
In this chapter we will explore testing ML systems, how testing specialists fit in to the process, levels of testing, metrics and techniques. In addition, we’ll discuss how to test some specific characteristics of AI systems.
THE ROLE OF A TESTER
If you are working in an organisation developing ML systems, you might be lucky enough to be working with a smart team of data scientists and engineers. Some testing and quality specialists (as well as developers, for that matter) might be intimidated by the mathematical-sounding language and seemingly magic processes these teams use. Frequently, testers shy away from fully testing their outputs, or are discouraged from evaluating them. How can someone without data science expertise find holes in work by specialists?
There is no reason why the work would not be full of defects. Data scientists are no better at finding issues with their models than developers are at finding issues with their code. Conventional developers miss issues in their own work because of confirmation bias, that is, because they are making assumptions, or they inject small logical errors into their work. Data scientists also make assumptions. Sometimes these assumptions are based on their expectations of the predictions the model should make, rather than reality. It is too easy to keep tweaking the hyper-parameters of a model until you get the results you expect to see, without considering whether those results are correct.

Hyper-parameter is a variable set by a human in an ML model, before training the model.
The first area where testing and quality specialists can add value is simply by asking the right questions. Two of the most important qualities they can have are, firstly, thinking critically about the work outputs and, secondly, being fantastic at spotting risks. This starts at data collection and labelling. How have data for training been gathered? Are they representative of the real-world distribution? How have they been labelled? Have sample checks been carried out on the labels? What are the motivations of the labellers? Are there any subsets of the training data that might have been labelled incorrectly? Just asking these questions can reveal root causes of potential faults that may otherwise not be detected until much, much later.
Some of these questions can be explored statistically. For those with some technical skills, it might be useful to load the training data into an exploratory analysis tool (this might be a spreadsheet, a Python library or an off-the-shelf business intelligence tool). You can explore the data yourself and look for outliers, patterns, inconsistencies, sampling issues and errors.
The next area to look at is the data pipeline, which is the process by which data get to and from the model. Perhaps your organisation has a skilled data engineering team that takes the data scientists’ requirements and builds a great data pipeline that transforms and manipulates the data, or perhaps the data scientists build it themselves. The latter is a red flag for quality; data scientists are not engineers, and data pipelines are an engineering output. The code quality of data pipelines can be terrible, for this reason (Lenarduzzi et al., 2021). Component testing code coverage is of course the first place to look, but do not be surprised if there is very little.
A data pipeline is the infrastructure supporting an ML algorithm. It includes acquiring data, pre-processing and preparation, training one or more models and exporting the models to production.
Where data pipelines are built by separate teams, there is of course a risk of assumptions and implementation constraints being overlooked. The end-to-end integration between the source of the data, and the predictions from a model are crucial. You might hear that the data scientists have tested a million records in their model, but most likely those records have been fed in using CSV or some other format directly to the model, skipping the end-to-end data flow. Consider some potential bugs that might slip into the integration.
Firstly, the data pipeline could erroneously transform certain values that are features of the model, leading to incorrect predictions for both affected and unaffected records. For example, age could incorrectly be transformed to a single digit, leading to highly incorrect predictions if age was a key component of the prediction.
Secondly, the data pipeline could pass null values for some fields incorrectly, and that leads to the entire record being dropped. ML does not work well with missing values, resulting in incorrect training and missing outputs. For example, a lookup based on postal code could fail and leave city as a null, resulting in a failure to consider that record valid in either training or operation.
Thirdly, the data pipeline could duplicate some records incorrectly, and that would create too many examples of the duplicated record, skewing the model towards the values in those records.
A key role of a tester is identifying the scope of and approach for testing at each test level, with specified components and acceptance criteria. It is important that the product risks that emerge from an integrated system and the ML model are identified appropriately and mitigated through testing.
THE NATURE OF ML
We have discussed some of the quality problems AI can have, but there is one problem that turns testing very much on its head. ML uses statistical correlations to make predictions, and this is both its super-power and its weakness. As outlined before, this allows ‘automation without specification’, and allows for predictions to be created without human engineers really understanding the patterns that a model is identifying and using to make those predictions.
Conventional software is largely deterministic (if we forget about small differences introduced by things like multi-threading) and uses explicit logic to determine outputs. We can look at a specification, design some inputs and usually predict the outputs or actions of a system. With ML, that is much harder. It can be hard because it is too difficult to calculate the expected outcome, but it can also be hard because we do not expect ML systems to have 100 per cent accuracy.
For example, think about a facial recognition system. We can perhaps take 100 photographs of people’s faces, knowing that those faces are known to the system, and run them through the system as a test. Now, if 99 of those faces are recognised, but one is not, is that a test failure? It is unclear. This is an example of a test oracle problem.
It may also be of questionable validity because 100 is not a statistically significant number in the context of the global population of faces. Often, we really need to be testing thousands (or more) sets of inputs to get something that is statistically meaningful. Further, while with facial recognition we can use our human eyes to try to determine the expected results (a match, or not a match), with many predictive systems it is not that easy to determine the ‘ground truth’.
It is also difficult to use white-box testing techniques (that is, with knowledge of the code or structure of the system) because the internal structure of the ML model is not easily understood. Conventional software suffers from defects that follow certain heuristics (loop boundaries, field boundaries, field combinations), and this has led to testing techniques designed to detect such defects. Even when we are black-box testing a system (that is, without knowledge of the internal structure), we can use these techniques to find likely issues. ML largely does not follow those heuristics, so it is more difficult to plan tests that will expose issues. For all we know, our facial recognition system may completely fail with types of faces that are different in ways the human eye struggles to perceive.
ML can be described as a probabilistic system. A probabilistic system is one that is difficult to describe without using probability. For example, the weather is a probabilistic system as it is too difficult to model every particle, every gust of wind, and every temperature variation at a micro-level. So, forecasters use probability to make predictions. ML models are in many ways similar.
These testing problems are not insurmountable, but they require a different mindset from testing conventional software. They can also be significantly compounded by several factors. One of these is the integration of multiple ML components to create an integrated system. This is more common that you may think; for example in facial recognition it is common to use one model to detect the face within a larger image, and one to perform the identification against an existing dataset of face images. When you combine multiple probabilistic systems together, it becomes harder to predict behaviour, and in turn, predict what might go wrong.
Another problem is the use of ‘AI-as-a-service’. Much like software-as-a-service, this abstracts a lot of the complexity away into a third-party application programming interface (API) that is called to deliver the predictions. This can save a lot of effort on the development, but from a testing perspective it can be a nightmare. It makes the system less transparent, and usually makes testing it at a statistically significant scale more difficult. Instead of a data scientist running millions of records through the model on their desktop, you need to dynamically call APIs to get results.
Throughout this book you will see reference to test oracles. An oracle is something that allows you to determine whether a test has passed or failed. These might be requirements, specifications, alternative systems (pseudo-oracles) or just things you know (implicit oracles).
Levels of testing
A test level is a specific instantiation of a testing process. In a conventional project this will typically first comprise component testing that tests the smallest independent module of software, then integration and system testing and acceptance testing. Dependent upon the context, technology, risk and methodology being used, these levels vary from project to project. In highly iterative and agile projects these levels are executed in small increments, over a short period of time.
So how does this change with ML systems? From one perspective, not a lot. The levels of testing remain broadly the same; however, more careful thought might need to be put into the planning simply because of the complexity of the technology. To explain this, it is first necessary to consider why we have such levels in the first place – essentially, because it is easier to find and investigate failures when the verification scope is smaller. To illustrate this, consider a boundary (or ‘off-by-one’) error in a simple for loop in a micro-service. To find and detect this in a system or acceptance testing process, when many components have been joined together in an integrated system, is very complex. The effort involved to run end-to-end tests covering a boundary value is likely to be significant. The effort required to investigate the resulting failure and pin it down to the root cause is also going to be significant. Contrast this to a component test, where writing a test to check a boundary is almost intuitive, and the cause of the failure is likely to be faster to find.
We can apply the same logic to detecting failures in the predictions of an ML model. It is far easier to find and detect that failure when running a large volume of tests in a model testing process, than in an integrated, costly end-to-end environment. It is necessary to plan testing to ensure that complex failures are detected as early as possible, without introducing additional unnecessary components.
From another perspective, there are two test levels that are quite different from a conventional test process: model testing and input data testing. The first has already been mentioned: model testing is a form of component testing but can be clearly contrasted from conventional component testing. It is statistical in nature, it involves large amounts of data, the test results are complex and require mathematical analysis, and it is an iterative process normally conducted by a data scientist.
Typically, a data scientist will receive a dataset for training and testing a model. Some proportion of those data (between 20 per cent and 40 per cent, normally) will be held back for validation. The remainder will be used for training the model. To put this another way, most of the data are shown to the ML model as examples, the remainder are used to check that the model behaves correctly. There are several complexities here, for example for some methodologies a data scientist can dynamically attempt training using different subsets of the data for testing, and thereby provide multiple levels of testing with different subsets. This helps to ensure that the model is not overfitting to a particular training dataset.
This test level is critical, and it is not something a testing professional should be trying to pull away from a data scientist; it is effectively part of the development process (much like test-driven development at the component test level). However, there are three pitfalls to be aware of. The first is experimenter’s bias. This is a human cognitive bias that occurs when the experimenter (in our case, the data scientist) has a preconceived notion of what the test results of the model should be and fails to notice a flaw in their methodology because the results confirm their expectations. An example is failing to notice that the dataset that they have been provided with only contains a limited set of examples from some arbitrary subset; that means the population of data is not representative of reality. For this reason, it is useful to do some input data testing (more on this later).
The second pitfall is to assume that because the model has been thoroughly tested in this way, high-volume testing of the functional performance of the model is not required in later phases. This is not the case. In almost all ML implementations there is a complex data pipeline that pre-processes and adapts the data ready for testing. This might comprise adjusting images from cameras by normalising contrast or might involve transforming structured data values. These data pipelines carry all the same risks as conventional software, and by simply accidentally dropping some records, or incorrectly transforming some values, the effect on the ML predictions at a statistical level can be dramatic. It is necessary to thoroughly test the end-to-end data flows, and statistically test the overall system in later stages.
The third pitfall is not actually doing model testing at all. This is unlikely to happen where an in-house developer is developing a model, but can often occur where a software developer leverages a third-party model, or third-party model hidden behind a web-service facade. AI-as-a-service is an increasingly common business model, where ML components are leveraged without in-house data science skills. In this example it is crucial that model testing is carried out, and it may fall to quality and testing professionals to flag up this risk.
Going back to input data testing, this can be considered a test level. It falls into the category of static testing (that is, testing without dynamically executing a program), and is sometimes called ‘exploratory data analysis’ (Figure 4.1). Generally, it would take the form of obtaining the training data for an ML model and analysing the statistical properties of them.
Figure 4.1 Exploratory data analysis and model testing scope
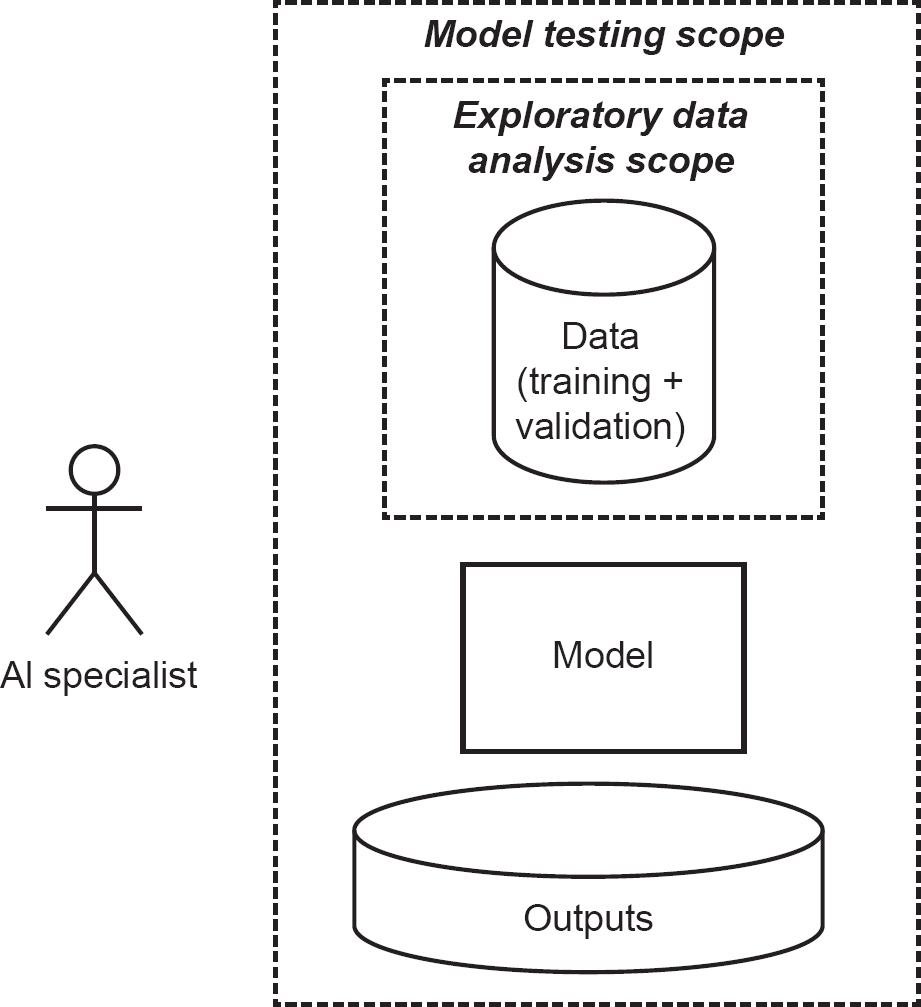
There are several reasons for doing this. Firstly, one of the biggest causes of ML prediction failures is imbalance in the training dataset. Analysing the distribution of data can reveal imbalances. For example, consider non-response bias, that is, where certain people tend not to answer questions or surveys. You might find that data are skewed towards groups of people who have more time or inclination to provide data. Another example is facial recognition; many models are trained based on publicly available data on the internet, which are skewed towards white male westerners. Detecting such an imbalance in training data allows you to detect likely failures (and bias) in trained models.
Another example of an issue you might detect in input data testing are partial data. ML models do not work well with partial data. Let us say for example we have some structured data with three columns, but one column is optional. Typically, a data scientist will either impute (guess) the missing values or drop the rows where that column is missing. Even if you start with a reasonably balanced dataset, the process of dropping some of the records can introduce an imbalance.
Although it is not a test level, it is normal to conduct far more monitoring of an ML system’s functional performance on an ongoing basis. Typically, with conventional software we build it, test it, then throw it over the wall into ‘production’, or live usage. We tend not to frequently revisit it. However, with ML systems we need to continually review and revisit the quality of the system in live usage. There are a few different reasons for this. Firstly, the quality of ML is wholly dependent on how well the training data represent the ‘unseen’ data it will encounter in the live environment, so it is necessary to continue monitoring the data after go-live to ensure that the model remains robust. In addition, models can suffer from concept drift, that is, the correlations between inputs and outputs that are presumed to exist (because they exist in the training data) are not static, they change over time. Consider a model designed to predict foot traffic in a shopping mall based on various datasets. No doubt as soon as the COVID-19 pandemic occurred the correlations between different input features and shopping mall foot traffic were turned on their head. This is an extreme example, but as the real world changes, the quality of ML model predictions can both improve and degrade. Another reason for monitoring the quality of ML in production is bias detection; it can be difficult to determine bias sometimes in a test environment, again due to a potential difference between the training data and the data a model is exposed to in the live environment, and continued monitoring can help with this.
In summary, there are two specific ‘levels’ of testing that are not likely to be required (or at least, as important) with conventional software that we need to consider in relation to ML: model testing and input data testing. However, more testing may be required on an ongoing basis.
User acceptance testing of AI systems, while broadly the same as conventional user acceptance testing, may need additional focus. It could be that the system is designed to replace human activity, in which case it might be necessary to compare the behaviour of a system to humans. Special consideration should be given to automation bias, that is, the degree to which human decisions degrade when supported by a machine, or when monitoring a machine.
TESTING METRICS
Testing processes are frequently measured, either as part of a management and control process, or as part of an exercise to understand the degree to which the testing ‘covers’ the basis of testing. The latter is discussed in the next section. There are lots of other metrics that can be applied to testing ML systems, often in terms of their accuracy, or performance. These are used because we do not expect ML to get everything right all the time, so we need to run a statistically significant number of tests and look at the test results statistically too. This is like analysing the results of performance testing (how fast something runs under a certain load of data or users).

There is an important terminology difference between the software engineering and the AI/ML domain in the way the word performance is used. For some reason, engineers use ‘performance’ to mean time-behaviour, efficiency and resource utilisation. Not so in AI/ML, where ‘performance’ simply means how well the system or model behaves given a particular metric. To try to avoid confusion, we use the term ‘functional performance’.
The functional performance of an ML model is measured differently depending upon the business objectives, and the type of output. Two of the most common types of output are a continuous number or prediction of whether something belongs to a particular class. As you can imagine, these are quite different types of output, which we discuss in different ways.

Regression models, in ML, are those that output a continuous variable, that is, a floating point number. Classification models are those that predict whether something belongs to a particular class.
For regression model results, we can use mean square error (MSE). That is simply the average error rate (the difference between the expected value and the predicted value) squared. If I run 10 tests and the expected result should be 0 for each test, and all the actual results are 10, then my (mean) average error is 10. However, if the actual results range between −10 and +10, then my simple average might end up being 0, indicating incorrectly that all my tests pass. That is why we ‘square’ the error; as you can see in Table 4.1, it more correctly reflects the result:
Table 4.1 Example of MSE
Expected result | Actual result | Error | Squared error |
0 | −10 | −10 | 100 |
0 | 0 | 0 | 0 |
0 | +10 | 10 | 100 |
Average: | 0 | 66.66 |
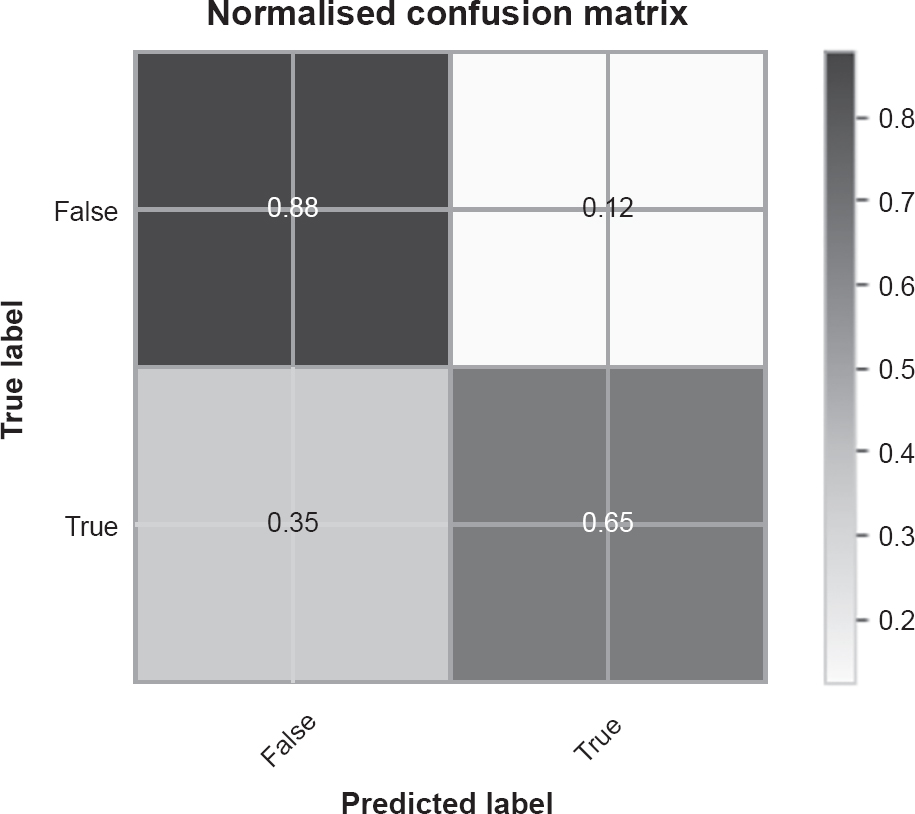
For measuring the results of classification models, we need to take a different approach. Each prediction has two properties, whether the prediction was that something did or did not belong to a class, and whether that prediction was correct. These are referred to as true positives (correctly predicting something belongs to a class), true negatives (correctly predicting something does not belong to a class), false positives (incorrectly predicting something belongs to a class) and false negatives (incorrectly predicting something does not belong to a class). Not only does this mean we have two separate modes of failure, but the impact of those failures may be very different. Predicting someone has a disease, incorrectly, has a very different impact from incorrectly predicting someone does not have the same disease. In the former, they may find out through follow-up tests and predictions. In the latter they may not get tested again.1
We therefore often visualise these failure rates through a confusion matrix (it is perhaps called a confusion matrix because although it originated in the study of statistics, it was used for many years primarily in the study of psychology). Figure 4.2 is an example of a confusion matrix.
Figure 4.2 A confusion matrix
TESTING TECHNIQUES
The 10 tests used as an example for MSE in the previous section are unlikely to be enough to get statistically significant results. That of course leads to the question ‘How many does?’ Well, much like in the testing of conventional systems, exhaustive testing is not possible. Conventionally we use a risk-based approach combined with test techniques shown to maximise the likelihood of finding an error, by exploiting heuristics of common software errors. We prioritise requirements and analyse the structure of the system to design test procedures that contain expected results.
However, where the system is non-deterministic, there may be multiple valid outputs from the system’s processing – even when presented with the same inputs and starting from the same state.
So how can we approach this challenge with ML? There are several ways, none of which is fundamentally proven yet to be the best approach, but that is also partly true of conventional test techniques. In fact, focusing on any one test technique too much can lead to problems like test case explosion, so they should always be used with care and in a balanced way.
Combinatorial testing
In some circumstances, you can analyse the data that have been used for testing, against all possible variations of input data. Given the ML model is trained to respond to input data, looking at the variety of input data used can give you a proxy for coverage. For example, if you have ‘age’ or ‘country’ as an input feature, you can look at whether the test data have covered all ages and countries to a statistically significant degree. This might be useful, but it might also be a lot of effort to obtain or manufacture additional data. It is also a technique that is only applicable to the simplest use cases. Imagine trying to do this with facial recognition; the sheer volume and variety of inputs is staggering.
One way to simplify the selection of test inputs is to use the concept of pairwise testing. Pairwise testing (or All-pairs testing; Wikipedia, 2021) is based on the concept that manipulating pairs of inputs exposes more defects than simply manipulating a single input. It is based on research conducted on conventional software (Nie and Leung, 2011), but that does not mean it does not apply to ML.
To apply pairwise testing, we can take a variety of inputs. With facial recognition as an example, we could use skin colour, eye colour, nose size, background and lighting. We can assume that each of these inputs can be bucketed into 10 possible values. For instance, using equivalence partitioning you might bucket lighting into 1–10, where 10 represents very bright, and 1 represents very dark. After applying buckets to each input, you are left with 5 inputs with 10 possible values, that is 50 test cases for each input, and 505 possible test cases, or 312 million. Applying a pairwise technique to these will reduce the number of test cases to just 100. Explaining the mathematics of this is somewhat outside the scope of this book, but there are plenty of online resources, papers and even web-based test design tools you can explore to investigate this technique further.
Using this technique does not alleviate problems you may have with your test oracle, that is, challenges determining whether a test has passed or failed.
Neuron coverage
Test coverage is a widely discussed concept in software engineering. At one end of the spectrum, test analysts might map requirements and business processes to sets of tests, to measure the degree to which the high-level business requirements have been covered by tests. At the other end of the spectrum, in automated testing (particularly in component testing), it is common to measure the statements and branches of code in the software under test that have been covered by those tests. This is performed by instrumenting the code (or using a wrapper around a Java Virtual Machine) and leads to a scientific measure of test coverage. In fact, this is required for some domains, such as the safety testing of road vehicle systems.
How can we do this with neural networks? Firstly, we need to drill a little more into the detail of how neural networks work. Before that we need to recap on Boolean logic. Boolean logic is the foundation of computer science, it is how we process 1s and 0s (binary numbers) inside hardware processors and low-level machine code. The most important Boolean operators are OR, AND, NOT and XOR.
- If I pass two binary numbers to an OR operator, it will return 1 if either input is 1 and 0 if neither is.
- If I pass two binary numbers to an AND operator, it will return 1 if both inputs are 1, and 0 if they are not.
- If I pass one binary number to a NOT operator, it will return the other binary number (i.e. if I pass 0 it will return 1, and vice versa).
- If I pass two binary numbers to an XOR operator, it will return 1 if either input is 1, and 0 if they are both 0 or both 1.
Without dwelling too much on how these powerful but simple concepts underpin modern computing, let us look at how we could replicate the AND operator using a really simple neural network.
A layer of a neural network comprises two important variables, weights (one per input) and an activation value. The weights determine the relative importance of each input to the layer, and the activation value determines the decision boundary for the output. The training process automatically determines the correct weights and activation values based on the training data and the model hyper-parameters.
The mathematics of a neural network layer can be described as follows:
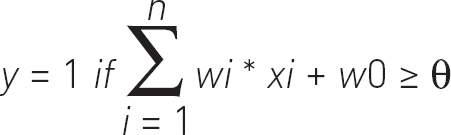
To break that down a bit:
- y is the output value.
- xi represents all our inputs, in the AND example there are two inputs x1 and x2.
- wi represents our weights, which are both 1 in the AND example, as both inputs have equivalent importance.
- w0 represents a constant value (of our choosing).
- θ represents the activation value (the decision boundary), usually values less than zero output a zero, and values of zero and greater return one.
Breaking the above formula down into manageable chunks, first we need to multiply each input by its associated weight, then add the results together (α), as shown in Table 4.2.
We know that the AND operator should only return 1 if both inputs are 1, and from Table 4.2 we can observe that α is clearly different in this scenario: it is 2. In order for the result of our formula to be 1 only in this scenario, we need to adjust α so that it is the only result greater than or equal to zero. We do this by adjusting the constant w0. In this example we can set it to −1.5, and now we have the AND operator implemented in a neural network as shown in Table 4.3.
Initial example of the AND operator as an activation function
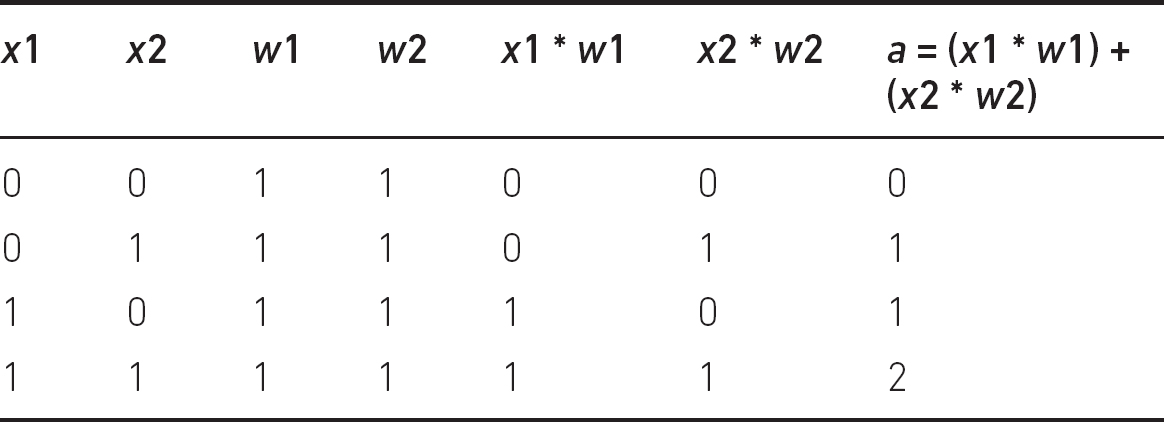
Table 4.3 Example of the AND operator as an activation function
x1 | x2 | a = (x1 * w1) + | a − w0 | Y (a – w0≥0) |
0 | 0 | 0 | −1.5 | 0 |
0 | 1 | 1 | −0.5 | 0 |
1 | 0 | 1 | −0.5 | 0 |
1 | 1 | 2 | 0.5 | 1 |
Obviously, this is an incredibly simple piece of logic to try to replicate. Also, a data scientist would certainly not train a neural network by developing lots of tables and analysing the data at this level, they would simply train the model by providing examples, and the ML framework would make all the necessary adjustments to weights and constants. In practice, multiple layers are required to interact with each other in order to solve most problems.
Going back to test coverage, even though ML models are ultimately machine code, it is not going to be relevant to apply traditional code coverage measures such as statement coverage. This is because the same lines of code are usually run for each prediction. We need to adjust the measures to handle the formula described above. These measures are built around the following questions:
- Has a test caused every neuron to achieve an activation value of greater than 0?
- Has a test caused every neuron to achieve both a positive and negative activation value?
- Has each neuron been covered by two tests with a certain distance between activation values?
- Have pairs of neurons in adjacent layers been tested in combination, so that the change in the activation value in the first layer causes a change in the activation value in the second layer?
Bear in mind that measuring neuron coverage helps you to understand how much of your model is exercised by your tests, but it does not tell you the expected results of those tests or tell you whether you are checking the right things. Also, tools for measuring these coverage criteria are not widely available, and require testability features to be added to the ML framework.
Experience-based testing
Exploratory testing techniques can be applied to ML, as can checklist-based techniques. Much like error guessing techniques can be used to guess where bugs might be in conventional software, the same can be applied to ML.
Experience-based testing uses implicit oracles, either heuristics related to quality risks discussed in the previous chapter, or standardised checks.
For example, when performing experience-based input data testing, one might ask:
(i) | Is there a protected category variable in the features? |
(ii) | Is there another feature that correlates with a protected category variable? |
(iii) | Is there less than a representative amount of data associated with a protected category variable? |
Another example of a checklist-based technique is using Google’s list of 28 ML checks to determine readiness for production (Breck et al., 2017). This includes checks on the feature selection, the architecture, the documentation and the test results.
Some researchers (Herbold and Haar, 2022) also found that by using conventional test techniques, such as boundary value analysis, they were able to find fundamental defects in ML frameworks themselves. For example, by passing ‘0’ for many features they were able to cause the framework to crash.
Metamorphic testing
Metamorphic testing is a test technique that generates new test cases from previous test executions. It is unusual as a test technique in this regard, as usually tests can be designed in advance of executing them. In some ways, it is a little like exploratory testing using an implied oracle, as the tester establishes some heuristic and uses that to determine expected results. In exploratory testing such an implied oracle might be ‘the result of a square root should never be negative’. In metamorphic testing it might be that the model should provide fewer results if more inputs are provided, or be more likely to predict something, given a particular input. These heuristics are called metamorphic relations, and they establish a probabilistic relative requirement upon the system and allow us to create expected results for follow-up tests.
A simple way to imagine such a test is any online store where you can filter items in a search. A search with a filter should, generally, give fewer results than a search without a filter. By executing a series of test cases, you can gradually apply filters and see fewer results. While you cannot easily predict how many results you will see each time, you can see whether the metamorphic relation holds true.
Metamorphic testing can be useful when you are having trouble determining the expected result of a test in advance. Again, an oracle problem.
A/B testing
A/B testing is a technique where two variations of a system are used, and the results compared. This technique takes its name from a marketing technique, where small variations in marketing emails or on websites are presented to different groups of users to see if it changes their responses.
A/B testing can be used to test two models and can be particularly useful where the ‘ground truth’ is not known. Consider for example where you are recommending news articles of interest to individual users; how do you know that you are recommending things that they are actually interested in? One way is to monitor what they click on and compare the click-through-rate from results provided by two models.
Use of experts
Some test oracle problems can be alleviated using experts to help determine if a test passed or failed. Consider a system that replaces those with expertise in a field like diagnostic medicine; at some point, during the testing, it is essential to have some medical diagnostic experts in the room.
There are challenges with the use of experts: they naturally vary in competence and they may disagree. Humans can express things with ambiguity or adapt their responses to add caveats. This is more difficult for an expert system to do.
Experts may also have particular motivations about automation; it might be necessary to make evaluations double-blind, so experts do not know whether they are reviewing the outputs of a colleague or a machine.
Adversarial testing
Models may be vulnerable to adversarial attacks. Adversarial testing is testing a model to learn about the model’s behaviour and then to identify potential vulnerabilities. It is exactly what an attacker would do, but with different goals – to prevent the attacks.
Adversarial testing may also involve the use of tools to conduct white-box analysis on the model to identify successful adversarial attacks and add them to the training dataset to make the model less vulnerable to them. However, this is not how an attacker would do it. An attacker would rely on the fact that most of these vulnerabilities are actually transferable models, so they might try to build a similar model, find vulnerabilities in that and then try applying them to the model they are trying to subvert.
Adversarial testing can be considered both a functional and a security test, in that it is simulating attacks that are trying to change the functionality. As mentioned in Chapter 2, adversarial examples can be found in multiple types of application of AI, including computer vision and natural language processing. In both cases, the overall image or text is still seen to be conveying the same information to a human, but is perceived differently by AI.
Back-to-back testing
Back-to-back testing, also called parallel or difference testing, helps where there is an oracle problem. An existing or otherwise alternative implementation is used as a reference, or a pseudo-oracle.
Any tests that are run on the system under test can also be run on the alternative implementation and the results compared. This approach has been used for a long time in testing, for example in financial services where the results of two large batch systems that perform millions of calculations can be compared, without the intellectual activity of defining the expected result for each calculation.
One way to do this is to use industry standard ML benchmarks, which represent a certain level of functional performance. These benchmarks might be labelled, and therefore allow for the functional performance of the system to be tested without a test oracle; however, it is necessary to consider how that labelling occurred. A study in 2021 found a 3.4 per cent label error rate across popular benchmarks (Northcutt et al., 2021).
TESTING AI-SPECIFIC CHARACTERISTICS
In Chapter 2 we discussed unique quality characteristics of AI. Let’s now look at how to test for some of those characteristics.
Self-optimising systems
Testing systems that learn from their own experience present several challenges for designing and maintaining tests.
The constraints and behaviour of the system may be clear at the point of release; however, the changes made by a system since that point are not known. The system could have changed in terms of its functional behaviour; these changes may cause previously passing regression tests to fail, even if the changes make the system better overall – another example of a test oracle problem. The system might have found a new way of achieving its goals that may not be easily discovered or analysed.
It is quite important for test design to understand the mechanisms in place to learn for any system. It may be that the system is a shared one used by many stakeholders, not just those at the company implementing it. Using cloud-based AI systems typically constrains the ability for stakeholders to understand or monitor learning, as the details of the process can be hidden from the user.
Even if you are using an internal system and have a great level of control, you might need to think about the timeliness of retraining and test the automation of it. You might also need to consider the resources used; if a system can achieve its goals by using ever more system resources, that might be good for functional behaviour, but eventually cause a failure when those resources run out.
Another non-functional concern is adversarial actors, for example hackers. It might be possible to poison the data or other inputs that the system is learning from in a way that influences its learning and subsequent behaviour.
Autonomous systems
Purely autonomous systems are those that require no human monitoring or intervention for their operation. However, many such systems have operating parameters that may be breached and trigger them to seek human intervention. It could be necessary to design tests that check how this works and ensure that the system requests intervention (or does not request intervention) in certain scenarios. It is likely to be necessary to manipulate the operating environment significantly in order to check these scenarios.
Algorithmic, sample and inappropriate bias
Bias is a huge topic that was covered in Chapter 3. Testing for it might include reviewing training and input data (input data testing) or reviewing the methods and decisions in the procurement of those data. It can also include ensuring that the pre-processing of data is being done accurately and without introducing sample bias, and detailed analysis of the outputs of model testing. Further, it can include using explainability tools to understand how particular inputs to the model cause changes in the outputs.
It can sometimes, particularly with inappropriate bias, be very useful to obtain additional data that are not directly processed by the model. This might be demographic or diversity related data, or it might simply be the ‘ground truth’, that is, a determination of whether the model’s predictions were correct.
NON-DETERMINISTIC SYSTEMS
Non-deterministic systems are those that may produce different outputs each time they are used, even with the same initial state and inputs. Typically, when we execute regression tests on a system, we expect to see the same results as before, whereas with a non-deterministic system we may have multiple valid outputs.
Usually, the solution to this is a deeper understanding of the system in order to define implicit or explicit tolerances that the outputs should meet. It might also be necessary to run them a lot of times, in order to obtain a statistically significant output.
TRANSPARENCY, EXPLAINABILITY AND INTERPRETABILITY
Transparency and explainability were covered in Chapter 2 and are very important characteristics. Not only do they affect the investigation and resolution of defects, but they are necessary for continuous improvement. Methods and tools for explainability are a rapidly evolving area, but SHAP (Shapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) analysis might be a good place to start. These tools allow analysis of how inputs affect outputs and can reveal some odd issues.
For example, in classifying something based on natural language inputs, SHAP analysis might reveal that quite irrelevant words have an excessive influence on the classification.
Sometimes, obtaining an explanation for an action might be something that the user can do themselves through system functionality. Sometimes, there might be a need for an operator to do the same. An important factor here is how easy that is, how timely and how understandable. These aspects fall under ‘interpretability’, and testing might be performed with the users or operators of the system.
SUMMARY
In this chapter we have explored how to test ML systems. This is a rapidly evolving field, and it is not yet standardised with clear best practices. It is also worth remembering that there are other types of AI systems, such as reasoning systems, that are not ML and that we haven’t covered in this chapter.
1 Even though such false positives can be resolved through further testing, the impact of false positives over a large population can still lead to millions of people being given an incorrect positive result with a significant impact.