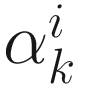Adaptive Machine Learning Algorithms with Python
Solve Data Analytics and Machine Learning Problems on Edge Devices

This Apress imprint is published by the registered company APress Media, LLC part of Springer Nature.
The registered company address is: 1 New York Plaza, New York, NY 10004, U.S.A.
I dedicate this book to my father, Basudev Chatterjee, and all my teachers and mentors who have guided and inspired me.
This book presents several categories of streaming data problems that have significant value in machine learning, data visualization, and data analytics. It offers many adaptive algorithms for solving these problems on streaming data vectors or matrices. Complex neural network-based applications are commonplace and computing power is growing exponentially, so why do we need adaptive computation?
Adaptive algorithms are critical in environments where the data volume is large, data has high dimensions, data is time-varying and has changing underlying statistics, and we do not have sufficient storage, computing power, and bandwidth to process the data with low latency. One such environment is computation on edge devices.
Power usage for computation at scale
Non-stationarity of inputs and drift of the incoming data
Latency of computation on devices
Memories and bandwidth of devices
The 2021 Gartner report on Edge computation [Stratus Technologies, 2021] suggests that device-based computation growth propelled by the adoption of cloud and 5G will require us to prioritize and build a framework for edge computation.
The data cannot be batched immediately and needs to be used instantaneously. We have a streaming sequence of vectors or matrices as inputs to the algorithms.
The data changes with time. In other words, the data is non-stationary, causing significant drift of input features whereby the machine learning models are no longer effective over time.
The data volume and dimensionality are large, and we do not have the device memory, bandwidth, or power to store or upload the data to the cloud.
- 1.
Calculate feature drift of incoming data and detect training-serving skew [Kaz et al. 2021] ahead of time.
- 2.
Adapt to incoming data drift and calculate features that best fit the data.
- 3.
Calculate anomalies in incoming data so that good, clean data is used by the models.
- 4.
Compress incoming data into features for use in new model creation.
In Chapter 8, I present solutions to these problems with adaptive algorithms discussed with real-world data.
Detecting Feature Drift
See the example where the real-time data [Vinicius Souza et al. 2020] has a gradual drift of features. In real-time environments there are changes in the underlying distribution of the observed data. These changes in the statistical properties of the data are called drift. When the changes in statistical properties are smooth, it is called gradual drift. Figure 1 shows a slow change in the magnitude of the components of a multivariate data over time, showing a gradual drift.

Data components show gradual drift over time

An adaptive principal component-based metric detects drift in data early in the real-time process
The downward slope of the detection metric in the graph indicates the gradual drift of the features.
Adapting to Drift

Simulated data that abruptly changes statistical properties after 500 samples

Principal eigenvectors adapt to abruptly changing data
My Approach
Adaptive Algorithms and Best Practices
- 1.
My algorithms process each incoming sample xk such that at any instant k all of the currently available data is taken into consideration.
- 2.
For each sample, the algorithm estimates the desired matrix functions, and its estimates have known statistical properties.
- 3.
The algorithms have the ability to adapt to variations in the underlying systems so that for each sample xk I obtain the current state of the process and not an average over all samples (i.e., I can handle both stationary and non-stationary data).
Problems with Conventional Non-Adaptive Approaches
- 1.
The dimension of the samples may be large so that even if all the samples are available, performing the matrix algebra may be difficult or may take a prohibitively large number of computational resources and memory.
- 2.
The matrix functions evaluated by conventional schemes cannot adapt to small changes in the data (e.g., a few incoming samples). If the matrix functions are estimated by conventional methods from K (finite) samples, then for each additional sample, all of the computation must be repeated.
These deficiencies make the conventional schemes inefficient for real-time applications.
Computationally Simple
My approach is to use computationally simple adaptive algorithms. For example, given a sequence of random vectors {xk}, a well-known algorithm for the principal eigenvector evaluation uses the update rule wk+1 = wk+η (xkxkT–wkwkTxkxkTwk), where η is a small positive constant. In this algorithm, for each sample xk the update procedure requires simple matrix-vector multiplications, yet the vector wk converges quickly to the principal eigenvector of the data correlation matrix. Clearly, this can be easily implemented in CPUs on devices with low memory and power usage.
The objective of this book is to present a variety of neuromorphic [neuromorphic engineering, Wikipedia] adaptive algorithms [Wikipedia] for matrix algebra problems. Neuromorphic algorithms work by mimicking the physics of the human neural systems using networks, where activation by neurons propagate to other neurons in a cascading chain.
Matrix Functions I Solve
Normalized mean, median
LU decomposition (square root), inverse square root
Eigenvector/eigenvalue decomposition (EVD)
Generalized EVD
Singular value decomposition (SVD)
Generalized SVD
For each matrix function, I will discuss practical use cases in machine learning and data analytics and support them with experimental results.
Common Methodology to Derive Adaptive Algorithms
Another contribution of this book is the presentation of a common methodology to derive each adaptive algorithm. For each matrix function and every adaptive algorithm, I present a scalar unconstrained objective function J(W;A) whose minimizer W* is the desired matrix function of A. From this objective function J(W;A), I derive the adaptive algorithm such as Wk + 1 = Wk − η∇WJ(Wk; A) by using standard techniques of optimization (for example, gradient descent). I then speed up these adaptive algorithms by using statistical methods. Note that this helps practitioners create new adaptive algorithms for their use cases.
In summary, the book starts with a common framework to derive adaptive algorithms and then uses the framework for each category of streaming data problems starting with the adaptive median to complex principal components and discriminant analysis. I present practical problems in each category and derive the algorithms to solve them. The final chapter solves critical edge computation problems for time-varying, non-stationary data with minimal compute, memory, latency, and bandwidth. I also provide the code [Chatterjee GitHub] for all algorithms discussed here.
GitHub
All simulations and implementation code by chapters are published in the public GitHub:
https://github.com/cchatterj0/AdaptiveMLAlgorithms
Python code for all chapters starting with Chapter 2
MATLAB simulation code in a separate directory
Data for all implementation code
Proofs of convergence for some of the algorithms
I want to thank my professor and mentor Vwani Roychowdhury for guiding me through my Ph.D. thesis, where I first created much of the research presented in this book. Vwani taught me how to research, write, and present this material in the many papers we wrote together. He also inspired me to continue this research and eventually write this book. I could not have done it without his inspiration, help, and guidance. I sincerely thank Vwani for being my teacher and mentor.