
- How to use request identifiers to prevent duplicate requests
- How to manage collisions with request identifiers to avoid confusing results
- Balancing caching and consistency of requests and responses
In a world where we cannot guarantee that all requests and responses will complete their journeys as intended, we’ll inevitably need to retry requests as failures occur. This is not an issue for API methods that are idempotent; however, we’ll need a way to safely retry requests without causing duplicated work This pattern presents a mechanism to safely retry requests in the face of failure in a web API, regardless of the idempotence of the method.
26.1 Motivation
Unfortunately, we live in a very uncertain world, and this is especially so in anything involving a remote network. Given the sheer complexity of modern networks and the variety of transmission systems available today, it’s a bit of a miracle that we’re able to reliably transfer messages at all! Sadly, this issue of reliability is just as prevalent in web APIs. Further, as APIs are used more frequently over wireless networks on smaller and smaller devices, sending requests and receiving responses over longer and longer distances means that we actually have to care about reliability more than we would on, say, a small, wired, local network.
The inevitable conclusion of this inherent unreliability of networks is the scenario where a request sent by the client might not always arrive at the server. And even if it does, the response the server sends might not always arrive at the client. When this happens with idempotent methods (e.g., methods that don’t change anything, such as a standard get method), it’s really not a big deal. If we don’t get a response, we can always just try again. But what if the request is not idempotent? To answer this question, we need to look a bit closer at the situation.
In general, when we make a request and don’t get a response, there are two possibilities. In one case (shown in figure 26.1), the request was never received by the API server, so of course we haven’t received a reply. In the other (shown in figure 26.2), the request was received but the response never made it back to the client.

Figure 26.1 A request was sent but never received.

Figure 26.2 A response was sent but never received.
While both of these scenarios are unfortunate, the first one (where a request is never even received by the API server) is a completely recoverable situation. In this case, we can just retry the request. Since it was never received, it’s basically as though the request never happened at all. The second case is far scarier. In this scenario, the request was received, processed by the API server, and the response was sent—it just never arrived.
The biggest problem though is that we can’t tell the difference between these two scenarios. Regardless of whether the problem happened when sending the request or on receiving the response, all the client knows is that there was a response expected and it never showed up. As a result, we have to prepare for the worst: that the request made it but we haven’t been informed about the result. What can we do?
This is the main goal of this pattern: to define a mechanism by which we can prevent duplicate requests, specifically for non-idempotent methods, across an API. In other words, we should be able to safely retry methods (even ones that launch missiles) without knowing whether the request was received, and without worrying about the method being executed twice as a result of retrying.
26.2 Overview
This pattern explores the idea of providing a unique identifier to each request that we want to ensure is serviced once and only once. Using this identifier, we can clearly see whether a current incoming request was already handled by the API service, and if so, can avoid acting on it again.
This leads to a tricky question: what should we return as the result when a duplicate request is caught? While returning an error stating that this request was already handled is certainly sufficient, it’s not all that useful in practical terms. For example, if we send a request to create a new resource and never get a response, when we make another request we’re hoping to get something useful back, specifically the unique ID of the resource that was created. An error does prevent duplication, but it’s not quite what we’re looking for in a result.
To handle this, we can cache the response message that went along with the request ID provided that when a duplicate is found, we can return the response as it would have been returned when the request was first made. An example of this flow using request IDs is shown in figure 26.3.

Figure 26.3 Overview of the sequence of events for deduplicating requests
Now that we have an idea of how this simple pattern works at a high level, let’s get into the implementation details.
26.3 Implementation
The first thing needed to make this pattern work is a definition of a request identifier field so that we can use it when determining whether a request has been received and processed by the API. This field would be present on any request interfaces clients send for any methods that require deduplication (in this case, that’s generally just the methods that are not idempotent). Let’s begin by looking more closely at this field and the values that will end up stored in it.
26.3.1 Request identifier
A request identifier is nothing more than a standard ID field; however, rather than living on a resource interface, this field lives on certain request interfaces (see listing 26.1). Just as an ID field on a resource uniquely identifies the resource across the entire API, a request identifier aims to accomplish the same goal. The catch here is that while resource identifiers are almost always permanent (chapter 6), request identifiers are a bit more like single-use values. And because they’re something a client uses to identify their outgoing requests, it’s absolutely critical that they be chosen by the client itself.
Listing 26.1 Definition of a request with an identifier field
interface CreateChatRoomRequest { requestId?: string; ❶ resource: ChatRoom; }
❶ Defining the request identifier as an optional string field on the request interface
Unfortunately, as we learned in chapter 6, it’s usually a bad idea to allow clients to choose identifiers, as they tend to choose poorly. Since it’s a necessity, though, the best we can do is specify a format, recommend that the identifier be chosen randomly, and enforce the indicated format (e.g., we really wouldn’t want someone sending a request with its ID set to 1 or “abcd”). Instead, request identifiers should follow the same standards for resource identifiers (discussed in chapter 6).
Even though request identifiers are not as permanent as those for resources, this doesn’t make them any less important. As a result, if the API server receives an incoming request with an invalid request ID, it should reject the request and throw an error (e.g., a 400 Bad Request HTTP error). Note that this is different from leaving a request identifier blank or missing. In that case, we should proceed as though the request is never going to be retried, bypassing all the caching discussed in section 26.2, and behaving as any other API method would.
One question that often comes up is, “Why not just derive an identifier from the request itself?” At first glance this seems like quite an elegant solution: perform some sort of hash on the request body and then ensure that whenever we see it again we know it shouldn’t be processed again.
The issue with this method is that we cannot guarantee that we won’t actually need to execute the same request twice. And instead of an explicit declaration from the client (“I definitely want to ensure this request is only processed once”), we’re implicitly determining the intended behavior without providing a clear way to opt out of this deduplication. Obviously the user could provide some extra headers or meaningless query string parameters to make the request look different, but this has the defaults swapped around.
By default, requests should not be deduplicated, as we cannot know for sure the user’s intent. And a safe way to allow a user to clearly express the intent of their request is to accept a user-chosen identifier, not deriving one implicitly from the request content.
Finally, given what we’ll learn in section 26.3.5, this ultimately will not be a true case of never duplicating work. Since cache values almost certainly expire at some point, this would act more as a rate limit mechanism, ensuring the same request wouldn’t be executed twice within some time period.
While we’re on the topic of how caching works, let’s briefly discuss what will be cached and the rationale behind these choices.
26.3.2 Response caching
In figure 26.4, we can see that every request that has a request identifier will have the result stored in a cache somewhere. The process begins by checking the cache for the provided request ID, and if a value is present we return the result that was cached the first time around when the request was actually processed by the server. If the request ID isn’t found in the cache, we process the request and then update the cache with the result value before sending the response back to the user as requested.

Figure 26.4 Sequence of caching responses for nonduplicate requests
One thing that might seem worrisome with this pattern is the fact that the entire response value is being stored in the cache. In this case, the storage requirements can grow out of control pretty quickly; after all, we’re technically caching the results of every non-idempotent API call. And what if these responses are quite large themselves? For example, imagine a batch create method with 100 resources provided. If we receive that request and are using this pattern for request deduplication, we’ll need to cache quite a bit of data, and that’s only a single request.
The bottom line, for all the clever engineers out there, is that even though we could design a more complicated system that avoids caching all this data and instead tries to recalculate the response without processing the request again, it’s still not a good idea. At the end of the day, an engineer’s hourly rate for debugging and managing a complex system far outweighs the costs for more RAM or a larger caching cluster in the cloud. As a result, caching the responses is just the safe bet in the long term, as you can always throw more hardware at a problem pretty quickly, but it’s not nearly as easy to throw more brain power.
26.3.3 Consistency
Hidden in this requirement to cache the responses from requests that have been processed is a key question of consistency. In other words, cached values can very easily become stale or out of date as the data is updated over time and these updates are not reflected in the cached value. The question, then, is whether this is important when it comes to request deduplication.
To illustrate the problem more clearly, let’s imagine that two clients (A and B) are both performing updates on a resource, shown in figure 26.5. And in this case, let’s assume that there are no conflicts to worry about. Instead, let’s worry about the fact that client A has a poor connection and may need to retry requests every so often.

Figure 26.5 It’s possible to see stale data when retrying requests.
In this example, while A and B are both updating a resource and having no conflicts in those updates, the response from A’s update is lost in transit and never received. As a result, A simply decides to retry the request using the same request identifier as before to ensure that the modifications are repeated twice. On this second attempt, the server responds with the cached value of the resource, showing A the title that was originally set in the request. There’s one problem though: that’s really not how the data looks right now!
In general, stale or inconsistent data like this can be an enormous problem, but it’s critical to recall the purpose of this pattern. The primary goal is to allow clients to retry requests without causing potentially dangerous duplication of work. And a critical part of that goal is to ensure that the client receives the same result in response that they would have if everything worked correctly the first time. As a result, while this sequence of events (figure 26.5) might look a bit strange, it’s completely reasonable and correct. As a matter of fact, it’d probably be more confusing and unpredictable to return anything else besides this result. In other words, the cache should absolutely not be kept up-to-date as the underlying data changes, as it would lead to even more confusion than the stale data we see in this case.
26.3.4 Request ID collisions
An inevitable consequence of allowing users to choose their own identifiers for requests is that they are generally bad at it. And one of the most common results of poorly chosen request identifiers is collisions: where a request ID is not really all that random and ends up being used more than once. In our design, this can lead to some tricky situations.
For example, let’s imagine two users (A and B) interacting with our API, with perfectly good connections, but they are both terrible at choosing request IDs. As we can see in figure 26.6, they end up each choosing the same request ID, with disastrous (and very strange) consequences.
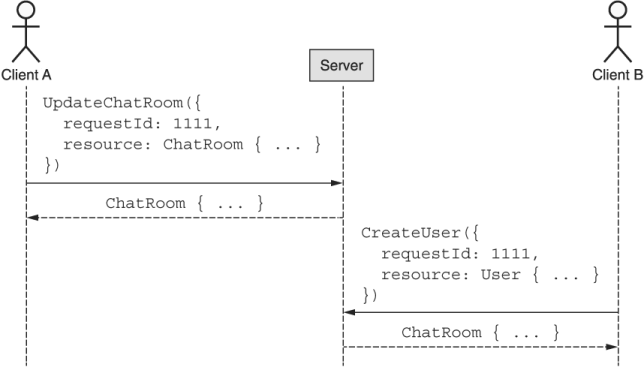
Figure 26.6 Confusing results happen due to request identifier collisions.
Somehow it seems that client B attempted to create a User resource and instead got back a ChatRoom resource. The cause of this is pretty simple: since there was a collision on the request ID, the API server noticed it and returned the previously cached response. In this case, it turns out that the response is completely nonsensical, having nothing to do with what client B is trying to do. This is clearly a bad scenario, so what can we do?
The correct thing to do is ensure that the request itself hasn’t changed since the last time we saw that same identifier. In other words, client B’s request should have the same request body as well—otherwise, we should throw an error and let client B know they’ve clearly made a mistake. To make this work, we’ll need to address two things, both shown in listing 26.2.
First, when we cache the response value after executing a request that doesn’t yet have a cache value, we need to also store a unique fingerprint of the request body itself (e.g., a SHA-256 hash of the request). Second, when we look up a request and find a match, we need to verify that the request body on this (potential) duplicate matches the previous one. If they match, then we can safely return the cached response. If they don’t, we need to return an error, ideally something along the lines of a 409 Conflict HTTP error.
Listing 26.2 Example method to update a resource with request identifiers
function UpdateChatRoom(req: UpdateChatRoomRequest): ChatRoom { if (req.requestId === undefined) { ❶ return ChatRoom.update(...); } const hash = crypto.createHash('sha256') .update(JSON.stringify(req)) .digest('hex'); const cachedResult = cache.get(req.requestId); if (!cachedResult) { ❷ const response = ChatRoom.update(...); cache.set(req.requestId, { response, hash }); ❸ return response; } if (hash == cachedResult.hash) { ❹ return cachedResult.response; } else { throw new Error('409 Conflict'); ❺ } }
❶ If there’s no request ID provided, simply perform the update and return the result.
❷ If there's no cached value for the given request ID, actually update the resource.
❸ Update the cache with the response and the hash value.
❹ If the hash matches, we can safely return the response.
❺ If the hash doesn’t match, throw an error.
By using this simple algorithm, whenever we see a request ID that has already been serviced, we can double-check that it really is a duplicate of the same request and not a collision. This allows us to safely return the response in the face of the unfortunately common scenario where users do a poor job of choosing truly unique request identifiers.
26.3.5 Cache expiration
Now that we’ve covered most of the complicated bits of this pattern, we can move onto one final topic: how long to keep data around in the cache. Obviously, in a perfect world, we could keep all data around forever and ensure that any time a user had to retry a request, even if it was several years after the request was made, we could return the cached result exactly as we would have when we first responded. Unfortunately, data costs money to store, and is therefore a limited commodity in our API. Ultimately, this means we have to decide on how long we want to keep things in the request cache.
In general, requests are retried relatively soon after a failure occurs, typically a few seconds after the original request. As a result, a good starting point for a cache expiration policy is to hang onto data for around five minutes but restart that timer every time the cached value is accessed, because if we have a cache hit it means that the request was retried. If there is further failure, we want to give subsequent retries the same expiration policy as first attempts.
To make this decision easier, there’s some good news. Since caching, by its very nature, results in data expiring after some amount of time, whatever we decide can always be fine-tuned later based on how much capacity there is compared to how much traffic there is. In other words, while five minutes is a good starting point, this decision is extraordinarily easy to reevaluate and adjust based on user behavior, memory capacity available, and cost.
26.3.6 Final API definition
The final API definition is quite simple for this pattern: just adding a single field. To clarify the details of the pattern once more, a full example sequence is shown in figure 26.7.
Listing 26.3 Final API definition
abstract class ChatRoomApi { @post("/chatRooms") CreateChatRoom(req: CreateChatRoomRequest): ChatRoom; } interface CreateChatRoomRequest { resource: ChatRoom; requestId?:string }
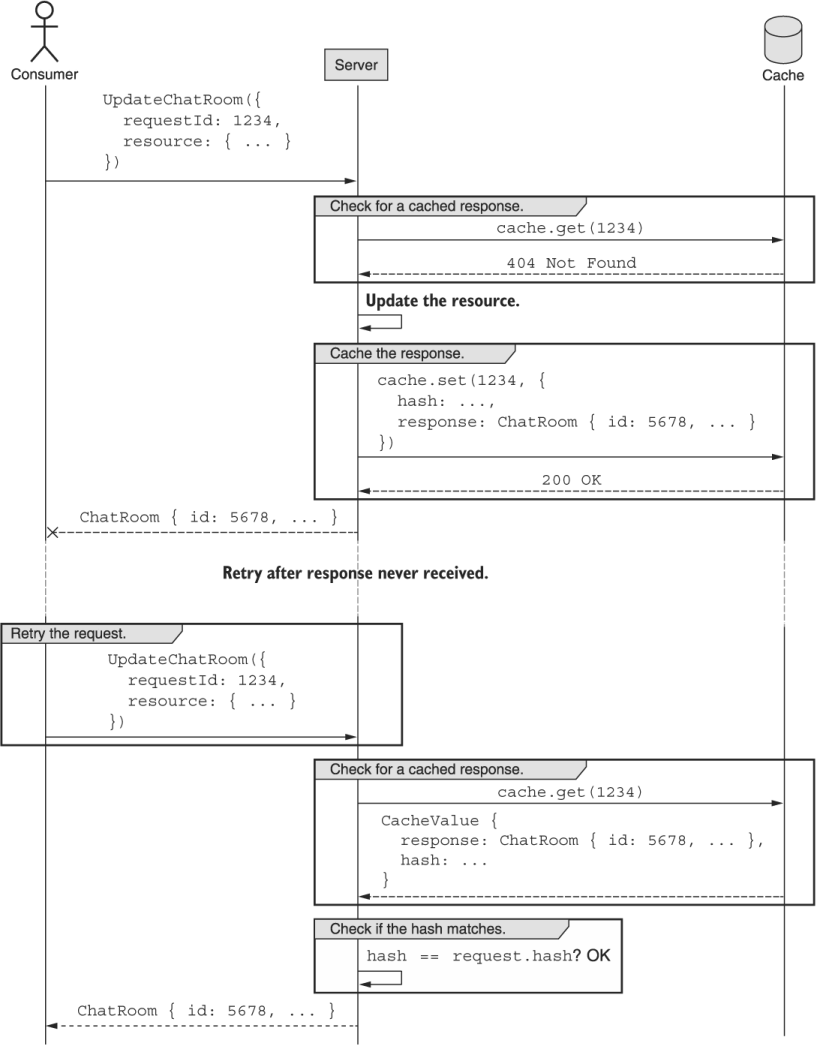
Figure 26.7 Sequence of events for request deduplication
26.4 Trade-offs
In this pattern, we use a simple unique identifier to avoid duplicating work in our APIs. This is ultimately a trade-off between permitting safe retries of non-idempotent requests and API method complexity (and some additional memory requirements for our caching requirements). While some APIs might not be all that concerned about duplicate request scenarios, in other cases it can be critical—so critical, in fact, that request identifiers might be required instead of optional.
At the end of the day, the decision of whether to complicate certain methods with this mechanism for request deduplication really does depend on the scenario. As a result, it likely makes sense to add it on an as-needed basis, starting with some particularly sensitive API methods and expanding over time to others.
26.5 Exercises
-
Why is it a bad idea to use a fingerprint (e.g., a hash) of a request to determine whether it’s a duplicate?
-
Why would it be a bad idea to attempt to keep the request-response cache up-to-date? Should cached responses be invalidated or updated as the underlying resources change over time?
-
What would happen if the caching system responsible for checking duplicates were to go down? What is the failure scenario? How should this be protected against?
-
Why is it important to use a fingerprint of the request if you already have a request ID? What attribute of request ID generation leads to this requirement?
Summary
-
Requests might fail at any time, and therefore unless we have a confirmed response from the API, there’s no way to be sure whether the request was processed.
-
Request identifiers are generated by the API client and act as a way to deduplicate individual requests seen by the API service.
-
For most requests, it’s possible to cache the response given a request identifier, though the expiration and invalidation parameters must be thoughtfully chosen.
-
API services should also check a fingerprint of the content of the request along with the request ID in order to avoid unusual behavior in the case of request ID collisions.