
- What idempotence is and its side effects
- A tour of all standard methods (get, list, create, update, delete)
- An additional semi-standard method: replace
- Benefits and drawbacks of relying on standard methods
As we learned in chapter 1, one of the characteristics of a good API is predictability. One great way to build a predictable API is to vary only the resources available while keeping a consistent set of specific actions (often called methods) that everyone can perform on those resources. This means that each of these methods must be consistent in appearance and behavior down to the last detail; otherwise, the predictability is completely lost when the same action isn’t identical when applied to multiple resources. This pattern explores the specific rules that should be followed when implementing these standard methods across the resources in an API.
7.1 Motivation
One of the most valuable aspects of a well-designed API is the ability for users to apply what they already know in order to more quickly understand how an API works. In other words, the less a user has to learn about an API, the quicker they can start using it to accomplish their own goals. One way to do this, expressed often in RESTful APIs, is to use a set of standard actions (or methods) on a variety of resources defined by the API. Users will still need to learn about the resources in the API, but once they’ve built up their understanding of those resources, they’re already familiar with a set of standard methods that can be performed on those resources.
Unfortunately, this only works if each of the standard methods is truly standardized, both across the API as a whole as well as more generally across the majority of web APIs. Luckily, the REST standard has been around for quite some time and has laid the groundwork for this level of web API standardization. Based on that, this pattern outlines all the standard methods and the various rules that should be applied to each of them, taking quite a lot of inspiration from the REST specifications.
7.2 Overview
Since our goal is to drive more consistency and end up with a more predictable API, let’s start by looking at the list of proposed standard methods and their overall goals, shown in table 7.1.
Table 7.1 Standard methods overview
While these methods and their descriptions might seem quite straightforward, there is actually a large amount of information missing. And when information is missing, this leads to ambiguity. This ambiguity ultimately leads to a wide range of interpretation of how each method should act, leading to the same “standard” method acting completely different across different APIs or even different resources in the same API.
Let’s look closely at a single method for an example: delete. The behavior description in table 7.1 says that this method removes an existing resource. In other words, we might expect that if a resource was created and a user deletes it, we should get the equivalent of a 200 OK HTTP response code and go on our merry way. But what if the resource doesn’t exist yet? Should the response still be OK? Or should it return a 404 Not Found HTTP error?
Some might argue that the intent of the method is to remove the resource, so if the resource no longer exists, then it has done its job and should return an OK result. Others argue that it’s important to distinguish between a result (the resource no longer existing when the method is executed) and the behavior (the resource was specifically removed by this method being executed), and therefore trying to remove a resource that doesn’t exist should return a Not Found error, indicating that the resource does not exist now, but it also did not exist when this method was executed.
Further, what if the resource does exist but the user trying to execute the method does not have access to the resource? Should the result be a 404 Not Found HTTP error? Or a 403 Forbidden HTTP error? Should these error codes differ depending on whether the resource actually exists? Ultimately, this subtle design choice is meant to prevent an important security problem. In this case, if an unauthorized user attempts to retrieve a resource, they can determine whether the resource truly doesn’t exist (by receiving a 404 Not Found response) or whether the resource does exist, but they just don’t have access to it (by receiving a 403 Forbidden response). By doing so, it’s possible for someone with no access permissions whatsoever to probe a system for the resources that exist and potentially target them later for attack.
There is no good reason for every API designer to re-answer these questions over and over. Instead, the guidelines in this chapter provide some standard answers that ensure consistency (and prevent security leaks or other issues) across standard methods in a way that will grow gracefully as an API expands over time. But rather than just stating a bunch of rules, let’s explore these types of nuanced and subtle issues in the next section.
7.3 Implementation
Before we get into the specifics of each standard method, let’s begin by exploring the cross-cutting aspects that apply to all standard methods, starting with an obvious question: is it a hard requirement that all resources must support all standard methods? In other words, if one of my resources is immutable, should the resource still support the update standard method? Or if it’s permanent, should it still support the delete standard method?
7.3.1 Which methods should be supported?
Since the goal of standardizing a set of methods is all about driving consistency, it may seem a bit curious that this question is even up for discussion. In other words, it might seem hypocritical that there’s an entire chapter on implementing a set of standard behaviors in the exact same way, only to then allow some resources to simply opt out of implementing the methods at all. And that’s a fair point, but when it comes down to it, practicality is still a critical component of API design, and there’s simply no way to escape the real-life scenarios where certain resources might not want to support all standard methods. In short, not every standard method is required for each resource type.
Some scenarios are different from others though, and it’ll become important to distinguish between cases where a method shouldn’t be supported entirely (e.g., returning the equivalent of a 405 Method Not Allowed HTTP error) and cases where a method is simply not permitted on this specific instance (returning the equivalent of a 403 Forbidden HTTP error). What should never happen though, is a scenario where an API simply omits a specific route (e.g., the update method) and returns a 404 Not Found HTTP error whenever someone attempts to use that method on a resource. If an API were to do this, the implication is that the resource doesn’t exist, which isn’t true: it’s the method that technically doesn’t exist for that resource type.
What are the rules when deciding whether to support each standard method? While there are no firm requirements, the general guideline is that each standard method should exist on each resource unless there is a good reason for it not to (and that reason should be documented and explained). For example, if a resource is actually a singleton sub-resource (see chapter 12), the resource is a singleton and exists only by virtue of its parent existing. As a result, only the get and update standard methods make any sense; the rest can be ignored entirely. This is also an example of a case where the method fundamentally doesn’t make sense and as a result should return the equivalent of a 405 Method Not Allowed HTTP error.
In other cases, certain methods might not make sense for a specific instance of a resource but still make conceptual sense for the resource type. For example, if a storage system has a “write protection” flag on a specific directory that prevents modifications on resources living inside that directory, the API should still support the standard methods (e.g., update and delete) but return an error when someone attempts to perform those actions on the resource if they’re not currently permitted. This scenario also covers resource types that might be considered permanent (i.e., should never be deleted) or immutable (i.e., should never be modified). Just because they are permanent and immutable now does not mean they will never be in the future. As a result, it makes the most sense to implement the complete set of standard methods and simply return a 403 Forbidden error code whenever anyone attempts to modify or delete them.
Now that we have some guidelines on when to define which methods, let’s look at one of the core assumptions of standard methods: a lack of side effects.
7.3.2 Idempotence and side effects
Since a critical piece of standard methods is their predictability, it should come as no surprise that standard methods should do exactly what they say they’ll do and nothing more. Put simply, standard methods should not have any side effects or unexpected behavior. Further, some methods have a specific property called idempotence, which indicates whether repeating the same request (with the same parameters) multiple times will have the same effect as a single request. Breaking the assumptions generally held about this property on specific methods can lead to disastrous consequences, such as data loss or corruption.
Determining what is acceptable and not breaking the no-side-effects rule can be complicated, as many APIs have scenarios where extra behavior is required, beyond that indicated by just a simple standard method, and often it can seem as though the standard method is the right place for that behavior to live. This can lead to even more confusion when the extra behavior is subtle or doesn’t really change any meaningful state, so much so that we might still consider the method idempotent.
What constitutes a side effect? Some are obvious, for example in an email API, creating an email and storing the information in a database would not be considered a side effect. But if that standard create method also connected via SMTP to a server to send that email, this would be considered a side effect (and therefore avoided as part of the standard create method).
What about a request counter, where every time you retrieve a resource it increments a counter to keep track of how many times it has been retrieved via a standard get method? Technically, this means this method is no longer idempotent as state is changing under the hood, but is this really such a big problem? The complicated answer is it depends. Does the counter updating have a performance implication where the request will be significantly slower or vary more than it otherwise would? What happens if updating the counter fails for any reason? Is it possible to have an error response where the resource retrieval fails simply because the counter had a technical issue that prevented it from being updated?
Ultimately, as we’ll learn in chapter 24 with defining a versioning policy, your judgment of what constitutes a side effect is a bit open to interpretation. While the blatant side effects (such as connecting to third-party or external services or triggering additional work that may cause the standard method to fail or result in a partially executed request) should be avoided at all costs, some of the more subtle cases might make sense for an API given consumer expectations.
Now that we’ve covered the general aspects of standard methods, let’s dig into each method and explore some of what we’ll need to consider for each one, starting with the read-only methods first and continuing with the rest.
7.3.3 Get
The goal of the standard get method is very straightforward: the service has a resource record stored somewhere and this method returns the data stored in that record. To accomplish this, the method accepts only a single input: the identifier of the resource in question. In other words, this is strictly a key-value lookup of the data stored.
Listing 7.1 An example of the standard get method
abstract class ChatRoomApi { @get("/{id=chatRooms/*}") ❶ GetChatRoom(req: GetChatRoomRequest): ChatRoom; ❷ } interface GetChatRoomRequest { id: string; }
❶ The standard get method always retrieves a resource by its unique identifier.
❷ The result of a standard get method should always be the resource itself.
As with most methods that don’t actively alter the underlying data, this method should be idempotent, meaning you should be free to run it multiple times and, assuming no other changes are happening concurrently, the result should be the same each time. This also means that this method, like all standard methods, should not have any noticeable side effects.
While there is plenty more to discuss about a standard get method, such as retrieving specific resource revisions, we’ll leave these topics for later discussion in specific future design patterns. For now, let’s move on to the next read-only standard method: list.
7.3.4 List
Since the standard get method is exclusively a key-value lookup, we obviously need another mechanism to browse the available resources, and the list standard method is just that. In a list method, you provide a specific collection that you need to browse through and the result is a listing of all the resources belonging to that collection.
It’s important to note that the standard list method is different from the standard get method in its target: instead of asking for a specific resource, we instead ask for a list of resources belonging to a specific collection. This collection might itself belong to another specific resource, but that’s not always the case. For example, consider the case where we might have a set of ChatRoom resources, each of which contains a collection of Message resources. Listing ChatRoom resources would require targeting the chatRooms collection, whereas listing the Message resources for a given ChatRoom would target the messages collection, belonging to the specific ChatRoom.
Listing 7.2 An example of the standard list method
abstract class ChatRoomApi { @get("/chatRooms") ❶ ListChatRooms(req: ListChatRoomsRequest): ListChatRoomsResponse; @get("/{parent=chatRooms/*}/messages") ❷ ListMessages(req: ListMessagesRequest): ListMessagesResponse; } interface ListChatRoomsRequest { filter: string; } interface ListChatRoomsResponse { results: ChatRoom[]; } interface ListMessagesRequest { parent: string; filter: string; } interface ListMessagesResponse { results: Message[]; }
❶ When listing resources belonging to a top-level collection, there is no target!
❷ When listing resources belonging to a subcollection of a resource, the target is the parent resource (in this case, the ChatRoom resource).
While the concept of listing a set of resources might seem just as simple as the standard get method, it actually has quite a lot more to it than meets the eye. While we won’t address everything about this method (e.g., some aspects are covered in future design patterns, such as in chapter 21), there are a few topics worth covering here, starting with access control.
While it doesn’t make sense to go into too much detail, there is an important aspect worth covering: how should the list method behave when different requesters have access to different resources? Put differently, what if you want to list all the available ChatRoom resources in an API but you only have access to see some of those resources? What should the API do?
It’s obviously important that API methods are consistent in their behavior, but does that mean that every response must be the same for every requester? In this scenario, the answer is no. The response should only include the resources the requester has access to. This means that, as you’d expect, different people listing the same resources will get different views of the data.
If possible, resources could be laid out to minimize scenarios like these (e.g., ensure single-users resources have a separate parent), leading instead to simple 403 Forbidden error responses when listing resources that are secured from the requester; however, there is simply no avoiding the fact that there will be times when a user has access to some items in a collection but not all.
Next, there is often the temptation to include a count of the items along with the listing. While this might be nice for user-interface consumers to show a total number of matching results, it often adds far more headache as time goes on and the number of items in the list grows beyond what was originally projected. This is particularly complicated for distributed storage systems that are not designed to provide quick access to counts matching specific queries. In short, it’s generally a bad idea to include item counts in the responses to a standard list method.
If some sort of result count is absolutely necessary, or the data involved in the collection is guaranteed to remain small enough to handle counting results without any extreme computation burden, it’s almost always more efficient to use some sort of estimate and rely on that to indicate the total number of results rather than an exact count. And if the count is an estimate rather than an exact count, it’s also important that the field be named for what it is (e.g., resultCountEstimate) to avoid potential confusion about the accuracy of the value. To leave breathing room for the unexpected, if you decide that result counts are both important and feasible, it’s still a good idea to name the field as an estimate (even if the value is an exact count). This means that if you need to change to estimates in the future to alleviate the load on the storage system, you’re free to do that without causing any confusion or difficulty for anyone. After all, an exact count is technically just a very accurate estimate.
For similar reasons, applying ordering over a list of items is also generally discouraged. Just like showing a result count, the ability to sort the results is a common nice-to-have feature, particularly for consumers who are rendering user interfaces. Unfortunately, allowing sorting over results in a standard list method can lead to even more difficulty than displaying result counts.
While allowing sorting might be easy to do early on in the life cycle of an API, with relatively small amounts of data it will almost certainly become more and more complicated as time goes on. More items being returned in a list requires more server processing time to handle the sorting, but, most importantly, it’s very difficult to apply a global sort order to a list that is assembled from several different storage backends (as is the case in distributed storage systems). For example, consider trying to consolidate and sort 1 billion items spread across 100 different storage backends. This is a complicated problem to solve with static data in an offline processing job (even if each data source sorts its smaller portion of the data first) but even more complex for a rapidly changing data set like a live API. Further, executing this type of sorting on demand each time a user wants to view their list of resources can very easily result in overloaded API servers.
All in all, this tiny little feature tends to add a significant amount of complexity in the future for relatively little value to the API consumer. As a result, just like a total result count, it is generally a bad idea.
While ordering and counting the items involved in a standard list method is discouraged, filtering the results of that method to be more useful is a common, and therefore encouraged, feature. This is because the alternatives to applying a filter (e.g., requesting all items and filtering the results after the fact) are exceptionally wasteful of both processing time and network bandwidth.
When it comes to implementing filtering, there is an important caveat. While it can be tempting to design a strictly typed filtering structure to support filtering (e.g., with a schema for the various conditions, as well as “and” and “or” evaluation conditions), this type of design typically does not age very well. After all, there’s a good reason SQL still accepts queries as simple strings. Just like enumerations, as seen in chapter 5, as we expand the functionality or different types available for filtering, clients are required to upgrade their local schemas in order to take advantage of these changes. As a result, while filtering is encouraged, the best choice of data type for conveying the filter itself is a string, which can then be parsed by the server and applied before returning results, either by passing the parsed filter to the storage system if possible, or directly by the API service. This topic is discussed in much more detail in chapter 22.
So far, we’ve focused on reading data out of an API. Let’s switch gears and look at how we get data into an API using the standard create method.
7.3.5 Create
Neither the standard get method (section 7.3.3) nor the standard list method (section 7.3.4) is of any use unless there is some data in the API. And the primary mechanism to get data into any API is to use a standard create method. The goal of the standard create method is simple: given some information about a resource, create that new resource in the API such that it can be retrieved by its identifier or discovered by listing resources. To see what this might look like, an example of creating ChatRoom and Message resources is shown in listing 7.3. As you can see, the request (sent via a HTTP POST method) contains the relevant information about the resource, and the resulting response is always the newly created resource. Additionally, the target is either the parent resource, if available, or nothing more than a top-level collection (e.g., "/chatRooms").
Listing 7.3 An example of the standard create method
abstract class ChatRoomApi { @post("/chatRooms") ❶ CreateChatRoom(req: CreateChatRoomRequest): ChatRoom; ❷ @post("/{parent=chatRooms/*}/messages") ❶ CreateMessage(req: CreateMessageRequest): Message; ❷ } interface CreateChatRoomRequest { resource: ChatRoom; } interface CreateMessageRequest { parent: string; resource: Message; }
❶ In both cases, the standard create method uses the POST HTTP verb.
❷ The standard create method always returns the newly created resource.
While the concept behind creating resources is simple, there are few areas worth exploring in more detail as they’re a bit more complicated than meets the eye. Let’s start by taking a brief look at how we identify these newly created resources.
As we learned in chapter 6, it’s usually best to rely on server-generated identifiers for newly created resources. In other words, we should let the API itself choose the identifier for a resource rather than attempting to choose one ourselves. That said, there are many cases where it makes more sense to let the consumer of the API choose the identifier (e.g., if the API is being used by a mobile device that intends to synchronize a local versus remote set of resources). In those types of scenarios, it is perfectly acceptable to allow consumer-chosen IDs; however, they should follow the guidelines provided in chapter 6.
If you must provide a resource identifier at the time it’s being created, this should be done by setting the ID field in the resource interface itself. For example, to create a ChatRoom resource with a specific identifier, we would make an HTTP request looking something like POST /chatRooms { id: 1234, ... }. As we’ll see later on, there’s an alternative to this with the semi-standard replace method, but since not all APIs are expected to support that method, it’s probably best to focus on setting identifiers as part of a standard create method.
Years ago, it was almost guaranteed that every bit of data you create would be stored in a single database somewhere, usually a relational database service like MySQL or PostgreSQL. Nowadays, however, there are many more storage options that scale horizontally without falling over as the data set grows. In other words, when you have too much data for the database as it’s configured, you can simply turn on more storage nodes and the system will perform better with the larger data size.
These systems have been a miraculous cure for the plague (and gift) of enormous data sets and extraordinarily large numbers of requests, but they often come with their own set of trade-offs. One of the most common is related to consistency, with eventual consistency being a common side effect of the seemingly infinite scalability. In eventually consistent storage systems, data is replicated around the system over time, but it usually takes a while to arrive at all the available nodes, leading to a world where data is updated but hasn’t been replicated everywhere right away. This means you may create a resource but it might not show up in a list request for quite some time. Even worse, depending on how routing is configured, it might be possible that you create a resource but then get an HTTP 404 Not Found error when you attempt to retrieve that same resource via a standard get method.
While this might be unavoidable depending on the technology being used, it should absolutely be avoided if at all possible. One of the most important aspects of an API is its transactional behavior, and one of the key aspects of that is strong consistency. This means, in short, that you should always be able to immediately read your writes. Put differently, it means that once your API says you’ve created a resource, it should be created in every sense of the word and available to all the other standard methods. That means you should be able to see it in a standard list method, retrieve it with a standard get method, modify it with a standard update method, and even remove it from the system with a standard delete method.
If you find yourself in a position where you have some data that cannot be managed in this way, you should seriously consider using a custom method (see chapter 9) to load the data in question. The reason is pretty simple: APIs have expectations about the consistency of standard methods but, as we’ll see in chapter 9, custom methods come with none of those expectations. So rather than having an eventually consistent CreateLogEntry method, consider using a custom import method such as ImportLogEntries, which would explain to any potential users that the results are eventually consistent across the system. Another option, if you can be certain when the data replication across the system is complete, would be to rely on long-running operations, which we’ll explore in more detail in chapter 10.
Now that we have some idea of the subtleties involved in creating new resources, let’s look at how we modify existing resources with the standard update method.
7.3.6 Update
Once a new resource is loaded into an API, unless the resource is itself immutable and intended to never be changed, we’ll need a straightforward way to modify the resource, which leads us to the standard update method. The goal of this method is to change some existing information about a single resource, and as a result it should avoid side effects, as noted in section 7.3.2.
The recommended way to update a resource relies on the HTTP PATCH method, pointing to a specific resource using its unique identifier and returning the newly modified resource. One key aspect of the PATCH method is that it does partial modification of a resource rather than a full replacement. We’ll explore this in much more detail, as there’s quite a bit to discuss on the topic (e.g., how do you distinguish between user intent of “don’t update this field” versus “set this field to blank”), but for now the key takeaway is that a standard update method should update only the aspects of a resource explicitly requested by the API consumer.
Listing 7.4 Example of the standard update method
abstract class ChatRoomApi { @patch("/{resource.id=chatRooms/*}") ❶ UpdateChatRoom(req: UpdateChatRoomRequest): ChatRoom; } interface UpdateChatRoomRequest { resource: ChatRoom; // ... ❷ }
❶ The standard update method uses the HTTP PATCH verb to modify only specific pieces of the resource.
❷ We’ll learn how to safely handle partial updates of resources in chapter 8.
The standard update method is the perfect place to modify an existing resource, but there are still some scenarios where updates are best done elsewhere. Scenarios like transitioning from one state to another are likely to be accomplished by some alternative action. For example, rather than setting a ChatRoom resource’s status to archived, it’s much more likely that an ArchiveChatRoom() custom method (see chapter 9) would be used to accomplish this. In short, while an update method is the standard mechanism to modify an existing resource, it is far from the only way to accomplish this.
7.3.7 Delete
Once a resource has outlived its purpose in an API, we’ll need a way to remove it. This is exactly the purpose of the standard delete method. Listing 7.5 shows how this method might look for deleting a ChatRoom resource in an API. As you’d expect, the method relies on the HTTP DELETE method and is targeted at the resource in question via its unique identifier. Further, unlike most other standard methods, the return value type here is an empty message, expressed as void in our API definition. This is because the successful result of a standard delete method is to have the resource disappear entirely.
Listing 7.5 The standard delete method
abstract class ChatRoomApi { @delete("/{id=chatRooms/*}") ❶ DeleteChatRoom(req: DeleteChatRoomRequest): void; ❷ } interface DeleteChatRoomRequest { id: string; }
❶ The standard delete method uses the HTTP DELETE verb to remove the resource.
❷ The result is an empty response message rather than an actual response interface.
While this method is also very straightforward in purpose, there is a bit of potential confusion about whether this is considered idempotent and how to handle requests to delete already deleted resources. Ultimately, this comes down to a question of whether the standard delete method is more result focused (declarative) or action focused (imperative). On the one hand, it’s possible to picture deleting a resource as simply making a request to declare that your intent is for the resource in question to no longer exist. In that case, deleting a resource that has already been deleted should be considered a success due to the simple fact that the resource is gone after the request finished processing. In other words, executing the standard delete method twice in a row with the same parameters would have the same successful result, therefore making the method idempotent, shown in figure 7.1.
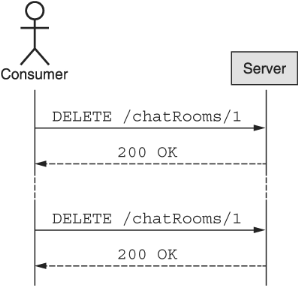
Figure 7.1 A declarative view on the standard delete method results in idempotent behavior.
On the imperative side, it’s possible to picture the standard delete method as requesting that an action be taken, that action being to remove the resource. Therefore, if the resource does not exist when the request is received, the service is unable to perform the intended action and the request would result in a failure. In other words, attempting to delete the same resource twice in a row might result in a success the first time but a failure the second time, shown in Figure 7.2. As a result, a delete method behaving this way would not be considered idempotent. But which option is right?

Figure 7.2 Imperative view of the standard delete method results in non-idempotent behavior.
While there are lots of declarative APIs out there (e.g., Kubernetes), resource-oriented APIs are generally imperative in nature. As a result, the standard delete method should behave in the non-idempotent manner. In other words, attempting to delete a resource that doesn’t exist should result in a failure. This can lead to lots of complications when you’re worried about network connections getting snapped and responses being lost, but we’ll explore quite a bit more about repeatability for API requests in chapter 26.
Finally, let’s look at a semi-standard method that’s related to our implementation of the standard update method called the standard replace method.
7.3.8 Replace
As we learned in section 7.3.6, the standard update method is responsible for modifying the data about existing resources. We also noted that it relied exclusively on the HTTP PATCH method to allow updating only pieces of the resource (which we’ll learn far more about in chapter 8). But what if you actually want to update the entire resource? The standard update method makes it easy to set specific fields and control which fields are set on the resource, but this means that if you’re unfamiliar with a field (e.g., it was added in a future minor version, as we’ll see in chapter 24), it’s possible that the resource will have a value that you don’t intend to exist.
For example, in figure 7.3 we can see a consumer updating a ChatRoom resource, attempting to set the description field using the HTTP PATCH method. In this case, if the consumer wanted to erase all the tags on the ChatRoom resource but the client didn’t know about the tags field, there’s no way for the client to accomplish this! So how do you handle it?

Figure 7.3 The standard update method modifies the remote resource but does not guarantee the final content.
The semi-standard replace method’s goal is exactly that: replace an entire resource with exactly the information provided in this request. This means that even if the service has additional fields that aren’t known about yet by the client, these fields will be removed given that they weren’t provided by the request to replace the resource, shown in figure 7.4.

Figure 7.4 The standard replace method ensures the remote resource is identical to the request content.
To accomplish this, the replace method uses the HTTP PUT verb rather than the PATCH verb targeted at the resource itself and provides exactly (and exclusively) the information meant to be stored in the resource. This full replacement, compared to the specific targeted modification provided by the standard update method, ensures that the remote copy of a resource looks exactly as expressed, meaning clients need not worry whether there are additional fields lingering around that they weren’t aware of.
Listing 7.6 Definition of the standard replace method
abstract class ChatRoomApi { @put("/{resource.id=chatRooms/*}") ❶ ReplaceChatRoom(req: ReplaceChatRoomRequest): ChatRoom; ❷ } interface ReplaceChatRoomRequest { resource: ChatRoom; }
❶ Unlike the standard update method, the replace method relies on the HTTP PUT verb.
❷ Similar to the standard update method, the replace method returns the newly updated (or created) resource.
This leads to a potentially confusing question: if we can replace the content of a resource with exactly what we want, can’t we just use that same mechanism to replace a non-existing resource? In other words, can this magical replace standard method actually be a tool for creating new resources?
The short answer is yes: this replacement tool can be used to create new resources, but it should not be a replacement itself for the standard create method because there are cases where API consumers may want to create a resource if (and only if) the resource doesn’t already exist. Similarly, they may want to update a resource if (and only if) the resource already does exist. With the standard replace method, there’s no way to know whether you’re replacing (updating) an existing resource or creating a new one, despite the ultimate success of the method either way. Instead, you only know that what was once stored in the place for a specific resource is now set to the content provided when making the replace request.
Further, as you might guess, using the standard replace methods to create resources means the API must support user-chosen identifiers. As we learned in chapter 6, this is certainly possible and acceptable in some cases but should generally be avoided for a variety of reasons (see section 6.4.2).
And with that, we’ve explored the key standard methods that will make up the lion’s share of the interaction for most resource-oriented APIs. In the next section we’ll briefly review what this looks like when we put it all together.
7.3.9 Final API definition
Shown in listing 7.7 is a collection of all the standard methods we’ve talked about so far: create, get, list, update, delete, and even replace. The example follows those from earlier, with ChatRoom resources and child Message resources.
Listing 7.7 Final API definition
abstract class ChatRoomApi { @post("/chatRooms") CreateChatRoom(req: CreateChatRoomRequest): ChatRoom; @get("/{id=chatRooms/*}") GetChatRoom(req: GetChatRoomRequest): ChatRoom; @get("/chatRooms") ListChatRooms(req: ListChatRoomsRequest): ListChatRoomsResponse; @patch("/{resource.id=chatRooms/*}") UpdateChatRoom(req: UpdateChatRoomRequest): ChatRoom; @put("/{resource.id=chatRooms/*}") ReplaceChatRoom(req: ReplaceChatRoomRequest): ChatRoom; @delete("/{id=chatRooms/*}") DeleteChatRoom(req: DeleteChatRoomRequest): void; @post("/{parent=chatRooms/*}/messages") CreateMessage(req: CreateMessageRequest): Message; @get("/{parent=chatRooms/*}/messages") ListMessages(req: ListMessagesRequest): ListMessagesResponse; } interface CreateChatRoomRequest { resource: ChatRoom; } interface GetChatRoomRequest { id: string; } interface ListChatRoomsRequest { parent: string; filter: string; } interface ListChatRoomsResponse { results: ChatRoom[]; } interface UpdateChatRoomRequest { resource: ChatRoom; } interface ReplaceChatRoomRequest { resource: ChatRoom; } interface DeleteChatRoomRequest { id: string; } interface CreateMessageRequest { parent: string; resource: Message; } interface ListMessagesRequest { parent: string; filter: string; } interface ListMessagesResponse { results: Message[]; }
7.4 Trade-offs
Whenever you rely on standards rather than entirely custom-designed tooling, you give up some flexibility. And unfortunately, unless your scenario happens to be an exact match for which the standard was designed, this trade-off can occasionally be painful. But in exchange for those mismatches, you almost always get quite a few benefits.
In some ways, it’s a bit like shopping for clothing. That new shirt in size medium might be just a bit too big, but size small is definitely way too small, and you’re left feeling like your options are either to lose weight or have a bit of a baggy shirt. But the benefit is that this shirt costs about $10 instead of $100 because it’s able to be mass produced. This is sort of the scenario we find ourselves in with resource-oriented APIs and standard methods.
These standard methods are not perfect for every situation. They will have some mismatches from time to time, for example where things aren’t really created but more brought about into existence. And you could absolutely design a custom method to handle these unique scenarios (see chapter 9). But in exchange for relying on standard methods rather than an entirely custom RPC-based API, you get the benefit of those using your APIs being able to quickly learn and understand the different methods without having to do much work. And even better, once they’ve learned how the methods work (in case they hadn’t already known that from working with RESTful APIs in the past), they know how the methods work across all of the resources in your API, effectively multiplying their knowledge at the drop of a hat.
In short, standard methods should (and likely will) get an API 90% of the way there. And for the rest of the scenarios, you have custom methods to explore in the next chapter. But the standardization of using a set of common building blocks is so useful that it’s almost always the best choice to try building the API using standard methods and only expanding to custom options when some unforeseen scenario makes them absolutely necessary.
7.5 Exercises
-
Is it acceptable to skip the standard create and update methods and instead just rely on the replace method?
-
What if your storage system isn’t capable of strong consistency of newly created data? What options are available to you to create data without breaking the guidelines for the standard create method?
-
Why does the standard update method rely on the HTTP
PATCHverb rather thanPUT? -
Imagine a standard get method that also updates a hit counter. Is it idempotent? What about a standard delete method? Is that idempotent?
-
Why should you avoid including result counts or supporting custom sorting in a standard list method?
Summary
-
Standard methods are a tool to drive more consistency and predictability.
-
It’s critical that all standard methods follow the same behavioral principles (e.g., all standard create methods should behave the same way).
-
Idempotency is the characteristic whereby a method can be repeatedly called with identical results on all subsequent invocations.
-
Not all standard methods must be idempotent, but they should not have side effects, where invoking the method causes changes somewhere else in the API system.
-
While it might seem counterintuitive, the standard delete method should not be idempotent.
-
Standard methods do force a tight fit into a very narrow set of behaviors and characteristics, but this is in exchange for a much easier-to-learn API that allows users to benefit from their existing knowledge about resource-oriented APIs.