit character. If we are not careful in how we specify this pattern in a string literal, we run into trouble.
String p2 = "d"; // Java compiler: Invalid escape sequence!
The escape sequence d is invalid in the string literal above. Both string literals and regular expressions use a backslash () to escape metacharacters. For every backslash in a regular expression, we need to escape it in the string literal, i.e. specify it as a backslash pair (\). This ensures that the Java compiler accepts the string literal, and the string will contain only one backslash for every backslash pair that is specified in the string literal. A backslash contained in the string is thus interpreted correctly as a backslash in the regular expression.
String p3 = "\d"; // regex: d
String p4 = "\."; // regex: . (i.e. the . non-metacharacter)
String p5 = "."; // regex: . (i.e. the . metacharacter)
If we want to use a backslash as a non-metacharacter in a regular expression, we have to escape the backslash (), i.e use the pattern \. In order to escape these two backslashes in a string literal, we need to specify two consecutive backslash pairs (\\). Each backslash pair becomes a single backslash inside the string, resulting in the two pairs becoming a single backslash pair, which is interpreted correctly in the regular expression, as the two backslash characters represent a backslash non-metacharacter.
String nonMetaBackslash = "\\"; // regex: \ (i.e. the non-metacharacter)
Below are examples of string literals for some of the regular expressions we have seen earlier. Each backslash in the regular expression is escaped in the string literal.
String p6 = "\d\d-\d\d-\d\d"; // regex: dd-dd-dd
String p7 = "\d+\.\d+"; // regex: d+.d+
String p8 = "(^[a-z])|(\?$)"; // regex: (^[a-z])|(?$)
The two classes Pattern and Matcher in the java.util.regex package embody the paradigm for working efficiently with regular expressions in Java. It consists of the following steps:
1. Compiling the regular expression string into a Pattern object which constitutes the compiled representation of the regular expression (i.e., a pattern) mentioned earlier:
Pattern pattern = Pattern.compile(regexStr);
2. Using the Pattern object to obtain a Matcher (i.e., an engine) for applying the pattern to a specified input of type java.lang.CharSequence:
Matcher matcher = pattern.matcher(input);
3. Using the operations of the matcher to apply the pattern to the input:
boolean eureka = matcher.matches();
The approach outlined above is recommended, as it avoids compiling the regular expression string repeatedly, and it is specially optimized for using the same pattern multiple times on the same input or different inputs. When used on the same input repeatedly, the pattern can be used to find multiple matches.
As mentioned above, the input must be of type CharSequence, which is a readable sequence of char values. The interface CharSequence is implemented by such classes as String and StringBuilder.
With the setup outlined above, it is possible to use the same pattern with different engines. The bookkeeping for doing the actual pattern matching against some input is localized in the matcher, not in the pattern.
The two methods below can be used to compile a regular expression string into a pattern and to retrieve the regular expression string from the pattern, respectively.
String regexStr = "\d\d-\d\d-\d\d"; // regex: dd-dd-dd
Pattern datePattern = Pattern.compile(regexStr);
static Pattern compile(String regexStr)
Compiles the specified regular expression string into a pattern. Throws the unchecked PatternSyntaxException if the regular expression is invalid. When the source is line-oriented, it is recommended to use the overloaded compile() method that additionally takes the argument Pattern.MULTILINE.
String pattern()
Returns the regular expression string from which this pattern was compiled.
The matcher() method returns a Matcher, which is the engine that does the actual pattern matching. This method does not apply the underlying pattern to the specified input. The matcher provides special operations to actually do the pattern matching.
Matcher dateMatcher = datePattern.matcher("01-03-49 786 09-09-09");
The Pattern class also provides a static convenience method that executes all the steps outlined above for pattern matching. The regular expression string and the input are passed to the static method matches(), which does the pattern matching on the entire input. The regular expression string is compiled and the matcher is created each time the method is called. Calling the matches() method is not recommended if the pattern is to be used multiple times.
boolean dateFound = Pattern.matches("\d\d-\d\d-\d\d", "01-03-49"); // true
Matcher matcher(CharSequence input)
Creates a matcher that will match the specified input against this pattern.
static boolean matches(String regexStr, CharSequence input)
Compiles the specified regular expression string and attempts to match the specified input against it. The method only returns true if the entire input matches the pattern.
The normal mode of pattern matching is to find matches for the pattern in the input. In other words, the result of pattern matching is the sequences of characters (i.e., the matches, also called groups) that match the pattern. Splitting returns sequences of characters that do not match the pattern. In other words, the matches are spliced out and the sequences of non-matching characters thus formed from the input are returned in an array of type String. The pattern is used as a delimiter to tokenize the input. The token in this case is a sequence of non-matching characters, possibly the empty string. The classes StringTokenizer and Scanner in the java.util package also provide the functionality for tokenizing text-based input. See the subsection The java.util.Scanner Class, p. 571.
The example below shows the results from splitting an input on a given pattern. The input is a ‘|’-separated list of names. The regular expression string is "\|", where the metacharacter | is escaped in order to use it as a non-metacharacter. Splitting the given input according to the specified regular expression, results in the array of String shown below.
Input: "tom|dick|harry" Split: "\|"
Results: { "tom", "dick", "harry" }
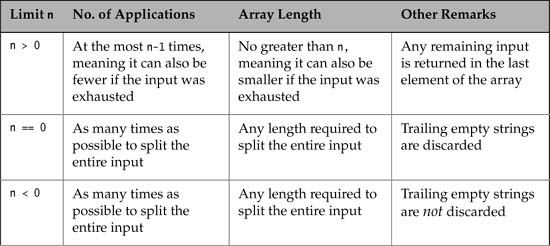
The split() method can be called on a pattern to create an array by splitting the input according to the pattern. Each successful application of the pattern, meaning each match of the pattern delimiter in the input, results in a split of the input, with the non-matched characters before the match resulting in a new element in the array, and any remaining input being returned as the last element of the array.
String[] split(CharSequence input, int limit)
Splits the specified input around matches of this pattern. The limit determines how many times this pattern will be applied to the input to create the array.
The number of applications of the pattern is controlled by the limit value passed to the method, as explained in Table 12.14. The code below will result in the array shown earlier:
String input = "tom|dick|harry";
String splitRegex = "\|"; // regex: |
Pattern splitPattern = Pattern.compile(splitRegex);
String[] results = splitPattern.split(input, 4); // { "tom", "dick", "harry" }
Using the split() method is illustrated in Example 12.7. The doPatSplits() method at (1) creates a Pattern at (2) and calls the split() method at (3) on this pattern. Partial output from Example 12.7 is shown below. Limit value 1 does not split the input, limit value 2 splits the input once, and so on. Limit value greater than 3 does not change the results, as the input is exhausted at limit value 3. A non-positive limit value splits the input on the pattern as many times as necessary, until the input is exhausted.
Input: tom|dick|harry Split: |
Limit Length Results
3 3 { "tom", "dick", "harry" }
2 2 { "tom", "dick|harry" }
1 1 { "tom|dick|harry" }
0 3 { "tom", "dick", "harry" }
-1 3 { "tom", "dick", "harry" }
If we change the input above to the input shown below, we see how empty strings come into the picture. The empty string is returned as a token to “mark” the split when the delimiter is found at the head of any remaining input, or at the end of the input. Five applications of the pattern were necessary to exhaust the input. Note that the limit value 0 does not return trailing empty strings.
Input: |tom||dick|harry| Split: |
Limit Length Results
6 6 { "", "tom", "", "dick", "harry", "" }
5 5 { "", "tom", "", "dick", "harry|" }
4 4 { "", "tom", "", "dick|harry|" }
3 3 { "", "tom", "|dick|harry|" }
2 2 { "", "tom||dick|harry|" }
1 1 { "|tom||dick|harry|" }
0 5 { "", "tom", "", "dick", "harry" }
-1 6 { "", "tom", "", "dick", "harry", "" }
Example 12.7 Splitting
import java.util.regex.Pattern;
public class Splitting {
public static void main(String[] args) {
System.out.println("===Using the Pattern.split() method===");
doPatSplits("tom|dick|harry", "\|", -1, 3);
doPatSplits("|tom||dick|harry|", "\|", -1, 6);
System.out.println("===Using the String.split() method===");
doStrSplits("tom|dick|harry", "\|", -1, 3);
}
public static void doPatSplits(String input, String splitRegex,
int lowerLimit, int upperLimit) { // (1)
System.out.print("Input: " + input);
System.out.println(" Split: " + splitRegex);
System.out.println("Limit Length Results");
Pattern splitPattern = Pattern.compile(splitRegex); // (2)
for (int limit = upperLimit; limit >= lowerLimit; limit--) {
String[] results = splitPattern.split(input, limit); // (3)
System.out.printf("%3d%6d ", limit, results.length);
printCharSeqArray(results);
}
}
public static void doStrSplits(String input, String splitRegex,
int lowerLimit, int upperLimit) { // (4)
System.out.print("Input: " + input);
System.out.println(" Split: " + splitRegex);
System.out.println("Limit Length Results");
for (int limit = upperLimit; limit >= lowerLimit; limit--) {
String[] results = input.split(splitRegex, limit); // (5)
System.out.printf("%3d%6d ", limit, results.length);
printCharSeqArray(results);
}
}
static void printCharSeqArray(CharSequence[] array) { // (6)
System.out.print("{ ");
for (int i = 0; i < array.length; i++) {
System.out.print(""" + array[i] + """);
System.out.print((i != array.length -1) ? ", " : " ");
}
System.out.println("}");
}
}
The String class also has a split() method that takes the regular expression string and the limit as parameters. Given that the reference input is of type String, the call input.split(regexStr,limit) is equivalent to the call Pattern.compile(regexStr). split(input, limit). The doStrSplits() method at (4) in Example 12.7 uses the split() method in the String class. Here is another example of using the split() method from the String class:
String[] results = "tom|dick|harry".split("\|", 0); // { "tom", "dick", "harry" }
We will not split hairs here any more, but encourage experimenting with splitting various input on different patterns using the code in Example 12.7.
A Matcher is an engine that performs match operations on a character sequence by interpreting a Pattern. A matcher is created from a pattern by invoking the Pattern. matcher() method. Here we will explore the following three modes of operation for a matcher:
1. One-Shot Matching: Using the matches() method in the Matcher class to match the entire input sequence against the pattern.
Pattern pattern = Pattern.compile("\d\d-\d\d-\d\d");
Matcher matcher = pattern.matcher("01-03-49");
boolean isMatch = matcher.matches(); // true
matcher = pattern.matcher("1-3-49");
isMatch = matcher.matches(); // false
The convenience method matches() in the Pattern class in the last subsection calls the matches() method in the Matcher class implicitly.
boolean matches()
Attempts to match the entire input sequence against the pattern. The method returns true only if the entire input matches the pattern.
2. Successive Matching: Using the find() method in the Matcher class to successively apply the pattern on the input sequence to look for the next match (discussed further in this subsection).
3. Match-and-Replace Mode: Using the matcher to find matches in the input sequence and replace them (discussed further in this subsection).
The main steps of successive matching using a matcher are somewhat analogous to using an iterator to traverse a collection (p. 786). These steps are embodied in the code below, which is extracted from Example 12.8.
...
Pattern pattern = Pattern.compile(regexStr); // (2)
Matcher matcher = pattern.matcher(target); // (3)
while(matcher.find()) { // (4)
...
String matchedStr = matcher.group(); // (7)
...
}
...
Once a matcher has been obtained, the find() method of the Matcher class can be used to find the next match in the input (called target in the code). The find() returns true if a match was found.
If the previous call to the find() method returned true, and the matcher has not been reset since then, the next call to the find() method will advance the search in the target for the next match from the first character not matched by the previous match. If the previous call to the find() returned false, no match was found, and the entire input has been exhausted.
The call to the find() method is usually made in a loop condition, so that any match found can be dealt with successively in the body of the loop. A match found by the find() method is called the previous match (as opposed to the next match which is yet to be found). The characters comprising the previous match are called a group, and can be retrieved by calling the group() method of the Matcher class. The group’s location in the target can be retrieved by calling the start() and the end() methods of the Matcher class, as explained below. The two methods find() and group() are called successively in lockstep to find all matches/groups in the input.
Once pattern matching has commenced, the matcher can be reset. Its target and pattern can also be changed by passing the new target to the reset() method and by passing the new pattern to the usePattern() method, respectively. The reset() method resets the search to start from the beginning of the input, but the usePattern() method does not.
boolean find()
Attempts to find the next match in the input that matches the pattern. The first call to this method, or a call to this method after the matcher is reset, always starts the search for a match at the beginning of the input.
String group()
Returns the characters (substring) in the input that comprise the previous match.
int start()
int end()
The first method returns the start index of the previous match. The second method returns the index of the last character matched, plus one. The values returned by these two methods define a substring in the input.
Matcher reset()
Matcher reset(CharSequence input)
The method resets this matcher, so that the next call to the find() method will begin the search for a match from the start of the current input. The second method resets this matcher, so that the next call to the find() method will begin the search for a match from the start of the new input.
Matcher usePattern(Pattern newPattern)
Replaces the pattern used by this matcher with another pattern. This change does not affect the search position in the input.
Pattern pattern()
Returns the pattern that is interpreted by this matcher.
Example 12.8 is a complete program that illustrates successive matching. In fact, the program in Example 12.8 was used to generate all examples of regular expressions in the subsection Regular Expression Fundamentals, p. 554. Again, we recommend experimenting with successive matching on various inputs and patterns to better understand regular expressions.
Example 12.8 String Pattern Matching
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MatchMaker {
public static void main(String[] args) {
// All examples from the subsection "Regular Expression Fundamentals".
matchMaker("o", "All good things come to those who wait");
matchMaker("who", "Interrogation with who, whose and whom.");
matchMaker("[^aeiouAEIOU]", "I said I am.");
matchMaker("[-A-Z]", "I-love-REGEX.");
matchMaker(".[Hh]o",
"Who is who? Whose is it? To whom it may concern. How are you?");
matchMaker("\d\d-\d\d-\d\d", "01-03-49 786 09-09-09");
matchMaker("\?$", "Who is who? Who me? Who else?");
matchMaker("([Jj][aA][vV][aA])|([Cc]\+\+)",
"JaVA jAvA C++ jAv c+++1 javan C+");
matchMaker("a?", "banana");
matchMaker("\d\d?-\d\d?-\d\d?", "01-3-49 23-12 9-09-09 01-01-2010");
matchMaker("a*", "baananaa");
matchMaker("(0|[1-9]\d*)\.\d\d", ".50 1.50 0.50 10.50 00.50 1.555");
matchMaker("a+", "baananaa");
matchMaker("\d+\.\d+", ".50 1.50 0. 10.50 00.50 1.555");
matchMaker("<.+>", "My <>very<> <emphasis>greedy</emphasis> regex");
matchMaker("<.+?>", "My <>very<> <emphasis>reluctant</emphasis> regex");
matchMaker("<[^>]+>", "My <>very<> <emphasis>powerful</emphasis> regex");
// Some more regular expression examples.
matchMaker("(^[a-z])|(\?$)", "who is who? Who me? Who else?");
matchMaker("[\\-^$.?*+()|]", "\-^$.?*+()|");
matchMaker("[-+]?[0-9]+", "+123 -34 567 2.3435");
matchMaker("[a-zA-Z][a-zA-Z0-9]+", "+a123 -X34 567 m2.3mm435");
matchMaker("[^,]+", "+a123, -X34, 567, m2,3mm435");
matchMaker("\\", "book\\chapter\section\");
matchMaker("[^\\]+", "book\\chapter\section\");
}
public static void matchMaker(String regexStr, String target) { // (1)
System.out.print("Index: ");
for (int i = 0; i < target.length(); i++) {
System.out.print(i%10);
}
System.out.println();
System.out.println("Target: " + target);
System.out.println("Pattern: " + regexStr);
System.out.print( "Match: ");
Pattern pattern = Pattern.compile(regexStr); // (2)
Matcher matcher = pattern.matcher(target); // (3)
while(matcher.find()) { // (4)
int startCharIndex = matcher.start(); // (5)
int lastPlus1Index = matcher.end(); // (6)
int lastCharIndex = startCharIndex == lastPlus1Index ?
lastPlus1Index : lastPlus1Index-1;
String matchedStr = matcher.group(); // (7)
System.out.print("(" + startCharIndex + "," + lastCharIndex + ":" +
matchedStr + ")");
}
System.out.println();
}
}
Output from the program:
...
Index: 0123456789012345678901
Target: book\chaptersection
Pattern: [^\]+
Match: (0,3:book)(6,12:chapter)(14,20:section)
In this mode, the matcher allows the matched characters in the input to be replaced with new ones. Details of the methods used for this purpose are given below. The find() and the appendReplacement() methods comprise the match-and-replace loop, with the appendReplacement() method completing the operation when the loop finishes.
Note that these methods use a StringBuffer, and have not been updated to work with a StringBuilder.
Matcher appendReplacement(StringBuffer sb, String replacement)
Implements a non-terminal append-and-replace step, i.e., it successively adds the non-matched characters in the input, followed by the replacement of the match, to the string buffer.
The find() method and the appendReplacement() method are used in lockstep to successively replace all matches, and the appendTail() method is called as the last step to complete the match-and-replace operation.
StringBuffer appendTail(StringBuffer sb)
Implements a terminal append-and-replace step, i.e., it copies the remaining characters from the input to the string buffer, which is then returned. It should be called after appendReplacement() operations have completed.
String replaceAll(String replacement)
Replaces every subsequence of the input that matches the pattern with the specified replacement string. The method resets the matcher first and returns the result after the replacement.
String replaceFirst(String replacement)
Replaces the first subsequence of the input that matches the pattern with the specified replacement string. The method resets the matcher first and returns the result after the replacement.
Example 12.9 illustrates the match-and-replace loop. Non-matching characters in the input and the replacements of the matches are successively added to the string buffer in the loop at (1), with the call to the appendTail() method at (3) completing the operation. The same operation is repeated using the replaceAll() method at (4).
Using the replaceAll() method replaces all matches with the same replacement, but the match-and-replace loop offers greater flexibility in this regard, as each replacement can be tailored when a match is found.
Example 12.9 Match and Replace
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MatchAndReplace {
public static void main(String[] args) {
// Match and replace loop:
Pattern pattern = Pattern.compile("be");
String input = "What will be will be.";
System.out.println(input);
Matcher matcher = pattern.matcher(input);
StringBuffer strBuf = new StringBuffer();
while (matcher.find()) { // (1)
matcher.appendReplacement(strBuf, "happen"); // (2)
}
matcher.appendTail(strBuf); // (3)
System.out.println(strBuf);
// Match and replace all:
matcher.reset();
String result = matcher.replaceAll("happen"); // (4)
System.out.println(result);
}
}
Output from the program:
What will be will be.
What will happen will happen.
What will happen will happen.
A scanner reads characters from a source and converts them into tokens. The source is usually a text-based input stream containing formatted data. The formatted values in the source are separated by delimiters, usually whitespace. A token is a sequence of characters in the source that comprises a formatted value. A scanner generally uses regular expressions to recognize tokens in the source input. A point to note is that a scanner can also use regular expressions to recognize delimiters, which are normally discarded. Such a scanner is also called a tokenizer (also called a lexical analyzer), and the process is called tokenization. Some scanners also convert the tokens into values of appropriate types for further processing. Scanners with this additional functionality are usually called parsers.
The class Scanner in the java.util package provides powerful tools to implement text scanners which use regular expressions to tokenize and parse formatted data into primitive types and strings. The Pattern.split() method (and the String.split() method that uses this method) also provide tokenizing capabilities (p. 563), but these are not as versatile as the Scanner class.
We will discuss two modes of operation for a scanner:
• Tokenizing Mode, for tokenizing a stream of formatted data values.
• Multi-Line Mode, for searching or finding matches in line-oriented input.
Tokenizing is analogous to successive matching (p. 567), involving reading of the characters in the source, and recognizing tokens in the source. Example 12.10 shows a bare-bones tokenizer that tokenizes a string, but it embodies the paradigm for constructing more sophisticated scanners. The rest of the subsection will present variations on this tokenizer.
1. The source for the input to the scanner must be identified. The example shows a String as the source, but we can also use other sources, such as a File, an InputStream or a BufferedReader.
2. A scanner is created and associated with the source that is passed as argument in the constructor call. The Scanner class provides constructors for various kinds of sources.
3. The bulk of the work of a scanner is done in a lookahead-and-parse loop.
The condition of the loop is a call to a lookahead method to see if an appropriate token can be identified in the remaining source. The Scanner class provides lookahead methods named hasNextType to determine whether the next token in the source is of the appropriate primitive Type. Note that the scanner reads the characters from the source sequentially.
The call to the hasNext() method at (3) returns true if there is a (String) token in the source. The loop terminates when the hasNext() method returns false, meaning that the source string has been exhausted, i.e., there are no more tokens.
Each successive call to a lookahead method causes the scanner to advance and look for the next token in the source.
4. If a lookahead method determines that there is a token in the source, the token can be parsed in the loop body. The Scanner class provides parse methods named nextType to parse the next token in the source to the appropriate primitive type. The call to the next() method at (4) parses the next token to a String. In the example, the parsed value is printed, but it can be stored and used as desired. Also in the example, the scanner uses the default delimiters (whitespace) to tokenize the string.
A lookahead method and its corresponding parse method are used in lockstep to ensure that characters in the source are matched and parsed to a token of an appropriate type.
5. A scanner whose source has been explicitly associated in the code, should be closed when it is no longer needed. This also closes the source, if that is necessary.
Example 12.10 Tokenizing Mode
import static java.lang.System.out;
import java.util.Scanner;
class BareBonesTokenizer {
public static void main(String[] args) {
String input = "The world will end today -- not!"; // (1) String as source
Scanner lexer = new Scanner(input); // (2) Create a scanner
while (lexer.hasNext()) { // (3) Processing loop
out.println(lexer.next()); // (4) Parsing
}
lexer.close(); // (5) Close the scanner
}
}
Output from the program:
The
world
will
end
today
--
not!
A scanner must be constructed and associated with a source before it can be used to parse text-based data. The source of a scanner is passed as an argument in the appropriate constructor call. Once a source is associated with a scanner it cannot be changed. If the source is a byte stream (e.g., an InputStream), the bytes are converted to characters using the default character encoding. A character encoding can also be specified as an additional argument in an overloaded constructor, except when the source is a String.
The Scanner class provides two overloaded hasNext() methods that accept a regular expression specified as a string expression or as a Pattern, respectively. The next token is matched against this pattern. All primitive types and string literals have a pre-defined format which is used by the appropriate lookahead method.
All lookahead methods return true if the match with the next token is successful. This means that we can safely call the corresponding parse method to parse the token to an appropriate type. Note that a lookahead method does not advance past any input character, regardless of whether the lookahead was successful. It only determines whether appropriate input is available at the current position in the input.
boolean hasNext()
boolean hasNext(Pattern pattern)
boolean hasNext(String pattern)
The first method returns true if this scanner has another (string) token in its input. The last two methods return true if the next token matches the specified pattern or the pattern constructed from the specified string, respectively.
boolean hasNextIntegralType()
boolean hasNextIntegralType(int radix)
Returns true if the next token in this scanner’s input can be interpreted as a value of the integral type corresponding to IntegralType in the default or specified radix. The name IntegralType can be Byte, Short, Int or Long, corresponding to the primitive types byte, short, int, or long, respectively.
boolean hasNextFPType()
Returns true if the next token in this scanner’s input can be interpreted as a value of the floating-point type corresponding to FPType. The name FPType can be Float or Double, corresponding to the types float or double, respectively.
boolean hasNextBoolean()
Returns true if the next token in this scanner’s input can be interpreted as a boolean value using a case insensitive pattern created from the string "true|false".
boolean hasNextLine()
Returns true if there is another line in the input of this scanner.
A scanner uses white space as its default delimiter pattern to identify tokens. The useDelimiters() method of the Scanner class can be used to set a different delimiter pattern for the scanner during parsing. Note that a scanner uses regular expressions for two purposes: a delimiter pattern to identify delimiter characters and a token pattern to find a token in the input.
A scanner is able to read and parse any value that has been formatted by a printf method, provided the same locale is used. The useLocale() method of the Scanner class can be used to change the locale used by a scanner.
The delimiters, the locale, and the radix can be changed any time during the tokenizing process.
Pattern delimiter()
Scanner useDelimiter(Pattern pattern)
Scanner useDelimiter(String pattern)
The first method returns the pattern this scanner is currently using to match delimiters. The last two methods set its delimiting pattern to the specified pattern or to the pattern constructed from the specified pattern string, respectively.
Locale locale()
Scanner useLocale(Locale locale)
These methods return this scanner’s locale or set its locale to the specified locale, respectively.
int radix()
Scanner useRadix(int radix)
These methods return this scanner’s default radix or set its radix to the specified radix, respectively.
The Scanner class provides methods to parse strings and values of all primitive types, except the char type.
Corresponding to the hasNext() methods, the Scanner class provides two overloaded next() methods that accept a regular expression as a string expression or as a Pattern, respectively. This pattern is used to find the next token.
It is important to understand how a parse method works. A call to a parse method first skips over any delimiters at the current position in the source, and then reads characters up to the next delimiter. The scanner attempts to match the non-delimiter characters that have been read against the pattern associated with the parse method. If the match succeeds, a token has been found, which can be parsed accordingly. The current position is advanced to the new delimiter character after the token. The upshot of this behavior is that if a parse method is not called when a lookahead method reports there is a token, the scanner will not advance in the input. In other words, tokenizing will not proceed unless the next token is “cleared.”
A scanner will throw an InputMismatchException when it cannot parse the input, and the current position will remain unchanged.
String next()
String next(Pattern pattern)
String next(String pattern)
The first method scans and returns the next token as a String. The last two methods return the next string in the input that matches the specified pattern or the pattern constructed from the specified string, respectively.
ReturnIntegralType nextIntegralType()
ReturnIntegralType nextIntegralType(int radix)
Returns the next token in the input as a value of primitive type corresponding to IntegralType. The name IntegralType can be Byte, Short, Int, or Long, corresponding to the primitive types byte, short, int, or long, respectively. The name ReturnIntegralType is the primitive type corresponding to the name IntegralType.
ReturnFPType nextFPType()
Returns the next token in the input as a value of the primitive type corresponding to FPType. The name FPType can be Float or Double, corresponding to the primitive types float or double, respectively. The name ReturnFPType is the primitive type corresponding to the name FPType.
boolean nextBoolean()
Returns the next token in the input as a boolean value.
String nextLine()
Advances this scanner past the current line and returns the input that was skipped.
Example 12.11 illustrates parsing of primitive values (and strings) from formatted data. To parse such values, we need to know what type of values occur in what order in the input so that an appropriate lookahead and a corresponding parse method can be used. We also need to know what locale was used to format them and which delimiters separate the individual values in the input. This is exactly the information accepted by the parse() method at (1).
The order in which the different type of values occur in the input is specified by the vararg parameter tokenTypes, whose element type is the enum type TokenType. A call to the method parse(), such as the one shown below, thus indicates the order, the type and the number of values to expect in the input.
parse(locale, input, delimiters,
TokenType.INT, TokenType.DOUBLE, TokenType.BOOL,
TokenType.INT, TokenType.LONG, TokenType.STR);
Example 12.11 can be used as the basis for experimenting with a scanner for parsing primitive values in the formatted input.
Example 12.11 Parsing Primitive Values and Strings
import static java.lang.System.out;
import java.util.Locale;
import java.util.Scanner;
public class ParsingPrimitiveValues {
/** Types of tokens to parse */
enum TokenType { INT, LONG, FLOAT, DOUBLE, BOOL, STR }
public static void main(String[] args) {
// Using default delimiters (i.e. whitespace).
// Note Norwegian locale format for floating-point numbers.
String input = "123 45,56 false 567 722 blahblah";
String delimiters = "default";
Locale locale = new Locale("no", "NO");
parse(locale, input, delimiters,
TokenType.INT, TokenType.DOUBLE, TokenType.BOOL,
TokenType.INT, TokenType.LONG, TokenType.STR);
// Note the use of backslash to escape characters in regex.
input = "2008 | 2 | true";
delimiters = "\s*\|\s*";
parse(null, input, delimiters,
TokenType.INT, TokenType.INT, TokenType.BOOL);
// Another example of a regex to specify delimiters.
input = "Always = true | 2 $ U";
delimiters = "\s*(\||\$|=)\s*";
parse(null, input, delimiters,
TokenType.STR, TokenType.BOOL, TokenType.INT, TokenType.STR);
}
/**
* Parses the input using the locale, the delimiters and
* expected sequence of tokens.
*/
public static void parse(Locale locale, String input, String delimiters,
TokenType... tokenTypes) { // (1) Vararg
Scanner lexer = new Scanner(input); // (2) Create a scanner.
if (!delimiters.equalsIgnoreCase("default")) { // (3) Change delimiters?
lexer.useDelimiter(delimiters);
}
if (locale != null) { // (4) Change locale?
lexer.useLocale(locale);
}
out.println("Locale: " + lexer.locale());
out.println("Delim: " + delimiters);
out.println("Input: " + input);
out.print("Tokens: ");
// (5) Iterate through the tokens:
for (TokenType tType : tokenTypes) {
if (!lexer.hasNext()) break; // (6) Handle premature end of input.
switch(tType) {
case INT: out.print("<" + lexer.nextInt() + ">"); break;
case LONG: out.print("<" + lexer.nextLong() + ">"); break;
case FLOAT: out.print("<" + lexer.nextFloat() + ">"); break;
case DOUBLE: out.print("<" + lexer.nextDouble() + ">"); break;
case BOOL: out.print("<" + lexer.nextBoolean() + ">"); break;
case STR: out.print("<" + lexer.next() + ">"); break;
default: assert false;
}
}
System.out.println("
");
lexer.close(); // (7) Close the scanner.
}
}
Output from the program:
Locale: no_NO
Delim: default
Input: 123 45,56 false 567 722 blahblah
Tokens: <123><45.56><false><567><722><blahblah>
Locale: en_GB
Delim: s*|s*
Input: 2008 | 2 | true
Tokens: <2008><2><true>
Locale: en_GB
Delim: s*(||$|=)s*
Input: Always = true | 2 $ U
Tokens: <Always><true><2><U>
The skip() method can be used to skip characters in the input during the course of tokenizing. This operation ignores delimiters and will only skip input that matches the specified pattern. If no such input is found, it throws a NoSuchElementException.
The match() method can be called after the value of a token has been returned. The MatchResult interface provides methods to retrieve the start index, the end index, and the group of the token. For example, after parsing a floating-point number in the input, a MatchResult can be obtained by calling the match() method, which can then be queried about the location of the characters comprising the value, etc.
When the source is an input stream (e.g., a File, an InputStream, a Reader), a read operation can throw an IOException. If this exception is thrown in the course of a lookahead method call, it is not propagated by the scanner and the scanner assumes that the end of the input has been reached. Subsequent calls to a lookahead method will throw a NoSuchElementException. To determine whether processing terminated because of a genuine end of input or an IOException, the ioException() method can be called to verify the situation.
Closing a scanner is recommended when the client code has explicit control over the assigning of the source. Calling a scanning method on a closed scanner results in an IllegalStateException.
Scanner skip(Pattern pattern)
Scanner skip(String pattern)
These methods skip input that matches the specified pattern or the pattern constructed from the specified string, respectively, ignoring any delimiters. If no match is found at the current position, no input is skipped and a NoSuchElementException is thrown.
MatchResult match()
Returns the match result of the last scanning operation performed by this scanner.
IOException ioException()
Returns the IOException last thrown by this scanner’s underlying Readable object.
Scanner reset()
Resets this scanner to the default state with regard to delimiters, locale, and radix.
void close()
Closes this scanner. When a scanner is closed, it will close its input source if the source implements the Closeable interface (implemented by various Channels, InputStreams, Readers).
Example 12.12 is the analog of Example 12.8 that uses a scanner instead of a matcher. The thing to note about Example 12.12 is the loop at (4). The method call hasNext() looks ahead to see if there is any input. The method call hasNext(pattern) attempts to match the pattern with the next token (found using the delimiters). If the attempt is not successful, the method call next() returns the token, which is ignored, but advances the scanner.
The split() method (p. 563) in the Pattern and the String classes can also tokenize, but is not as versatile as a scanner. The example below shows the difference between a scanner and a matcher. In the tokenizing mode, a scanner tokenizes and then attempts to match the token with the pattern. A matcher does not tokenize, but searches for the pattern in the input. The results below make this difference quite apparent in the number of matches the two approaches find in the same input.
Results from a scanner (see Example 12.12):
Index: 01234567890123456789012345678901
Target: JaVA jAvA C++ jAv c+++1 javan C+
Delimit: default
Pattern: ([Jj][aA][vV][aA])|([Cc]++)
Match: (0,3:JaVA)(5,8:jAvA)(10,12:C++)
Results from a matcher (see Example 12.8):
Index: 01234567890123456789012345678901
Target: JaVA jAvA C++ jAv c+++1 javan C+
Pattern: ([Jj][aA][vV][aA])|([Cc]++)
Match: (0,3:JaVA)(5,8:jAvA)(10,12:C++)(18,20:c++)(24,27:java)
Example 12.12 Using Delimiters and Patterns with a Scanner
import static java.lang.System.out;
import java.util.Scanner;
import java.util.regex.MatchResult;
import java.util.regex.Pattern;
public class Tokenizer {
public static void main(String[] args) {
tokenize("([Jj][aA][vV][aA])|([Cc]\+\+)",
"JaVA jAvA C++ jAv c+++1 javan C+", "default");
tokenize("[a-z[A-Z]]+", "C:\Program Files\3MM\MSN2Lite\Help", "\\");
}
public static void tokenize(String regexStr, String source,
String delimiters) { // (1)
System.out.print("Index: ");
for (int i = 0; i < source.length(); i++) {
System.out.print(i%10);
}
System.out.println();
System.out.println("Target: " + source);
System.out.println("Delimit: " + delimiters);
System.out.println("Pattern: " + regexStr);
System.out.print( "Match: ");
Pattern pattern = Pattern.compile(regexStr); // (2)
Scanner lexer = new Scanner(source); // (3)
if (!delimiters.equalsIgnoreCase("default"))
lexer.useDelimiter(delimiters); // (5)
while(lexer.hasNext()) { // (4)
if (lexer.hasNext(pattern)) { // (5)
String matchedStr = lexer.next(pattern); // (5)
MatchResult matchResult = lexer.match(); // (6)
int startCharIndex = matchResult.start();
int lastPlus1Index = matchResult.end();
int lastCharIndex = startCharIndex == lastPlus1Index ?
lastPlus1Index : lastPlus1Index-1;
out.print("(" + startCharIndex + "," + lastCharIndex + ":" +
matchedStr + ")");
} else {
lexer.next(); // (7)
}
}
System.out.println();
}
}
...
Index: 0123456789012345678901234567890123
Target: C:Program Files3MMMSN2LiteHelp
Delimit: \
Pattern: [a-z[A-Z]]+
Match: (30,33:Help)
If the input is line-oriented, the scanner can be used to perform search in the input one line at a time. The methods hasNextLine(), findInLine(), and nextLine() form the trinity that implements the multi-line mode of searching the input with a pattern.
Example 12.13 illustrates the basics of the multi-line use of a scanner. The program processes a text file line by line, printing the names found in each line. The program essentially comprises two nested loops: an outer loop to access the input one line at a time, and an inner loop to search for all names in this line. The name of the source file is specified as a program argument at (1). The pattern that defines a name is specified at (2), and a scanner with the text file as the source is created at (3).
The call to the lookahead method hasNextLine() at (4) checks to see if there is another line of input. If that is the case, the findInLine() method is called at (5) to find the first match. All characters in the line are treated as being significant by the findInLine() method, including the delimiters that are set for the scanner. If a call to the findInLine() method results in a match, it advances the search past the matched input in the line and returns the matched input. The value returned by the findInLine() method can be used as a condition in an inner loop to successively find remaining occurrences of the pattern in the line at (8).
If no match is found in the line, the findInLine() method returns the value null and the search position remains unchanged. The findInLine() method never reads past a line separator. This means that the scanner does not budge if a match cannot be found in the line or if it has reached the end of the line. A call to the nextLine() method at (9) reads the rest of the line, i.e., any characters from the current position to the end of the line, including the line separator. The scanner is thus poised to process the next line.
Since the findInLine() method only recognizes the line separator as a delimiter, absence of line separators in the input may result in buffering of the input while the scanner tries to match the search pattern.
String findInLine(Pattern pattern)
String findInLine(String pattern)
These methods attempt to find the next occurrence of the specified pattern or the pattern constructed from the specified string, respectively, ignoring any delimiters.
Example 12.13 Multi-Line Mode
import static java.lang.System.out;
import java.io.File;
import java.io.IOException;
import java.util.Scanner;
import java.util.regex.Pattern;
class MultiLineMode {
public static void main(String[] args) throws IOException {
String source = args[0]; // (1) Filename from program args
Pattern pattern = Pattern.compile("[a-zA-Z]+",
Pattern.MULTILINE);// (2) Search pattern
Scanner lexer = new Scanner(new File(source));// (3) Create a scanner
// Outer loop:
while (lexer.hasNextLine()) { // (4) Lookahead for next line
String match = lexer.findInLine(pattern); // (5) Find the first match
// Inner loop:
while (match != null) { // (6) Parse rest of the line
out.println(match); // (7) Process the match
match = lexer.findInLine(pattern); // (8) Get the next match
}
lexer.nextLine(); // (9) Clear rest of the line
}
IOException ioe = lexer.ioException();
if (ioe != null) // (10) Check for read problem
throw ioe;
lexer.close(); // (11) Close the scanner
}
}
Running the program:
>java MultiLineMode MultiLineMode.java
import
static
...
scanner
12.7 Which statements are true about the following target string?
"oblaada oblaadi"
Select the three correct answers.
(a) The regular expression a+ will match two substrings of the target string.
(b) The regular expression aa+ will match two substrings of the target string.
(c) The regular expression (aa)+ will match two substrings of the target string.
(d) The regular expressions aa+ and (aa)+ will match the same two substrings of the target string.
12.8 Which statements are true about the following target string?
"oblaada oblaadi"
Select the three correct answers.
(a) The regular expression a? will match five non-empty substrings of the target string.
(b) The regular expression aa? will match two non-empty substrings of the target string.
(c) The regular expression (aa)? will match two non-empty substrings of the target string.
(d) The regular expressions aa? and (aa)? will not match the same non-empty substrings of the target string.
12.9 Which statement is true about the following target string?
"oblaada oblaadi"
Select the one correct answer.
(a) The regular expression a* will match three non-empty substrings of the target string.
(b) The regular expression aa* will match at least two non-empty substrings of the target string.
(c) The regular expression (aa)* will match two non-empty substrings of the target string.
(d) The regular expressions a* and aa* will match the same non-empty substrings of the target string.
(e) All of the above.
12.10 Which statement is true about the following target string?
"0.5 7UP _4me"
Select the one correct answer.
(a) The pattern d will match 0.5, 7, and 4 in the target string.
(b) The pattern d will match 0, ., 5, 7, and 4 in the target string.
(c) The pattern w will match UP and me in the target string.
(d) The pattern s will match 0.5, 7UP, and _4me in the target string.
(e) The pattern . will match the . character in the target string.
(f) The regular expression [meUP] will match UP and me in the target string.
(g) None of the above.
12.11 Which statements are true about the following program?
import java.util.regex.Pattern;
public class RQ500_10 {
public static void main(String[] args) {
System.out.println(Pattern.matches("+?d", "+2007")); // (1)
System.out.println(Pattern.matches("+?\d+","+2007")); // (2)
System.out.println(Pattern.matches("+?\d+", "+2007")); // (3)
System.out.println(Pattern.matches("\+?\d+", "+2007")); // (4)
}
}
Select the two correct answers.
(a) Only in the statements at (1) and (2) will the compiler report an invalid escape sequence.
(b) Only in the statements at (3) and (4) will the compiler report an invalid escape sequence.
(c) Only in the statements at (1) and (3) will the compiler report an invalid escape sequence.
(d) The statements at (2) and (4) will compile but will throw an exception at runtime.
(e) After any compile-time errors have been eliminated, only one of the statements will print true when executed.
(f) None of the above.
12.12 Given the following code:
import java.util.regex.Pattern;
public class RQ500_20 {
public static void main(String[] args) {
String[] regexes = {
"(-|+)\d+", "(-|+)?\d+", "(-|\+)\d+", // 0, 1, 2
"(-|\+)?\d+", "[-+]?\d+", "[-+]?[0-9]+", // 3, 4, 5
"[-\+]?\d+" }; // 6
// (1) INSERT DECLARATION STATEMENT HERE
System.out.println(Pattern.matches(regexes[i], "2007"));
System.out.println(Pattern.matches(regexes[i], "-2007"));
System.out.println(Pattern.matches(regexes[i], "+2007"));
}
}
Which declarations, when inserted independently at (1), will make the program print:
true
true
true
Select the four correct answers.
(a) int i = 0;
(b) int i = 1;
(c) int i = 2;
(d) int i = 3;
(e) int i = 4;
(f) int i = 5;
(g) int i = 6;
12.13 Given the following code:
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RQ500_40 {
public static void main(String[] args) {
String regex = "ja[^java]*va";
String index = "012345678901234567890123456";
String target = "jambo valued jam vacationer";
Pattern pattern = __________.compile(_________);
Matcher matcher = __________.matcher(_________);
while(matcher.___________()) {
int startIndex = matcher.__________();
int endIndex = matcher.__________();
int lastIndex = startIndex == endIndex ? endIndex : endIndex-1;
String matchedStr = matcher._______();
System.out.print("(" + startIndex + "," + lastIndex + ":" +
matchedStr + ")");
}
System.out.println();
}
}
Which identifiers, when filled in the blanks in the order they are specified, will make the program print:
(0,7:jambo va)(13,18:jam va)
Select the one correct answer.
(a) Pattern, pattern, target, regex, find, start, end, group
(b) Matcher, pattern, regex, target, hasMore, start, end, element
(c) Matcher, pattern, regex, target, hasNext, start, end, next
(d) Pattern, regex, pattern, target, find, start, end, group
(e) Pattern, regex, pattern, target, hasNext, start, end, next
(f) Pattern, regex, pattern, target, find, start, end, result
12.14 What will the program print when compiled and run?
public class RQ500_60 {
public static void main(String[] args) {
String regex = "[Jj].?[Aa].?[Vv].?[Aa]";
String target1 = "JAVA JaVa java jaVA";
String target2 = "JAAAVA JaVVa jjaavvaa ja VA";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(target1);
makeMatch(matcher);
matcher.reset();
makeMatch(matcher);
matcher.reset(target2);
makeMatch(matcher);
}
public static void makeMatch(Matcher matcher) {
System.out.print("|");
while(matcher.find()) {
System.out.print(matcher.group() + "|");
}
System.out.println();
}
}
Select the one correct answer.
(a) |JAVA|JaVa|java|jaVA|
|JAAAVA|JaVVa|jjaavva|ja VA|
(b) |JAVA|JaVa|java|jaVA|
|
|JAAAVA|JaVVa|jjaavva|ja VA|
(c) |JAVA|JaVa|java|jaVA|
|JAVA|JaVa|java|jaVA|
|JAAAVA|JaVVa|jjaavva|ja VA|
(d) |JAVA|JaVa|java|jaVA|
|JAVA|JaVa|java|jaVA|
|JaVVa|jjaavva|ja VA|
(e) The program will throw an exception when run.
12.15 What will the program print when compiled and run?
public class RQ500_70 {
public static void main(String[] args) {
System.out.print(Pattern.compile("\s+")
.matcher("| To be |
|or not to be|")
.replaceAll(" "));
}
}
Select the one correct answer.
(a) | To be |
|or not to be|
(b) | To be |
|or not to be|
(c) | To be |
|or not to be|
(d) | To be | |or not to be|
(e) | To be ||or not to be|
(f) | To be ||or not to be|
(g) The program will not compile.
(h) The program will throw an exception when run.
12.16 What will the program print when compiled and run?
public class RQ500_80 {
public static void main(String[] args) {
matchMaker("X.*z", "XyzXyz Xz"); // (1)
matchMaker("X.+z", "XyzXyz Xz"); // (2)
matchMaker("X.*?z", "XyzXyz Xz"); // (3)
matchMaker("X.+?z", "XyzXyz Xz"); // (4)
}
public static void matchMaker(String regStr, String target) {
Matcher matcher = Pattern.compile(regStr).matcher(target);
System.out.print("|");
while(matcher.find()) {
System.out.print(matcher.group() + "|");
}
System.out.println();
}
}
Select the one correct answer.
(a) |Xyz|Xyz|Xz|
|XyzXyz|Xz|
|Xyz|Xyz|Xz|
|Xyz|Xyz|
(b) |XyzXyz Xz|
|XyzXyz Xz|
|Xyz|Xyz|Xz|
|Xyz|Xyz|
(c) |XyzXyz Xz|
|XyzXyz|Xz|
|XyzXyz Xz|
|XyzXyz|Xz|
(d) The program will throw an exception when run.
12.17 What will the program print when compiled and run?
public class RQ500_90 {
public static void main(String[] args) {
CharSequence inputStr = "no 7up 4 _u too!";
String patternStr = "[a-zA-Z0-9_]+";
Matcher matcher = Pattern.compile(patternStr).matcher(inputStr);
StringBuffer buf = new StringBuffer();
while (matcher.find()) {
String matchedStr = matcher.group();
matchedStr = Character.toUpperCase(matchedStr.charAt(0)) +
matchedStr.substring(1);
matcher.appendReplacement(buf, matchedStr);
}
matcher.appendTail(buf);
System.out.println(buf);
}
}
Select the one correct answer.
(a) No 7Up 4 _U Too!
(b) No 7up 4 _u Too!
(c) No 7Up 4 _u Too!
(d) No 7up 4 _U Too!
(e) The program will throw an exception when run.
12.18 What will the program print when compiled and run?
public class RQ500_110 {
public static void main(String[] args) {
printArray("Smile:-)and:)the:-(world.-)smiles:o)with-you".
split("[.:\-()o]+"));
}
private static <T> void printArray(T[] array) {
System.out.print("|");
for (T element : array)
System.out.print(element + "|");
System.out.println();
}
}
Select the one correct answer.
(a) |Smile|and|the|world|smiles|with-you|
(b) |Smile|and|the|world|smiles|with-y|u|
(c) |Smile|and|the|world|smiles|with|you|
(d) |Smile|and|the|w|rld|smiles|with|y|u|
(e) The program will not compile.
(f) The program will compile and will throw an exception when run.
(g) The program will compile and will execute normally without printing anything.
12.19 Which statements are true about the Scanner class?
Select the 3 correct answers.
(a) The Scanner class has constructors that can accept the following as an argument: a String, a StringBuffer, a StringBuilder, a File, an InputStream, a Reader.
(b) The Scanner class provides a method called hasNextBoolean, but not a method called hasNextChar.
(c) The methods hasNext(), next(), skip(), findInLine(), and useDelimiters() of the Scanner class can take a Pattern or a String as an argument.
(d) The situation where the scanner cannot match the next token or where the input is exhausted, can be detected by catching an unchecked NoSuchElementException in the program.
12.20 Given the following code:
public class RQ600_10 {
public static void main(String[] args) {
Scanner lexer = new Scanner(System.in);
// (1) INSERT PRINT STATEMENT HERE.
}
}
Which print statements, when inserted independently at (1), will not make the program run as follows (with user input shown in bold):
>java RQ600_10
99 20.07 true 786
99
>
Select the three correct answers.
(a) System.out.println(lexer.nextByte());
(b) System.out.println(lexer.nextShort());
(c) System.out.println(lexer.nextInt());
(d) System.out.println(lexer.nextLong());
(e) System.out.println(lexer.nextDouble());
(f) System.out.println(lexer.nextBoolean());
(g) System.out.println(lexer.next());
(h) System.out.println(lexer.nextLine());
12.21 Given the following code:
public class RQ600_30 {
public static void main(String[] args) {
String input = "A00.20BCDE0.0060.0F0.800";
Scanner lexer = new Scanner(input).useDelimiter(____(1)_____);
System.out.print("|");
while (lexer.hasNext()) {
System.out.print(lexer.next() + "|");
System.out.print(lexer.nextInt() + "|");
}
lexer.close();
}
}
Which pattern strings, when inserted at (1), will not give the following output:
|A|2|BCDE|6|F|8|
Select the two correct answers.
(a) "[0\.]+"
(b) "[0.]+"
(c) "(0|.)+"
(d) "(0|\.)+"
(e) "0+(\.)*"
(f) "0+\.*0*"
12.22 What will the program print when compiled and run?
public class RQ600_40 {
public static void main(String[] args) {
String input = "_AB..0C.-12.),DEF0..-34G.(H.";
Scanner lexer = new Scanner(input).useDelimiter("\w+\.");
while (lexer.hasNext())
System.out.print(lexer.next());
lexer.close();
}
}
Select the one correct answer.
(a) .-.),.-.(
(b) -),-(
(c) .-),-(.
(d) .-),.-(
(e) The program will not compile.
(f) The program will compile and will throw an exception when run.
12.23 Given the following code:
public class RQ600_50 {
public static void main(String[] args) {
String input = "1234||567.|12.34|.56||78.|.";
String delimiters = "\|+";
// (1) INSERT DECLARATION HERE
lexIt(regex, delimiters, input);
}
public static void lexIt(String regex, String delimiters, String input) {
Scanner lexer = new Scanner(input).useDelimiter(delimiters);
while (lexer.hasNext()) {
if (lexer.hasNext(regex))
System.out.printf("%7s", lexer.next(regex) + ",");
else
System.out.printf("%7s", "X" + lexer.next() + ",");
}
System.out.println();
lexer.close();
}
}
Which declaration statements, when inserted at (1), will give the following output:
1234, 567., 12.34, .56, 78., X.,
Select the one correct answer.
(a) String regex = "\d+\.?";
(b) String regex = "\.?\d+";
(c) String regex = "\d+\.\d+";
(d) String regex = "\d*\.?\d*";
(e) String regex = "\d+\.?\d*";
(f) String regex = "(\d+\.?|\.?\d+|\d+\.\d+)";
(g) The program will not compile regardless of which declaration from above is inserted at (1).
(h) The program will compile and run, but will throw an exception regardless of which declaration from above is inserted at (1).
12.24 What will the program print when compiled and run?
public class RQ600_70 {
public static void main(String[] args) {
Scanner lexer = new Scanner("B4, we were||m8s & :-) 2C,1 THR,");
lexer.useDelimiter("[|,]");
System.out.print("<" + lexer.next("\w*") + "><" + lexer.next() + ">");
lexer.useDelimiter("[a-z|& ]+");
System.out.print("<" + lexer.nextInt() + "><" + lexer.next() + ">");
lexer.useDelimiter("[ ,]");
System.out.print("<" + lexer.next("\w+") + "><" + lexer.next("\d+") + ">");
lexer.next();
lexer.close();
}
}
Select the one correct answer.
(a) <B4>< we were><8><:-)><2C><1>
(b) <B4>< we were><m8s><:-)><2C><THR>
(c) <B4><we were><8><:-)><2C,><1>
(d) <B4>< we were><8s><2C1><><THR>
(e) The program will not compile.
(f) The program will compile and will throw an exception when run.
12.25 What will the program print when compiled and run?
public class RQ600_80 {
public static void main(String[] args) {
Scanner lexer = new Scanner("Trick or treat");
while(lexer.hasNext()) {
if(lexer.hasNext("[kcirTtea]+"))
System.out.print("Trick!");
lexer.next();
}
lexer.close();
}
}
Select the one correct answer.
(a) The program will not compile.
(b) The program will compile and will throw an exception when run.
(c) The program will compile and will go into an infinite loop when run.
(d) The program will compile, run, and terminate normally, without any output.
(e) The program will compile, run, and terminate normally, with the output Trick!.
(f) The program will compile, run, and terminate normally, with the output Trick!Trick!.
(g) The program will compile, run, and terminate normally, with the output Trick!treat!.
12.26 Given the following code:
public class RQ600_20 {
public static void main(String[] args) {
System.out.print("|");
// (1) INSERT CODE HERE
System.out.println();
lexer.close();
}
Which code, when inserted independently at (1), will not print one of the lines shown below:
|2007| -25.0|mp3 4 u | true| after8|
|mp|u|true|after|
|2007.0|25.0|0.0|mp3|4.0|u|true|after8|
|4|
|2007|25|0|3|4|8|
|2007.0|-25.0|
Select the three correct answers.
(a) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter(",");
while(lexer.hasNext())
System.out.print(lexer.next() + "|");
(b) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("\s*,\s*");
while(lexer.hasNext())
if(lexer.hasNextDouble())
System.out.print(lexer.nextDouble() + "|");
else
lexer.next();
(c) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("\s*,\s*");
while(lexer.hasNext())
if(lexer.hasNextDouble())
System.out.print(lexer.nextDouble() + "|");
(d) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("[,\- .a-z]+");
while(lexer.hasNext())
if(lexer.hasNextInt())
System.out.print(lexer.nextInt() + "|");
else
lexer.next();
(e) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("[,\- .\d]+");
while(lexer.hasNext())
if(lexer.hasNextBoolean())
System.out.print(lexer.nextInt() + "|");
else
lexer.next();
(f) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("[,\- .\d]+");
while(lexer.hasNext())
if(lexer.hasNextBoolean())
System.out.print(lexer.nextBoolean() + "|");
else
System.out.print(lexer.next() + "|");
(g) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("[,\- .]+");
while(lexer.hasNext())
if(lexer.hasNextDouble())
System.out.print(lexer.nextDouble() + "|");
else
System.out.print(lexer.next() + "|");
(h) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.useDelimiter("[,\- .]+");
do {
if(lexer.hasNextInt())
System.out.print(lexer.nextInt() + "|");
} while(lexer.hasNext());
(i) Scanner lexer = new Scanner("2007, -25.0,mp3 4 u , true, after8");
lexer.reset();
do {
if(lexer.hasNextInt())
System.out.print(lexer.nextInt() + "|");
else
lexer.next();
} while(lexer.hasNext());
The class java.util.Formatter provides the core support for formatted text representation of primitive values and objects through its overloaded format() methods:
format(String format, Object... args)
format(Locale l, String format, Object... args)
Writes a string that is a result of applying the specified format string to the values in the vararg array args. The resulting string is written to the destination object that is associated with the formatter.
The destination object of a formatter is specified when the formatter is created. The destination object can, for example, be a String, a StringBuilder, a file, or any OutputStream.
The classes java.io.PrintStream and java.io.PrintWriter also provide an overloaded format() method with the same signature for formatted output. These streams use an associated Formatter that sends the output to the PrintStream or the PrintWriter, respectively. However, the format() method returns the current Formatter, PrintStream, or PrintWriter, respectively, for these classes, allowing method calls to be chained.
The String class also provides an analogous format() method, but it is static. Unlike the format() method of the classes mentioned earlier, this static method returns the resulting string after formatting the values.
In addition, the classes PrintStream and PrintWriter provide the following convenience methods:
printf(String format, Object... args)
printf(Locale l, String format, Object... args)
These methods delegate the formatting to the format() method in the respective classes.
The java.io.Console only provides the first form of the format() and the printf() methods (without the locale specification), writing the resulting string to the console’s output stream, and returning the current console.
The syntax of the format string provides support for layout justification and alignment, common formats for numeric, string, and date/time values, and some locale-specific formatting. The format string can specify fixed text and embedded format specifiers. The fixed text is copied to the output verbatim, and the format specifiers are replaced by the textual representation of the corresponding argument values. The mechanics of formatting values is illustrated below by using the PrintStream that is associated with the System.out field, i.e., the standard output stream. The following call to the printf() method of this PrintStream formats three values:
System.out.printf("Formatted output|%6d|%8.3f|%10s|%n", // Format string
2008, Math.PI, "Hello"); // Values to format
At runtime, the following characters are printed to the standard output stream, according to the default locale (in this case, Norwegian):
Formatted output| 2008| 3,142| Hello|
The format string is the first actual parameter in the method call. It contains four format specifiers. The first three are %6d, %8.3f, and %10s, which specify how the three arguments should be processed. Their location in the format string specifies where the textual representation of the arguments should be inserted. The fourth format specifier %n is special, and stands for a platform-specific line separator. All other text in the format string is fixed, including any other spaces or punctuation, and is printed unchanged.
An implicit vararg array is created for the values of the three arguments specified in the call, and passed to the method. In the above example, the first value is formatted according to the first format specifier, the second value is formatted according to the second format specifier, and so on. The '|' character has been used in the format string to show how many character positions are taken up by the text representation of each value. The output shows that the int value was written right-justified, spanning six character positions using the format specifier %6d, the double value of Math.PI took up eight character positions and was rounded to three decimal places using the format specifier %8.3f, and the String value was written right-justified spanning ten character positions using the format specifier %10s. Since the default locale is Norwegian, the decimal sign is a comma (,) in the output. We now turn to the details of defining format specifiers.
The general syntax of a format specifier is as follows:
%[argument_index][flags][width][precision]conversion
Only the special character % and the formatting conversion are not optional. Table 12.15 provides an overview of the formatting conversions. The occurrence of the character % in a format string marks the start of a format specifier, and the associated formatting conversion marks the end of the format specifier. A format specifier in the format string is replaced either by the textual representation of the corresponding value or by the specifier’s special meaning. The compiler does not provide much help regarding the validity of the format specifier. Depending on the error in the format specifier, a corresponding exception is thrown at runtime (see Selected Format Exceptions, p. 601).
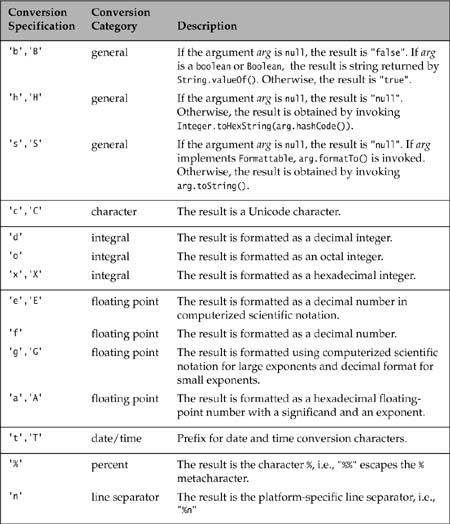
The optional argument_index has the format i$, or it is the < character. In the format i$, i is a decimal integer indicating the position of the argument in the vararg array, starting with position 1. The first argument is referenced by 1$, the second by 2$, and so on. The < character indicates the same argument that was used in the preceding format specifier in the format string, and cannot therefore occur in the first format specifier. The following printf() statements illustrate argument indexing:
String fmtYMD = "Year-Month-Day: %3$s-%2$s-%1$s%n";
String fmtDMY = "Day-Month-Year: %1$s-%2$s-%3$s%n";
out.printf(fmtYMD, 1, "March", 2008); // Year-Month-Day: 2008-March-1
out.printf(fmtDMY, 1, "March", 2008); // Day-Month-Year: 1-March-2008
out.printf("|%s|%<s|%<s|%n", "March"); // |March|March|March|
The optional flag is a character that specifies the layout of the output format. Table 12.16 provides an overview of the permissible flags, where an entry is either marked ok or ×, meaning the flag is applicable or not applicable for the conversion, respectively. The combination of valid flags in a format specifier depends on the conversion.
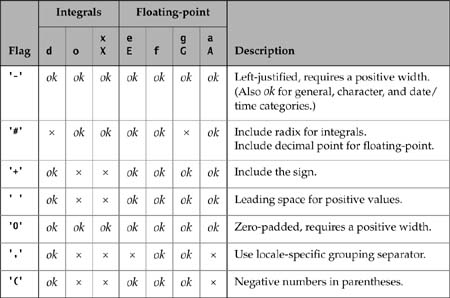
The optional width is a decimal integer indicating the minimum number of characters to be written to the output.
The optional precision has the format .n, where n is a decimal integer and is used usually to restrict the number of characters. The specific behavior depends on the conversion.
The order of the various components of a format specifier is important. More details and examples are provided in the next subsection on formatting conversions.
The required conversion in a format specifier is a character indicating how the argument should be formatted. The set of valid conversions for a given argument depends on the argument’s data type. The different conversions can be grouped into categories depending on the data types they can be applied to. These conversion categories are shown in Table 12.15, together with information about each conversion. An uppercase conversion converts any non-digit characters in the result to uppercase according to the default or a specific locale. We will not always mention the uppercase conversion explicitly, but it is understood that any discussion about the lowercase conversion also applies to the uppercase conversion.
These general conversions may be applied to any argument type.
The width indicates the minimum number of characters to output. The precision specifies the maximum number of characters to output, and takes precedence over the width, resulting in truncating the output if the precision is smaller than the width. Padding is only done to fulfill the minimum requirement.
Only the ‘-’ flag is applicable for left-justifying the output, requiring a positive width.
The conversions 'b' and 'B' represent boolean conversions. The following printf statement illustrates using boolean conversions. Note how null and non-boolean values are formatted and the effect of precision on the output.
out.printf("|%7b|%-7b|%7.3b|%2.3b|%b|%n",
null, true, false, "false", "Kaboom"); // | false|true | fal|tru|true|
The conversions 'h' and 'H' represent hash code conversions. The output is the hash code of the object:
out.printf("|%7h|%-7h|%n", null, "Kaboom"); // | null|85809961|
The conversions 's' and 'S' represent string conversions. The following printf calls illustrates using string conversions. An array is passed as argument in the method call. Note how we can access the elements of this array in the format specifier with and without argument indices. Note also how the precision and the width affect the output.
Object[] arguments = {null, 2008, "Kaboom"};
out.printf("1|%.1s|%.2s|%.3s|%n", arguments); // 1|n|20|Kab|
out.printf("2|%6.1s|%4.2s|%2.3s|%n", arguments); // 2| n| 20|Kab|
out.printf("3|%2$s|%3$s|%1$s|%n", arguments); // 3|2008|Kaboom|null|
out.printf("4|%2$-4.2s|%3$2.3s|%1$-6.1s|%n", arguments); // 4|20 |Kab|n |
These character conversions may be applied to primitive types which represent Unicode characters, including char, byte, short, and the corresponding object wrapper types.
The ‘-’ flag is only applicable for left-justifying the output, requiring a positive width.
The width specifies the minimum number of characters to output, padded with spaces if necessary.
The precision is not applicable for the character conversions.
Some examples of using the character conversions are shown below, together with the output:
out.printf("1|%c|%-6c|%6c|%c|%n",
null, (byte) 58, ':', 'a'), // 1|null|: | :|a|
The 'd', 'o', and 'x' conversions format an argument in decimal, octal or hexadecimal formats, respectively. These integral conversions may be applied to the integral types: byte, short, int, long, and to the corresponding object wrapper types.
Table 12.16 shows which flags are allowed for the integral conversions. The following flag combinations are not permitted: "+ " (sign/space) or "-0" (left-justified/ zero-padded). Both '-' and '0' require a positive width.
The width indicates the minimum number of characters to output, including any characters because of the flag that are specified. It is overridden if the argument actually requires a greater number of characters than the width.
For integral conversions, the precision is not applicable. If a precision is provided, an exception will be thrown.
Some examples of using the integral conversions are shown below, together with the output:
out.printf("1|%d|%o|%x|%n", (byte) 63, 63, 63L); // 1|63|77|3f|
out.printf("2|%d|%o|%x|%n",
(byte) -63, -63, -63L); // 2|-63|37777777701|ffffffffffffffc1|
out.printf("3|%+05d|%-+5d|%+d|%n", -63, 63, 63); // 3|-0063|+63 |+63|
out.printf("4|% d|% d|%(d|%n", -63, 63, -63); // 4|-63| 63|(63)|
out.printf("5|%-, 10d|%, 10d|%,(010d|%n",
-654321, 654321, -654321); // 5|-654,321 | 654,321|(0654,321)|
// out.printf("6|%+ d|%-0d|%n", 123, 123); // Illegal flag combinations!
// out.printf("7|%+2.3d|%n", 123, 123); // Precision not permitted!
See also Section 12.5, The java.text.NumberFormat Class, p. 546, where formatting of numbers is discussed.
These floating-point conversions may be applied to floating-point types: float, double, and the corresponding object wrapper types.
The conversions 'e' and 'E' use computerized scientific notation (e.g., 1234.6e+00). The conversion 'f' uses decimal format (for example, 1234.6). The conversions 'g' and 'G' use general scientific notation, i.e. computerized scientific notation for large exponents and decimal format for small exponents. The conversions 'a' and 'A' use hexadecimal exponential format (e.g., 0x1.5bfp1, where the exponent p1 is 21).
Table 12.16 shows which flags are allowed for the integral conversions. As for the integral conversions, the following flag combinations are not permitted: "+ " (sign/space) or "-0" (left-justified/zero-padded). Both '-' and '0' require a positive width.
The width indicates the minimum number of characters to output, with padding if necessary.
If the conversion is 'e', 'E', 'f', 'a' or 'A', the precision is the number of decimal places. If the conversion is 'g' or 'G', the precision is the number of significant digits. If no precision is given, it defaults to 6. In any case, the value is rounded if necessary.
Some examples of using the floating-point conversions are shown below, together with the output in the UK locale (the default locale in this case).
out.printf("1|%1$e|%1$f|%n", Math.E); // 1|2.718282e+00|2.718282|
out.printf("2|% .3f|%-+10.3f|%1$+10f|%n",
Math.PI, -Math.PI); // 2| 3.142|-3.142 | +3.141593|
out.printf("3|%-12.2f|%12.2f|%n",
1.0/0, 0.0/0.0); // 3|Infinity | NaN|
Here is an example of a table of aligned numerical values:
for(int i = 0; i < 4; ++i) {
for(int j = 0; j < 3; ++j)
out.printf("%,10.2f", Math.random()*10000.0);
out.println();
}
Output (default locale is UK):
548.35 3,944.18 1,963.84
7,357.72 9,764.11 209.10
4,897.17 6,026.72 3,133.10
6,109.59 6,591.39 4,872.63
See also Section 12.5, The java.text.NumberFormat Class, p. 546, where formatting of numbers is discussed.
These date/time conversions may be applied to types which are capable of encoding a date and/or time: long, Long, Calendar, and Date. The general syntax for the string specifier for these conversions is the following:
%[argument_index][flags][width]conversion
The optional argument index, flags, and width are defined as for general, character and numeric types. No precision can be specified.
The required conversion is a two character sequence. The first character is 't' or 'T'. The second character indicates the format to be used. Here we will only present an overview of date/time conversions that are called date/time composition conversions (shown in Table 12.17). The following printf calls use these formats to output the values in the current calendar according to the US locale:
Calendar myCalendar = Calendar.getInstance();
out.printf(Locale.US, "1|%tR%n", myCalendar); // 1|15:50
out.printf(Locale.US, "2|%tT%n", myCalendar); // 2|15:50:45
out.printf(Locale.US, "3|%tr%n", myCalendar); // 3|03:50:45 PM
out.printf(Locale.US, "4|%tD%n", myCalendar); // 4|03/11/08
out.printf(Locale.US, "5|%tF%n", myCalendar); // 5|2008-03-11
out.printf(Locale.US, "6|%tc%n", myCalendar); // 6|Tue Mar 11 15:50:45 EDT 2008

See also Section 12.4, The java.text.DateFormat Class, p. 541, where formatting of date/time values is discussed.
Table 12.18 shows some selected unchecked exceptions in the java.util package that can be thrown because of errors in a format string. These exceptions are subclasses of the IllegalFormatException class.
The destination object of a Formatter, mentioned earlier, can be any one of the following:
• a StringBuilder, by default
• an Appendable, e.g., a String that implements this interface
• a file specified either by its name or by a File object
• a PrintStream, or another OutputStream
The Formatter class provides various constructors that allow mixing and matching of a destination object, a character encoding (i.e., a Charset) and a locale. Where no destination object is specified, the default destination object is a StringBuilder. The formatted output can be retrieved by calling the toString() method of the Formatter class. When no character encoding or locale is specified, the default character encoding or the default locale is used, respectively. The Formatter class also provides the flush() and the close() methods, analogous to those of an output stream, that also affect the destination object. Once a formatter is closed, calling the format() method throws a FormatterClosedException.
Various constructors in the Formatter class:
Formatter()
Formatter(Locale l)
Formatter(Appendable a)
Formatter(Appendable a, Locale l)
Formatter(File file)
Formatter(File file, String charset)
Formatter(File file, String charset, Locale l)
Formatter(OutputStream os)
Formatter(OutputStream os, String charset)
Formatter(OutputStream os, String charset, Locale l)
Formatter(String fileName)
Formatter(String fileName, String charset)
Formatter(String fileName, String charset, Locale l)
Formatter(PrintStream ps)
Example 12.14 illustrates the use of the format() method from different classes. Using the static String.format() method is shown at (1). The output is printed to the standard output stream, using the default character encoding and the default locale. The PrintWriter.format() method is used at (2). The formatted output is written to the specified file, using the default character encoding and the locale passed to the format() method. The format() method of the System.out field is used to write the output directly to the standard output stream at (3), i.e., the same as using the printf() method.
The Formatter.format() method is used at (4). The formatted output is written to the specified StringBuilder, using the default character encoding and the specified locale. The Formatter.format() method is used at (5) to write to an OutputStream. The formatted output is written to the specified file using the default character encoding and the locale passed to the format() method. The program flushes and closes any streams or formatters that were created explicitly.
Example 12.14 Using the format() Method
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintWriter;
import java.util.Formatter;
import java.util.Locale;
/* Using the format() method */
class UsingFormatMethod {
public static void main(String[] args) throws FileNotFoundException {
// String.format() returns a string with the formatted text. (1)
String output = String.format("1:Formatted output|%6d|%8.2f|%-10s|%n",
2008, 12345.678, "Hello");
System.out.print(output);
// PrintWriter.format() writes to the specified file, (2)
// using the specified locale.
PrintWriter pw = new PrintWriter("output2.txt");
pw.format(new Locale("no", "NO"),
"2:Formatted output|%6d|%8.2f|%-10s|%n",
2008, 12345.678, "Hello");
pw.flush();
pw.close();
// PrintStream.format() writes to the standard output stream. (3)
System.out.format("3:Formatted output|%6d|%8.2f|%-10s|%n",
2008, 12345.678, "Hello");
// Formatter.format() writes to the string builder, (4)
// using specified locale.
StringBuilder stb = new StringBuilder();
Formatter fmt = new Formatter(stb, new Locale("no", "NO"));
fmt.format("4:Formatted output|%6d|%8.2f|%-10s|%n",
2008, 12345.678, "Hello");
System.out.print(stb);
fmt.flush();
fmt.close();
// Formatter.format() writes to the specified file, (5)
// using the specified locale.
Formatter fmt2 = new Formatter(new FileOutputStream("output5.txt"));
fmt2.format(new Locale("no", "NO"),
"5:Formatted output|%6d|%8.2f|%-10s|%n",
2008, 12345.678, "Hello");
fmt2.flush();
fmt2.close();
}
}
Output from the program:
1:Formatted output| 2008|12345.68|Hello |
3:Formatted output| 2008|12345.68|Hello |
4:Formatted output| 2008|12345,68|Hello |
Contents of the file output2.txt after program execution:
2:Formatted output| 2008|12345,68|Hello |
Contents of the file output5.txt after program execution:
5:Formatted output| 2008|12345,68|Hello |