
18. Documentation: Explaining Your Code to a Web-Centric World
I’ve never met a human being who would want to read 17,000 pages of documentation, and if there was, I’d kill him to get him out of the gene pool.
—Joseph Costello
Unix’s first application, in 1971, was as a platform for document preparation—Bell Labs used it to prepare patent documents for filing. Computer-driven phototypesetting was still a novel idea then, and for years after it debuted in 1973 Joe Ossana’s troff(1) formatter defined the state of the art.
Ever since, sophisticated document formatters, typesetting software, and page-layout programs of various sorts have been an important theme in the Unix tradition. While troff(1) has proven surprisingly durable, Unix has also hosted a lot of groundbreaking work in this application area. Today, Unix developers and Unix tools are at the cutting edge of far-reaching changes in documentation practice triggered by the advent of the World Wide Web.
At the user-presentation level, Unix-community practice has been moving rapidly toward ’everything is HTML, all references are URLs’ since the mid-1990s. Increasingly, modern Unix help browsers are simply Web browsers that know how to parse certain specialized kinds of URLs (for example, ’man:ls(1)’ interprets the ls(1) man page into HTML). This relieves the problems created by having lots of different formats for documentation masters, but does not entirely solve them. Documentation composers still have to grapple with issues about which master format best meets their particular needs.
In this chapter, we’ll survey the rather unfortunate surfeit of different documentation formats and tools left behind by decades of experimentation, and we’ll develop guidelines for good practice and good style.
18.1 Documentation Concepts
Our first distinction is between “What You See Is What You Get” (WYSIWYG) documentation programs and markup-centered tools. Most desktop-publishing programs and word processors are in the former category; they have GUIs in which what one types is inserted directly into an on-screen presentation of the document intended to resemble the final printed version as closely as possible. In a markup-centered system, by contrast, the master document is normally flat text containing explicit, visible control tags and not at all resembling the intended output. The marked-up source can be modified with an ordinary text editor, but has to be fed to a formatter program to produce rendered output for printing or display.
The visual-interface, WYSIWYG style was too expensive for early computer hardware, and remained rare until the advent of the Macintosh personal computer in 1984. It is completely dominant on non-Unix operating systems today, Native Unix document tools, on the other hand, are almost all markup-centered. The Unix troff(1) of 1971 was a markup formatter, and is probably the oldest such program still in use.
Markup-centered tools still have a role because actual implementations of WYSIWYG tend to be broken in various ways—some superficial, some deep. WYSIWYG document processors have the general problem with GUIs that we discussed in Chapter 11; the fact that you can visually manipulate anything tends to mean you must visually manipulate everything. That would remain a problem even if the WYSIWIG correspondence between screen and printer output were perfect—but it almost never is.
In truth, WYSIWYG document processors aren’t exactly WYSIWIG. Most have interfaces that obscure the differences between screen presentation and printer output without actually eliminating them. Thus they violate the Rule of Least Surprise: the visual aspect of the interface encourages you to use the program like a typewriter even though it is not, and your input will occasionally produce an unexpected and undesired result.
In further truth, WYSIWIG systems actually rely on markup codes but expend great effort on keeping them invisible in normal use. Thus they break the Rule of Transparency: you can’t see all of the markup, so it is difficult to fix documents that break because of misplaced markup codes.
Despite its problems, WYSIWYG document processors can be very nice if what you want is to slide a picture three ems to the right on the cover of a four-page brochure. But they tend to be constricting any time you need to make a global change to the layout of a 300-page manuscript. WYSIWYG users faced with that kind of challenge must give it up or suffer the death of a thousand mouse clicks; in situations like that, there is really no substitute for being able to edit explicit markup, and Unix’s markup-centered document tools offer better solutions.
Today, in a world influenced by the example of the Web and XML, it has become common to make a distinction between presentation and structural markup in documents—the former being instructions about how a document should look, the latter being instructions about how it’s organized and what it means. This distinction wasn’t clearly understood or followed through in early Unix tools, but it’s important for understanding the design pressures that led to today’s descendants of them.
Presentation-level markup carries all the formatting information (e.g., about desired whitespace layout and font changes) in the document itself. In a structural-markup system, the document has to be combined with a stylesheet that tells the formatter how to translate the structure markup in the document to a physical layout. Both kinds of markup ultimately control the physical appearance of a printed or browsed document, but structural markup does it through one more level of indirection that turns out to be necessary if you want to produce good results for both printing and the Web.
Most markup-centered documentation systems support a macro facility. Macros are user-defined commands that are expanded by text substitution into sequences of built-in markup requests. Usually, these macros add structural features (like the ability to declare section headings) to the markup language.
The troff macro sets (mm, me, and my ms package) were actually designed to push people away from format-oriented editing and toward content-oriented editing. The idea was to label the semantic parts and then have different style packages that would know whether in this style the title should be boldfaced or not, centered or not, and so on. Thus there was at one point a set of macros that tried to imitate ACM style, and another that imitated Physical Review style, but used the basic -ms markup. All of the macros lost out to people who were focused on producing one document, and controlling its appearance, just as Web pages get bogged down in the dispute over whether the reader or author should control the appearance. I frequently found secretaries who were using the .AU (author name) command just to produce italics, noticing that it did that, and then getting into trouble with its other effects.
—Mike Lesk
Finally, we note that there are significant differences between the sorts of things composers want to do with small documents (business and personal letters, brochures, newsletters) and the things they want to do with large ones (books, long articles, technical papers, and manuals). Large documents tend to have more structure, to be pieced together from parts that may have to be changed separately, and to need automatically-generated features like tables of contents; these are both traits that favor markup-centered tools.
18.2 The Unix Style
The Unix style of documentation (and documentation tools) has several technical and cultural traits that set it apart from the way documentation is done elsewhere. Understanding these signature traits first will create context for you to understand why the programs and the practice look the way they do, and why the documentation reads the way it does.
18.2.1 The Large-Document Bias
Unix documentation tools have always been designed primarily for the challenges involved in composing large and complex documents. Originally it was patent applications and paperwork; later it was scientific and technical papers, technical documentation of all sorts. Consequently, most Unix developers learned to love markup-centered documentation tools. Unlike the PC users of the time, the Unix culture was unimpressed with WYSIWYG word processors when they became generally available in the late 1980s and early 1990s—and even among today’s younger Unix hackers it is still unusual to find anyone who really prefers them.
Dislike of opaque binary document formats—and especially of opaque proprietary binary formats—also played a part in the rejection of WYSIWYG tools. On the other hand, Unix programmers seized on PostScript (the now-standard language for controlling imaging printers) with enthusiasm as soon as the language documentation became available; it fits neatly in the Unix tradition of domain-specific languages. Modern open-source Unix systems have excellent PostScript and Portable Document Format (PDF) tools.
Another consequence of this history is that Unix documentation tools have tended to have relatively weak support for including images, but strong support for diagrams, tables, graphing, and mathematical typesetting—the sorts of things often needed in technical papers.
The Unix attachment to markup-centered systems has often been caricatured as a prejudice or a troglodyte trait, but it is not really anything of the kind. Just as the putatively ’primitive’ CLI style of Unix is in many ways better adapted to the needs of power users than GUIs, the markup-centered design of tools like troff(1) is a better fit for the needs of power documenters than are WYSIWYG programs.
The large-document bias in Unix tradition did not just keep Unix developers attached to markup-based formatters like troff, it also made them interested in structural markup. The history of Unix document tools is one of lurching, muddled, and erratic movement in a general direction away from presentation markup and toward structural markup. In mid-2003 this journey is not yet over, but the end is distantly in sight.
The development of the World Wide Web meant that the ability to render documents in multiple media (or, at least, for both print and HTML display) became the central challenge for documentation tools after about 1993. At the same time, even ordinary users were, under the influence of HTML, becoming more comfortable with markup-centered systems. This led directly to an explosion of interest in structural markup and the invention of XML after 1996. Suddenly the old-time Unix attachment to markup-centered systems started looking prescient rather than reactionary.
Today, in mid-2003, most of the leading-edge development of XML-based documentation tools using structural markup is taking place under Unix. But, at the same time, the Unix culture has yet to let go of its older tradition of presentation-level markup systems. The creaking, clanking, armor-plated dinosaur that is troff has only partly been displaced by HTML and XML.
18.2.2 Cultural Style
Most software documentation is written by technical writers for the least-common-denominator ignorant—the knowledgeable writing for the knowledgeless. The documentation that ships with Unix systems has traditionally been written by programmers for their peers. Even when it is not peer-to-peer documentation, it tends to be influenced in style and format by the enormous mass of programmer-to-programmer documentation that ships with Unix systems.
The difference this makes can be summed up in one observation: Unix manual pages traditionally have a section called BUGS. In other cultures, technical writers try to make the product look good by omitting and skating over known bugs. In the Unix culture, peers describe the known shortcomings of their software to each other in unsparing detail, and users consider a short but informative BUGS section to be an encouraging sign of quality work. Commercial Unix distributions that have broken this convention, either by suppressing the BUGS section or euphemizing it to a softer tag like LIMITATIONS or ISSUES or APPLICATION USAGE, have invariably fallen into decline.
Where most other software documentation tends to to oscillate between incomprehensibility and oversimplifying condescension, classic Unix documentation is written to be telegraphic but complete. It does not hold you by the hand, but it usually points in the right direction. The style assumes an active reader, one who is able to deduce obvious unsaid consequences of what is said, and who has the self-confidence to trust those deductions.
Unix programmers tend to be good at writing references, and most Unix documentation has the flavor of a reference or aide memoire for someone who thinks like the document-writer but is not yet an expert at his or her software. The results often look much more cryptic and sparse than they actually are. Read every word carefully, because whatever you want to know will probably be there, or deducible from what’s there. Read every word carefully, because you will seldom be told anything twice.
18.3 The Zoo of Unix Documentation Formats
All the major Unix documentation formats except the very newest one are presentation-level markups assisted by macro packages. We examine them here from oldest to newest.
18.3.1 troff and the Documenter’s Workbench Tools
We discussed the Documenter’s Workbench architecture and tools in Chapter 8 as an example of how to integrate a system of multiple minilanguages. Now we return to these tools in their functional role as a typesetting system.
The troff formatter interprets a presentation-level markup language. Recent implementations like the GNU project’s groff(1) emit PostScript by default, though it is possible to get other forms of output by selecting a suitable driver. See Example 18.1 for several of the troff codes you might encounter in document sources.
Example 18.1. groff(1) markup example.

troff(1) has many other requests, but you are unlikely to see most of them directly. Very few documents are written in bare troff. It supports a macro facility, and half a dozen macro packages are in more or less general use. Of these, the overwhelmingly most common is the man(7) macro package used to write Unix manual pages. See Example 18.2 for a sample.
Example 18.2. man markup example.

Two of the other half-dozen historical troff macro libraries, ms(7) and mm(7) are still in use. BSD Unix has its own elaborate extended macro set, mdoc(7). All these are designed for writing technical manuals and long-form documentation. They are similar in style but more elaborate than man macros, and oriented toward producing typeset output.
A minor variant of troff(1) called nroff(1) produces output for devices that can only support constant-width fonts, like line printers and character-cell terminals. When you view a Unix manual page within a terminal window, it is nroff that has rendered it for you.
The Documenter’s Workbench tools do the technical-documentation jobs they were designed for quite well, which is why they have remained in continuous use for more than thirty years while computers increased a thousandfold in capacity. They produce typeset text of reasonable quality on imaging printers, and can throw a tolerable approximation of a formatted manual page on your screen.
They fall down badly in a couple of areas, however. Their stock selection of available fonts is limited. They don’t handle images well. It’s hard to get precise control of the positioning of text or images or diagrams within a page. Support for multilingual documents is nonexistent. There are numerous other problems, some chronic but minor and some absolute showstoppers for specific uses. But the most serious problem is that because so much of the markup is presentation level, it’s difficult to make good Web pages out of unmodified troff sources.
Nevertheless, at time of writing man pages remain the single most important form of Unix documentation.
18.3.2 TEX
TEX (pronounced /teH/ with a rough h as though you are gargling) is a very capable typesetting program that, like the Emacs editor, originated outside the Unix culture but is now naturalized in it. It was created by noted computer scientist Donald Knuth when he became impatient with the quality of typography, and especially mathematical typesetting, that was available to him in the late 1970s.
TEX, like troff(1), is a markup-centered system. TEX’s request language is rather more powerful than troff’s; among other things, it is better at handling images, page-positioning content precisely, and internationalization. TEX is particularly good at mathematical typesetting, and unsurpassed at basic typesetting tasks like kerning, line filling, and hyphenating. TEX has become the standard submission format for most mathematical journals. It is actually now maintained as open source by a working group of the the American Mathematical Society. It is also commonly used for scientific papers.
As with troff(1), human beings usually do not write large volumes of raw TEX macros by hand; they use macro packages and various auxiliary programs instead. One particular macro package, LATEX, is almost universal, and most people who say they’re composing in TEX almost always actually mean they’re writing LATEX. Like troff’s macro packages, a lot of its requests are semistructural.
One important use of TEX that is normally hidden from the user is that other document-processing tools often generate LATEX to be turned into PostScript, rather than attempting the much more difficult job of generating PostScript themselves. The xmlto(1) front end that we discussed as a shell-programming case study in Chapter 14 uses this tactic; so does the XML-DocBook toolchain we’ll examine later in this chapter.
TEX has a wider application range than troff(1) and is in most ways a better design. It has the same fundamental problems as troff in an increasingly Web-centric world; its markup has strong ties to the presentation level, and automatically generating good Web pages from TEX sources is difficult and fault-prone.
TEX is never used for Unix system documentation and only rarely used for application documentation; for those purposes, troff is sufficient. But some software packages that originated in academia outside the Unix community have imported the use of TEX as a documentation master format; the Python language is one example. As we noted above, it is also heavily used for mathematical and scientific papers, and will probably dominate that niche for some years yet.
18.3.3 Texinfo
Texinfo is a documentation markup invented by the Free Software Foundation and used mainly for GNU project documentation—including the documentation for such essential tools as Emacs and the GNU Compiler Collection.
Texinfo was the first markup system specifically designed to support both typeset output on paper and hypertext output for browsing. The hypertext format was not, however, HTML; it was a more primitive variety called ’info’, originally designed to be browsed from within Emacs. On the print side, Texinfo turns into TEX macros and can go from there to PostScript.
The Texinfo tools can now generate HTML. But they don’t do a very good or complete job, and because a lot of Texinfo’s markup is at presentation level it is doubtful that they ever will. As of mid-2003, the Free Software Foundation is working on heuristic Texinfo to DocBook translation. Texinfo will probably remain a live format for some time.
18.3.4 POD
Plain Old Documentation is the markup system used by the maintainers of Perl. It generates manual pages, and has all the familiar problems of presentation-level markups, including trouble generating good HTML.
18.3.5 HTML
Since the World Wide Web entered the mainstream in the early 1990s, a small but increasing percentage of Unix projects have been writing their documentation directly in HTML. The problem with this approach is that it is difficult to generate high-quality typeset output from HTML. There are particular problems with indexing as well; the information needed to generate indexes is not present in HTML.
18.3.6 DocBook
DocBook is an SGML and XML document type definition designed for large, complex technical documents. It is alone among the markup formats used in the Unix community in being purely structural. The xmlto(1) tool discussed in Chapter 14 supports rendering to HTML, XHTML, PostScript, PDF, Windows Help markup, and several less important formats.
Several major open-source projects (including the Linux Documentation Project, FreeBSD, Apache, Samba, GNOME, and KDE) already use DocBook as a master format. This book was written in XML-DocBook.
DocBook is a large topic. We’ll return to it after summing up the problems with the current state of Unix documentation.
18.4 The Present Chaos and a Possible Way Out
Unix documentation is, at present, a mess.
Between man, ms, mm, TEX, Texinfo, POD, HTML, and DocBook, the documentation master files on modern Unix systems are scattered across eight different markup formats. There is no uniform way to view all the rendered versions. They aren’t Web-accessible, and they aren’t cross-indexed.
Many people in the Unix community are aware that this is a problem. At time of writing most of the effort toward solving it has come from open-source developers, who are more actively interested in competing for acceptance by nontechnical end users than developers for proprietary Unixes have been. Since 2000, practice has been moving toward use of XML-DocBook as a documentation interchange format.
The goal, which is within sight but will take a lot of effort to achieve, is to equip every Unix system with software that will act as a systemwide document registry. When system administrators install packages, one step will be to enter the package’s XML-DocBook documentation into the registry. It will then be rendered into a common HTML document tree and cross-linked to the documentation already present.
Early versions of the document-registry software are already working. The problem of forward-converting documentation from the other formats into XML-DocBook is a large and messy one, but the conversion tools are falling into place. Other political and technical problems remain to be attacked, but are probably solvable. While there is not as of mid-2003 a communitywide consensus that the older formats have to be phased out, that seems the likeliest working out of events.
Accordingly, we’ll next take a very detailed look at DocBook and its toolchain. This description should be read as an introduction to XML under Unix, a pragmatic guide to practice and as a major case study. It’s a good example of how, in the context of the Unix community, cooperation between different project groups develops around shared standards.
18.5 DocBook
A great many major open-source projects are converging on DocBook as a standard format for their documentation. The advocates of XML-based markup seem to have won the theoretical argument against presentation-level and for structural-level markup, and an effective XML-DocBook toolchain is available in open source.
Nevertheless, a lot of confusion still surrounds DocBook and the programs that support it. Its devotees speak an argot that is dense and forbidding even by computer-science standards, slinging around acronyms that have no obvious relationship to the things you need to do to write markup and make HTML or PostScript from it. XML standards and technical papers are notoriously obscure. In the rest of this section, we’ll try to dispel the fog of jargon.
18.5.1 Document Type Definitions
(Note: to keep the explanation simple, most of this section tells some lies, mainly by omitting a lot of history. Truthfulness will be fully restored in a following section.)
DocBook is a structural-level markup language. Specifically, it is a dialect of XML. A DocBook document is a piece of XML that uses XML tags for structural markup.
For a document formatter to apply a stylesheet to your document and make it look good, it needs to know things about the overall structure of your document. For example, in order to physically format chapter headers properly, it needs to know that a book manuscript normally consists of front matter, a sequence of chapters, and back matter. In order for it to know this sort of thing, you need to give it a Document Type Definition or DTD. The DTD tells your formatter what sorts of elements can be in the document structure, and in what order they can appear.
What we mean by calling DocBook a ’dialect’ of XML is actually that DocBook is a DTD—a rather large DTD, with somewhere around 400 tags in it.1
1 In XML-speak, what we have been calling a ’dialect’ is called an ’application’; we’ve avoided that usage, since it collides with another more common sense of the word.
Lurking behind DocBook is a kind of program called a validating parser. When you format a DocBook document, the first step is to pass it through a validating parser (the front end of the DocBook formatter). This program checks your document against the DocBook DTD to make sure you aren’t breaking any of the DTD’s structural rules (otherwise the back end of the formatter, the part that applies your stylesheet, might become quite confused).
The validating parser will either throw an error, giving you messages about places where the document structure is broken, or translate the document into a stream of XML elements and text that the parser back end combines with the information in your stylesheet to produce formatted output.
Figure 18.1 diagrams the whole process.
Figure 18.1. Processing structural documents.

The part of the diagram inside the dotted box is your formatting software, or toolchain. Besides the obvious and visible input to the formatter (the document source) you’ll need to keep the two hidden inputs of the formatter (DTD and stylesheet) in mind to understand what follows.
18.5.2 Other DTDs
A brief digression into other DTDs may help clarify what parts of the previous section are specific to DocBook and what parts are general to all structural-markup languages.
TEI <http://www.tei-c.org/> (Text Encoding Initiative) is a large, elaborate DTD used primarily in academia for computer transcription of literary texts. TEI’s Unix-based toolchains use many of the same tools that are involved with DocBook, but with different stylesheets and (of course) a different DTD.
XHTML, the latest version of HTML, is also an XML application described by a DTD, which explains the family resemblance between XHTML and DocBook tags. The XHTML toolchain consists of Web browsers that can format HTML as flat ASCII, together with any of a number of ad-hoc HTML-to-print utilities.
Many other XML DTDs are maintained to help people exchange structured information in fields as diverse as bioinformatics and banking. You can look at a list of repositories <http://www.xml.com/pub/rg/DTD_Repositories> to get some idea of the variety available.
18.5.3 The DocBook Toolchain
Normally, what you’ll do to make XHTML from your DocBook sources is use the xmlto(1) front end. Your commands will look like this:
![]()
In this example, you converted an XML-DocBook document named foo.xml with three top-level sections into an index page and two parts. Making one big page is just as easy:
![]()
Finally, here is how you make PostScript for printing:
![]()
To turn your documents into HTML or PostScript, you need an engine that can apply the combination of DocBook DTD and a suitable stylesheet to your document. Figure 18.2 illustrates how the open-source tools for doing this fit together.
Figure 18.2. Present-day XML-DocBook toolchain.
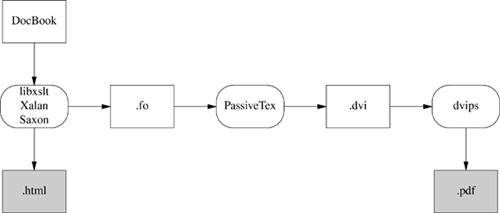
Parsing your document and applying the stylesheet transformation will be handled by one of three programs. The most likely one is xsltproc, the parser that ships with Red Hat Linux. The other possibilities are two Java programs, Saxon and Xalan.
It is relatively easy to generate high-quality XHTML from either DocBook; the fact that XHTML is simply another XML DTD helps a lot. Translation to HTML is done by applying a rather simple stylesheet, and that’s the end of the story. RTF is also simple to generate in this way, and from XHTML or RTF it’s easy to generate a flat ASCII text approximation in a pinch.
The awkward case is print. Generating high-quality printed output—which means, in practice, Adobe’s PDF (Portable Document Format)—is difficult. Doing it right requires algorithmically duplicating the delicate judgments of a human typesetter moving from content to presentation level.
So, first, a stylesheet translates DocBook’s structural markup into another dialect of XML—FO (Formatting Objects). FO markup is very much presentation-level; you can think of it as a sort of XML functional equivalent of troff. It has to be translated to PostScript for packaging in a PDF.
In the toolchain shipped with Red Hat Linux, this job is handled by a TEX macro package called PassiveTeX. It translates the formatting objects generated by xsltproc into Donald Knuth’s TEX language. TEX’s output, known as DVI (DeVice Independent) format, is then massaged into PDF.
If you think this bucket chain of XML to TEX macros to DVI to PDF sounds like an awkward kludge, you’re right. It clanks, it wheezes, and it has ugly warts. Fonts are a significant problem, since XML and TEX and PDF have very different models of how fonts work; also, handling internationalization and localization is a nightmare. About the only thing this code path has going for it is that it works.
The elegant way will be FOP, a direct FO-to-PostScript translator being developed by the Apache project. With FOP, the internationalization problem is, if not solved, at least well confined; XML tools handle Unicode all the way through to FOP. The mapping from Unicode glyphs to Postscript font is also strictly FOP’s problem. The only trouble with this approach is that it doesn’t work—yet. As of mid-2003, FOP is in an unfinished alpha state—usable, but with rough edges and missing features.
Figure 18.3 illustrates what the FOP toolchain looks like.
Figure 18.3. Future XML-DocBook toolchain with FOP.

FOP has competition. Another project called xsl-fo-proc aims to do the same things as FOP, but in C++ (and therefore both faster than Java and not relying on the Java environment). As of mid-2003, xsl-fo-proc is in an unfinished alpha state, not as far along as FOP.
18.5.4 Migration Tools
The second biggest problem with DocBook is the effort needed to convert old-style presentation markup to DocBook markup. Human beings can usually parse the presentation of a document into logical structure automatically, because (for example) they can tell from context when an italic font means ’emphasis’ and when it means something else such as ’this is a foreign phrase’.
Somehow, in converting documents to DocBook, those sorts of distinctions need to be made explicit. Sometimes they’re present in the old markup; often they are not, and the missing structural information has to be either deduced by clever heuristics or added by a human.
Here is a summary of the state of conversion tools from various other formats. None of these do a completely perfect job; inspection and perhaps a bit of hand-editing by a human being will be needed after conversion.
GNU Texinfo
The Free Software Foundation intends to support DocBook as an interchange format. Texinfo has enough structure to make reasonably good automatic conversion possible (human editing is still needed afterwards, but not much of it), and the 4.x versions of makeinfo feature a --docbook switch that generates DocBook. More at the makeinfo project page <http://www.gnu.org/directory/texinfo.html>.
POD
A POD::DocBook <http://www.cpan.org/modules/by-module/Pod/> module translates Plain Old Documentation markup to DocBook. It claims to translate every POD tag except the L<> italic tag. The man page also says “Nested =over/=back lists are not supported within DocBook”, but notes that the module has been heavily tested.
LATEX
A project called TeX4ht <http://www.lrz-muenchen.de/services/software/sonstiges/tex4ht/mn.html> can, according to the author of PassiveTEX, generate DocBook from LATEX.
man pages and other troff-based markups
These are generally considered the biggest and nastiest conversion problems. And indeed, the basic troff(1) markup is at too low a presentation level for automatic conversion tools to do much of any good. However, the gloom in the picture lightens significantly if we consider translation from sources of documents written in macro packages like man(7). These have enough structural features for automatic translation to get some traction.
I wrote a tool to do troff-to-DocBook myself, because I couldn’t find anything else that did a tolerable job of it. It’s called doclifter <http://www.catb.org/~esr/doclifter/>. It will translate to either SGML or XML DocBook from man(7), mdoc(7), ms(7), or me(7) macros. See the documentation for details.
18.5.5 Editing Tools
One thing we do not have in mid-2003 is a good open-source structure editor for SGML/XML documents.
LyX <http://www.lyx.org/> is a GUI word processor that uses LATEX for printing and supports structural editing of LATEX markup. There is a LATEX package that generates DocBook, and a how-to document <http://bgu.chez.tiscali.fr/doc/db4lyx/> describing how to write SGML and XML in the LyX GUI.
GNU TeXMacs <http://www.math.u-psud.fr/~anh/TeXmacs/TeXmacs.html> is a project aimed at producing an editor that is good for technical and mathematical material, including displayed formulas. 1.0 was released in April 2002. The developers plan XML support in the future, but it’s not there yet.
Most people still hack DocBook tags by hand using either vi or emacs.
18.5.6 Related Standards and Practices
The tools are coming together, if slowly, to edit and format DocBook markup. But DocBook itself is a means, not an end. We’ll need other standards besides DocBook itself to accomplish the searchable-documentation-database objective. There are two big issues: document cataloging and metadata.
The ScrollKeeper <http://scrollkeeper.sourceforge.net/> project aims directly to meet this need. It provides a simple set of script hooks that can be used by package install and uninstall productions to register and unregister their documentation.
ScrollKeeper uses the Open Metadata Format <http://www.ibiblio.org/osrt/omf/>. This is a standard for indexing open-source documentation analogous to a library card-catalog system. The idea is to support rich search facilities that use the card-catalog metadata as well as the source text of the documentation itself.
18.5.7 SGML
In previous sections, we have deliberately omitted a lot of DocBook’s history. XML has an older brother, Standard Generalized Markup Language (SGML).
Until mid-2002, no discussion of DocBook would have been complete without a long excursion into SGML, the differences between SGML and XML, and detailed descriptions of the SGML DocBook toolchain. Life can be simpler now; an XML DocBook toolchain is available in open source, works as well as the SGML toolchain ever did, and is easier to use.
18.5.8 XML-DocBook References
One of the things that makes learning DocBook difficult is that the sites related to it tend to overwhelm the newbie with long lists of W3C standards, massive exercises in SGML theology, and dense thickets of abstract terminology. See XML in a Nutshell [Harold-Means] for a good book-length general introduction.
Norman Walsh’s DocBook: The Definitive Guide is available in print <http://www.oreilly.com/catalog/docbook/> and on the Web <http://www.docbook.org/tdg/en/html/docbook.html>. This is indeed the definitive reference, but as an introduction or tutorial it’s a disaster. Instead, read this:
Writing Documents Using DocBook <http://xml.web.cern.ch/XML/goossens/dbatcern/>. This is an excellent tutorial.
There is an equally excellent DocBook FAQ <http://www.dpawson.co.uk/docbook/> with a lot of material on styling HTML output. There is also a DocBook wiki <http://docbook.org/wiki/moin.cgi>.
Finally, the The XML Cover Pages <http://xml.coverpages.org/> will take you into the jungle of XML standards if you really want to go there.
18.6 Best Practices for Writing Unix Documentation
The advice we gave earlier in the chapter about reading Unix documentation can be turned around. When you write documentation for people within the Unix culture, don’t dumb it down. If you write as if for idiots, you will be written off as an idiot yourself. Dumbing documentation down is very different from making it accessible; the former is lazy and omits important things, whereas the latter requires careful thought and ruthless editing.
Don’t think for a moment that volume will be mistaken for quality. And especially, never ever omit functional details because you fear they might be confusing, nor warnings about problems because you don’t want to look bad. It is unanticipated problems that will cost you credibility and users, not the problems you were honest about.
Try to hit a happy medium in information density. Too low is as bad as too high. Use screen shots sparingly; they tend to convey little information beyond the style and feel of the interface. They are never a good substitute for clear textual description.
If your project is of any significant size, you should probably be shipping three different kinds of documentation: man pages as reference material, a tutorial manual, and a FAQ (Frequently Asked Questions) list. You should have a website as well, to serve as a central point of distribution (see the guidelines on communication in Chapter 19).
Huge man pages are viewed with some disfavor; navigation within them can be difficult. If yours are getting large, consider writing a reference manual, with the man page(s) giving a quick summary, pointers into the reference manual, and details of how the program(s) are invoked.
In your source code, include the standard metainformation files described in the Chapter 19 section on open-source release practices, such as README. Even if your code is going to be proprietary, these are Unix conventions and future maintainers coming from a Unix background will come up to speed faster if the conventions are followed.
Your man pages should be command references in the traditional Unix style for the traditional Unix audience. The tutorial manual should be long-form documentation for nontechnical users. And the FAQ should be an evolving resource that grows as your software support group learns what the frequent questions are and how to answer them.
There are more specific habits you should adopt if you want to get a little ahead of mid-2003’s practice:
- Maintain your document masters in XML-DocBook. Even your man pages can be DocBook
RefEntrydocuments. There is a very good HOWTO <http://www.linuxdoc.org/HOWTO/mini/Man-Page.html> on writing manual pages that explains the sections and organization your users will expect to see. - Ship the XML masters. Also, in case your users’ systems don’t have xmlto(1) ship the troff sources that you get by running
xmlto manon your masters. Your software distribution’s installation procedure should install those in the normal way, but direct people to the XML files if they want to write or edit documentation. - Make your project’s installation package ScrollKeeper-ready.
- Generate XHTML from your masters (with
xmlto xhtml) and make it available from your project’s Web page.
Whether or not you’re using XML-DocBook as a master format, you’ll want to find a way to convert your documentation to HTML. Whether your software is open-source or proprietary, users are increasingly likely to find it via the Web. Putting your documentation on-line has the direct effect of making it easier for potential users and customers who know your software exists to read it and learn about it. It has the indirect effect that your software will become more likely to turn up in a Web search.