
Chapter 6. Access Structured Query Language (SQL)
Introduction to Access SQL
As we have said, Microsoft Access uses a form of query language referred to as Structured Query Language, or SQL. (I prefer to pronounce SQL by saying each letter separately, rather than saying “sequel.” Accordingly, I will write “an SQL statement” rather than “a SQL statement.”)
SQL is the most common database query language in use today. It is actually more than just a query language, as I have defined the term in the previous chapter. It is a complete database management system (DBMS) language, in that it has the capability not only to manipulate the components of a database, but also to create them in the first place. In particular, SQL has the following components:
A data definition language (DDL)component, to allow the definition (creation) of database components, such as tables.
A data manipulation language (DML) component, to allow manipulation of database components.
A data control language (DCL) component, to provide internal security for a database.
We will discuss the first two components of SQL in some detail in this chapter.
SQL (also known as SEQUEL) was developed by IBM in San Jose, California. The current version of SQL is called SQL-92. However, Microsoft Access, like all other commercial products that support SQL, does not implement the complete SQL-92 standard and in fact adds some additional features of its own to the language. Since this book uses Microsoft Access, we will discuss the Access version of SQL.
Access Query Design
In Microsoft Access, queries can be defined in several different ways, but they all come down to an SQL statement in the end. The Query Wizard helps create a query by asking the user to respond to a series of questions. This approach is the most user friendly, but also the least powerful. Access also provides a Query Design window with two different views. The Design View is shown in Figure 6-1.

Query Design View displays table schemes, along with their relationships, and allows the user to select columns to return (projection) and specify criteria for the returned data (selection). Figure 6-1 shows a query definition that joins the BOOKS and PUBLISHERS table and returns the Title, Publisher, and Price of all books whose price is over $25.00.
The Query Design window also has an SQL View. Switching to this view shows the SQL statement that corresponds to the Design View query. Figure 6-2 shows the corresponding SQL statement for the query in Figure 6-1.

In addition to using the Design View, users can enter SQL statements directly into the SQL View window. In fact, some constructions, such as directly creating the union of two tables in a third table, cannot be accomplished using Design View and therefore must be entered in SQL View. However, such constructs are rare, and it is often possible to complete a project without the need to enter SQL statements directly.
Access Query Types
Access supports a variety of query types. Here is a list, along with a brief description of each:
- Select query
These queries return data from one or more tables and display the results in a result table. The table is (usually) updatable, which means that we can change the data in the table, and the changes will be reflected in the underlying tables. Select queries can also be used to group rows and calculate sums, counts, averages, and other types of totals for these groups.
- Action queries
These are queries that take some form of action. The action queries are:
- Make-table query
A query that is designed to create a new table with data from existing tables.
- Delete query
A query that is used to delete rows from a given table or tables.
- Append query
A query that is used to append additional rows to the bottom of an existing table.
- Update query
A query that is used to make changes to one or more rows in a table.
- SQL queries
These are queries that must be entered in SQL View. The SQL queries are:
- Crosstab query
This is a special type of select query that displays values in a spreadsheet format, with both row and column headings. For instance, we might wish to know how many books are published by each publisher at each price. This is most conveniently pictured as a crosstab query, as shown in Table 6-1.
- Parameter query
For select or crosstab queries, we may choose to let the user supply certain data at runtime by filling in a dialog box. This can be done in both Design View and SQL View. When the query asks for information from the user, it is referred to as a parameterized query, or parameter query.
Price | Total | Big House | Medium House | Small House |
$12.00 | 1 | 1 | ||
$13.00 | 3 | 2 | 1 | |
$15.00 | 1 | 1 | ||
$18.00 | 1 | 1 | ||
$20.00 | 6 | 1 | 5 | |
$25.00 | 2 | 2 | ||
$34.00 | 5 | 1 | 4 | |
$44.00 | 1 | 1 | ||
$49.00 | 6 | 1 | 4 | 1 |
$99.00 | 1 | 1 |
Finally, I mention that Access allows a select or action query to contain another select query. This is done by nesting SQL SELECT statements, as we will see. The internal query is called a subquery of the external query. Access allows multiple levels of subqueries.
Why Use SQL?
As you look through the syntax of the SQL statements in this chapter, you may be struck by the fact that SQL is not a particularly pleasant language. Moreover, as I have said, many features of SQL can be accessed through the Access Query Design Window. So why program in SQL at all?
Here are some reasons:
There are some important features of SQL that cannot be reached through the Query Design Window. For instance, there is no way to create a union query, a subquery, or an SQL pass-through query (which is a query that passes through Access to an external database server, such as Microsoft SQL Server) using the Query Design Window.
You cannot use the DDL component of SQL from within the Query Design Window. To use this component, you must write SQL statements directly.
SQL can be used from within other applications, such as Microsoft Excel, Word, and Visual Basic, to run the Access SQL engine.
SQL is an industry-standard language for querying databases, and as such it is useful outside of the Microsoft Access environment.
Despite these important reasons, we suggest that, on first reading, you go lightly over the SQL commands to get a flavor for how they work. Then you can use this chapter as a reference whenever you actually need to write SQL statements yourself. Fortunately, SQL has relatively few actual commands, which makes it easy to get an overall picture of the language. (For instance, SQL is single-statement oriented. It does not have control structures such as For...Next... loops, nor conditional statements such as If...Then... statements.)
We should also mention that using the Query Design Window itself is a good way to learn SQL, for you can create a query in the Design Window and then switch to SQL View to see the corresponding SQL statement, obligingly created by Microsoft Access.
Access SQL
SQL is a nonprocedural language, meaning, as we have seen, that expressions in SQL state what needs to be done, but not how it should be done. This frees the programmer to concentrate on the logic of the SQL program. The Access Query Engine takes care of optimization.
One way to experiment with SQL is to enter a query using Design View and then switch to SQL View to see how Access resolves the query into SQL. It is also worth mentioning that the Help system has complete details on the syntax and options of each SQL statement.
Incidentally, reading the definition of SQL statements can be tiresome. You may wish to just skim over the syntax of each statement and go directly to the examples. The main goal here is to get a reasonable feel for SQL statements and what they can do. You can then look up the correct syntax for the relevant statement when needed (as I do).
Syntax Conventions
In looking at the SQL commands, we need to establish a consistent syntax. I will employ the following conventions:
Uppercase words are SQL keywords and should be typed in as written.
Words in constant width italic are intended to be replaced with something else. For instance, in the statement:
CREATE TABLE
TableNamewe must replace
TableNamewith the name of a table.An item in square brackets [ ] is optional.
Braces ({}) are used to (hopefully) clarify the syntax. They are never to be included in the statement proper.
Parentheses should be typed as shown.
The symbol ::= means “defined as” and the symbol | means “or.” For instance, the line:
TableElement ::= ColumnDefinition | TableConstraint
means that a table element is defined as either a column definition or a table constraint.
The syntax
item,...means that you can repeatitemas often as desired, separated by commas. For instance, in the line:CREATE TABLE TableName (TableElement, ...)
you may repeat the
TableElementas many times as desired but at least once, since it is not enclosed in square brackets, so it is not optional. (The parentheses must be included.) If a group of items may be repeated, then we use curly braces to enclose those items (for easier reading). For instance, the following expression means that you may repeat the clauseColName[ASC|DESC]:{ColName[ASC|DESC]}, ...
Notes
You may break the lines in an SQL statement at any point, which is useful for improving readability.
Each SQL statement should end with a semicolon (although Access SQL does not require this).
If a table name (or other name) contains a character that SQL regards as illegal, then the name must be enclosed in square brackets. For instance, the forward slash character is illegal in SQL and so the table name BOOK/AUTHOR is also illegal. Thus, it must be enclosed in square brackets: [BOOK/AUTHOR]. This should not be confused with the use of square brackets to denote optional items in SQL syntax descriptions.
The DDL Component of Access SQL
We begin by looking at the data definition commands in Access SQL. These commands do not have a counterpart in Query Design View (although, of course, you can perform these functions through the Access graphical environment). Access SQL supports these four DDL commands:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
I should mention now that there is some duplication of features in the DDL commands. For instance, you can add an index to a table using either the ALTER TABLE command or the CREATE INDEX command.
The CREATE TABLE Statement
The CREATE TABLE command has the following syntax:
CREATE TABLETableName(ColumnDefinition,... [,Multi-ColumnConstraint,...] );
In words, the parameters to the CREATE TABLE statement are a table name, followed by one or more column definitions, followed by one or more (optional) multicolumn constraints. Note that the parentheses are also part of the syntax.
Column definition
A column definition is defined as follows:
ColumnDefinition ::=ColumnNameDataType[(Size)] [Single-ColumnConstraint]
In words, a ColumnDefinition is a
ColumnName, followed by a
DataType (with size if appropriate),
followed by a
Single-ColumnConstraint.
There are several data types available in Access SQL. For comparison, the list in Table 6-2 includes the corresponding selection in the Access Table Design window. (We have not included all synonyms for the data types.) Note that the SQL type INTEGER corresponds with the Access data type Long. Note also that the Size option affects only TEXT columns, indicating the length of the field. (If it is omitted, the text length defaults to 255.)
SQL data type | Table Design field type |
BOOLEAN, LOGICAL, or YES/NO | Yes/No |
BYTE or INTEGER1 | Number, Field Size = Byte |
COUNTER or AUTOINCREMENT | AutoNumber, Field Size = Long Integer |
CURRENCY or MONEY | Currency |
DATETIME, DATE, or TIME | Date/Time |
SHORT, INTEGER2, or SMALLINT | Number, Field Size = Integer |
LONG, INT, INTEGER, or INTEGER4 | Number, Field Size = Long |
SINGLE, FLOAT4, or REAL | Number, Field Size = Single |
DOUBLE, FLOAT, FLOAT8, NUMBER, or NUMERIC | Number, Field Size = Double |
TEXT, ALPHANUMERIC, CHAR, CHARACTER, or STRING | Text |
LONGTEXT, LONGCHAR, MEMO, or NOTE | Memo |
LONGBINARY, GENERAL, or OLEOBJECT | (OLE) Object |
GUID | AutoNumber, Field Size = Replication ID |
Constraints
Constraint clauses can be used to:
Designate a primary key
Designate a foreign key, thus establishing a relationship between two tables
Force a column to contain only unique values
(In SQL-92, these clauses have two other uses: to disallow NULLs and to restrict allowable values to a specified range.)
There are two types of constraint clauses in a CREATE TABLE command. The single-column constraint is used (as indicated in the syntax) within a column definition. Its syntax is:
Single-ColumnConstraint ::= CONSTRAINTIndexName[PRIMARY KEY | UNIQUE | REFERENCESReferencedTable[(ReferencedColumn,...)] ]
The first option designates the column as a primary key and
creates an index file of the name
IndexName on that column. The second
option designates the column as a (candidate) key and creates a
unique index file on that key, by the name
IndexName. The third option designates
the column as a foreign key that references the
ReferencedColumn ,... column(s) of the
ReferencedTable. The
ReferencedColumn ,... clause is optional if the
referenced table has a primary key, since that key will be the
referenced key.
For multicolumn constraints, the CONSTRAINT clause must appear after all
column definitions and has the syntax:
Multi-ColumnConstraint ::= CONSTRAINTIndexName[PRIMARY KEY (ColumnName,...) | UNIQUE (ColumnName,...) | FOREIGN KEY (ReferencingColumn,...) REFERENCES ReferencedTable [(ReferencedColumn,...)] ]
Here are some examples.
Create the Publishers table scheme:
CREATE TABLE PUBLISHERS (PubID TEXT(10) CONSTRAINT PrimaryKeyName PRIMARY KEY, PubName TEXT(100), PubPhone TEXT(20));
Create the Books table scheme, and link to Publishers using PubID as foreign key:
CREATE TABLE BOOKS
(ISBN TEXT(13) CONSTRAINT PrimaryKeyName PRIMARY KEY,
TITLE TEXT(100),
PRICE MONEY,
PubID TEXT(10) CONSTRAINT Test FOREIGN KEY (PubID) REFERENCES
Publishers
(PubID) );Notes
The CREATE TABLE statement does not provide a way to create an index with nonunique values. This can be done using the CREATE INDEX statement, however.
In specifying a foreign key, the CREATE TABLE statement does enable referential integrity rules, but does not allow the option of enabling cascading updates or deletes. (This is one place where Access SQL is weaker than SQL-92, which has a FOREIGN KEY clause that allows the programmer to specify ON UPDATE CASCADE and/or ON DELETE CASCADE.)
The ALTER TABLE Statement
The ALTER TABLE command is used to:
Add a new column to a table
Delete a column from a table
Add or delete single- or multiple-column index
The syntax for the ALTER TABLE command is:
ALTER TABLETableNameADD COLUMNColName ColType[(size)] [Single-ColumnConstraint] | DROP COLUMNColName| ADD CONSTRAINTMulti-ColumnConstraint| DROP CONSTRAINTMultiColumnIndexName;
As you can see, the Single- and Multi-Column Constraint clauses (as defined earlier) can be used here to add or delete (DROP) an index.
Notes
New columns are added at the beginning of the table, immediately following any primary key columns.
You cannot delete a column that is part of an index. The index must first be removed using a DROP CONSTRAINT statement (or DROP INDEX).
The CREATE INDEX Statement
The CREATE INDEX command has the following syntax:
CREATE [ UNIQUE ] INDEXIndexNameONTableName({ColName[ASC|DESC]},...]) [WITH {PRIMARY | DISALLOW NULL | IGNORE NULL}]
where ASC stands for ascending and DESC for descending. Note that:
The UNIQUE keyword prevents duplicate values in the index.
WITH PRIMARY designates the primary key and creates a primary index file. In this case, the UNIQUE keyword is redundant.
WITH DISALLOW NULL disallows NULL values in the key.
WITH IGNORE NULL allows NULL values in the key, but does not include them in the index file. (Hence, they will be skipped in any searches that use the index.)
Note
The CREATE INDEX command is specific to Access SQL and is not part of the SQL-92 standard.
The DML Component of Access SQL
We now turn to the DML component of SQL. The commands we will consider are:
SELECT
UNION
UPDATE
DELETE
INSERT INTO
SELECT INTO
TRANSFORM
PARAMETER
Before getting to these statements, however, we must discuss a few relevant points.
Updatable Queries
In many situations, a query is updatable , meaning that we may edit the values in the result table, and the changes are automatically reflected in the underlying tables. The details of when this is permitted are fairly involved, but they are completely detailed in the Access Help facility. (This information is not easy to find, however. You can locate it by entering “updatable query” in the Access Answer Wizard and choosing Determine when I can update data from a query.)
Joins
Let’s begin with a brief discussion of how Access SQL denotes joins. Note that a join clause is not an SQL statement by itself, but must be placed within an SQL statement.
Inner joins
The INNER JOIN clause in Access SQL actually denotes a θ-join on one or more columns. (See the discussion of joins in Chapter 5.) In particular, the syntax is:
Table1
INNER JOIN Table2 ON
Table1.Column1
θ
1 Table2.Column1
[{AND|OR ON Table1.Column2 θ 2
Table2.Column2},...]
where each θ is one of =, <, >, <=, >=, <> (not equal to).
Outer joins
The syntax for an outer join clause is:
Table1
{LEFT [OUTER]} | {RIGHT [OUTER]} JOIN
Table2 ON
Table1.Column1 θ 1
Table2.Column1 [{AND|OR ON
Table1.Column2 θ 2
Table2.Column2},...]
where θ is one of =, <, >, <=, >=, or < >. Note that the word OUTER is optional.
Nested joins
JOIN statements can be nested. Here is an example that joins the BOOKS, AUTHORS, PUBLISHERS, and BOOK/AUTHOR tables and then selects the Title, AuName, and PubName columns. I have indented some lines in the hope of increasing readability. (I will describe the SELECT statement soon.)
SELECT Title, AuName, PubName FROM AUTHORS INNER JOIN (PUBLISHERS INNER JOIN (BOOKS INNER JOIN [BOOK/AUTHOR] ON BOOKS.ISBN=[BOOK/AUTHOR].ISBN) ON PUBLISHERS.PubID = BOOKS.PubID) ON AUTHORS.AuID = [BOOK/AUTHOR].AuID;
To see how this was constructed, it helps to look at the relationships between the tables involved. Figure 6-3 shows a portion of the relationships window in Access.
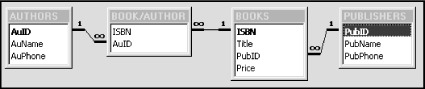
One way to create the previous join statement is to work from the inside out. We first join BOOKS and BOOK/AUTHOR by the statement:
(BOOKS INNER JOIN [BOOK/AUTHOR]
ON BOOKS.ISBN=[BOOK/AUTHOR].ISBN)We then join this to PUBLISHERS on the PubID column:
(PUBLISHERS INNER JOIN (BOOKS INNER JOIN [BOOK/AUTHOR] ON BOOKS.ISBN=[BOOK/AUTHOR].ISBN) ON PUBLISHERS.PubID = BOOKS.PubID)
and finally we join this to AUTHORS on the AuID column.
Self-joins
A table can be joined to itself, resulting in a self-join. In order to do this, SQL requires the use of the AS AliasName syntax. For instance, we can write:
BOOKS INNER JOIN BOOKS AS BOOKS2 ON ...
The least confusing way to think of this statement is as though Access creates a second copy of the BOOKS table and calls it BOOKS2. We can now refer to the columns of BOOKS as BOOKS.ColumnName or BOOKS2.ColumnName.
Notes
An outer join may be nested inside an inner join, but an inner join may not be nested inside an outer join.
We may use Access expressions, which involve functions (such as Left$, Len, Trim$, and Instr) in SQL statements (even though the “official” syntax does not describe this).
In Access, we can define relationships between tables. However, these relationships have no effect on SQL statements. Thus, an INNER JOIN statement does not require that a relationship already exist between the participating tables. Relationships are used in Design View, however, and translate into INNER JOIN statements. For example, if we add BOOKS and PUBLISHERS to the Query Design View window, move Title and PubName to the Design grid, and then view the SQL equivalent, we will see an INNER JOIN clause in the SQL statement.
The SELECT Statement
The SELECT statement is the workhorse of SQL commands (as you can tell by the length of our discussion on this statement). The statement returns a table and can perform both of the relational algebra operations selection and projection. The syntax of the SELECT statement is:
SELECT [predicate] ReturnColumnDescription,... FROM TableExpression [WHERE RowCondition] [GROUP BY GroupByCriteria] [HAVING GroupCriteria] [ORDER BY OrderByCriteria]
Let us describe the various components of this statement. We note immediately that the keyword SELECT is in some ways unfortunate, since it denotes the relational algebra operation of projection, not selection. It is the WHERE clause that performs selection.
Predicate
The predicate is used to describe how to handle duplicate return rows. It can have one of the following values: ALL, DISTINCT, DISTINCTROW, or TOP.
The default option ALL returns all qualifying rows, including duplicates. If there is more than one qualifying row with the same values in all of the columns that arerequested in the ReturnColumnDescription, then the option DISTINCT returns only the first such row. The:
TOPnumberor:
TOPpercent PERCENToption returns the top number (or
percent) of rows in the sort order determined by the ORDER BY clause.
The DISTINCTROW option can be a bit confusing, so let us see if we can straighten it out. The Access Help system says that the DISTINCTROW option “Omits data based on entire duplicate records, not just duplicate fields.” It doesn’t say how this is done. Microsoft Technet is a bit less vague:
In contrast, DISTINCTROW is unique to Microsoft Access. It causes a query to return unique records, not unique values. For example, if 10 customers are named Jones, a query based on the SQL statement “SELECT DISTINCTROW Name FROM Customers” returns all 10 records with Jones in the Name field. The major reason for adding the DISTINCTROW reserved word to Microsoft Access SQL is to support updatable semi-joins, such as one-to-many joins in which the output fields all come from the table on the “one” side. DISTINCTROW is specified by default in Microsoft Access queries and is ignored in queries in which it has no effect. You should not delete the DISTINCTROW reserved word from the SQL dialog box.
The intended purpose of DISTINCTROW is simple. DISTINCTROW applies only when the FROM clause involves more than one table. Consider this statement:
SELECT ALL PubName FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID;
Since there are many books published by the same publisher, the result table tblALL shown in Table 6-3 has many duplicate publisher names.
PubName |
Small House |
Small House |
Small House |
Small House |
Big House |
Big House |
Big House |
Big House |
Big House |
Big House |
Alpha Press |
Alpha Press |
Alpha Press |
Alpha Press |
To remove duplicate publisher names, we can include the DISTINCT keyword. Thus, the statement
SELECT DISTINCT PubName FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID;
produces the table tblDISTINCT that is shown in Table 6-4.
Now consider what happens if the PUBLISHERS table is changed by adding a new publisher with the same name as an existing publisher (but a different PubID and phone), as we have done in Table 6-5. The previous DISTINCT statement will give the same result table as before, thus leaving out the new publisher.
PubID | PubName | PubPhone |
1 | Big House | 123-456-7890 |
2 | Alpha Press | 999-999-9999 |
3 | Small House | 714-000-0000 |
4 | Small House | 555-123-1111 |
What is called for is a selection criterion that will return both publisher names simply because they come from different rows of the PUBLISHERS table. This is the purpose of DISTINCTROW. Thus, the statement:
SELECT DISTINCTROW PubName FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID;
produces the result table tblDISTINCTROW shown in Table 6-6 (note that we also had to add a book to the BOOKS table, with PubID 4).
We can now describe how DISTINCTROW works. Consider the following SQL skeleton:
SELECT DISTINCTROWColumnsRequestedFROMTablesClause
Here ColumnsRequested is a list
of columns requested by the statement, and
TablesClause is a join of tables. Let
us refer to a table mentioned in
TablesClause as a return
table if at least one of its columns is mentioned in
ColumnsRequested .
Thus, in the statement:
SELECT DISTINCTROW PubName FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID;
PUBLISHERS is a return table, but BOOKS is not. Here is how DISTINCTROW works:
Form the join(s) described in TablesClause.
Project the resulting table onto all of the columns from all return tables (not just the columns requested). Put another way, remove all columns that are not part of a return table.
Remove all duplicate rows, where two rows are considered duplicates if they are composed of the same rows from each result table. It is not the values that are compared, but the actual rows. It is necessary to add this because two different rows may have identical values in an Access table.
Let us illustrate with a simple example.
Consider the following tables, named Temp1, Temp2, and Temp3, respectively:
The statement:
SELECT * FROM (Temp1 INNER JOIN Temp2 ON Temp1.A2 = Temp2.B2) INNER JOIN Temp3 ON Temp2.B3 = Temp3.C3;
gives the result table tblALL:
A1 | A2 | B1 | B2 | B3 | C1 | C2 | C3 |
a3 | link | b2 | link | link2 | c2 | v | link2 |
a3 | link | b2 | link | link2 | c1 | t | link2 |
a2 | link | b2 | link | link2 | c2 | v | link2 |
a2 | link | b2 | link | link2 | c1 | t | link2 |
Now let us add the DISTINCTROW keyword and select a single column from just tblA:
SELECT DISTINCTROW A1 FROM (Temp1 INNER JOIN Temp2 ON Temp1.A2 = Temp2.B2) INNER JOIN Temp3 ON Temp2.B3 = Temp3.C3;
Now we consider the projection onto the rows of the only return table (tblA):
It is clear that the first two rows of this table are the same row of tblA, so they produce only one row in the final result table. The same holds for the last two rows. Hence, the result table is:
Let us now change this by requesting a column from tblC, thus making it a return table as well:
SELECT DISTINCTROW A1,C1 FROM (Temp1 INNER JOIN Temp2 ON Temp1.A2 = Temp2.B2) INNER JOIN Temp3 ON Temp2.B3 = Temp3.C3;
The projection onto return table rows is now:
These row “pairs” are all distinct. In fact:
Row 1 comes from row 3 of tblA and row 2 of tblC.
Row 2 comes from row 3 of tblA and row 1 of tblC.
Row 3 comes from row 2 of tblA and row 2 of tblC.
Row 4 comes from row 2 of tblA and row 1 of tblC.
It follows that the return table includes all rows:
Finally, consider what happens if we change the third row of tblA to:
Running the first DISTINCTROW statement:
SELECT DISTINCTROW A1 FROM (Temp1 INNER JOIN Temp2 ON Temp1.A2 = Temp2.B2) INNER JOIN Temp3 ON Temp2.B3 = Temp3.C3;
gives:
Comparing this to the previous result table DISTINCTROW, A1 emphasizes the fact that, even though the second and third rows of tblNewA are identical in values, they are different rows, so they both contribute to the final result table. If we were to replace the DISTINCTROW keyword with the word DISTINCT, then the result table would have only one row, since then it is the values in each row that form the basis for comparison.
Of course, this would not be an issue if all tables had a key, since then the values in a row would determine the row. You may now see why I recommended against having two different rows with the same column values, even though Access permits this possibility (but true relational databases do not).
Notice what happens if all tables mentioned in the TablesClause are return tables. This would happen, for instance, if there is only one table in TablesClause. In this case, the projection does nothing; since each row of the TablesClause result table must come from a distinct combination of rows of the result tables, we deduce that DISTINCTROW has exactly the same effect as ALL. To put it another way, DISTINCTROW is ignored.
It is useful to compare DISTINCTROW and DISTINCT. We can see that the only difference is that a DISTINCT statement will return distinct values, rather than values from distinct rows. However, these will be the same if the requested columns from each return table uniquely identify their rows.
Let us illustrate with the PUBLISHERS example. Suppose we return a key (PubID) for PUBLISHERS, as in the statement:
SELECT DISTINCTROW PubID, PubName FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID;
Then the result table will return all PUBLISHERS rows that have at least one book in the BOOKS table, as Table 6-7 shows.
PubID | PubName |
3 | Small House |
1 | Big House |
2 | Alpha Press |
4 | Small House |
This is, in fact, the semi-join:
PUBLISHERSsemi-joinPUBLISHERS.PubID=BOOKS.PubIDBOOKS
Recall that the semi-join is the projection of the join onto one of the tables (in this case, the PUBLISHERS table). Thus, as Microsoft itself says, the purpose of the DISTINCTROW option is to return an updatable semi-join.
Of course, the same statement with DISTINCT in place of DISTINCTROW will return the same result table. However, there is one big difference. Since DISTINCT statements can completely hide the origin of the returned values, it would be a disaster if Access allowed such a result table to be updatable—and indeed it does not. For instance, recall the table tblDISTINCT discussed earlier and shown in Table 6-8.
Changing the name of Small House in this result table would be disastrous, since we would not know which Small House was being affected!
On the other hand, the result table of the DISTINCTROW statement has a “representative” from each row of the PUBLISHERS table, as Table 6-9 shows. Hence, while it still may not be a good idea to change this particular table, since we cannot tell which Small House is which, it would be reasonable to make a change to both names, for instance.
More generally, Access does not permit updating of the result table of a DISTINCT statement, but it does permit updating of the result table for a DISTINCTROW statement.
Finally, we mention that Microsoft Access includes the DISTINCTROW keyword by default when you create a query using the Access Query Design Window.
ReturnColumnDescription
The ReturnColumnDescription describes the columns, or combination of columns, to return. It can be any of the following:
* (indicating all columns)
The name of a column
An expression involving column names, enclosed in brackets, along with strings and string operators; for example,
[PubID]&"-"&[Title]
(Note that, according to the syntax of the SELECT statement, ReturnColumnDescription can be repeated as many times as desired.)
When two returned columns (from different tables) have the same name, it is necessary to qualify the column names using the table names. For instance, to qualify the PubID column name, we write BOOKS.PubID and PUBLISHERS.PubID. We can also write BOOKS.* to indicate all columns of the BOOKS table.
Finally, each ReturnColumnDescription can end with:
[AS AliasName]
to give the return column a (new) name. For example, the following statement:
SELECT DISTINCTROW [ISBN] & " from " & [PubName] AS [ISBN from PubName] FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID;
returns a single-column result table ISBN-PUB, as shown in Table 6-10.
ISBN from PubName |
0-12-345678-9 from Small House |
0-11-345678-9 from Small House |
0-321-32132-1 from Small House |
0-55-123456-9 from Small House |
0-12-333433-3 from Big House |
0-103-45678-9 from Big House |
0-91-335678-7 from Big House |
0-99-999999-9 from Big House |
1-22-233700-0 from Big House |
1-1111-1111-1 from Big House |
0-91-045678-5 from Alpha Press |
0-555-55555-9 from Alpha Press |
0-99-777777-7 from Alpha Press |
0-123-45678-0 from Alpha Press |
Not only does the AS AliasName option allow us to name a compound column, it also allows us to rename duplicate column names without having to qualify the names.
FROM TableExpression
The FROM clause specifies the tables (or queries) from which the SELECT statement is to take its rows. The expression TableExpression can be a single table name, several table names separated by commas, or a join clause. The TableExpression may also include the AS AliasName syntax for table-name aliases.
When tables are separated by commas in the FROM clause, a Cartesian product is formed. For example, the statement:
SELECT * FROM AUTHORS, PUBLISHERS;
will produce the Cartesian product of the two tables.
WHERE RowCondition
The RowCondition is any Access expression that specifies which rows are included in the result table. Expressions can involve column names, constants, arithmetic (=, <, >, <=, >=, < >, BETWEEN) and logical (AND, OR, XOR, NOT, IMP) relations, as well as functions. Here are some examples:
WHERE Title LIKE “F*”
WHERE Len(Trim(Title)) > 10
WHERE Instr(Title, “Wind”) > 0 AND Len(Trim(Title)) > 10
WHERE DateSold = #5/21/96#
Note that dates are enclosed in number signs (#) and the strings are enclosed in quotation marks (” “).
GROUP BY GroupByCriteria
The GROUP BY option allows records to be grouped together for the purpose of computing the value of an aggregate function (Avg, Count, Min, Max, Sum, First, Last, StDev, StDevP, Var, and VarP). It is equivalent to creating a so-called totals query. The GroupByCriteria can contain the names of up to 10 columns. The order of the column names determines the grouping levels, from highest to lowest.
For example, the following statement lists each publisher by name, along with the minimum price of each publisher’s books in the BOOKS table:
SELECT PUBLISHERS.PubName, MIN(Price) AS [Minimum Price] FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID GROUP BY PUBLISHERS.PubName;
The result table appears in Table 6-11.
HAVING GroupCriteria
The HAVING option is used in conjunction with the GROUP BY option and allows us to specify a criterion, in terms of aggregate functions, for deciding which data to display.
For example, the following command is the same as the previous one, with the additional HAVING option that restricts the return table to those publishers whose minimum price is less than $20.00:
SELECT PUBLISHERS.PubName, MIN(Price) AS [Minimum Price] FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID GROUP BY PUBLISHERS.PubName HAVING MIN(Price)<20.00;
The result table is shown in Table 6-12.
PubName | Minimum Price |
Alpha Press | $12.00 |
Big House | $15.00 |
Note that the WHERE clause restricts which rows participate in the grouping and hence contribute to the value of the aggregate functions, whereas the HAVING clause affects only which values are displayed.
ORDER BY OrderByCriteria
The ORDER BY option describes the order in which to return the rows in the return table. The OrderByCriteria has the form:
OrderByCriteria ::= {ColumnName [ASC | DESC ]},...In other words, it is just a list of columns to use in the ordering. Rows are sorted first by the first column listed, then rows with identical values in the first column are sorted by the values in the second column, and so on.
The UNION Statement
The UNION statement is used to create the union of two or more tables. The syntax is:
[TABLE]Query{UNION [ALL] [TABLE]Query},...
where Query is either a SELECT
statement, the name of a stored query, or the name of a stored table
preceded by the TABLE keyword. The ALL option forces Access to include all records.
Without this option, Access does not include duplicate rows. The use
of ALL increases performance as well and is thus recommended even
when there are no duplicate rows.
Example
The following statement takes the union of all rows of BOOKS and those rows of NEWBOOKS that have Price > $25.00, sorting the result table by Title:
TABLE BOOKS UNION ALL SELECT * FROM NEWBOOKS WHERE Price > 25.00 ORDER BY Title;
Notes
All queries in a UNION operation must return the same number of fields. However, the fields do not need to have the same size or data type.
Columns are combined in the union by their order in the query clauses, not by their names.
Aliases may be used in the first SELECT statement (if there is one) to change the names of returned columns.
An ORDER BY clause can be used at the end of the last
Queryto order the returned data. Use the column names from the firstQuery.GROUP BY and/or HAVING clauses can be used in each query argument to group the returned data.
The result table of a UNION is not updatable.
UNION is not part of SQL-92.
The UPDATE Statement
The UPDATE statement is equivalent to an Update query and is used for updating data in a table or tables. The syntax is:
UPDATETableName|QueryNameSETNewValueExpression,... WHERECriteria;
The WHERE clause is used to restrict updating to qualifying rows.
Example
The following example updates the Price column in the BOOKS table with new prices from a table called NEWPRICES that has an ISBN and a Price column:
UPDATE BOOKS INNER JOIN NEWPRICES ON BOOKS.ISBN = NEWPRICES.ISBN SET BOOKS.Price = NEWPRICES.Price WHERE BOOKS.Price <> NEWPRICES.Price;
Note that UPDATE does not produce a result table. To determine which rows will be updated, first run a corresponding SELECT query, as in:
SELECT * FROM BOOKS INNER JOIN NEWPRICES ON BOOKS.ISBN = NEWPRICES.ISBN WHERE BOOKS.Price <> NEWPRICES.Price
The DELETE Statement
The DELETE statement is equivalent to a Delete query and is used to delete rows from a table. Here is the syntax:
DELETE FROMTableNameWHERECriteria
Criteria is used to determine which
rows to delete.
This command can be used to delete all data from a table, but it will not delete the structure of the table. Use DROP for that purpose.
You can use DELETE to remove records from tables that have a one-to-many relationship. If cascading delete is enabled when you delete a row from the one side of the relationship, all matching rows are deleted from the many side. The action of the DELETE statement is not reversible. Always make backups before deleting! You can run a SELECT operation before DELETE to see which rows will be affected by the DELETE operation.
The INSERT INTO Statement
The INSERT INTO statement is designed to insert new rows into a table. This can be done by specifying the values of a new row using this syntax:
INSERT INTOTarget[(FieldName,...)] VALUES (Value1,...)
If you do not specify the FieldName
(s), then you must include values for each field in
the table.
Let’s look at several examples of the INSERT INTO statement. The following statement inserts a new row into the BOOKS table:
INSERT INTO BOOKS
VALUES ("1-000-00000-0", "SQL is Fun",1,25.00);The following statement inserts a new row into the BOOKS table. The Price and PubID columns have NULL values.
INSERT INTO BOOKS (ISBN,Title)
VALUES ("1-1111-1111-1","Gone Fishing");To insert multiple rows, use this syntax:
INSERT INTOTarget[(FieldName,...)] SELECTFieldName,... FROMTableExpression
In both syntaxes, Target is the
name of the table or query into which rows are to be inserted. In
the case of a query, that query must be updatable and all updates
will be reflected in the underlying tables.
TableExpression is the name of the table
from which records are inserted, the name of a saved query, or a
SELECT statement.
Assume that NEWBOOKS is a table with three fields: ISBN, PubID, and Price. The following statement inserts rows from BOOKS into NEWBOOKS. It inserts only those books with Price > $20.00.
INSERT INTO NEWBOOKS SELECT ISBN, PubID, Price FROM BOOKS WHERE Price>20;
Note
Text field values must be enclosed in quotation marks.
The SELECT...INTO Statement
The SELECT... INTO statement is equivalent to a MakeTable query. It makes a new table and inserts data from other tables. The syntax is:
SELECTFieldName,... INTONewTableNameFROMSourceWHERERowConditionORDER BYOrderCondition
FieldName is the name of the field
to be copied into the new table. Source
is the name of the table from which data is taken. This can also be
the name of a query or a join statement.
For example, the following statement creates a new table called EXPENSIVEBOOKS and includes books from the BOOKS table that cost more than $45.00:
SELECT Title, ISBN INTO EXPENSIVEBOOKS FROM BOOKS WHERE Price>45 ORDER BY Title;
Notes
This statement is unique to Access SQL.
This statement does not create indexes in the new table.
TRANSFORM
The TRANSFORM statement (which is not part of SQL-92) is designed to create crosstab queries. The basic syntax is:
TRANSFORMAggregateFunctionSelectStatementPIVOTColumnHeadingsColumn[IN (Value,...)]
The AggregateFunction is one of
Access’ aggregate functions (Avg,
Count, Min,
Max, Sum,
First, Last,
StDev, StDevP,
Var, and VarP). The
ColumnHeadingsColumn is the column that
is pivoted to give the column headings in the crosstab result table.
The Values in the IN clause option
specify fixed column headings.
The SelectStatement is a SELECT
statement that uses the GROUP BY clause, with some modifications. In
particular, the select statement must have at least two GROUP BY
columns and no HAVING clause.
As an example, suppose we wish to display the total number of books from each publisher by price. The SELECT statement:
SELECT PubName, Price, COUNT(Title) AS Total FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID=BOOKS.PubID GROUP BY PubName, Price;
whose result table is shown in Table 6-13, doesn’t really give the information in the desired form. For instance, it is difficult to tell how many books cost $20.00. (Remember, this small table is just for illustration.)
PubName | Price | Total |
Big House | $15.00 | 1 |
Big House | $20.00 | 1 |
Big House | $25.00 | 2 |
Big House | $49.00 | 1 |
Medium House | $12.00 | 2 |
Medium House | $20.00 | 1 |
Medium House | $34.00 | 1 |
Medium House | $49.00 | 1 |
Small House | $49.00 | 1 |
We can transform this into a crosstab query in two steps:
Add a TRANSFORM clause at the top, and move the aggregate function whose value is to be computed to that clause.
Add a PIVOT line at the bottom, and move the column whose values will form the column headings to that clause. Also, delete the reference to this column in the SELECT clause.
This gives:
TRANSFORM COUNT(Title) SELECT Price FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID=BOOKS.PubID GROUP BY Price PIVOT PubName;
with the result table shown in Table 6-14.
Price | Big House | Medium House | Small House |
$12.00 | 2 | ||
$15.00 | 1 | ||
$20.00 | 1 | 1 | |
$25.00 | 2 | ||
$34.00 | 1 | ||
$49.00 | 1 | 1 | 1 |
We can group the rows by the values in more than one column. For example, suppose that the BOOKS table also had a DISCOUNT column that gave the discount from the regular price of the book (as a percentage). Then by including the DISCOUNT column in the SELECT and GROUP BY clauses, we get:
TRANSFORM COUNT(Title) SELECT Price, Discount FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID=BOOKS.PubID GROUP BY Price, Discount PIVOT PubName;
for which the result table is shown in Table 6-15.
Price | Discount | Big House | Medium House | Small House |
$12.00 | 30% | 2 | ||
$15.00 | 20% | 1 | ||
$20.00 | 20% | 1 | ||
$20.00 | 30% | 1 | ||
$25.00 | 10% | 1 | ||
$25.00 | 20% | 1 | ||
$34.00 | 10% | 1 | ||
$49.00 | 10% | 1 | ||
$49.00 | 30% | 1 | 1 |
In this case, each row represents a unique price/discount pair.
A crosstab can also include additional row aggregates by adding additional aggregate functions to the SELECT clause, as follows:
TRANSFORM COUNT(Title) SELECT Price, COUNT(Price) AS Count, SUM(Price) AS Sum FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID=BOOKS.PubID GROUP BY Price PIVOT PubName;
which gives the result table shown in Table 6-16.
Price | Count | Sum | Big House | Medium House | Small House |
$12.00 | 2 | $24.00 | 2 | ||
$15.00 | 1 | $15.00 | 1 | ||
$20.00 | 2 | $40.00 | 1 | 1 | |
$25.00 | 2 | $50.00 | 2 | ||
$34.00 | 1 | $34.00 | 1 | ||
$49.00 | 3 | $147.00 | 1 | 1 | 1 |
Finally, by including fixed column names, we can reorder or omit columns from the crosstab result table. For instance, the next statement is just like the previous one except for the PIVOT clause:
TRANSFORM COUNT(Title)
SELECT Price, COUNT(Price) AS Count, SUM(Price) AS Sum
FROM PUBLISHERS INNER JOIN BOOKS
ON PUBLISHERS.PubID=BOOKS.PubID
GROUP BY Price
PIVOT PubName IN ("Small House", "Medium House");The result table is shown in Table 6-17. Note that the order of the columns has changed and Big House is not shown.
Subqueries
SQL permits the use of SELECT statements within the following:
Other SELECT statements
SELECT... INTO statements
INSERT... INTO statements
DELETE statements
UPDATE statements
The internal SELECT statement is referred to as a subquery and is generally used in the WHERE clause of the main query.
The syntax of a subquery takes three possible forms, described as follows.
Syntax 1
Comparison[ANY | SOME | ALL] (SQLStatement)
where Comparison is an expression
followed by a comparison relation that compares the expression
with the return value(s) of the subquery. This syntax is used to
compare a value against the values obtained from another
query.
For example, the following statement returns all titles and prices of books from the BOOKS table, whose prices are greater than the maximum price of all books in the table BOOKS2:
SELECT Title, Price FROM BOOKS WHERE Price > (SELECT Max(Price) FROM BOOKS2);
Note that since the subquery returns only one value, we do not need to use any of the keywords ANY, SOME, or ALL.
The following statement selects all BOOKS titles and prices for books that are more expensive than ALL of the books published by Big House:
SELECT Title, Price FROM BOOKS WHERE Price > ALL (SELECT Price FROM PUBLISHERS INNER JOIN BOOKS ON PUBLISHERS.PubID = BOOKS.PubID WHERE PubName = "Big House");
Note that ANY and SOME have the same meaning and return all choices that make the comparison true for at least one value returned by the subquery. For example, if we were to replace ALL by SOME in the previous example, the return table would consist of all book titles and prices for books that are more expensive than the cheapest book published by Big House.
Syntax 2
Expression[NOT] IN (SQLStatement)
This syntax is used to look up a column value in the result table of another query.
For example, the following statement returns all book titles from BOOKS that do not appear in the table BOOKS2:
SELECT Title FROM BOOKS WHERE Title NOT IN (SELECT Title FROM BOOKS2);
Syntax 3
[NOT] EXISTS (SQLStatement)This syntax is used to check whether an item exists (is returned) in the subquery.
For example, the following statement selects all publishers that do not have books in the BOOKS table:
SELECT PubName FROM PUBLISHERS WHERE NOT EXISTS (SELECT * FROM BOOKS WHERE BOOKS.PubID = PUBLISHERS.PubID);
Notice that the PUBLISHERS table is referenced in the subquery. This causes Access to evaluate the subquery once for each value of PUBLISHERS.PubID in the PUBLISHERS table.
Parameters
Access SQL allows the use of parameters to obtain information from the user when the query is run. The PARAMETERS line must be the first line in the statement and has the syntax:
PARAMETERSName DataType,...An example will illustrate the technique.
The following statement will prompt the user for a portion of the title of a book and return all books from BOOKS with that string in the title. Note the semicolon at the end of the PARAMETERS line.
PARAMETERS [Enter portion of title] TEXT; SELECT * FROM BOOKS WHERE Instr(Title, [Enter portion of title]) > 0;
The function Instr(Text1,
Text2) returns the first location
of the text string Text2 within the text
string Text1. Note that
Name is repeated in the WHERE clause and
will be filled in by the value that the user enters as a result of
Name appearing in the PARAMETERS
clause.