
- How pagination allows users to consume large data sets in bite-sized chunks
- The specific size of each page of data
- How API services should indicate that paging is complete
- How to define the page token format
- How to page across large chunks of data inside a single resource
In this pattern, we’ll explore how to consume data when the number of resources or the size of a single resource is simply too large for a single API response. Rather than expecting all of the data in a single response interface, we’ll enter a back-and-forth sequence whereby we request a small chunk of data at a time, iterating until there is no more data to consume. This functionality is commonly seen in many web interfaces, where we go to the next page of results, and is equally important for APIs.
21.1 Motivation
In a typical API, consumers may need to retrieve and browse through their resources. As these resources grow in both size and number, expecting consumers to read their data in a single large chunk becomes more and more unreasonable. For example, if an API offered access to 1 billion data entries using 100 GB of storage space, expecting a consumer to retrieve this data using a single request and response could be painfully slow or even technically infeasible. How best can we expose an interface that allows consumers to interact with this data? In other words, how can we avoid forcing consumers to bite off more than they can chew? The obvious answer is to split the data into manageable partitions and allow consumers to interact with these subsets of the data, but this leads to yet another question: how and where do we split the data?
We might choose to draw a dividing line between any two records, but this won’t always be sufficient, particularly in cases where single records might grow to be unwieldy in size themselves (e.g., a single 100 MB object). In this case the question of splitting the data into reasonable chunks becomes even more fuzzy, particularly if that chunk is structured data (e.g., a 10 MB row in a database). Where should we split the data inside a single record? How much control should we provide to consumers over these split points?
On the other hand, there are some scenarios where consumers actually want all the records in the database delivered using a single request and response (e.g., backing up or exporting all data); however, these two scenarios are not necessarily mutually exclusive, so this doesn’t change the fact that we still need a way of interacting with data in reasonably sized chunks. For this common scenario, there’s a pattern that has become quite common on many websites and carries over nicely to APIs: pagination.
21.2 Overview
The term pagination comes from the idea that we want to page through the data, consuming data records in chunks, just like flipping through pages in a book. This allows a consumer to ask for one chunk at a time and the API responds with the corresponding chunk, along with a pointer for how the consumer can retrieve the next chunk. Figure 21.1 is a flow diagram demonstrating how a consumer might request multiple pages of resources from an API until there are no more left.

Figure 21.1 Flow of pagination
To accomplish this, our pagination pattern will rely on the idea of a cursor, using opaque page tokens as a way of expressing the loose equivalent of page numbers. Given this opacity, it will be important that the API responds both with the chunk of results as well as the next token. When it comes to handling large single resources, the same pattern can apply to each resource, where the content of a resource can be built up over multiple pages of data.
21.3 Implementation
At a high level, we really want a way of picking up where we left off, effectively viewing a specific window of the available data. To do this, we’ll rely on three different fields to convey our intent:
-
pageToken, which represents an opaque identifier, meaningful only to the API server of how to continue a previously started iteration of results -
maxPageSize, which allows the consumer to express a desire for no more than a certain number of results in a given response -
nextPageToken, which the API server uses to convey how the consumer should ask for more results with an additional request
To see this more clearly, we can replace some of the text in figure 21.2 with these fields.

Figure 21.2 Pagination using these specific fields
If we were to translate this pattern into an API definition, we would end up with something that looks very similar to a standard list, with pageToken and maxPageSize added to the request and nextPageToken added to the response.
Listing 21.1 API specification for paginating in a standard list method
abstract class ChatRoomApi { @get("/chatRooms") ListChatRooms(req: ListChatRoomsRequest): ListChatRoomsResponse; } interface ListChatRoomsRequest { pageToken: string; ❶ maxPageSize: number; ❶ } interface ListChatRoomsResponse { results: ChatRoom[]; nextPageToken: string; ❶ }
❶ Adding three new fields to the standard list method requests and responses to support pagination
This definition itself isn’t all that interesting, but it turns out that each of these fields has some interesting hidden secrets. Let’s first explore the harmless looking maxPageSize field.
21.3.1 Page size
At first glance, setting the size of the page you want (i.e., the number of results that should be returned) seems pretty innocuous, but it turns out that there’s quite a bit more to it. Let’s start by looking at the name of the field itself: maxPageSize.
First, why do we use a maximum instead of just setting the exact size? In other words, why do we return up to 10 results instead of exactly 10 results? It turns out that in most cases an API server might always be able to return an exact number of results; however, in many larger-scale systems this simply won’t be possible without paying a significant cost premium.
For example, imagine a system that stores 10 billion rows of data in a table, which, due to size constraints, has no secondary indexes (which would make querying this data more efficient). Let’s also imagine that there are exactly 11 matching rows with 5 right at the start, followed by 5 billion rows, followed by the remaining 6, further followed by the rest of the data, as shown in figure 21.3. Finally, let’s also assume that we have a goal of returning most responses (e.g., 99%) within 200 milliseconds.

Figure 21.3 Matching rows could be widely distributed.
In this scenario, when a user asks for a page of 10 results, we have two options to choose between. On the one hand, we could return exactly 10 results (as there are enough to fill up the page), but it’s unlikely that this query will be consistently fast given that it must scan about 5 billion rows in order to fill the page completely. On the other hand, we could also return the 5 matching rows that we find after having searched until our specific cut-off time (here this might be 180 ms) and then pick up where we left off on a subsequent request for more data.
Given these constraints, always trying to fill the entire page will make it very difficult to tell the difference between violations of our latency goal and simple variations in request complexity. In other words, if the request is slow (takes more than 200 ms), this could be because something is actually broken or because the request just searches a lot of data—and we won’t be able to distinguish between the two without quite a bit of work. If we fill a page as much as possible within our time limit, we may often be able to return exactly 10 results (perhaps because we put them close together), but we don’t paint ourselves into a corner in the case where our data set becomes exceedingly large. As a result, it makes the most sense for our interface contract to specify that we will return up to maxPageSize results rather than exactly that number.
It’s important to decide on reasonable defaults for any optional field so that consumers aren’t surprised when they leave the optional field blank. In this case, choosing a default for the maximum page size will depend on the shape and size of the resources being returned. For example, if each item is tiny (e.g., measured in bytes rather than kilobytes), it might make sense to use a default of 100 results per page. If each item is a few kilobytes, it might make more sense to use a default of 10 or 25 results. In general, the recommended default page size is 10 results. Finally, it’s also acceptable to require that consumers specify a maximum page size; however, that should be reserved for situations where a reasonable default simply can’t be assumed by the API server.
While picking a default maximum page size is important, it’s even more important to document this default value and remain consistent with it whenever possible across the rest of your API. For example, it’s generally a bad idea to use a variety of default values for this field without a good reason for each value. If a consumer learns that your API tends to default to 10 results per page, it will be very frustrating if elsewhere in that API the default is 50 results for no good reason.
Obviously a negative page size is meaningless to an API server, and as a result should be rejected with an error noting that the request is invalid. But what should we do if a request specifies a maximum page size of 3 billion? Luckily our previous design that relies on a maximum page size rather than an exact page size means that we can happily accept these values, return a reasonable number of results that our API server is capable of producing within some set amount of time, and remain consistent with the API definition.
In other words, while it’s certainly acceptable to reject page sizes above a certain limit (e.g., over 1,000 results in a page), it’s perfectly fine to consider them valid as we can always return fewer results than specified while sticking to our agreement with the consumer. Now that we’ve discussed the simple pieces, let’s move onto one of the more complex ones: page tokens.
21.3.2 Page tokens
So far we’ve noted that a page token should be used as a cursor, but we haven’t clarified the behavior of this token. Let’s start by looking at one of the simplest, yet often confusing things about how page tokens work: how we know we’re finished.
Since there is no way to force a consumer to continue making subsequent requests, pagination can technically be terminated by the consumer at any point in time where the consumer simply decides they’re no longer interested in more results. But how can the server indicate that there are no more results? In many systems we tend to assume that once we get a page of results that isn’t full we’re at the end of the list. Unfortunately, that assumption doesn’t work with our page size definition since page sizes are maximum rather than exact. As a result, we can no longer depend on a partially full page of results that indicates pagination is complete. Instead, we’ll rely on an empty page token to convey this message.
This can be confusing to consumers, particularly when we consider that it is perfectly valid to return an empty list of results along with a nonempty page token! After all, it seems surprising to get no results back but still be told there are more results. As we learned before when deciding to keep track of a maximum page size, this type of response happens when the request reaches the time limit without finding any results and cannot be certain that no further results will be found. In other words, a response of {results: [], nextPageToken: 'cGFnZTE='} is the way the API says, “I dutifully searched for up to 200 ms but found nothing. You can pick up where I left off by using this token.”
So far, we’ve discussed how we use a page token to communicate whether a consumer should continue paging through resources, but we’ve said nothing about its content. What exactly do we put into this token?
Put simply, the content of the token itself should be anything the API server needs to pick up where it left off when iterating through a list of results. This could be something abstract like a serialized object from your code, or more concrete, like a limit and offset to pass along to a relational database. For example, you might simply use a serialized JSON object like eyJvZmZzZXQiOiAxMH0= which is {"offset": 10} Base64-encoded. What’s more important though is that this implementation detail must remain completely hidden from consumers. This might seem unnecessary, but it’s actually a very important detail.
Regardless of what you put into your page token, the structure, format, or meaning of the token should be completely hidden from the consumer. This means that rather than Base64 encoding the content, we should actually encrypt the content so that the content of the token itself is completely meaningless to consumers. The reason for this is pretty simple: if the consumer is able to discern the structure or meaning of this token, then it’s part of the API surface and must be treated as part of the API itself. And since the whole point of using a page token was to allow us to change the implementation under the hood without changing the API surface for consumers, exposing this prohibits us from taking advantage of that flexibility. In essence, if we allow consumers to peek inside these page tokens, we’re leaking the implementation details and may end up in a situation where we cannot change the implementation without breaking consumers.
Now that we’ve looked at what can go into a token, this notion of keeping the token opaque to consumers begs the question: why do we use a string type to represent the token? Why not use a number or raw bytes?
Given our need to store encrypted data, it becomes obvious that using a numeric value like an integer simply won’t work. On the flip side, raw bytes tend to be a great way to store an encrypted value, but we use a string primarily out of convenience. It turns out that these tokens will often end up in URLs (as parameters in a GET HTTP request) as well as in JSON objects, neither of which handle raw bytes very well. As a result, the most common format is to use a Base64-encoded encrypted value passed around as a UTF-8 serialized string.
So far, our discussion about paging through data has assumed that the data itself was static. Unfortunately this is seldom the case. Instead of assuming that the data involved is read-only, we need a way of paging through data despite it changing, with new results added and existing results removed. To further complicate the case, different storage systems provide different querying functionality, meaning that the behavior of our API may be tightly coupled to the system used to store our data (e.g., MySQL).

Figure 21.4 A consumer might see duplicate results if new data is added in the middle of paging.
As you’d expect, this can often lead to frustrating scenarios. For example, imagine paging through data two results at a time and while this is happening someone else happens to add two new resources at the start of the list (figure 21.4). If you are using an offset count (where your next page token represents an offset starting at item 3), the two newly created resources added at the start of the list will cause you to see page 1 twice. This is because what is now the new page 2 has the offset from the start of the old page 1. Further, this scenario shows up again when a filter is applied to the request and results are modified such that they either join or leave the matching group. In that case, consumers may lose confidence in your API to deliver all the matching results as well as only matching results. What should we do?
Unfortunately, there is no simple answer to this question. If your database supports point-in-time snapshots of the data (such as Google Cloud Spanner or CockroachDB), it may make sense to encode this information in page tokens such that you can guarantee strongly consistent pagination. In many cases databases will not allow strongly consistent results, in which case the only other reasonable option is to note in the documentation of your API that pages may represent a “smear” of the data as underlying resources are added, removed, or modified (figure 21.5). As noted, it’s also a good idea to avoid relying on a numeric offset and instead use the last seen result as a cursor so that your next page token really does pick up where things left off.
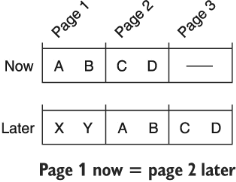
Figure 21.5 Page numbers may change over time as the underlying data changes.
When we think of consuming a large list of results, we tend to assume that the requests happen in some relatively short window of time, typically measured in seconds or minutes. But what if requests happen much more slowly (as seen in figure 21.6)? Obviously it might be a bit ridiculous to request a page of data and the next page 10 years later, but is 24 hours later all that crazy? What about 60 minutes? Unfortunately we rarely document the lifetime of page tokens, which can lead to some tricky situations.

Figure 21.6 Using page tokens from 10 years ago might be unreasonable.
Generally, APIs choose not to define limits of when page tokens might expire. Since paging through data should be an idempotent operation, the failure mode of running into an expired token just requires a retry. This means that failure here is simply an inconvenience.
That said, we should clarify how long tokens should remain valid to set consumer expectations about their paging operations. In a classic case of setting the bar low, it’s generally a good idea to set token expiration to be relatively short given your use case. For a typical API this is likely to be measured in minutes (or hours at the most), with a 60-minute expiration considered generous by most consumers.
21.3.3 Total count
Finally, a common question when paging through results is whether to include a total count of results, typically used when showing user interface elements like “Results 10–20 of 184.” When this total count is relatively small (e.g., 184 as shown), it’s an easy statistic to show. However, when this number gets much larger (e.g., 4,932,493,534), the simple act of counting those results could become so computationally intensive that it’s impossible to return an accurate count quickly.
At that point we’re left to choose between providing an accurate count very slowly, or an inaccurate count as a best guess relatively quickly. None of these options is particularly good, so APIs generally should not provide a total result count unless there is a clear need to consumers (i.e., without this count they cannot do their job) or the count can never become large enough that it lands in this situation. If, for some reason you absolutely must include the total count, it should be an integer field named totalResults attached to the response.
Listing 21.2 Response interface including the total number of results
interface ListChatRoomsResponse { results: ChatRoom[]; nextPageToken: string; totalResults: number; ❶ }
❶ Use a totalResults field to indicate how many results would be included if pagination were completed.
Now that we know all about page tokens, let’s look at a relatively unique case where single resources might be sufficiently large to justify pagination inside a single resource rather than across a collection of resources.
21.3.4 Paging inside resources
In some scenarios single resources could become quite large, perhaps to the point where consumers want the ability to page through the content of the resource, building it up into the full resource over several requests. In these scenarios, we can apply the same principles to a single resource rather than a collection of resources by breaking the resource up into arbitrarily sized chunks and using continuation tokens as cursors through the chunks.
Listing 21.3 API definition for paging through single large resources
abstract class ChatRoomApi { @get("/{id=chatRooms/*/messages/*/attachments/*}:read") ReadAttachment(req: ReadAttachmentRequest): ReadAttachmentResponse; ❶ } interface ReadAttachmentRequest { id: string; pageToken: string; ❷ maxBytes: number; ❸ } interface ReadAttachmentResponse { chunk: Attachment; ❹ fieldMask: FieldMask; ❺ nextPageToken: string; ❻ }
❶ The custom read method allows us to consume a single resource in small bite-sized chunks.
❷ The continuation token from a previous response. If empty, it indicates a request for the first chunk of the resource.
❸ Maximum number of bytes to return in a given chunk. If empty, a default value of, say, 1,024 bytes is used.
❹ A single chunk of data belonging to the resource
❺ The list of fields with data provided in the chunk to be appended to the resource
❻ The token to use when requesting the next chunk of the resource. If empty, it indicates that this is the final chunk.
In this design, we assume that a read of a single resource can be strongly consistent, which means that if the resource is modified while we are paging through its data, the request should be aborted. It also relies on the idea of building up a resource over several requests where each response contains some subset of the data to be appended to whatever data has been built up so far, shown in figure 21.7. We also rely on the field mask to explicitly convey which fields of the ChatRoom interface have data to be consumed in this given chunk.

Figure 21.7 Example flow of paging through a single large resource
21.3.5 Final API definition
Now that we’ve gone through all of the nuances of this pattern, the final resulting API definition is shown in listing 21.4, covering both pagination across a collection of resources as well as inside a single resource.
Listing 21.4 Final API definition
abstract class ChatRoomApi { @get("/chatRooms") ListChatRooms(req: ListChatRoomsRequest): ListChatRoomsResponse; @get("/{id=chatRooms/*/messages/*/attachments/*}:read") ReadAttachment(req: ReadAttachmentRequest): ReadAttachmentResponse; } interface ListChatRoomsRequest { pageToken: string; maxPageSize: number; } interface ListChatRoomsResponse { results: ChatRoom[]; nextPageToken: string; } interface ReadAttachmentRequest { id: string; pageToken: string; maxBytes: number; } interface ReadAttachmentResponse { chunk: Attachment; fieldMask: FieldMask; nextPageToken: string; }
21.4 Trade-offs
Now that we’ve seen the API resulting from this pattern, let’s look at what we lose out, starting with paging direction.
21.4.1 Bi-directional paging
One obvious thing that is not possible with this pattern is the ability to work in both directions. In other words, this pattern doesn’t allow you to page backward from the current position to look at results previously seen. While this might be inconvenient for user-facing interfaces that allow browsing through results, for programmatic interaction it’s very unlikely to be a truly necessary feature.
If a user interface truly needs this ability, one good option is to use the API to build a cache of results and then allow the interface to move arbitrarily through that cache. This has the added benefit of avoiding issues with paging consistency.
21.4.2 Arbitrary windows
Similarly, this pattern does not provide an ability to navigate to a specific position within the list of resources. In other words, there’s no way to specifically ask for page 5 for the very simple reason that the concept of a page number doesn’t exist. Instead of relying on page numbers, consumers should instead use filters and ordering in order to navigate to a specific matching set of resources. Again, this tends to be a feature required for user-facing interfaces that allow browsing rather than a requirement for programmatic interaction.
21.5 Anti-pattern: Offsets and limits
For the sake of completeness, let’s look briefly at a simple (and quite common) implementation of the spirit of this pattern that should generally be avoided. Given that most relational databases support the OFFSET and LIMIT keywords, it’s often tempting to carry that forward in an API as a way of exposing a window over a list of resources. In other words, instead of asking for some chunk we choose a specific chunk by asking for the data starting at a certain offset and limiting the size of the result to a certain number, shown in figure 21.8.

Figure 21.8 Defining a window using offets and limits
When turned in an API surface, this results in two additional fields added to the request, both integers that specify the start offset and the limit. The next offset can be easily computed by adding the number of results to the previously requested offset (e.g., nextOffset = offset + results.length). Further, we can use an incomplete page as the termination condition (e.g., hasMoreResults = (results.length != limit)).
Listing 21.5 API surface using offset and limit
abstract class ChatRoomApi { @get("/chatRooms") ListChatRooms(req: ListChatRoomsRequest): ListChatRoomsResponse; } interface ListChatRoomsRequest { ❶ offset: number; ❶ limit: number; ❶ } ❶ interface ListChatRoomsResponse { results: ChatRoom[]; }
❶ To support paging through resources, we include offset and limit parameters.
When we translate this to our underlying database, there’s basically no work to be done: we simply take the provided offset and limit parameters (e.g., a GET request to https://example.org/chatRooms/5/messages?offset=30&limit=10) and pass them along with our query.
Listing 21.6 Pagination using SQL LIMIT and OFFSET
SELECT * FROM messages WHERE chatRoomId = 5 OFFSET 30 ❶ LIMIT 10 ❷
❶ The OFFSET modifier specifies the page number (in this case an offset of 30 with 10 results per page points to page 4).
❷ The LIMIT modifier specifies the page size (in this case, 10 results per page).
The fundamental problem with this pattern is that it leaks the implementation details to the API, so this API must continue to support offsets and limits regardless of the underlying storage system. This may not seem like a big deal now, but as storage systems become more complex, implementations using limits and offsets may not always work. For example, if your data is stored in an eventually consistent distributed system, finding the starting point of an offset might actually become more and more expensive as the offset value increases.
This pattern also suffers from problems related to consistency. In this example, if some new results are added, they may cause the response to return results that were already seen in a previous page.
21.6 Exercises
-
Why is it important to use a maximum page size rather than an exact page size?
-
What should happen if the page size field is left blank on a request? What if it’s negative? What about zero? What about a gigantic number?
-
Is it reasonable for page tokens for some resource types to have different expirations than those from other resource types?
-
Why is it important that page tokens are completely opaque to users? What’s a good mechanism to enforce this?
Summary
-
Pagination allows large collections of results (or large single resources) to be consumed in a series of bite-sized chunks rather than as a single large API response using three special fields:
maxPageSize,pageToken, andnextPageToken. -
If there are more pages, a response will include a
nextPageTokenvalue, which can be provided in thepageTokenfield of a subsequent request to get the next page. -
We rely on a maximum page size rather than an exact page size as we don’t know how long it will take to fill a page exactly and must reserve the ability to return even before a page of results is fully populated.
-
Paging is complete when a response has no value for the next page token (not when the results field is empty).