
AOL has a long and conflicted history with the Web. AOL started its “life” as an Internet Service Provider (ISP), and all the content viewed by our members—before the Web was born—was experienced in a series of proprietary screens we called “forms.” As a company, it took a while for us to “get” the Web and understand the value of moving our content out of the AOL client and onto the open Web. The company’s main portal, AOL.com, had already been around for years (see FIGURE 7.1), more of a marketing site than a content portal.
This first-person perspective is provided by Kevin Lawver, a 12-year veteran of AOL’s Web development teams.
In 2005, Jon Miller, AOL’s then-CEO, started a project to change all of that. He wanted AOL to open up, to get all of our content onto the Web and outside of the traditional desktop client. The first step to this was to open up the company’s home page. As with most high-profile projects with a lot of executive involvement, the timeline was short, the list of requirements long, and the expectations high.
A small group of folks did the development work on AOL.com, integrated all the different Web services, wrote all the code, and worked with our internal experts in design, optimization, and accessibility to make it work in as many browsers as possible, as quickly as possible, and available to as many people as possible.
This chapter shares, directly and indirectly, some of the processes, techniques, and lessons they learned while building and maintaining one of the largest and most highly trafficked sites on the Web.
Launching a complete redesign of your company’s site, knowing that you’re facing dozens of integration points and an army of stakeholders, all under a tight deadline that the entire company knows about, is daunting. That AOL.com launched on time (or at all) was due more to the efforts of the team setting themselves up for success at the very beginning of the project than to any other factor.
The key to speeding things up during the process of defining the requirements and design for AOL.com was getting the developers involved in the process early. We’ll discuss what went wrong with the project, and how the development team compensated and handled those setbacks by “cheating ahead” and being flexible.
No project is perfect, and AOL.com had its fair share of problems from the start. The AOL.com redesign was the cornerstone of AOL’s move from being primarily a dial-up ISP, built around yearly client releases, to a Web company built around Web products supported by advertising and premium services. This was a bold move by the company’s CEO, Jon Miller. He wanted to make a statement to the company, AOL’s users, and the market that AOL was changing, and AOL.com was the main vehicle for that change. That kind of visibility to all parts of the company and to upper management meant that almost every product decision went through several layers of management in order to come back to the team as an actual requirement. This created “swirl,” which is deadly if you’re looking at a hard end date.
Another important part of this project, as with most large development efforts, was communication. Because of all the groups involved both in the requirements phase and in integration, there were copious opportunities for communication to break down, for things to get missed, and for unforeseen problems to cause major delays.
A third issue was dealing with a development process that didn’t fit the project and caused more problems than it solved.
To wrap up this section, we’re going to talk about attitude, and how to think of development as a craft. During the interviews conducted for this book, it became clear that a common thread ran through all them: These folks all treated their profession as a craft. We’ll define what it means to be a craftsperson and how that can help you deal with even the most problematic projects.
We’ll start by letting the main players introduce themselves and explain their roles on the team.
Let’s start with you, Michael—what do you do?
Michael Richman: I’m the technical lead and architect on AOL.com backend and front-end and client-side.
And for people reading the book who don’t know what an architect does...?
Michael: I help to shape the decisions on the best way to implement each of the requirements that come to us, balancing all of the stakeholders’ concerns. So, my goal is always to make every constituency happy. That includes product, project management, portal, the performance team, the accessibility team, the QA team, the development team, and ops. So, basically, in every step of the way I want to meet the requirements either perfectly or better than they envisioned it. I want to do it in a way that makes it easy to test.
I want to try to repass the requirements and anticipate what extra requests are going to come down the pike in the future to kind of get ready for those. So when we design the solution and design the implementation of a requirement or set of requirements, we want to do it in a way that’s flexible enough so when they inevitably come in with a different spin on it, we actually have already done that.
And then, also, we’ve learned over the past few years to keep in mind the accessibility and the performance teams’ requirements as well, which was definitely a learned behavior.
And Kevin, what about you?
Kevin Luman: I’m the technology manager for AOL.com, which always involves me being the first line of, I don’t want to say, defense...
If it is, it is.
Kevin: [laughs] Or point of contact, you could say, between all of these groups. It doesn’t mean they don’t go to Michael or any other individual contributor. But I see one of my main goals as trying to filter out as much as I can so that when they come to the team, at least the request comes with as much meat as possible, as well-formed as possible, so they can continue doing what it is that they love, which is writing software.
When I worked in Search, we used to call that the “umbrella.” Is that how you still see it?
Kevin: Yeah—my job is to keep the rain off.
Michael: I like to think of Kevin more as a momma bird...We have a dev team of tiny chicklets sitting in a nest squawking with their beaks open waiting for the manna to fall from heaven. Oh no, I’ve mixed my metaphors.
Kevin: I think it’s probably appropriate, especially in this place and this product where it really is a never-ending onslaught of just random requesters for a feature or just they want information. It could be other technologists looking for data.
Michael would never be able to do his job if he was having to do nothing but field these requests on top of all the other requests that really are related to a particular release we’re working on at that point in time...so I’m trying to do a lot of advance work too.
It’s not only protecting but sheltering the team from a lot of these requests. But it’s actually working to refine them, as well as trying to do some advance work.
We’ll continue the interview in the following sections to illustrate exactly how Kevin and Michael led the team through the different challenges they came upon (and continue to—the team is still together and still working on AOL.com, so a lot of these lessons are from more than just the one redesign we’re discussing in this chapter).
The number of stakeholders in AOL.com was daunting. Every decision was up for debate at several levels of management, from directors all the way up to the CEO of the company. This created a lot of uncertainty, misinformation, and a constantly moving target. This made it very difficult for design and development to move forward on anything other than the most preliminary of explorations.
How would you guys define swirl?
Kevin: For me, the experience is generally comes from a lack of defined leadership in that it creates a vacuum, and swirl is kind of an appropriate metaphor in that people just kind of move around and there’s no real goal or aim. They tend to debate and go to these meetings upon meetings on just something. And it’s somewhat aimless. I think an example right now that I’m working with is the Mexico and Puerto Rico portal. They want to start it but they’re not quite sure how. It’s not in the official channels even. It’s not on the Plan of Record [a list of priorities for a particular business unit within AOL].
And they’re asking me about the level of effort. Well, hey you guys, first let’s step back, because they’re starting to swirl. And if you let it continue on that path, the worst possible scenario is people actually start doing work on this thing that’s not quite defined. And who knows if it has executive sign-off to even launch if it got code ready.
I see two types of swirl: Vertical, which is where a product manager makes a decision, people start moving on it, their boss remakes the decision, it goes up, like hail where it starts as a raindrop but it keeps getting kicked up and down the management chain until it becomes this gigantic ball of ice and crushes your car.
And then there’s horizontal swirl, where it’s just peers, and you can’t decide on what the priorities are, and therefore you get into a stalemate and end up not accomplishing anything. I think AOL.com had both because everything had to go way up the management chain. And even when it went up all the way, it sometimes came down totally different.
Kevin: It comes down filtered or reinterpreted. I see a lot of it, and it looks like it arises from an offhand comment that an executive makes that is interpreted as a mandate.
Michael: I would only add that swirl is largely marked by a series of unproductive and circling meetings.
Kevin: And I would add, part of my job if I’m doing it correctly is that Michael’s not, and the rest of the team are not, in those meetings. Hopefully I’m successful, for the most part.
That leads right into my next question: How do you stop swirl and get someone to make a decision? And how do you make progress while it’s going on, because you still have a hard date at the end?
Kevin: The biggest thing is finding out what are the decisions to be made, and defining that. And from my experience, what we try to do is just tell them: “Stop. And step back. What are the goals you are after?” And then, if they don’t know, tell them: “Well then, why don’t you take a couple of days, write a PRD [Product Requirements Document] or an email, or document in some way what it is you’re after, and come back.”
Michael: The other aspects of it I think are effective are having a really strong facilitator on meetings, and a very strong position when you’re representing the dev team and saying: “We can do this, whatever you want to do once you define it, but here are the impacts.” And it’s one of the things that we do, if there’s swirl going on, we say: “We need to know by this date, or the date slips day for day.”
And that’s the kind of thing that’s really effective, because the dates are really important to upper management, usually. So as soon as you put it in very real terms and put your stake in the ground, you have to say: “Hey, you can’t do work until what you are supposed to do is clearly defined.”
So that’s one mistake. The other way around for the mitigated is to say: “You have until next Monday, or next month,” or whatever it is, give them a specific date, say: “This is when we need to know the final requirement, if we are to keep the schedule. If you don’t care about the schedule, then you can take as much time as you want, we’re not going to work on anything.”
Kevin: Generally, we say we’re going to continue proceeding upon the current path, or whatever path, but generally it’s current path, and like Michael was saying, at such and such point, it’s too late. Without impact. Like, this is the point we can’t absorb it anymore. Or, beyond this, if it’s not in their work too far in development, we’ll have to scapegoat.
As soon as requirements came up, Kevin and Michael started doing research. They did their best to uncover integration points and potential problems, and communicate those back to the team. The larger a project team is and the more groups it involves, the more important communication becomes. A good project manager is essential to getting the right information to the right people, but developers often lack communication skills or inclination to communicate problems and issues back to the team. It’s not a sign of weakness to have issues; it’s a fact of life in every development project. Being able to communicate effectively is a key skill that developers need to cultivate: communicating just the facts, without emotion, while explaining the likely consequences and possible solutions.
You’ve mentioned setting deadlines and measuring the impacts. How do you develop this skill of laying out those facts and communicating them up in a way that will drive people to do the right thing?
Michael: I think a lot of that has to do with our track record as a team. I mean, you can do that if have a strong position and a strong way of delivering it. We have a really good working relationship with Product and Project Management, and we have also a good history on delivering things on time, and have been fairly accurate on our estimates. So, maybe that’s somewhat of a credibility issue. But I think you can do it also if you are just confident in your delivery, frankly.
And it doesn’t have to be antagonistic. I’m not painting an adversarial picture, it’s more...collaborative.
What I’ve always tried to do is to be as transparent as possible. To build trust. So I figure, if they know everything I’m doing, there’s not that question of, “Well, is that padding, are they overestimating a feature because they don’t really want to do it?” Right?
Michael: Yeah, kind of like our reviews...
Kevin: ...in the standard document I do for LOEs (Level of Effort), right? Where it’s a very formal, tabular format; I repeat their product request. We go through it, we put the hours there, how many developers can work on it; and then all of our assumptions. So they see what we’re thinking, what we were thinking when we came up with this.
And I think that leads to that sort of transparency, credibility, and you build that. You know, you won’t have it at [first], but the more open and transparent you are with your internal processes, especially in dev, I think kind of nips in the bud any of those distrusts.
Right. You’ve both touched on it: Trust is key. And, you didn’t use these words, but “constructive” and “collaborative...” You don’t just say “Oh, this is a stupid idea.”
Kevin: Yeah, you say “Here are the issues that we have, technically, with this idea; and here’s what we’ve seen work with other products.” It usually comes up with regard to a feature that maybe, you know technically as a developer, is just crazy, as far as a request goes. But you don’t want to say: “Hey, that’s a crazy obscene request,” you know? Just tell them the facts: “That’s going to be weeks of development.”
But I always say, that’s only half. Because I’ve seen that happen before with other managers and leads, where it’s just shoot down, shoot down. And Michael is very good at this...you want to do it in a constructive way, and you can do that in telling them a cost. Because that’s really what they want to hear and what, more than anything you could say, will kind of hit them with the reality of it, is just the time it will take, and the cost.
But you don’t want to leave them hanging there, right, with their product up in the air?
Kevin: Right, you need to think about, can that feature, if tweaked another way, can they get half of what they want? Can they get 95% of what they want, if they’d just drop maybe one particular piece?
Michael: Right. Mostly you have think that the product-owners don’t really know where they benefit from the collaborative relationship with dev.
Kevin: It builds trust.
Michael: Yeah. The other thing—the only negative effect of being kind of reactionary to crazy requirements is that you don’t want a product to be gun-shy, and that’s what you get with that. You want them to think pie-in-the-sky, because for all you know, they’re going to think of a really neat feature that is actually easy to implement, whereas if you have this kind of knock-heads relationship where they’re somewhat timid about bringing requirements, or they perceive it as complicated or difficult to implement, they might just not bring it, and you definitely don’t want that.
Kevin: And that’s what I say: If it’s an us-versus-them, an adversarial relationship, and not a team...you’ve lost before you’ve started. If that’s how you’re coming in as a dev team approaching your product, whether you’re a contractor or internal—you’ve lost before you’ve started. It’s not that they’re your customer, it’s that they’re your peer, your equal, and we’re all trying to create this one product, and we all have come at it with a different aspect.
When the project started, AOL still operated in the “waterfall” method of development. Each group involved in a project did its bit pretty much in isolation:
Business owners created requirements and produced a Product Requirements Document (PRD).
Designers produced user interface and visual designs, and went through a lengthy review process through several layers of management, and then produced a Design Requirements Document (DRD).
Development didn’t usually start development until at least the PRD was complete and signed off on. Once the PRD was signed off, the development lead produced a Technical Requirements Document (TRD) and a System Design Document (SDD).
This model is great if you want to produce a lot of documentation, are working on huge projects with lots of integration, and have both a long development cycle and a known end date far in the future; and it was developed while AOL was producing client software that had maybe two releases a year. It’s not so great if you have to produce a final product very quickly, or for things that move quickly, like most Web applications. Most teams at AOL are switching to the more agile and collaborative Scrum model of development but AOL.com is a good example of a team working around a cumbersome process to get things done the right way, and to get them done more quickly than working within the usual system would have allowed.
During the requirements-gathering phase, while the PRD was still being created, Kevin Luman and Michael Richman would find requirements that felt very close to final and start working on them. This might be as small a thing as looking for services within the company that provide that feature, or building infrastructure to feed the user interface. That “cheating ahead” allowed them to make progress while the rest of the organization made up its collective mind, and get some time back for the inevitable last-minute changes and additional requirements.
David Artz and Kevin Lawver were involved in the design process from the beginning, weighing in on both potential performance problems and technical feasibility. They worked with designers and executives to lay out the pros and cons of each and give guidance where needed. Their success proves the point that it’s essential to have the developers get involved early on. We’ll talk more about this in detail in the next section.
So the big question—and I think the one that developers are most concerned with—is: How do you insert yourself into the process early on while still being collaborative and constructive and not coming off as intruding on the process?
Kevin: A lot of it, again, comes back to that trust factor in a team. If you have that trust, you are invited. And if you don’t, then I would reach out and tell them, “Hey, we are really interested in what is going on in design. Could we come to one of the meetings?” Just ask. Let them know, it’s not the whole team, but we would like to get some insight.
I think we are still using the waterfall and it has actually been pretty productive. The way we do it is that a lot of it is in parallel, just kind of staggered, like in a staggered, parallel well. Take the co-brands (advertising features on AOL.com): I have done a lot of work without even Michael there, working with them in the PRD and even like the DRD requirements and just sanity checks. Then bringing Michael in when it is a little more baked. That’s how I have seen what’s been going on.
Michael: I think that’s right. Interestingly, we are probably not as involved as the Scrum process has the whole team involved and everybody involved. But it hasn’t really presented too much of a problem for us.
Recently we actually had a Scrum-like brainstorming session for requirements and it was really productive. I think everybody thought so—product, QA, development, everybody. Several ideas from that made it into the next set of requirements.
So I don’t know that we as a team really know the full benefits of the more Scrum-like process because we haven’t done it so much. But, like I said, we haven’t really run into many problems with the process probably because we are a tight team. Maybe we don’t know what we are missing, what potentially great things could have come out of the last year and a half or two years if we had been doing that process. But to the extent that we have had the involvement, it has been working fine.
Kevin: But I wonder too, and having not done Scrum I don’t know. Like Michael mentioned, we could be missing out. The process right now—the sort of waterfall-ish process we use, the parallel waterfall, has been working well. We have been getting tons of releases out on time.
I don’t know if AOL.com as a product would lend itself to Scrum very well, given that a lot of it is date driven. From upper management and—sometimes not necessarily so much from upper management but because of contracts that are due. Especially with co-brands—you will get a contract that has to be done by this timeline. And they really need that projection, especially with sales, because marketing and sales sell ahead and they need to know, “OK, what are the new spots going to be? And when are they going to be delivered?”
Maybe Scrum can be worked in that. I don’t know.
It can. So to go back, it sounds like the “how” is you just have to build that trust relationship. You have to start by being open and transparent and putting your cards on the table first, before anyone else will.
Michael: Yeah, it’s funny how we keep going back to that—much more than I had anticipated.
That’s come up more and more for me recently. All development problems and everywhere that a project goes wrong is very rarely technology. It’s almost always people. And it all comes back to trust. If development doesn’t trust design and vice versa, then you don’t have that collaboration because collaboration is built on trust. If design thinks that we are going to use that against them or not implement what they deliver and we think that they are going to give us crap that is not implementable, well, that is exactly what you’re going to get.
It’s the same relationship on either side of the development. You’ve got product. If you don’t trust product you’re not going to believe that what they want is actually what they want. If QA doesn’t trust development, then their estimates are going to get blown up and you’re never going to launch anything on time.
Kevin: There is also something I know that we touched on with maybe some of the lower stakeholders. Like say, for us, it may be the accessibility team or the performance team. And especially in 2005 we were really good as far as us bringing them to the table. And I think that built a lot of trust too.
I want to go back to that in a minute. Michael mentioned it earlier about anticipating both consequences and people that we need to go and talk to. But just to finish the wrap-up on the getting involved—so, as the tech manager, you are involved really early.
Kevin: Yeah. I help manage swirl and help refine requirements, and then, when they are a little more solid, Michael comes in and he can poke and prod a bit but they are pretty well vetted.
Then the same thing happens with design. I get involved early on with sketches and then Michael comes in when things are little more baked. And I think being a developer has helped tremendously.
So if you weren’t a developer before you were a manager, would you have Michael involved earlier in the process?
Kevin: Yeah, I would have to bring him in a lot earlier on. I don’t know how much of that kind of parallel stuff we could do if that were the case, though, because Michael would be stretched too thin.
That’s true. You would need another.
Michael: You would almost need, like, tag team leads, so that one person could be leading the current development cycle while the next lead is working on the design and brainstorming stages.
Kevin: And I don’t know if I am writing myself out of a job. [laughter] But I am kind of doing that, and cultivating that, for other reasons, like bringing Jason up as another type lead.
From an advantage perspective, I want him to grow. I want all the members of my team to grow for their own careers’ sake. I am self-interested, of course. I’m looking out for the company. I also want redundancies. But that also helps with, in this perspective, if I weren’t able to technically evaluate things on my own, I could have Jason lead.
Well, it almost doubles your capacity at that point. You can be involved in two projects extremely early on and then bring them in and you don’t really mess up a current development cycle, you can just do more because you have more resources.
Now I want to go back. I think it is really important to be able to anticipate problem spots. This is going to be really hard to answer. It’s a skill. I think anyone can do it. It’s just a skill. So how do you develop that skill? Is it just experience, or are there other things that you can do?
Kevin: Like share tips.
Michael: And like the skill of anticipating the future requests and having that influence how you implement current requests.
Yes, all of that. I’ve called it “cheating ahead”—Mark Robinson’s term—where you can see a requirement and you know the kernel of it. You can distill and synthesize it quickly and turn it into something that you can do before maybe it’s absolutely final. I think you’ve both mentioned that. How do you do that? How do you learn to boil those down?
Kevin: One of the things I do—and I did actually even in the very first beta—was early prototyping. And I know there’s other people on the team. Michael has done that as well. Even just now. Right? With the “draggable” make-this-my-home-page kind of thing.
So, we do a lot of that. A request will come in. I worked on prototypes for AIM, supertab, video. Those are ones that we knew, even before the DRD was complete, getting that done so you can scope it when you do your LOEs. You’ll be able to anticipate some of how it would work and feed that back to the product people with advice on how you think it should probably work, technically as well as program-full.
I think that helps a lot, especially with some of the more meaty problems that are going to be hard to LOE. Some of these easier ones we’ve got down and any experienced developer knows. Some little piece-of-the-page widget with 10 links is going to take them a number of hours.
But some advanced AIM supertab, integrating in a new API you’ve never really looked at, it’s going to be a complete SWAG unless you’ve done prototyping beforehand.
Michael: In terms of implementing requirements, implementing features in such a way that leaves the door somewhat open for future aspects of them, one of the things that that makes me think of is the whole...Two different ends of the spectrum are the person who has developed the skill to do that really well, and I don’t know if you want to use the AOL.com team as an example of that or not, I don’t know. We do it pretty well.
So compare that to the other end of the spectrum. I always think of, like, the outsourcing teams, right? Not to bash India, but the biggest problem that I’ve had working with developers in India is usually that they need letter-by-letter instruction on how to implement things, and they don’t stray from it.
And they need letter-by-letter instructions on the details, like implementation details, which is really what you’re talking about. We’re talking about how you implement something, which decisions you make to lead you down one path versus another.
Like, Path A will be a very limiting path for the future but will still fulfill the requirements. Whereas Path B will fill the requirements and leave you open.
Kevin: One example that came to mind that you always do and the team does well, is published parts on the page. Take for example that link-list module. The list of links. They’ll say, “OK, we just want the links. And we want six.” So, [our response is] usually, “They want six. Let’s put 10.” For when that one more or two more come in, as well as, “Let’s make the title publishable.”
Because, yeah, even when they say they want it to be the “happy, fun module,” tomorrow it might be the “extremely happy, fun module.”
Michael: Yeah. That captures the whole mantra that we have that nothing is hard-coded. We hard-code nothing. If we can, we make the configuration publishable. We make everything tweakable and publishable through a tool.
My goal, as I always state it, is to write myself out of the process. That’s always been my goal. And maybe it comes from the fact that the best developers are the laziest developers. Right? In a way. Because I want to do the least amount of work in the future.
So, the better I write the thing today, the less I have to do later. And when the requests come down the pike for things, I can say that’s publishable, and everybody’s happy. So, definitely, the “hard-code nothing” mantra is a big one.
Kevin: There’s a danger here, though, and I’ve seen it: over-engineering.
Michael: Sure, yeah. There’s definitely the balance. You definitely have to keep the balance.
So, is that purely experience? To develop...what’s that line?
Michael: I think in a way that it’s a continuum of experience and intuition. And if you don’t have the intuition, you need more experience to make up for it.
Probably, some people can come out of their development training and start on day one, and since they’re a very intuitive person on this level, they can make guesses as to how to do things. But if you don’t have that, you need to use the past experience to build that up.
So, a lot of it just is having the experience to develop that intuition and say, “I’ve seen this before...”
Michael: Yes, exactly.
“...And this is what worked last time and this is what didn’t.” I think the other part is creativity. I find this in hard-core computer science guys who come out of college with a master’s in computer science, where everything is a [xx]. It’s all the same solution, it doesn’t matter what the problem was.
Where if you have some creativity, you can find a different solution that may be more...And part of that is knowing when to shut the creativity off, too.
Michael: Yeah. There is definitely the art aspect of it. I mean, that’s why it’s hard. It’s not like you can apply a formula to it and make it work. I just keep coming back to the whole outsourcing thing, when you have a cultural difference between the majority of the developers that we run into from India, who really do need that lock-step set of instructions.
And there isn’t necessarily that learned behavior from the last project to the next project. It’s like, you finish one project—and this is not just India, this is anybody—there are some people who...A project is very discrete. You have your requirements, you do your requirements, you’re done with that project, and you forget it.
And you go on to the next project. And you have those requirements and there is no relationship between those requirements and the ones in the last project. Even though those are two completely different projects, you have to bring...
I think, in order to achieve this kind of creativity, intuition, and learned behavior thing, you have to bring forward everything you learned from the last project—what went wrong and what went right, and what they wanted after it was done, to say how should I have done that—to every future project.
It’s the way you can keep honing the skill and the direction.
There’s as much art to Web development as there is science. In several discussions about Web development, it’s come up that the best developers consider what they do a craft to be honed instead of just a job. Some attributes of a craftsperson are
passion
dedication
curiosity
creativity
intuition
problem-solving
All are skills that can be developed, even if you don’t have an innate talent for them. When you start thinking of your code as art, something should fundamentally change in how you do your job. Code is created to get something from one point to another. Art creates pleasure. When you get true pleasure from creating artful code, you’ve successfully joined the guild of Web craftspeople. The skills learned along the way help make even the most troublesome projects easier to manage, and are all you need to find at least something in each one to get excited about.
Hopefully, you became a developer because you’re passionate about the Web and building things on the Web (sites, applications, widgets, Web services, or whatever). Sometimes, that passion wanes, or moves, and that’s OK. But, if you’re passionate, you’re more likely to explore and spend your time looking for the most elegant, simplest solution possible to every problem. As you develop your problem-solving skills, you move beyond solving problems just in code, and start thinking about and solving problems for the entire project, even if it’s not in your discipline or your responsibility. The willingness to look outside of your own domain is a good indication that you’ve crossed the line from “assembly-line worker” to craftsperson.
A large part of problem-solving is the ability to take previous experience and apply it to current problems. Being able to think about past problems and see how they apply to the current problem is a key skill. Craftspeople rarely make the same mistake twice, and develop the intuition necessary to know which direction to head. Part of applying past experience is introspection and being honest about assessing how well you’ve accomplished something. Without that, you won’t be able to apply those lessons to future problems, because you won’t have understood what exactly you learned from a problem.
There is a challenge here for managers to give their people opportunities for development, and empower them to develop the skills of a craftsperson. It helps a great deal if management encourages developers to feel ownership over their small piece of the project. They may be given a fairly limited task but they should be given the freedom to solve that problem in their own way. Depending on the experience level of the developer, there may need to be some more mentoring or validation of code, but giving developers freedom to explore possibilities and choose the best one for themselves can help them develop that sense of ownership. Also, the more developers know about where their tasks fit into the big picture, the more likely they are to feel like what they’re doing matters and the more likely they are to develop that sense of ownership.
Part of my discussion with Michael Richman and Kevin Luman centered around coming up with a definition of craftsman and how they develop passion, ownership, and empowerment in developers on their team.
Kevin: I guess it’s the difference between thinking of yourself, too, as a craftsman or an assembly-line worker. If you’re a craftsman and you really care and you’re really into what you’re doing and the products you create and your output, I think that sort of mind-set leads more towards wanting to explore other avenues and different levels, or different ways of approaching problems. And introspection and reflection on what things worked and what things didn’t.
Michael: Developers are problems-solvers, right? The more line-worker developers are problem-solvers only on the code level, but the more expansive, craftsman developers are problem-solvers for all aspects of the project, and that’s where you get the people aspect.
So, anticipating future requests and future needs is about problem-solving for your customers. And you have to think about all possible customers, product QA, ops, performance, accessibility, the users, the publishers, and the dev team.
You’ve got to think of everybody and try to solve everybody’s problems. That also may mean trying to think of what the problems are around that project for each of those groups.
But the craftsman ideal isn’t just a skill, it’s an ethic. How does that assembly-line developer become a craftsman and treat his or her work as not a science but an art?
Kevin: Part of it, they have to be empowered to be able to do so. And treated like a craftsman and not an assembly-line worker. And that’s where you are more of a team, and you feel a vested interest in a product. I think that helps, certainly.
I think we’ve probably seen that in Big Bowl (a publishing system used on a lot of AOL content channels). You can do the opposite, where you take craftsmen and turn them into assembly-line workers.
By removing any creativity?
Kevin: Yeah. You take a person and you say, “Today you’re going to work on pets. And you’re going to get this feature in. Here it is, the requirements.” I’m tech manager and I’m just doling out requirements that have come in this pipeline. Like, never-ending feature requests or enhancements. And I’m responsible for this N number of channels, and my team, I just plug in different developers into different requests.
And there’s no care or concern. Code needs to be nurtured too. I mean, it’s living, especially if you have multiple developers working in that code. At some point, it’ll become unmanageable.
If people aren’t stopping and saying, “It’s time for a re-factor,” they’ll just keep cutting and pasting the same stuff over and over again, or repeating the same errors over and over again.
Or, even worse, they have a myopic view of the product itself, and the code base. And they don’t see what impact their changes may have.
That small set of requirements is sort of the product as a whole.
Kevin: Yes, the only person they’re trying to please is their manager, the tech manager. And that’s it, because they are an assembly-line worker. And there’s the manager. You clock in, you clock out, you just do what you’re told to do. You could be replaced easily by a WYSIWYG editor.
Michael, what’s your definition of a craftsman?
Michael: This is a hard question. I try to think about the people on the dev team that I work with, who I’ve seen evolve into more craftsmen-like developers. And I’m asking myself, “Why? Did I have any influence on that?” Possibly. And if so, how?
What I think of is, it’s just that I try to communicate in every meeting the process of thinking about something that leads me to suggest the way that they do it. I don’t just say, “Do it this way.” We have a conversation about, “This is something that I want to make publishable and here’s why. Why don’t you do it this way, because it’ll leave the door open in the future for this request that’s going to come down the pike.”
For me, it’s about trying to solve everybody’s problems with the particular implementation. That’s not really a definition of a craftsman but it’s the way I think about it from a coding point of view.
I haven’t mentioned this, but I definitely engage it and feel it: I love coding. And I love coming up with the creative and elegant and simplest solution to the problem, in code, that does all of these things for everybody. This is starting to sound super-geeky, but I really do love opening up VI and getting the code.
In fact, that’s one of the first things I do when “architecting.” I do think about it, but documentation for architecture doesn’t work for me. I actually code to architect.
Michael: Yeah.
Kevin: I think one of the key defining factors for a craftsman is passion. If you don’t have a passion for what you’re doing, it’s going to reflect in your code. And everything you do. It’s going to reflect in your interactions with the people you work with, your customers, QA, Ops, whoever it might be.
It’ll permeate throughout, and it will be reflected throughout. So, a passion for what you’re doing is one of the must-haves of a craftsman. I don’t know if it’s the whole definition of a craftsman, but it’s definitely a requirement for becoming a craftsman.
And I don’t think people necessarily come with a passion. There’s some people who get in the field with passion, some people get into it because they think it’s a high-paying job—and, hey, that’s fine—it doesn’t mean that they can’t be passionate or become passionate.
And the organization can help in that respect. Or it can hurt, as we’ve seen. It can take that passion away, just as easily.
How do you figure out what that passion is, and how to take assembly-line workers—or people who may have at one time had that spark—and reignite it? Because you’re right, being a craftman is all about being passionate about what you do, whatever it is. And when you have that passion, you want to get better at it.
Kevin: And please the people, the stakeholders involved.
That’s the difference between creating code and creating art. Code is to get something from Point A to Point B, and art is to create pleasure in something, whatever it is. So, I think we have a definition. It’s passion—that’s all good. But how do you ignite it? Michael mentioned empowerment.
Michael: Yeah, Kevin mentioned empowerment too. But I was going to echo it, because I think that’s one of the key ways. If you let someone get in on the ground floor and have some kind of stake in the thing they’re going to be developing, then they’ll definitely care about it more.
As opposed to just kind of doling out the requirement at the end of the line, saying, “You’re the last cog in the widget.” That’s wrong...“The last cog in the line to spit out the widget.” [laughs]
I think that’s definitely one way of doing it, giving people a voice in the whole process.
Kevin: And to be honest with AOL.com, in the “what you see” we really don’t have a lot of say or empowerment.
So, it’s really finding the spot where you can empower people within the process.
Kevin: Exactly. That’s what I said. But it doesn’t mean that you’re powerless. So, what are the spots where you can effect change? For instance, we’re proud of what we’ve done in maintainability of code, in performance, and in accessibility. Because those are the things we can instill and we can succeed in, regardless of the feature.
So, part of empowerment is ownership. How do you make people feel that they own their piece of it? Is it freedom to fail, freedom to experiment? What is it? How do you do it?
Michael: How do we do that, Kevin? [laughter] I’m not sure we do do that. Do people feel like they do have ownership over their pieces? I think some people do and some people don’t on our particular team.
And in a way, that’s like the people who do are the ones who choose to. And the people who don’t, choose not to. Now, are we asking how do we “make” or encourage the people who don’t feel the ownership to feel it? I don’t know. I mean, there’s a certain limit. Some people just don’t want it.
Right. And I don’t think we’re saying there’s not a place for the assembly-line worker.
Michael: I guess it comes down to the style in which you manage and lead the team. Because if you leave it open and leave it as a...
Kevin: I don’t micro-manage.
Michael: Right. There’s no micro-management and there’s no dictation of how things should go.
Kevin: Michael! I don’t micro-manage! Repeat after me! “Kevin Luman does not micro-manage.” [laughter]
Michael: Right. And I don’t micro-architect.
Kevin: Yep, it’s true. Even when you’re telling people, in the end, that you’re right. Everyone gets assigned a task to do but it keeps going down. They still have freedom within that to be creative.
I try and psych people up: “Hey, this is a really good, meaty problem.” Like, it’s going to be interesting. Here are some of the problems and it’s going to be interesting finding how we do this in an elegant, maintainable way.
And as a manager, I at least try to spark that. “OK, do they think it’s cool?” Can you at least drive that?”
And if they don’t, you give them a carrot for the next one... You say, we just have to get this done, the next thing will be...
Kevin: I have to do that too. If there’s some people who don’t want...Like, take the CSS, like some of the Web developer or Web technologist types, now engineers, who have had to take on the ownership of a lot of the CSS.
One of the things I’ve tried to do with the team is make sure all the engineers write their own CSS. But we still have our gurus, who shoulder bigger burdens of it. And it’s like, some releases there’s a lot more of it; others, less. But I still try to give everyone on the team something challenging and interesting when I can.
And if things are crunched, we might, of course, have to move it off to someone else.
So, you guys let your developers give their own estimates, right? Do you guys LOE everything?
Michael: Yes, and it works. I think we’re pretty cognizant of when we’re utterly insane. We try to keep in mind how long it will take a particular person to accomplish something.
Kevin: We definitely give the LOE with that in mind. As a manager, I have to be thinking, what’s the acceptable max? And part of doing that would be knowing that if it gets to a certain limit, someone—like maybe a Michael—will have to lead, to step in and help out. But you also hope that’s part of the training.
You set them up for success.
Kevin: Yeah. And learning, and growth.
Which is great, because that encourages the craftsman development. “I’m not a hired gun to just do this one thing. I can branch out. And now I know, even if I don’t necessarily like this and I’m not passionate about that kind of development or whatever, I’ve got the experience and I can speak the language.” So that’s a really good thing.
Kevin: And they own more of the project.
Right. And you get more coverage. So, if somebody gets hit by a bus, you’ve got backup. [laughter]
Kevin: Which goes both ways. It’s not just on the harder stuff. It’s also why I want—and I’ve tried to push—all the engineers to be doing the CSS. It’s something they should know as well. For a throughput, as well. And I think it is growth, if they like it or not. I think, as a developer, if you’re in this, you should know that.
Right. Definitely. So, anything we missed? Anything else you guys want to share?
Kevin: A wrong turn for me—they’re not major ones, but minor ones that I constantly try to catch myself on—is not communicating enough. Forgetting to make sure, oh, yeah, I should have put QA on that mail, got them involved earlier on this.
Or even right now when I’m doing prototyping, make sure to cc: Michael (lead software design engineer) or Jason (senior software engineer), so they’re up to speed, as much as they want to be. If they’re really busy, Michael and I kind of do this, have this agreement: If I see him and he knows, it’s not a priority, I’m not looking for a response, it’s informational only. If he’s really busy, he won’t look at it. If he’s not, he has time.
This has highlighted that your relationship is as important as almost any of the other parts to the success of anything you do. If you don’t have a good relationship with whoever’s in charge of managing or requirements and resourcing, you’re sunk.
Michael: Yep.
Kevin: Yeah, relationships are crucial.
Well, it goes back to the communication in the end. The reaching out early and knowing who to pull in, and when, is essential.
Kevin: And that helps to build the trust.
Right. When you don’t surprise people at the last minute with stuff, that really helps. Because they’re more likely to cut you some slack the next time that there is an emergency.
Kevin: Well, and there’s a give and take that goes back to what Michael was saying. There’s this balance with everything you have to weigh. And if accessibility digs in their heels, they could make life really tough for us.
But if they trust us, and when we say, “Hey, this is going to be really tough. Can we go this step and work on addressing that feature release?” a lot of times they say, “Yeah.” Because they trust us, that we’re not just going to keep punting it off down the road. Then you’ve got to follow up and do what you’ve promised.
This comes up a lot. So you don’t say “No,” you say, “We can’t do it now. And here’s why. But we can do it here. Is that OK?” And nine times out of 10 they’ll say it’s fine. Because you have to make sure that you tell them, “Well, if we stop everything we’re doing, and do this one thing that you want, it’s going to cost you. If we wait, you get it just a little bit later than that. But you still get everything you asked for.”
Kevin: Again, teams want to succeed. Teams want to win. And if everyone’s on the team, they’re focused on that goal of winning, more so than their own particular fiefdom or agenda.
Hopefully, you can see throughout the interview that Kevin and Michael have a great relationship, and that helps them a great deal in dealing with the stress of the day-to-day challenges of working on AOL.com.
The design goal for AOL.com was to create something that looked and felt like AOL, but was cutting-edge and differentiated the site from its competitors. To that end, before there were even any specific requirements set down for this project, and just to get an idea of what the product team was looking for, the design team came up with several dozen initial concepts for the look and feel of the site—extremely creative and beautiful designs. Unfortunately, most of them contained several elements that just couldn’t be implemented in modern Web browsers, or would cause major performance problems.
And therein lay the rub: performance. The site needed to load and be usable over a dial-up connection in less than 10 seconds. This meant that everyone involved had to compromise: Designers had to let go of some visual flair, and development had to come up with some new ways of doing things.
Fortunately for AOL.com, they were able to do all of that. Development was involved from the very beginning of the design process, and worked with the designers to make sure that what was designed could be faithfully created in “real life.”
David Artz and I were involved very early on in the process, brought in to comment on how things could be implemented and to find performance problems in the designs. We worked with the designers on each revision, providing comments, suggestions, and, in some cases, prototypes to show how each design element impacted performance. This meant a lot of revisions from the designers until we got to the final design for the product.
Design Is A Team Effort
For many projects, design happens in a vacuum, without feedback or input from development. This leads to unreasonable requirements, broken expectations, and missed deadlines. There’s absolutely no reason for this to happen if design and development work together from the start.
David and I wanted to see if we could estimate the page size before we started development, and came up with a couple methods for doing so that ended up working quite well.
Before we get into that, we need to take a step back and talk a little bit about tools. I love tools, and have built several over the years to help me determine how well I was doing my job (building Web pages). One of these was a script that ripped pages apart and told me what percentage of the document was markup. This became a personal guidepost for how well I was marking things up. The percentage goal was based on how complex the design was, of course, but I tried to keep my documents to less than 50% markup. Unfortunately, the more complex the design and data, the more markup you need to represent that data. A complex data table is going to have far more markup than a blog, for example.
My original script was a page built for AOL’s server, and no longer exists. But I’ve recreated the basic methodology here as a JavaScript bookmarklet (remove all the line breaks if you actually want to use it):
javascript:
function recurseNodes(node) {
var total = 0, kids=node.childNodes, n=kids.length, i=0;
for (i=0;i<n;i++) {
t = kids[i];
if (t.nodeType == 3) {
total+=t.nodeValue.length;
} else if (t.childNodes.length > 0) {
total+=recurseNodes(t);
}
}
return total;
}
function pageSize() {
var d=document;
var h=document.getElementsByTagName("html")[0];
var text=recurseNodes(h);
var markup = h.innerHTML.length;
var p = (text/markup)*100;
var m=h.innerHTML;alert("Text: "+text+", HTML: "+markup+", text
percentage of whole: "+p+"%");
}
pageSize();If you create a bookmark in your browser with that code in it (again, with line breaks removed), you can click that bookmark on any page, and it will throw an alert with the size of the “text” content of the page, the size of the markup, and the percentage of the whole document that’s textual content. It’s not perfect, but it’s a fun, quick test to see if you’re meeting your goal.
TABLE 7.1 shows the results from some popular commercial sites.
Table 7.1. Amount of Text Content on Selected Popular Sites
Web Site | Amount of Text (in bytes) | Total Content (in bytes) | Text % of total content |
|---|---|---|---|
Amazon.com | 37,322 | 141,481 | 26.4% |
AOL.com | 13,808 | 62,233 | 22.2% |
CNN.com | 20,281 | 117,459 | 17.3% |
eBay.com | 28,427 | 70,772 | 40.2% |
Google.com | 1,385 | 5,136 | 27% |
MSN.com | 7,482 | 43,335 | 17.3% |
MySpace.com | 12,435 | 47,178 | 26.6% |
Yahoo.com | 85,176 | 115,704 | 73.6% |
Steve Chipman has also written a bookmarklet called “Page Info” that does that, and more. You can find it at his Web site: http://slayeroffice.com/?c=/content/tools/pagenfo.html.
David and I did a quick spin around the Web looking for comparable portals and did some checks to see how they were doing with their markup and what percentage of the whole it was. From that unscientific assessment, we concluded that if we could hit 1:5 ratio of text to markup (that’s 20%), we’d be OK.
It all starts with content. Early on, our design team produced wireframes with example content provided by the editorial group. We took those, copied all the text out into a blank text file, got the size of it, and then multiplied it by five to get what we thought the markup size would be. That gave us our initial load time estimate. We knew that we couldn’t be any faster than that initial number.
Once we left the markup, we had to start guessing about images, CSS, and JavaScript. There were some scripts we knew we had to include for reporting and advertising, but we also knew that we’d need a certain amount of JavaScript for actual functionality. We assumed that the site would have about half as much JavaScript as it had markup, and the CSS would be about one-third the size of the markup. These were just guesses. We ignored most of the art (because we assumed it would be pulled in through CSS after the page had loaded) except the photos. We found photos that were roughly the same dimensions, optimized them, and then added their size to the total.
Once we had all those numbers, we could come up with an estimate for how large the page would be once it was built, based solely on the design mockup. We did this for each of the designs, presented them to the designers and product owners, and made our suggestions.
Having numbers is always good—even if they’re only for comparison—and they helped us back up our opinions about each feature’s piece of the overall performance picture.
To illustrate, here’s an example “worksheet” for figuring it out:
Enter the number of characters in the document: ________
Markup size = line 1 × 5: ________
List known required JavaScript and CSS files and their sizes: ________
Application JavaScript = line 2 × .5: ________
Application CSS = line 2 × .33: ________
Combined size of photos: ________
Just fill in the data as you get it, and you can get a pretty good estimate of how long it’s going to take for a user to load your page.
If you take just line 2, that’s the number of bytes users have to download if they have all the other content in their cache. This is a user who comes back using the same browser and either just reloads the page or comes back the next day.
If you take the numbers from the lines 2 through 5, you have the number of bytes that the user without any of your content in their cache has to download in order to get to “first render” (when content is first displayed in the browser), as long as all your JavaScript files are in the <head> of the document.
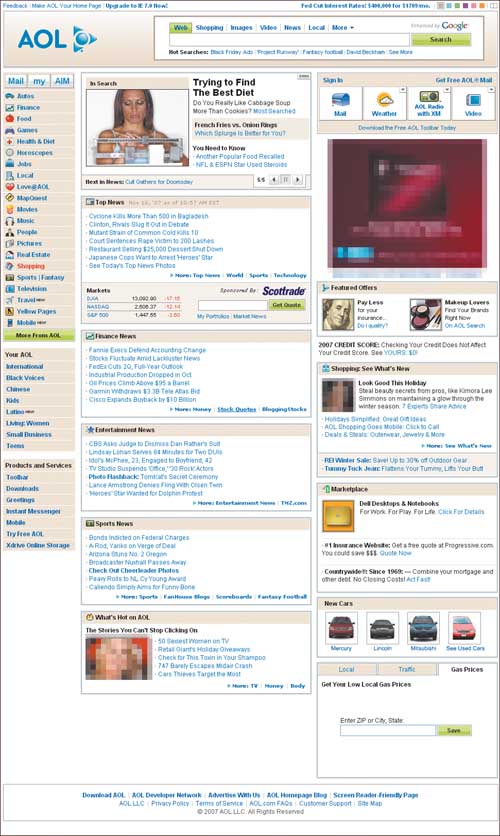
There are several things to keep in mind when dealing with performance. There are many compromises to be made between the different pieces of content on the page, and many things that can be done to make sure the most important content on your page shows up first while the rest of the page loads. The first step is to determine which sections of the page are the most important. Usually, they’re near the top left corner of the page. Let’s look at AOL.com as shown in FIGURE 7.2:

The first thing you see is the AOL logo, and then the search box. The next section is the “dynamic lead” that rotates through five different editorial mini-pages. To the right of that is a small toolbox with the six most popular activities on AOL. Then, you see the first ad. All of these things are “above the fold,” meaning that 90% of the audience will be able to see them without needing to scroll.
When you bring up AOL.com in a browser over a slow connection, you get usable content fairly quickly—as quickly as your browser can download the HTML and initial CSS and JavaScript. As shown in FIGURE 7.3, everything else loads as it comes in, but the page is usable as soon as that initial chunk of content comes in.
The user isn’t waiting for an ad to render or any onload events to fire in order to use the page. Everything is functional as soon as the first render happens.
Getting to this stage isn’t easy. It means a lot of work up front to make sure that all of that important content is actually in the document, and sometimes breaking some principles of “progressive enhancement.” It all depends on the goals of your site. If you’re a portal and you want to drive people to your content, and allow them to get to what they want to do quickly, maybe this is the right approach for you.
All content on AOL.com is delivered compressed. Take a look at total amount of data that is ultimately delivered:
44 kilobytes of HTML
62 kilobytes of JavaScript
40 kilobytes of CSS
However, when it’s compressed, you’ll see that it’s actually only
12 kilobytes of markup
24 kilobytes of JavaScript
9 kilobytes of CSS.
That means the browser will render the content a lot faster, because it spends less time waiting for content to download.
Compression is great for text content. As you can see, you can greatly reduce the size of markup, JavaScript, and CSS. The same can’t be said for compressing images or other binary files; you’ll get some benefit there but the big win is for text.
Note
Please see Appendix C for more information on compression.
Let’s go through how AOL.com has maximized performance by looking at what has to download in order for the most important content on the page to be usable before all of the art has downloaded and before the onload event has fired. We’ll walk through the pieces of content downloaded and when things happen in the browser. FIGURE 7.4 illustrates the process outlined below.
Markup is downloaded, decompressed, and turned into a DOM.
JavaScript and CSS files in the
<head>of the document are downloaded, decompressed, and parsed.The browser starts rendering, stopping as it hits
<script>elements in the document to either run or download scripts. The first script outside the<head>the browser finds on AOL.com is for reporting; it shows up right after the<body>tag, so no content is rendered until that file is downloaded, parsed, and run.The browser renders the header, which contains the logo and the search box.
It encounters another script element. This one puts focus on the search box, so users can search right away without needing to click in the field first.
Minor scripts write out the Sign In/Sign Out links.
The Dynamic Lead is loaded—first all the markup, and then the three script elements that start the rotation.
The rest of the content in the left column is loaded.
The right column starts rendering. The “Communication Center” renders first, followed by a script that sets a class on the dropdown arrows next to “Money,” “Music,” “My AOL,” and “Video.”
Several placeholders for advertising render, but not until after all the content on the page is displayed. (We’ll talk more about this later.)
The rest of the right column renders.
The footer renders.
The scripts that call the ads are run. Once the ads render, they’re moved into the correct spots in the right column.
Among those familiar with progressive enhancement, that list may raise an eyebrow or two. That’s fine, because AOL.com is also accessible—since all the important content is on the page, screen readers easily handle it. All of the JavaScript has accessible alternatives. We’ll talk more about accessibility later on.
AOL.com is a site that people come back to—to check mail, read the news, hear the latest albums, or get stock quotes. To improve their experience with the site, files are cached, meaning users don’t have to download the files every time they request the page. Now, because the content of the page changes so frequently, the HTML is never cached. But all JavaScript, CSS, and images are cached, for variable amounts of time. For example
HTML: never cached
Images: 24 hours
JavaScript: 30 days
CSS: 30 days
This is great, because as long as someone uses the same browser and doesn’t empty his cache, he’ll never need to go back to the server to download those files—greatly reducing the amount of time it takes to load the page.
All of this caching introduces a problem: What if you need to make a change to the CSS or JavaScript? There’s a chance that users won’t see that change for a month. AOL.com solves this by versioning all JavaScript and CSS files in the URL. If you look at the page, you’ll see a URL that looks like this:
http://www.aolcdn.com/_media/aolp_v21/main.css
The “v21” piece is the version. There’s a configuration option to tell what version the page should load. This gets around the caching problem easily; since it’s a brand new file, all users should see the changes as soon as the file’s published.
One last tip on reducing load time: Reduce the number of files you make the browser download. Your overall file size might be OK, but if that’s split up over a couple hundred files, your page will feel a lot slower than it should. There are several reasons for this:
In Internet Explorer, only two files at a time will be downloaded from any one domain.
Every file you download has anywhere from one-half to several kilobytes of HTTP headers that come along with it. This can greatly increase the total amount of data users have to download to see your page. HTTP headers aren’t compressed, so there’s very little you can do to reduce this size.
All the JavaScript and CSS files you put in the
<head>of your document must be downloaded before the browser will try to render the page. Since all CSS, link, and style elements have to be specified in the<head>anyway, it should all be one file.JavaScript “blocks” page rendering (meaning the browser won’t display any content below that
<script>tag until the script is done downloading and running), even when the scripts are pulled in inside the body of a document. This means that the browser will stop rendering when it gets to a<script>element and wait for that to download or execute before continuing.
Performance is an ongoing process. Especially for legacy projects, you’ll want to start small and make incremental improvements. If you’re starting with a clean slate, you’ll want to do as much as you can up front to make sure your page is as fast as possible. Just because more users are on high-speed connections doesn’t mean they’re getting more patient. If anything, they’re less patient—expecting everything to load instantly. The closer you can get to “instant,” the more satisfied users will be with your site.
David Artz leads AOL’s Optimization team, which looks at AOL products and provides feedback on how to make them faster, in addition to tools for measuring a site’s performance. He did a lot of work with the AOL.com team to make sure the page loaded as quickly as possible.
What’s your role at AOL?
AOL’s Optimization team is focused on improving the speed and accessibility of AOL’s Web sites. We do this by providing clear, measurable standards in Web site optimization and by documenting and evangelizing best practices and solutions in achieving a more “optimized” experience. We also consult and provide real-time feedback and analysis on high priority products such as AOL.com throughout the entire design process.
What’s the difference between “perceived” and “real” performance?
When you start digging into performance, you quickly realize there’s a blurry line when it comes to deciding when a page is “loaded.” Do you count the stuff loading below the fold? What about objects and scripts engineered to load last?
Perceived performance is the user’s perception of the speed of the page, and when it’s ready enough for them to start using. Though this can vary for different users, I generally say it’s when all graphics, text, and essential functionality above the fold (browser window without scrolling) is ready to use.
Real performance is much easier to measure, which is typically why it serves as our benchmark when managing performance-improvement efforts. It’s when all objects on a page are loaded in, no matter where they load in the document or if the user even needs them.
Our team places much emphasis on perceived performance, and uses techniques such as moving scripts from the
<head>element to the bottom of the body, system text and CSS for design elements, load status messages, strategically ordering HTML content, and loading content only when the user scrolls to see it.What tools do you use?
We use HTTPWatch and a homegrown tool lovingly named “PAT” (Performance Analysis Tool) that generates charts and reports based on data from HTTPWatch. PAT will parse HTTPWatch’s logs, and give us the opportunity to classify objects as advertisements, code, graphics, etc., so we have a good idea of where our KB and requests are going, and then estimate load time based on that data for various connection speeds.
We also have a tool that is a hit with our execs called Webometer, which quickly loads a site and its competitors in a Web browser, giving instant data on comparative performance.
What should developers do first when judging a design for performance?
If you want to truly estimate, you have to imagine the outcome of the resulting build, which may be tough on new projects or if you’re new to Web development. Also, a more experienced developer (especially one who’s been through my training) will have an arsenal of tools that can make any design perform well.
This could be a chapter in itself, but the steps I would follow are
Get a spreadsheet; you’ll want to tally up K size and number of objects.
Based on the amount of text and the complexity of the layout, calculate how big the CSS and HTML will be (this is one of those experience-dependent ones).
Look at the design and think through how many and how heavy the graphics and photos will be when sliced.
Estimate the client-side JavaScript file size you will need—this can get big if you need to use shared libraries.
Tally up the results, and divide total KB by the speed you’re targeting (DSL = 768 kilobits = 96 kilobytes per second).
Account for object requests by multiplying by 40ms per object for JavaScript and 20ms for CSS and images.
In general, all a developer can do is push for lighter design and less functionality, and think where we can be clever by moving requests later in the page.
How do you keep track of performance over time?
On the Operations side of the AOL house, we have automated tests that run over the week, which we use as a pulse on our top sites and their competitors. Our goal at AOL is to be faster than the competition, and be optimized for performance using the latest techniques regardless.
There are concrete steps you can take during the design process to make sure your site will perform when you’re done with development. We talked about them fairly quickly, so here’s a quick list of things to make sure you do whenever you start the design process:
Involve development early.
Use available tools to get the numbers from competitors or comparable sites.
Use those numbers to set performance goals for your project.
Scrutinize each revision of the design for potential performance pitfalls.
Measure and get numbers—the more “real” you can make those numbers, the better.
Think about performance up front. The more work you can do during the design phase, the better you’ll be in the long run.
Performance is a process. The last point in the list above is really important, so I’ll repeat it: The more work you can do up front, the better. The time you spend finding problems early in the process will save hours and hours of debugging and hair-pulling later on when the design’s been agreed upon and you have to get it working.
On large projects like AOL.com, no one is ever working alone. There are Web services to integrate, databases and Web servers to set up, repositories to create, art to cut, and various other tasks that have to get done before you can flip the switch and launch something. On a project this large, no one person does all of these things. This section’s not going to discuss most of these in detail but will address how you can approach the monumental integration and technical design tasks associated with building something this large.
When it comes to developing Web applications, the buddy system is definitely the way to go. Pairing up your backend/middleware developer with your front-end developer as a team to work very closely together is a great way to get things done quickly. They should work together to design Web services and tools so you end up with a seamlessly integrated product instead of a bunch of duct tape.
There are several benefits to this way of working:
The producer and consumer of Web services (JSON, XML) for the page are on the same page. This means the services and the code to interact with them will be as efficient as possible.
No one person has to worry about everything. Dividing responsibilities between the front end and middleware is a nice clean line. You can have some crossover, but you know who “owns” each piece.
Although there’s an owner for each piece, there’s also backup. Having someone close by to bounce ideas off of and answer questions is always helpful.
Two is a small enough number that there’s not a lot of communication overhead. Most problems can be solved over an instant message or a quick phone call. There’s no need to schedule big conference calls with dozens of people and juggle schedules.
Two seems to be the right number when working on a project of this size. You’ll need to have many more folks working on other pieces, like publishing tools, managing other projects that feed pieces of the main one (Web services, integration points, etc), designers, operations, database administrators, etc. But, pairing the developers on the project works well.
The days of flat Web pages are over. For the most part, no one writes just HTML and publishes it as a single document, at least not for large sites like AOL.com. That means Web services, scripting languages, and integration with other systems.
When it comes to designing Web services, there is no such thing as a vacuum. A Web service should never be designed without thinking about how a developer would go about consuming that service. That means thinking in terms of simplicity, what steps someone will have to take to interact with your service, and making those steps as simple as possible. The easiest way to do this is to create stubs— example responses or processes that take a request and return a canned (fake) response. This gives the consumers of your Web service a chance to play around with it and give you feedback before you go through the trouble of actually hooking it up with any backend systems. This is a good way to make sure your “buddy” (the one we paired you up with in the last section) will be able to work quickly and with confidence once the “real” service is ready.
Things to think about when creating stubs:
Don’t just think about what happens when things work—think about when things aren’t going so well. What does an error response look like? How can you tell the consumer of your service whether to try again or give up?
What kinds of data can be returned? Can you get more than a set number of items back? For example, if your service returns search results, what does it look like when you get two results back? Three? Ten? None?
Do you need to provide more than one “flavor”? How do you provide both XML and JSON responses?
Can any programming language consume your services? Validate your assumptions and make sure that you’re not tying yourself to a single way to consume the service.
Stubs allow for integration to happen before all the pieces are ready. This means each party responsible for a piece of infrastructure or any front-end developer could be finished with their work long before you’re ready to integrate with them. If you’ve done your job correctly, and the real service matches the stubs, it’s just a small configuration change to point from the stub to the real thing.
Stubs also give you something to test against. When you have the real service ready to go, you should always go back and compare it to the stubs to make sure you’ve remained consistent. There isn’t much point in creating stubs if the end result is totally different.
Creating stubs for all of your Web services not only saves you time, it gives you a reference implementation you can give to other folks who might need to integrate your services. You don’t need to give them access to a live production machine to develop with. They can develop and test against the stubs and then test against the live service once they’re done. It saves load on your production environment, and means a lot less hassle for folks who may work remotely or outside of your corporate firewall.
Consumers (we call them “users”) aren’t the only ones who interact with your product. In the case of AOL.com, there’s an entire army of folks who do editorial work on the individual pieces of the page. They’re spread across organizational units, and they all have their own concerns and requirements for the tools they use to publish content. These requirements may include licenses for photography, content that needs to go live and come down at a particular time, different methods for formatting, different feeds they need to integrate, or ways to track contractual obligations. All of these requirements need to be addressed and handled by the publishing tools you create to drive the site.
In many cases, the tools are the last things to be built because they’re seen as the least important. They’re not. When you think about all the hours that each of those editors spends in those tools, and all the times they do the same thing over and over again, any wasted steps or broken tools could end up costing your company thousands, if not millions, of dollars in lost productive time.
One way to go about building tools is to first gather information from the editorial staff:
That’s just a sample. There are some questions you might want to avoid. Don’t ask about flexibility or uptime. No matter if they need it or not, the response is always “100% flexible and available 100% of the time.” No one needs a tool that’s 100% flexible, and most publishing tools don’t need to have 99.999% uptime. Flexibility is expensive. The more flexible a tool is, the more options it needs to have, which cuts down on how quickly you can do the things you do most often.
There’s also a danger in asking people what they want. They may not know, or may not know quite how to ask for the thing they really need. How do you get around the fact that human beings are unreliable? Watch them work. This may seem uncomfortable, but having someone walk you through exactly how they do their job is a much more enlightening process than asking them questions. Spend an hour or two watching them do their job and take notes. This will give you a lot of insight into what they really spend their time doing and what the tool needs to do in order to help them do it more efficiently.
Often, tools are designed by the developer, which can lead to problems. It’s a good idea to have a designer spend some time on the workflow around tools. They shouldn’t spend their time making it “pretty,” but a good interface designer spending an hour or two making sure the tool makes sense is a good investment. Developers have a habit of thinking of what a tool is doing underneath the interface, which leads to some strange interactions for the people using the tool. The input of a thoughtful designer will help will make the tool’s “user experience” a lot smoother.
Being considerate of the users of the tools used to publish the site will almost always lead to better content, and the cost savings can be pointed to as a real win, no matter how big the company is.
You can have the fastest Web server, database, and cache server, and you may be connected to the Internet with the fastest pipe possible—and your users may still think your site is slow. There is a tendency in technology organizations to give less time or discipline to front-end code, even though the vast majority of time between when a user makes a request and when content is displayed is spent downloading and rendering that content. No amount of performance optimization on the backend will improve that experience; the only way to make things feel faster is to show the same discipline on the front end that you use in your server-side code. This section will introduce the basics of standards-based development, and some best practices you can use to whip your markup and CSS into shape.
Early on in the process of designing and developing AOL.com, the team met often to discuss markup best practices, performance, and to make sure that all of them were on the same page. Prior to this, my work on improving performance for AOL Search taught me that one of the best ways to improve performance was to use semantic markup, and a DOCTYPE that put modern Web browsers into “standards mode.” We chose that same approach for AOL.com.
But before we get into that, let’s take a step back. Some of the words in the previous paragraph may be English but might not make any sense unless you’re already a part of the Web standards “club.”
In the old days, everyone used HTML tables to determine the layout of their pages. This worked, but created bloated, hard to maintain documents that took a long time for browsers to download and then render.
This model was OK. It mostly worked, and allowed people to build complex layouts on the Web. Unfortunately, it wasn’t very flexible or maintainable, and it punished users because their browsers had to try to figure out how to draw gigantic mazes of nested tables (according to several people who work on browser rendering engines, rendering tables is one of the hardest things they have to do).
The lingua franca of the Web, HTML, was also a problem. HTML 4 didn’t enforce its rules. To write valid HTML 4, you could leave tags unclosed, have both unquoted and quoted attributes, use both upper- and lower-case tags, and there was no need to provide a DOCTYPE, telling the software consuming the document what specification the document conformed to. This meant that browsers had to guess about where a particular tag ended, which led to a gigantic set of tests the browser had to do before it could even consider rendering the document.
Thankfully, no one has to live with that pain any more.
The advent of XHTML 1.0 and CSS 2.0 gave browsers a chance to break from the old rendering model of HTML 4 (now called “quirks mode”). XHTML took some of the rules of XML and applied them to HTML’s vocabulary. The rules are simple but allow browsers (or any other parser) to very quickly decipher the document’s structure and move on to rendering. For a document to meet the standards of valid XHTML, it has to
Use a DOCTYPE as the first content of the document. The DOCTYPE for XHTML 1.0 transitional is:
<LINELENGTH>90</LINELENGTH><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Have an opening and closing
<html>element as the root element of the document.Have an opening and closing
<head>element as a child of<html>.Have an opening and closing
<body>element as a child of<html>and as a sibling of<head>.Have an opening and closing
<title>element as a child of<head>.Set all tags in lowercase.
Have closed tags. For example, if you create a paragraph tag, it should look like this:
<p></p>instead of just<p>.Set all attribute names in lowercase.
Enclose all attribute values in quotes.
These rules are fairly easy for browsers to enforce, and, equally good news, there aren’t that many of them, which means browsers can render that content faster.
Browsers were able to introduce a feature called DOCTYPE switching, which allowed them to very quickly decide what kind of document they were dealing with and change the rendering mode appropriately. The two modes are called quirks mode and standards mode. (Firefox has a third mode, but it’s not different enough to talk about.) Quirks mode is the old model, where the browser goes through all of the different tests it used in the “old days” to create something to render. Standards mode does away with most of those tests and gets to something renderable much faster. In many cases, just changing from quirks to standards mode can provide a 10x improvement in rendering speed.
How do you tell the browser to render a document in standards mode? By using a DOCTYPE! It’s highly recommended that you use XHTML 1.0 Transitional (see the rules list above for the exact text). This provides the same vocabulary of available tags while giving you the benefit of standards mode. XHTML 1.0 Strict removes several elements (most importantly, iframe) that limit its usefulness.
Once your document is rendered in standards mode, you’re not done. You need to then make sure it’s valid, using either a built-in validator (most good text editors and WYSIWYG editors have them built in now) or by using the W3C’s validator at http://validator.w3.org. Having a valid XHTML document is just the first step to producing a good product, but it’s an important one. It’s a good initial test of quality. If the document validates, it means you can be reasonably sure that the CSS you write will find the right elements and do what you expect it to.
Even with a valid XHTML document, it’s still possible to use HTML tables for layout and continue creating bloated, unmaintainable pages. But part of the benefit of having your document render in standards mode is that you need less markup to handle your layout, because most of the instructions for how the browser should display your document is in an associated CSS file (which we’ll get to in a little bit).
Instead of relying on tables, it’s now possible to use the entire HTML vocabulary to express so much more than how a document is supposed to look. It’s now possible to express what the content of a document means. If there’s a list of items, it should be marked up with list elements. For example, in the old days, lists might be marked up like this:
• Oranges<br/> • Apples<br/> • Grapes<br/> • Pears<br/>
But, today, you should use HTML lists:
<ul> <li>Oranges</li> <li>Apples</li> <li>Grapes</li> <li>Pears</li> </ul>
By default, that gives you the default styling of a list, but it also opens up a lot of possibilities. If you want to take that list and turn it into a navigation bar, or maybe just a comma-separated list on a single line, you could accomplish it with CSS. Compare that to the fate of the previous, old-timey example—what you see is all it’s ever going to be, and no amount of CSS is going to save you.
This new way, HTML lists, will also result in less markup (not in that example, but there will be a better one in a minute). Because you’re now able to use the entire vocabulary that HTML has to offer, you can use the “right” element for content instead of using meaningless elements like <div> or <span>. For example, most sites have a navigation bar at the top of their sites that contains a list of links. Many sites have something very close to the following to represent that list of links:
<div id="navigation"> <div id="link-one"><a href="/">home</a></div> <div id="link-two"><a href="/about">about</a></div> <div id="link-three"><a href="/help">help</a></div> <div id="link-four"><a href="/login">login</a></div> </div>
Many sites don’t even use links there but use <spans> with onclick events. Why they do this boggles the mind, but it certainly exists out there in the wild. A better, smaller, and more semantic way to represent that list might be:
<ul> <li id="home-link"><a href="/">home</a></li> <li id="about-link"><a href="/about">about</a></li> <li id="help-link"><a href="/help">help</a></li> <li id="login-link"><a href="/login-link">login</a></li> </ul>
The first snippet contains 272 characters. The second contains 247 characters, a savings of almost 10%. Over an entire document, especially when replacing layout tables with more semantic elements, that savings can grow to as much as 50%.
Using semantic markup instead of table-based layouts or using <div>s and <span>s for everything can greatly reduce the amount of markup in your document, which means your users have a better experience with your products.
Cascading Style Sheets were introduced to the Web in 1996. Until Netscape 4.7 and Internet Explorer 4 came out, CSS was only good for setting fonts and maybe text color, because the browsers hadn’t implemented it fully yet.
Thankfully, today’s modern browsers have reasonably interoperable implementations of CSS, which gives developers and designers a lot of freedom when it comes to styling semantic content.
AOL.com had very aggressive performance targets for broadband and dial-up users, which meant that the more style information that could be pushed into cached CSS files, the better.
Before a browser renders any part of the page, it will download all CSS and JavaScript files in the <head>. Once those files are downloaded and parsed, the browser will usually try to render as much of the HTML document as it has.
It’s a good idea to put the link to your CSS file as the first thing in the <head> after the <title> element. This gives your browser a head start (no pun intended) on downloading it and building out the CSS DOM. The fewer CSS files the browser has to deal with, the simpler that CSS DOM, and the faster the browser can render the page.
One of the things the team learned during performance testing, especially for broadband users, is that as bandwidth goes up, the browser’s CPU and connections-per-host become the largest bottlenecks for performance. According to the HTTP 1.1 specification, a browser is only allowed to open two connections for each domain. That means if you have two style sheets on the same domain, your browser can’t download anything else while it’s working on those two files. The fewer files you make your users download, the faster your page will load, no matter how much bandwidth the user has available.
What that means for your site, as it did for AOL.com, is you should put all your CSS into one large style sheet. It may seem like a pain, but there are several tricks you can use to keep yourself sane while working with one large file that contains all your styles.
The best place to start is to have good markup, which we talked about in the previous section. This will help you write less CSS, and CSS that’s easier to keep organized. By giving yourself logical hooks to style by, and semantic classes and IDs, you’ll be able to navigate the different sections of your CSS much like you navigate through the HTML that makes up the document.
You should pick a structure for your CSS document that works for you. You can use the one below, or pick one of your own, but keep it consistent. The closer you can keep your CSS selectors to the order they appear in the document, and the more specific your selectors are, the easier it will be to find things when you need to change something.
Here’s a sample:
body {
width:80%;
margin:0 auto;
padding:0
font:76% arial, helvetica, sans-serif;
background:#fff;
color:#000
}
h1, h2, h3, h4, h5, h6 {
margin:0;
padding:0;
}
#header {
margin:0;
padding:1em;
}
#header h1 {
padding:1.5em
}
#header h1 a {
display:block;
color:#333;
text-decoration:none;
}
#content {
margin:0 1em 0 0;
padding:1.2em;
}There’s no HTML document to refer to but here’s the basic order:
Generic HTML selectors
General use class selectors
ID selectors for major sections of the document
Descendent selectors for that section
The properties within a declaration are also kept in order, just to keep things clear when reading the file. This helps for documentation purposes and troubleshooting. Pick an order that makes sense to you and that you can stay consistent with. Here’s one possibility:
If you can keep your CSS files in sync with your HTML document, you’ll be better off when you need to troubleshoot those styles, or if you need to hand that document off to someone else. Whoever takes it over should easily be able to figure out your convention and make sense of it.
One of the coolest accessibility features that AOL.com has is how it handles resizing fonts. It resizes not only the text on the page, but the entire layout and major images as well. This section will show you how that’s done, by building a much simpler document and applying the same principles.
As you’ll see, this is a much simpler version of the layout that AOL.com uses. Here’s the markup:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Accessible CSS Example</title>
<link rel="stylesheet" type="text/css" href="accessible.css"/>
</head>
<body>
<div id="header">
<h1><a href="http://aol.com">AOL.com</a></h1>
</div>
<div id="content">
<h3>This Section's Title</h3>
<p class="image"><img src="example-image.jpg" alt="This image is just an example."/></p>
<p>Welcome to my example document. What do you think? Isn't it swell?</p>
</div>
<div id="navigation">
<h3>Tools</h3>
<ul>
<li><a href="">mail</a></li>
<li><a href="">money</a></li>
<li><a href="">music</a></li>
<li><a href="">AIM</a></li>
<li><a href="">MyAOL</a></li>
<li><a href="">video</a></li>
</ul>
</div>
<div id="footer">
AOL LLC | AOL International | Terms of Use | Privacy Policy |
Trademarks | Customer Support
Accessibility Policy | AOL Unsolicited Bulk E-Mail Policy |
Advertise With Us | Download AOL | Beta | Site Map
</div>
</body>
</html>FIGURE 7.5 shows what it should look like in a browser.
Right, not the most attractive thing you’ve ever seen. That’s about to change.
Let’s start by putting in some generic styles and styling the major sections of the site, and see where that gets us.
Here’s the CSS:
body {
margin:0 auto;
padding:0;
font: 76% arial, helvetica, sans-serif;
background:#fff;
color:#000;
}
h1, h2, h3, h4, h5, h6 {
margin:0;
padding:0;
}
#header {
background:#036;
padding:1em;
}
#header h1 a {
color:#fff;
text-decoration:none;
}
#content {
float:left;
padding:1em 0;
}
#content h3 {
padding:.5em;
background: #036;
font-size:1.2em;
color:#fff;
}
#navigation {
float:right;
padding:1em 0;
}
#navigation h3 {
padding:.3em;
font-size:1.1em;
background:#063;
color:#fff;
}
#footer {
clear:both;
padding:1em 0 .5em 0;
}FIGURE 7.6 shows what it should look like now in your browser.

Definition
An em is a unit of measurement that is set relative to the font size of the current element.
Now comes the fun part! AOL.com pulls off its trick by using em values for content and image widths, so that’s exactly what we’re going to do. If you look at the initial styles we created for our example document, you should see the following declaration:
body {
margin:0 auto;
padding:0;
font: 76% arial, helvetica, sans-serif;
background:#fff;
color:#000;
}Since modern browsers all set their default font size to 16 pixels, 76% of that is 12px. Everything we do from this point on will be relative to the font size we set on the <body> element. For example, to get a width of 755px at the default font size, the browsers set the width of their containing <div> to 62.5em (because 755 ÷ 12 = 62.5). All of the other elements that are resized when the user changes font size are set up using this formula.
Taking the CSS we had from the previous step, we’ll add widths to the <body> element, the content and navigation <div>s, and the example image.
Here’s the CSS:
body {
width:62.5em;
margin:0 auto;
padding:0;
font: 76% arial, helvetica, sans-serif;
background:#fff;
color:#000;
}
h1, h2, h3, h4, h5, h6 {
margin:0;
padding:0;
}
#header {
background:#036;
padding:1em;
}
#header h1 a {
color:#fff;
text-decoration:none;
}
#content {
width:40em;
float:left;
padding:1em 0;
}
#content h3 {
padding:.5em;
background: #036;
font-size:1.2em;
color:#fff;
}
#content p.image {
float:left;
padding:0 .25em .25em 0;
}
#content p.image img {
width:16.66em;
height:12.5em;
}
#navigation {
width:22.5em;
float:right;
padding:1em 0;
}
#navigation h3 {
padding:.3em;
font-size:1.1em;
background:#063;
color:#fff;
}
#footer {
clear:both;
padding:1em 0 .5em 0;
}Looking at the widths, TABLE 7.2 shows what we have.
FIGURE 7.7 shows what it should look like in any modern Web browser (tested in IE6, Opera 9.5, Firefox 2.0, Safari 2.0, and Firefox 1.5).
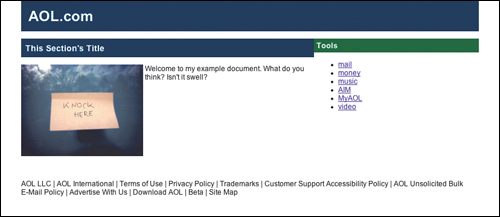
And FIGURE 7.8 shows it with the font one step larger.

This approach gives you a lot of flexibility; more importantly, it gives your users a lot of flexibility. When they resize the text in their browser, it’s not crammed into a tiny little space. The container grows with the text, instead of staying the same size and ruining the visual look of your site.
One of the biggest challenges in any site is performance. We talked at the beginning of this section about the work you can do up front to give yourself the best opportunity to have a well-performing site. Now it’s time to talk about what you do with the live product to make sure your users have the best possible experience. The three most important things you can do to maximize performance for your users, no matter their connection speed, are caching, compression, and reducing the number of objects users have to download. We’ll discuss best practices and pitfalls around each.
We’ve talked about caching before, but it’s important enough to repeat when it comes to real-world performance.
There are very few things that users really need to download every time they visit your site. Usually, the large majority of content users have to download won’t change every time they view the page. To give your users the best possible performance, it’s a good idea to cache the content that doesn’t change frequently. This usually includes CSS, JavaScript, and images. Since the HTML for dynamic sites is just that—dynamic—there’s no good way to cache it.
The easiest way to tell a browser to cache a file is to set the “Expires” HTTP header to some far-distant date. Setting this depends on your Web server and programming language. If you have a CDN (Content Delivery Network), it may do this for you. Let’s look at a couple examples from AOL.com. All of the CSS and JavaScript files have an Expires date set 30 days in the future. So, for a whole month, users will use the cached version of the CSS. The navigational images also use the same Expires date. All of the programmed images have an Expires time of only 24 hours in the future, since those change frequently—potentially several times a day. If you use Apache as your Web server, you can use the following in your .htaccess file to do the same thing:
ExpiresActive on ExpiresByType "text/css" "now plus 1 month" ExpiresByType "image/jpeg" "now plus 1 year" ExpiresByType "image/png" "now plus 1 year" ExpiresByType "image/gif" "now plus 1 year" ExpiresByType "text/javascript" "now plus 1 month"
This does raise one problem: What if you have to make a change? Currently, AOL.com will publish a file with a whole new URL and change the HTML to point to it. This gets around users having the file cached and makes sure they get the updates.
There are many different ways to handle caching and updating content, but this approach has worked well for AOL.com.
One of the best things you can do to improve performance is to compress all your non-binary files. There are several points where you can do this compression: by hand on the file system, in the Web server, or in your router. AOL.com currently uses the router to do the compression, but most modern Web servers have compression either built in or provided by a plug-in.
Compressing text content (HTML, CSS, and JavaScript) can provide a savings of up to 50% in the amount of data sent over the Internet. There’s a little overhead on the user’s machine when the content is decompressed, but 90% of the time it is much faster to decompress the file than download it, even over a high-speed connection. Compressing binary files such as images, though, usually provides no benefit, and creates files larger than the original.
As connection speeds increase, the bottleneck for users displaying your page moves from downloading the content to parsing and rendering. There is also a hard limit on the number of files that browsers will download at a time. Internet Explorer (all versions) will only download two files per host at a time. This means that if all your files are on the same domain (like www.aol.com), IE will only download two of those files at a time, no matter how fast the connection is. The default for Firefox is four files per domain (although this is easily tweaked either by using the preferences or the FasterFox extension). Also, the more complicated your CSS and JavaScript, and the more files they’re split up across, the more work the user’s browser has to do to create the initial Document Object Model and the CSS Object Model, and to decide what the Cascade and Inheritance for all those styles are.
The more you can combine CSS and JavaScript into single files, the better. Currently, AOL.com has one main JavaScript and CSS file. There are a couple of other JavaScript files, but they’re for external advertising and reporting systems. All of the JavaScript, Flash, and CSS files downloaded by ads aren’t loaded until after the browser’s “onload” event has been fired.
The team behind AOL.com is a first-rate group of developers and designers working in a very closely watched fishbowl and under a lot of internal pressure. AOL.com is the front page not only of that domain but of all AOL products. That means everyone wants a piece of them and their every move is scrutinized. Under this pressure, this world-class group turned out a world-class portal—not only in how it looks and works but in accessibility, performance, and in ease of adding new features. I’m proud of the very small part I could play in the process of developing AOL.com, and to have worked with such an amazing group of professionals.
AOL.com isn’t perfect—no site is—but the things it does well, it does very well. Those are the parts I felt were important to share: the way the team works together, Web standards, accessibility, and performance. Hopefully, you can take the lessons we learned on this project and apply them to your own.