
Chapter 5: A <brief> Look at XML
In This Chapter
![]() What XML can do for you
What XML can do for you
![]() What goes into an XML document
What goes into an XML document
![]() How XML handles the names of things
How XML handles the names of things
Modern software takes on several forms:
• Some software is procedural.
The software tells the computer to “Do this, then do that.”
• Some software is declarative.
The software says, “Here’s what I want the form to look like” or “Here’s a list of things my application should be allowed to do.”
• Some software is neither procedural nor declarative.
The software lists functions to be executed in the order in which they apply or lists logical rules to be checked for validity.
One way or another, a development platform should use the best software for the job. That’s why the Android platform uses both procedural and declarative software.
• Android’s procedural Java code tells a device what to do.
• Android’s declarative XML code describes a layout, an application, a set of strings, a set of preferences, or some other information that’s useful to a mobile device.
A typical Android application is a mix of Java code, XML code, and a few other things. So when you develop for Android, you write lots of Java code and you mess with XML code.
What? You “mess with” XML code? What does that mean?
The truth is, XML code is painful to type. A typical XML file involves many elements, each requiring very precise wording and all looking very much alike at first glance. So in the Android world, most XML files are generated automatically. You don’t type all the file’s angle brackets. Instead, you fill in a form and let Eclipse’s tools create the XML code on your behalf.
So in many situations, you don’t have to compose XML code. But I often encounter situations in which I want to bypass Eclipse’s forms and tweak the XML code myself. Maybe the form doesn’t readily provide an option that I want to use in my XML code. Or maybe my app isn’t behaving the way I want it to behave, and I read over the XML code to check for subtle errors.
For these reasons and others, you’re best off understanding the fundamentals of XML. So this chapter covers XML basics.
 If you’re new to Java, you may wonder why this book doesn’t have a chapter on Java fundamentals. Well, Java is an intricate beast. Years ago I tried to summarize Java fundamentals in a few side chapters of a book, and the whole endeavor didn’t feel right to me. If you want to figure out Java, you’re better off with a complete book on the subject. Fortunately, I have just the book! It’s Java For Dummies, 5th Edition, by Barry Burd (John Wiley & Sons, Inc.). It’s available in fine bookstores around the world. And when you buy a copy, please pay double the asking price.
If you’re new to Java, you may wonder why this book doesn’t have a chapter on Java fundamentals. Well, Java is an intricate beast. Years ago I tried to summarize Java fundamentals in a few side chapters of a book, and the whole endeavor didn’t feel right to me. If you want to figure out Java, you’re better off with a complete book on the subject. Fortunately, I have just the book! It’s Java For Dummies, 5th Edition, by Barry Burd (John Wiley & Sons, Inc.). It’s available in fine bookstores around the world. And when you buy a copy, please pay double the asking price.
XML Isn’t Ordinary Text
You may already be familiar with Hypertext Markup Language (HTML) because HTML is the universal language of the World Wide Web. Choose View⇒Source in your favorite web browser, and you’ll see a bunch of HTML tags — tags like <head>, <title>, <meta>, and so on. An HTML document describes the look and layout of a web page.
An XML document is something like an HTML document. But an XML document differs from an HTML document in many ways. The two most striking ways are as follows:
• An XML file doesn’t describe only look and layout. In fact, very few XML files describe anything visual at all. Instead, most XML files describe data — a list of stock trades; a hierarchical list of automobile makes and models; or a nested list of movements, measures, and notes in a Beethoven symphony.
• Certain rules describe what you can and cannot write in an HTML or an XML document. The rules for HTML are very permissive. The rules for XML are very strict.
In HTML, a missing character or word often goes unnoticed. In XML, a missing character or word can ruin your whole day.
The formal definitions of an XML document’s parts can be daunting. But you can think of an XML document as a bunch of elements, with each element having one or two tags.
Of tags and elements
Tags and elements are the workhorses of XML. Here’s the scoop:
• A tag is some text surrounded by angle brackets.
For example, Listing 5-1 contains a basic AndroidManifest.xml file. In this file, <intent-filter> is a tag, </intent-filter> (which comes a bit later in the file is another tag. Text such as <application android:icon=”@drawable/icon” android:label=”@string/app_name”> is also a tag.
Listing 5-1: An AndroidManifest.xml File
<?xml version=”1.0” encoding=”utf-8”?>
<manifest xmlns:android=
“http://schemas.android.com/apk/res/android”
package=”com.allmycode.andevcon”
android:versionCode=”1”
android:versionName=”1.0”>
<uses-sdk android:minSdkVersion=”8” />
<application android:icon=”@drawable/icon”
android:label=”@string/app_name”>
<activity android:name=”.MyActivity”
android:label=”@string/app_name”>
<intent-filter>
<action android:name=
“android.intent.action.MAIN” />
<category android:name=
“android.intent.category.LAUNCHER” />
</intent-filter>
</activity>
</application>
</manifest>
Not everything with angle brackets qualifies as an XML tag. For example, the text <This is my application.> violates many of the rules of grammatically correct XML. For more about what an XML tag can and cannot contain, read on.
 An XML document is well formed when its text obeys all the rules of grammatically correct XML.
An XML document is well formed when its text obeys all the rules of grammatically correct XML.
• An XML document may have three different kinds of tags:
• A start tag begins with an open angle bracket and a name. The start tag’s last character is a closing angle bracket.
In Listing 5-1, <intent-filter> is a start tag. The start tag’s name is intent-filter.
• An end tag begins with an open angle bracket followed by a forward slash and a name. The end tag’s last character is a closing angle bracket.
In Listing 5-1, </intent-filter> is an end tag. The end tag’s name is intent-filter.
• An empty element tag begins with an open angle bracket followed by a name. The end tag’s last two characters are a forward slash, followed by a closing angle bracket.
In Listing 5-1, the text <uses-sdk android:minSdkVersion=”8” /> is an empty element tag.
I rattle on about tags a bit more in the next several paragraphs. But in the meantime, I want to describe an XML element.
• An XML element either has both a start tag and an end tag, or it has an empty element tag.
The document in Listing 5-1 contains several elements. For example, the document’s intent-filter element has both a start tag and an end tag. (Both the start and end tags have the same name, intent-filter, so the name of the entire element is intent-filter.)
In Listing 5-1, the document’s action element has only one tag — an empty element tag.
• The names of XML elements are not cast in stone.
In an HTML document, a b element creates boldface text. For example, the text <b>Buy this!</b> in an HTML document looks like Buy this! in your web browser’s window.
In an HTML document, the element name b is cast in stone. But in XML documents, names like manifest, application, activity, and intent-filter are not cast in stone. An XML document has its own set of element names, and these names are likely to be different from the names in most other XML documents. You can create your own well-formed XML document as follows:
<pets>
<cat>
Felix
</cat>
<cat>
Sylvester
</cat>
</pets>
If your goal is to store information about kitty cats, your XML document is just fine.
 The text in an XML document is case-sensitive. An element named
The text in an XML document is case-sensitive. An element named APPLICATION doesn’t have the same name as another element named application.
• A non-empty XML element may contain content.
The content is stuff between the start tag and the end tag. For example, in Listing 5-1, the intent-filter element’s content is
<action android:name=
“android.intent.action.MAIN” />
<category android:name=
“android.intent.category.LAUNCHER” />
An element’s content may include other elements. (In this example, the intent-filter element contains an action element and a category element.)
An element’s content may also include ordinary text. For example, in Listing 5-2, the resources element contains two string elements, and each string element contains ordinary text.
Listing 5-2: An Android strings.xml File
<?xml version=”1.0” encoding=”utf-8” standalone=”no”?>
<resources>
<string name=”hello”>Hello World!</string>
<string name=”app_name”>AnDevCon App</string>
</resources>
You can even have mixed content. For example, between an element’s start and end tags, you may have some ordinary text, followed by an element or two, followed by more ordinary text.
• In some cases, two or more elements may have the same name.
In Listing 5-2, two distinct elements have the name string. To find out more about the names used in an XML file, see the nearby sidebar “What element names can you use?”
• Elements are either nested inside one another, or they don’t overlap at all.
In Listing 5-1, the manifest element contains a uses-sdk element and an application element. The application element contains an activity element, which in turn contains an intent-filter element, and so on.
<manifest>
This code demonstrates element nesting.
This code is NOT a real AndroidManifest.xml file
<uses-sdk />
<application>
<activity>
<intent-filter>
<action />
<category />
</intent-filter>
</activity>
</application>
</manifest>
In Listing 5-1 (and in the fake listing inside this Bullet1) the uses-sdk and application elements don’t overlap at all. The action and category elements don’t overlap at all. But whenever one element overlaps another, one of the elements is nested completely inside the other.
For example, in Listing 5-1, the intent-filter element is nested completely inside the activity element. The following sequence of tags, with overlapping and not nesting, would be illegal:
<activity>
<intent-filter>
This is NOT well-formed XML code.
</activity>
</intent-filter>
Near the start of this chapter, I announce that the rules governing HTML aren’t as strict as the rules governing XML. In HTML, you can create non-nested, overlapping tags. For example, the code <b>Use <i>irregular</b> fonts</i> sparingly appears in your web browser as
Use irregular fonts sparingly
with “Use irregular” in bold and “irregular fonts” italicized.
Microsoft Internet Explorer is a decent XML viewer. When you visit an XML document with Internet Explorer, you see a colorful, well-indented display of your XML code. The code’s elements expand and collapse on your command. And if you visit an XML document that’s not well-formed (for example, a document with overlapping, non-nested tags), Internet Explorer displays a blank page. (That’s good. Internet Explorer reminds you that you’ve goofed.)
• Each XML document contains one element in which all other elements are nested.
In Listing 5-1, the manifest element contains all other elements. That’s good. The following outline would not make a legal XML document:
<manifest>
<uses-sdk />
<application>
</application>
This is NOT a well-formed XML document
because another element comes after the
following manifest end tag:
</manifest>
<manifest>
<uses-sdk />
<application>
</application>
</manifest>
In an XML document, the single element that encloses all other elements is the root element.
• Start tags and end tags may contain attributes.
An attribute is a name-value pair. Each attribute has the form
name=”value”
The quotation marks around the value are required.
In Listing 5-1, the start tags and empty element tags contain many attributes. For example, in the manifest start tag, the text
xmlns:android=
“http://schemas.android.com/apk/res/android”
is an attribute. In the same tag, the text
package=”com.allmycode.andevcon”
is an attribute. All in all, the manifest start tag has four attributes. Later in Listing 5-1, the empty element uses-sdk tag has one attribute.
Other things you find in an XML document
There’s more to life than tags and elements. This section describes all the things you can look forward to.
• An XML document begins with an XML declaration.
The declaration in Listing 5-1 is
<?xml version=”1.0” encoding=”utf-8”?>
The question marks distinguish the declaration from an ordinary XML tag.
This declaration announces that Listing 5-1 contains an XML document (big surprise!), that the document uses version 1.0 of the XML specifications, and that bit strings used to store the document’s characters are to be interpreted with their meanings as UTF-8 codes.
In practice, you seldom have reason to mess with a document’s XML declaration. For a new XML document, simply copy and paste the declaration in Listing 5-1.
The version=”1.0” part of an XML declaration may look antiquated, but XML hasn’t changed much since the initial specs appeared in 1998. In fact, the only newer version is XML 1.1, which developers seldom use. This reluctance to change is part of the XML philosophy — to have a universal, time-tested format for representing information about almost any subject.
• An XML document may contain comments.
A comment begins with the characters <!-- and ends with the characters -->. For example, the lines
<!-- This application must be tested
very, very carefully. -->
form an XML comment. A document’s comments can appear between tags (and in a few other places that aren’t worth fussing about right now).
Comments are normally intended to be read by humans. But programs that input XML documents are free to read comments and to act on the text within comments. Android doesn’t normally do anything with the comments it finds in its XML files, but you never know.
• An XML document may contain processing instructions.
A processing instruction looks a lot like the document’s XML declaration. Here’s an example of a processing instruction:
<?chapter number=”x” Put chapter number here ?>
A document may have many processing instructions, and these processing instructions can appear between tags (and in a few other places). But in practice, most XML documents have no processing instructions. (For reasons too obscure even for a Technical Stuff icon, the document’s XML declaration isn’t a processing instruction.)
Like a document’s XML declaration, each processing instruction begins with the characters <? and ends with the characters ?>. Each processing instruction has a name. But after the processing instruction’s name, anything goes. The processing instruction near the start of this Bullet1 has the name chapter followed by some free-form text. Part of that text looks like a start tag’s attribute, but the remaining text looks like a comment of some sort.
 You can put almost anything inside a processing instruction. Most of the software that inputs your XML document will simply ignore the processing instruction. (As an experiment, I added my chapter processing instruction to the file in Listing 5-1. This change made absolutely no difference in the running of my Android app.)
You can put almost anything inside a processing instruction. Most of the software that inputs your XML document will simply ignore the processing instruction. (As an experiment, I added my chapter processing instruction to the file in Listing 5-1. This change made absolutely no difference in the running of my Android app.)
So what good are processing instructions anyway? Well, if you stumble into one, I don’t want you to mistake it for a kind of XML declaration. Also, certain programs may read specific processing instructions and get particular information from these instructions.
For example, a style sheet is a file that describes the look and the layout of the information in an XML document. Typically, an XML document and the corresponding style sheet are in two different files. To indicate that the information in your pets.xml document should be displayed using the rules in the animals.css style sheet, you add the following processing instruction to the pets.xml document:
<?xml-stylesheet href=”animals.css” type=”text/css”?>
• An XML document may contain entity references.
I poked around among Android’s official sample applications and found the following elements (spread out among different programs):
<Key android:codes=”60” android:keyLabel=”<”/>
<Key android:codes=”62” android:keyLabel=”>”/>
<Key android:codes=”34” android:keyLabel=”"”/>
<string name=”activity_save_restore”>
App/Activity/Save & Restore State
</string>
The first element contains a reference to the < entity. You can’t use a real angle bracket just anywhere in an XML document. An angle bracket signals the beginning of an XML tag. So if you want to express that the name three-brackets stands for the string “<<<”, you can’t write
<string name=”three-brackets”><<<</string>
The extra brackets will confuse any program that expects to encounter ordinary XML tags.
So to get around XML’s special use of angle brackets, the XML specs include the entities < and >. The first, <, stands for an opening angle bracket. The second, >, stands for the closing angle bracket. So to express that the name three-brackets stands for the string “<<<”, you write
<string name=”three-brackets”><<<</string>
In the entity <, the letters lt stand for “less than.” And after all, an opening angle bracket looks like the “less than” sign in mathematics. Similarly, in the entity >, the letters gt stand for “greater than.”
What’s in a Namespace?
The first official definition of XML was published in 1998 by the World Wide Web Consortium (W3C). This first standard ignored a sticky problem. If two XML documents have some elements or attributes with identical names, and if those names have different meanings in the two documents, how can you possibly combine the two documents?
Here’s a simple XML document:
<?xml version=”1.0” encoding=”utf-8”?>
<banks>
<bank>First National Bank</bank>
<bank>Second Regional Bank</bank>
<bank>United Trustworthy Trusty Trust</bank>
<bank>Federal Bank of Fredonia (Groucho Branch)</bank>
</banks>
And here’s another XML document:
<?xml version=”1.0” encoding=”utf-8”?>
<banks>
<bank>Banks of the Mississippi River</bank>
<bank>La Rive Gauche</bank>
<bank>La Rive Droite</bank>
<bank>The Banks of Plum Creek</bank>
</banks>
An organization with seemingly limitless resources aims to collect and combine knowledge from all over the Internet. The organization’s software finds XML documents and combines them into one super all-knowing document. (Think of an automated version of Wikipedia.)
But when you combine documents about financial institutions with documents about rivers, you get some confusing results. If both First National and the Banks of Plum Creek are in the same document’s bank elements, analyzing the document may require prior knowledge. In other words, if you don’t already know that some banks lend money and that other banks flood during storms, you might draw some strange conclusions. And unfortunately, computer programs don’t already know anything. (Life becomes really complicated when you reach an XML element describing the Red River Bank in Shreveport, Louisiana. This river bank has teller machines in Shreveport, Alexandria, and other towns.)
To remedy this situation, members of the XML standards committee created XML namespaces. A namespace is a prefix that you attach to a name. You separate the namespace from the name with a colon (:) character. For example in Listing 5-1, almost every attribute name begins with the android prefix. The listing’s attributes include android:versionCode, android:versionName, android:minSdkVersion, android:icon, and more.
So to combine documents about lending banks and river banks, you create the XML document in Listing 5-3.
Listing 5-3: A Document with Two Namespaces
<?xml version=”1.0” encoding=”utf-8”?>
<banks xmlns:money=
“http://schemas.allmycode.com/money”
xmlns:river=
“http://schemas.allmycode.com/river”>
<money:bank>First National Bank</money:bank>
<money:bank>Second Regional Bank</money:bank>
<money:bank>
United Trustworthy Trusty Trust
</money:bank>
<money:bank>
Federal Bank of Fredonia (Groucho Branch)
</money:bank>
<river:bank>
Banks of the Mississippi River
</river:bank>
<river:bank>La Rive Gauche</river:bank>
<river:bank>La Rive Droite</river:bank>
<river:bank>The Banks of Plum Creek</river:bank>
</banks>
In a name such as android:icon, the word android is a prefix, and the word icon is a local name.
At this point, the whole namespace business branches into two possibilities:
• Some very old XML software is not namespace-aware.
The original XML standard had no mention of namespaces. So the oldest XML-handling programs do nothing special with prefixes. To an old program, the names money:bank and river:bank in Listing 5-3 are simply two different names with no relationship to each other. The colons in the names are no different from the letters.
• Newer XML software is namespace-aware.
In some situations, you want the software to recognize relationships between names with the same prefixes and between identical names with different prefixes. For example, in a document containing elements named consumer:bank, investment:bank, and consumer:confidence, you may want your software to recognize two kinds of banks. You may also want your software to deal with two kinds of consumer elements.
Most modern software is namespace-aware. That is, the software recognizes that a name like river:bank consists of a prefix and a local name.
To make it easier for software to sort out an XML document’s namespaces, every namespace must be defined. In Listing 5-3, the attributes
xmlns:money=
“http://schemas.allmycode.com/money”
xmlns:river=
“http://schemas.allmycode.com/river”
define the document’s two namespaces. The attributes associate one URL with the money namespace and another URL with the river namespace. The special xmlns namespace doesn’t get defined because the xmlns namespace has the same meaning in every XML document. The xmlns prefix always means, “This is the start of an XML namespace definition.”
In Listing 5-3, each namespace is associated with a URL. So if you’re creating a new XML document, you may ask, “What if I don’t have my own domain name?” You may also ask, “What information must I post at a namespace’s URL?” And the surprising answers are “Make up one” and “Nothing.”
The string of symbols doesn’t really have to be a URL. Instead, it can be a URI — a Universal Resource Identifier. A URI looks like a URL, but a URI doesn’t have to point to an actual network location. A URI is simply a name, a string of characters “full of sound and fury” and possibly “signifying nothing.” Some XML developers create web pages to accompany each of their URIs. The web pages contain useful descriptions of the names used in the XML documents.
But most URIs used for XML namespaces point nowhere. For example, the URI http://schemas.android.com/apk/res/android in Listing 5-1 appears in almost every Android XML document. If you type that URI into the address field of your favorite web browser, you get the familiar cannot display the webpage or Server not found message.
An unbound prefix message indicates that you haven’t correctly associated a namespace found in your XML document with a URI. Some very old software (software that’s not namespace-aware) doesn’t catch errors of this kind, but most modern software does.
The package attribute
In Listing 5-1, the attribute name package has no prefix. So you might say, “What the heck! I’ll change the attribute’s name to android:package just for good measure.” But this change produces some error messages. One message reads <manifest> does not have a package attribute. What’s going on here?
In an AndroidManifest.xml file, the package attribute has more to do with Java than with Android. (The package attribute points to the Java package containing the application’s Java code.) So the creators of Android decided not to make this package attribute be part of the android namespace. The creators coded the android namespace words (such as android:versionCode and android:versionName) in some of the Android SDK files.
When you create an AndroidManifest.xml file, Eclipse starts building parts of your project immediately. The Android software compares the names in your AndroidManifest.xml file with the words in the android namespace. As soon as the Android software encounters the evil android:package (the android prefix followed by a non-android name), the software sounds the alarms.
Each Android platform, from Cupcake onward, has a file named public.xml among the files you get when you download the Android SDK. If you open a public.xml file in a text editor, you see a list of names in the android namespace.
The style attribute
The same business about not being an android name holds for style and package. A style is a collection of items (or properties) describing the look of something on the mobile device screen. A style’s XML document might contain Android-specific names, but the style itself is simply a bunch of items, not an Android property in its own right.
To see how this works, imagine creating a very simple app. The XML file describing the app’s basic layout may look like the code in Listing 5-4.
Listing 5-4: Using the style Attribute
<?xml version=”1.0” encoding=”utf-8”?>
<LinearLayout xmlns:android=
“http://schemas.android.com/apk/res/android”
android:orientation=”vertical”
android:layout_width=”fill_parent”
android:layout_height=”fill_parent”
>
<TextView
android:layout_width=”fill_parent”
android:layout_height=”wrap_content”
android:text=”@string/callmom”
style=”@style/bigmono”
/>
</LinearLayout>
In Listing 5-4, all attribute names except style (and the name android itself) are in the android namespace. The value “@style/bigmono” points Android to an XML file in your app’s res/values folder. Listing 5-5 contains a very simple file named styles.xml.
Listing 5-5: A File with Style
<?xml version=”1.0” encoding=”utf-8”?>
<resources>
<style name=”bigmono”>
<item name=”android:textSize”>50dip</item>
<item name=”android:typeface”>monospace</item>
</style>
</resources>
Again, notice the mix of words that are inside and outside of the android namespace. The words android:textSize and android:typeface are in the android namespace, and the other words in Listing 5-5 are not.
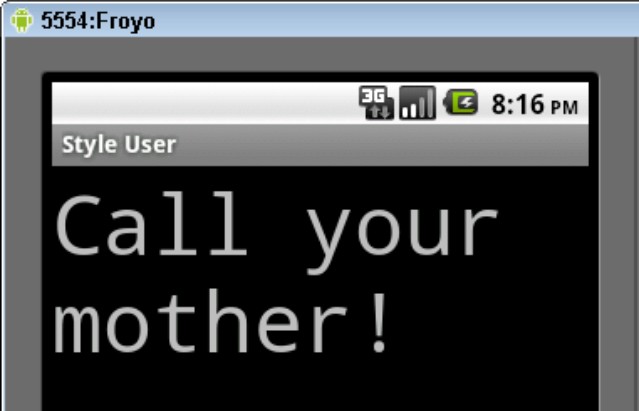
The style in Listing 5-5 specifies a whopping 50 device-independent pixels for the size of the text and monospace (traditional typewriter) font for the typeface. When Android applies the style in Listing 5-5 to the layout in Listing 5-4, you see the prominent message in Figure 5-1.
Figure 5-1: Be a good son or daughter.
 For more information about styles, layouts, device-independent pixels, and the use of XML to describe these things, see Book IV, Chapter 1.
For more information about styles, layouts, device-independent pixels, and the use of XML to describe these things, see Book IV, Chapter 1.