
6. Transparency: Let There Be Light
Beauty is more important in computing than anywhere else in technology because software is so complicated. Beauty is the ultimate defense against complexity.
Machine Beauty: Elegance and the Heart of Technology (1998)
—David Gelernter
In the previous chapter we discussed the importance of textual data formats and application protocols, representations that are easy for human beings to examine and interact with. These promote qualities in design that are much valued in the Unix tradition but seldom if ever talked about explicitly: transparency and discoverability.
Software systems are transparent when they don’t have murky corners or hidden depths. Transparency is a passive quality. A program is transparent when it is possible to form a simple mental model of its behavior that is actually predictive for all or most cases, because you can see through the machinery to what is actually going on.
Software systems are discoverable when they include features that are designed to help you build in your mind a correct mental model of what they do and how they work. So, for example, good documentation helps discoverability to a user. Good choice of variable and function names helps discoverability to a programmer. Discoverability is an active quality. To achieve it in your software you cannot merely fail to be obscure, you have to go out of your way to be helpful.1
1 An economically-minded friend comments: “Discoverability is about reducing barriers to entry; transparency is about reducing the cost of living in the code”.
Transparency and discoverability are important for both users and software developers. But they’re important in different ways. Users like these properties in a UI because they mean an easier learning curve. UI transparency and discoverability are a large part of what people mean when they say a UI is ’intuitive’; most of the rest is the Rule of Least Surprise. We’ll examine the properties that make user interfaces pleasant and effective in more depth in Chapter 11.
Software developers like these qualities in the code itself (the part users don’t see) because they so often need to understand it well enough to modify and debug it. Also, a program designed so that its internal data flows are readily comprehensible is more likely to be one that does not fail because of bad interactions that the designer didn’t notice, and more likely to be able to evolve forward gracefully (including accommodating change when new maintainers pick up the baton).
Transparency is a major component of what David Gelernter refers to as “beauty” in this chapter’s epigraph. Unix programmers, borrowing from mathematicians, often use the more specific term “elegance” for the quality Gelernter speaks of. Elegance is a combination of power and simplicity. Elegant code does much with little. Elegant code is not only correct but visibly, transparently correct. It does not merely communicate an algorithm to a computer, but also conveys insight and assurance to the mind of a human that reads it. By seeking elegance in our code, we build better code. Learning to write transparent code is a first, long step toward learning how to write elegant code—and taking care to make code discoverable helps us learn how to make it transparent. Elegant code is both transparent and discoverable.
It may be easier to appreciate the difference between transparency and discoverability with a pair of extreme examples. The Linux kernel source is remarkably transparent (given the intrinsic complexity of what it does) but not at all discoverable—acquiring the minimum knowledge needed to live in the code and understand the idiom of the developers is difficult, but once you do the whole makes sense.2 On the other hand, the Emacs Lisp libraries are discoverable but not transparent. It’s easy to acquire enough knowledge to tweak just one thing, but quite difficult to comprehend the whole system.
2 The Linux kernel makes a number of attempts at discoverability, including the Documentation subdirectory in the Linux kernel source tarball and quite a number of tutorial websites and books. These attempts are frustrated by the speed at which the kernel changes; the documentation has a chronic tendency to fall behind.
In this chapter, we’ll examine features of Unix designs that promote transparency and discoverability not just in UIs but in the parts users don’t normally see. We’ll develop some useful rules you can apply to your coding and development practice. Later on, in Chapter 19 we’ll see how good release-engineering practices (like having a README file with appropriate content) can make your source code as discoverable as your design.
If you need a practical reminder why these qualities are important, remember that the sanity you save by writing transparent, discoverable systems may well be that of your own future self.
6.1 Studying Cases
Normal practice in this book has been to intersperse case studies with philosophy. But in this chapter we’ll begin by looking at several Unix designs that exhibit transparency and discoverability, and attempt to draw lessons from them only after all have been presented. Each major point of the analysis in the latter half of this chapter draws on several of these, and the arrangement avoids forward references to case studies the reader hasn’t seen yet.
6.1.1 Case Study: audacity
First, we’ll look at an example of transparency in UI design. It is audacity, an open-source editor for sound files that runs on Unix systems, Mac OS X, and Windows. Sources, downloadable binaries, documentation, and screen shots are available at the project site <http://audacity.sourceforge.net/>.
This program supports cutting, pasting, and editing of audio samples. It supports multitrack editing and mixing. The UI is superbly simple; the sound waveforms are shown in the audacity window. The image of the waveform can be cut and pasted; operations on that image are directly reflected in the audio sample as soon as they are performed.
Figure 6.1. Screen shot of audacity.

Multitrack editing is supported in the simplest possible way; the screen splits into multiple per-track displays in a spatial relationship that conveys their concurrency and makes it easy to match features by inspection. Tracks can be dragged right or left with the mouse to change their relative timing.
Several features of this UI are subtly excellent and worthy of emulation: the large, easily visible and clickable operation buttons with distinguishing colors, the presence of an undo command that removes most of the risk from experimentation, the volume slider that makes softness/loudness visually obvious in its shape.
But these are details. The central virtue of this program is that it has a superbly transparent and natural user interface, one that erects as few barriers between the user and the sound file as possible.
6.1.2 Case Study: fetchmail’s -v option
fetchmail is a network gateway program. Its main purpose is to translate between POP3 or IMAP remote-mail protocols and the Internet’s native SMTP protocol for email exchange. It is in extremely widespread use on Unix machines that use intermittent SLIP or PPP connections to Internet service providers, and as such probably touches an appreciable fraction of the Internet’s mail traffic.
fetchmail has no fewer than 60 command-line options (which, as we’ll establish later in this book, is probably too many), and a number of other options that are settable from the run-control file but not from the command line. Of all these, the most important—by far—is -v, the verbose option.
When -v is on, fetchmail dumps each one of its POP, IMAP, and SMTP transactions to standard output as they happen. A developer can actually see the code doing protocol with remote mailservers and the mail transport program it forwards to, in real time. Users can send session transcripts with their bug reports. Example 6.1 shows a representative session transcript.

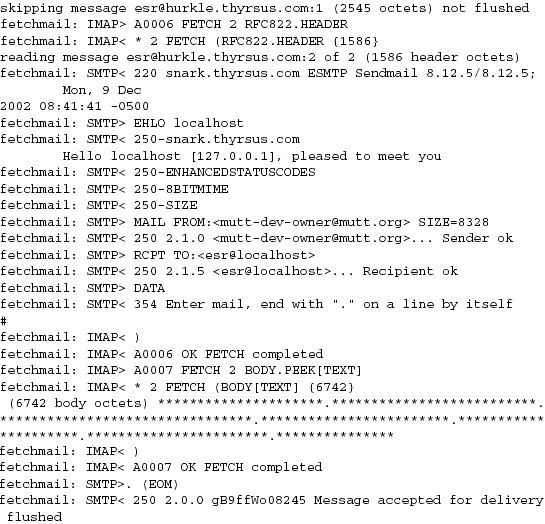
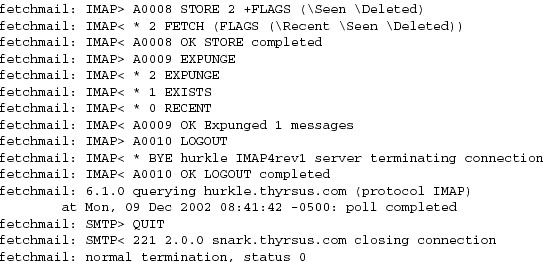
The -v option makes what fetchmail is doing discoverable (by letting you see the protocol exchanges). This is immensely useful. I considered it so important that I wrote special code to mask account passwords out of -v transaction dumps so that they could be passed around and posted without anyone having to remember to edit sensitive information out of them.
This turned out to be a good call. At least eight out of ten problems reported get diagnosed within seconds of a knowledgeable person’s eyes seeing a session transcript. There are several knowledgeable people on the fetchmail mailing list—in fact, because most bugs are easy to diagnose, I seldom have to handle them myself.
Over the years, fetchmail has acquired a reputation as a rather bulletproof program. It can be misconfigured, but it very seldom outright breaks. Betting that this has nothing to do with the fact that the exact circumstances of eight out of ten bugs are rapidly discoverable would not be smart.
We can learn from this example. The lesson is this: Don’t let your debugging tools be mere afterthoughts or treat them as throwaways. They are your windows into the code; don’t just knock crude holes in the walls, finish and glaze them. If you plan to keep the code maintained, you’re always going to need to let light into it.
6.1.3 Case Study: GCC
GCC, the GNU C compiler used on most modern Unixes, is perhaps an even better example of engineering for transparency. GCC is organized as a sequence of processing stages knit together by a driver program. The stages are: preprocessor, parser, code generator, assembler, and linker.
Each of the first three stages takes in a readable textual format and emits a readable textual format (the assembler has to emit and the linker to accept binary formats, pretty much by definition). With various command-line options of the gcc(1) driver, you can see not just the results after C preprocessing, after assembly generation, and after object code generation—but you can also monitor the results of many intermediate steps in parsing and code generation.
This is exactly the structure of cc, the first (PDP-11) C compiler.
—Ken Thompson
There are many benefits of this organization. One that is particularly important for GCC is regression testing.3 Because most of the various intermediate formats are textual, deviations from expected results in a regression test are easily spotted and analyzed using simple textual diff operations on the intermediate results; there is no need for specialist dump-analysis tools that may well harbor their own bugs, and in any case would represent an additional maintenance burden.
3 Regression testing is a method for detecting bugs introduced as software is modified. It consists of periodically checking the output of the changing software for some fixed test input against a snapshot of output captured at an earlier stage of the process and known (or assumed) to be correct.
The design pattern to extract from this example is that the driver program has monitoring switches that merely (but sufficiently) expose the textual data flows among the components. As with fetchmail’s -v option, these options are not afterthoughts; they are designed in for discoverability.
6.1.4 Case Study: kmail
kmail is the GUI mailreader distributed with the KDE environment. The kmail UI is tastefully and well designed, with many good features including automatic display of enclosed images in a MIME multipart and support for PGP key encryption/decryption. It is friendly to end-users—my beloved but nontechie wife uses and enjoys it.
Many mail user agents make one gesture in the direction of discoverability by having a command that toggles display of all the mail headers, as opposed to a select few like From and Subject. The UI of kmail takes this a long step further.
A running kmail displays status notifications in a one-line subwindow at the bottom of its window, in small type over a steel-gray background clearly modeled on the Netscape/Mozilla status bar. When you open a mailbox, for example, the status bar displays counts of total and unread messages. The visual presentation is unobtrusive; it is easy to ignore the notifications, but also easy to focus on them if you want to.
Figure 6.2. Screen shot of kmail.
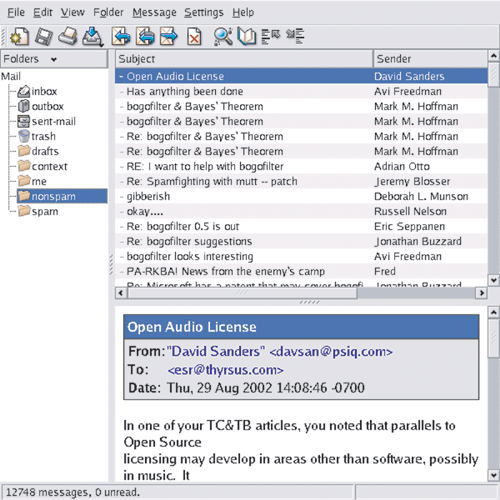
The kmail GUI is good user-interface design. It’s informative, but not distracting; it gets around the reason we adduce in Chapter 11 that the best policy for Unix tools operating normally is usually silence. The authors showed excellent taste in borrowing the look and feel of the browser status bar.
But the extent of the kmail developers’ tastefulness will not become clear until you have to troubleshoot an installation that is having trouble sending mail. If you watch closely during the send, you will observe that each line of the SMTP transaction with the remote mail transport is echoed into the kmail status bar as it happens.
The kmail developers neatly avoid a trap that often makes GUI programs like kmail a terrible pain in a troubleshooter’s fundament. Most design teams with kmail’s objectives would have suppressed those messages entirely, fearing that they would give Aunt Tillie a touch of the vapors that would drive her back to the meretricious pseudo-simplicity of a Windows box.
Instead, they designed for transparency—they made the transaction messages show, but also made them visually easy to ignore. By getting the presentation right, they managed to please both Aunt Tillie and her geeky nephew Melvin who fixes her computer problems. This was brilliant; it’s a technique other GUI interfaces could and should emulate.
Ultimately, of course, the visibility of those messages is good for Aunt Tillie, because they mean Melvin is far less likely to throw up his hands in frustration while trying to solve her email problems.
The lesson here is clear. Dumbing down your UI is only the half-smart thing to do. The really smart thing is to find a way to leave the details accessible, but make them unobtrusive.
6.1.5 Case Study: SNG
The program sng translates between PNG format and an all-text representation of it (SNG or Scriptable Network Graphics format) that can be examined and modified with an ordinary text editor. Run on a PNG file, it produces an SNG file; run on an SNG file, it recovers the equivalent PNG. The transformation is 100% faithful and lossless in both directions.
In syntactic style, SNG resembles CSS (Cascading Style Sheets), another language for controlling presentation of graphics; this makes at least a gesture in the direction of the Rule of Least Surprise. Here is a test example:
Example 6.2. An SNG Example.


The point of this tool is to enable users to edit various obscure PNG chunk types that are not necessarily supported by conventional graphics editors. Rather than writing special-purpose code to grovel through the PNG binary format, the user can simply flip an image into an all-text representation, edit that, and massage it back. Another potential application is in making images amenable to version control; under most version-control systems, text files are much easier to manage than binary blobs, and diff operations on SNG representations actually have some possibility of yielding useful information.
The gains here go beyond the time not spent writing special-purpose code for manipulating binary PNGs, however. The code of the sng program itself is not especially transparent, but it promotes transparency in larger systems of programs by making the entire contents of PNGs discoverable.
6.1.6 Case Study: The Terminfo Database
The terminfo database is a collection of descriptions of video-display terminals. Each entry describes the escape sequences that perform various manipulations on the terminal screen, such as inserting or deleting lines, erasing from the cursor position to end of line or screen, or beginning and ending screen highlights such as reverse video, underline, or blink.
The terminfo database is primarily used by the curses(3) libraries. These underlie the “roguelike” interface style we discuss in Chapter 11, and some very widely used programs such as mutt(1), lynx(1), and slrn(1). Though the terminal emulators such as xterm(1) that run on today’s bitmapped displays all have capabilities that are minor variations on those of the ANSI X3.64 standard and the venerable VT100 terminal, there is still enough variation that hardwiring ANSI capabilities into applications would be a bad idea. Terminfo is also worth studying because problems that are logically similar to the one it addressed arise constantly in managing other kinds of peripheral hardware that doesn’t have a standard way to report their own capabilities.
The design of terminfo benefits from experience with an earlier capability format called termcap. The database of termcap descriptions lived in a textual format in one big file, /etc/termcap; though this format is now obsolete, your Unix system almost certainly includes a copy.
Normally, the key used to look up your terminal type entry is the environment variable TERM, which for purposes of this case study is set by magic.4 Applications that use terminfo (or termcap) pay a small penalty in startup lag; when the curses(3) library initializes itself, it has to look up the entry corresponding to TERM and load the entry into memory.
4 Actually, TERM is set by the system at login time. For actual terminals on serial lines, the mapping from tty lines to TERM values is set from a system configuration file at boot time; the details vary among Unixes. Terminal emulators like xterm(1) set this variable themselves.
Experience with termcap showed that the startup penalty was dominated by the time required to parse the textual representation of capabilities. Accordingly, terminfo entries are binary structure dumps that can be marshaled and unmarshaled more quickly. There is a master textual format for the entire database, the terminfo capability file. That file (or individual entries) can be compiled to binary form with the terminfo compiler tic(1); binary entries can be decompiled to the editable text format by infocmp(1).
The design superficially contradicts the advice we gave in Chapter 5 against binary caches, but this is actually the extreme case in which that’s a good tactic. Edits to the text masters are very rare—in fact, Unixes normally ship with the terminfo database precompiled and the text master serving primarily as documentation. Thus, the synchronization and inconsistency problems that would normally militate against this approach almost never arise.
The designers of terminfo could have optimized for speed in a second way. The entire database of binary entries could have been put in some kind of big opaque database file. What they actually did instead was more clever and more in the Unix spirit. Terminfo entries live in a directory hierarchy, usually on modern Unixes under /usr/share/terminfo. Consult the terminfo(5) man page to find the location on your system.
If you look in the terminfo directory, you’ll see subdirectories named by single printable characters. Under each of these are the entries for each terminal type that has a name beginning with that letter. The goal of this organization was to avoid having to do a linear search of a very large directory; under more modern Unix file systems, which represent directories with B-trees or other structures optimized for fast lookup, the subdirectories won’t be necessary.
I found that even on a fairly modern Unix, splitting a big directory up into subdirectories can improve performance substantially. It was tens of thousands of files, an authorized-user database for a big educational institution, on a late-model DEC Alpha running DEC’s Unix. (Subdirectories named by first and last letter of name—e.g., “johnson” would be in directory “j_n”—worked best of the schemes we tested. Using the first two letters wasn’t nearly as good, because there were a lot of systematically-generated names which differed only toward the end.) This may just say that sophisticated directory indexing is still not as common as it should be... but even so, that makes an organization which works well without it more portable than one which requires it.
—Henry Spencer
Thus, the cost of opening a terminfo entry is two file system lookups and a file open. But since mining the same entry from one big database would have required a lookup and open for the database, the incremental cost for terminfo’s organization is at most one file system lookup. Actually, it’s less than that; it’s the cost difference between one file system lookup and whatever retrieval method the one big database would have used. This is probably marginal, and quite tolerable once per application at startup time.
Terminfo uses the file system itself as a simple hierarchical database. This is a superb bit of constructive laziness, obeying the Rule of Economy and the Rule of Transparency. It means that all the ordinary tools for navigating, examining and modifying the file system can be used to navigate, examine, and modify the terminfo database; no special ones (other than tic(1) and infocmp(1) for packing and unpacking the individual records) need to be written and debugged. It also means that work on speeding up database access would be work on speeding up the file system itself, tuning that would benefit many more applications than just users of curses(3).
There is one additional advantage of this organization that doesn’t come up in the terminfo case; you get to use Unix’s permissions mechanism rather than having to invent your own access-control layer with its own bugs. This falls out as a consequence of adopting the “everything is a file” philosophy of Unix rather than trying to fight it.
The terminfo directory layout is rather space-inefficient on most Unix file systems. The entries are usually between 400 and 1400 bytes long, but file systems normally allocate a minimum of 4K for every nonempty disk file. The designers accepted this cost for the same reason they chose a packed binary format, to cut the startup latency of terminfo-using programs to a minimum. Disk capacity for constant price has exploded over a thousandfold since, tending to vindicate that decision.
The contrast with the formats used by the Microsoft Windows registry files is instructive. Registries are property databases used by both Windows itself and applications. Each registry lives in one big file. Registries contain a mix of text and binary data that requires specialized editing tools. The one-big-file approach leads, among other things, to the notorious ’registry creep’ phenomenon; average access time rises without bound as new entries are added. Because there is no standard API for editing the registry provided by the system, applications use ad-hoc code to edit it themselves, making it notoriously subject to corruption that can lock up the entire system.
Using the Unix file system as a database is a tactic other applications with simple database requirements might do well to emulate. Good reasons not to do it are more likely to have to do with the database keys not naturally looking like filenames than they are with any performance problems. In any case, it’s the sort of good fast hack that can be very useful in prototyping.
6.1.7 Case Study: Freeciv Data Files
Freeciv is an open-source strategy game inspired by Sid Meier’s classic Civilization II. In it, each player begins with a wandering band of neolithic nomads and builds a civilization. Player civilizations may explore and colonize the world, fight wars, engage in trade, and research technological advances. Some players may actually be artificial intelligences; solitaire play against these can be challenging. One wins either by conquering the world or by being the first player to reach a technology level sufficient to get a starship to Alpha Centauri. Sources and documentation are available at the project site <http://www.freeciv.org/>.
Figure 6.3. Main window of a Freeciv game.

In Chapter 7 we’ll exhibit the Freeciv strategy game as an example of client-server partitioning, with the server maintaining shared state and the client concentrating on GUI presentation. But this game has another notable architectural feature; much of the game’s fixed data, rather than being wired into the server code, is expressed in a property registry read in by the game server at startup time.
The game’s registry files are written in a textual data-file format that assembles text strings (with associated text and numeric properties) into various internal lists of important data (such as nations and unit types) in the game server. The minilanguage has an include directive, so game data can be broken up into semantic units (different files) that are each separately editable. This design choice has been carried through to such an extent that it’s possible to define new nations and new unit types simply by creating new declarations in the data files, without touching the server code at all.
The Freeciv server’s startup parsing has an interesting feature that creates something of a conflict between two of Unix’s design rules, and is therefore worth closer examination. The server ignores property names it doesn’t know how to use. This makes it possible to declare properties that the server doesn’t yet use without breaking the startup parsing. It means that development of the game data (policy) and the server engine (mechanism) can be cleanly separated. On the other hand, it also means startup parsing won’t catch simple misspellings of attribute names. This quiet failure seems to violate the Rule of Repair.
To resolve this conflict, notice that it’s the server’s job to use the registry data, but the task of carefully error-checking that data could be handed off to another program to be run by human editors each time the registry is modified. One Unix solution would be a separate auditing program that analyzes either a machine-readable specification of the ruleset format or the source of the server code to determine the set of properties it uses, parses the Freeciv registry to determine the set of properties it provides, and prepares a difference report.5
5 The ur-ancestor of such validator programs under Unix was lint, a validator for C code separate from the C compiler. Though GCC has absorbed its functions, old Unix hands are still apt to refer to the process of running a validator as ’linting’, and the name survives in utilities such as xmllint.
The aggregate of all Freeciv data files is functionally similar to a Windows registry, and even uses a syntax resembling the textual portions of registries. But the creep and corruption problems we noted with the Windows registry don’t crop up here because no program (either within or outside the Freeciv suite) writes to these files. It’s a read-only registry edited only by the game’s maintainers.
The performance impact of data-file parsing is minimized because for each file the operation is performed only once, at either client or server startup time.
6.2 Designing for Transparency and Discoverability
To design for transparency and discoverability, you need to apply every tactic for keeping your code simple, and also concentrate on the ways in which your code is a communication to other human beings. The first questions to ask, after “Will this design work?” are “Will it be readable to other people? Is it elegant?” We hope it is clear by now that these questions are not fluff and that elegance is not a luxury. These qualities in the human reaction to software are essential for reducing its bugginess and increasing its long-term maintainability.
6.2.1 The Zen of Transparency
One pattern that emerges from the examples we’ve examined so far in this chapter is this: If you want transparent code, the most effective route is simply not to layer too much abstraction over what you are manipulating with the code.
In Chapter 4’s section on the value of detachment, our advice was to abstract and simplify and generalize, to try and detach from the particular, accidental conditions under which a design problem was posed. The advice to abstract does not actually contradict the advice against excessive abstractions we’re developing here, because there is a difference between getting free of assumptions and forgetting the problem you’re trying to solve. This is part of what we were driving at when we developed the idea that glue layers need to be kept thin.
One of the main lessons of Zen is that we ordinarily see the world through a haze of preconceptions and fixed ideas that proceed from our desires. To achieve enlightenment, we must follow the Zen teaching not merely to let go of desire and attachment, but to experience reality exactly as it is—without the preconceptions and the fixed ideas getting in the way.
This is excellent pragmatic advice for software designers. It’s part of what’s implicit in the classic Unix advice to be minimalist. Software designers are clever people who form ideas (abstractions) about the application domains they deal with. They organize the software they write around those ideas. Then, when debugging, they often find they have great trouble seeing through those ideas to what is actually going on.
Any Zen master would recognize this problem instantly, yell “Three pounds of flax!”, and probably clout the student a good one.6 Consciously designing for transparency is a slightly less mystical way of addressing it.
6 See the koan called Tozan’s Three Pounds in the Gateless Gate [Mumon].
In Chapter 4 we criticized object-oriented programming in terms likely to prove a bit shocking to programmers who were raised on the 1990s gospel of OO. Object-oriented design doesn’t have to be over-complicated design, but we’ve observed that too often it is. Too many OO designs are spaghetti-like tangles of is-a and has-a relationships, or feature thick layers of glue in which many of the objects seem to exist simply to hold places in a steep-sided pyramid of abstractions. Such designs are the opposite of transparent; they are (notoriously) opaque and difficult to debug.
As we’ve previously noted, Unix programmers are the original zealots about modularity, but tend to go about it in a quieter way. Keeping glue layers thin is part of it; more generally, our tradition teaches us to build lower, hugging the ground with algorithms and structures that are designed to be simple and transparent.
As with Zen art, the simplicity of good Unix code depends on exacting self-discipline and a high level of craft, neither of which are necessarily apparent on casual inspection. Transparency is hard work, but worth the effort for more than merely artistic reasons. Unlike Zen art, software requires debugging—and usually needs continuing maintenance, forward-porting, and adaptation throughout its lifetime. Transparency is therefore more than an esthetic triumph; it is a victory that will be reflected in lower costs throughout the software’s life cycle.
6.2.2 Coding for Transparency and Discoverability
Transparency and discoverability, like modularity, are primarily properties of designs, not code. It is not sufficient to get right the low-level elements of style, such as indenting code in a clear and consistent way or having good variable-naming conventions. These qualities have much more to do with code properties that are less obvious to inspection. Here are a few to think about:
• What is the maximum static depth of your procedure-call hierarchy? That is, leaving out recursions, how many levels of call might a human have to model mentally to understand the operation of the code? Hint: If it’s more than four, beware.
• Does the code have invariant properties7 that are both strong and visible? Invariant properties help human beings reason about code and detect problem cases.
7 An invariant is a property of a software design that is preserved by every operation in it. For example, in most databases it is an invariant that no two records may have the same key. In a C program that correctly manipulates strings, every string buffer must contain a terminating NUL byte on exit from each string function. In an inventory system, no parts count can hold a number less than zero.
• Are the function calls in your APIs individually orthogonal, or do they have too many magic flags and mode bits that have a single call doing multiple tasks? Avoiding mode flags entirely can lead to a cluttered API with too many nigh-identical functions, but the obverse error (lots of easily-forgotten and confusable mode flags) is even more common.
• Are there a handful of prominent data structures or a single global scoreboard that captures the high-level state of the system? Is this state easy to visualize and inspect, or is it diffused among many individual global variables or objects that are hard to find?
• Is there a clean, one-to-one mapping between data structures or classes in your program and the entities in the world that they represent?
• Is it easy to find the portion of the code responsible for any given function? How much attention have you paid to the readability not just of individual functions and modules but of the whole codebase?
• Does the code proliferate special cases or avoid them? Every special case could interact with every other special case; all those potential collisions are bugs waiting to happen. But even more importantly, special cases make the code harder to understand.
• How many magic numbers (unexplained constants) does the code have in it? Is it easy to discover the implementation’s limits (such as critical buffer sizes) by inspection?
It’s best for code to be simple. But if it answers these sorts of questions well, it can be very complex without putting an impossible cognitive burden on a human maintainer.
The reader might find it instructive to compare these with our checklist questions about modularity in Chapter 4.
6.2.3 Transparency and Avoiding Overprotectiveness
Close kin to the programmer tendency to build overelaborate castles of abstractions is a tendency to overprotect others from the low-level details. While it’s not bad practice to hide those details in the program’s normal mode of operation (fetchmail’s -v switch is off by default), they should be discoverable. There’s an important difference between hiding them and making them inaccessible.
Programs that cannot reveal what they are doing make troubleshooting far more difficult. Thus, experienced Unix users actually take the presence of debugging and instrumentation switches as a good sign, and their absence as possibly a bad one. Absence suggests an inexperienced or careless developer; presence suggests one with enough wisdom to follow the Rule of Transparency.
The temptation to overprotect is especially strong in GUI applications targeted for end users, like mail readers. One reason Unix developers have been cool toward GUI interfaces is that, in their designers’ haste to make them ’user-friendly’ each one often becomes frustratingly opaque to anyone who has to solve user problems—or, indeed, interact with it anywhere outside the narrow range predicted by the user-interface designer.
Worse, programs that are opaque about what they are doing tend to have a lot of assumptions baked into them, and to be frustrating or brittle or both in any use case not anticipated by the designer. Tools that look glossy but shatter under stress are not good long-term value.
Unix tradition pushes for programs that are flexible for a broader range of uses and troubleshooting situations, including the ability to present as much state and activity information to the user as the user indicates he is willing to handle. This is good for troubleshooting; it is also good for growing smarter, more self-reliant users.
6.2.4 Transparency and Editable Representations
Another theme that emerges from these examples is the value of programs that flip a problem out of a domain in which transparency is hard into one in which it is easy. Audacity, sng(1) and the tic(1)/infocmp(1) pair all have this property. The objects they manipulate are not readily conformable to the hand and eye; audio files are not visual objects, and although images expressed in PNG format are visual, the complexities of PNG annotation chunks are not. All three applications turn manipulation of their binary file formats into a problem to which human beings can more readily apply intuition and competences gained from everyday experience.
A rule all these examples follow is that they degrade the representation as little as possible—in fact, they translate it reversibly and losslessly. This property is very important, and worth implementing even if there is no obvious application demand for that kind of 100% fidelity. It gives potential users confidence that they can experiment without degrading their data.
All the advantages of textual data-file formats that we discussed in Chapter 5 also apply to the textual formats that sng(1), infocmp(1) and their kin generate. One important application for sng(1) is robotic generation of PNG image annotations by scripts—because sng(1) exists, such scripts are easier to write.
Whenever you face a design problem that involves editing some kind of complex binary object, the Unix tradition encourages asking first off whether you can write a tool analogous to sng(1) or the tic(1)/infocmp(1) pair that can do a lossless mapping to an editable textual format and back. There is no established term for programs of this kind, but we’ll call them textualizers.
If the binary object is dynamically generated or very large, then it may not be practical or possible to capture all the state with a textualizer. In that case, the equivalent task is to write a browser. The paradigm example is fsdb(1), the file-system debugger supported under various Unixes; there is a Linux equivalent called debugfs(1). The psql(1) used to browse PostgreSQL databases, and the smbclient(1) program that can be used to query Windows file shares on a SAMBA-equipped Linux machine, are two more. All five are simple CLI programs that could be driven by scripts and test harnesses.
Writing a textualizer or browser is a valuable exercise for at least four reasons:
• You gain an excellent learning experience. There may be other ways that are as good to learn about the structure of the object, but none that are obviously better.
• You gain the ability to dump the contents of the structure for inspection and debugging. Because such a tool makes dumping easy, you’ll do it more. You’ll get more information, probably leading to more insight.
• You gain the ability to easily generate test loads and unusual cases. This means you are more likely to probe the odd corners of the object’s state space—and to break the associated software, so you can fix it before your users break it.
• You gain code you may be able to reuse. If you’re careful about how you write the browser/textualizer and keep the CLI interpreter properly separated from the marshaling/unmarshaling library, you may find you have code that can be reused for your actual application.
After you’ve done this, you may well discover that it’s possible to apply the “separated engine and interface” pattern (see Chapter 11) using your textualizer/debugger as the engine. All the usual benefits of this pattern will apply.
It is desirable, although often difficult, for a textualizer to be able to read and write even a damaged binary object. For one thing, it lets you generate damaged test cases to stress-test software; for another, it can make emergency repairs a whole lot easier. It may be hard to handle cases in which the structure of the object is messed up, but at least you should handle cases in which the content of the structure is nonsense, e.g., by showing nonsense values in hex and converting the hex back to the values.
—Henry Spencer
6.2.5 Transparency, Fault Diagnosis, and Fault Recovery
Yet another benefit of transparency, related to ease of debugging, is that transparent systems are easier to perform recovery actions on after a bug bites—and, often, more resistant to damage from bugs in the first place.
In comparing the terminfo database with Windows registries we noted that registries are notoriously subject to being corrupted by buggy application code. This can make the entire system unusable. Even if it doesn’t, recovery can be difficult if the corruption confuses the specialized registry-editing tools.
Our Unix case studies illustrate ways that designing for transparency can prevent this class of problem. Because the terminfo database is not one big file, botching one terminfo entry does not make the whole terminfo data set unusable. Fully textual one-big-file formats like termcap are usually parsed with methods which (unlike block reads of binary structure dumps) can recover from single-point errors. Syntax errors in an SNG file can be corrected by hand without requiring specialized editors that might refuse to load a damaged PNG image.
Going back to the kmail case study, that program makes fault diagnosis easier because it obeys the Rule of Repair: SMTP failures are noisy, usefully so. You don’t have to decode a layer of obfuscatory messages generated by kmail itself to see what the interaction with the SMTP server looks like. All you have to do is look in the right place, because kmail is being transparent and not throwing away information about the error state. (It helps that SMTP itself is textual and includes human-readable status messages in its transactions.)
Discoverability tools like textualizers and browsers also make fault diagnosis easier. We’ve already touched on one reason: they make inspecting the state of the system easier. But there is another effect at work as well; textualized versions of data tend to have useful redundancies (such as using whitespace for visual separation as well as explicit delimiters for parsing). These are present to make them easier to read for humans, but also have the effect of making them more resistant to being irreparably trashed by point failures. A corrupted chunk in a PNG file is seldom recoverable, but the human capacity for pattern recognition and reasoning from context might be able to repair the equivalent SNG form.
Over and over again, the Rule of Robustness is clear. Simplicity plus transparency lowers costs, reduces everybody’s stress, and frees people to concentrate on new problems rather than cleaning up after old mistakes.
6.3 Designing for Maintainability
Software is maintainable to the extent that people who are not its author can successfully understand and modify it. Maintainability demands more than code that works; it demands code that follows the Rule of Clarity and communicates successfully to human beings as well as the computer.
Unix programmers have a lot of implicit knowledge available to them about what makes for maintainable code, because Unix hosts source code that goes back decades. For reasons we’ll discuss in Chapter 17, Unix programmers learn a tendency to scrap and rebuild rather than patching grubby code (see Rob Pike’s meditation on this subject in Chapter 1). Thus, any sources that have survived more than a decade of evolutionary pressure have been selected for maintainability. These old, successful, well-established projects with maintainable code are the community’s models for practice.
A question Unix programmers—and especially Unix programmers in the open-source world—learn to ask about tools they are evaluating for use is: “Is this code live, dormant, or dead?” Live code has an active developer community attached to it. Dormant code has often become dormant because the pain of maintaining it exceeded its utility to its originators. Dead code has been dormant for so long that it would be easier to reimplement an equivalent from scratch. If you want your code to live, investing effort to make it maintainable (and therefore attractive to future maintainers) will be one of the most effective ways you can spend your time.
Code that is designed to be both transparent and discoverable has gone a long way toward being maintainable. But there are other practices we can observe in the model projects in this chapter that are worth emulating.
One very important practice is an application of the Rule of Clarity: choosing simple algorithms. In Chapter 1 we quoted Ken Thompson: “When in doubt, use brute force”. Thompson understood the full cost of complicated algorithms—not just that they’re more bug-prone when initially implemented, but that they’re harder for maintainers down the line to understand.
Another important practice is the inclusion of hacker’s guides. It has always been highly approved behavior for source code distributions to include guide documents informally describing the key data structures and algorithms in the code. In fact, Unix programmers have often been better about producing hacker’s guides than they are about writing end-user documentation.
The open-source community has seized on and elaborated this custom. Besides being advice to future maintainers, hacker’s guides for open-source projects are also designed to make it easy for casual contributors to add features or fix bugs. The Design Notes file shipped with fetchmail is representative. The Linux kernel sources include literally dozens of these.
In Chapter 19 we’ll describe conventions that Unix developers have evolved for making source code distributions easy to examine and easy to build running code from. These practices, too, promote maintainability.