
- What versioning is
- What compatibility means
- How to define backward compatibility
- The trade-offs involved in choosing a versioning strategy
- An overview of a few popular versioning strategies for web APIs
The software we build is rarely static. Instead, it tends to change and evolve frequently over time as new features are created and new functionality is added. This leads to a problem: how do we make these improvements without seriously inconveniencing users who have come to depend on things looking and acting as they did before? In this chapter, we’ll explore the most common mechanism for addressing this problem: versioning.
24.1 Motivation
Not only is software development rarely static, it is also rarely a continuous process. Even with continuous integration and deployment, we often have checkpoints or launches where some new functionality “goes live” and is visible to users, which holds especially true for web APIs. This need is exacerbated by the fact that APIs are both rigid and public, meaning changes are difficult to make safely. This leads to an obvious question: how can we make changes to a web API without causing damage to those using the API already?
The default option of “users will deal with it” is clearly not acceptable. Additionally, the alternative of “just never change the web API” is practically impossible, even when we never plan to add new functionality. For example, if there were a security or legal issue (e.g., a lawyer notifies you that the API call in question is somehow breaking the law), the change would be unavoidable. To address this, this pattern will explore how to introduce the concept of versions to an API along with a variety of different strategies that suit the wide spectrum of requirements for web APIs.
24.2 Overview
In order to ensure that existing users of an API are unaffected by subsequent changes, APIs can introduce checkpoints or versions of their API, maintaining separate deployments for each different version. This means that new changes that might typically cause problems for existing users of the API would be deployed as a new version rather than as changes to the existing version. This effectively hides changes from the subset of users that is not ready for these changes.
Unfortunately, there’s far more to this than just labeling different deployments of a web API as separate versions and calling the problem solved. We also have to worry about the different levels at which versioning can be implemented (e.g., client libraries versus wire protocol) as well as which versioning policy to choose out of the many available options. Perhaps the most challenging aspect is that there’s really no right answer. Instead, choosing how to implement versioning in a web API will vary with the expectations and profiles of those building the API, as well as those using it on the other side.
There is, however, one thing that remains invariant: the primary goal of versioning is to provide users of an API with the most functionality possible while causing minimal inconvenience. Keeping this goal in mind, let’s start by exploring what we can do to minimize inconvenience by examining whether changes can be considered compatible.
24.2.1 What is compatibility?
Compatibility is the distinction of whether two different components can successfully communicate with one another. In the case of web APIs, this generally refers to communication between a client and a server.
This concept might seem elementary, but it gets far more complicated when we consider the temporal aspects of compatibility. When you launch a web API, any client-side code will, clearly, be compatible with the API, but, unfortunately, neither APIs nor clients tend to be static or frozen in time. As things change and we start seeing more combinations of clients and servers, we have to consider whether these different combinations are able to communicate with one another, which is not as simple as it sounds. For example, if you have three iterations of an API client and three different API server versions available, you actually have nine total communication paths to think about, not all of which are expected to work.
Since API designers don’t have the ability to control client-side code written by users of the API, we instead must focus on whether changes made to the API server are compatible with existing client code. In other words, we’d call two API server versions compatible with one another if you could swap out one for the other and any existing client-side code wouldn’t notice the difference (or at least wouldn’t stop functioning).
For example, let’s imagine that a user of a web API has written some code that talks to the API (either directly or through a client library). Let’s now imagine that we have a new version of the web API service (in this case, v1.1), shown in figure 24.1. We’d say that these two versions are compatible if the client code continues working after traffic is shifted away from v1 and over to v1.1.
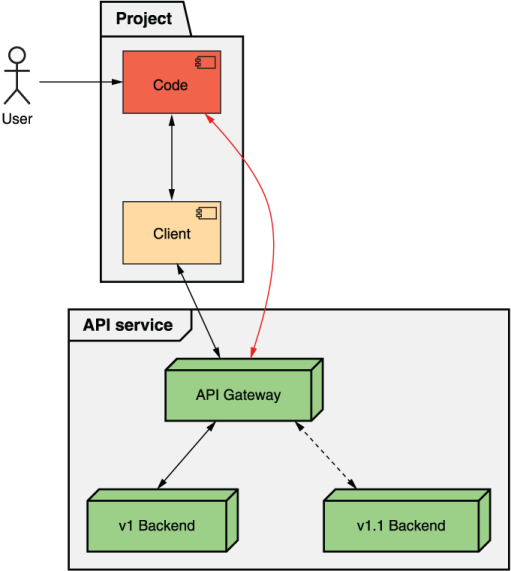
Figure 24.1 Experiment to determine whether two versions are compatible
So why do we care about compatibility? If you recall earlier in this section, we learned that versioning is a means to an end: to provide the maximum amount of functionality to our users while causing as little inconvenience as possible (and ideally no inconvenience at all). One way we do this is by deploying new versions alongside existing ones so that users can access new functionality without causing any previously written code to break for others. This works because we effectively create a whole new world with a new API version, but is this really the best we can do? What if there was an even better way to get more functionality into the hands of existing users without causing any inconvenience?
It turns out that we can do better by injecting new functionality into an existing version in such a way that the API itself is close enough to how it looked before. The modified version would be so close, in fact, that a client may not even be able to tell the difference between the API before and after adding the new functionality. This means that if we only ever make changes to an API that are compatible, all existing code will continue functioning in blissful ignorance of our changes.
But now this leads us to a very complicated and intricate problem: how do we decide whether a given change is backward compatible? In other words, how do we decide whether or not a change will be noticeable or break existing client-side code?
24.2.2 Defining backward compatibility
As we just saw, the ability to make only backward compatible changes to an API means that we have the mystical power to provide new functionality to users without the need to do any work whatsoever. So now all we have to do is decide what exactly constitutes a backward compatible change. Often, this decision is easy. We just ask ourselves a simple question: does the change cause existing code to break? If so, then it’s breaking, or backward incompatible.
It turns out that that’s not quite the whole story, and, unfortunately, this is one of those scenarios in API design where there is no single easy answer. Instead, what we’re left with is lots of different answers that are all arguably correct. Further, the degree of correctness will depend on the users who rely on your API and what their expectations are. In other words, unlike the many other design patterns in this book, this is one of those cases where there is no single clear and obvious best way to apply the pattern.
There are certainly a few topics API designers should consider when setting a policy of what should and should not be considered backward compatible. In other words, while this section will not provide a guaranteed right answer, it will pose a few different questions that really should be answered. No decision is likely to be purely right or wrong; however, designers must choose the best option based on what the users of the API expect. For example, a big data warehouse using an API will have very different expectations from a fleet of tiny IoT (Internet of Things) devices, as we’ll see a bit later.
Let’s dive right in and start looking at the most common questions worth answering.
The most obvious place to start is whether you want to even consider this ability to augment existing versions as a way of providing new functionality. In other words, are the users of your API so strict on their stability requirements that they want every single version frozen in time forever? If the main users of an API are banks, this might be a very reasonable expectation. They might want any new versions to be explicitly opt-in, such that they have to actually change their code to take advantage of any new features. And that’s perfectly fine. On the other hand, if the users of an API are a bunch of small tech startups, they might care a lot more about getting new functionality than the stability of a single API version.
If you do decide that new functionality should be permitted inside an existing version, you may need to think more closely about how that new functionality appears to API users. For example, new functionality could be represented as new fields on existing resources, as entirely new resources, or as new actions that can be performed. And each of these has different effects on the users.
In the case of new fields on existing resources, this could have a meaningful effect on any users that have very strict resource requirements. For example, imagine an API used by an IoT device with very limited memory available. If a new field is added to an existing resource, a previously working HTTP GET request could actually cause the device to run out of memory and the process to crash. This might seem far-fetched when retrieving a single resource, but imagine adding a field that might contain a lot of information and the IoT device listing all the resources. Not only might the amount of data per resource increase beyond the expected boundaries, but the problem is magnified based on the number of resources showing up in response to listing the items.
In the case of adding new resources or new API methods, it’s unlikely (if not impossible) that existing code will be aware of these new aspects of the API; however, this doesn’t mean we’re completely free from any issues. For example, imagine client-side code to back up all resources from an API. If a new resource is created and the existing code has no knowledge of the new resource, it will obviously be missing from the backup output. While in many cases it’s best to avoid taking on responsibility for these types of problems, there are scenarios where it might be reasonable to prohibit adding new resources for cases like these.
Things get a bit dicier in cases where the newly added resource introduces some sort of new dependency or relationship with the existing resources or fields. For example, imagine that an API introduces a new MessagePolicy sub-resource belonging to a ChatRoom resource (and includes a primitive policy by default). If we can only delete a ChatRoom resource after we’ve first deleted the MessagePolicy resource, we’re effectively forcing existing users to learn about this new change rather than allowing them to live in ignorance of this new functionality, which could be a bad choice.
As we discussed before, these are certainly not firm rules that must be followed. Instead, these are potential scenarios that any API designer should consider and decide on when launching a new API. Ultimately, deciding whether it’s safe to add new functionality to an existing API is a bit more art than science, so the least that can be expected is consistent and clear policies articulated on the topic.
Even if you decide that adding new functionality in any form isn’t something you want to consider safely backward compatible, there’s an even more difficult topic to cover: how to handle bug fixes.
When writing software, we rarely get things perfectly right on the first try. It’s far more common that we make a mistake, have that mistake pointed out by someone else when they find it, and then we simply go back and fix the mistake. But, as you might be seeing now, isn’t that change just another form of improved functionality? If so, do we have to fix our mistakes in a separate version? Or can we safely inject that change into the existing version and call it a backward compatible change? As you might guess, the answer to this question is, “It depends.”
Some bugs will present themselves very obviously. When a client makes a specific API request, the service has an error and returns the dreaded HTTP 500 Internal Server Error response code. In these cases, fixing the bug will usually be backward compatible because there should never be client-side code that assumes a given request will result in an internal error on the API server and then fail when it stops crashing.
But what about more subtle issues? What if a specific API request succeeds, returning a nonsensical result when it should instead have returned an error (e.g., a 400 Bad Request error)? It’s far more likely that someone has come to depend on this erroneous but mistakenly successful behavior. And if we “fix the bug,” client code that previously returned a successful result will start seeing an error result instead.
Taking this even further, consider the case where this bug is buried deep inside some calculating code and fixing it means that result numbers change. One day, when we make an API call like Add(0.1, 0.2) it might return 0.30000000000000004; then the next day we fix the bug with floating point arithmetic and it starts returning 0.3. Is this something we want to consider backward compatible?
Listing 24.1 Example of an API implementation with floating point arithmetic problems
class AdditionApi { Add(a: number, b: number): number { return a + b; ❶ } }
❶ This simply adds two floating point numbers together, resulting in a floating point bug.
Listing 24.2 Example where we fix the floating point issues using fixed-point math
const Decimal = require('decimal.js'); class AdditionApi { Add(a: number, b: number): number { return Number(Decimal(a).plus(Decimal(b))); ❶ } }
❶ By relying on a fixed-point construct, we avoid the floating point error. But is this a backward compatible change?
Unfortunately, yet again, there is no right answer. In general, fixing API calls that throw errors is pretty safe for most users. Making an API call suddenly start throwing errors is probably not a great idea, particularly if the users of the API care a lot about stability and would rather not have their code start breaking for no obvious reason. For the even more subtle fixes it really depends on the profile of the typical user and the impact of the bug. For example, if the bug really is just about adding two numbers together and having something that’s pretty close but has some weird floating point error, then perhaps it’s not all that important to fix. If the calculation is being used for rocket launch trajectories and the precision is critically important, then it probably makes sense to have a policy of fixing the bug, even if it leads to a change in results from one day to the next.
This leads us to a similar though not quite identical issue worth discussion: mandatory changes.
Almost always, the decision to add new functionality or make changes to a web API is our own. In other words, the typical course of events is that we, the creators of this web API, decide we want to make a change and get to work putting that into action. Occasionally though, we may have some work forced on us by others. For example, when the European Union (EU) passed their privacy law (General Data Protection Regulation; GDPR; https://gdpr-info.eu/), there were many new changes that were required in order to serve users residing in the EU. And since many of these requirements were focused on data retention and consent on the web, it’s certainly possible that there were API changes that needed to be made to accommodate the new regulations. This leads to the obvious question: should those changes be injected into an existing version or should they be deployed as a new, isolated version? Put differently, should we consider the changes made to adhere to the rules set out in the GDPR to be backward compatible?
Ultimately, this decision depends on what, exactly, the changes are and what the law says, but it’s still open to discussion whether the change would be considered backward compatible given who is using and relying on the API itself. In the case of the GDPR, you might follow their timeline and deploy a new version with the new changes while leaving the existing, noncompliant API available to everyone up until the date at which the GDPR comes into effect. At that point, you might begin blocking any requests coming from customers that have a registered address in the EU (or made from an IP address located in the EU), requiring these EU-based customers to use the new version of the API that is GDPR compliant. Or it might make more sense to simply shut down the noncompliant API entirely given the potential risks and fines involved in GDPR violations. It should go without saying that security patches and other changes in that category are often mandated, although not always by lawyers.
While there are cases that it’s simply impossible to be completely compliant with all laws (e.g., it’s rumored that the bitcoin blockchain has metadata storing material that’s illegal in most countries, and blockchains are built specifically so that you cannot alter past data), it’s almost always possible to make changes to comply with relevant laws. The question, really, is one of how best to make these mandated changes (often coming from lawyers or other primarily nontechnical people) without causing undue amounts of stress on API users. In other words, when these types of changes come up it’s almost impossible to insulate API users from the changes you’re mandated to make. The question is one of how to minimize the impact on those users by providing advance notice when possible and minimizing the work required of existing users.
Diving further down the rabbit hole, we can start to look at other subtle types of changes that might or might not be considered backward compatible. This generally includes deeper changes such as performance optimizations or other general subtle functionality changes that are neither bug fixing nor necessarily new functionality but are still modifications of the underlying system that responds to API requests and result in different results in some way or another.
One simple example of this is a performance optimization (or regression) that makes an API call return a result faster (or slower) than it did previously. This type of change would mean that the API response is completely identical, but it would show up after a different amount of computing time on the API server. This is often considered a backward compatible change; however, the argument could be made in the other direction.
For example, if an API call currently takes about 100 milliseconds to complete, it’s pretty difficult to notice a change that causes that same call to take 50 milliseconds (if performance improved) or 150 milliseconds (if performance degraded). On the other hand, if the API call suddenly takes 10 seconds (10,000 milliseconds) to complete, this difference in timing is enough to justify a change in programming paradigm. In other words, with an API call that slow, you might prefer to use an asynchronous programming style so that your process can do other things while waiting for the API response in the meantime. In cases like that, you might consider this a backward incompatible change, or potentially even a bug introduced that causes such a severe degradation in performance.
Another example of a deeper change might be if you rely on a machine learning model to generate some results in an API call, such as translating text, recognizing faces or items in an image, or labeling scene changes in a video. In cases such as these, changing the machine learning model that’s used might lead to drastically different results for these types of API calls. For example, one day you might have an image that the API call says contains pictures of a dog, and the next it might say that’s actually a muffin (this is more common than you might think; try searching for “Chihuahua or Muffin” to see an example).
This kind of change might be an improvement to one API user and a regression to another given the different results. And, depending on the profile of API users, there may be a need for stable results from a machine learning model. In other words, some users might really rely on an image providing consistent results unless they explicitly ask for an upgrade of sorts. In cases like these, this type of change might actually be considered backward incompatible.
The last category to consider is probably both the broadest and most subtle: general semantic changes. This refers to general behavioral changes or the meaning of the various concepts in an API (e.g., resources or fields).
These types of changes cover a broad range of possibilities. For example, this might be something large and obvious (such as the behavioral changes resulting from the introduction of a new permission model in an API), or it might be something much more subtle and difficult to notice (such as the order of items returned when listing resources or items in an array field). As you might guess, there is no blanket best practice policy for handling these types of changes. Instead, the best we can do is explore the effect it would have on existing users and their code, consider how accepting of instability those users might be, and then decide whether the change is disruptive enough to justify injecting the change into an existing version or deploying a new, isolated one.
To see what this means, let’s imagine an example Chat API with ChatRoom and User resources, where users can create messages inside chat rooms. What if we decide we want to introduce a new concept of a message policy that determines whether users are able to create messages inside chat rooms based on a variety of factors such as the rate at which users are sending messages (e.g., you can’t post more than once per second) or even the content of the messages (maybe a machine learning algorithm determines whether a message is abusive and blocks it). Would a change introducing this resource be backward compatible? As you might guess, the answer is, yet again, “maybe.”
First, the decision might depend on the default semantics of existing ChatRoom resources (e.g., do existing ChatRoom resources automatically pick up this new behavior? Or is this only reserved for newly created ChatRooms?). Regardless, we have to look at the impact to existing users. Does the new message policy concept cause existing code to break? This also depends. If someone has a script that attempts to send two messages in quick succession, that existing code might stop functioning correctly due to the restriction of only allowing a single message per second.
Listing 24.3 Code that may fail after new semantic changes introduced
function testMessageSending() { const chatRoom = ChatRoom.get(1234); chatRoom.sendMessage("Hello!"); ❶ chatRoom.sendMessage("How is everyone?"); ❷ }
❶ This sendMessage() call will succeed as usual.
❷ This sendMessage() call might fail if new rate limiting is enforced.
But how does that scenario play out? Does the user get an error response when they previously would have gotten a successful one? Or does the message simply go into a queue and show up one second later? Neither of these is necessarily right, but they are certainly different. In the first, the user will see an error immediately, which would clearly cause them to think the change has caused their existing code to break. In the latter, the error might not be noticed until later down the line (e.g., if they send two messages quickly and then verify they have both been received, the verification step will fail because the message has been delayed for a full second).
Listing 24.4 Code that may fail in a different place after changes
function testMessageSending() { const chatRoom = ChatRoom.get(1234); chatRoom.sendMessage("Hello!"); ❶ chatRoom.sendMessage("How is everyone?"); ❶ const messages = chatRoom.listMessages(); if (messages.length != 2) { ❷ throw new Error("Test failed!"); } }
❶ These two sendMessage() calls will succeed as usual.
❷ This check for the messages being posted will fail unless there is a full one-second pause between the sending and the check for the message results.
As we’ve learned, ultimately the decision of whether this change is backward compatible or not is dependent on the expectations of the existing users. Almost always there will be a user somewhere who will have code that manages to demonstrate that an API change is breaking. It’s up to you to decide whether a user could reasonably expect that particular bit of code would be supported over the lifetime of a specific version of an API. Based on that, you can determine whether your semantic change is considered backward compatible.
Now that we have at least some sort of grasp on the different issues that we’ll need to consider when deciding on a backward compatibility policy, we need to move on and look at some of the considerations that go into deciding on a versioning strategy. To do this, we need to understand the various trade-offs that will go into our decision.
24.3 Implementation
Assuming you’ve made some choices about what changes you’ll consider backward compatible, you’re only about halfway through the journey of deciding how to manage versioning. In fact, the only case where you’re already done is if you decide that absolutely everything will be backward compatible because you’ll only ever need one single version forever. In all the other cases though, we’ll need to explore and understand the many different options available on how to handle the new versions when you do happen to need them. In other words, if you make a change you consider backward incompatible and intend to create a new version, how exactly does that work? For example, what should we use as a name for the new versions? Ideally, there’s some sort of pattern to make it easy for users to understand. How long should these versions live before being deprecated? One possible answer for this is forever, but for every other choice, you’ll need a deprecation policy to convey to users when they should expect old versions to disappear and stop working.
With these types of issues in mind, let’s take a moment to explore a few popular versioning strategies. In these, we’ll explain how they work, their benefits and drawbacks, and how they compare to one another based on the trade-offs we considered in section 24.2. Keep in mind that these strategies might hint at or imply a set of policies for determining backward compatibility, but they don’t always prescribe a single policy for making this determination. In other words, each strategy should have some flexibility when it comes to choosing some policies on whether to consider a change backward compatible.
24.3.1 Perpetual stability
One of the most popular versioning strategies happens to be the one many people often end up using accidentally. Far more than anyone would care to admit, many APIs are created with no versioning scheme or strategy in mind at all. It’s only when the need arises to make a very big, scary, and (most importantly) backward incompatible change that we start to think about versioning. In that scenario, our next step is to decide that everything as it exists today will become “v1” and the API with the new changes will be called “v2.” At this point, we often might start considering what else can fit into v2. For example, maybe that other field we’ve been wanting to change for a while can be fixed in v2.
This strategy is often referred to as perpetual stability primarily because each version is typically left stable forever, with all new potentially backward incompatible changes being reserved for the next version. Even though this strategy tends to come about accidentally, there is nothing preventing us from using the same strategy in an intentional way. In that case, how might it work?
The general process we follow with this strategy is as follows:
-
All existing functionality is labeled “Version N” (e.g., the first version is Version 1”).
-
Any changes that are backward compatible are added directly into Version N.
-
Any new functionality that might fall afoul of our compatibility definitions is built as part of “Version N+1” (e.g., anything that is backward incompatible for Version 1 is saved for “Version 2”).
-
Once we have enough functionality to merit a new version, we release Version N+1.
-
Optionally, at some point in the future, we might deprecate Version N to avoid incurring extra maintenance costs or because no one appears to be using the version anymore.
-
At this point, we go back to step 1 and the cycle begins again.
This process works well in a few scenarios, with the trade-offs shown in figure 24.2. First, in cases where you don’t introduce many backward compatible changes, the majority of changes can be rolled into the existing version without causing much trouble for users and leaving most changes happily stuck on step 2. Assuming the compatibility policy maintains a reasonably high bar of what is backward compatible, this will likely lead to a very stable API in exchange for deploying lots of new functionality rapidly.

Figure 24.2 Trade-offs for perpetual stability versioning strategy
Additionally, and again assuming a reasonably high bar for what passes as a backward compatible change, this strategy tends to maximize the number of people who can reasonably use the API based on the versioning strategy. It might not be perfect, but the majority of users are likely to be in the “okay” bucket of the distribution.
This strategy is unlikely to work well in cases where users absolutely require an extreme level of granularity. For example, an IoT device as an API client using this versioning strategy would probably struggle because it encourages lots of changes rolling into the existing version whereas IoT devices typically need the ability to freeze an API at an exact version to avoid some tricky edge cases such as memory overflows.
In cases where the bar for backward compatibility is excessively high (i.e., all changes are considered incompatible), you may end up in a world with an exceeding large number of versions (v1, v2, . . ., v100, and on). Obviously, this can become unwieldy for both the service managing all of those versions and clients deciding which version is right for them to use.
Regardless of these issues, many popular APIs rely on this versioning mechanism and have made it work well over the years. For example, many Google Cloud Platform APIs use this strategy for a variety of reasons, and while it certainly isn’t perfect, it does seem to work quite well for many customers.
24.3.2 Agile instability
Another popular strategy, sometimes referred to as agile instability, relies on a sliding window of active versions in order to minimize the maintenance overhead for API designers while still providing new functionality in a timely manner to customers. While far from perfect, this strategy can be quite effective with active and engaged API users who are involved enough in product development to cope with frequent deprecations of previous versions in exchange for the new functionality provided.
This strategy works by pushing each version through a steady life cycle, going from birth (preview), where all functionality might change at any time, all the way to death (deleted), where the version itself is no longer accessible. An overview of the different states is shown in table 24.1, but to see how this works, let’s go through an example scenario of a few versions in a demo API.
Table 24.1 Overview of different version states
When first starting out, an API is certainly not stable enough to show anyone. Most importantly, developers want the freedom to change it at the drop of a hat. In this scenario, it’s simply easiest to put all work into version 1. In this case, we’d label version 1 as “Preview” as it’s not really ready for real users. Any users who are accepting of the fact that there are no stability guarantees for this stage are free to use it, but they should be certain they understand the hard truths here: code they write today will probably be broken tomorrow.
Once version 1 is looking more mature, we might want to allow real users to start building against this API. In this case, we promote version 1 to “Current.” While in this stage, we want to ensure that client code continues working, so the only changes that should be made are mandatory requirements (e.g., security patches) and potentially critical bug fixes. In short, by promoting version 1 to current, we’re freezing it exactly as it is and leaving it alone unless absolutely necessary.
Obviously feature development shouldn’t simply stop, though. So where do we put all the new hard work? The simple answer is that any new features or other noncritical changes that we would’ve liked to make to version 1 would simply be put into the next version: version 2. And it just so happens that version 2 is labeled as the new preview version. As you might expect, the rules for version 2 are the same rules we used to have for version 1 when it was in the preview stage.
At some point this cycle will repeat and version 2 will become more mature to the point that we’ll want it to be promoted to become the new current version. When that happens, we have a new problem: what do we do with the existing current version? We shouldn’t maintain two current versions, but we also don’t want to delete a version entirely just because there’s something newer and shinier available to users. In this strategy, our answer is to mark this version as “Deprecated.” While in the deprecated state, we’ll enforce the same rules about changes as we did when the version was current; however, we start a ticking clock for when the version will ultimately go away—after all, we don’t want to maintain every version that ever existed until the end of time!
Once the clock timer expires, we remove the deprecated version in question entirely and it can be considered deleted. The exact timing of how long it takes for a version to go from deprecated to deleted depends on API users’ expectations; however, the most important thing is to have some specific amount of time declared ahead of time, shared with the users of the API, and stick to the timeline. A summary of this timeline is shown in table 24.2 with a monthly release cadence (and a two-month deprecation policy).
Table 24.2 Example timeline of versions and their states
There are quite a few interesting things about this strategy, with a summary of the different trade-offs shown in figure 24.3. First, note that while there may be lots of different deprecated (and deleted) versions, there is only ever a single current version and a single preview version. This is a critical piece of the strategy in that it acts as a forcing function to move toward continual improvement while keeping the number of active versions to an absolute minimum. In other words, this strategy tends to see new versions as improvements on top of the existing versions rather than alternative views that happen to be equally good. By deprecating versions in order to make way for the latest and greatest new version, we ensure that new functionality doesn’t take too long to get in front of API users.

Figure 24.3 Trade-offs for agile instability versioning strategy
Additionally, notice that this benefit of rapid cycling through versions can also be a drawback: any code written against a current version is virtually guaranteed to stop working eventually. At the very least, there is absolutely no guarantee that it will continue to function, so if it does that might be a pure coincidence. This means that any users who expect to be able to write code and then forget about it for a couple of years will likely find this versioning strategy completely unusable. On the other hand, anyone who is actively updating and changing their code and has a great appreciation for new functionality will find this strategy quite welcoming given their attitude toward software development.
Overall, this strategy can work well when users are active and engaged in development and need small windows of stability followed by quick upgrades to new versions with new functionality. Any users who require longer-term stability in exchange for having less access to new functionality over time will almost certainly find this model very difficult to use. And while it’s possible to coincidentally have code continue to work, the lack of a guarantee can be quite off-putting to anyone who would much rather have a stronger promise that their code will continue to function as intended for more than a fixed, relatively short window of time.
24.3.3 Semantic versioning
Probably the most popular form of versioning out there today, semantic versioning (or SemVer; https://semver.org), is a very powerful tool that allows a single version label to convey quite a lot of meaning in three simple numbers. Most importantly, this meaning is practical: it can tell a user about the differences between two APIs and whether code written against one should continue to work with another. Let’s take a moment to look at how exactly this works.
A semantic version string (illustrated in figure 24.4) is built up of three numbers separated by dots (e.g., 1.0.0 or 12.5.2), where each number increases as changes are made to an API and carries a different meaning about the change that was made to bring about this increase. The first number of the version string, called the major version, is increased in scenarios where the change is considered backward incompatible according to the compatibility policy defined, which we explored in section 24.2.2. For example, changing a field name is almost always considered a backward incompatible change, so if we were to rename a field, the version string would increment the major version (e.g., from 1.0.0 to 2.0.0). In other words, you can assume that any code written for a major version N is almost certainly not going to function as expected for a major version M. If it happens to actually work, it’s entirely coincidental and not at all due to any sort of guarantee by design.

Figure 24.4 The different version numbers in a semantic version string
The next number in a semantic version string is the minor version. This number is incremented when a backward compatible change is made according to the rules defined in the compatibility policy that is some new functionality or change in behavior. For example, if we were to add a new field to the API and we’ve defined this action as being backward compatible in our policy, then we would increment the minor version rather than the major version (e.g., from 1.0.0 to 1.1.0). This is powerful because it allows you to assume that any code written for a specific minor version is guaranteed not to be broken when targeted at future minor versions, as each subsequent minor version is only making backward compatible changes (e.g., code written for version 1.0.0 will not crash when run against both 1.1.0 and 1.2.0). While this older code will not be able to take advantage of the new functionality provided in the newer minor versions, it will still function as expected when run against any of the newer minor versions.
The third and final number in a semantic version string is the patch version. This number is incremented when a change is made that is both backward compatible and primarily a bug fix rather than new functionality being added or behavior being altered. This number should, ideally, convey no obvious implication regarding compatibility. In other words, if the only difference between two versions is the patch version, code written against one should work with the other.
Semantic versioning, when used with web APIs, simply follows these rules as new changes come out. Making a change that would be backward incompatible? That change should be released as the next major version. Adding some backward compatible functionality to the API? Keep the same major version but increment the minor version. Applying a backward compatible bug fix? Keep the same major and minor version and release the patched code with an incremented patch version. As we explored in section 24.2.2, your compatibility policy will guide you to decide which category your change falls into; so as long as you follow it, semantic versioning works quite well.
One major issue with semantic versioning, though, is the sheer number of versions available to the user (and to be managed as separate services). In other words, semantic versioning provides a huge number of versions to choose from, each with a varying set of functionality, to the point where users might end up quite confused.
Additionally, since users will want to be able to pin to a specific, very granular version for as long as possible, this means that the web API must actually maintain and run lots of different versions of the API, which can become an infrastructural headache. Luckily, since versions are almost completely frozen after they are made available to users we can often freeze and continue to run a binary, but the overhead can still be quite daunting. That said, modern infrastructure orchestration and management systems (e.g., Kubernetes; https://kubernetes.io/) and modern development paradigms (e.g., microservices) can help to alleviate much of the pain brought about by this problem, so relying on these tools can help quite a bit.
That said, it’s not necessarily required that versions always live forever. On the contrary, there’s nothing wrong with defining a deprecation policy and stating from the time a version is made available how long it’s expected to be maintained and continue running. Once that clock runs out, the version is removed from service and simply disappears.
This deprecation policy aside, one of the best things about relying on semantic versioning is the balance between stability and new functionality, effectively giving us the best of both worlds. In a sense, users are able to pin to specific versions (all the way down to which bug was fixed) while at the same time having access to new functionality if needed. There is the clear issue that it might be hard to pick and choose specific features (e.g., someone might want to use version 1.0.0 but get access to some special functionality that was added in version 2.4.0), but that’s simply an issue with any chronologically based versioning strategy.
Lastly, this strategy also finds a balance between being satisfactory to everyone and making quite a few people happy (summarized in figure 24.5). In short, because there is so much choice available, and assuming a reasonable deprecation policy, most use cases, ranging from the small startups who want the ability to quickly explore new functionality to large corporate customers who want stability, are able to get what they want out of this versioning scheme. Most importantly, this doesn’t come at the cost of a strategy that frustrates users. It might be a bit overwhelming in the number of version options available, but overall this strategy allows users to get what they want from an API, assuming it’s been built and put into a specific version.

Figure 24.5 Trade-offs for semantic versioning strategy
Keep in mind that these are just a few popular strategies for versioning web APIs and not at all an exhaustive list. As you’ve seen, each has their own benefits and drawbacks, and therefore none is guaranteed to be a perfect fit for all specific scenarios. As a result, it’s important to understand all the different options available and think carefully about which option is likely to be the best choice for your web API given the constraints, requirements, and preferences of your unique set of users.
24.4 Trade-offs
As we can see, defining a policy on what types of changes should be considered backward compatible is complicated. But more importantly, the choices we make on these topics will almost certainly be our way of striking a balance between two different ends of a spectrum. While there is typically never a perfect choice on these topics, the least we can do is understand the trade-offs we’re making and ensure that these choices are made consciously and intentionally. Let’s take a moment to understand the various spectrums we should consider when deciding on the compatibility policy for each unique situation.
24.4.1 Granularity vs. simplicity
The first, very broad, spectrum that many of our choices will lie on is one of choice. In the book The Paradox of Choice (Harper Perennial, 2004), Barry Schwartz discusses how more choice for consumer products doesn’t always lead to happier buyers. Instead, the overwhelming number of choices can actually cause increased levels of anxiety. When designing an API, we’re not really buying a product at a shopping mall; however, the argument may still carry some weight and is worth looking at. When it comes to choosing a versioning policy, this trade-off has to do with striking a balance between lots of granularity and choice versus a simpler, one-size-fits-all single option.
To see how this works, consider the case where we decide that our customers care about stability so much that any change at all should be considered backward incompatible. The result is that each and every change will be deployed as an entirely new version, and users of the API will have the ability to choose from a potentially enormous number of versions for their application. It’s certainly true that this extensive collection of potential versions does ensure that a given user can choose a very specific version and stick to it, but it raises the question of whether that user will be overwhelmed or confused by the sheer number of options available.
Further, it’s also likely that versioning schemes behaving this way will tend to follow a temporal flow, resulting in a steady stream of changes over time. This means that a user isn’t able to pick and choose specific aspects of an API but instead is only given a time machine of sorts where they can pick a specific version representing how the API looked at a specific point in history. If that user wants some behavior from two years ago as well as some feature from today, they’ll typically be forced to accept all changes in behavior between those two points as well. In short, the cost for pinning to a version is that it must include all changes made up until the launch of that specific version.
Now consider the other end of the spectrum: every single change is always considered backward compatible no matter what the effect on existing users of the API happens to be. In this scenario, the resulting API would have only one single version, always and forever, meaning there is no choice at all for the users. While no one could ever argue that this choice doesn’t provide enough of a choice, it probably skews too far toward oversimplification. In other words, one choice is clearly the easiest thing to understand, but it’s rarely a practical choice given the typical audience of an API, particularly those who have specific stability requirements.
Obviously there is no right answer, but the best answer is almost certainly somewhere in between these two ends of the spectrum. This might mean finding a set of policies for what changes are backward compatible such that they result in a reasonable number of versions (the definition of reasonable here will certainly vary), or it might mean finding a deprecation policy where you delete old versions at some point in time. Either way, the trade-off will depend on the users and how big their appetite for choices is (as well as how big yours is for managing all of these different versions).
24.4.2 Stability vs. new functionality
The next trade-off worth discussion is probably the most obvious: how much new functionality do API users really need? In other words, if you simply make fewer changes to your API, then you have fewer chances to even decide whether a change is backward compatible. This trade-off is really more about short-circuiting the compatibility policy entirely at the cost of API users having less access to new features, bug fixes, or behavioral changes.
To put this into perspective, on one end of this spectrum we have perfect stability: never make any changes, ever. This scenario means that once the API is launched and available to users, it will never change ever again. While this might sound easy (after all, how hard can it be to just leave it alone?) it’s actually far more complicated than that. To truly remain perfectly stable, you’d also need to ensure that you never applied any security patches or upgraded the underlying operating system for the servers that are powering your API, and that the same remains true of any of your suppliers. If any of those things change, it’s very easy for something subtle to make its way into the users’ view, resulting in, technically, a change. And that means you’d need to decide whether that merits a new version.
On the other end of the spectrum, you might decide that any and all functionality is critically important to launch. All bugs are critically important to fix. And operating system and library upgrades, security patches, and other underlying changes should be pushed out to API users as quickly as possible. In this scenario, the choices made when defining backward compatibility will be as important as ever.
As usual, there’s no best choice for where you should fall on this spectrum; however, APIs that don’t make the choice of where on the spectrum best suits their users (and instead just make it up on the fly) tend to anger and frustrate users far more. And, as always, the best choice almost certainly lies somewhere in between. For less accommodating users (e.g., a large government organization) the desire of new features might not be as important as stability. And the opposite might be true if the typical user is a startup. But it’s important to identify the expectations of those who will be using the API and decide where on this spectrum best suits those users.
24.4.3 Happiness vs. ubiquity
The final, and possibly most important, trade-off has to do with how your policy is received by the various users of your API. So far we’ve thought of users as one single group that will either be happy or not with your policies on which changes might be considered backward compatible. Unfortunately, this type of homogeneity across all of your users is relatively rare. In other words, it’s very unlikely that your policies will be well received by every single customer for the simple reason that users are different from one another and have different opinions on the topics we’re deciding on. While some APIs may skew toward homogeneous groups of users (e.g., a set of APIs built for central banks or municipal governments may all want stability far more than new functionality), many APIs attract a diverse group of users and we can no longer assume that all users fall into the same bucket. What do we do?
As you might guess, this is yet another trade-off. To understand this, we need to think of API users as falling into one of four groups with different levels of satisfaction with our policies. The spectrum goes from those who would refuse to use the API given the circumstances (cannot use), to those who can use it but are not at all happy with it (mad), to those who are fine with the policy but not thrilled either (okay), and finally those who are completely satisfied with the policy (happy). While typically the majority of users should land in the okay bucket, some policies may alienate a big group of potential users. For example, if an API had a policy of considering all changes backward compatible, that policy might alienate quite a few people and force them to look elsewhere for their API needs (e.g., lots of users in the cannot use bucket). Given this distribution, let’s look at the trade-off we’re considering.
On one end of the spectrum we have maximum happiness for users, where our decision is aimed at maximizing the number of users who are in the happy bucket with our policy on backward compatibility. While we certainly can’t make all users happy, we can always try. However, keep in mind that this means we are choosing a policy without any consideration for the other buckets. This can lead to the situation shown in figure 24.6, where we might maximize the number of happy users, but because we’re not thinking about the other buckets, we end up with quite a lot of users falling into the cannot use bucket.

Figure 24.6 We might maximize the number of happy users at the cost of a lot of users who cannot use the API.
On the other end of the spectrum is the maximum usability across all users, where our decision tries to maximize the number of users who can definitely use the API. Put another way, this end of the spectrum is aimed at minimizing the number of users in the cannot use bucket and thus obviously suffers from a similar problem: it doesn’t consider which bucket the other users are in so long as they’re not in the cannot use bucket. In figure 24.7, we can see a potential distribution of users categorized by these buckets, where we certainly have a minimal number of people in the cannot use bucket. However, it’s pretty obvious that this is unlikely to be a good situation as the overwhelming majority of users, while able to use the API, are not at all happy with it and fall into the mad bucket.

Figure 24.7 We might minimize the number of users who cannot use the API but at the cost of lots of mad users.
As always, the best choice probably lies somewhere in the middle of this spectrum and will obviously depend on the profile of these users. This might try to balance the need for maximizing happiness with minimizing those who simply cannot use the API entirely. Ideally, it might also minimize the mad users and search for a solution that maximizes the number of users in either the okay or happy buckets. This might lead to the user distribution of buckets shown in figure 24.8. One thing we can be certain of is that it’s typically impossible to find a policy that makes all people happy all the time. The next best thing we can do is figure out whether we will aim for a solution that prioritizes ubiquitous access to the API by minimizing those who cannot use it entirely or prioritize the most happiness.

Figure 24.8 A balanced distribution minimizes the number of users who cannot use the API and still maintains a respectable number of users who are happy with the policy.
24.5 Exercises
-
Would it be considered backward compatible to change a default value of a field?
-
Imagine you have an API that caters to financial services with a large commercial bank as an important customer of the API. Many of your smaller customers want more frequent updates and new features while this large bank wants stability above all else. What can you do to balance these needs?
-
Right after launching an API, you notice a silly and embarrassing typo in a field name:
port_numberwas accidentally calledporn_number. You really want to change this quickly. What should you consider before deciding whether to make this change without changing the version number? -
Imagine a scenario where your API, when a required field is missing, accidentally returns an empty response (
200 OKin HTTP) rather than an error response (400 Bad Request), indicating that the required field is missing. Is this bug safe to fix in the same version or should it be addressed in a future version? If a future version, would this be considered a major, a minor, or a patch change according to semantic versioning (semver.org)?
Summary
-
Versioning is a tool that allows API designers to change and evolve their APIs over time while causing as little detriment and providing as many improvements to users as possible.
-
Compatibility refers to the property where code written against one version of an API will continue to function against another version.
-
A new version is considered backward compatible if code written for a previous version continues to function as expected. The question that is left to interpretation is how an API designer defines user expectations.
-
Often things that might seem harmless (e.g., fixing bugs) can lead to backward incompatible changes. The definition of whether a change is backward compatible is dependent on API users.
-
There are several different popular versioning strategies, each with their own benefits and drawbacks. Most come down to trade-offs between granularity, simplicity, stability, new functionality, individual user happiness, and ubiquity of usability.