Akshay Kulkarni1, Adarsha Shivananda2, Anoosh Kulkarni3 and V Adithya Krishnan4
(1)
Bangalore, Karnataka, India
(2)
Hosanagara tq, Shimoga dt, Karnataka, India
(3)
Bangalore, India
(4)
Navi Mumbai, India
The previous chapters implemented recommendation engines using content-based and collaborative-based filtering methods. Each method has its pros and cons. Collaborative filtering suffers from cold-start, which means when there is a new customer or item in the data, recommendation won’t be possible.
Content-based filtering tends to recommend similar items to that purchased/liked before, becoming repetitive. There is no personalization effect in this case.
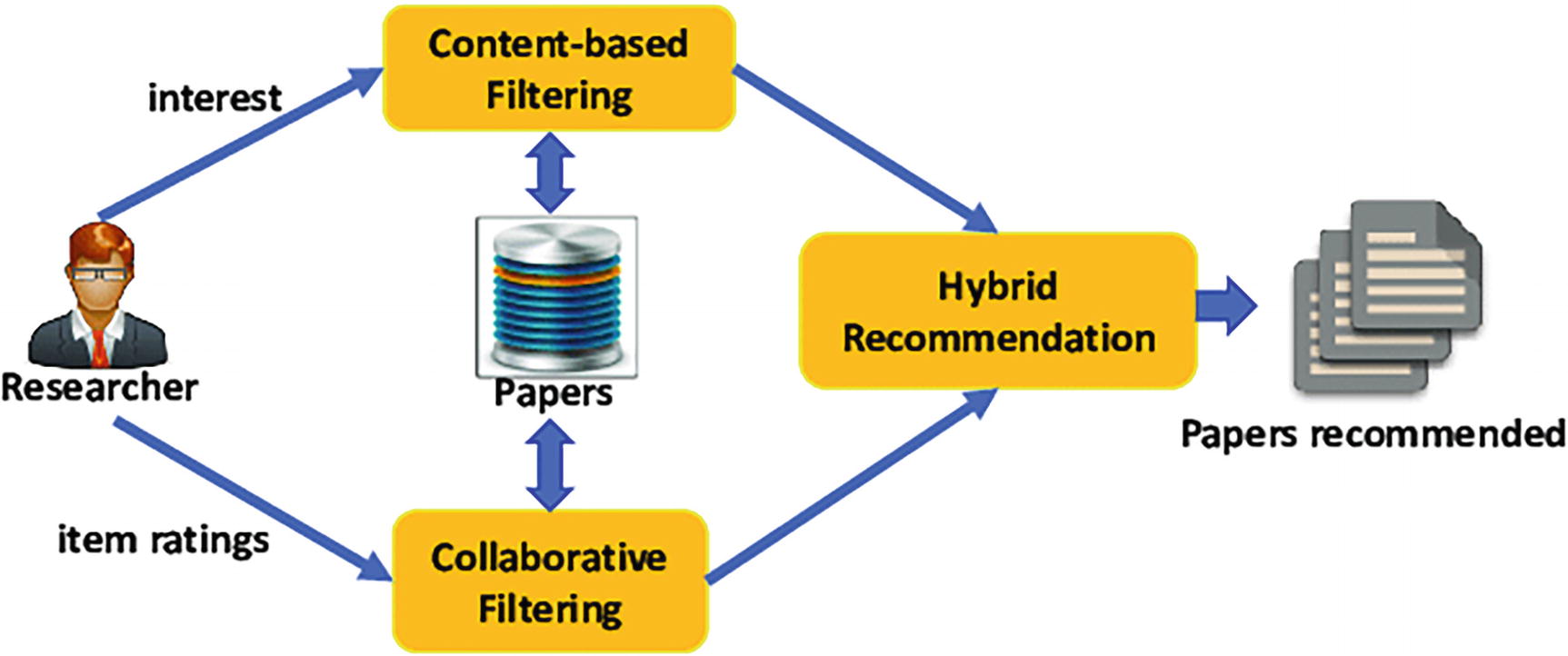
An architecture of hybrid recommendation system. It starts from researcher to content-based filtering, hybrid recommendation, and collaborative filtering.
To tackle some of these cons, introducing hybrid recommendations systems. Hybrid recommendation systems use a hybrid model (i.e., combining content-based and collaborative filtering methods). It will not only help to overcome the shortcomings of the individual models but also increase efficiency and give better recommendations in most cases.
This chapter implements a hybrid recommendation engine built to recommend products used for an e-commerce company. The LightFM Python package is used for this implementation.
from scipy.sparse import coo_matrix # for constructing sparse matrix
from lightfm import LightFM # for model
from lightfm.evaluation import auc_score
import time
import sklearn
from sklearn import model_selection
Data Collection
This chapter uses the same custom e-commerce dataset used in previous chapters. It can be found at github.com/apress/applied-recommender-systems-python.
An output file depicts the list of the first five orders data frame. It includes invoice number, stock code, quantity, invoice date, delivery date, discount percentage, ship mode, shipping cost, and customer I D.
An output file depicts the list of the first five rows of the customers data frame. It includes customer I D, gender, age, income, zip code, and customer segment.
An output file depicts the list of the first five rows of the products data frame. It includes stock code, product name, description, category, brand, and unit price.
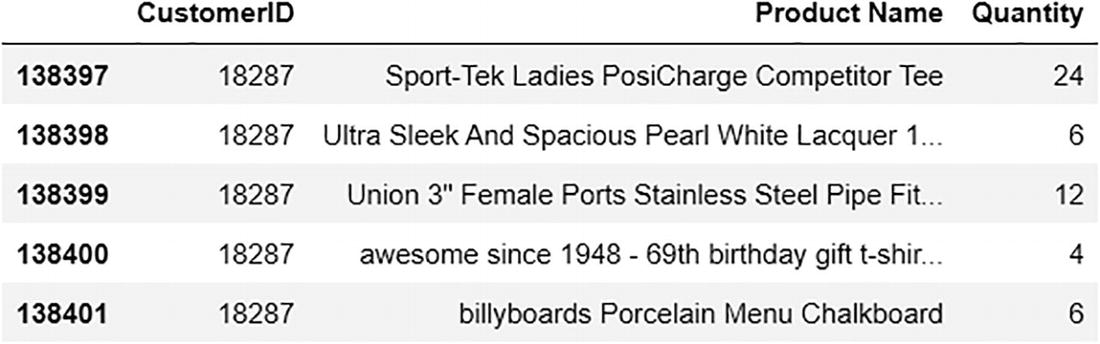
Figure 6-5 shows the merged DataFrame that will be used.
An output file depicts the merged data frame. It includes invoice number, stock code, quantity, invoice date, delivery date, discount percentage, and ship mode followed by details of a single customer.
Figure 6-5
Merged data
Data Preparation
Before building the recommendation model, the required data must be in the proper format so that the model can take input. Let’s get the user-to-product interaction matrix and product-to-features interaction mappings.
Start with getting the list of unique users and unique products. Write two functions to get the unique lists.
array(['Ganma Superheroes Ordinary Life Case For Samsung Galaxy Note 5 Hard Case Cover',
'Eye Buy Express Prescription Glasses Mens Womens Burgundy Crystal Clear Yellow Rounded Rectangular Reading Glasses Anti Glare grade',
...,
'Mediven Sheer and Soft 15-20 mmHg Thigh w/ Lace Silicone Top Band CT Wheat II - Ankle 8-8.75 inches',
Union 3" Female Ports Stainless Steel Pipe Fitting',
'Auburn Leathercrafters Tuscany Leather Dog Collar’,
'3 1/2"W x 32"D x 36"H Traditional Arts & Crafts Smooth Bracket, Douglas Fir'])
Let’s create a function to get the total list of unique values given three feature names from a DataFrame. It gets the total unique list for three features: Customer Segment, Age, and Gender.
Now that we have the unique list for users, products, and features, we need to create ID mappings to convert user_id, item_id, and feature_id into integer indices because LightFM can’t read any other data types.
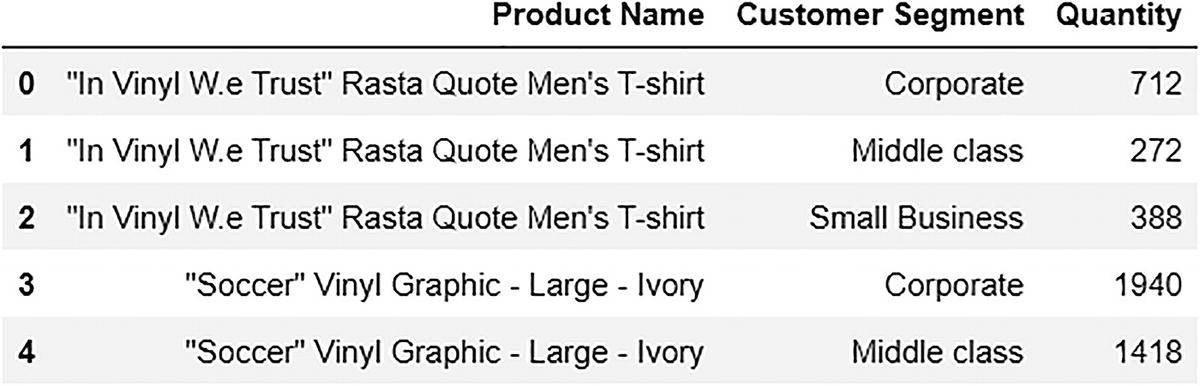
Figure 6-7 shows the product-to-features relationship data.
An output file depicts the relationship data of product-to-features. It includes the product name, customer segment, and quantity of a single customer.
Figure 6-7
Product-to-features relationship data
Let’s split the user-to-product relationship into train and test data.
Now that the data and the ID mappings are in place, to get the user-to-product and product-to-features interaction matrix, let’s first create a function that returns the interaction matrix.
The data is in the correct format, so let’s begin the modeling process. This chapter uses the LightFM model, which can incorporate user and item metadata to form robust hybrid recommendation models.
Let’s try multiple models and then choose the one with the best performance. These models have different hyperparameters, so this is part of the hyperparameter tuning stage of modeling.
The loss function used in the model is one of the parameters to tune. The three values are warp, logistic, and bpr.
Let’s start the model-building experiment.
Attempt 1 is loss = warp, epochs = 1, and num_threads = 4.
# initialising model with warp loss function
model_with_features = LightFM(loss = "warp")
start = time.time()
#===================
# fitting the model with hybrid collaborative filtering + content based (product + features)
print("time taken = {0:.{1}f} seconds".format(end - start, 2))
print("average AUC without adding item-feature interaction = {0:.{1}f}".format(auc_with_features.mean(), 2))
time taken = 0.25 seconds
average AUC without adding item-feature interaction = 0.89
The last model (logistic) performed the best overall (highest AUC score). Let’s merge the train and test and do a final training by using the parameters from the logistic model, which gave 0.89 AUC.
Merge the train and test with the following function.
This function calculates a user’s prediction score (the likelihood to buy) for all items, and the ten highest scored items are recommended. Let’s print the known positives or items bought by that user for validation.
Call the following function for a random user (CustomerID 17017) to get recommendations.
Ganma Superheroes Ordinary Life Case For Samsung Galaxy Note 5 Hard Case Cover
MightySkins Skin Decal Wrap Compatible with Nintendo Sticker Protective Cover 100's of Color Options
Mediven Sheer and Soft 15-20 mmHg Thigh w/ Lace Silicone Top Band CT Wheat II - Ankle 8-8.75 inches
MightySkins Skin Decal Wrap Compatible with OtterBox Sticker Protective Cover 100's of Color Options
MightySkins Skin Decal Wrap Compatible with DJI Sticker Protective Cover 100's of Color Options
MightySkins Skin Decal Wrap Compatible with Lenovo Sticker Protective Cover 100's of Color Options
Ebe Reading Glasses Mens Womens Tortoise Bold Rectangular Full Frame Anti Glare grade ckbdp9088
Window Tint Film Chevy (back doors) DIY
Union 3" Female Ports Stainless Steel Pipe Fitting
Ebe Women Reading Glasses Reader Cheaters Anti Reflective Lenses TR90 ry2209
Recommended:
Mediven Sheer and Soft 15-20 mmHg Thigh w/ Lace Silicone Top Band CT Wheat II - Ankle 8-8.75 inches
MightySkins Skin Decal Wrap Compatible with Apple Sticker Protective Cover 100's of Color Options
MightySkins Skin Decal Wrap Compatible with DJI Sticker Protective Cover 100's of Color Options
3 1/2"W x 20"D x 20"H Funston Craftsman Smooth Bracket, Douglas Fir
MightySkins Skin Decal Wrap Compatible with HP Sticker Protective Cover 100's of Color Options
Owlpack Clear Poly Bags with Open End, 1.5 Mil, Perfect for Products, Merchandise, Goody Bags, Party Favors (4x4 inches)
Ebe Women Reading Glasses Reader Cheaters Anti Reflective Lenses TR90 ry2209
Handcrafted Ercolano Music Box Featuring "Luncheon of the Boating Party" by Renoir, Pierre Auguste - New YorkNew York
A6 Invitation Envelopes w/Peel & Press (4 3/4 x 6 1/2) - Baby Blue (1000 Qty.)
MightySkins Skin Decal Wrap Compatible with Lenovo Sticker Protective Cover 100's of Color Options
Many recommendations align with the known positives. This provides further validation. This hybrid recommendation engine can now get recommendations for all other users.
Summary
This chapter discussed hybrid recommendation engines and how they can overcome the shortfalls of other types of engines. It also showcased the implementation with the help of LightFM.

{kind=link}