
Now that you know the importance of random numbers in cryptography and how to generate them, let’s look at one of the pillars of cryptography. In Chapter 2, I mentioned the four pillars of modern cryptography: cryptography, integrity, authentication, and non-repudiation. In this chapter, we explore integrity and authentication by looking at the various hashing and authenticated hashing operations available in .NET. Let’s start with integrity and hashing.
Hashing and Integrity

A hash function takes data and generates a unique hash code for it
The hash code must be easily calculated for any given input message.
You should not be able to create a message that has a specified hash code.
Any changes to the original message should completely change the hash code.
You should not be able to find two input messages that result in the same hash code.
Another way to frame the concept of a hash function is to think of it as the digital equivalent of a fingerprint for a piece of data. Once you have generated a hash code for that piece of data, the hash code is always the same if you calculate it again, unless the original data changes in any way, no matter how small that change is.
The process of calculating a hash code or digest of an item of data is straightforward in the .NET Framework or .NET Core. There are different algorithms you can use in .NET, including MD5, SHA-1, SHA-256, and SHA-512, which we explore in this chapter.
Generating a hash code for a piece of data is a one-way operation, which means that once you have calculated the hash code for a piece of data, you cannot reverse the hash code back to the original data. There is no reversal process to return hash code back to the original data. On the flip side, encryption is designed to be a two-way operation. Once you have encrypted data with a key, you can then decrypt that data using the same key or recover the original message. Encryption is covered later in this book.
The properties of hashing, such as only being able to hash in one direction, and the hash code is unique to a piece of data, makes hashing the perfect mechanism for checking the integrity of data. Integrity checking means when you send data across a network to someone else, you can use hashing as a way to tell if the original data has been tampered with or corrupted. Before sending the data, you calculate a hash of the data to get its unique fingerprint. You then send that data and the hash to the recipient. The recipient calculates the hash of the data and then compares it to the hash you sent. If the generated hash codes are identical, then the data is successfully received without data loss or corruption. If the hash codes fail to match correctly, then the data received is not the same as the data initially sent. The two most common hashing methods are MD5 and the SHA family of hashes (SHA-1, SHA-256, and SHA-512), which are all supported in .NET. Let’s look at these in more detail.
MD5
The MD5 message digest algorithm is a widely used cryptographic hash function that produces a 128-bit (16-byte) hash value, which is expressed in text format as a 32-digit hexadecimal number or as a base64-encoded string. MD5 is used in a wide variety of cryptographic applications for operating systems and large-scale enterprise systems. One of the most common uses is verifying file integrity.
MD5 was designed by Ron Rivest in 1991 to replace MD4, an earlier hash function.
A flaw in the design of MD5 was found in 1996. The flaw did not seem to be a fatal weakness, but cryptographers recommended the use of other algorithms, such as the SHA family, which we explore later in this chapter. MD5 was used commercially for a long time, but in 2004, it was discovered that MD5 is not collision-resistant, which means that it is possible that generating an MD5 hash of two sets of data could result in the same hash.
Because of this flaw, MD5 is not recommended in any new systems. It is still important to talk about its use, though, as you may still need it in applications if you are checking the integrity of data coming from a legacy system that makes use of MD5. In most companies, legacy code is something developers have to live with, which is why MD5 may still be very relevant. Old data stored in a database may contain MD5 hashes as part of the data stored in their table, and legacy code potentially checks these hashes in disparate systems. If you need to read or receive any of that data from these older systems, you need the ability to recalculate and check the same hashes.
I had this problem in a company I used to work for, which was a large Internet bank in the United Kingdom. The core banking platform lived on AS400 mainframes, and the modern website and services that the company provided were developed in .NET and ASP.NET on top of the core banking platform. This means that we frequently had to query data from the AS400 banking system. All of this data was sent with a corresponding MD5 hash of the payload, which meant to check the integrity of the financial data coming from the banking platform, we had to recalculate the MD5 hash in .NET and compare the values. If they matched, then we were happy that the data integrity was intact. The banking platform used MD5, which wasn’t going to change, so we had to accept this decision and work with it. This is why MD5 is still relevant today, but don’t use it unless you have to.
Once you have a byte array for your data, you then need to hash it. To do this with MD5, you call the static Create method on the MD5 class, which gives you an instance of a class that you can use to create the hash. Once you have that instance, you call the ComputeHash method and pass in the byte array of the data where you want the hash code created.
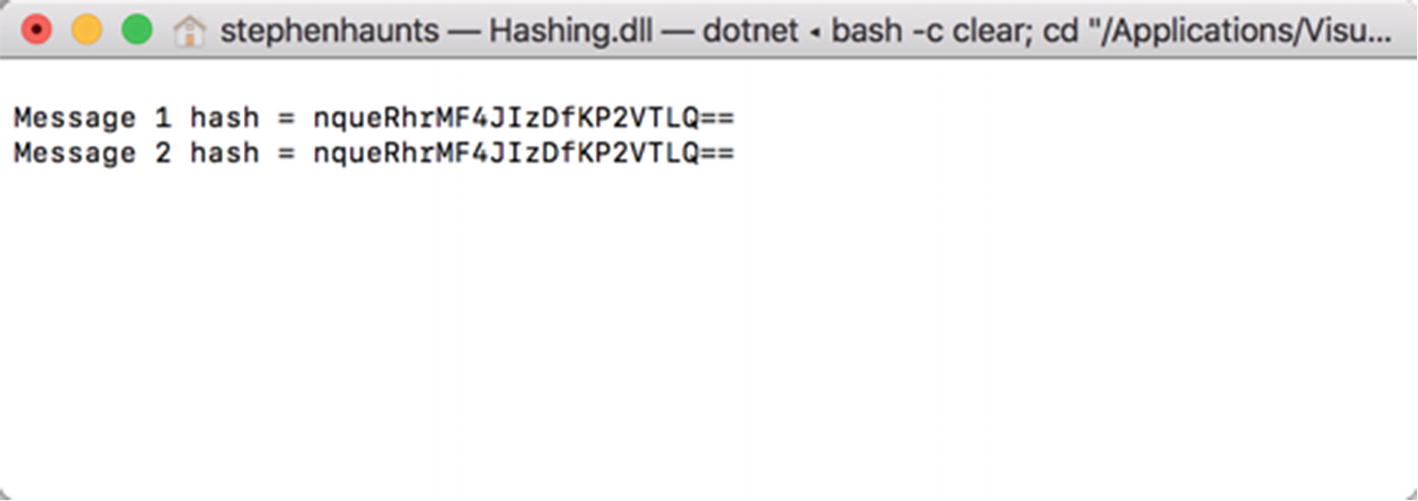
The result of running MD5 against two identical strings
If you were to change just a single character in one of those strings, then the generated hash codes would be completely different.
Secure Hash Algorithm (SHA) Family
MD5 shouldn’t be used if you can help it, but what is the available alternative in .NET? The alternative is the Secure Hash Algorithm family of hash functions, or the SHA family. The SHA family is a family of cryptographic hash functions published by the US National Institute of Standards and Technology (NIST). The premise of the SHA family of hashes is the same as with MD5. You supply some input data, run it through the hashing function, and get a hash code back. The concept is the same, but the underlying algorithm is different, and you get a much longer and more robust hash code.
SHA-1. The SHA-1 hash function produces a 160-bit (20 bytes) hash code. SHA-1 was designed by the National Security Agency to be part of the Digital Signature Algorithm (DSA). Cryptographic weaknesses were discovered in SHA-1, and the standard was no longer approved for most cryptographic uses after 2010. As with MD5, it is still around to enable integration with legacy systems that use SHA-1.
SHA-2. SHA-2 is a family of two similar hash functions with different block sizes known as SHA-256 and SHA-512. These hash functions differ in word size. SHA-256 uses 32-bit words, whereas SHA-512 uses 64-bit words. NSA designed these versions of the SHA algorithm.
SHA-3. SHA-3 was defined after a public competition to find a hashing function implementation that was not designed by NSA. The winner was chosen in 2012. It is based on a hashing implementation called Keccak. SHA-3 supports the same hash length as SHA-2, but its internal working and structure is entirely different from SHA-1 and SHA-2. SHA-3 is not currently supported in the .NET Framework directly, although third-party implementations are available.
Size of Hash Codes in Bits and Bytes
Hash Type | Size in Bits | Size in Bytes |
|---|---|---|
SHA-1 | 160 | 20 |
SHA-256 | 256 | 32 |
SHA-512 | 512 | 64 |
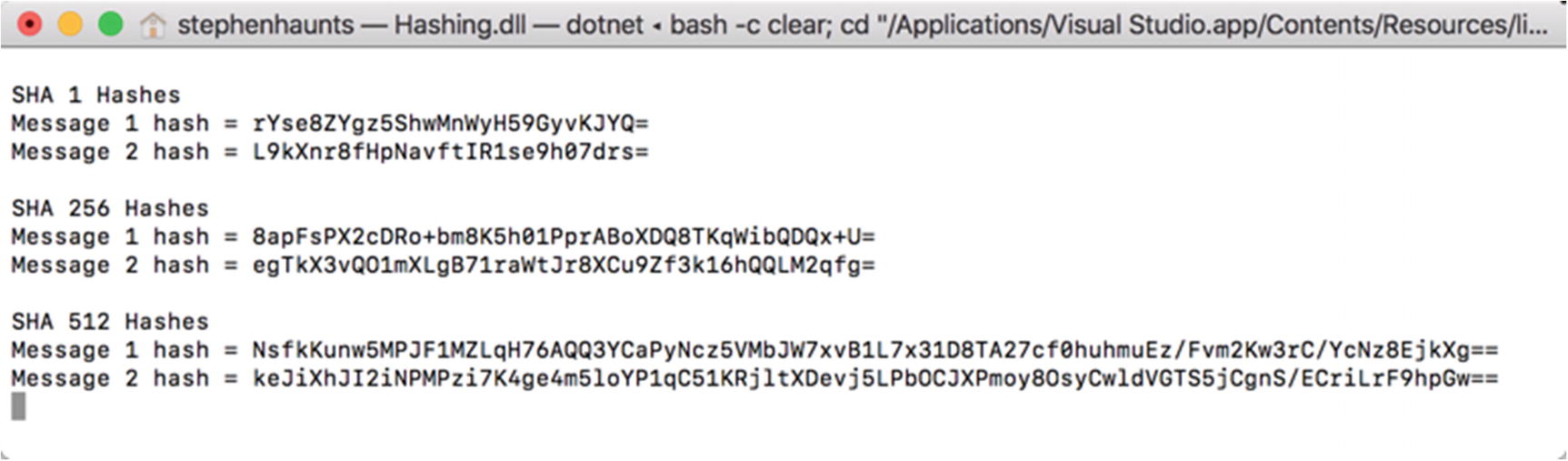
The result of running SHA family hashes against two different strings
We now have the ability to perform integrity checking through hashing. Let’s extend this capability with authentication by looking at hashed message authentication codes.
Authenticated Hashing
So far, we have covered MD5 and the SHA family of hashing functions. Their purpose is to provide integrity checking capabilities within applications to help detect if data has been tampered with or corrupted over time. What we want to do now is satisfy another of our four pillars of cryptography by talking about authentication, which naturally follows integrity.
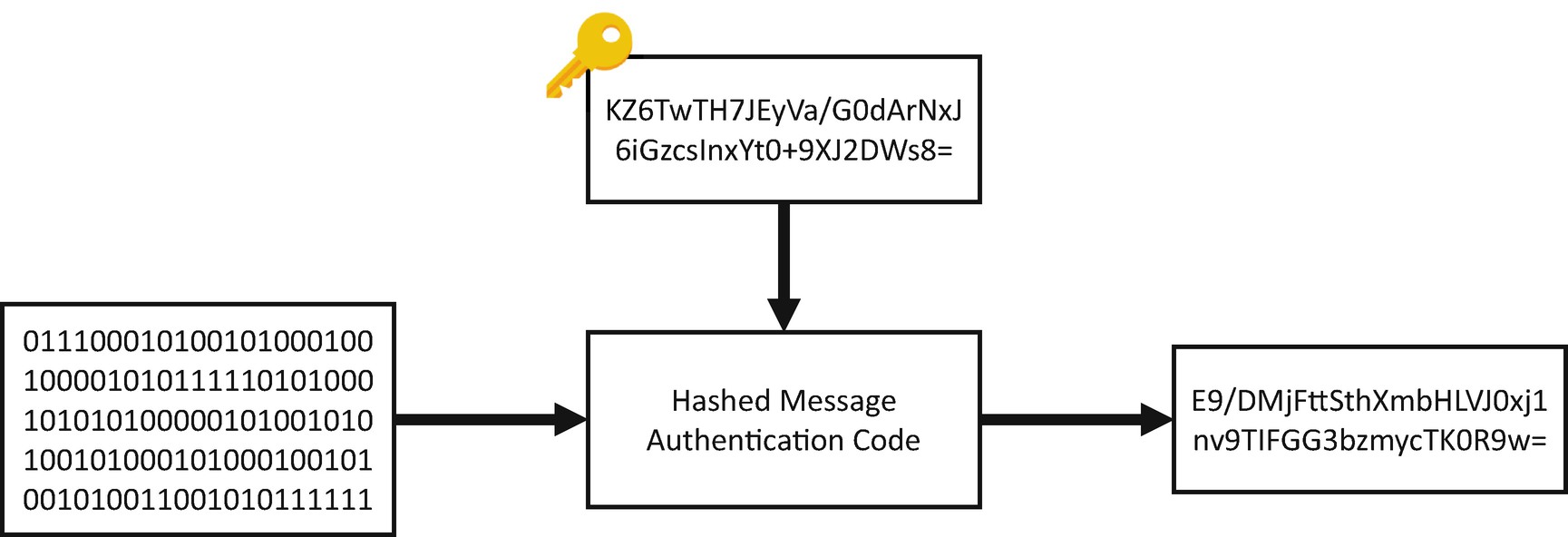
HMAC is similar to a normal hashing function, except that it takes a key as well as its input data
A HMAC also allows you to verify the authentication of a message, because only the person who knows the key can calculate the same message’s hash. Let’s walk through that with an example.
Let’s say you have a PDF file on your computer, and you calculate an HMAC of that data. To do this, you create a key using the same technique we talked about in Chapter 3. You generate a 256-bit or 32-byte random number using the RNGCryptoServiceProvider class. You take the PDF file and the key, pass it in the HMAC function, and get a hash code back. You then send the PDF to a colleague along with the key. (We won’t worry about how you send the key just yet because we tackle that problem later in the book.) Your colleague recalculates the hash code using the same key, and they receive the same hash code in response, which means they are confident that the PDF file is intact.
The same day, someone else gets hold of a copy of the PDF file and tries to calculate the same hash code. The problem is they do not have a copy of the key, so when they try to recalculate the hash code, they get a completely different response; the hash code doesn’t match for this person because they are not in possession of the correct key. This means that only the authorized person can calculate the same hash code for a file. The authorized party has a copy of the correct key.
Why does this matter so much? Well, it gives us a level of trust. If Alice and Bob are the only people who know the authentication key for the HMAC; if Alice sends Bob a message and a hash code, when Bob recalculates the hash (with the key he has), if the hashes match, Bob is confident that that data came from Alice. On the flipside to that, if our hacker, Eve, sends a message to Bob but uses a different key; when Bob recalculates the hash with the key he knows Alice has, the hash codes won’t match. If they don’t match, he shouldn’t trust the message that has been sent to him and Bob should disregard it.
I’ll summarize the fundamental differences between a standard MD5 or SHA hash and an HMAC: anyone can calculate a hash code using MD5 or SHA and get the same results for a piece of data. Only an authorized individual can generate the same hash code using an HMAC because they need to have the same key used to generate the original HMAC hash code.
A HMAC, while requiring a key to be passed in, can be used with different hashing functions like MD5 or the SHA family of algorithms. The cryptographic strength of an HMAC depends on the size of the key that is used for the hash. When I use a HMAC in the systems I develop, I tend to use a 32-byte random number. Another common way to provide a key is a standard password that is first hashed with SHA-256, and then the hashed password is used as the key. If you need an ordinary person to provide a key, then using passwords is common, but then you have the problem of weak passwords to deal with. I talk about passwords and password storage in the next chapter.
The most common attack against an HMAC is a brute-force attack to uncover the key. A brute-force attack involves trying multiple combinations of a key until you find the correct key. The attacker tries to find a new key by iterating in a loop, and then compares the hash code output with the original hash code. This is why using a secure key such as a 32-byte randomly generated key is better; the chances of finding the correct key are significantly harder.
Passwords, on the other hand, are much easier to crack because the attacker can use a dictionary attack to recover the password. This is where a vast precomputed list of passwords and their corresponding hashes are stored. The attacker then checks to see if the hash code for the key is in the dictionary. If it is, they know the key. The dictionaries contain several gigabytes of precomputed passwords, including all the common variants in which people switch vowels into numbers or insert an exclamation mark at the end of the password.
Earlier I said that one of the requirements for a hashing algorithm is to not produce a hash code that is the same for two different pieces of original data, which is called a hash collision . Hash collisions are one of the main reasons why MD5 is no longer recommended. HMACs are substantially less affected by hash collisions than their underlying hashing algorithms, such as MD5 or SHA, because you are also using a key to add entropy to the source data being hashed.
In the following example, we look at how to use the different HMAC variants available in .NET. First, we have a class called Hmac. This class has everything needed to perform a hashed message authentication code, including the generation of a random number key. The code in GenerateKey is identical to the random number generator we used in Chapter 3. In this example, we use RNGCryptoServiceProvider to generate a fixed-size 32 byte or 256 bit key. The key doesn’t have to be this size, but I always default to 32 bytes because it is more impervious to a brute-force attack. You can make the key longer if you wish, or you can make it shorter, but personally, I wouldn’t go shorter than 32 bytes.
Next, we have the code to generate an HMAC based on the SHA-256 algorithm. First, an instance of the HMACSHA256 class is instantiated with the key passed into the constructor. Next, you call ComputeHash by passing in a byte array of the data you want hashed. Again, if your data is not represented as a byte array, you need to convert it. When ComputeHash finishes, it returns a byte array with the final hash code. The fundamental difference from ordinary hashing is that this hash is dependent on the key that is generated, so if the recipient of the hash wants to calculate the same hash code for the same input data, they need a copy of that key.
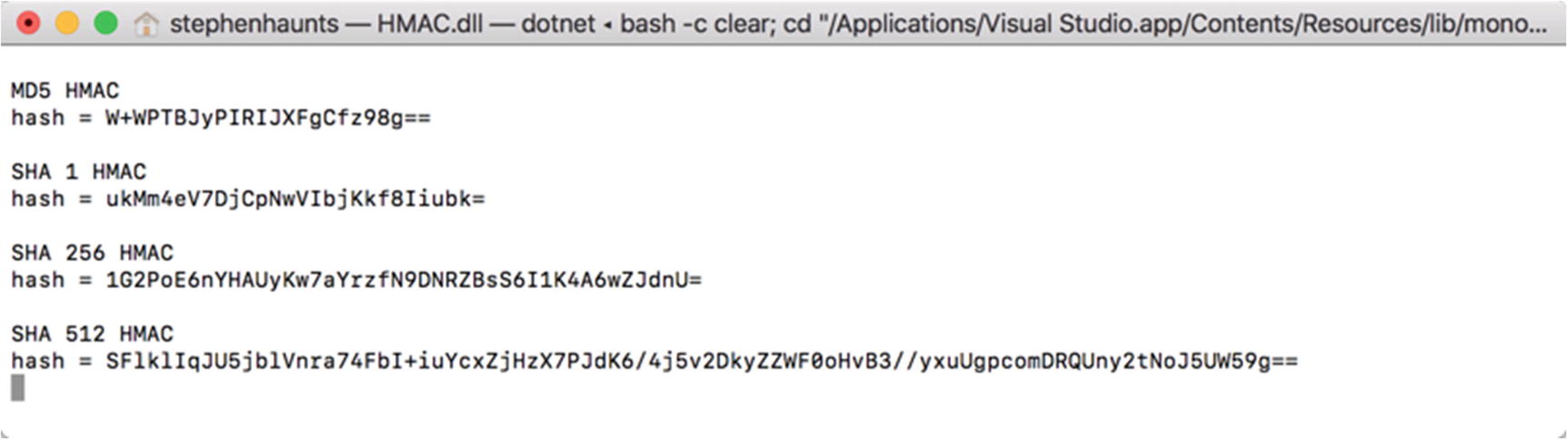
The result of running HMACs for our input data with a precomputed key
Summary
In this chapter, we explored classes in .NET to help satisfy two of the four pillars of cryptography: integrity and authentication. We used hashing algorithms such as MD5 and the SHA family of hashes to accomplish our integrity checking. The benefit of integrity checking is that if you’re sending data to another system or person, you can calculate a hash code of that data before sending it. The recipient can then recalculate the hash code from the data they receive and compare it to the original hash code sent to them. If they match, then the data wasn’t tampered with or corrupted.
Hashing functions, such as MD5 and the SHA hashes, work by passing source data into the hashing function, and then getting a unique hash code returned for that data. It should not be possible to produce the same hash for two different pieces of source data; if you encounter this, it is called a hash collision. MD5 is susceptible to this problem, which is why it is not recommended to use it in new applications. We covered how to use MD5 because you will most likely need it when interfacing with legacy systems. The recommendation is to use the SHA family of hashes, ideally SHA-256.
Then, I introduced authentication. Hashed message authentication codes, or HMACs for short, extend the hashing concept by providing a key as well as the original data that you want to hash. This gives us a unique property in that the recipient can only recalculate the same hash for some data if they are in possession of the key. If they don’t have the key or an incorrect key, then the resulting hash code will be different. This has another unique property in that if the recipient can recalculate the correct hash code with their key, then they have a level of confidence that the correct person sent the message. If an imposter sent the message and hash code, they would have a different key, provider the originator had kept their key safe. I cover the safe storage of keys later in the book.
In the next chapter, we build upon what we have covered in this chapter by talking about secure password storage.