
AI can and has been used in test automation for various tasks and activities. These range from self-healing and self-adaption of automated tests to test generation and test data generation as well as other aspects in between. Test generation and test data generation can happen on all levels, from code level white-box testing (e.g. unit tests) to interface level, to user interface (UI) level. Interestingly enough, test code is the easiest code one can generate. At the same time, sufficiently high code coverage is the enabler through which automated bug fixes and automated code generation is possible. In this chapter I will take you on a journey through all the testing tasks that AI can and is being used for, and will then focus on test generation and test data generation, concluding with an outlook on how code generation will depend on this and can even be the next logical step from here.
The topic ‘AI quality’ is ambiguous. It can point to the quality of an AI system, but it can also indicate ‘AI’ as some sort of quality badge – of a system or product that is either produced or has its quality assured by an AI system. In this chapter, we want to explore the latter: a system, that is, software, that has its quality assured by an AI system.
QUALITY ASSURANCE
Quality assurance is ultimately the domain of humans. In many situations it is difficult to define the desired outcome in an airtight way, considering all possibilities in which that definition can be misinterpreted. That is especially true for software, where many of the ‘natural’ constraints of the physical world do not apply.
In the digital realm, virtually anything is possible. It is therefore vital to have humans perform the final quality assurance check as to whether the end result meets the defined criteria in an acceptable way, or whether some implicit and unexpressed requirement has been violated. As discussed before, this is called the oracle problem.
The oracle problem
The oracle problem is the problem of telling right from wrong: whether the outcome of a calculation or process is flawed in any way. The oracle problem applies to individual features of software as much as it applies to the overall software itself: is the outcome of the software development process (i.e. the software) flawed in any way?
In the end it all boils down to context, intent and communication. Whether 12 + 1 = 1 is correct or not hinges on whether we are in the context of a regular mathematical calculation, or in the context of a date manipulation, calculating a month of a year. For every such decision, there is usually a bigger context to consider, and an intent that has been communicated for that context. Just telling someone you want a photo sharing app could result in the creation of either Snapchat or Instagram, both of which serve that purpose in very different ways.
In real-world software development, it is often the case that the product owner defines the general idea in varying degrees, and the testers and developers fill the remaining gaps by applying common sense. To apply AI to either of these tasks of testing and developing is currently not possible, as the level of common sense needed to fill gaps, infer context and interpret intent would require roughly a human-level of intelligence. Given the comparable efforts and incurred costs of the two tasks, it stands to assume that, if ever AI became powerful enough to achieve either, it would be used to generate the code (which, in itself, is a formal specification of the intended behaviour). As indicated above, it is much easier for a human to check whether some implicit and unexpressed requirement has been violated, than to come up with an original coded solution.
To really understand how hard it is to solve the oracle problem in a general way, one should consider why it is called the ‘oracle’ problem in the first place: all problems and their respective solutions can be expressed as software, even such outlandish tasks as determining the future or determining whether God exists. Mind you, I am not talking about correct implementations of the solutions to these problems as software, merely about any solution at all. The minimalist implementation of the simplest solution would, for every posed question, always answer with ‘yes’. To determine the correctness of that answer to many questions and thus of the software, you would, for example, need to know the future or whether God exists. This is exactly why you would need an oracle from ancient Greek mythology – hence the name.
TESTING VERSUS TEST AUTOMATION
Software is usually developed in an iterative and incremental way: starting from a first working version, the software is enhanced and improved as version numbers increase. For non-software developers it is often difficult to comprehend how sometimes dependencies connect otherwise unrelated parts of the software in unknown, almost mystical, ways. This means even small changes can have unexpected side effects in unforeseen places. To address this issue, the software has to be continually tested – even parts and features that have already been tested in the past. This essentially requires a lot of repetitive and redundant work, begging for automation. Automation brings the added benefit of speeding up the testing process, allowing testing to be performed ideally after every change.

Note that in the context of this chapter, I am talking about test automation for regression testing or maintenance testing, ignoring other test automation purposes.
However, as the realisation of testing changes with automation, so does its goal. The goal of testing is to find flaws and defects. While this is still technically true for test automation, as per the oracle problem, it cannot be achieved in a general way. Also, it is mostly not necessary: as manual testing has presumably determined the correctness of the software, the goal of test automation changes to ensuring that the software is still correct. This means that test automation aims to find unintended and unwanted ways in which the behaviour of the software changes.
This is called the consistency oracle: the software should be consistent to former versions of the same software. This oracle can be explicitly defined, as is currently the case in most situations. What is interesting about this, is that the oracle can also be derived: having a previous version of the software for comparison, one can simply execute both versions in parallel and compare the execution results and characteristics. Alternatively, one can store said results and characteristics of the previous version as a baseline and compare against that.
For the consistency oracle to be applicable, it is necessary for the software to be (mostly) deterministic. Also it is very useful to only make small changes to the software and continually compare the changes in behaviour to the baseline and update the baseline with intended changes. Otherwise, one runs the risk of being overwhelmed with too many changes, generating a lot of effort and defying the purpose of the approach.
Since test automation is a huge cost factor and major cause of additional effort and risks, it is a very worthwhile goal for AI to address this problem. In the following section we will focus on this specific task, before addressing other things AI can do in the realm of testing and quality assurance.
AI IN UNIT TEST AUTOMATION
AI can be used to generate automated tests; however, the level on which this is done dramatically changes the challenges being faced when doing so. In this chapter we will focus specifically on what is often called the code, module, component or unit level.
For many people, this is the desired place to put most of the test automation. This desire is often characterised as the ‘test pyramid’ (Cohn, 2009) (Figure 5.1).
Figure 5.1 Schematic illustration of the test pyramid (Source: Based on Cohn, 2009)
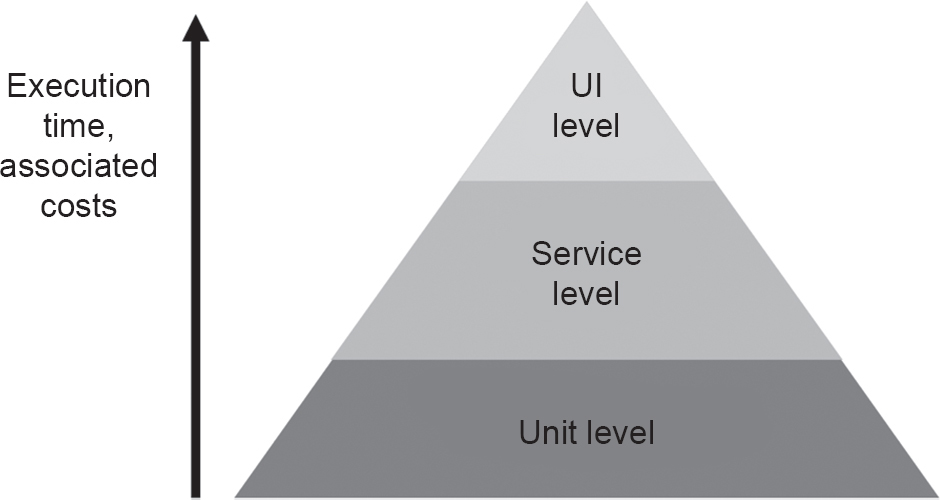
The principal idea is that test automation on the UI level results in brittle tests, where a single small UI change can often result in the inability to correctly execute many of these tests. This often also results in high maintenance costs to fix the tests or high development costs to avoid the problem – or both. Executing these tests usually requires starting the complete system, often multiple times, making it time-consuming to do. On top of that, these tests require a complex software stack with many external dependencies, making them often non-deterministic to run (referred to as ‘flakiness’). This non-determinism then results in a lot of false positives, which together with their vulnerability to changes undermines trust and can eventually render UI tests more of a burden than an aid in many projects.
For all these reasons, it is preferable to have the majority of tests at the unit test level. However, these tests do not represent the way the software is consumed and experienced by the end-user, so they are only part of an overall mix of different kinds of tests. It is important to keep that in mind, or else the focus might shift to a purely functional one, disregarding softer aspects like visuals and user experience.
Since these tests reside in the code and are defined in code, they need to be created by developers. An AI system being able to generate these tests would be a huge step towards decreasing their cost. For this reason, a lot of effort has been put into research on how AI could generate these tests. Unfortunately, many challenges still need to be solved to have a market-ready solution. In the following section, we will analyse the different challenges individually.
Test oracles for unit tests
As has already been established, generating test automation can make use of the consistency oracle. The consistency oracle assumes that the software should be consistent to former versions of the same software. However, while this is true for the software behaviour from a user’s perspective, it can be vastly different in regard to the low-level implementation details of that behaviour. This means there needs to be a lot of emphasis on the way the consistency oracle is specified, which in the realm of unit test automation usually happens in the form of assertions. To be robust and non-redundant, an ideal unit test ensures a single aspect of the individual unit under test – and nothing else. However, from the code level most of the inner state of the system is available or reachable, making it hard for an AI to focus on the current unit under test or the specific aspects currently being ensured. Often, AI ends up ensuring aspects that are non-meaningful or non-relevant. This becomes especially clear if state changes are the desired outcome of an operation. For this reason, much of the academic literature focuses on stateless and side-effect-free operations, such as transformations and calculations.
To illustrate the issues, imagine we want to generate tests for our software. Among the code is an operation user.setActive(), where the desired outcome is that the status of the user is changed to ‘active’. To detect whether the operation was successful, it is usually not desirable to directly access the inner state of the user – as the AI doesn’t know what is relevant, it might decide to assert a specific randomly generated and non-deterministic ID or timestamp. A human-created test would most likely query the user object using its appropriate methods, such as user.getState(). Since the user-persistence unit will most likely offer many other operations, deciding to use that specific query operation from all the options is challenging. Of course, these simple examples can be solved by executing the operation multiple times to detect changing aspects. However, in general, deciding which specific aspects of the data should be ensured literally and which in a more abstract manner is hard and determines both the flakiness and the robustness to change of the tests.
Another oracle that is often used on the UI level is the implicit robustness oracle: the software should never crash, no matter what the user does. On the code level, exceptions and crashes may be non-problematic as robustness typically is only ensured on interfaces. So, if the unit under test passes invalid data, such as a null reference, throwing an exception and crashing might be the expected behaviour, rendering this oracle invalid for test generation on the code level.
Preconditions and parameters
The preconditions necessary to trigger interesting or relevant functionality for a specific unit can be arbitrarily complex. For example, the code might expect an established database connection to exist, that specific environment variables are defined, and so on. Recent advancements in mocking technology (e.g. Mockito) combined with execution path analysis alleviated this problem somewhat; however, similar to the aforementioned challenge of deciding which changes are relevant to a specific unit or aspect being tested, it remains a challenge to automatically decide which behaviour is relevant. If mocking too much, the automated test eventually tests the mock instead of the relevant functionality. If mocking not enough, irrelevant prerequisites are being set up, lowering robustness and making it hard for developers to debug the test, once it fails – essentially turning the test into an integration test.
To illustrate the issues, let us come back to our test for a save(User) operation of a user-persistence unit. Establishing a connection to a remote database is somewhat costly and the goal is not to test the internals of the database, which can be safely assumed to work correctly. Therefore, it would make perfect sense to mock the database and just test the persistence logic, for example, the object validation and the correct creation and issuing of the SQL statement. While it is usually a good idea to mock an interface, the challenge is to decide which interface to mock. This could be accomplished, for example, on the communication level of the remote connection, or the API level of the underlying communication framework. Both have the drawback that they merely ‘freeze’ the current state of the implementation, without verifying its correctness. A change to the underlying SQL schema could cause the unit under test to malfunction or utterly fail in production – but would not be detected by this test. A manually created test on the other hand would probably opt to use an in-memory database instead. Such a database works similarly to an API in that it requires no remote connections, but instead of verifying that the SQL statement is unchanged, it would verify that the SQL statement works for the current schema, even if the latter is subject to change.
Many operations are also being called with complex parameters. In a generated test, these parameters need to be created in a way that matches the intent of the current aspect being tested. Since the aforementioned necessary preconditions can be turned into parameters and vice versa, whether one differentiates this challenge merely depends on the way the code is organised. Often, when talking about complex parameters, the emphasis is on the data and their validity and structure.
To illustrate this, our save(User) operation of a user-persistence unit may require a valid email address to be set within the given complex User object. It is entirely possible to have the validity of the email address being validated on the database level. Since this code is then outside the scope of the test system and probably not accessible for further analysis during execution, it will be very hard for the test generation system to ‘understand’ the problem and come up with a valid email address on its own. In this simple scenario, the problem can be easily mitigated if successful and correct executions can be observed and learned from (heeding privacy concerns). However, there are many complex real-world scenarios with intricate dependencies that will be hard for the test generation system to ‘understand’ and navigate.
Protocols and internal state
In many real-world scenarios, the unit under test has an internal state that is affected and manipulated by the order in which the related operations (in the following referred to as methods) are being called and with which parameters. It is often desirable to verify that this state change is correctly triggered and executed, following a specific (often implicit) protocol. Think about establishing and terminating connections, opening and closing files, and so on. However, deciding whether the change of an internal state is significant or not is a very hard problem, essentially boiling down to the separation of information from noise. The overall number of options multiply per permutation, meaning that with an internal state of 10 Boolean variables, the unit can have 210 = 1024 internal states. So, for many real-world systems the number of possible states is already quite large, just considering meaningful differentiations. Without the ability to abstract, the state space of a system can be unfathomably large, or even infinite. This is the reason this challenge has famously been coined the ‘state space explosion problem’ (E. M. Clarke et al., 2012). This makes it practically impossible to generate tests for every possible state change. So, the test generation system must decide or prioritise what constitutes relevant states and which state changes are relevant to generate tests for.
Let us again illustrate, using our previous user-persistence unit. In order to persist and load User objects, the unit will connect to a database in some form. When analysing the internal state of the persistence unit, one must decide about the level of abstraction. This could either mean to treat the connection object as binary (i.e. as existing within the unit or not), or to extend the analysis into the connection object itself. Treating the connection as binary would be too coarse and miss some important cases: for example, the connection object as such could exist, but the underlying network connection may not yet have been established or has been closed already. However, extending the analysis into the connection object would require the same decision regarding abstraction recursively at each level. Every data point tracked is a potential differentiator for internal state. Is the exact timestamp relevant? The difference to the current time? If so, in which granularity? This is already hard for humans to understand, or else we wouldn’t need to test in the first place. And eventually the decision about which abstractions make sense boils down to be an instance of the famous halting-problem: the only surefire way for all possible programs to know whether a specific change in state makes a difference or whether it can be abstracted away, is to execute the program.
Test code generation
The result of unit test generation is usually unit tests in the form of code. Most developers think that the structure and readability of code is very important, provoking trends and movements, such as the software craftmanship manifesto (Manifesto for Software Craftsmanship, n.d.) and the clean code initiative (Clean Code Developer, n.d.), and static analysis tools that check for ‘code smells’.1 This attitude is understandable, given that code is read 10 times as often as it is written (Martin, 2008). However, ‘readability’ is more of an art than an easy and straightforward concept, making it difficult to put it into hard rules. This is further complicated by the fact that each language and often each test framework have different concepts of how readable code looks.
Clear focus and intent
This has an overlap with some other challenges. As has been discussed, an ideal unit test ensures a single aspect of the individual unit under test – and nothing else. A human ideally would analyse a specific unit or feature and define both the intended use cases and some probable edge cases, and then create a test for each of these. Test-driven development actually proposes to create these tests before the actual implementation. This is a top-down approach.
Lacking the understanding and context, a test generation system will instead typically apply a bottom-up approach: analyse the code and its behaviour and then generate tests for each specific case, trying to cover as much code as possible. Both approaches have their benefits and drawbacks: while a top-down approach is somewhat more structured and allows for a ‘logical’ differentiation of the test cases, a bottom-up approach can detect specific cases that, according to specification, should not even exist, but somehow got implemented. This is an instance of the oracle problem: deciding whether an existing case of specific and distinct behaviour is intended or constitutes an error.
Obviously, the challenge of focus and intent is very closely related to the question of protocols and internal state: what constitutes relevant states and which state changes are relevant to generate tests for. However, an additional aspect that hasn’t been discussed so far is the problem of the overall prioritisation: when is a specific function, unit or aspect tested ‘enough’ in comparison to the rest of the system?
AI in unit testing: summary
As can be seen, there are challenges when trying to generate tests on the unit level. However, due to the expected gains in efficiency, it is still an area of ongoing research, resulting in both commercial tools and free-to-use open-source tools. One open-source tool that generates unit tests for existing code is EvoSuite (Fraser, n.d.).
AI IN UI LEVEL TEST AUTOMATION
Many of the challenges that arise when generating tests on the unit level are much smaller or do not arise at all when generating tests on the UI level or the system level (Gross et al., 2012).
While both the consistency oracle and the implicit robustness oracle do not apply easily or at all at the unit or code level, they both do apply on the user interface level. The user values consistency from one version to another, so it is vital to change the user interface carefully and deliberately. Any unintended side effect and non-approved change is a defect. Thus, the consistency oracle can be used to verify the consistency of the system boundary over iterations of the software. Differences on that boundary between versions of the software tend to be meaningful and, in any case, have a much lower noise ratio – if the software is deterministic.
The robustness oracle applies as well: from a user perspective, the software must not crash ever, no matter the input. Therefore, any crash that can be triggered is a defect. Also, the software should respond within a certain amount of time.
Interestingly enough, all of the above observations hold true for any system interface, even for technical ones, including APIs.
Preconditions, parameters, repeatability and interdependence
For the UI to be available, usually the complete system must be started. For most self-contained software, this creates all the necessary preconditions by itself (i.e. it loads the configuration, establishes the database connection, and so on), solving the aforementioned challenge that arises for unit tests.
However, the fact that the complete software must be started (or at least reset) each time a test executes well adds to the problem of the long-running execution cycles of these kinds of tests, as was mentioned earlier. Also, the side effects of executing certain tests tend to be long-lasting, whether it’s the creation, alteration or deletion of data, or the change of configuration. This often results in tests being interdependent, as they access the same data or configuration. Worse still, this interdependence is often created involuntarily and thus exists secretly, only exposed by one or several problems arising over time.
Tests being interdependent is highly undesirable for a variety of reasons. As has just been explained, UI tests tend to have long execution cycles. An easy remedy is parallelisation and prioritisation, both of which are unavailable to interdependent tests. Interdependence also routinely results in brittleness of already fragile tests, increasing complexity of cause–effect analysis and associated costs of maintenance (when both software and tests change). The easiest such case, but fortunately also the most common one, is that if one test fails, it will result in a couple of dependent tests failing as well, obfuscating the original cause. The analysis is much more difficult if tests depend on one another in more subtle ways, such as one test changing some data, maybe even involuntarily or implicitly, that another test depends on. This also makes manual debugging much more difficult, resulting in ‘Heisenberg Bugs’ (or ‘Heisenbugs’), that is, problems that vanish once someone tries to debug them.
Another challenge that was discussed, is the generation of input parameters. On the code level, literally anything can be turned into an input parameter: from complex data objects to database connections. On the other hand, when generating tests for the UI, input parameters consist only of primitives, such as point and click operations and strings as being generated mostly for individual input fields. Complex input data (such as valid XML) are very rarely needed (obviously depending on the type of UI under test). This often allows for either a brute-force generation of the necessary data, or for individual recordings to be reused. This is further facilitated, in that existing protocols tend to be enforced or at least hinted at by the UI design.
Monkey testing
Have you ever marvelled at how vast infinity is? It is unfathomable. And one of the many fascinating facts is that a truly random series of numbers (i.e. one that never repeats itself, ever) contains all the other numbers. This means that the Archimedes’ constant π does contain the bible – and every edition and every language thereof.
Following this reasoning, the infinite monkey theorem states that a monkey randomly hitting keys on a typewriter for an infinite amount of time will eventually type any text, including the complete works of William Shakespeare. The term ‘monkey testing’ is derived from both this theorem and the, often nonsensical, way of interacting with the system. It should be noted that, according to the monkey theorem, monkey testing already completely solves the problem of generating every possible test for the system, given enough time. The only remaining problem is that ‘infinity’ is an impractical amount of time, for most projects anyway. So, adding heuristics and AI to the monkey is meant to make it more efficient, that is, the monkey gets to more meaningful tests faster.
Monkey testing is just a means to generate test executions, but these then obviously lack the test oracles. Thus, they are traditionally only used in conjunction with the implicit test oracle that a system should not crash no matter what the user does. With that intent, monkey testing has been used since the 1980s, to test systems for robustness and stability.
Fuzz testing is the use of a (pseudo) random number generator to produce test data. In a sense, user interaction – clicking, swiping, as well as text input – can be considered as a special kind of randomly generated test data. Therefore, monkey testing is a special case of fuzz testing, but restricted in the type of data generated and the type of interface applicable.
This means that for monkey testing, similar AI approaches can be applied as for fuzz testing: genetic algorithms can be used to generate variations and combinations of existing (recorded) test cases. Neural networks can also be used and trained on what a typical user would do (i.e. which fields and buttons would be used and in what order). This is essentially comparing graphical user interface (GUI) usage to playing a game: in any given GUI state, the AI must decide what move to make next (i.e. what user interaction to perform). Most interesting is that the knowledge that becomes encoded in such neural networks is often not tied to any particular software – part of it represents general rules for user experience design, such as Fitts’ law.2
These approaches can even be combined. An evolutionary algorithm starts with a seed population. This seed population can either be generated by humans (e.g. recordings of user stories or user interactions), or it can be randomly generated. The better the seed population, the better and faster the results. So, if the seed population is (partially) randomly generated, a neural network can be used to generate more human-like tests.
In contrast to playing a game, where the goal for the AI (to win) is clear, the goal in testing is not so clear. The goal must be measurable by the AI in a fully automated way, so manually evaluated ‘soft’ criteria are not usable. A naïve goal would be maximal code coverage, but that often results in tests that are unrealistic or non-sensible from a user perspective. A more sensible goal would be input coverage or coverage of controls. Choosing the right goal has a strong effect on how the AI algorithm performs.
Test selection and prioritisation
As has been detailed before, UI tests tend to be long-running tests. This can quickly result in a situation where there are simply too many automated tests to run regularly, as best practice would have it, such as per commit, per pull request or even per night. Even with parallelisation, the required computational power and the associated costs can be excessive compared with the perceived benefits. And on top of that, brittleness and fragility result in many failing tests, each of which needs to be examined and can often turn out to be a false positive. All of these are strong arguments for test selection and prioritisation.
Test prioritisation utilises runtime information, such as code coverage and test similarity of execution paths, and can be further enhanced by historical information, such as test effectiveness, that is, number and criticality of defects discovered in the past (Juergens et al., 2011).
Object identification and identifier selection
Object identification is a challenge that is unique to UI testing and does not occur in other testing scenarios, but, for example, in robotic process automation (RPA). The test system must interact with the software under test, both to simulate the user input and to verify expected results. This requires the same UI elements, such as buttons, text fields and labels, to be reliably re-identified. If this is not possible anymore, the test fails, often representing a false positive.
The most crude and fragile method for doing so, but sometimes also the last resort, is using X/Y coordinates. Obviously, this not only breaks with any changes in resolution and layout, it is also hard to maintain without any comments as to which object was intended in the first place. It can even lead to some hard-to-identify situations, where the text was entered into the wrong field, or the wrong button was clicked. A somewhat better method is using XPath or similar (the internal unique path of the element within the GUI), although this can also be subject to change. Obviously preferrable are semantic identification criteria, such as ID or name, but even these can change.
AI can help to identify the correct object based on a variety of identification criteria (e.g. XPath, label, ID, class, X/Y coordinates), based on the ‘look’ of the object by applying some form of image recognition, or by selecting the most historically stable single identification criterion. All these approaches have been used in the past.
Visual test automation addresses the specific problem that sometimes software is technically correct in the information that is being shown, but becomes practically unusable or ‘ugly’. It aims exclusively to identify visual differences on different platforms (cross-platform and cross-device testing) or visual regressions. This includes unintended changes in a GUI’s position, size, layout, font, colour or other visible attributes; whether some objects are difficult to see or outright inaccessible; or visual artefacts or other issues. Visual test automation does not aim to test functional or business aspects of the software.
AI in UI level test automation: summary
By now it should have become obvious that testing software on the UI level is much easier than testing it on the code level – although many challenges remain to be solved. One of the main advantages is probably that no coding skills are required at this level, making the technology accessible to a much wider audience.
APPLYING AI TO OTHER TASKS IN SOFTWARE QUALITY ASSURANCE
In order to manage and assure the quality of a piece of software, there are many more tasks required than merely testing the software. However, the range of tasks is so wide, and the number of possibilities of how AI can support it so vast, that it is prohibitive to provide a near-complete list. Instead, we will name the most likely candidates of tasks that will be supported by AI in the foreseeable future.
Note that some of the tasks (such as test data generation, test optimisation or test selection) are needed for the already discussed generation of tests, and therefore have also been discussed above.
Bug triaging
For large projects with hundreds of thousands of users or more, a considerable amount of effort goes into the management of bug reports – especially if there are automated bug reporting systems (e.g. for Microsoft Windows, Firefox or similar). Up to a fourth of bug reports can be duplicates. Clustering algorithms can be used to remove duplicates and point out particularly critical bugs that are responsible for a large percentage of bug reports (Bettenburg et al., 2008).
Anomaly detection
Anomaly detection is something that comes quite ‘naturally’ to AI and can be used in a variety of use cases. This includes, for instance, live monitoring of production systems or test systems, looking for incidences or ‘strange behaviour’ that can show human or system faults or even security breaches. Things that can be monitored include network traffic, input/output behaviour, log messages, API call usage, disk space, central processing unit and memory consumption and many more.
Risk prediction and fault estimation
The analysis of change patterns in software repositories and comparison with historical data about bug occurrences has so far only been applied in scientific research. Correlating these data with yet unreleased changes allows us to make predictions about the riskiness of these changes and the likeliness that they will introduce new bugs or cause post-release problems (Zimmermann et al., 2009).
It should be noted that this approach suffers from the pesticide paradox in that the effectiveness decreases over time, just as pesticides fail to kill insects after a certain period of usage.
Effort estimation for manual testing
The analysis of change patterns in software repositories mentioned above also allows us to point out the most problematic changes and have a more targeted manual testing and review process. This in turn lets managers somewhat adjust the efforts for testing – that is, low-risk releases need less testing.
Defect analysis
This is a task that often needs to happen fast and usually takes a lot of effort. Additional to that, it ties into several interesting research topics, such as test generation, code analysis, execution analysis and automated programming. This topic is therefore constantly being researched and a lot of interesting approaches have been developed – however, none is available for purchase at the time of writing. One of the more interesting applications is the SapFix system, which even automatically generates fixes for technical errors (Jia et al., 2018).
Defects can be analysed from a lot of different angles, resulting in various ways that manual analysis can be sped up or, for example, tickets assigned to the ideal development resource. This includes the generation of additional tests for cause–effect chain analysis, stack trace analysis, execution path analysis and more.
Applying AI to other tasks: summary
These brief examples show the wide variety of ways AI can be used to support humans in development and quality assurance. We remain curious as to what unexpected approaches the future holds for us.
EVALUATING TOOL SUPPORT FOR TESTING
It is rarely useful to implement any of the aforementioned techniques directly in a typical project context. Instead, a tool vendor or platform provider would provide a tool that you then can choose to use. Therefore, this section will be the most applicable for most projects: how do you decide whether any given approach should be used and how do you choose between multiple available tools implementing an approach?
Metrics for an AI-based testing approach
In principle, an AI-based quality assurance tool is both an AI system like any other, and a quality assurance tool like any other – so the same metrics can be applied.
One of the requirements of a task that is given to AI-based systems, to counter the no-free-lunch theorem,3 is that the past is a good predictor of the future. However, ‘good’ is a somewhat fuzzy concept in many real-world scenarios. For example, in ‘Risk prediction and fault estimation’, one must be aware of both the pesticide paradox and the effect of self-fulfilling prophecies, which ironically have opposite effects: focusing testing effort on certain parts of the system will initially result in more errors and higher risk being indicated because the system will be tested more intensively at those points (self-fulfilling prophecy). After some time, as the quality of the code and the awareness of developers and manual testers increases, the pesticide paradox will kick in and the effectiveness of the prediction will decrease.
Typical metrics for AI-based approaches include the false positives (type I errors) and false negatives (type II errors). However, for many real-world problems, the latter are hard to measure. For instance, the type II errors of missed bugs in a system are often impossible to determine (i.e. it is hard to know how many bugs were not detected). Another aspect to consider is the severity of the defects that are found by the test cases, even if they cause a crash. It is not unlikely that the tool finds defects that in principle have a high severity (because they cause a crash), but no customer would ever use the software in the way necessary to trigger the defects. Reporting such defects may even have a negative net effect by diverting focus from more customer-relevant tasks or by spamming the ticket system. Therefore, it is not the number of bugs that is important, but the associated risk or impact on customers, which is even harder to measure.
However, unusual behaviours are often how adversarial agents attempt to access a system. So if the testing goal is security testing, then vulnerabilities, even obscure ones, are important to find.
Assessing claims of tool vendors
Many tool vendors have perfected their marketing to provide a most compelling story. And since AI became en vogue, this story often contains some sort of AI. However, one should not buy a tool for the tool’s sake and AI for AI’s sake, so, it does not really matter whether AI is part of a solution – which it often even isn’t. According to a 2019 report by MMC on some 2,830 AI start-ups in 13 EU countries, they could find no evidence of AI in 40 per cent of cases (MMC, 2019). It is reasonable to assume that when describing software products, such as testing tools, a similar amount of leeway is used in defining ‘AI’.
A healthy dose of scepticism should be applied when reviewing vendor claims. Whether AI is actually part of a proper solution is more of an academic question, as long as the tool performs as promised by the vendor. However, the performance is exactly what should be critically examined. Management’s expectations of an AI-based testing tool can also differ and even be unrealistic, putting the tool’s proponents in a difficult position if the tool fails to meet these expectations. In general, many tools work quite well for small examples, but scale poorly for larger projects, so make sure to account for that when performing the evaluation.
Unfortunately, many projects run into a chicken-and-egg problem: in order to realistically evaluate a tool, it has to be set up and configured (or even trained) properly. So, most of the effort must be invested before anything can even be evaluated. This in turn means one needs to resort to looking at the vendor’s previous implementations of the product and ideally talk to existing or past customers.
Return on investment
Ultimately, management typically will want to see some sort of ROI calculation. This can be hard to do for several reasons:
(i) | Depending on the processes in place, some of the metrics are easier to get and are more objective, such as number of bugs, number of customer requests or downtime. Depending on the accuracy of the tracking tools, one can derive metrics like effort in hours per bug and, based on that, costs per bug. However, most of the intuitive metrics are the wrong type of metrics (as opposed to merely being irrelevant) and don’t account for things like customer sentiments or lost sales due to, for example, bad ratings. |
(ii) | Depending on the selected metrics, expected reductions are hard to extrapolate – even with such seemingly objective measures as number of bugs. However, it is even more complicated, as the results range from effects that are subtle or unobtrusive, all the way to completely redesigning processes by adding capabilities. In some situations, the added value diminishes over time, making it even more difficult to estimate. |
(iii) | There will also probably be additional and unforeseen costs. These come from needing special knowledge and experience, effort for maintaining the system or reviewing findings (e.g. manually going through a lot of false positives regularly). Ironically enough, a tool can also introduce additional risk (e.g. false negatives). |
In order to get at least a rough estimate of the potential costs and savings, it is sensible to consider several questions: what impact will this system have on existing processes? For example, will you need to recreate or migrate artefacts such as existing automated tests? Will it integrate well with existing infrastructure, such as your existing test and reporting systems, continuous integration/continuous deployment (CI/CD) systems, release systems, documentation systems or ticket systems? Will it cause employees to change their behaviour (e.g. blind trust in the system through complacency or automation)? Will employees need additional training? Could there be unintended long-term effects?
Assessing test case generation tools
In the case of test case generation tools, there are several specific considerations and questions to be asked: are the generated tests realistic in that they represent typical or sensible usage? Do they cover key business risks, that is, do the generated test cases cover relevant user scenarios? Are the data used (or generated) representative of typical data? Is it even possible for the AI to generate realistic test cases without additional training? If not, how is such training possible, that is, what is the input to the AI system in terms of training data? Is it sufficient to merely record test cases?
When adding test cases to a project, the added value per test case decreases with the number of test cases added. The first test case is much more valuable than the thousandth. More test cases come with higher maintenance costs, slower execution cycles, higher life cycle management complexity and many other hidden costs. These costs should be outweighed by the benefits that the added test cases bring, so it is important to determine what the marginal costs are. Generated test cases are usually difficult for humans to understand (e.g. determining the goal of a particular test case) and therefore difficult to maintain. Sometimes a small detail makes a test valuable (e.g. in terms of coverage by checking a particular option). If the maintainer does not know what makes the test valuable in comparison to the others when maintaining it, a valuable test can easily be turned into useless ballast. All things considered, generated test cases are often cheap to generate, but expensive to maintain. What are the criteria for discarding the generated test cases and simply starting from scratch?
Evaluation tool support: summary
It has been shown that many questions have to be asked and answered in order to evaluate tool support in quality assurance – whether AI based or not. Unfortunately, the right answers for many of the questions are situation- and project-specific, closing the loop all the way back to the oracle problem, that is, determining what actually constitutes ‘correct’. Therefore, the goal of this chapter was to give an idea of what aspects to look at and what to consider when evaluating tools. We hope this will be of much more long-term value than giving concrete answers, which will be short-lived and ultimately wrong for most situations anyway.
TASKS THAT WILL LIKELY REMAIN CHALLENGING FOR AI
There are some tasks in the realm of quality assurance that will likely remain challenging for AI. These include gathering and challenging specifications and assumptions, communication with stakeholders, improving processes and organisations and many more. Should there be significant improvements in that regard, the chances are that these will have a more significant impact in other fields (such as management in general), so that the effects on quality assurance will pale in comparison.
As was discussed at the beginning of this chapter, the specification of test oracles, that is, the final assessment of the result of the software design and development process, will most likely remain a manual task – even if all else gets automated. This will entail communication with stakeholders to clarify ambiguities and retrieve missing information. Like the development of autonomous cars, we should not expect sudden leaps in AI in the field of quality assurance, but instead a steady improvement in the way these tools assist us with our daily chores.
AI can be used in very different ways when being applied to quality assurance. In this chapter, we have shown applications to the unit, interface and user interface levels, all of which come with their own respective challenges and solutions. And as technology progresses, many more yet unforeseen approaches are to be expected.
However, it is rarely the duty of testing practitioners to envision or develop such tools – so the intention of the last part of this chapter was to provide the knowledge necessary for the far more likely duty: to evaluate and decide on a tool and then apply it in practice.
Many testing experts are afraid of using AI, fearing that it will threaten their jobs in the long term. From our point of view, it should be consoling that AI will much more likely replace software developers (at least partially) than it will replace software testers. With Microsoft Copilot and OpenAI Codex, the first big steps in that direction have already been taken and many more will surely follow.
1 A code smell is considered a bad coding practice in most situations, but since there are legitimate exceptions, there are no hard rules.
2 Fitts’ law predicts the time a human needs for a specific movement, such as pointing a mouse before clicking, depending on the distance and size of the target.
3 The no-free-lunch theorem states that any two optimisation algorithms (including completely random ones) are equivalent when their performance is averaged across all possible problems. In order for any approaches (such as AI) to be superior, specific assumptions in regards to the problems have to be made – such as that the past is a good predictor of the future.