
14
File Organizations
14.1. Introduction
The main component of a computer system is the memory, also referred to as the main memory or the internal memory of the computer. Memory is a storage repository of data that is used by the CPU during its processing.
When the CPU has to process voluminous data, the computer system has to take recourse to external memory or external storage to store the data, due to the limited capacity of the internal memory. The devices which provide support for external memory are known as external storage devices or auxiliary storage devices.
Given that the main memory of the computer is the primary memory, the external memory is also referred to as secondary memory and the devices as secondary storage devices. Examples of secondary storage devices are magnetic tapes, magnetic disks, drums, floppies, USB flash drives and so forth. While the internal memory of a computer system is volatile, meaning that data may be lost when the power goes off, secondary memory is nonvolatile.
Each of the secondary storage devices has its distinct characteristics. Magnetic tapes, built on the principle of audio tape devices, are sequential storage devices that store data sequentially. On the other hand, magnetic disks, drums, floppy diskettes and USB flash drives are random access storage devices that can store and retrieve data both sequentially and randomly. Random-access storage devices are also known as direct access storage devices. Section 18.2 elaborately discusses the structure and configuration of magnetic tapes and disks.
The growing demands for information have called for the support of what is known as tertiary storage devices. Though these devices are capable of storing huge volumes of data running to terabytes or petabytes, at lesser costs, they are characterized by significantly higher read/write time when compared to secondary storage devices. Examples of tertiary storage devices are optical disk jukeboxes, ad hoc tape storage and tape silos.
The organization of data in the internal memory calls for an application of both sequential and linked data structures. In the same vein, the organization of data in the secondary memory also calls for a number of strategies for their efficient storage and retrieval. Files are used for the organization of data in the secondary memory.
In this chapter, we discuss the concept of files and their methods of organization, for example, heap or pile files, sequential files, indexed sequential files and direct files.
14.2. Files
A file is commonly thought of as a folder that holds a sheaf of related documents arranged according to some order. In the context of secondary storage devices, files are used for the storage and organization of related data. In fact, a file is a logical organization of data. A file is technically defined to be a collection of records. A record is a logical collection of fields. A field is a collection of characters, which can be either numeric, alphabetic or alphanumeric. A file could be a collection of fixed length records or variable length records, where the lengthof a record is indicative of the number of characters that makes up a record.
Let us consider the example of a student file. The file is a logical collection of student records. A student record is a collection of fields such as roll number, name, city, date of birth, grade and so forth. Each of these fields could be numeric, alphabetic or alphanumeric. A sample set of student records are shown below.

A file is a logical entity and has to be mapped onto a physical medium for its storage and access. To facilitate storage, it is essential to know the field length or fieldsize (normally specified in bytes). Thus, every file has its physical organization.
For example, the student file stored on a magnetic tape would have the records listed above occurring sequentially, as shown in Figure 14.1. In such a case the processing of these records would only call for the application of sequential data structures. In fact, in the case of magnetic tapes, the logical organization of the records in the files and their physical organization when stored in the tape, are one and the same.

Figure 14.1 Physical organization of the student file on a magnetic tape
On the other hand, the student file could be stored either sequentially or non-sequentially (random access) on a magnetic disk, as called for by the applications using the file. In the case of random access, the records are physically stored in various portions of the disk where space is available. Figure 14.2 illustrates a snapshot of the student file storage in the disk. The logical organization of the records in the file is kept track of by physically linking the records through pointers. The processing of such files would call for linked data structures. Thus, in the case of magnetic disks, for files that have been stored in a non-sequential manner, the logical and physical organizations need not coincide.

Figure 14.2 Physical organization of the student file on a magnetic disk
The physical organization of the files is designed and ordered by the File Manager of the operating system.
14.3. Keys
In a file, one or more fields could serve to uniquely identify the records for efficient retrieval and storage. These fields are known as primary keys or commonly, keys. For example, in the student file discussed above, the roll number could be designated as the primary key as it uniquely identifies each student and hence the record too.
If additional fields were added to the primary key, the combination would still continue to uniquely identify the record. Such a combination of fields is referred to as a super key. For example, the combination of roll number and name would still continue to uniquely identify records in the student file. A primary key can therefore be described as a minimal super key.
It is possible to have more than one combination of fields that can serve to uniquely identify a record. These combinations are known as candidate keys. It now depends on the file administrator to choose any one combination as the primary key. In such a case, the rest of the combinations are called alternate keys. For example, consider an employee file shown below.
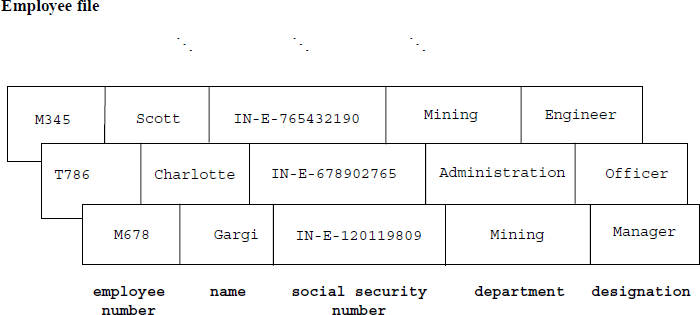
Here, both the fields, employee number and social security number could act as the primary keys since both would serve to uniquely identify the record. Thus, we term them candidate keys. If we chose to have an employee number as the primary key then the social security number would be referred to as an alternate key.
A field or a combination of fields that may not be a candidate key, but can serve to classify records based on a particular characteristic, are called secondary keys. For example in the employee file, department could be a secondary key to classifying employees based on the department.
14.4. Basic file operations
Some of the basic file operations are:
- open, which prepares the files concerned, for reading or writing. Commonly, a file pointer is opened and set at the beginning of the file that is to be read or written;
- read, when the contents of the record pointed to by the file pointer, are read;
- insert, when new records are added to the file;
- delete, when existing records are removed from the file;
- update, when data in one or more fields in the existing records of the files are modified;
- reset, when the file pointer is set to the beginning of the file;
- close, when the files that were opened for operations are closed for access.
Commercial implementations of programming languages provide a variety of other file operations. However, from a data structure standpoint, the operations of insert, delete and update are considered significant and therefore we shall restrict our discussion to these operations alone.
In the case of deletion, the operation could be executed logically or physically, as determined by the application. In the case of physical deletion, the records are physically removed from the file. On the other hand, in the case of logical deletion, the record is either “flagged” or “marked” to indicate that it is not in use. Every record has a bit or a byte called the deletion marker which is set to some value indicating deletion of the record. Though the records are physically available in the file, they are logically excluded from consideration during file processing. The logical deletion also facilitates the restoration of the deleted records, which could be done by “unflagging” or “unmarking” the records.
In the case of the student file, the addition of details pertaining to new students could call for the insertion of appropriate student records. Students opting to drop out of the program could have their records ‘logically’ or ‘physically’ deleted. Again, a change of address or a change in grades after revaluation could call for the relevant fields of the record to be updated.
14.5. Heap or pile organization
The heap or pile organization is one of the simplest file organizations. These are non-keyed sequential files. The records are maintained in no particular order. The insert, delete and update operations are undertaken as described below. This unordered file organization is basically suitable for instances where records are to be collected and stored for future use.
14.5.1. Insert, delete and update operations
Insert: To insert records into the heap or pile, the records are merely appended to the file.
Delete: To delete records, either a physical deletion or logical deletion is done. In the case of physical deletion, either the record is physically deleted or the last record is brought forward to replace the deleted one. This indeed calls for several accesses.
Update: To retrieve a record to update it, a linear search of the file is needed, which in the worst case, could call for a search from the beginning to the end of the file.
14.6. Sequential file organization
Sequential files are ordered files maintained in a logical sequence as primary keys. The organization was primarily meant to satisfy the characteristics of magnetic tapes which are sequential devices.
14.6.1. Insert, delete and update operations
A sequential file is stored in the same logical sequence as its records, on the tape. Thus, the physical and logical organization of sequential files are one and the same. Since random access is difficult on a tape, the handling of insert, delete and update operations could turn out to be expensive if they are handled on an individual basis. Therefore a batched mode of these operations is undertaken.
For a sequential file S, the records which are to be inserted, deleted or updated are written onto a separate tape as a sequential file T. The file T, known as the transaction file, is ordered according to its primary keys. Here, S is referred to as the master file. With both S and T ordered according to their primary keys, a maintenance program reads the two files and while undertaking a “merge” operation, executing the relevant operation (insert/delete/update), in parallel. The updated file is available on an output tape.
During the merge operation, in the case of an insert operation, the new records merely get copied onto the output tape in the primary key ordering sequence. In the case of a delete operation, the corresponding records are stopped from getting copied onto the output tape and are just skipped. For update operation, the appropriate fields are updated and the modified records are copied onto the output tape. Figure 14.3 illustrates the master maintenance procedure.
The new file that is available on the output tape is referred to as the new master file Snew. The advantage of this method is that it leaves a backup of the master file before it is updated. The file S at this point gets referred to as the old master file. In fact, it is common to retain an ancestry of backup files depending on the needs of the application. In such a case, while the new master file would be referred to as the son file, the old master file would be referred to as the father file and the older master file as the grandfather file, and so on.

Figure 14.3 Master file maintenance
14.6.2. Making use of overflow blocks
Since the updating of the file calls for the creation of a new file each time, an alternative could be to store the records in blocks with ‘holes’ in them. The ‘holes’ are vacant spaces at the tail end of the blocks.
Insertions are accommodated in these ‘holes’. If there is no space to accommodate insertions in the appropriate blocks, the records are accommodated in special blocks called overflow blocks.
Although this method renders insert operations efficient, retrievals could call for a linear search of the whole file. In the case of deletions, it would be prudent to adopt logical deletions. However, when the number of logical deletions increases or when the overflow blocks fill up fast, it is advisable to reorganize the entire file.
14.7. Indexed sequential file organization
While sequential file organizations provide efficient sequential access to data, random access to records is quite cumbersome. Indexed sequential file organizations are hybrid organizations that provide efficient sequential, as well as random access to data. The method of storage and retrieval, known as the indexed sequential access method (ISAM) makes use of indexes to facilitate random access of data, while the data themselves are maintained in sequential order. The files following the ISAM method of storage and retrieval are also known as ISAM files.
14.7.1. Structure of the ISAM files
An ISAM file consists of:
- a primary storage area, where the data records of the file are sequentially stored;
- a hierarchy of indexes, where an index is a directory of information pertaining to the physical location of the records;
- overflow area(s) or block(s), where new records to be added to the file and which could not be accommodated in the primary storage area, are stored.
Though ISAM files provide efficient retrieval of records, the operations of insertion and deletion can get quite involved and need to be efficiently handled. There are many methods to maintain indexes and efficiently handle insertions and deletions in the primary storage, as well as overflow areas.
The primary storage area is divided into blocks where each block can store a definite number of records. The data records of the ISAM file are distributed onto the blocks in the logical order of their sequence, one block after the other. Thus, all of the keys of the records stored in block Bt have to be greater than or equal to those of the records stored in the previous block Bt-1.
The index is a two-dimensional table with each entry indicative of the physical location of the records. An index entry is commonly a key-address pair, (K, B↑ ) where K is the key of the record and B↑ is a pointer to the block containing the record or sometimes a pointer to the record itself. An index is always maintained in the sorted order of the keys K. If the index maintains an entry for each record of the file then the index is an N × 2 table where N is the size of the file. In such a case the index is said to be a dense index. In the case of large files, the processing time of dense indexes can be large due to the huge amount of entries in them. To reduce the processing time, we could devise strategies so that only one entry per block is made in the index. In such a case, the index is known as a sparse index. Commonly, the entry could pertain to a special record in the block, known as the block anchor. The block anchor could be either the first record (smallest key) or the last record (largest key) of the block. If the file occupies b blocks the size of the index would be b × 2.
14.7.2. Insert, delete and update operations for a naïve ISAM file
The insert, delete and update operations for a naïve ISAM file are introduced here. However, it needs to be recollected that a variety of methods exist for maintaining indexes, each of which commands its exclusive methods of operations.
Insert: To insert records, the records are first inserted in the primary storage area. The existing records in a block may have to be moved to make space for the new records. This, in turn, may call for a change in the index entries, especially if the block anchors shift due to the insertions.
A simple solution would be to provide ‘holes’ in the blocks where new records could be inserted. However, the possibility of blocks overflowing cannot be ruled out. In such a case the new records are pushed into the overflow area, which merely maintains the records as an unordered list. Another option would be to maintain an overflow area for each block, as a sorted linked list of records.
Delete: The most convenient way to handle deletions is to undertake logical deletions by making use of deletion markers.
Update: A retrieval of records for update is quite efficiently done in an ISAM file. To retrieve a record with key K', we merely undertake a linear search (or even binary search discussed in section 16.5 of Chapter 16) of the index table to find the entry (K, B↑ ), such that K' ≤ K. Following the pointer B↑, we linearly search the block of records to retrieve the desired record. However, in the case of the record being available in the overflow blocks, the search procedure can turn out to be a bit more complex.

Figure 14.4 Schematic diagram of a naïve ISAM file
For example, in the ISAM file structure shown in Figure 14.4, to retrieve the record with key 255, we merely search the index to find the appropriate entry (286, B2↑ ), where B2↑ is the pointer to the block B2. A linear search of the key 255 in block B2 retrieves the desired record.
14.7.3. Types of indexing
There are many methods of indexing files. Commonly, all methods of indexes make use of a single key field on which the index entries are maintained. The key field is known as the indexing field. A few of the indexing techniques are detailed here.
14.7.3.1. Primary indexing
This is one of the most common forms of indexing. The file is sorted according to its primary key. The primary index is a sparse index that contains the pair (K, B↑ ) as its entries, where K is the primary key of the block anchor and B↑ is the pointer to the block concerned. The indexing method used in the ISAM file illustrated in example 14.1, is in fact primary indexing. The general operations of insert, delete and update discussed in section 14.7.2 hold true for primary indexing-based ISAM files.
14.7.3.2. Multilevel indexing
In the case of voluminous files, despite employing sparse indexes, searching through the index can itself become an overhead due to a large number of entries in the index. In such a case, to cut down the search time, a hierarchy of indexes also known as multilevel indexes is constructed. Multilevel indexes are indexes over indexes.
Example 14.2 discusses an ISAM file based on multilevel indexing. It can be seen that while the lowest level index points to the physical location of the blocks, the rest of the indexes point to their lower level indexes. To retrieve a record with key K, we begin from the highest level index and work our way down the indexes until the appropriate block is reached. A linear search of the block yields the record.
14.7.3.3. Cluster indexing
Typically, ISAM files have their records ordered sequentially according to the primary key values. It is possible that the records are ordered sequentially according to some non-key field that can carry duplicate values. In such a case, the indexing field, which is the non-key field, is called the clustering field and the index is called the cluster index.
A cluster index is a sparse index. As with all other sparse indexes, a cluster index is also made up of entries of the form (I, B↑), where I is the clustering field value and B↑ is the block address of the appropriate record. For a group of records with the same value for I, B↑ indicates the block address of the first record in the group. The rest of the records in the group may be easily accessed by making a forward search in the block concerned, since the records in the primary storage area are already sorted according to the non-key field.
However, in the case of cluster indexing, the insert/delete operations, as before, can become complex, since the data records are physically ordered. A straightforward strategy for efficient handling of insert/delete operations would be to maintain the block or cluster of blocks in such a way that all records holding the same value for their clustering field are stored in the same blocks or cluster of blocks.

Figure 14.5 An ISAM file based on multilevel indexing

Figure 14.6 An ISAM file based on cluster indexing
14.7.3.4. Secondary indexing
Secondary indexes are built on files for which some primary access already exists. In other words, the data records in the prime storage area are already sorted according to the primary key and available in blocks. The secondary indexing may be on a field that may be a candidate key (distinct values) or on a non-key field (duplicate values).
In the case of the secondary key field having distinct values, the index is a dense index with one entry (K, B↑ ), where K is the secondary key value and B↑ is the block address, for every record. The (K, B↑ ) entries are however ordered on the key K, to facilitate binary search on the index during retrievals of data. To retrieve the record with secondary key value K, the entire block of records pointed to by B↑ is transferred to the internal memory and a linear search is done to retrieve the record.
In the case of the secondary key field having duplicate values, there are various options available to construct a secondary index. The first is to maintain a dense index of (K, B↑ ) pairs, where K is the secondary key value and B↑ is the block address, for every record. In such a case the index could carry several entries of (K, B↑ ) pairs, for the same value of K. The second option would be to maintain the index as consisting of variable length entries. Each index entry would be of the form (K, B1↑, B2↑, B3↑, …… Bt↑ ), where Bi↑’s are block addresses of the various records holding the same value for the secondary key K. The third option is a modification of the second where Bi↑’s are maintained as a linked list of block pointers and the index entry is just (K, T↑ ), where T↑ is a pointer to the linked list.
A file could have several secondary indexes defined on it. Secondary indexes find significant applications in query-based interfaces to databases.
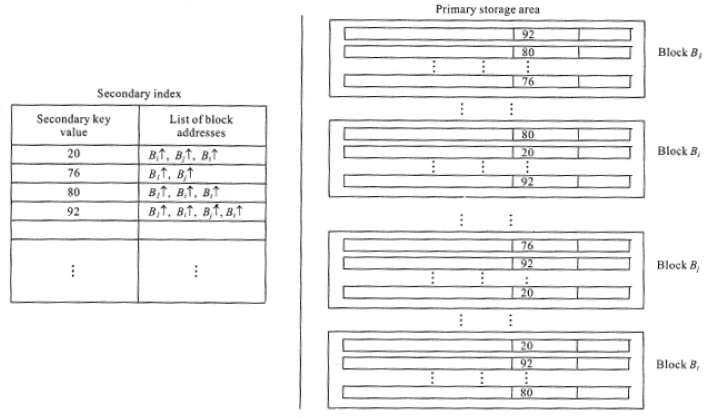
Figure 14.7 Secondary indexing of a file
14.8. Direct file organization
Direct file organizations make use of techniques to directly map the key values of their records to their respective physical location addresses. Commonly, the techniques employ some kind of arithmetic or mathematical functions to bring about the mapping. The direct mapping of the keys with their addresses paves the way for efficient retrievals and storage.
Hash functions are prominent candidates used by direct files to bring about the mapping between the keys and the addresses. Hash functions and hashing were elaborately discussed in Chapter 13. The application of hashing for the storage of files in the external memory is known as external hashing.
Given a file of records {R1, R2, R3,……RN} with keys {k1, k2, k3,…kN}, a hash function H is employed to determine the storage address of each of the records in the storage device. Given a key k, H(k) yields the storage address. Unlike other file organizations where indexes are maintained to track the storage address area, direct files undertake direct mapping of the keys to the storage locations of the records. In practice, the hash function H(k) yields a bucket number which is then mapped to the absolute block address in the disk.
Buckets are designed to handle collisions amongst keys. Thus, a group of synonyms shares the same bucket. In the case of overflow of a bucket, a common solution employed is to maintain overflow buckets with links to their original buckets. Severe overflows to the same bucket may call for multiple overflow buckets linked to one another. This may however deteriorate the performance of the file organization during a retrieval operation. If a deletion leaves an overflow bucket empty, then the bucket is removed and perhaps could be inserted into a linked list of empty overflow buckets for future use.

Figure 14.8 A direct file organization
Summary
- The internal memory or the primary memory of a computer is limited in capacity. To handle voluminous data, a computer system resorts to external memory or secondary memory.
- A file is a collection of records and a record is a collection of fields. File organizations are methods or strategies for the efficient storage and retrieval of data. While the organization of records in a file refers to its logical organization, the storage of the records on the secondary storage device refers to its physical organization.
- A primary key or a key, is a field or a collection of fields that uniquely identifies a record. Candidate keys, super keys, secondary keys and alternate keys are other terms associated with the keys of a file.
- Files support a variety of operations such as open, close, read, insert, delete, update and reset.
- A heap or pile organization is a non-keyed file where records are not maintained in any particular order.
- A sequential file organization maintains its records in the order of its primary keys. The insert, delete and update operations are carried out in a batched mode, leading to the creation of transaction and new master files. The operations could also be handled by making use of overflow blocks.
- Indexed sequential files offer efficient sequential and random access to its data records. The random access is made possible by making use of indexes. A variety of indexing based file organizations are possible by employing various types of indexing. Primary indexing, multilevel indexing, cluster indexing and secondary indexing are some of the important types of indexing.
- Direct file organizations make use of techniques to map their keys to the physical storage addresses of the records. Hash functions are a popular choice to bring about this mapping.
14.9. Illustrative problems
Review questions
- A minimal super key is in fact a --------------------
- secondary super key
- primary key
- non-key
- none of these
- State whether true or false:
- A cluster index is a sparse index
- A secondary key field with distinct values yields a dense index
- true
- true
- true
- false
- false
- true
- false
- false
- An index consisting of variable length entries where each index entry would be of the form (K, B1↑, B2↑, B3↑, …… Bt↑ ), where Bi↑’s are block addresses of the various records holding the same value for the secondary key K, can occur only in
- primary indexing
- secondary indexing
- cluster indexing
- multilevel indexing
- Match the following:
- heap file organization
- transaction file
- sequential file organization
- non keyed
- ISAM file organization
- hash function
- direct file organization
- indexing
- (A, i)) (B, iv)) (C, iii)) (D, ii))
- (A, ii)) (B, iv)) (C, iii)) (D, i))
- (A, ii)) (B, i)) (C, iv)) (D, iii))
- (A, iii)) (B, i)) (C, ii)) (D, iv))
- Find the odd term out in the context of basic file operations, from the following list:
open close update delete evaluate read
- close
- read
- open
- evaluate
- Distinguish between primary memory and secondary memory.
- Give examples for i) super key ii) primary key iii) secondary key and iv) alternate key.
- How are insertions and deletions carried out in a pile?
- Distinguish between logical and physical deletion of records.
- Compare the merits and demerits of a heap file with that of a sequential file organization.
- How do ISAM files ensure random access to data?
- What is the need for multilevel indexing in ISAM files?
- When are cluster indexes used?
- How are secondary indexes maintained?
- What is external hashing?
- A file comprises the following sample set of primary keys. The block size in the primary storage area is 2. Design an ISAM file organization based on i) primary indexing and ii) multilevel indexing (level = 3).
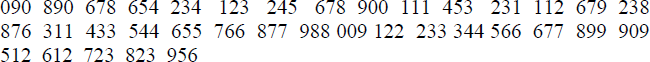
- Making use of the hash function h(k)= k mod 11, where k is the key, design a direct file organization for the sample file (list of primary keys) shown in review problem 16. Assume that the bucket size is 3 and the block size is 4.
- Assume that the sample file (list of primary keys) shown in review problem 16, had a field called
categorywhich carries the character ‘A’ if the primary key is odd and ‘B’ if the primary key is even. Design a cluster index-based file organization built on the fieldcategory. Assume a block size of 4.
Programming assignments
- Implement the
used carfile discussed in illustrative problem 14.3, in a programming language of your choice that supports the data structures of files and records. Experiment with the basic operations of a file. What other operations does the language support to enhance the use of the file? Write a menu-driven program to implement the operations. - Assume that the
used carfile discussed in illustrative problem 14.3, was implemented as a sequential file. Simulate the batched mode of updating the sequential file by creating a transaction file of insertions (details of cars that are brought in for sale) and deletions (cars that were sold out), to update the existing master file. - A
moviefile has the following record structure:name of the movieproducerdirectortypeproduction costAssume that the
name of the movieis the primary key of the file. The fieldtyperefers to the type of the movie, for example, drama, sci-fi, horror, crime thriller, comedy and so forth. Input a sample set of records of your choice into themoviefile.- Implement a primary index-based ISAM file organization.
- Implement secondary indexes on
director,typeandproduction cost. - How could the secondary index-based file organization in Programming Assignment 3 (ii), be used to answer a query such as “Who are the directors who have directed films of the comedy or drama type, who have incurred the highest production cost?”
- A company provides reimbursement of mobile phone subscription charges to its employees belonging to the managerial cadre and above. The following record structure captures the details.
employee number, which is designated as the primary key, is a numerical 3-digit key.typerefers to a post-paid or pre-paid class of subscription to the mobile service.subscription chargesrefer to the charges incurred by the employee at the end of every month.employee numberdesignationmobile numbertypeSubscription chargesFor a sample set of records implement the file as
- an array of records (block size = 1), and
- an array of pointers to records (assume that each pointer to a record is a linked list of two nodes, each representing a record. In other words, each block is a linked list of two nodes (block size = 2)).
Make use of an appropriate hash function to design a direct file organization for the said file. Write a menu-driven program, which
- inserts new records when recruitments or promotions to the managerial cadre is made,
- deletes records when the employees concerned relinquish duties or terminate mobile subscriptions due to various reasons,
- updates records regarding the
subscription chargesat the end of every month, changes if any, intypeanddesignationfields and so forth.
- Make use of a random number generator to generate a list of 500 three-digit numbers. Create a sequential list FILE of the 500 numbers. Artificially implement storage blocks on the sequential list with every block containing a maximum of 10 numbers only. Open an index INDX over the sequential list FILE which records the highest key in each storage block and the address of the storage block. Implement Indexed Sequential search to look for keys K in FILE. Compare the number of comparisons made by the search with that of the sequential search for the same set of keys.
Extend the implementation to include an index over the index INDX.