
6
Financial Risk Modeling and Portfolio Optimization Using R
6.1 Introduction to the Optimization Process
6.1.1 Classical Optimization Approach in Mathematics
Generally, an optimization process may be represented in the following way:
- Given: a function f: A → R from some set A to the set of all real numbers R.
- To find:
- “Maximization”: An element x0 in A such that f(x0) ≥ f(x), for all x in A, or
- “Minimization”: An element x0 in A such that f(x0) ≤ f(x), for all x in A.
Such a formulation is called an optimization problem or a mathematical programming problem. Many theoretical as well as real-world problems may be modeled in this general approach, for example:
- A is some subset of the Euclidean space Rn, often specified by a set of constraints, equalities, or inequalities that the members of A have to satisfy.
- A feasible solution that minimizes (or maximizes) the objective function is called an optimal solution.
6.1.1.1 Global and Local Optimal Values
A real-valued function f defined on a domain X has a global (or absolute) maximum point at x1 if and only if
Similarly, the function has a global (or absolute) minimum point at x2 if and only if
The value of the function at a maximum point is called the maximum value of the function, and the value of the function at a minimum point is called the minimum value of the function.
Remarks:
- If the domain X is a metric space, then f is said to have a local (or relative) maximum point at the point x* if there exists some ε > 0 such that

- Similarly, the function has a local (or relative) minimum point at x* if

- A similar definition can be used when X is a topological space, since the definition just given can be re-expressed in terms of neighborhoods. Note that a global maximum point is always a local maximum point, and similarly for minimum points.
- In both the global and local cases, the concept of a strict extremum can be defined. For example, x* is a strict global maximum point if, for all x in X with x ≠ x*, one has f(x*) > f(x), and x* is a strict local maximum point if there exists some ε > 0 such that, for all x in X within distance ε of x* with x ≠ x*, one has f(x*) > f(x).
- A point is a strict global maximum point if and only if it is the unique global maximum point, and similarly for minimum points.
- Conventional optimization problems are usually stated in terms of minimization. Generally, unless both the objective function and the feasible region are convex in a minimization problem, there may be several local minima.
- If the domain X is a metric space, then f is said to have a local (or relative) maximum point at the point x* if there exists some ε > 0 such that

- Similarly, the function has a local minimum point at x* if

6.1.1.2 Graphical Illustrations of Global and Local Optimal Value
The foregoing concepts of global and local maximum or minimum are illustrated in Figure 6.1.
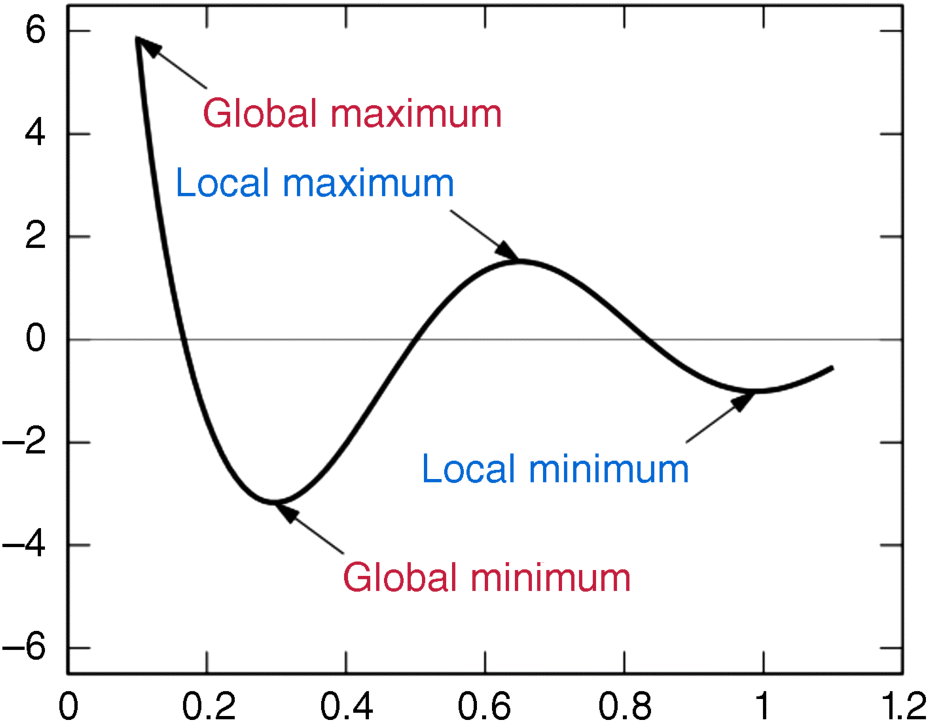
Figure 6.1 Local and global maxima and minima for cos(3πx)/x, 0.1 ≤ x ≤ 1.1.
6.1.2 Locating Functional Maxima and Minima
- Finding global maxima and minima is the aim of mathematical optimization. If a function is continuous on a closed interval, then by the extreme value theorem global maxima and minima exist.
- Also, a global maximum (or minimum) must either be a local maximum (or minimum) in the interior of the domain or must lie on the boundary of the domain. Hence, an approach for finding a global maximum (or minimum) is to examine all the local maxima (or minima) in the interior, and also look at the maxima (or minima) of the points on the boundary, and select the largest (or smallest) one.
- For any function that is defined piecewise, one finds a maximum (or minimum) by finding the maximum (or minimum) of each piece separately, and then seeing which one is largest (or smallest).
- These concepts are illustrated in Figure 6.2.

Figure 6.2 Graph of a paraboloid given by z = f(x, y) = − (x2 + y2) + 4. The global maximum at (x, y, z) = (0, 0, 4) is indicated by a blue dot.
6.2 Optimization Methodologies in Probabilistic Calculus for Financial Engineering
Preamble Since classical mathematical optimization techniques are generally built upon the approach of locating the minima at the turning points (at which the gradients are zeros), it is implicitly assumed that these minima do exist! However, in probabilistic calculus, such minima, or even such turning points, may not exist or may not be readily located. Heuristic approaches may have to be called upon to locate any existing and available minima.
Some useful heuristic methodology in locating minima, and the corresponding R programs for minimization are discussed in the following sections.
6.2.1 The Evolutionary Algorithms (EA)
Optimization algorithms inspired by the process of natural selection have been in use since the 1950s, and are often referred to as evolutionary algorithms. The genetic algorithm is one such method, and was invented by Holland in the 1960s. Genetic algorithms apply logical operations, usually on bit strings of fixed or variable lengths, in order to perform crossover, mutation, and selection on a population. Following successive generations, the members of the population are more likely to represent a minimum of an objective function. Genetic algorithms have shown to be useful heuristic methods for global optimization, in particular for combinatorial optimization problems. Evolution strategies are another variety of evolutionary algorithm. Genetic algorithms apply logical operations, usually on bit strings of fixed or variable length, in order to perform crossover, mutation, and selection on a population. Following successive generations, the members of the population are more likely to represent a minimum of an objective function.
Genetic algorithms are useful heuristic methods for global optimization, in particular for combinatorial optimization problems.
6.2.2 The Differential Evolution (DE) Algorithm
Another useful approach in portfolio optimization, particularly in assessing the equal risk contributions to the portfolio, is the differential evolution (DE) algorithm, introduced by Storn and Ulrich (1997), with its application demonstrated by Price, et al. (2006). It is considered to be a genetic algorithm, and is a derivative-free global optimizer.
The DEoptim implementation of DE was motivated by the objective of extending the set of algorithms available for global optimization in the R language and environment for statistical computing (R Development Core Team 2009). R enables rapid prototyping of objective functions, access to a wide array of tools for statistical modeling, and ability to generate customized plots of results with ease (which in many situations makes use of R preferable over the use of programs in languages like Java, MS Visual C++, Fortran 90, or Pascal). DEoptim is available at http://CRAN.R-project.org/package=DEoptim.
6.3 Financial Risk Modeling and Portfolio Optimization
In the real world of financial engineering, most private investors work through one or more “financial advisors', which, in turn, work with “wealth management corporations.”
The following is an example of a typical financial advisor (Crystal Cove Advisors of Newport Beach, California), which invests via large professional organizations (such as the LPL Financial of San Diego, California).
6.3.1 An Example of a Typical Professional Organization in Wealth Management
6.3.1.1 LPL (Linsco Private Ledger) Financial
From Wikipedia (Figure 6.3):

Figure 6.3 LPL Financial.
LPL Financial is one of the largest organizations of independent financial advisors in the United States of America. Formed in 1989 through the merger of two brokerage companies – Linsco (established in 1968) and Private Ledger (established in 1973) – LPL has since expanded its number of independent financial advisors to more than 14,000. LPL Financial has main offices in
- Boston, MA,
- Charlotte, NC, and
- San Diego, CA
covering the eastern, southern, and western regions of the United States, respectively, as well as other associated territories.
Approximately 3500 employees support financial advisors, financial institutions, and technology, custody, and clearing service subscribers with enabling technology, comprehensive clearing, and compliance services, practice management programs and training, and independent research.
LPL Financial advisors support clients with a number of financial services, including equities, bonds, mutual funds, annuities, insurance, and fee-based programs. However, LPL Financial does not develop its own investment products, thus enabling the firm's investment professionals to offer financial ostensibly free from broker/dealer-inspired conflicts of interest.
Additional information on LPL
- Recent Timeline
- Some Important Statistics
- External links
6.3.1.1.1 Recent Timeline
In 1989, LPL Financial was created through the merger of two small brokerage firms Linsco and Private Ledger.
In 2003, LPL Financial acquired Private Trust Company, which manages trusts and family assets for high-net-worth clients in all 50 states.
In 2004, LPL Financial acquired the broker/dealer operations of the Phoenix Companies, which offered Phoenix the chance to sell its products through the LPL Financial network.
In 2005, private equity firms Hellman & Friedman and Texas Pacific Group took a 60% stake in the firm.
In August 2006, LPL Financial expanded its client base following the purchase of UVEST Financial Services, which provided independent brokerage services to more than 300 regional and community banks and credit unions throughout the United States.
In June 2007, LPL Financial finalized its acquisition of several broker/dealers under the Pacific Select Group (aka Pacific Life) umbrella, which added 2000 financial advisors.
In September 2007, LPL Financial and Sun Life Financial announced a definitive agreement under which an affiliate of LPL Financial acquired Independent Financial Marketing Group, Inc. (IFMG) from Sun Life Financial. Sun Life Financial is a leading international financial services organization. The LPL Financial Institution Services business unit, which manages the IFMG business, is the nation's top provider of investment and insurance services to banks and credit unions. The deal closed in November 2007.
On January 1, 2008, Linsco/Private Ledger Corp. (LPL Financial Services) changed its brand name to “LPL Financial.”
On November 18, 2010, LPL Investment Holdings Inc., the parent company of LPL Financial, become a publicly traded company on the NASDAQ Stock Market under ticker symbol LPLA.
In 2011, LPL Financial acquired New Jersey-based Concord Capital Partners, which helps trust companies automate the business practices of their internal investment management activities.
In January 2012, LPL Financial acquired Rockville-based Fortigent, which provides high-net-worth solutions and consulting services to RIAs, banks, and trust companies.
In November 2015, LPL Financial announced its first advisor online tool suite certification for Investment Support Services.
6.3.1.1.2 Some Important Statistics
Key facts regarding LPL Financial include the following:
- 4.5 million funded accounts
- 14,000 financial advisors supported
- Approximately 4500 technology, custody, and clearing service subscribers
- Approximately 700 financial institution partners
- $475 billion in advisory and brokerage assets
6.3.1.1.3 External links
- LPL Financial Web site
- LPL Financial recruiting Web site
As an example of a typical independent “Financial Advisor” serving the public (for a fee), through LPL, consider the following
Crystal Cove Advisors
- Crystal Cove Advisors is an investment management firm located in Newport Beach, California. Its team of professionals will provide clients with investment strategies that focus on limiting risk while seeking profitable results. It believes that avoiding serious loss is the best way to increase long-term returns.
- The financial markets are ever-changing with new challenges constantly presenting themselves. The reactions to these challenges are not always rational, but they are often volatile. For years, the investment community has championed a “buy and hold” strategy, which suggests that over the long term volatility is just noise and returns will be positive. At Crystal Cove Advisors one could not disagree more! The buy and hold philosophy has serious flaws in practice. It fails to account for the behavioral nature of the financial markets and the emotional reactions that follow. The majority of investment mistakes are made when an investor sees significant loss of principal, this stress turns “buy and hold” into “buy high and sell low – thus becoming victims of the BLASH (buy low and sell high) theory. ” Crystal Cove Advisors recognizes the difficulties that negative market cycles present; thus one should place the focus on risk and employ tactical strategies that place capital preservation as the top priority.
- At Crystal Cove Advisors, a three-step process is used, specific to each client:
- Portfolio Analysis to determine risk tolerance and current exposure
- Portfolio Construction to establish allocation parameters and stress testing
- Portfolio Management to implement and adjust risk exposure as market cycles change.
- The goal of Crystal Cove Advisors is a service that provides the following:
- An asset allocation and portfolio optimization wealth-advising platform
- Financial confidence to all clients so they can be totally free to focus on life and family.
-
Disclosures to All Clients
No strategy assures success, or can guarantee protection against loss.
Tactical allocation may involve more frequent buying and selling of assets that can lead to higher transaction costs. Investors are advised to consider the tax consequences of moving positions more frequently.
- R version 3.2.2 (2015-08-14) -- “Fire Safety”
- Copyright (C) 2015 The R Foundation for Statistical ComputingPlatform: i386-w64-mingw32/i386 (32-bit)
R is free software and comes with ABSOLUTELY NO WARRANTYYou are welcome to redistribute it under certain conditions.Type 'license()' or 'licence()' for distribution details. Natural language support but running in an English locale. R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications.Type 'demo()' for some demos, 'help()' for on-line help, or'help.start()' for an HTML browser interface to help.Type 'q()' to quit R.
6.4 Portfolio Optimization Using R1
6.4.1 Portfolio Optimization by Differential Evolution (DE) Using R
In 1997, Storn and Price developed an evolution strategy they termed differential evolution (DE). This approach searches the global optimum of a real-valued function of real-valued parameters, and does not require that the function be either continuous or differentiable. This technique has been successfully applied in a wide variety of fields, from computational physics to operations research.
The DEoptim implementation of DE extended the set of algorithms available for global optimization in the R environment for statistical computing.
In the DE algorithm, each generation transforms a set of parameter vectors, called the population, into another set of parameter vectors, the members of which are more likely to minimize the objective function, as follows:
- To generate a new parameter vector NP, DE transforms an old parameter vector with the scaled difference of two randomly selected parameter vectors. The variable NP represents the number of parameter vectors in the population.
- At generation 0, NP assumes that the optimal value of the parameter vector are made
- either using random values between upper and lower bounds for each parameter
- or using values given by the analyst.
Each generation involves creating a new population from the current population members xi,g, where
- i indicates the vectors that make up the population and
- g indicates the generation.
This is achieved by the differential mutation of the population members:
A trial mutant parameter vector vi,g is created by choosing three members of the population: xr0,g, xr1,g, and xr2,g at random. Then vi,g is generated as
(6.1)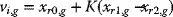
where K is a positive scaling factor. Effective values of K are typically less than 1.
- This mutation is continued until either length(x) mutations have been made or
(6.2)
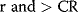
where
- CR is a cross over probability
(6.3)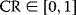
and where rand denotes a random number from U(0, 1).
- The crossover probability CR controls the fraction of the parameter values that are copied from the mutant. CR approximates (but does not exactly represent) the probability that a parameter value will be inherited from the mutant, since at least one mutation always occurs. Mutation is applied in this way to each member of the population.
- If an element vj of the parameter vector is found to exceed the bounds after mutation and crossover, it is reset, where j is to index a parameter vector.
- When using DEoptim
- if vj > upperj, it is reset as vj = upperj − rand · (upperj − lowerj) and
- if vj < lowerj, it is reset as vj = lowerj + rand · (upperj − lowerj).
This guarantees that candidate population members found to violate the bounds are set some random amount away from them, in such a way that the bounds are guaranteed to be satisfied. Then the objective function values associated with the children v are determined.
- If a trial vector vi,g has equal or lower objective function value than the vector xi,g, then vi,g replaces xi,g in the population; otherwise xi,g remains.
- The algorithm automatically terminates after some set number of generations, or after the objective function value associated with the best member has been reduced below some preset threshold, or if it is unable to reduce the best member by a certain value over a specified number of iterations.
- Applying the R code DEoptim in portfolio optimisation
Remarks:
- At present, there are two versions of R codes for DE on the Comprehensive R Archive Network (CRAN):
- DEoptim: Global Optimization by Differential Evolution – By implementing the differential evolution algorithm for global optimization of a real-valued function of a real-valued parameter vector: published on September 7, 2015, by D. Ardia, K. Mullen, B. Peterson, J. Ulrich, and K. Boudt.
- DEoptimR: Differential Evolution Optimization in Pure R – An implementation n of a variant of the differential evolution stochastic algorithm for global optimization of nonlinear programming problems: published on July 1, 2016, by E. L. T. Conceicao and M. Maechler.
- For the DEoptim code
| Version: | 2.2-3 |
| : | foreach, iterators |
| Published: | 2015-01-09 |
6.4.2 Portfolio Optimization by Special Numerical Methods
Numerical financial modeling is the building of an abstract representation or model of a real-world financial situation. This is a mathematical model for representing the performance of a financial asset or portfolio of an investment. Financial modeling is applicable to different areas of finance, including the following:
- Accounting and corporate finance applications
- Quantitative finance applications.
Financial modeling may mean an exercise in either asset pricing or corporate finance, of a quantitative nature. It is concerned with the modeling of a set of hypotheses about the behavior of markets or agents into numerical predictions. For example, a corporation's decisions about investments (the corporation will invest 25% of assets) or investment returns (returns on Stock X will be 20% higher than the market's returns).
In investment banking, corporate finance, and so on, financial modeling is largely synonymous with financial statement forecasting. This usually involves the preparation of detailed company-specific models used for decision-making purposes and financial analysis.
Applications of financial modeling include:
- Financial statement analysis
- Business valuation
- Management decision making
- Capital budgeting
- Cost of capital calculations
- Project finance
- Mergers and acquisitions
- Analyst buy/sell recommendations
These models are built around financial statements; calculations and outputs are monthly, quarterly, or annual. The inputs take the form of “assumptions,” where the analyst specifies the values that will apply in each period for the following:
- External/global variables (exchange rates, tax percentage, etc.; may be considered as the model parameters), and for internal variables (wages, costs, etc.) Correspondingly, both characteristics are reflected (at least implicitly) in the mathematical form of these models: first, the models are in discrete time; second, they are deterministic.
- In many instances, such calculations are spreadsheet based, each institution having its own internal ground rules.
- At a more sophisticated level is financial modeling, also known as quantitative finance, which is, in reality, mathematical modeling. A general distinctions are made among the following:
- Quantitative Financial Management: Models of the financial situation of a large, complex firm
- Quantitative Asset Pricing: Models of the returns of different stocks
- Financial Engineering: Models of the price or returns of derivative securities
These problems are generally probabilistic/stochastic and continuous in nature, and models here require complex algorithms, entailing finance. Modellers are generally referred to as “quants” (quantitative analysts), and typically have advanced academic degrees such as Master of Quantitative Finance, Master of Computational Finance, or Master of Financial Engineering. Not a few are at the Ph.D. level in quantitative disciplines such as mathematics, statistics, physics, engineering, computer science, operations research, and so on.
Alternatively, or in addition to their quantitative background, they complete a finance masters with a quantitative orientation.
6.4.3 Portfolio Optimization by the Black–Litterman Approach Using R
The Black–Litterman Model
The goals of the Black–Litterrman model were
- to create a systematic method of specifying a portfolio, and then
- to incorporate the views of the analyst/portfolio manager into the estimation of market parameters.
Let,
be a set of random variables representing the returns of n assets. In the BL model, the joint distribution of A is taken to be multivariate normal, that is,
The model then considers incorporating an analyst's views into the estimation of the market mean μ. If one considers
- μ to be a random variable which is itself normally distributed, and that
- its dispersion is proportional to that of the market,
then
where π is some parameter that may be determined by the analyst by some established procedure. On this point, Black and Litterman proposed (based on equilibrium considerations) that this should be obtainable from the intercepts of the capital asset pricing model.
Next, upon the consideration that the analyst has certain subjective views on the actual mean of the return for the holding period, this part of the BL model may allow the analyst to include personal views. BL suggested that such views should best be made as linear combinations, namely, portfolios, of the asset return variable mean μ:
- Each such personal view may be allocated a certain mean-and-error, (μi, εi), so that a typical view would take the form
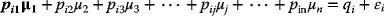
where
 .
.
The standard deviations ![]() of each view may be assumed to control the confidence in each. Expressing these views in the form of a matrix, call the “pick” matrix, one obtains the “general” view specification
of each view may be assumed to control the confidence in each. Expressing these views in the form of a matrix, call the “pick” matrix, one obtains the “general” view specification
in which Ω is the diagonal matrix diag(![]() ,
, ![]() ,
, ![]() ,…,
,…, ![]() ). It may be shown, using Bayes' law, that the posterior distribution of the market mean conditional on these views is
). It may be shown, using Bayes' law, that the posterior distribution of the market mean conditional on these views is
where
One may obtain the posterior distribution of the market by taking
independent of μ.
One may then obtain
and
6.4.3.1 A Worked Example Portfolio Optimization by the Black–Litterman Approach Using R
Portfolio optimization using the R code BLCOP that illustrates the implementation of the foregoing BL approach.
6.4.3.1.1 Introduction to the R Package BLCOP
The R package BLCOP is an implementation of the Black–Litterman (BL) and copula opinion pooling frameworks. These two methods are suitably combined in this package.
6.4.3.1.2 Overview of the Black–Litterman model
The Black–Litterman model was devised in 1992 by Fisher Black and Robert Litterman with the objective of creating a systematic method of specifying and then incorporating analyst/portfolio manager views into the estimation of market parameters.
Let
be a set of random variables representing the returns of n assets. In the BL model
- the joint distribution of A is assumed to be multivariate normal, that is,

- to incorporate an analyst's views into the estimation of the market mean μ, it is further assumed that one may take itself to be a random variable which is itself normally distributed, and moreover that its dispersion is proportional to that of the market. Thus,
where π is some underlying parameter that may be determined by the analyst using some established procedure. Black and Litterman proposed, from equilibrium considerations, that this might be obtained from the intercepts of the capital asset pricing model.

- Next, the analyst forms subjective views on the actual mean of the returns for the holding period. This is the assumption of the model that allows the analyst, or portfolio manager, to include his or her views. Moreover, BL proposed that views should be made on linear combinations (i.e., portfolios) of the asset return variable means μ.
Each view would take the form of a “mean plus error”. For example, a typical view should be expressed as follows:
where ![]() .
.
The standard deviations ![]() of each view could be taken as controlling the confidence in each view. Collecting these views into a matrix, call the “pick” matrix, one obtains the “general” view specification:
of each view could be taken as controlling the confidence in each view. Collecting these views into a matrix, call the “pick” matrix, one obtains the “general” view specification:
where Ω is the diagonal matrix diag (![]() ,
, ![]() ,
, ![]() ,…,
,…, ![]() ).
).
Based on Bayes' law, it may be shown that the posterior distribution of the market mean conditional on this approach is
where
These ideas are implemented in the BLCOP package, as shown in the following worked example.
A CRAN mirror is selected.
trying URL 'https://stat.ethz.ch/CRAN/bin/windows/contrib/3.2/BLCOP_0.3.1.zip'Content type 'application/zip' length 646041 bytes (630 KB)downloaded 630 KBpackage ‘BLCOP’ successfully unpacked and MD5 sums checkedThe downloaded binary packages are inC:UsersBertAppDataLocalTempRtmpmMX9H9downloaded_packages> library(BLCOP)Loading required package: MASSLoading required package: quadprogWarning message:package ‘BLCOP’ was built under R version 3.2.4> ls("package:BLCOP")[1] "addBLViews" "addCOPViews"[3] "assetSet" "BLCOPOptions"[5] "BLPosterior" "BLViews"[7] "CAPMList" "confidences"[9] "confidences<-" "COPPosterior"[11] "COPViews" "createBLViews"[13] "createCOPViews" "deleteViews"[15] "densityPlots" "distribution"[17] "getPosteriorEstim" "getPriorEstim"[19] "monthlyReturns" "mvdistribution"[21] "newPMatrix" "numSimulations"[23] "optimalPortfolios" "optimalPortfolios.fPort"[25] "PMatrix" "PMatrix<-"[27] "posteriorEst" "posteriorFeasibility"[29] "posteriorMeanCov" "posteriorSimulations"[31] "priorViews" "qv<-"[33] "runBLCOPTests""sampleFrom"[35] "show" "sp500Returns"[37] "updateBLViews" "US13wTB"[39] "viewMatrix"> pickMatrix <- matrix(c(1/2, -1, 1/2, rep(0, 3)), nrow = 1, ncol+ = 6)> views <- BLViews(P = pickMatrix, q = 0.06,confidences = 100,+ assetNames = colnames(monthlyReturns))> views # Outputting:1 : 0.5*IBM+-1*MS+0.5*DELL=0.06 + eps. Confidence: 100> priorMeans <- rep(0, 6)< priorVarcov <- cov.mve(monthlyReturns)$cov< marketPosterior <- posteriorEst(views = views, sigma =+ priorVarcov, mu = priorMeans, tau = 1/2)<< marketPosterior # Outputting:Prior means:IBM MS DELL C JPM BAC0 0 0 0 0 0Posterior means:IBM MS DELL C JPM BAC0.0040334203 -0.0083696450 0.0114088881 -0.0008696187 -0.0031865767 0.0008424655Posterior covariance:IBM MS DELL C JPM BACIBM 0.014968077 0.010859214 0.011769151 0.010298180 0.007407937 0.003690800MS 0.010859214 0.018563403 0.015853209 0.010405993 0.011377177 0.004699313DELL 0.011769151 0.015853209 0.034133394 0.009431736 0.011381346 0.006756110C 0.010298180 0.010405993 0.009431736 0.010811254 0.008246582 0.004926015JPM 0.007407937 0.011377177 0.011381346 0.008246582 0.012875001 0.006741935BAC 0.003690800 0.004699313 0.006756110 0.004926015 0.006741935 0.007630011< finViews <- matrix(ncol = 4, nrow = 1, dimnames = list(NULL,+ c("C","JPM","BAC","MS")))> finViews[,1:4] <- rep(1/4,4)> views <- addBLViews(finViews, 0.15, 90, views)> views1 : 0.5*IBM+-1*MS+0.5*DELL=0.06 + eps. Confidence: 1002 : 0.25*MS+0.25*C+0.25*JPM+0.25*BAC=0.15+ eps. Confidence: 90>> marketPosterior <- BLPosterior(as.matrix(monthlyReturns),+ views, tau = 1/2,+ marketIndex = as.matrix(sp500Returns),riskFree =+ as.matrix(US13wTB))>>> BLPosterior # Output:function (returns, views, tau = 1, marketIndex, riskFree = NULL,kappa = 0, covEstimator = "cov"){covEstimator <- match.fun(covEstimator)alphaInfo <- CAPMList(returns, marketIndex, riskFree = riskFree)post <- posteriorEst(views, tau = tau, mu = alphaInfo[["alphas"]],sigma = unclass(covEstimator(returns)), kappa = kappa)post}<environment: namespace:BLCOP>>> marketPosterior <- BLPosterior(as.matrix(monthlyReturns),+ views, tau = 1/2,+ marketIndex = as.matrix(sp500Returns),riskFree =+ as.matrix(US13wTB))> marketPosteriorPrior means:IBM MS DELL C JPM BAC0.020883598 0.059548398 0.017010062 0.014492325 0.027365230 0.002829908Posterior means:IBM MS DELL C JPM BAC0.06344562 0.07195806 0.07777653 0.04030821 0.06884519 0.02592776Posterior covariance:IBM MS DELL C JPM BACIBM 0.021334221 0.010575532 0.012465444 0.008518356 0.010605748 0.005281807MS 0.010575532 0.031231768 0.017034827 0.012704758 0.014532900 0.008023646DELL 0.012465444 0.017034827 0.047250599 0.007386821 0.009352949 0.005086150C 0.008518356 0.012704758 0.007386821 0.016267422 0.010968240 0.006365457JPM 0.010605748 0.014532900 0.009352949 0.010968240 0.028181136 0.011716834BAC 0.005281807 0.008023646 0.005086150 0.006365457 0.011716834 0.011199343>## Optimization of Portfolios:# The fPortfolio package, in CRAN, of the Rmetrics project# RmCTWu09, has many functionalities available for portfolio# optimization. The approach of this package will be used# hereinafter.>> install.packages("fPortfolio")Installing package into ‘C:/Users/Bert/Documents/R/win-library/3.2’(as ‘lib’ is unspecified)trying URL 'https://stat.ethz.ch/CRAN/bin/windows/contrib/3.2/fPortfolio_3011.81.zip'Content type 'application/zip' length 1066509 bytes (1.0 MB)downloaded 1.0 MBpackage ‘fPortfolio’ successfully unpacked and MD5 sums checkedThe downloaded binary packages are inC:UsersBertAppDataLocalTempRtmpmMX9H9downloaded_packages> library(fPortfolio)Loading required package: timeDateLoading required package: timeSeriesLoading required package: fBasicsRmetrics Package fBasicsAnalysing Markets and calculating Basic StatisticsCopyright (C) 2005-2014 Rmetrics Association ZurichEducational Software for Financial Engineering and ComputationalScienceRmetrics is free software and comes with ABSOLUTELY NOWARRANTY.https://www.rmetrics.org --- Mail to: [email protected]Loading required package: fAssetsRmetrics Package fAssetsAnalysing and Modeling Financial AssetsCopyright (C) 2005-2014 Rmetrics Association ZurichEducational Software for Financial Engineering and ComputationalScienceRmetrics is free software and comes with ABSOLUTELY NOWARRANTY.https://www.rmetrics.org --- Mail to: [email protected]Rmetrics Package fPortfolioPortfolio OptimizationCopyright (C) 2005-2014 Rmetrics Association ZurichEducational Software for Financial Engineering and Computational ScienceRmetrics is free software and comes with ABSOLUTELY NOWARRANTY.https://www.rmetrics.org --- Mail to: [email protected]Warning messages:1: package ‘fPortfolio’ was built under R version 3.2.42: package ‘timeDate’ was built under R version 3.2.33: package ‘timeSeries’ was built under R version 3.2.34: package ‘fBasics’ was built under R version 3.2.35: package ‘fAssets’ was built under R version 3.2.3> ls("package:fPortfolio") # Output:[1] "addRainbow"[2] "amplDataAdd"[3] "amplDataAddMatrix"[4] "amplDataAddValue"[5] "amplDataAddVector"[6] "amplDataOpen"[7] "amplDataSemicolon"[8] "amplDataShow"[9] "amplLP"[10] "amplLPControl"[11] "amplModelAdd"[12] "amplModelOpen"[13] "amplModelShow"[14] "amplNLP"[15] "amplNLPControl"[16] "amplOutShow"[17] "amplQP"[18] "amplQPControl"[19] "amplRunAdd"[20] "amplRunOpen"[21] "amplRunShow"[22] "backtestAssetsPlot"[23] "backtestDrawdownPlot"[24] "backtestPlot"[25] "backtestPortfolioPlot"[26] "backtestRebalancePlot"[27] "backtestReportPlot"[28] "backtestStats"[29] "backtestWeightsPlot"[30] "bcpAnalytics"[31] "bestDiversification"[32] "budgetsModifiedES"[33] "budgetsModifiedVAR"[34] "budgetsNormalES"[35] "budgetsNormalVAR"[36] "budgetsSampleCOV"[37] "cmlLines"[38] "cmlPoints"[39] "covEstimator"[40] "covMcdEstimator"[41] "covOGKEstimator"[42] "covRisk"[43] "covRiskBudgetsLinePlot"[44] "covRiskBudgetsPie"[45] "covRiskBudgetsPlot"[46] "cvarRisk"[47] "Data"[48] "donlp2NLP"[49] "donlp2NLPControl"[50] "drawdownsAnalytics"[51] "ECON85"[52] "ECON85LONG"[53] "efficientPortfolio"[54] "emaSmoother"[55] "eqsumWConstraints"[56] "equalWeightsPoints"[57] "equidistWindows"[58] "feasibleGrid"[59] "feasiblePortfolio"[60] "frontierPlot"[61] "frontierPlotControl"[62] "frontierPoints"[63] "garchAnalytics"[64] "GCCINDEX"[65] "GCCINDEX.RET"[66] "getA"[67] "getA.fPFOLIOSPEC"[68] "getA.fPORTFOLIO"[69] "getAlpha"[70] "getAlpha.fPFOLIOSPEC"[71] "getAlpha.fPFOLIOVAL"[72] "getAlpha.fPORTFOLIO"[73] "getConstraints"[74] "getConstraints.fPORTFOLIO"[75] "getConstraintsTypes"[76] "getControl"[77] "getControl.fPFOLIOSPEC"[78] "getControl.fPORTFOLIO"[79] "getCov"[80] "getCov.fPFOLIODATA"[81] "getCov.fPORTFOLIO"[82] "getCovRiskBudgets"[83] "getCovRiskBudgets.fPFOLIOVAL"[84] "getCovRiskBudgets.fPORTFOLIO"[85] "getData"[86] "getData.fPFOLIODATA"[87] "getData.fPORTFOLIO"[88] "getEstimator"[89] "getEstimator.fPFOLIODATA"[90] "getEstimator.fPFOLIOSPEC"[91] "getEstimator.fPORTFOLIO"[92] "getMean"[93] "getMean.fPFOLIODATA"[94] "getMean.fPORTFOLIO"[95] "getMessages"[96] "getMessages.fPFOLIOBACKTEST"[97] "getMessages.fPFOLIOSPEC"[98] "getModel.fPFOLIOSPEC"[99] "getModel.fPORTFOLIO"[100] "getMu"[101] "getMu.fPFOLIODATA"[102] "getMu.fPORTFOLIO"[103] "getNAssets"[104] "getNAssets.fPFOLIODATA"[105] "getNAssets.fPORTFOLIO"[106] "getNFrontierPoints"[107] "getNFrontierPoints.fPFOLIOSPEC"[108] "getNFrontierPoints.fPFOLIOVAL"[109] "getNFrontierPoints.fPORTFOLIO"[110] "getObjective"[111] "getObjective.fPFOLIOSPEC"[112] "getObjective.fPORTFOLIO"[113] "getOptim"[114] "getOptim.fPFOLIOSPEC"[115] "getOptim.fPORTFOLIO"[116] "getOptimize"[117] "getOptimize.fPFOLIOSPEC"[118] "getOptimize.fPORTFOLIO"[119] "getOptions"[120] "getOptions.fPFOLIOSPEC"[121] "getOptions.fPORTFOLIO"[122] "getParams"[123] "getParams.fPFOLIOSPEC"[124] "getParams.fPORTFOLIO"[125] "getPortfolio"[126] "getPortfolio.fPFOLIOSPEC"[127] "getPortfolio.fPFOLIOVAL"[128] "getPortfolio.fPORTFOLIO"[129] "getRiskFreeRate"[130] "getRiskFreeRate.fPFOLIOSPEC"[131] "getRiskFreeRate.fPFOLIOVAL"[132] "getRiskFreeRate.fPORTFOLIO"[133] "getSeries"[134] "getSeries.fPFOLIODATA"[135] "getSeries.fPORTFOLIO"[136] "getSigma"[137] "getSigma.fPFOLIODATA"[138] "getSigma.fPORTFOLIO"[139] "getSmoother"[140] "getSmoother.fPFOLIOBACKTEST"[141] "getSmootherDoubleSmoothing"[142] "getSmootherDoubleSmoothing.fPFOLIOBACKTEST"[143] "getSmootherFun"[144] "getSmootherFun.fPFOLIOBACKTEST"[145] "getSmootherInitialWeights"[146] "getSmootherInitialWeights.fPFOLIOBACKTEST"[147] "getSmootherLambda"[148] "getSmootherLambda.fPFOLIOBACKTEST"[149] "getSmootherParams"[150] "getSmootherParams.fPFOLIOBACKTEST"[151] "getSmootherSkip"[152] "getSmootherSkip.fPFOLIOBACKTEST"[153] "getSolver"[154] "getSolver.fPFOLIOSPEC"[155] "getSolver.fPORTFOLIO"[156] "getSpec"[157] "getSpec.fPORTFOLIO"[158] "getStatistics"[159] "getStatistics.fPFOLIODATA"[160] "getStatistics.fPORTFOLIO"[161] "getStatus"[162] "getStatus.fPFOLIOSPEC"[163] "getStatus.fPFOLIOVAL"[164] "getStatus.fPORTFOLIO"[165] "getStrategy"[166] "getStrategy.fPFOLIOBACKTEST"[167] "getStrategyFun"[168] "getStrategyFun.fPFOLIOBACKTEST"[169] "getStrategyParams"[170] "getStrategyParams.fPFOLIOBACKTEST"[171] "getTailRisk"[172] "getTailRisk.fPFOLIODATA"[173] "getTailRisk.fPFOLIOSPEC"[174] "getTailRisk.fPORTFOLIO"[175] "getTailRiskBudgets"[176] "getTailRiskBudgets.fPORTFOLIO"[177] "getTargetReturn"[178] "getTargetReturn.fPFOLIOSPEC"[179] "getTargetReturn.fPFOLIOVAL"[180] "getTargetReturn.fPORTFOLIO"[181] "getTargetRisk"[182] "getTargetRisk.fPFOLIOSPEC"[183] "getTargetRisk.fPFOLIOVAL"[184] "getTargetRisk.fPORTFOLIO"[185] "getTrace"[186] "getTrace.fPFOLIOSPEC"[187] "getTrace.fPORTFOLIO"[188] "getType"[189] "getType.fPFOLIOSPEC"[190] "getType.fPORTFOLIO"[191] "getUnits.fPFOLIODATA"[192] "getUnits.fPORTFOLIO"[193] "getWeights"[194] "getWeights.fPFOLIOSPEC"[195] "getWeights.fPFOLIOVAL"[196] "getWeights.fPORTFOLIO"[197] "getWindows"[198] "getWindows.fPFOLIOBACKTEST"[199] "getWindowsFun"[200] "getWindowsFun.fPFOLIOBACKTEST"[201] "getWindowsHorizon"[202] "getWindowsHorizon.fPFOLIOBACKTEST"[203] "getWindowsParams"[204] "getWindowsParams.fPFOLIOBACKTEST"[205] "glpkLP"[206] "glpkLPControl"[207] "ipopQP"[208] "ipopQPControl"[209] "kendallEstimator"[210] "kestrelQP"[211] "kestrelQPControl"[212] "lambdaCVaR"[213] "listFConstraints"[214] "lpmEstimator"[215] "LPP2005"[216] "LPP2005.RET"[217] "markowitzHull"[218] "maxBConstraints"[219] "maxBuyinConstraints"[220] "maxCardConstraints"[221] "maxddMap"[222] "maxFConstraints"[223] "maxratioPortfolio"[224] "maxreturnPortfolio"[225] "maxsumWConstraints"[226] "maxWConstraints"[227] "mcdEstimator"[228] "minBConstraints"[229] "minBuyinConstraints"[230] "minCardConstraints"[231] "minFConstraints"[232] "minriskPortfolio"[233] "minsumWConstraints"[234] "minvariancePoints"[235] "minvariancePortfolio"[236] "minWConstraints"[237] "modifiedVaR"[238] "monteCarloPoints"[239] "mveEstimator"[240] "nCardConstraints"[241] "neosLP"[242] "neosLPControl"[243] "neosQP"[244] "neosQPControl"[245] "netPerformance"[246] "nlminb2NLP"[247] "nlminb2NLPControl"[248] "nnveEstimator"[249] "normalVaR"[250] "parAnalytics"[251] "pcoutAnalytics"[252] "pfolioCVaR"[253] "pfolioCVaRplus"[254] "pfolioHist"[255] "pfolioMaxLoss"[256] "pfolioReturn"[257] "pfolioTargetReturn"[258] "pfolioTargetRisk"[259] "pfolioVaR"[260] "plot.fPORTFOLIO"[261] "portfolioBacktest"[262] "portfolioBacktesting"[263] "portfolioConstraints"[264] "portfolioData"[265] "portfolioFrontier"[266] "portfolioObjective"[267] "portfolioReturn"[268] "portfolioRisk"[269] "portfolioSmoothing"[270] "portfolioSpec"[271] "print.solver"[272] "quadprogQP"[273] "quadprogQPControl"[274] "ramplLP"[275] "ramplNLP"[276] "ramplQP"[277] "rdonlp2"[278] "rdonlp2NLP"[279] "rglpkLP"[280] "ripop"[281] "ripopQP"[282] "riskBudgetsPlot"[283] "riskMap"[284] "riskmetricsAnalytics"[285] "riskSurface"[286] "rkestrelQP"[287] "rneosLP"[288] "rneosQP"[289] "rnlminb2"[290] "rnlminb2NLP"[291] "rollingCDaR"[292] "rollingCmlPortfolio"[293] "rollingCVaR"[294] "rollingDaR"[295] "rollingMinvariancePortfolio"[296] "rollingPortfolioFrontier"[297] "rollingSigma"[298] "rollingTangencyPortfolio"[299] "rollingVaR"[300] "rollingWindows"[301] "rquadprog"[302] "rquadprogQP"[303] "rsolnpNLP"[304] "rsolveLP"[305] "rsolveQP"[306] "rsymphonyLP"[307] "sampleCOV"[308] "sampleVaR"[309] "setAlpha<-"[310] "setEstimator<-"[311] "setNFrontierPoints<-"[312] "setObjective<-"[313] "setOptimize<-"[314] "setParams<-"[315] "setRiskFreeRate<-"[316] "setSmootherDoubleSmoothing<-"[317] "setSmootherFun<-"[318] "setSmootherInitialWeights<-"[319] "setSmootherLambda<-"[320] "setSmootherParams<-"[321] "setSmootherSkip<-"[322] "setSolver<-"[323] "setStatus<-"[324] "setStrategyFun<-"[325] "setStrategyParams<-"[326] "setTailRisk<-"[327] "setTargetReturn<-"[328] "setTargetRisk<-"[329] "setTrace<-"[330] "setType<-"[331] "setWeights<-"[332] "setWindowsFun<-"[333] "setWindowsHorizon<-"[334] "setWindowsParams<-"[335] "sharpeRatioLines"[336] "shrinkEstimator"[337] "singleAssetPoints"[338] "slpmEstimator"[339] "SMALLCAP"[340] "SMALLCAP.RET"[341] "solnpNLP"[342] "solnpNLPControl"[343] "solveRampl.CVAR"[344] "solveRampl.MV"[345] "solveRdonlp2"[346] "solveRglpk.CVAR"[347] "solveRglpk.MAD"[348] "solveRipop"[349] "solveRquadprog"[350] "solveRquadprog.CLA"[351] "solveRshortExact"[352] "solveRsocp"[353] "solveRsolnp"[354] "spearmanEstimator"[355] "SPISECTOR"[356] "SPISECTOR.RET"[357] "stabilityAnalytics"[358] "summary.fPORTFOLIO"[359] "surfacePlot"[360] "SWX"[361] "SWX.RET"[362] "symphonyLP"[363] "symphonyLPControl"[364] "tailoredFrontierPlot"[365] "tailRiskBudgetsPie"[366] "tailRiskBudgetsPlot"[367] "tangencyLines"[368] "tangencyPoints"[369] "tangencyPortfolio"[370] "tangencyStrategy"[371] "ternaryCoord"[372] "ternaryFrontier"[373] "ternaryMap"[374] "ternaryPoints"[375] "ternaryWeights"[376] "turnsAnalytics"[377] "twoAssetsLines"[378] "varRisk"[379] "waveletSpectrum"[380] "weightedReturnsLinePlot"[381] "weightedReturnsPie"[382] "weightedReturnsPlot"[383] "weightsLinePlot"[384] "weightsPie"[385] "weightsPlot"[386] "weightsSlider">> optPorts <- optimalPortfolios.fPort(marketPosterior, optimizer+ = "tangencyPortfolio")> optPorts # Output:$priorOptimPortfolioTitle:MV Tangency PortfolioEstimator: getPriorEstimSolver: solveRquadprogOptimize: minRiskConstraints: LongOnlyPortfolio Weights:IBM MS DELL C JPM BACIBM = International Business Machines CorporationMS = Morgan StanleyDELL = Dell ComputersC = Citigroup IncorporatedJPM = J P Morgan Chase and CompanyBAC = Bank of America Corporation0.0765 0.9235 0.0000 0.0000 0.0000 0.0000Covariance Risk Budgets:IBM MS DELL C JPM BACTarget Returns and Risks:mean mu Cov Sigma CVaR VaR0.0000 0.0566 0.1460 0.0000 0.0000Description:Wed Mar 23 07:38:59 2016 by user: Bert$posteriorOptimPortfolioTitle:MV Tangency PortfolioEstimator: getPosteriorEstimSolver: solveRquadprogOptimize: minRiskConstraints: LongOnlyPortfolio Weights:IBM MS DELL C JPM BAC0.3633 0.1966 0.1622 0.0000 0.2779 0.0000Covariance Risk Budgets:IBM MS DELL C JPM BACTarget Returns and Risks:mean mu Cov Sigma CVaR VaR0.0000 0.0689 0.1268 0.0000 0.0000Description:Wed Mar 23 07:38:59 2016 by user: Bertattr(,"class")[1] "BLOptimPortfolios">Portfolio Weights:IBM MS DELL C JPM BACThe fPortfolio package of the Rmetrics project ([RmCTWu09]), for example, has a rich set of functionality available for portfolio optimization. Their 0.0765 0.9235 0.0000 0.0000 0.0000 0.0000## The selected portfolio consists of the following investments:## IBM = International Business Machine# MS = Morgan Stanley# DELL = Dell Computer# C = Citigroup Inc.# JPM = JPMorgan Chase and Company# BAC = Bank of America Corporation#Covariance Risk Budgets:IBM MS DELL C JPM BACTarget Returns and Risks:mean mu Cov Sigma CVaR VaR0.0000 0.0566 0.1460 0.0000 0.0000Description:Tue Mar 22 08:31:47 2016 by user: Bert$posteriorOptimPortfolioTitle:MV Tangency PortfolioEstimator: getPosteriorEstimSolver: solveRquadprogOptimize: minRiskConstraints: LongOnlyPortfolio Weights:IBM MS DELL C JPM BAC0.3633 0.1966 0.1622 0.0000 0.2779 0.0000Covariance Risk Budgets:IBM MS DELL C JPM BACTarget Returns and Risks:mean mu Cov Sigma CVaR VaR0.0000 0.0689 0.1268 0.0000 0.0000Description:Tue Mar 22 08:31:47 2016 by user: Bertattr(,"class")[1] "BLOptimPortfolios"> par(mfcol = c(2, 1))> # Output: Figure 6.4a: BL-1>(Providing space for following graphical outputs)> weightsPie(optPorts$priorOptimPortfolio)> # Output: Figure 6.4b: BL-2

Figure 6.4(a) BL-1: Preparing space for following plots.

Figure 6.4(b) BL-2: Output of weights pie (optPorts$priorOptimPortfolio).
>A piechart of the Relative Distributions of IBM and MS in the Optimum Portfolio>> weightsPie(optPort8s$posteriorOptimPortfolio)> # Output: Figure 6.5: BL-3
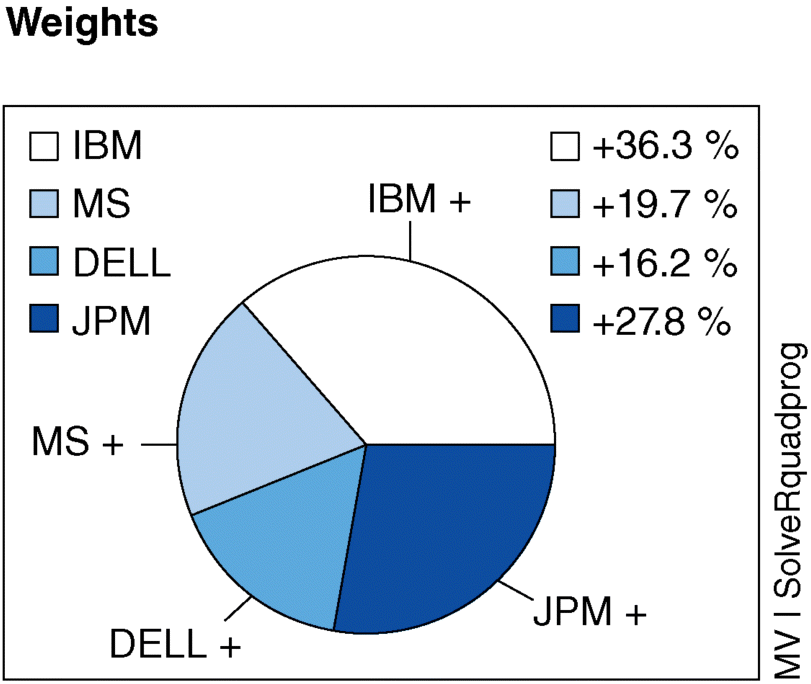
Figure 6.5 BL-3.
>> optPorts2 <- optimalPortfolios.fPort(marketPosterior,+ constraints = "minW[1:6]=0.1", optimizer = "minriskPortfolio")> optPorts2 # Output:$priorOptimPortfolioTitle:MV Minimum Risk PortfolioEstimator: getPriorEstimSolver: solveRquadprogOptimize: minRiskConstraints: minWPortfolio Weights:IBM MS DELL C JPM BAC0.1137 0.1000 0.1000 0.1098 0.1000 0.4764Covariance Risk Budgets:IBM MS DELL C JPM BACTarget Returns and Risks:mean mu Cov Sigma CVaR VaR0.0000 0.0157 0.0864 0.0000 0.0000Description:Tue Mar 22 12:12:53 2016 by user: Bert$posteriorOptimPortfolioTitle:MV Minimum Risk PortfolioEstimator: getPosteriorEstimSolver: solveRquadprogOptimize: minRiskConstraints: minWPortfolio Weights:IBM MS DELL C JPM BAC0.1000 0.1000 0.1000 0.1326 0.1000 0.4674Covariance Risk Budgets:IBM MS DELL C JPM BACTarget Returns and Risks:mean mu Cov Sigma CVaR VaR0.0000 0.0457 0.1008 0.0000 0.0000Description:Tue Mar 22 12:12:53 2016 by user: Bertattr(,"class")[1] "BLOptimPortfolios">> densityPlots(marketPosterior, assetsSel = "JPM")> # Output: Figure 6.6 BL-4

Figure 6.6 BL-4.
> dispersion c(.376,.253,.360,.333,.360,.600,.397,.396,.578,+.775) / 1000> sigma <- BLCOP:::.symmetricMatrix(dispersion, dim = 4)> caps <- rep(1/4, 4)> mu <- 2.5 * sigma %*% caps> dim(mu) <- NULL> marketDistribution <- mvdistribution("mt", mean = mu, S =+ sigma, df = 5)> class(marketDistribution)> pick <- matrix(0, ncol = 4, nrow = 1,> dimnames = list(NULL, c("SP", "FTSE", "CAC", "DAX")))> pick[1,"DAX"] <- 1> viewDist <- list(distribution("unif", min = -0.02, max = 0))> views <- COPViews(pick, viewDist = viewDist, confidences =+ 0.2, assetNames = c("SP", "FTSE", "CAC", "DAX"))> newPick <- matrix(0, 1, 2)> dimnames(newPick) <- list(NULL, c("SP", "FTSE"))> newPick[1,] <- c(1, -1) # add a relative view> views <- addCOPViews(newPick,> list(distribution("norm", mean = 0.05, sd = 0.02)), 0.5, views)> marketPosterior <- COPPosterior(marketDistribution, views,+ numSimulations = 50000)> densityPlots(marketPosterior, assetsSel = 4)> # Output: Figure 6.7 BL-5

Figure 6.7 BL-5: Density Plot.
6.4.4 More Worked Examples of Portfolio Optimization Using R
6.4.4.1 Worked Examples of Portfolio Optimization – No. 1 Portfolio Optimization by PerformanceAnalytics in CRAN
The R package PerformanceAnalytics, is a collection of econometric functions for performance and risk analysis, designed to analyze nonnormal return streams in asset allocation and portfolio optimization. It is mostly tested on return data, rather than on price, but most functions will work with irregular return data as well, and increasing numbers of functions will work with price data where possible.
PortfolioAnalytics-package
Numeric Methods for Optimization of Portfolios
Description
PortfolioAnalytics is an R package providing numerical solutions for portfolio problems with complex constraints and objective sets. The goal of the package is to aid practitioners and researchers in solving portfolio optimization problems with complex constraints and objectives that mirror real-world applications.
One of the goals of the packages is to provide a common interface to specify constraints and objectives that can be solved by any supported solver (i.e., optimization method). Currently, supported optimization methods include the following:
- Random portfolios
- Differential evolution
- Particle swarm optimization
- Generalized simulated annealing
- Linear and quadratic programming routines
The solver can be specified with the optimize_method argument in optimize.portfolio and optimize.portfolio.rebalancing. The optimize_method argument must be one of random, DEoptim, pso, GenSA, ROI, quadprog, glpk, or symphony.
Additional information on random portfolios is provided further. The differential evolution algorithm is implemented via the DEoptim package, the particle swarm optimization algorithm via the pso package, the generalized simulated annealing via the GenSA package, and linear and quadratic programming are implemented via the ROI package that acts as an interface to the Rglpk, Rsymphony.
6.4.4.2 Worked Example for Portfolio Optimization – No. 2 Portfolio Optimization using the R code DEoptim
6.4.4.3 Worked Example for Portfolio Optimization – No. 3 Portfolio Optimization Using the R Code PortfolioAnalytics in CRAN
A numerical portfolio solution for rather complex constraints or objective functions may be obtained by using a function that returns the specific risk measure as the objective function.
This numerical optimization is performed either with the differential evolution optimizer contained in the package DEoptim (see Worked Example No. 3) or by means of randomly generated portfolios satisfying the given constraints.
Worked Example No. 4: Portfolio Optimization using the R code PortfolioAnalytics
The PortfolioAnalytics-package
Numeric methods for optimization of portfolios
Description
PortfolioAnalytics is an R package to compute numerical solutions for portfolio problems with complex constraints and objective sets. The goal of the package is to aid practitioners and researchers in solving portfolio optimization problems with complex constraints and objectives that reflect real-world applications.
One of the goals of this package is to provide a common interface to specify constraints and objectives that can be solved by any supported optimization method. The supported optimization methods include the following:
- Random portfolios
- Differential evolution
- Particle swarm optimization
- Generalized simulated annealing
- Linear and quadratic programming routines
The solver can be specified with the optimize-method argument in optimize.portfolio and optimize.portfolio.rebalancing. The optimize-method argument must be one of random, DEoptim, pso, GenSA, ROI, quadprog, glpk, or performed with the differential evolution optimizer.
This package PortfolioAnalytics allows one to obtain a numerical portfolio solution for rather complex constraints or objective functions. For risk measure, one may use a function that returns the specific risk measure as the objective function.
The numerical optimization is performed either with the differential evolution optimizer contained in the package DEoptim (see Worked Example No. 2) or by means of randomly generated portfolios satisfying the given constraints.
Selected Example:
From the PortfolioAnalytics-package
Numeric methods for optimization of portfolios
ac.ranking Asset RankingDescription Compute the first moment from a single complete sortUsage ac.ranking(R, order, ...)
Arguments
R xts object of asset returnsorder a vector of indexes of the relative ranking of expected asset returns in ascending order. For example, order = c(2, 3, 1, 4) means that the expected returns of R[,2] < R[,3], < R[,1] < R[,4].... any other passthrough parameters
Details
This function computes the estimated centroid vector from a single complete sort using the analytical approximation as described in Almgren and Chriss, Portfolios from Sorts. The centroid is estimated and then scaled such that it is on a scale similar to the asset returns. By default, the centroid vector is scaled according to the median of the asset mean returns.
Value
The estimated first moments based on ranking views.
See Also
centroid.complete.mccentroid.sectorscentroid.signcentroid.buckets
Examples
data(edhec)R <- edhec[,1:4]ac.ranking(R, c(2, 3, 1, 4))
In the R domain:
> install.packages("PortfolioAnalytics")Installing package into ‘C:/Users/Bert/Documents/R/win-library/3.2’(as ‘lib’ is unspecified)trying URL 'https://cran.cnr.berkeley.edu/bin/windows/contrib/3.2/PortfolioAnalytics_1.0.3636.zip'Content type 'application/zip' length 1552727 bytes (1.5 MB)downloaded 1.5 MBpackage ‘PortfolioAnalytics’ successfully unpacked and MD5 sums checkedThe downloaded binary packages are inC:UsersBertAppDataLocalTempRtmpk9Doswdownloaded_packages> library(PortfolioAnalytics)Loading required package: zooAttaching package: ‘zoo’The following objects are masked from ‘package:base’:as.Date, as.Date.numericLoading required package: xtsLoading required package: foreachforeach: simple, scalable parallel programming from Revolution AnalyticsUse Revolution R for scalability, fault tolerance and more.http://www.revolutionanalytics.comLoading required package: PerformanceAnalyticsPackage PerformanceAnalytics (1.4.3541) loaded.Copyright (c) 2004-2014 Peter Carl and Brian G. Peterson, GPL-2 | GPL-3http://r-forge.r-project.org/projects/returnanalytics/Attaching package: ‘PerformanceAnalytics’The following object is masked from ‘package:graphics’:legendWarning messages:1: package ‘PortfolioAnalytics’ was built under R version 3.2.42: package ‘xts’ was built under R version 3.2.33: package ‘PerformanceAnalytics’ was built under R version 3.2.3> ls("package:PortfolioAnalytics")[1] "ac.ranking" "add.constraint"[3] "add.objective" "add.objective_v1"[5] "add.objective_v2" "add.sub.portfolio"[7] "applyFUN" "black.litterman"[9] "box_constraint" "CCCgarch.MM"[11] "center" "centroid.buckets"[13] "centroid.complete.mc" "centroid.sectors"[15] "centroid.sign" "chart.Concentration"[17] "chart.EF.Weights" "chart.EfficientFrontier"[19] "chart.EfficientFrontierOverlay" "chart.GroupWeights"[21] "chart.RiskBudget" "chart.RiskReward"[23] "chart.Weights" "combine.optimizations"[25] "combine.portfolios" "constrained_objective"[27] "constrained_objective_v1" "constrained_objective_v2"[29] "constraint" "constraint_ROI"[31] "create.EfficientFrontier" "diversification"[33] "diversification_constraint" "EntropyProg"[35] "equal.weight" "extractCokurtosis"[37] "extractCoskewness" "extractCovariance"[39] "extractEfficientFrontier" "extractGroups"[41] "extractObjectiveMeasures" “extractStats"[43] "extractWeights" "factor_exposure_constraint"[45] "fn_map" "generatesequence"[47] "group_constraint" "HHI"[49] "insert_objectives" "inverse.volatility.weight"[51] "is.constraint" "is.objective"[53] "is.portfolio" "leverage_exposure_constraint"[55] "meanetl.efficient.frontier" "meanvar.efficient.frontier"[57] "meucci.moments" "meucci.ranking"[59] "minmax_objective" "mult.portfolio.spec"[61] "objective" "optimize.portfolio"[63] "optimize.portfolio.parallel" "optimize.portfolio.rebalancing"[65] "optimize.portfolio.rebalancing_v1" "optimize.portfolio_v1"[67] "optimize.portfolio_v2" "portfolio.spec"[69] "portfolio_risk_objective" "pos_limit_fail"[71] "position_limit_constraint" "quadratic_utility_objective"[73] "random_portfolios" "random_portfolios_v1"[75] "random_portfolios_v2" "random_walk_portfolios"[77] "randomize_portfolio" "randomize_portfolio_v1"[79] "randomize_portfolio_v2" "regime.portfolios"[81] "return_constraint" "return_objective"[83] "risk_budget_objective" "rp_grid"[85] "rp_sample" "rp_simplex"[87] "rp_transform" "scatterFUN"[89] "set.portfolio.moments" "statistical.factor.model"[91] "trailingFUN" "transaction_cost_constraint"[93] "turnover" "turnover_constraint"[95] "turnover_objective" "update_constraint_v1tov2"[97] "var.portfolio" "weight_concentration_objective"[99] "weight_sum_constraint"> ac.rankingfunction (R, order, ...){if (length(order) != ncol(R))stop("The length of the order vector must equal the number of assets")nassets <- ncol(R)if (hasArg(max.value)) {max.value <- match.call(expand.dots = TRUE)$max.value}else {max.value <- median(colMeans(R))}c_hat <- scale.range(centroid(nassets), max.value)out <- vector("numeric", nassets)out[rev(order)] <- c_hatreturn(out)}<environment: namespace:PortfolioAnalytics>> data(edhec)> edhecConvertible CTA DistressedArbitrage Global Securities1997-01-31 0.0119 0.0393 0.01781997-02-28 0.0123 0.0298 0.01221997-03-31 0.0078 -0.0021 -0.00121997-04-30 0.0086 -0.0170 0.00301997-05-31 0.0156 -0.0015 0.0233---------------------------------------------------------2009-06-30 0.0241 -0.0147 0.01982009-07-31 0.0611 -0.0012 0.03112009-08-31 0.0315 0.0054 0.0244Emerging Equity Neutral EventMarkets Market Driven1997-01-31 0.0791 0.0189 0.02131997-02-28 0.0525 0.0101 0.00841997-03-31 -0.0120 0.0016 -0.00231997-04-30 0.0119 0.0119 -0.00051997-05-31 0.0315 0.0189 0.0346-------------------------------------------------------2009-06-30 0.0013 0.0036 0.01232009-07-31 0.0451 0.0042 0.02912009-08-31 0.0166 0.0070 0.0207Fixed Arbitrage Long/ShortIncome Global Macro Equity1997-01-31 0.0191 0.0573 0.02811997-02-28 0.0122 0.0175 -0.00061997-03-31 0.0109 -0.0119 -0.00841997-04-30 0.0130 0.0172 0.00841997-05-31 0.0118 0.0108 0.0394---------------------------------------------------------2009-06-30 0.0126 -0.0076 0.00092009-07-31 0.0322 0.0166 0.02772009-08-31 0.0202 0.0050 0.0157Merger Relative Short FundsArbitrage Value Selling of Funds1997-01-31 0.0150 0.0180 -0.0166 0.03171997-02-28 0.0034 0.0118 0.0426 0.01061997-03-31 0.0060 0.0010 0.0778 -0.00771997-04-30 -0.0001 0.0122 -0.0129 0.00091997-05-31 0.0197 0.0173 -0.0737 0.0275---------------------------------------------------------2009-06-30 0.0104 0.0101 -0.0094 0.00242009-07-31 0.0068 0.0260 -0.0596 0.01532009-08-31 0.0102 0.0162 -0.0165 0.0113> R <- edhec[,1:4]> ac.ranking(R, c(2, 3, 1, 4))[1] 0.01432457 -0.05000000 -0.01432457 0.05000000>> R # R = edhec [, 1:4], viz. Column Vectors 1 thru 4 of edhec:## 1. Convertible Arbitrage# 2. CTA Global# 3. Distressed Securities# 4. Emerging Markets## but NOT Columns 5 thru 6:# 5. Equity Market# 6. Neutral Event Driven# and, those 4 columns are:#Convertible TA DistressedArbitrage Global Securities1997-01-31 0.0119 0.0393 0.01781997-02-28 0.0123 0.0298 0.01221997-03-31 0.0078 -0.0021 -0.00121997-04-30 0.0086 -0.0170 0.00301997-05-31 0.0156 -0.0015 0.0233-------------------------------------------------------2009-06-30 0.0241 -0.0147 0.01982009-07-31 0.0611 -0.0012 0.03112009-08-31 0.0315 0.0054 0.0244EmergingMarkets1997-01-31 0.07911997-02-28 0.05251997-03-31 -0.01201997-04-30 0.01191997-05-31 0.0315-------------------------2009-06-30 0.00132009-07-31 0.04512009-08-31 0.0166>> ac.ranking(R, c(2, 3, 1, 4))> # Outputting:[1] 0.01432457 -0.05000000 -0.01432457 0.05000000
Remark:
order a vector of indexes of the relative ranking of expected asset returns in ascending order. Thus, the order = c(2, 3, 1, 4) means that the expectedreturns of R[,2] < R[,3], < R[,1] < R[,4].
6.4.4.4 Worked Example for Portfolio Optimization – Portfolio Optimization by AssetsM in CRAN
6.4.4.5 Worked Examples from Pfaff
Forecast
> install.packages("forecast")Installing package into ‘C:/Users/Bert/Documents/R/win-library/3.2’(as ‘lib’ is unspecified)--- Please select a CRAN mirror for use in this session ---also installing the dependency ‘ggplot2’> A CRAN mirror is selectedtrying URL 'https://cran.cnr.berkeley.edu/bin/windows/contrib/3.2/ggplot2_2.1.0.zip'Content type 'application/zip' length 2002561 bytes (1.9 MB)downloaded 1.9 MBtrying URL 'https://cran.cnr.berkeley.edu/bin/windows/contrib/3.2/forecast_7.1.zip'Content type 'application/zip' length 1356674 bytes (1.3 MB)downloaded 1.3 MBpackage ‘ggplot2’ successfully unpacked and MD5 sums checkedpackage ‘forecast’ successfully unpacked and MD5 sums checkedThe downloaded binary packages are inC:UsersBertAppDataLocalTempRtmp6X3C4jdownloaded_packages> library(forecast)Loading required package: zooAttaching package: ‘zoo’The following objects are masked from ‘package:base’:as.Date, as.Date.numericLoading required package: timeDateThis is forecast 7.1> ls("package:forecast")[1] "accuracy" "Acf" "arfima"[4] "Arima" "arima.errors" "arimaorder"[7] "auto.arima" "bats" "bizdays"[10] "BoxCox" "BoxCox.lambda" "Ccf"[13] "croston" "CV" "dm.test"[16] "dshw" "easter" "ets"[19] "findfrequency" "fitted.Arima" "forecast"[22] "forecast.ar" "forecast.Arima" "forecast.bats"[25] "forecast.ets" "forecast.fracdiff" "forecast.HoltWinters"[28] "forecast.lm" "forecast.nnetar" "forecast.stl"[31] "forecast.stlm" "forecast.StructTS" "forecast.tbats"[34] "fourier" "fourierf" "gas"[37] "geom_forecast" "GeomForecast" "getResponse"[40] "ggAcf" "ggCcf" "ggmonthplot"[43] "ggPacf" "ggseasonplot" "ggtaperedacf"[46] "ggtaperedpacf" "ggtsdisplay" "gold"[49] "holt" "hw" "InvBoxCox"[52] "is.acf" "is.Arima" "is.bats"[55] "is.constant" "is.ets" "is.forecast"[58] "is.mforecast" "is.nnetar" "is.nnetarmodels"[61] "is.splineforecast" "is.stlm" "logLik.ets"[64] "ma" "meanf" "monthdays"[67] "msts" "na.interp" "naive"[70] "ndiffs" "nnetar" "nsdiffs"[73] "Pacf" "plot.ar" "plot.Arima"[76] "plot.bats" "plot.ets" "plot.forecast"[79] "plot.splineforecast" "plot.tbats" "rwf"[82] "seasadj" "seasonaldummy" "seasonaldummyf"[85] "seasonplot" "ses" "simulate.ar"[88] "simulate.Arima" "simulate.ets" "simulate.fracdiff"[91] "sindexf" "snaive" "splinef"[94] "StatForecast" "stlf" "stlm"[97] "subset.ts" "taperedacf" "taperedpacf"[100] "taylor" "tbats" "tbats.components"[103] "thetaf" "tsclean" "tsdisplay"[106] "tslm" "tsoutliers" "wineind"[109] "woolyrnq"
Review Questions and Exercises
- Maxima and minima for a function of several variables
For a function of several variables, such as the probable value, at any given time, of a financial investment portfolio of many stocks, bonds, and so on, the value of the portfolio at any given time is, therefore, a function of many variables. Mathematically, the value of this portfolio may be expressed as a function of future time. With respect to this portfolio value,
- Describe mathematically, what is meant by its
- local maximum and local minimum
- global maximum and global minimum of the portfolio function.
- How may each of these values be determined?
- Describe mathematically, what is meant by its
- Optimization methodologies in probabilistic calculus for financial engineering
This subject encompasses a very wide field of applied mathematics – as different approaches may measure risks that may not be robust, other measures include the CVAR (conditional value at risk). Other approaches often consider portfolio optimization in two stages: optimizing weights of asset classes to hold and optimizing weights of assets within the same asset class. An example of the former would be selecting the proportions in bonds versus stocks, while an example of the latter would be choosing the proportions of the stock subportfolio placed in stocks A, B, C,…, Z. Bonds and shares have different financial characteristics. These important differences call for diversification of optimization approaches for different classes of investments. With this introduction in mind, write an outline to form a practical optimization methodology for a portfolio which is invested in the following portfolio that consists of each of the following assets:
- Cash (including cash loans from financial institutions)
- Termed fixed interest deposits
- Portfolio of mixed equities of stocks and high-yield corporate bonds in the United States
- Same as (3), but with extensions to overseas financial products
- Private companies in the construction of retirement homes for special markets, such as the retiring “Baby Boomers”
- Cash income producing real estates: private and commercial
- Noncash income producing real estates: private and commercial
- Commodities and precious metals
- Collectibles
- American, European, and Asian options
- The following paper, available on the Internet, provides a number of models for global optimization:
- The standard Markowitz model
- A model with risk-free asset (Tobin model)
- A multiobjective model for portfolio optimization
- A model based on Minkowski absolute metric of risk estimation
- A model based on Minkowski semiabsolute metric of risk estimation
- A model based on Chebyshev metric of risk estimation (maxmin and minimax models)
- The Sharpe model with fractional criteria
- Linear models of returns
- A model with limited number assets (cardinality constrained)
- A model with buy-in thresholds
- Models with transaction costs
- Models with integral (lot) assets
- Models with submodular constraints of diversification of risks
- Models using fuzzy expected return
Study the following paper on this survey – available at
http://www.math.uni-magdeburg.de/∼girlich/preprints/preprint0906.pdf
Consider other available survey papers on this subject, and comment on your findings.
Some further remarks on optimization methodologies in probabilistic calculus for financial engineering are as follows:
- The package PortfolioAnalytics provides a numerical solution of the portfolio with complex constraints and objective functions.
- Following that, the numerical optimization may then be performed either with the differential evolution optimizer in the package DEoptim or randomly.
- Carefully study the next two examples selected from the CRAN package: Portfolio Optimization Using the CRAN Package and Portfolio Optimization Using the CRAN Packages
Portfolio Optimization Using the CRAN Package PortfolioAnalytics: ac.ranking for Portfolio Optimization with Asset Ranking
The following is a description of this CRAN package: PortfolioAnalytics: Portfolio Analysis, Including Numerical Methods for Optimization of Portfolios
Portfolio optimization and analysis routines and graphics.
| Version: | 1.0.3636 |
| Depends: | R (≥ 2.14.0), zoo, xts (≥ 0.8), foreach, PerformanceAnalytics (≥ 1.1.0) |
| Suggests: | quantmod, DEoptim (≥ 2.2.1), iterators, fGarch, Rglpk, quadprog, ROI (≥ 0.1.0), ROI.plugin.glpk (≥ 0.0.2), ROI.plugin.quadprog (≥ 0.0.2), ROI.plugin.symphony (≥ 0.0.2), pso, GenSA, corpcor, testthat, nloptr (≥ 1.0.0), MASS, robustbase |
| Published: | 2015-04-19 |
| Author: | Brian G. Peterson [cre, aut, cph], Peter Carl [aut, cph], Kris Boudt [ctb, cph], Ross Bennett [ctb, cph], Hezky Varon [ctb], Guy Yollin [ctb], R. Douglas Martin [ctb] |
| Maintainer: | Brian G. Peterson <[email protected]> |
| License: | GPL-2 | GPL-3 [expanded from: GPL] |
| Copyright: | 2004–2015 |
| NeedsCompilation: | yes |
| Materials: | README |
| CRAN checks: | PortfolioAnalytics results |
Downloads:
| Reference manual: | PortfolioAnalytics.pdf |
| Vignettes: | Design Thoughts of the PortfolioAnalytics Package Portfolio Optimization with ROI in PortfolioAnalytics Custom Moment and Objective Functions An Introduction to Portfolio Optimization with PortfolioAnalytics Portfolio Optimization with CVaR budgets in PortfolioAnalytics |
| Package source: | PortfolioAnalytics_1.0.3636.tar.gz |
| Windows binaries: | r-devel: PortfolioAnalytics_1.0.3636.zip, r-release: PortfolioAnalytics_1.0.3636.zip, r-oldrel: PortfolioAnalytics_1.0.3636.zip |
| OS X Mavericks binaries: | r-release: PortfolioAnalytics_1.0.3636.tgz, r-oldrel: PortfolioAnalytics_1.0.3636.tgz |
Within this CRAN package, consider the following function program: ac.ranking. This function computes the estimated centroid vector from a single complete sort using the analytical approximation as described in Almgren and Chriss, “Portfolios from Sorts”. The centroid is estimated and then scaled such that it is on a scale similar to the asset returns. By default, the centroid vector is scaled according to the median of the asset mean returns.
This program is described further:
ac.ranking Asset Ranking
Description
Compute the first moment from a single complete sort.
Usage
ac.ranking(R, order, ...)
Arguments
R xts object of asset returnsorder a vector of indexes of the relative ranking of expected asset returns in ascending order. For example, order = c(2, 3, 1, 4) means that the expected returns of R[,2] < R[,3], < R[,1] < R[,4].... any other passthrough parameters
Details
This function computes the estimated centroid vector from a single complete sort using the analytical approximation as described in Almgren and Chriss, Portfolios from Sorts. The centroid is estimated and then scaled such that it is on a scale similar to the asset returns. By default, the centroid vector is scaled according to the median of the asset mean returns.
Value
The estimated first moments based on ranking views
See Also
centroid.complete.mc centroid.sectors centroid.sign centroid.buckets
Examples
**data(edhec)R <- edhec[,1:4]ac.ranking(R, c(2, 3, 1, 4))#data(edhec)R <- edhec[,1:10]ac.ranking(R, c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
Portfolio Optimization Using the CRAN Packages DEoptim:DEoptim-methods for Portfolio Optimization Using the DEoptim Approach
- DEoptim: Global optimization by differential evolution
- DEoptim-methods: DEoptim-methods
A) DEoptim: Global optimization by differential evolution
This introduction to the R package DEoptim is an abbreviated version of the manuscript published in the Journal of Statistical Software. DEoptim implements the Differential Evolution algorithm for global optimization of a real-valued function of a real-valued parameter vector. The implementation of differential evolution in DEoptim interfaces with C code for efficiency. Moreover, the package is self-contained and does not depend on any other packages.
Implements the differential evolution algorithm for global optimization of a real-valued function of a real-valued parameter vector.
| Version: | 2.2-4 |
| Depends: | parallel |
| Suggests: | foreach, iterators, colorspace, lattice |
| Published: | 2016-12-19 |
| Author: | David Ardia [aut], Katharine Mullen [aut, cre], Brian Peterson [aut], Joshua Ulrich [aut], Kris Boudt [ctb] |
| Maintainer: | Katharine Mullen <[email protected]> |
| License: | GPL-2 | GPL-3 [expanded from: GPL (≥ 2)] |
| NeedsCompilation: | yes |
| Citation: | DEoptim citation info |
| Materials: | README NEWS |
| In views: | Optimization |
| CRAN checks: | DEoptim results |
Downloads:
| Reference manual: | DEoptim.pdf |
| Vignettes: | DEoptim: An R Package for Differential Evolution Large scale portfolio optimization with DEoptim |
| Package source: | DEoptim_2.2-4.tar.gz |
| Windows binaries: | r-devel: DEoptim_2.2-4.zip, r-release: DEoptim_2.2-4.zip, r-oldrel: DEoptim_2.2-4.zip |
| OS X Mavericks binaries: | r-release: DEoptim_2.2-4.tgz, r-oldrel: DEoptim_2.2-4.tgz |
| Old sources: | DEoptim archive |
Reverse Dependencies:
| Reverse depends: | EcoHydRology, galts, IBHM, likeLTD, micEconCES, quickpsy, selectMeta |
| Reverse imports: | BBEST, CEGO, covmat, DstarM, FuzzyStatProb, MSGARCH, SpaDES |
| Reverse suggests: | BayesianTools, MSCMT, nanop, npsp, PortfolioAnalytics, RcppDE, SACOBRA, SPOT |
Examples from CRAN:
Use the following two examples, in R, to illustrate the use of the aforementioned approach in portfolio optimization:
DEoptim Differential Evolution Optimization
Description
Performs evolutionary global optimization via the differential evolution algorithm.
Usage
DEoptim(fn, lower, upper, control = DEoptim.control(), ...,fnMap=NULL)
Arguments
fn the function to be optimized (minimized). The function should have as its first argument the vector of real-valued parameters to optimize, and return a scalar real result. NA and NaN values are not allowed.lower, upper two vectors specifying scalar real lower and upper bounds on each parameter to be optimized, so that the i-th element of lower and upper applies to the ith parameter. The implementation searches between lower and upper for the global optimum (minimum) of fn.control a list of control parameters; see DEoptim.control.fnMap an optional function that will be run after each population is created, but before the population is passed to the objective function. This allows the user to impose integer/cardinality constriants.... further arguments to be passed to fn.
Details
DEoptim performs optimization (minimization) of fn.
The control argument is a list; see the help file for DEoptim.control for details.
The R implementation of DE, DEoptim, was first published on the Comprehensive R Archive Network (CRAN) in 2005 by David Ardia. Early versions were written in pure R. Since version 2.0-0 (published on CRAN in 2009), the package has relied on an interface to a C implementation of DE, which is significantly faster on most problems as compared to the implementation in pure R. The C interface is in many respects similar to the MS Visual C++ v5.0 implementation of the differential evolution algorithm distributed with the book Differential Evolution – A Practical Approach to Global Optimization by Price et al. and found online at http://www1.icsi.berkeley.edu/∼storn/code.html. Since version 2.0-3, the C implementation dynamically allocates the memory required to store the population, removing limitations on the number of members in the population and length of the parameter vectors that may be optimized. Since version 2.2-0, the package allows for parallel operation, so that the evaluations of the objective function may be performed using all available cores. This is accomplished using either the built-in parallel package or the foreach package. If parallel operation is desired, the user should set parallelType and make sure that the arguments and packages needed by the objective function are available; see DEoptim.control, the example below and examples in the sandbox directory for details.
Since becoming publicly available, the package DEoptim has been used by several authors to solve optimization problems arising in diverse domains.
To perform a maximization (instead of minimization) of a given function, simply define a new function which is the opposite of the function to maximize and apply DEoptim to it.
To integrate additional constraints (other than box constraints) on the parameters x of fn(x), for instance x[1] + x[2]^2 < 2, integrate the constraint within the function to optimize, for instance:
fn <- function(x){if (x[1] + x[2]^2 >= 2){r <- Infelse{...}return(r)}
This simplistic strategy usually does not work all that well for gradient-based or Newton-type methods. It is likely to be alright when the solution is in the interior of the feasible region, but when the solution is on the boundary, optimization algorithm would have a difficult time converging. Furthermore, when the solution is on the boundary, this strategy would make the algorithm converge to an inferior solution in the interior. However, for methods such as DE that are not gradient based, this strategy might not be that bad.
Note that DEoptim stops if any NA or NaN value is obtained. You have to redefine your function to handle these values (for instance, set NA to Inf in your objective function).
It is important to emphasize that the result of DEoptim is a random variable, that is, different results may be obtained when the algorithm is run repeatedly with the same settings. Hence, the user should set the random seed if they want to reproduce the results, for example, by setting set.seed(1234) before the call of DEoptim.
DEoptim relies on repeated evaluation of the objective function in order to move the population toward a global minimum. Users interested in making DEoptim run as fast as possible should consider using the package in parallel mode (so that all CPUs available are used), and also ensure that evaluation of the objective function is as efficient as possible (e.g., by using vectorization in pure R code, or writing parts of the objective function in a lower level language like C or Fortran).
Further details and examples of the R package DEoptim can be found in Mullen et al. (2011) and Ardia et al. (2011a, 2011b) or look at the package's vignette by typing vignette("DEoptim"). Also, an illustration of the package usage for a high-dimensional nonlinear portfolio optimization problem is available by typing vignette("DEoptimPortfolioOptimization").
Please cite the package in publications. Use citation("DEoptim").
Value
The output of the function DEoptim is a member of the S3 class DEoptim. More precisely, this is a list (of length 2) containing the following elements:
optim, a list containing the following elements:
- bestmem: the best set of parameters found.
- bestval: the value of fn corresponding to bestmem.
- nfeval: number of function evaluations.
- iter: number of procedure iterations.
member, a list containing the following elements:
- lower: the lower boundary.
- upper: the upper boundary.
- bestvalit: the best value of fn at each iteration.
- bestmemit: the best member at each iteration.
- pop: the population generated at the last iteration.
- storepop: a list containing the intermediate populations.
Members of the class DEoptim have a plot method that accepts the argument plot.type.
plot.type = "bestmemit" results in a plot of the parameter values that represent the lowest value of the objective function in each generation.
plot.type = "bestvalit" plots the best value of the objective function in each generation. Finally,
plot.type = "storepop" results in a plot of stored populations (which are only available if these have been saved by setting the control argument of DEoptim appropriately). Storing intermediate populations allows us to examine the progress of the optimization in detail. A summary method also exists and returns the best parameter vector, the best value of the objective function, the number of generations optimization ran, and the number of times the objective function was evaluated.
Note
DE is a search heuristic introduced by Storn and Price (1997). Its remarkable performance as a global optimization algorithm on continuous numerical minimization problems has been extensively explored. DE belongs to the class of genetic algorithms that use biology-inspired operations of crossover, mutation, and selection on a population in order to minimize an objective function over the course of successive generations. As with other evolutionary algorithms, DE solves optimization problems by evolving a population of candidate solutions using alteration and selection operators. DE uses floating-point instead of bit string encoding of population members, and arithmetic operations instead of logical operations in mutation. DE is particularly well suited to find the global optimum of a real-valued function of real-valued parameters, and does not require that the function be either continuous or differentiable.
Let NP denote the number of parameter vectors (members) x ∈ Rd in the population. In order to create the initial generation, NP guesses for the optimal value of the parameter vector are made, either using random values between lower and upper bounds (defined by the user) or using values given by the user. Each generation involves creation of a new population from the current population members {xi | i = 1,…, NP}, where i indexes the vectors that make up the population. This is accomplished using differential mutation of the population members. An initial mutant parameter vector vi is created by choosing three members of the population, xr0, xr1, and xr2, at random. Then vi is generated as
where F is the differential weighting factor, effective values for which are typically between 0 and 1. After the first mutation operation, mutation is continued until d mutations have been made, with a crossover probability CR ∈ [0, 1]. The crossover probability CR controls the fraction of the parameter values that are copied from the mutant. If an element of the trial parameter vector is found to violate the bounds after mutation and crossover, it is reset in such a way that the bounds are respected (with the specific protocol depending on the implementation). Then, the objective function values associated with the children are determined. If a trial vector has equal or lower objective function value than the previous vector, it replaces the previous vector in the population; otherwise the previous vector remains. Variations of this scheme have also been proposed.
Intuitively, the effect of the scheme is that the shape of the distribution of the population in the search space is converging with respect to size and direction toward areas with high fitness. The closer the population gets to the global optimum, the more the distribution will shrink and, therefore, reinforce the generation of smaller difference vectors.
As a general advice regarding the choice of NP, F, and CR, Storn et al. (2006) state the following:
Set the number of parents NP to 10 times the number of parameters, select differential weighting factor F = 0.8 and crossover constant CR = 0.9. Make sure that you initialize your parameter vectors by exploiting their full numerical range, that is, if a parameter is allowed to exhibit values in the range [−100, 100], it is a good idea to pick the initial values from this range instead of unnecessarily restricting diversity. If you experience misconvergence in the optimization process you usually have to increase the value for NP, but often you only have to adjust F to be a little lower or higher than 0.8. If you increase NP and simultaneously lower F a little, convergence is more likely to occur but generally takes longer, that is, DE is getting more robust (there is always a convergence speed/robustness trade-off).
DE is much more sensitive to the choice of F than it is to the choice of CR. CR is more like a fine tuning element. High values of CR, like CR = 1, give faster convergence if convergence occurs. Sometimes, however, you have to go down as much as CR = 0 to make DE robust enough for a particular problem. For more details on the DE strategy, we refer the reader to Storn and Price (1997) and Price et al. (2006).
Author(s)
David Ardia, Katharine Mullen <[email protected]>, Brian Peterson, and Joshua Ulrich.
See Also
DEoptim.control for control arguments, DEoptim-methods for methods on DEoptim objects, including some examples in plotting the results; optim or constrOptim for alternative optimization algorithms.
Examples
## Rosenbrock Banana function## The function has a global minimum f(x)=0 at the point (1,1).## Note that the vector of parameters to be optimized must be ## the first argument of the objective function passed to## DEoptim.Rosenbrock <- function(x){
x1 <- x[1]x2 <- x[2]100 * (x2 - x1 * x1)^2 + (1 - x1)^2}## DEoptim searches for minima of the objective function## between lower and upper bounds on each parameter to be ## optimized. Therefore in the call to DEoptim we specify vectors ## that comprise the lower and upper bounds; these vectors are ## the same length as the parameter vector.lower <- c(-10,-10)upper <- -lower## run DEoptim and set a seed first for replicabilityset.seed(1234)DEoptim(Rosenbrock, lower, upper)## increase the population sizeDEoptim(Rosenbrock, lower, upper, DEoptim.control(NP = 100))## change other settings and store the outputoutDEoptim <- DEoptim(Rosenbrock, lower, upper,DEoptim.control(NP = 80,itermax = 400, F = 1.2, CR = 0.7))## plot the outputplot(outDEoptim)## 'Wild' function, global minimum at about -15.81515Wild <- function(x)10 * sin(0.3 * x) * sin(1.3 * x^2) +0.00001 * x^4 + 0.2 * x + 80plot(Wild, -50, 50, n = 1000, main = "'Wild function'")outDEoptim <- DEoptim(Wild, lower = -50, upper = 50,control = DEoptim.control(trace = FALSE))plot(outDEoptim)DEoptim(Wild, lower = -50, upper = 50,control = DEoptim.control(NP = 50))## The below examples shows how the call to DEoptim can be## parallelized.## Note that if your objective function requires packages to be## loaded or has arguments supplied via code{...}, these## should be specified using the code{packages} and## code{parVar} arguments## in control.## Not run:Genrose <- function(x) {## One generalization of the Rosenbrock banana valley function ## (n parameters)n <- length(x)## make it take some time ...Sys.sleep(.001)1.0 + sum (100 * (x[-n]^2 - x[-1])^2 + (x[-1] - 1)^2)}# get some run-time on simple problemsmaxIt <- 250n <- 5oneCore <- system.time( DEoptim(fn=Genrose, lower=rep(-25, n), upper=rep(25, n),control=list(NP=10*n, itermax=maxIt)))withParallel <- system.time( DEoptim(fn=Genrose, lower=rep(-25, n), upper=rep(25, n),control=list(NP=10*n, itermax=maxIt, parallelType=1)))## Compare timings(oneCore)(withParallel)## End(Not run)
B) DEoptim-methods DEoptim-methods
Description
Methods for DEoptim objects.
Usage
## S3 method for class 'DEoptim'summary(object, ...)## S3 method for class 'DEoptim'plot(x, plot.type = c("bestmemit", "bestvalit", "storepop"), ...)
Arguments
object an object of class DEoptim; usually, a result of a call to DEoptim.x an object of class DEoptim; usually, a result of a call to DEoptim.plot.type should we plot the best member at each iteration, the best value at each iteration or the intermediate populations?... further arguments passed to or from other methods.
Details
Members of the class DEoptim have a plot method that accepts the argument plot.type.plot.type = "bestmemit" results in a plot of the parameter values that represent the lowest value of the objective function each generation.plot.type = "bestvalit" plots the best value of the objective function each generation. Finally,plot.type = "storepop" results in a plot of stored populations (which are only available if these have been saved by setting the control argument of DEoptim appropriately). Storing intermediate populations allows us to examine the progress of the optimization in detail. A summary method also exists and returns the best parameter vector, the best value of the objective function, the number of generations optimization ran, and the number of times the objective function was evaluated.
Note
Further details and examples of the R package DEoptim can be found in Mullen et al. (2011) and Ardia et al. (2011a, 2011b) or look at the package's vignette by typing vignette(“DEoptim”).
Please cite the package in publications. Use citation(“DEoptim”).
Author(s)
David Ardia, Katharine Mullen <[email protected]>, Brian Peterson, and Joshua Ulrich.
See Also
DEoptim and DEoptim.control.
Examples
## Rosenbrock Banana function## The function has a global minimum f(x)=0 at the point (1,1).## Note that the vector of parameters to be optimized must be ## the first argument of the objective function passed to## DEoptim.Rosenbrock <- function(x){x1 <- x[1]x2 <- x[2]100 * (x2 - x1 * x1)^2 + (1 - x1)^2}lower <- c(-10, -10)upper <- -lowerset.seed(1234)outDEoptim <- DEoptim(Rosenbrock, lower, upper)## print output informationsummary(outDEoptim)## plot the best membersplot(outDEoptim, type = 'b')## plot the best valuesdev.new()plot(outDEoptim, plot.type = "bestvalit", type = 'b', col = 'blue')## rerun the optimization, and store intermediate populationsoutDEoptim <- DEoptim(Rosenbrock, lower, upper,DEoptim.control(itermax = 500,storepopfrom = 1, storepopfreq = 2))summary(outDEoptim)## plot intermediate populationsdev.new()plot(outDEoptim, plot.type = "storepop")## Wild functionWild <- function(x)10 * sin(0.3 * x) * sin(1.3 * x^2) +0.00001 * x^4 + 0.2 * x + 80outDEoptim = DEoptim(Wild, lower = -50, upper = 50,DEoptim.control(trace = FALSE, storepopfrom = 50,storepopfreq = 1))plot(outDEoptim, type = 'b')dev.new()plot(outDEoptim, plot.type = "bestvalit", type = 'b')## Not run:## an example with a normal mixture model: requires package ## mvtnormlibrary(mvtnorm)## neg value of the density functionnegPdfMix <- function(x) {tmp <- 0.5 * dmvnorm(x, c(-3, -3)) + 0.5 * dmvnorm(x, c(3, 3))-tmp}## wrapper plotting functionplotNegPdfMix <- function(x1, x2)negPdfMix(cbind(x1, x2))## contour plot of the mixturex1 <- x2 <- seq(from = -10.0, to = 10.0, by = 0.1)thexlim <- theylim <- range(x1)z <- outer(x1, x2, FUN = plotNegPdfMix)contour(x1, x2, z, nlevel = 20, las = 1, col = rainbow(20),xlim = thexlim, ylim = theylim)set.seed(1234)outDEoptim <- DEoptim(negPdfMix, c(-10, -10), c(10, 10),DEoptim.control(NP = 100, itermax = 100, storepopfrom = 1,storepopfreq = 5))## convergence plotdev.new()plot(outDEoptim)## the intermediate populations indicate the bi-modality of the ## functiondev.new()plot(outDEoptim, plot.type = "storepop")## End(Not run)
The CRAN Package PortfolioAnalytics
In the R domain:
>> install.packages("PortfolioAnalytics")Installing package into ‘C:/Users/Bert/Documents/R/win-library/3.3’(as ‘lib’ is unspecified)--- Please select a CRAN mirror for use in this session ---
A CRAN mirror is selected.
also installing the dependencies ‘iterators’, ‘foreach’> library(PortfolioAnalytics)Attaching package: ‘PerformanceAnalytics’>> ls("package:PortfolioAnalytics")[1] "ac.ranking" "add.constraint"[3] "add.objective" "add.objective_v1"[5] "add.objective_v2" "add.sub.portfolio"[7] "applyFUN" "black.litterman"[9] "box_constraint" "CCCgarch.MM"[11] "center" "centroid.buckets"[13] "centroid.complete.mc" "centroid.sectors"[15] "centroid.sign" "chart.Concentration"[17] "chart.EF.Weights" "chart.EfficientFrontier"[19] "chart.EfficientFrontierOverlay" "chart.GroupWeights"[21] "chart.RiskBudget" "chart.RiskReward"[23] "chart.Weights" "combine.optimizations"[25] "combine.portfolios" "constrained_objective"[27] "constrained_objective_v1" "constrained_objective_v2"[29] "constraint" "constraint_ROI"[31] "create.EfficientFrontier" "diversification"[33] "diversification_constraint" "EntropyProg"[35] "equal.weight" "extractCokurtosis"[37] "extractCoskewness" "extractCovariance"[39] "extractEfficientFrontier" "extractGroups"[41] "extractObjectiveMeasures" "extractStats"[43] "extractWeights" "factor_exposure_constraint"[45] "fn_map" "generatesequence"[47] "group_constraint" "HHI"[49] "insert_objectives" "inverse.volatility.weight"[51] "is.constraint" "is.objective"[53] "is.portfolio" "leverage_exposure_constraint"[55] "meanetl.efficient.frontier" "meanvar.efficient.frontier"[57] "meucci.moments" "meucci.ranking"[59] "minmax_objective" "mult.portfolio.spec"[61] "objective" "optimize.portfolio"[63] "optimize.portfolio.parallel" "optimize.portfolio.rebalancing"[65] "optimize.portfolio.rebalancing_v1" "optimize.portfolio_v1"[67] "optimize.portfolio_v2" "portfolio.spec"[69] "portfolio_risk_objective" "pos_limit_fail"[71] "position_limit_constraint" "quadratic_utility_objective"[73] "random_portfolios" "random_portfolios_v1"[75] "random_portfolios_v2" "random_walk_portfolios"[77] "randomize_portfolio" "randomize_portfolio_v1"[79] "randomize_portfolio_v2" "regime.portfolios"[81] "return_constraint" "return_objective"[83] "risk_budget_objective" "rp_grid"[85] "rp_sample" "rp_simplex"[87] "rp_transform" "scatterFUN"[89] "set.portfolio.moments" "statistical.factor.model"[91] "trailingFUN" "transaction_cost_constraint"[93] "turnover" "turnover_constraint"[95] "turnover_objective" "update_constraint_v1tov2"[97] "var.portfolio" "weight_concentration_objective"[99] "weight_sum_constraint">> ac.rankingfunction (R, order, ...){if (length(order) != ncol(R))stop("The length of the order vector must equal the number of assets")nassets <- ncol(R)if (hasArg(max.value)) {max.value <- match.call(expand.dots = TRUE)$max.value}else {max.value <- median(colMeans(R))}c_hat <- scale.range(centroid(nassets), max.value)out <- vector("numeric", nassets)out[rev(order)] <- c_hatreturn(out)}<environment: namespace:PortfolioAnalytics>>> # Run 1> data(edhec)> R <- edhec[,1:4]> ac.ranking(R, c(2, 3, 1, 4)) # Outputting:[1] 0.01432457 -0.05000000 -0.01432457 0.05000000>> # Run 2> data(edhec)> R <- edhec[,1:10]> ac.ranking(R, c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) # Outputting:[1] -0.050000000 -0.032377611 -0.021216605 -0.012155458 -0.003968706[6] 0.003968706 0.012155458 0.021216605 0.032377611 0.050000000>
The CRAN Package DEoptim Portfolio Optimization Using the CRAN Packages: DEoptim:DEoptim-methods for Portfolio Optimization using the DEoptim approach. DEoptim: Global Optimization by Differential Evolution
In the R domain:
>> install.packages("DEoptim")
Installing package into ‘C:/Users/Bert/Documents/R/win-library/3.3’(as ‘lib’ is unspecified)--- Please select a CRAN mirror for use in this session ---
A CRAN mirror is selected.
trying URL 'https://cran.ism.ac.jp/bin/windows/contrib/3.3/DEoptim_2.2-4.zip'Content type 'application/zip' length 680535 bytes (664 KB)downloaded 664 KBpackage ‘DEoptim’ successfully unpacked and MD5 sums checkedThe downloaded binary packages are inC:UsersBertAppDataLocalTempRtmpkPO86Kdownloaded_packages> library(DEoptim)Loading required package: parallelDEoptim packageDifferential Evolution algorithm in RAuthors: D. Ardia, K. Mullen, B. Peterson and J. Ulrich> ls("package:DEoptim")[1] "DEoptim" "DEoptim.control"> DEoptimfunction (fn, lower, upper, control = DEoptim.control(), ...,fnMap = NULL){if (length(lower) != length(upper))stop("'lower' and 'upper' are not of same length")if (!is.vector(lower))lower <- as.vector(lower)if (!is.vector(upper))upper <- as.vector(upper)if (any(lower > upper))stop("'lower' > 'upper'")if (any(lower == "Inf"))warning("you set a component of 'lower' to 'Inf'. May imply 'NaN' results",immediate. = TRUE)if (any(lower == "-Inf"))warning("you set a component of 'lower' to '-Inf'. May imply 'NaN' results",immediate. = TRUE)if (any(upper == "Inf"))
warning("you set a component of 'upper' to 'Inf'. May imply 'NaN' results",immediate. = TRUE)if (any(upper == "-Inf"))warning("you set a component of 'upper' to '-Inf'. May imply 'NaN' results",immediate. = TRUE)if (!is.null(names(lower)))nam <- names(lower)else if (!is.null(names(upper)) & is.null(names(lower)))nam <- names(upper)else nam <- paste("par", 1:length(lower), sep = "")ctrl <- do.call(DEoptim.control, as.list(control))ctrl$npar <- length(lower)if (is.na(ctrl$NP))ctrl$NP <- 10 * length(lower)if (ctrl$NP < 4) {warning("'NP' < 4; set to default value 10*length(lower) ",immediate. = TRUE)ctrl$NP <- 10 * length(lower)}if (ctrl$NP < 10 * length(lower))warning("For many problems it is best to set 'NP' (in 'control') to be at least ten times the length of the parameter vector. ",immediate. = TRUE)if (!is.null(ctrl$initialpop)) {ctrl$specinitialpop <- TRUEif (!identical(as.numeric(dim(ctrl$initialpop)), as.numeric(c(ctrl$NP,ctrl$npar))))stop("Initial population is not a matrix with dim. NP x length(upper).")}else {ctrl$specinitialpop <- FALSEctrl$initialpop <- 0}ctrl$trace <- as.numeric(ctrl$trace)ctrl$specinitialpop <- as.numeric(ctrl$specinitialpop)ctrl$initialpop <- as.numeric(ctrl$initialpop)if (!is.null(ctrl$cluster)) {if (!inherits(ctrl$cluster, "cluster"))stop("cluster is not a 'cluster' class object")parallel::clusterExport(cl, ctrl$parVar)fnPop <- function(params, ...) {parallel::parApply(cl = ctrl$cluster, params, 1,fn, ...)}}else if (ctrl$parallelType == 2) {if (!foreach::getDoParRegistered()) {foreach::registerDoSEQ()}args <- ctrl$foreachArgsfnPop <- function(params, ...) {my_chunksize <- ceiling(NROW(params)/foreach::getDoParWorkers())my_iter <- iterators::iter(params, by = "row", chunksize = my_chunksize)args$i <- my_iterargs$.combine <- cif (!is.null(args$.export))args$.export = c(args$.export, "fn")else args$.export = "fn"if (is.null(args$.errorhandling))args$.errorhandling = c("stop", "remove", "pass")if (is.null(args$.verbose))args$.verbose = FALSEif (is.null(args$.inorder))args$.inorder = TRUEif (is.null(args$.multicombine))args$.multicombine = FALSEforeach::"%dopar%"(do.call(foreach::foreach, args),apply(i, 1, fn, ...))}}else if (ctrl$parallelType == 1) {cl <- parallel::makeCluster(parallel::detectCores())packFn <- function(packages) {for (i in packages) library(i, character.only = TRUE)}parallel::clusterCall(cl, packFn, ctrl$packages)parallel::clusterExport(cl, ctrl$parVar)fnPop <- function(params, ...) {parallel::parApply(cl = cl, params, 1, fn, ...)<}}else {fnPop <- function(params, ...) {apply(params, 1, fn, ...)}}if (is.null(fnMap)) {fnMapC <- function(params, ...) params}else {fnMapC <- function(params, ...) {mappedPop <- t(apply(params, 1, fnMap))if (all(dim(mappedPop) != dim(params)))stop("mapping function did not return an object with ","dim NP x length(upper).")dups <- duplicated(mappedPop)np <- NCOL(mappedPop)tries <- 0while (tries < 5 && any(dups)) {nd <- sum(dups)newPop <- matrix(runif(nd * np), ncol = np)newPop <- rep(lower, each = nd) + newPop * rep(upper -lower, each = nd)mappedPop[dups,] <- t(apply(newPop, 1, fnMap))dups <- duplicated(mappedPop)tries <- tries + 1}if (tries == 5)warning("Could not remove ", sum(dups), " duplicates from the mapped ","population in 5 tries. Evaluating population with duplicates.",call. = FALSE, immediate. = TRUE)storage.mode(mappedPop) <- "double"mappedPop}}outC <- .Call("DEoptimC", lower, upper, fnPop, ctrl, new.env(),fnMapC, PACKAGE = "DEoptim")if (ctrl$parallelType == 1)parallel::stopCluster(cl)
if (length(outC$storepop) > 0) {nstorepop <- floor((outC$iter - ctrl$storepopfrom)/ctrl$storepopfreq)storepop <- list()cnt <- 1for (i in 1:nstorepop) {idx <- cnt:((cnt - 1) + (ctrl$NP * ctrl$npar))storepop[[i]] <- matrix(outC$storepop[idx], nrow = ctrl$NP,ncol = ctrl$npar, byrow = TRUE)cnt <- cnt + (ctrl$NP * ctrl$npar)dimnames(storepop[[i]]) <- list(1:ctrl$NP, nam)}}else {storepop = NULL}names(outC$bestmem) <- namiter <- max(1, as.numeric(outC$iter))names(lower) <- names(upper) <- nambestmemit <- matrix(outC$bestmemit[1:(iter * ctrl$npar)],nrow = iter, ncol = ctrl$npar, byrow = TRUE)dimnames(bestmemit) <- list(1:iter, nam)storepop <- as.list(storepop)outR <- list(optim = list(bestmem = outC$bestmem, bestval = outC$bestval,nfeval = outC$nfeval, iter = outC$iter), member = list(lower = lower,upper = upper, bestmemit = bestmemit, bestvalit = outC$bestvalit,pop = t(outC$pop), storepop = storepop))attr(outR, "class") <- "DEoptim"return(outR)}<environment: namespace:DEoptim>> ## Rosenbrock Banana function> ## The function has a global minimum f(x) = 0 at the point+ ## (1,1).> ## Note that the vector of parameters to be optimized must be> ## the first> ## argument of the objective function passed to DEoptim.> Rosenbrock <- function(x){+ x1 <- x[1]+ x2 <- x[2]+ 100 * (x2 - x1 * x1)^2 + (1 - x1)^2+ }>> ## DEoptim searches for minima of the objective function> ## between> ## lower and upper bounds on each parameter to be> ## optimized. Therefore> ## in the call to DEoptim we specify vectors that comprise the> ## lower and upper bounds; these vectors are the same length> ## as the> ## parameter vector.> lower <- c(-10,-10)> upper <- -lower>> ## run DEoptim and set a seed first for replicability> set.seed(1234)> DEoptim(Rosenbrock, lower, upper)Iteration: 1 bestvalit: 231.182756 bestmemit: 2.298807 6.799427Iteration: 2 bestvalit: 147.937835 bestmemit: -2.864559 7.052430Iteration: 3 bestvalit: 147.937835 bestmemit: -2.864559 7.052430………………………………Iteration: 199 bestvalit: 0.000000 bestmemit: 1.000000 1.000000Iteration: 200 bestvalit: 0.000000 bestmemit: 1.000000 1.000000$optim$optim$bestmempar1 par21 1$optim$bestval[1] 3.010666e-16$optim$nfeval[1] 402$optim$iter[1] 200$member$member$lowerpar1 par2-10 -10$member$upperpar1 par210 10$member$bestmemitpar1 par21 2.8062121 6.211971052 2.2988072 6.799426743 -2.8645593 7.05243041……………199 1.0000000 0.99999997200 1.0000000 0.99999997$member$bestvalit[1] 2.797712e+02 2.311828e+02 1.479378e+02 1.479378e+02 1.297662e+01[6] 1.297662e+01 7.484302e+00 4.177053e+00 1.522458e+00 1.522458e+00[11] 1.522458e+00 1.522458e+00 1.505673e+00 1.505673e+00 1.505673e+00………………………………[191] 7.122327e-16 7.122327e-16 7.122327e-16 7.122327e-16 7.122327e-16[196] 3.010666e-16 3.010666e-16 3.010666e-16 3.010666e-16 3.010666e-16$member$pop[,1] [,2][1,] 1.0000000 1.0000001[2,] 1.0000000 0.9999999[3,] 1.0000000 0.9999999[4,] 1.0000000 1.0000000[5,] -1.6667868 2.8245124[6,] 1.0000001 1.0000001[7,] 1.0000001 1.0000002[8,] 1.0000000 1.0000001[9,] 1.0000000 1.0000000[10,] 1.0000000 1.0000000[11,] 1.0000000 1.0000000[12,] 1.0000000 1.0000000[13,] 1.0000000 1.0000000[14,] 1.0000000 1.0000001[15,] 1.0000000 1.0000000[16,] 1.0000000 1.0000001[17,] 1.0000000 1.0000001[18,] 0.9999999 0.9999999[19,] 1.0000000 1.0000000[20,] -1.6708498 2.9124751$member$storepoplist()attr(,"class")[1] "DEoptim">>> ## increase the population size> DEoptim(Rosenbrock, lower, upper, DEoptim.control(NP = 100))Iteration: 1 bestvalit: 0.831267 bestmemit: 0.993395 1.078004Iteration: 2 bestvalit: 0.831267 bestmemit: 0.993395 1.078004Iteration: 3 bestvalit: 0.136693 bestmemit: 1.238842 1.506507……………………………. .Iteration: 199 bestvalit: 0.000000 bestmemit: 1.000000 1.000000Iteration: 200 bestvalit: 0.000000 bestmemit: 1.000000 1.000000$optim$optim$bestmempar1 par21 1$optim$bestval[1] 1.561559e-22$optim$nfeval[1] 402$optim$iter[1] 200$member$member$lowerpar1 par2-10 -10$member$upperpar1 par210 10$member$bestmemitpar1 par21 -0.05055801 -0.35875922 0.99339454 1.07800423 0.99339454 1.0780042……………………………199 1.00000000 1.0000000200 1.00000000 1.0000000$member$bestvalit[1] 1.415855e+01 8.312672e-01 8.312672e-01 1.366929e-01 1.366929e-01[6] 1.366929e-01 1.366929e-01 1.366929e-01 1.366929e-01 5.009681e-02……………………………[196] 1.273210e-21 1.273210e-21 3.241491e-22 3.241491e-22 1.561559e-22
$member$pop[,1] [,2][1,] 1.000000 1.000000[2,] 1.000000 1.000000[3,] 1.000000 1.000000[4,] 1.000000 1.000000[5,] 1.000000 1.000000……………………[100,] 1.000000 1.000000$member$storepoplist()attr(,"class")[1] "DEoptim">>> ## change other settings and store the output> outDEoptim <- DEoptim(Rosenbrock, lower, upper,+ DEoptim.control(NP = 80,+ itermax = 400, F = 1.2, CR = 0.7))Iteration: 1 bestvalit: 3.635506 bestmemit: 1.317411 1.547563Iteration: 2 bestvalit: 3.635506 bestmemit: 1.317411 1.547563Iteration: 3 bestvalit: 3.635506 bestmemit: 1.317411 1.547563Iteration: 4 bestvalit: 3.635506 bestmemit: 1.317411 1.547563Iteration: 5 bestvalit: 3.635506 bestmemit: 1.317411 1.547563……………………………. .Iteration: 399 bestvalit: 0.000000 bestmemit: 1.000000 1.000000Iteration: 400 bestvalit: 0.000000 bestmemit: 1.000000 1.000000>> ## plot the output> plot(outDEoptim)> # Outputting: Figure 6.17

Figure 6.17 > plot(outDEoptim).
>> ## 'Wild' function, global minimum at about -15.81515> Wild <- function(x)+ 10 * sin(0.3 * x) * sin(1.3 * x^2) ++ 0.00001 * x^4 + 0.2 * x + 80>> plot(Wild, -50, 50, n = 1000, main = "'Wild function'")> # Outputting: Figure 6.18

Figure 6.18 > plot(Wild, -50, 50, n = 1000, main = "'Wild function'").
>> outDEoptim <- DEoptim(Wild, lower = -50, upper = 50,+ control = DEoptim.control(trace = FALSE))> plot(outDEoptim)> # Outputting: Figure 6.19

Figure 6.19 > plot(outDEoptim).
>> DEoptim(Wild, lower = -50, upper = 50,+ control = DEoptim.control(NP = 50))Iteration: 1 bestvalit: 68.834199 bestmemit: -15.802280Iteration: 2 bestvalit: 68.834199 bestmemit: -15.802280Iteration: 3 bestvalit: 67.562828 bestmemit: -15.509441Iteration: 4 bestvalit: 67.562828 bestmemit: -15.509441Iteration: 5 bestvalit: 67.562828 bestmemit: -15.509441……………………………Iteration: 199 bestvalit: 67.467735 bestmemit: -15.815151Iteration: 200 bestvalit: 67.467735 bestmemit: -15.815151$optim$optim$bestmempar1-15.81515$optim$bestval[1] 67.46773$optim$nfeval[1] 402$optim$iter[1] 200$member$member$lowerpar1-50$member$upperpar150$member$bestmemitpar11 -25.660722 -15.802283 -15.802284 -15.509445 -15.50944………………………….199 -15.81515200 -15.81515$member$bestvalit[1] 69.34871 68.83420 68.83420 67.56283 67.56283 67.56283 67.48859 67.48859……………………………[193] 67.46773 67.46773 67.46773 67.46773 67.46773 67.46773 67.46773 67.46773$member$pop[,1][1,] -15.66161[2,] -15.66161[3,] -15.81515……………………….[49,] -15.66161[50,] -15.66161$member$storepoplist()attr(,"class")[1] "DEoptim"> ## The below examples shows how the call to DEoptim can be> ## parallelized.> ## Note that if your objective function requires packages to be> ## loaded or has arguments supplied via code{...}, these should be> ## specified using the code{packages} and code{parVar} arguments> ## in control.> ## Not run:> Genrose <- function(x) {+ ## One generalization of the Rosenbrock banana valley function (n parameters)+ n <- length(x)+ ## make it take some time ...+ Sys.sleep(.001)+ 1.0 + sum (100 * (x[-n]^2 - x[-1])^2 + (x[-1] - 1)^2)+ }>> # get some run-time on simple problems> maxIt <- 250> n <- 5> oneCore <- system.time( DEoptim(fn=Genrose, lower=rep(-+ 25, n), upper=rep(25, n),+ control=list(NP=10*n, itermax=maxIt)))Iteration: 1 bestvalit: 67180.992768 bestmemit: 0.787009 -4.017866 4.091383 -2.065631 -7.987533Iteration: 2 bestvalit: 67180.992768 bestmemit: 0.787009 -4.017866 4.091383 -2.065631 -7.987533Iteration: 3 bestvalit: 67180.992768 bestmemit: 0.787009 -4.017866 4.091383 -2.065631 -7.987533Iteration: 4 bestvalit: 67180.992768 bestmemit: 0.787009 -4.017866 4.091383 -2.065631 -7.987533Iteration: 5 bestvalit: 42308.544031 bestmemit: 0.787009 -4.017866 0.493543 -2.065631 -7.987533……………………………Iteration: 249 bestvalit: 1.079131 bestmemit: -1.005728 0.991545 0.993995 1.004214 1.004883Iteration: 250 bestvalit: 1.079131 bestmemit: -1.005728 0.991545 0.993995 1.004214 1.004883> withParallel <- system.time( DEoptim(fn=Genrose, lower=rep(-+ 25, n), upper=rep(25, n),+ control=list(NP=10*n, itermax=maxIt, parallelType=1)))Iteration: 1 bestvalit: 1036700.619060 bestmemit: 8.705266 3.108165 -7.886303 -3.630207 -7.869868Iteration: 2 bestvalit: 540605.725273 bestmemit: 6.552843 -2.202845 6.752675 6.739165 2.361229Iteration: 3 bestvalit: 134358.516530 bestmemit: -0.173169 2.578942 -5.957804 1.230374 3.368074Iteration: 4 bestvalit: 134358.516530 bestmemit: -0.173169 2.578942 -5.957804 1.230374 3.368074Iteration: 5 bestvalit: 40126.427537 bestmemit: 0.397502 -3.122870 1.249653 4.073320 -1.059661Iteration: 6 bestvalit: 40126.427537 bestmemit: 0.397502 -3.122870 1.249653 4.073320 -1.059661……………………………. .Iteration: 249 bestvalit: 2.071510 bestmemit: 0.904367 0.836285 0.691696 0.466066 0.219700Iteration: 250 bestvalit: 2.071510 bestmemit: 0.904367 0.836285 0.691696 0.466066 0.219700> ## Compare timings> (oneCore)user system elapsed0.00 0.00 12.58> (withParallel)user system elapsed0.42 0.21 5.86>