
Chapter 3. Implementing Entity-Relationship Models: Relational Databases
An E/R model of a database is an abstract model, visualized through an E/R diagram. For this to be useful, we must translate the abstract model into a concrete one. That is, we must describe each aspect of the model in the concrete terms that a database program can manipulate. In short, we must implement the E/R model. This requires implementing several things:
The entities
The entity classes
The entity sets
The relationships between the entity classes
The result of this implementation is a relational database.
As we will see, implementing the relationships usually involves some changes to the entity classes, perhaps by adding new attributes to existing entity classes or by adding new entity classes.
Implementing Entities
As discussed in the previous chapter, an entity is implemented (or described in concrete terms) simply by giving the values of its attributes. Thus, the following is an implementation of a Books entity:
Title = Gone With the Wind ISBN = 0-12-345678-9 Price = $24.00
Implementing Entity Classes—Table Schemes
Since the entities in an entity class are implemented by giving their attribute values, it makes sense to implement an entity class by the set of attribute names. For instance, the Books entity class can be identified with the set:
{ISBN,Title,Price}(We will add the PubID attribute name later, when we implement the relationships.)
Since attribute names are usually used as column headings for a table, a set of attribute names is called a table scheme. Thus, entity classes are implemented as table schemes. For convenience, we use notation such as:
Books(ISBN,Title,Price)
which shows not only the name of the entity class, but also the names of the attributes in the table scheme for this class. You can also think of a table scheme as the column headings row (the top row) of any table that is formed using that table scheme. (I will present an example of this shortly.)
We have defined the concepts of a superkey and a key for entity classes. These concepts apply equally well to table schemes, so we may say that the attributes {A,B} form a key for a table scheme, meaning that they form a key for the entity class implemented by that table scheme.
Implementing Entity Sets—Tables
In a relational database, each entity set is modeled by a table. For example, consider the BOOKS table shown in Table 3-1, and note the following:
The first row of the table is the table scheme for the Books entity class.
Each of the other rows of the table implements a Books entity.
The set of all rows of the table, except the first row, implements the entity set itself.
ISBN | Title | Price |
0-12-333433-3 | On Liberty | $25.00 |
0-103-45678-9 | Iliad | $25.00 |
0-91-335678-7 | Faerie Queene | $15.00 |
0-99-999999-9 | Emma | $20.00 |
1-22-233700-0 | Visual Basic | $25.00 |
1-1111-1111-1 | C++ | $29.95 |
0-91-045678-5 | Hamlet | $20.00 |
0-555-55555-9 | Macbeth | $12.00 |
0-99-777777-7 | King Lear | $49.00 |
0-123-45678-0 | Ulysses | $34.00 |
0-12-345678-9 | Jane Eyre | $49.00 |
0-11-345678-9 | Moby-Dick | $49.00 |
0-321-32132-1 | Balloon | $34.00 |
0-55-123456-9 | Main Street | $22.95 |
More formally, a table T is a rectangular array of elements with the following properties:
The top of each column is labeled with a distinct attribute name Ai. The label Ai is also called the column heading .
The elements of the i th column of the table T come from a single set Di, called the domain for the i th column. Thus, the domain is the set of all possible values for the attribute. For instance, for the BOOKS table in Table 3-1, the domain D1 is the set of all possible ISBNs, and the domain D2 is the set of all possible book titles.
No two rows of the table are identical.
Let us make some remarks about the concept of a table:
A table may (but is not required to) have a name, such as BOOKS, which is intended to convey the meaning of the table as a whole.
The number of rows of the table is called the size of the table, and the number of columns is called the degree of the table. For example, the BOOKS table shown in Table 3-1 has size 14 and degree 3. The attribute names are ISBN, Title, and Price.
As mentioned earlier, to emphasize the attributes of a table, it is common to denote a table by writing T(A1,...,An); for example, we denote the BOOKS table by:
BOOKS(ISBN,Title,Price)
The order of the rows of a table is not important, and so two tables that differ only in the order of their rows are thought of as being the same table. Similarly, the order of the columns of a table is not important as long as the headings are thought of as part of their respective columns. In other words, we may feel free to reorder the columns of a table, as long as we keep the headings with their respective columns.
Finally, there is no requirement that the domains of different columns be different. (For example, it is possible for two columns in a single table to use the domain of integers.) However, there is a requirement that the attribute names of different columns be different. Think of the potential confusion that would otherwise ensue, in view of the fact that we may rearrange the columns of a table!
Now that we have defined the concept of a table, we can say that it is common to define a relational database as a finite collection of tables. However, this definition belies the fact that the tables also model the relationships between the entity classes, as we will see.
A Short Glossary
To help keep the various database terms clear, let us collect their definitions in one place:
- Entity
An object about which the database is designed to store information. Example: a book; that is, an ISBN, a title, and a price, as in:
0-12-333433-3, On Liberty, $25.00
- Attribute
A property that (partially or completely) describes an entity. Example: title.
- Entity class
An abstract group of entities, with a common description. Example: the entity class Books, representing all books in the universe.
- Entity set
The set of entities from a given entity class that are currently in the database. Example: the following set of 14 books:
0-12-333433-3, On Liberty, $25.00 0-103-45678-9, Iliad, $25.00 0-91-335678-7, Faerie Queene, $15.00 0-99-999999-9, Emma, $20.00 1-22-233700-0, Visual Basic, $25.00 1-1111-1111-1, C++, $29.95 0-91-045678-5, Hamlet, $20.00 0-555-55555-9, Macbeth, $12.00 0-99-777777-7, King Lear, $49.00 0-123-45678-0, Ulysses, $34.00 0-12-345678-9, Jane Eyre, $49.00 0-11-345678-9, Moby-Dick, $49.00 0-321-32132-1, Balloon, $34.00 0-55-123456-9, Main Street, $22.95
- Superkey
A set of attributes for an entity class that serves to identify an entity uniquely from among all possible entities in that entity class. Example: the set {Title, ISBN} for the Books entity class.
- Key
A minimal superkey; that is, a key with the property that, if we remove an attribute, the resulting set is no longer a superkey. Example: the set {ISBN} for the Books entity class.
- Table
A rectangular array of attribute values whose columns hold the attribute values for a given attribute and whose rows hold the attribute values for a given entity. Tables are used to implement entity sets. Example: the BOOKS table shown earlier in Table 3-1.
- Table scheme
The set of all attribute names for an entity class. Example:
{ISBN,Title,Price}Since this is the table scheme for the entity class Books, we can use the notation Books (ISBN,Title,Price).
- Relational database
A finite collection of tables that provides an implementation of an E/R database model.
Implementing the Relationships in a Relational Database
Now let us discuss how we might implement the relationships in an E/R database model. For convenience, we repeat the E/R diagram for the LIBRARY database in Figure 3-1.
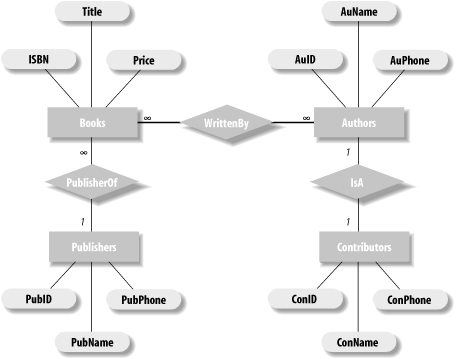
Implementing a One-to-Many Relationship—Foreign Keys
Implementing a one-to-many relationship, such as the PublisherOf relationship, is fairly easy. To illustrate, since {PubID} is a key for the Publishers entity class, we simply add this attribute to the Books entity class. Thus, the Books entity class becomes:
Books(ISBN,Title,PubID,Price)
The Books table scheme is now:
{ISBN,Title,PubID,Price}and the BOOKS table now appears as shown in Table 3-2 (sorted by PubID).
ISBN | Title | PubID | Price |
0-12-333433-3 | On Liberty | 1 | $25.00 |
0-103-45678-9 | Iliad | 1 | $25.00 |
0-91-335678-7 | Faerie Queene | 1 | $15.00 |
0-99-999999-9 | Emma | 1 | $20.00 |
1-22-233700-0 | Visual Basic | 1 | $25.00 |
1-1111-1111-1 | C++ | 1 | $29.95 |
0-91-045678-5 | Hamlet | 2 | $20.00 |
0-555-55555-9 | Macbeth | 2 | $12.00 |
0-99-777777-7 | King Lear | 2 | $49.00 |
0-123-45678-0 | Ulysses | 2 | $34.00 |
0-12-345678-9 | Jane Eyre | 3 | $49.00 |
0-11-345678-9 | Moby-Dick | 3 | $49.00 |
0-321-32132-1 | Balloon | 3 | $34.00 |
0-55-123456-9 | Main Street | 3 | $22.95 |
The PubID attribute in the Books entity class is referred to as a foreign key, because it is a key for a foreign entity class—that is, for the Publishers entity class.
Note that the value of the foreign key PubID in the BOOKS table provides a reference to the corresponding value in PUBLISHERS. Moreover, since {PubID} is a key for the Publishers entity class, there is at most one row of PUBLISHERS that contains a given value. Thus, for each book entity, we can look up the PubID value in the PUBLISHERS table to get the name of the publisher of that book. In this way, we have implemented the one-to-many PublisherOf relationship.
The idea just described is pictured in more general terms in Figure 3-2. Suppose that there is a one-to-many relationship between the entity classes (or, equivalently, table schemes) S and T. Figure 3-2 shows two tables S and T based on these table schemes. Suppose also that {A2} is a key for table scheme S (the one side of the relationship). Then we add this attribute to the table scheme T (and hence to table T). In this way, for any row of the table T, we can identify the unique row in table S to which it is related.
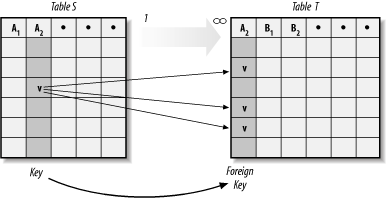
The attribute set {A2} in table S is a key for the table scheme S. For this reason, the attribute set {A2} is also called a foreign key for the table scheme T. More generally, a set of attributes of a table scheme T is aforeign key for T if it is a key for some other table scheme S. Note that a foreign key for T is not a key for T—it is a key for another table scheme. Thus, the attribute set {PubID} is a key for Publishers, but a foreign key for Books.
As with our example, a foreign key provides a reference to the entity class (table scheme) for which it is a key. The table scheme T is called the referencing table scheme, and the table scheme S is called the referenced table scheme . The key that is being referenced in the referenced table scheme is called the referenced key .
Note that adding a foreign key to a table scheme does create some duplicate values in the database, but we must expect to add some additional information to the database in order to describe the relationships.
Implementing a One-to-One Relationship
Of course, the procedure of introducing a foreign key into a table scheme works equally well for one-to-one relationships as for one-to-many relationships. For instance, we only need to rename the ConID attribute to AuID to make ConID into a foreign key that will implement the Authors-Contributors IsA relationship.
Implementing a Many-to-Many Relationship—New Entity Classes
The implementation of a many-to-many relationship is a bit more involved. For instance, consider the WrittenBy relationship between Books and Authors.
At first glance, we might think of just adding foreign keys to each table scheme, thinking of the relationship as two distinct one-to-many relationships. However, this approach is not good, since it requires duplicating table rows. For example, if we add the ISBN key to the Authors table scheme and the AuID key to the Books table scheme, then each book that is written by two authors must be represented by two rows in the BOOKS table, so we can have two AuIDs. To be specific, since the book Main Street is written by Smith and Jones, we would need two rows in the BOOKS table:
TITLE: Main Street, ISBN 0-55-123456-9, Price: $22.95 AuID: Smith TITLE: Main Street, ISBN 0-55-123456-9, Price: $22.95 AuID: Jones
It is clear that this approach will bloat the database with redundant information.
The proper approach to implementing a many-to-many relationship is to add a new table scheme to the database in order to break the relationship into two one-to-many relationships. In our case, we add a Book/Author table scheme, whose attributes consist precisely of the foreign keys ISBN and AuID:
Book/Author(ISBN,AuID)
To get a pictorial view of this procedure, Figure 3-3 shows the corresponding E/R diagram. Note that it is not customary to include this as a portion of the original E/R diagram, since it belongs more to the implementation of the design than to the design itself.

Referential Integrity
There are a few important considerations that we must discuss with regard to using foreign keys to implement relationships. First, of course, is the fact that each value of the foreign key must have a matching value in the referenced key. Otherwise, we would have a so-called dangling reference . For instance, if the PubID key in a BOOKS table did not match a value of the PubID key in the PUBLISHERS table, we would have a book whose publisher did not exist in the database—that is, a dangling reference to a nonexistent publisher.
The requirement that each value in the foreign key be a value in the referenced key is called the referential constraint , and the problem of ensuring that there are no dangling references is referred to as the problem of ensuring referential integrity.
There are several ways in which referential integrity might be compromised. First, we could add a value to the foreign key that is not in the referenced key. This would happen, for instance, if we added a new book entity to the BOOKS table, whose publisher is not listed in the PUBLISHERS table. Such an action will be rejected by a database application that has been instructed to protect referential integrity. More subtle ways to affect referential integrity are to change or delete a value in the referenced key—the one that is being referenced by the foreign key. This would happen, for instance, if we deleted a publisher from the PUBLISHERS table, but that publisher had at least one book listed in the BOOKS table.
Of course, the database program can simply disallow such a change or deletion, but there is sometimes a preferable alternative, as discussed next.
Cascading Updates and Cascading Deletions
Many database programs allow the option of performing cascading updates , which simply means that, if a value in the referenced key is changed, then all matching entries in the foreign key are automatically changed to match the new value. For instance, if cascading updates are enabled, then changing a publisher’s PubID in a PUBLISHERS table, say from 100 to 101, would automatically cause all values of 100 in the PubID foreign key of the referencing table BOOKS to change to 101. In short, cascading updates keep everything “in sync.”
Similarly, enabling cascading deletions means that if a value in the referenced table is deleted by deleting the corresponding row in the referenced table, then all rows in the referencing table that refer to that deleted key value will also be deleted. For instance, if we delete a publisher from a PUBLISHERS table, all book entries referring to that publisher (through its PubID) will be deleted from the BOOKS table automatically. Thus, cascading deletions also preserve referential integrity, at the cost of performing perhaps massive deletions in other tables. Thus, cascading deletions should be used with circumspection.
As you may know, Microsoft Access allows the user to enable or disable both cascading updates and cascading deletions. We will see just how to do this in Access later.
The LIBRARY Relational Database
We can now complete the implementation of the LIBRARY relational database (without the Contributors entity class) in Microsoft Access. If you open the LIBRARY database in Microsoft Access, you will see four tables:
AUTHORS
BOOK/AUTHOR
BOOKS
PUBLISHERS
(The LIBRARY_FLAT table is not used in the relational database.)
These four tables correspond to the following four entity classes (or table schemes):
Authors (AuID, AuName, AuPhone)
Book/Author (ISBN, AuID)
Books (ISBN, Title, PubID, Price)
Publishers (PubID, PubName, PubPhone)
The actual tables are shown in Tables Table 3-3 through Table 3-6.
AuID | AuName | AuPhone |
1 | Austen | 111-111-1111 |
10 | Jones | 123-333-3333 |
11 | Snoopy | 321-321-2222 |
12 | Grumpy | 321-321-0000 |
13 | Sleepy | 321-321-1111 |
2 | Melville | 222-222-2222 |
3 | Homer | 333-333-3333 |
4 | Roman | 444-444-4444 |
5 | Shakespeare | 555-555-5555 |
6 | Joyce | 666-666-6666 |
7 | Spenser | 777-777-7777 |
8 | Mill | 888-888-8888 |
9 | Smith | 123-222-2222 |
ISBN | AuID |
0-103-45678-9 | 3 |
0-11-345678-9 | 2 |
0-12-333433-3 | 8 |
0-12-345678-9 | 1 |
0-123-45678-0 | 6 |
0-321-32132-1 | 11 |
0-321-32132-1 | 12 |
0-321-32132-1 | 13 |
0-55-123456-9 | 9 |
0-55-123456-9 | 10 |
0-555-55555-9 | 5 |
0-91-045678-5 | 5 |
0-91-335678-7 | 7 |
0-99-777777-7 | 5 |
0-99-999999-9 | 1 |
1-1111-1111-1 | 4 |
1-22-233700-0 | 4 |
ISBN | Title | PubID | Price |
0-12-333433-3 | On Liberty | 1 | $25.00 |
0-103-45678-9 | Iliad | 1 | $25.00 |
0-91-335678-7 | Faerie Queene | 1 | $15.00 |
0-99-999999-9 | Emma | 1 | $20.00 |
1-22-233700-0 | Visual Basic | 1 | $25.00 |
1-1111-1111-1 | C++ | 1 | $29.95 |
0-91-045678-5 | Hamlet | 2 | $20.00 |
0-555-55555-9 | Macbeth | 2 | $12.00 |
0-99-777777-7 | King Lear | 2 | $49.00 |
0-123-45678-0 | Ulysses | 2 | $34.00 |
0-12-345678-9 | Jane Eyre | 3 | $49.00 |
0-11-345678-9 | Moby-Dick | 3 | $49.00 |
0-321-32132-1 | Balloon | 3 | $34.00 |
0-55-123456-9 | Main Street | 3 | $22.95 |
PubID | PubName | PubPhone |
1 | Big House | 123-456-7890 |
2 | Alpha Press | 999-999-9999 |
3 | Small House | 714-000-0000 |
Notice that we have included the necessary foreign key {PubID} in the BOOKS table in Table 3-5, to implement the PublisherOf relationship, which is one-to-many. Also, we have included the BOOK/AUTHOR table (Table 3-4) to implement the WrittenBy relationship, which is many-to-many.
Even though all relationships are established through foreign keys, we must tell Access that these foreign keys are being used to implement the relationships. Here are the steps.
Setting Up the Relationships in Access
Just to illustrate a point, make the following small change in the BOOKS table: Open the table and change the PubID field for Hamlet to 4. Note that there is no publisher with PubID 4 and so we have created a dangling reference. Then close the BOOKS window.
Now choose Relationships from the Tools menu. You should get a window showing the table schemes in the database, similar to that in Figure 3-4. Relationships are denoted by lines between these table schemes. As you can see, there are as yet no relationships. Note that the primary key attributes appear in boldface.
To set the relationship between PUBLISHERS and BOOKS, place the mouse pointer over the PubID attribute name in the PUBLISHERS table scheme, hold down the left mouse button, and drag the name to the PubID attribute name in the BOOKS table scheme. You should get a window similar to Figure 3-5.
This window shows the relationship between PUBLISHERS and BOOKS, listing the key {PubID} in PUBLISHERS and the foreign key {PubID} in BOOKS. (We did not need to call the foreign key PubID, but it makes sense to do so, since it reminds us of the purpose of the attribute.)
Now check the Enforce Referential Integrity box, and click the Create button. You should get the message in Figure 3-6. The problem is, of course, the dangling reference that we created by changing the PubID field in the BOOKS table to refer to a nonexistent publisher.
Click the OK button, reopen the BOOKS table, and fix the offending entry (change the PubID field for Hamlet back to 2). Then close the BOOKS table, and re-establish the relationship between PUBLISHERS and BOOKS. This time, check the Enforce Referential Integrity checkbox, as well as the Cascade Update Related Fields checkbox. Do not check Cascade Delete Related Fields.
Next, drag the ISBN attribute name from the BOOKS table scheme to the ISBN attribute name in the BOOK/AUTHOR table scheme. Again check the Enforce Referential Integrity and Cascade Update Related Fields checkboxes.
Finally, drag the AuID attribute name from the AUTHORS table scheme to the AuID attribute name in the BOOK/AUTHOR table scheme. Check the Enforce Referential Integrity and Cascade Update Related Fields checkboxes. You should now see the lines indicating these relationships, as shown in Figure 3-7. Note the small 1s and ∞s, indicating the one side and many side of each relationship.
To test the enforcement of referential integrity, try the following experiment: open the BOOKS and PUBLISHERS tables, and arrange them so that you can see both tables at the same time. Now change the value of PubID for Small House in the PUBLISHERS table from 3 to 4. As soon as you move the cursor out of the Small House row (which makes the change permanent), the corresponding PubID values in BOOKS should change automatically! When you are done, restore the PubID value in PUBLISHERS back to 3.




Index Files
When a table is stored on disk, it is often referred to as a file. In this case, each row of the table is referred to as a record , and each column is referred to as a field. (These terms are often used for any table.)
Since disk access is typically slow, an important goal is to reduce the amount of disk accesses necessary to retrieve the desired data from a file. Sequential searching of the data, record-by-record, to find the desired information may require a large number of disk accesses and is very inefficient.
The purpose of an index file is to provide direct (also called random) access to data in a database file.
Figure 3-8 illustrates the concept of an index file. For illustration purposes, we have changed the Publishers data, to include a city column. The file on the left is the index file and indexes the Publishers datafile by the City field, which is therefore called the indexed field. The city file is called an index for the PUBLISHERS table. (The index file is not a table in the same sense as the PUBLISHERS table is a table. That is to say, we cannot directly access the index file—instead we use it indirectly.) The index file contains the cities for each publisher, along with a pointer to the corresponding data record in the Publishers file.
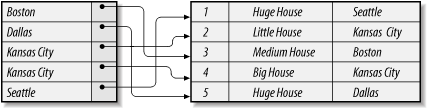
An index file can be used in a variety of ways. For instance, to find all publishers located in Kansas City, Access can first search the alphabetical list of cities in the index file. Since the list is alphabetical, Access knows that the Kansas City entries are all together, and so once it reaches the first entry after Kansas City, it can stop fcthe search. In other words, Access does not need to search the entire index file. (In addition, there are very efficient search algorithms for ordered tables.) Once the Kansas City entries are found in the index file, the pointers can be used to go directly to the Kansas City publishers in the indexed file.
Also, since the index provides a sorted view of the data in the original table, it can be used to efficiently retrieve a range of records. For instance, if the Books data were indexed on price, we could efficiently retrieve all books in the price range between $20.00 and $30.00.
A table can be indexed on more than one column; that is to say, a table can have more than one index file. Also, a table can be indexed on a combination of two or more columns. For instance, if the PUBLISHERS table also included a State column, we could index the table on a combination of City and State, as shown in Figure 3-9.

An index on a primary key is referred to as a primary index . Note that Microsoft Access automatically creates an index on a primary key. An index on any other column or columns is called a secondary index . An index based on a key (not necessarily the primary key) is called a unique index , since the indexed column contains unique values.
Example
To view the indexes for a given table in Microsoft Access, open the table in design view, and then choose Indexes from the View menu. For the BOOKS table, you should see a window similar to Figure 3-10 (without the PubTitle entry).

To add an index based on more than one attribute, you enter the multiple attributes on successive rows of the Indexes dialog box. We have done this in Figure 3-10, adding an index called PubTitle based on the PubID and the Title attributes. This index indexes the BOOKS entities first by PubID and then by Title (within each PubID).
NULL Values
The question of NULLs can be very confusing to the database user, so let us set down the basic principles. Generally speaking, a NULL is a special value that is used for two reasons:
To indicate that a value is missing or unknown
To indicate that a value is not applicable in the current context
For instance, consider an author’s table:
AUTHORS(AuID,AuName,AuPhone)
If a particular author’s phone number is unknown, it is
appropriate for that value to be NULL. This is not to say that the
author does not have a phone number, but simply that we have no
information about the number—it may or may not exist. If we knew that
the person had no phone number, then the information would no longer
be unknown. In this case, the appropriate value of the AuPhone
attribute would be the empty string, or perhaps the string no phone,
but not a NULL. Thus, the appropriateness of allowing NULL values for
an attribute depends upon the context.
The issue of whether NULLs should appear in a key needs some discussion. The purpose of a key is to provide a means for uniquely identifying entities, and so it would seem that keys and NULLs are incompatible. However, it is impractical to never allow NULLs in any keys. For instance, for the Publishers entity, this would mean not allowing a PubPhone to be NULL, since {PubName,PubPhone} is a key. On the other hand, the so-called entity integrity rule says that NULLs are not allowed in a primary key.
As a final remark, the presence of a NULL as a foreign key value does not violate referential integrity. That is, referential integrity requires that every non-NULL value in a foreign key must have a match in the referenced key.