
Shift right with digital twin testing means harnessing the power of analytics and autonomics to learn from the real world dynamically. Faced with volatile systemic failure models, digital interfaces need to be highly robust, work through numerous endpoints and process vast volumes of structured and unstructured data. Although adopting continual delivery and testing will help to enable agility, automation is generally powered by static rules using traditional scripting and orchestration. These approaches have a high maintenance overhead in order to keep up to date with changing requirements. The recent advent of predictive analytics and cognitive engineering technologies such as AIOps has opened up the possibility of pushing adaptive automation to self-healing and self-configuration, within evolving real-world situations.
THE SHIFT-RIGHT APPROACH TO TESTING
Increasing the benefits of learning by shifting the focus more to the right-hand side of the information systems design and testing cycle.
To better understand what shift right is, let us first explore what shift left is all about. Shift left refers to the traditional sequential design techniques of waterfall/V-model methodologies (i.e. requirement analysis, design, testing, then implementation), to the more recent focus of iterative agile design principles.
Recent approaches in systems design and testing tend to still be focused on tackling issues during the design phase rather than later in the life cycle (e.g. root cause analysis and the Pareto principle to find and eliminate the sources of the greatest number of defects) (see Figure 7.1), the intention being to reduce the costs that would otherwise arise from rework following changes.
When an information system or a piece of software is designed by trying to figure out as much as possible what would be best for the users based on testing every possible way that it could fail has an effect on the early design and testing phase, it can be called shifting to the left of the IT systems or software development cycle. Hence, the term shifting left is used to describe such practices.

Shifting left relates to the finding and removal of defects as close as possible to the point of introduction. This approach tends to shift the focus of time and effort towards the early design and testing phases, that is, shifting to the left of the systems or software development cycle.
Figure 7.1 Shifting left and shifting right
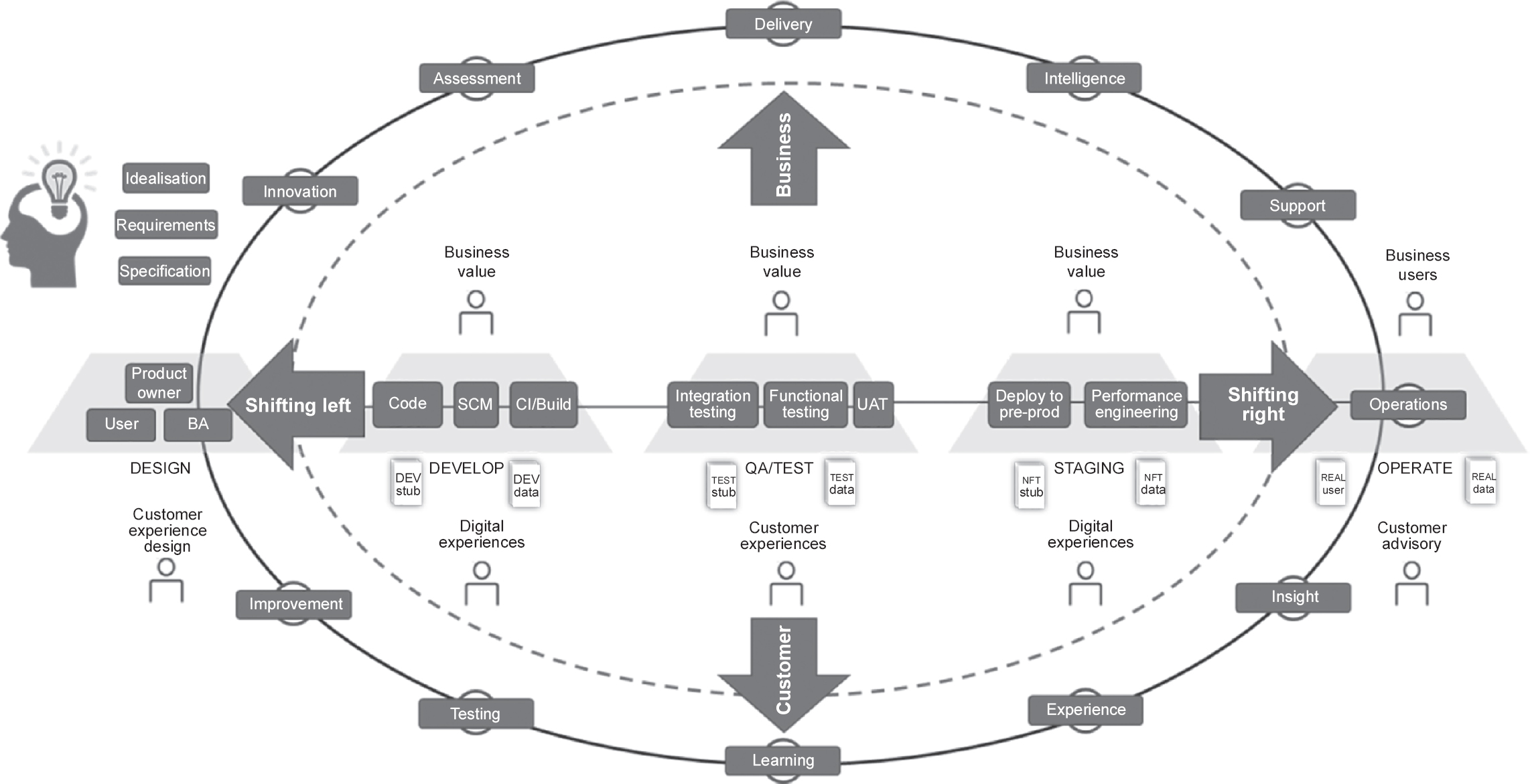
Note: BA = business analyst; CI = continuous integration; DEV = development; NFT = non-functional testing; pre-prod = pre-production; QA = quality assurance; SCM = source code management; UAT = user acceptance testing.
Contrasting shifting right with shifting left
With shifting right, rather than trying to identify the issues that could arise early on in the development and testing phases, we quickly develop and gain customer feedback sooner rather than spending excessive time on testing, thus shifting more to the right-hand side of the development and testing cycle.
Shifting right puts more weight on the learning aspect and the continual evolution of systems design and testing. After deploying the system or software, user experiences and other data are used as feedback. This feedback loop connects what the system or the software was designed for, to what is actually happening in the real world, in order to get a better understanding of the essential changes needed.
Shifting right relates to developing systems iteratively by focusing on learning rapidly from customer feedback. This approach focuses on quickly developing and releasing it to the users or focus groups to minimise the total testing time. Such a methodology is shifted more to the right-hand side of the development and testing life cycle.
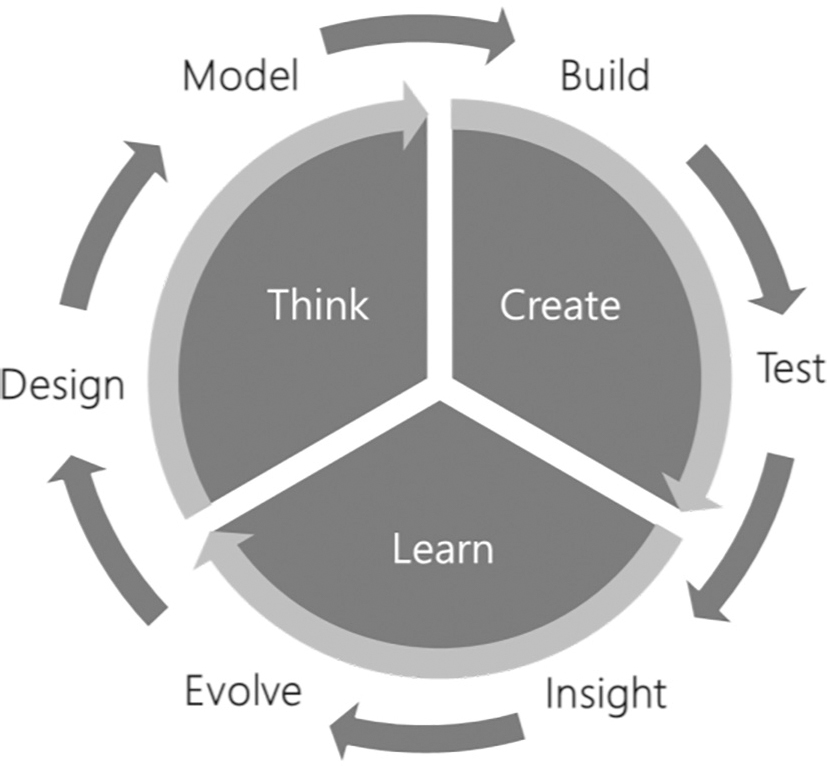
COGNITIVE ENGINEERING PRINCIPLES
Cognitive engineering software development principles can be considered as a trifecta of the following:
(i) | Thinking segment. Where we model something and expect it to behave in a particular manner. |
(ii) | Creating segment. Create according to the thinking aspect. |
(iii) | Learning segment. Learning with the help of operational tools and mapping if the created product or service has managed to deliver as predicted in step (i) (Figure 7.2). |
This traditional linear process now incorporates the feedback loop, feeding back data from events in the real world. By using a shift-right approach, the learning aspect can be achieved earlier on, and developers can start getting feedback on the system or software development much earlier in the life cycle, thereby saving considerable time for overall development and testing.
In other words, shifting right is a process of learning from the right-hand side or the user journey of the information system or software and using the feedback data to evolve smarter development and testing techniques that can help developers and testers understand potential issues that could arise before they occur.
But how can testers identify the potential issues that could arise with such a developed system? A plain explanation would be to say by looking at it with a more OpsDev approach, compared to the conventional DevOps approach, with the help of artificial intelligence, machine learning and deep learning technologies.
We are all familiar with the conventional software development cycle and the part played by DevOps, best described as enabling ‘Dev-centric Ops-capabilities’, where the actual true value should be OpsDev, ‘Ops-centric Dev-enablement’ collaboration. This can be achieved by providing improved insight into the operational space; these tools should not be limited only to the production space. Similar or better tools could be utilised to learn more about the behaviour of the software that is being built under the shift-right discipline.
Cognitive engineering disciplines
Cognitive engineering is a method of study using the concepts behind cognitive behavioural psychology to design and develop engineering systems to support the cognitive processes expected by the users (Wilson et al., 2013). How can cognitive engineering disciplines help to shift right the testing? By leveraging certain heuristics such as:
- Performance engineering. The emulation of production loads to determine the performance limitations (or bottlenecks). These tests are carried out to sort out any issues that might transpire under heavy load conditions.
- Site reliability testing (SRT). The focus of real-world testing of software within production. In other words, it is the practice of maintaining the programmable infrastructure and maximising the availability of the workloads that run on it. Site reliability testers blur the boundaries between testing within the software development life cycle (SDLC) and operations excellence, by applying a software testing mindset to IT operations management (ITOM).
- Chaos engineering. The discipline of experimenting on a software system in production in order to build confidence in the system’s capability to withstand unpredictable conditions.
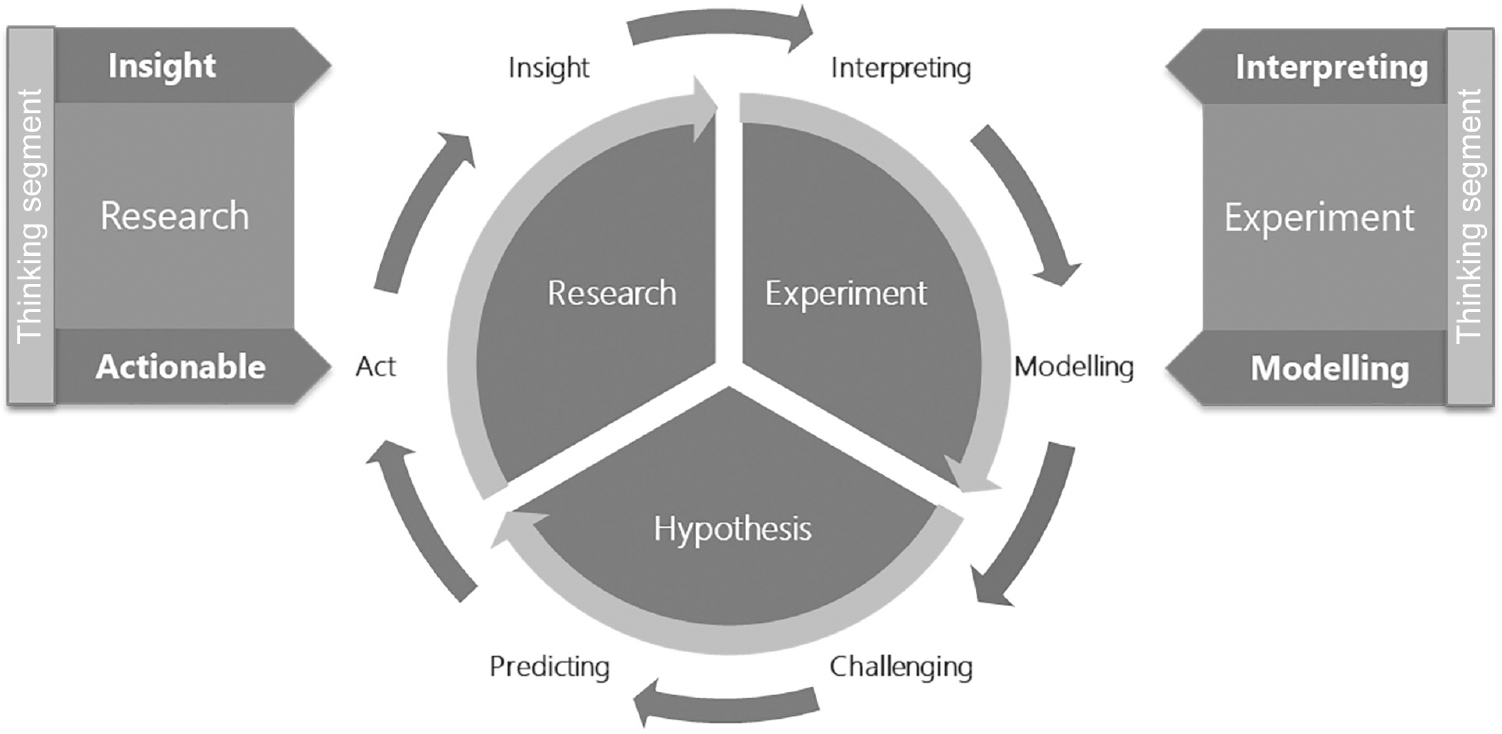
The ‘thinking segment’ in Figure 7.3 defines the ‘experiment’ and proves the ‘hypothesis’ of the behaviours, sharing the ‘Principles of Chaos Engineering’ (2019):
- Build a hypothesis around steady state behaviour. Focus on the measurable output of a system, rather than internal attributes of the system, by focusing on systemic behaviour patterns during experiments, verifying that the system does work, rather than validating how it works.
- Introduce real-world events. Chaos variants reflect real-world events. Prioritise events either by potential impact or estimated frequency. Any event capable of disrupting a steady state is a potential variant in an experiment.
- Automate experiments to run continuously. Build into the production system the ability to drive observability, orchestration and analysis.
Figure 7.3 Cognitive thinking: ‘The Digital Manifesto’ (Source: Wright, 2016b)
Chaos engineering is the discipline of experimenting on a software system in production in order to build confidence in the system’s capability to withstand turbulent and unexpected conditions (Principles of Chaos Engineering, 2019).
We can take these disciplines and apply them to the development of cognitive platforms such as those with artificial intelligence, machine learning and deep learning. The true power of cognitive engineering is that we can prove a hypothesis rapidly using these disciplines. This is where the real science behind modelling is the workload; volumetrics models help us to understand the real-world user journeys and allow us to create realistic load profiles that then can be run against target predefined system states.
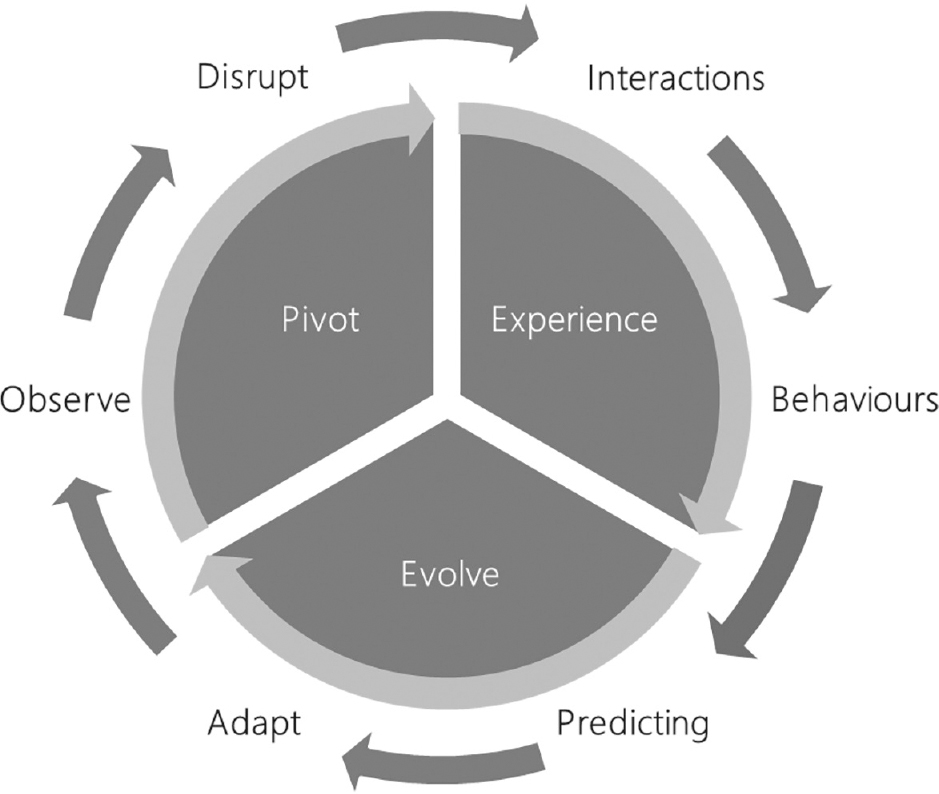
Cognitive engineering disciplines in collaboration with application performance management (APM) platforms, when combined with intelligent operations (AIOps), can help systems designers to identify when a system is going to break before it happens.
SRT enables observability and testability of a hyper-baselined system, that is, utilising multidimensional transactional datasets (for example combining time series data with streaming data services, such as the TICK stack) (Figure 7.4). This enables realistic or synthetically generated loads to be measured, and used to prove the hypothesis of a system or application.
DIGITAL TWIN CONCEPT IN SHIFTING RIGHT
The complex nature of modern software development often results in layers of abstraction, for example the hardware abstraction layer (HAL) hides the complexity of hardware design from software engineers. The same is true with systems of systems; the concept of a digital twin allows the abstraction of system thinking to make it explainable and understandable to non-technical subject matter experts.
Digital twin is the generation or collection of digital data representing a physical or virtual object. The concept of digital twin has its roots in engineering and the creation of engineering drawings or graphics. Digital twins are the outcome of continual improvement in the creation of product design and engineering activities.

NASA’s Apollo 13 mission can be considered as the first time the digital twin concept was used to safely return astronauts to Earth.
After a successful launch, Apollo 13 suffered damage to its main engine due to an explosion in the oxygen tank upon jettisoning the service module. This resulted in a life-threatening leak from the astronauts’ oxygen supply.
Mission control had to quickly dispatch all available ground resources to bring the astronauts home. With the help of other astronauts on the ground using simulators, NASA replicated the situation taking place in space nearly 200,000 miles away from Earth and managed to figure out a solution to return the astronauts to Earth successfully.
They created a virtual representation of the crippled spacecraft and ran simulations on that digital twin to better understand how to fix the damage before applying the changes made in the simulated environment to the actual one (Ritchson, 2021).
CASE STUDY: HELPING THE COMMUNITY STAY SAFE DURING THE PANDEMIC
Figure 7.5 depicts a COVID-19 dashboard taken on 14 February 2021, provided by Todd DeCapua (member of the ‘Splunk for Good’ team).
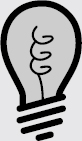
In 2020, Rob Tiffany shared the concept of how digital twins could be our best weapon in fighting the COVID-19 pandemic. This can be seen on YouTube at: https://youtu.be/XKINvqiTgxQ.
The digital twin approach helped to reduce the spread of COVID-19 during the pandemic by supporting the testing of both the global positioning system (GPS) and Google Apple Exposure Notifications (GAEN) contact tracing platforms. By working closely with Google and Apple, MIT were able to incorporate Bluetooth data instead of relying on GPS data, so that Bluetooth could be used as a proximity sensor when two individuals (or devices) interact. As a result of this collaboration came the idea of applying digital twins to help solve the contact tracing testing challenge.
Since early 2020, I have been collaborating directly with MIT, leading the quality assurance and testing efforts for the COVID PathCheck Foundation (n.d.). This focused on creating a more efficient contact tracing solution than the manual process used by other health officials at that time, which involved asking individuals where they have been, who they encountered, and so on for the past few days. Their manual approach was prone to many deficiencies as it relied heavily on an individual’s memory of the places they had visited.
The motive behind using such a concept in the contact tracing project was to increase the accuracy of the app by reducing the number of false positive alerts. When the whole world was affected by the spread of COVID-19, countries were in dire need of an effective solution for contact tracing. Dedicating a lot of time to consider all possible outcomes before an app can be made available was not a feasible solution.
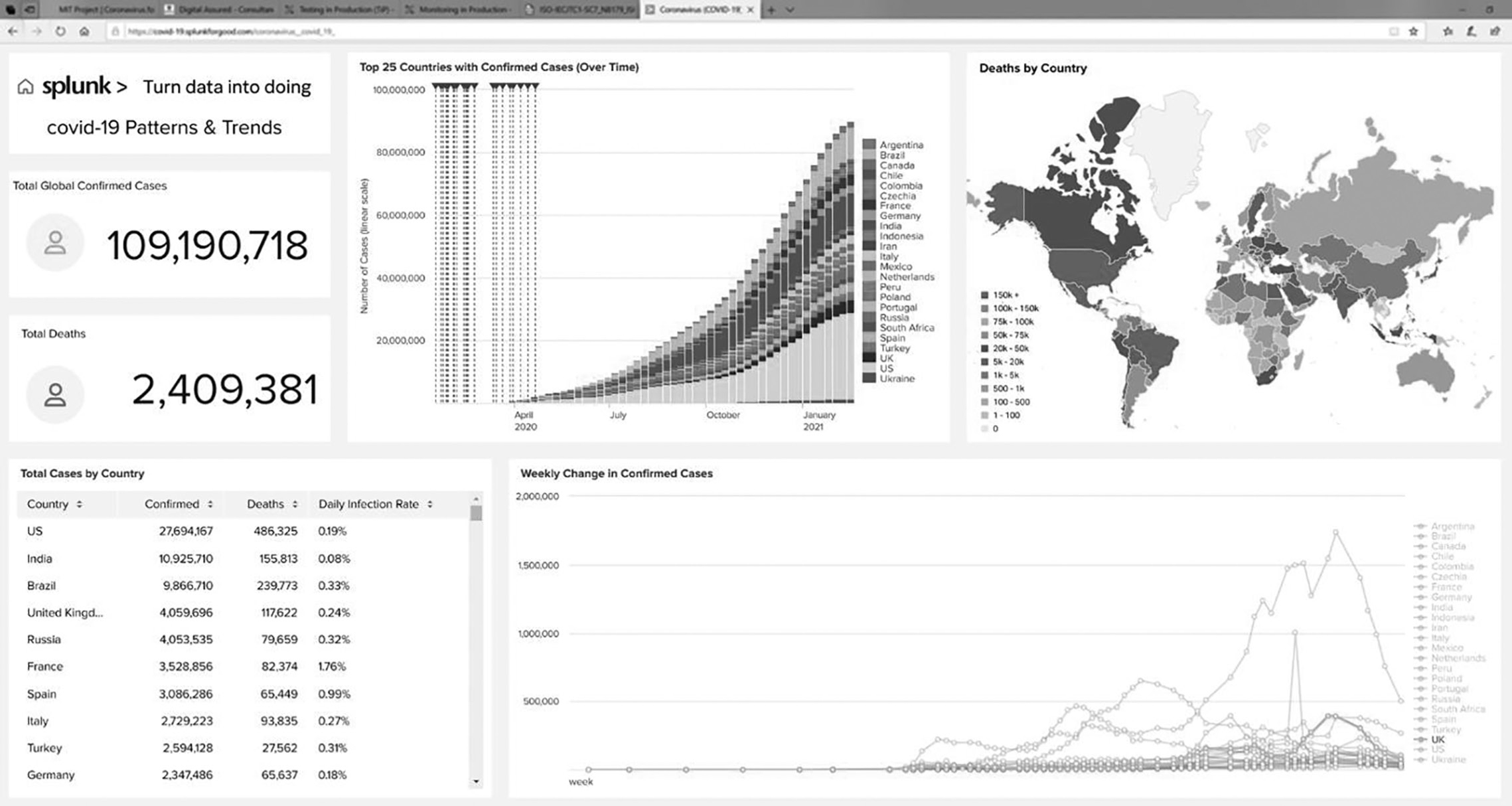
The British government started working on developing a mobile app to alert people to possible exposure to the virus, aiming to reduce the spread of the virus. They tested the app using real people walking around with smartphones to simulate real-world interactions. This shift-left approach consumed a disproportionate amount of time beforehand and resulted in the health authorities being unable to deliver a workable solution in time (Ward, 2020). This was a classic example of where a shift-right approach could have minimised the time constraints and enabled a practical and efficient contact tracing app to be developed more quickly.
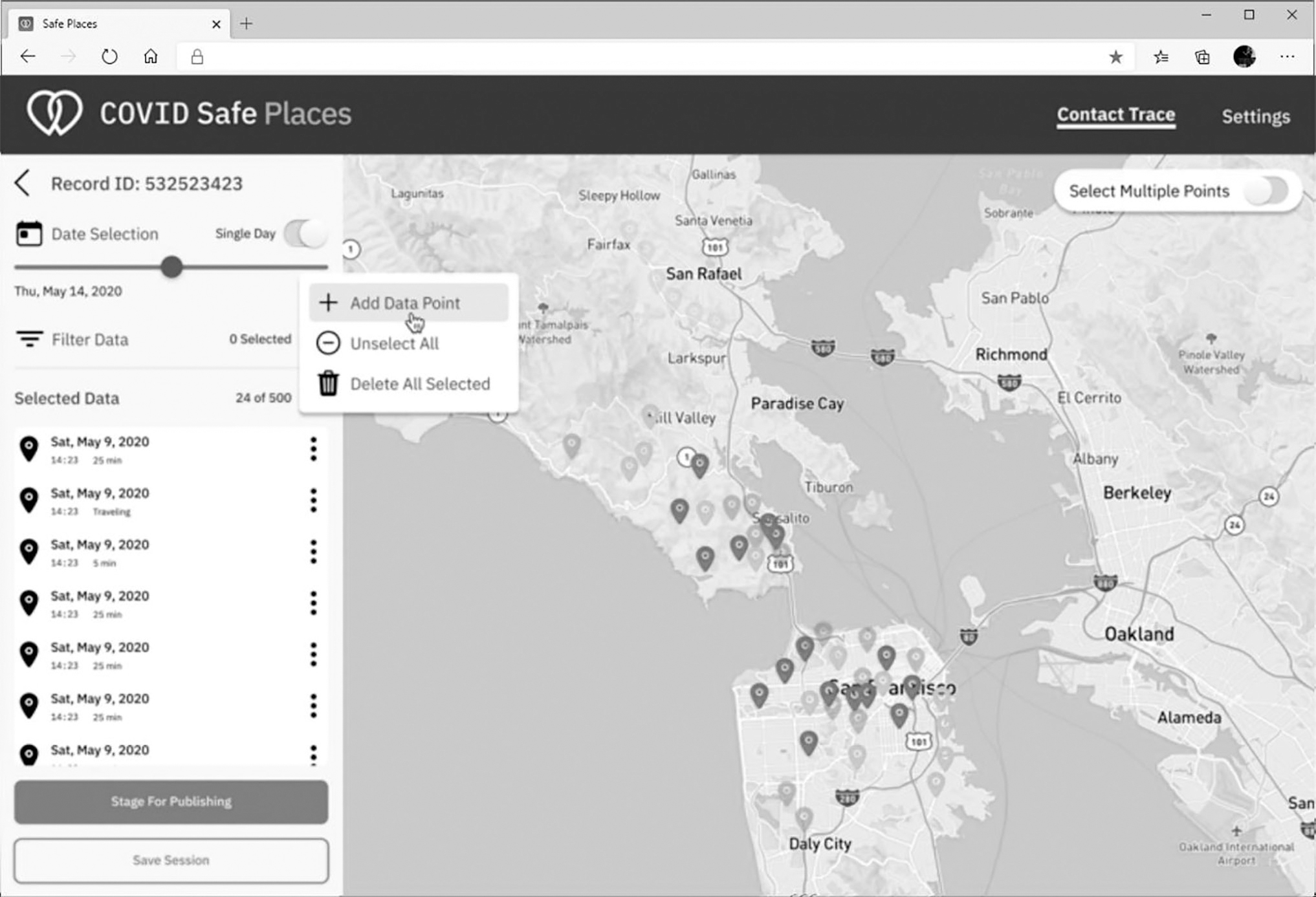
Our shift-right approach applied the digital twin semantic to represent historical location data of users who have experienced symptoms, are infected or have recovered. After developing the app, we created a model (shown on the left-hand side of Figure 7.6) of the mobile app (shown on the right-hand side).
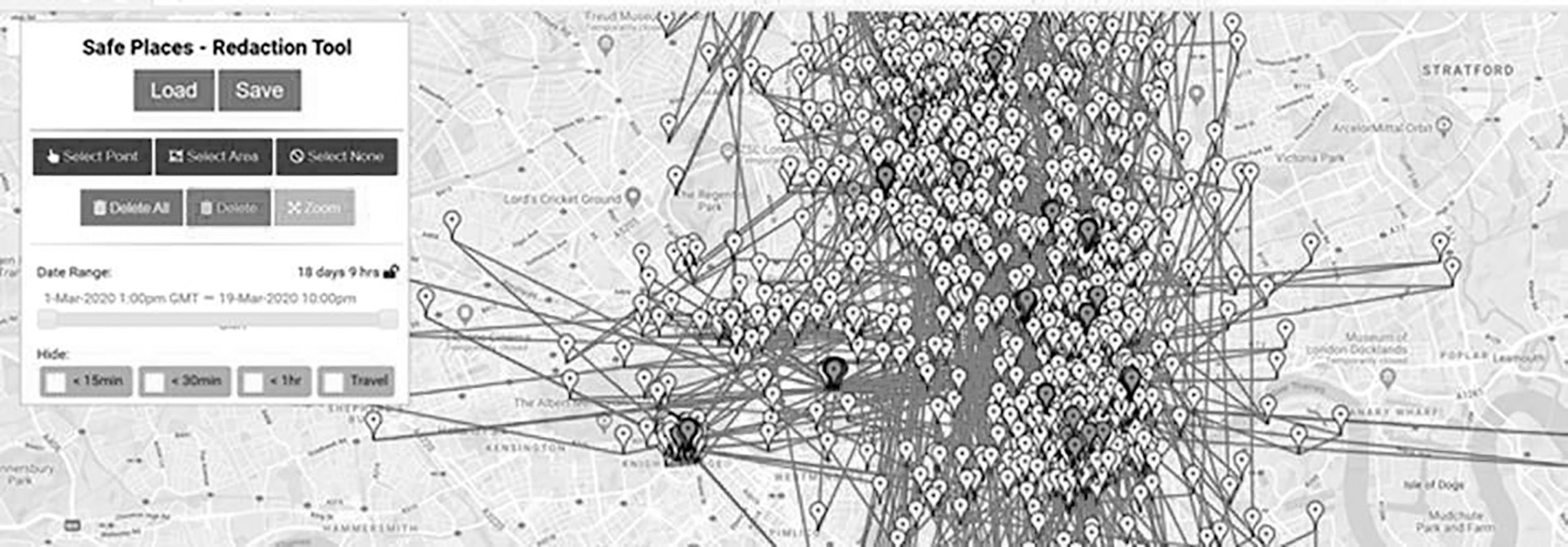
Now, let us say that people in London on a particular day are represented by pins as shown in Figure 7.7. The ones marked in the darker colour represent a person infected with COVID-19. There are relatively few darker dots. Some of these individuals may be driving in cars, taking the bus or self-isolating in their homes. Those driving in the confined space of their cars pose no risk of infecting a person outside the car until they get out of their car and go into an enclosed space, so the app does not necessarily need to trigger an alarm. The consequences of such false positives include people having to self-quarantine for no actual risk of infection.
This is where we can leverage machine learning to better understand real-world scenarios and differentiate between a darker dot representing a person driving a car at 6 mph, or a pedestrian walking at 3 mph, compared with someone sitting in a coffee shop in close proximity to other citizens.
By default, since 2017, every Android phone has been effectively tracking and capturing user locations every 5 minutes, whereas Google’s location services by default collect 650 data points of locations every 24 hours, resulting in 9,100 data points over a possible 14-day ‘incubation’ period. It was important to follow a privacy-first approach for our project, which involves the editing out of any personally identifiable data (Collins, 2017). GCHQ and the NHSx app came under fire during field testing of the mobile app on the Isle of Wight; they had been using Google Firebase and telemetry data from real users, thereby highlighting data privacy concerns (Ward, 2020).
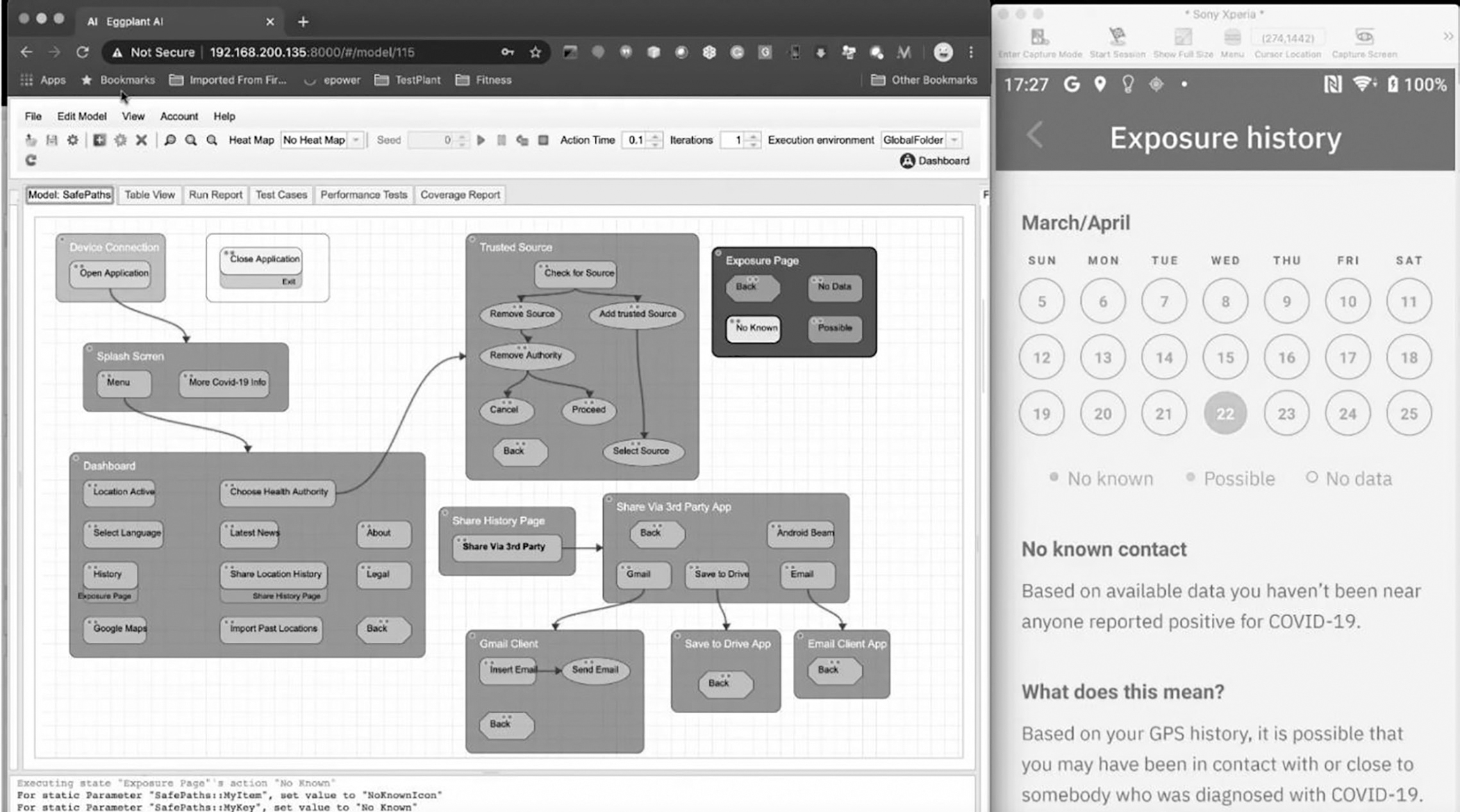
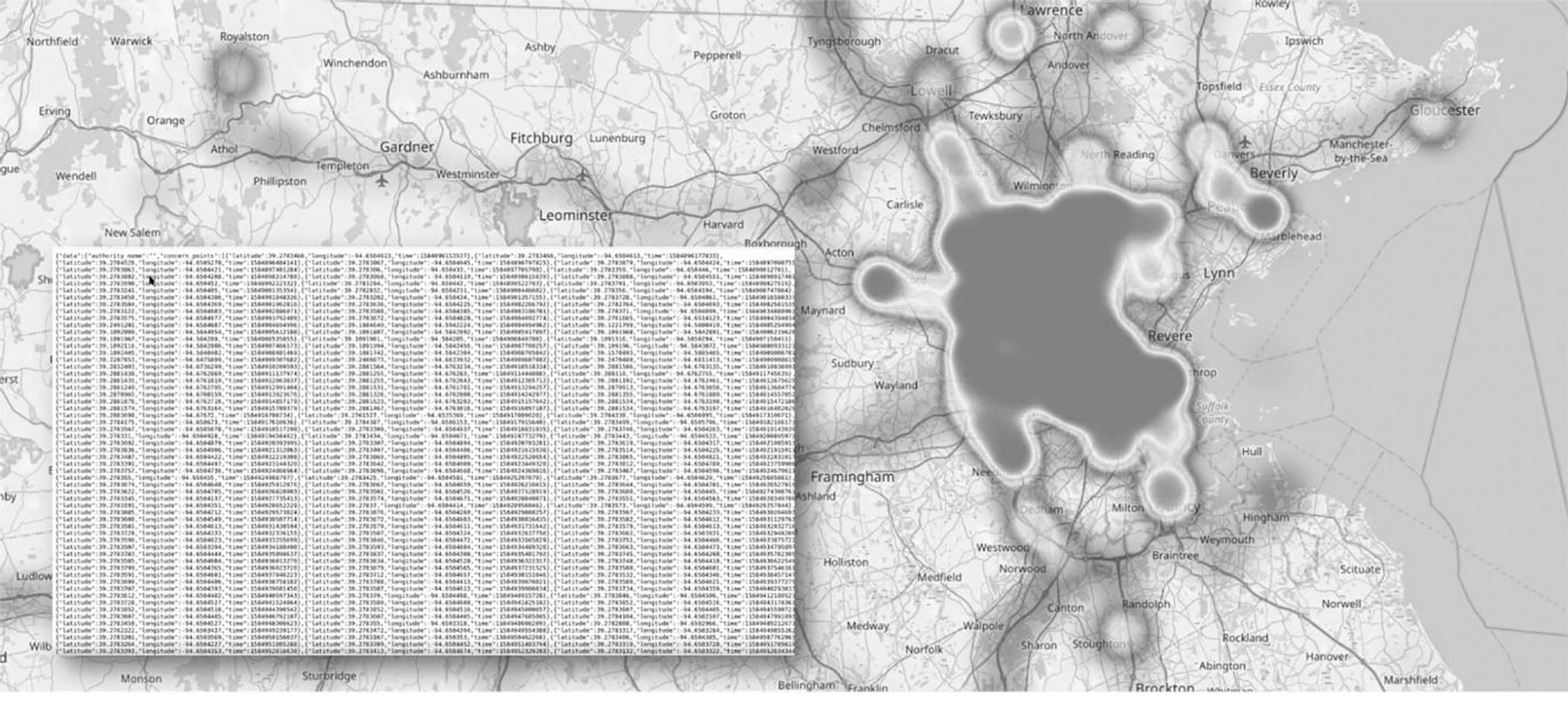
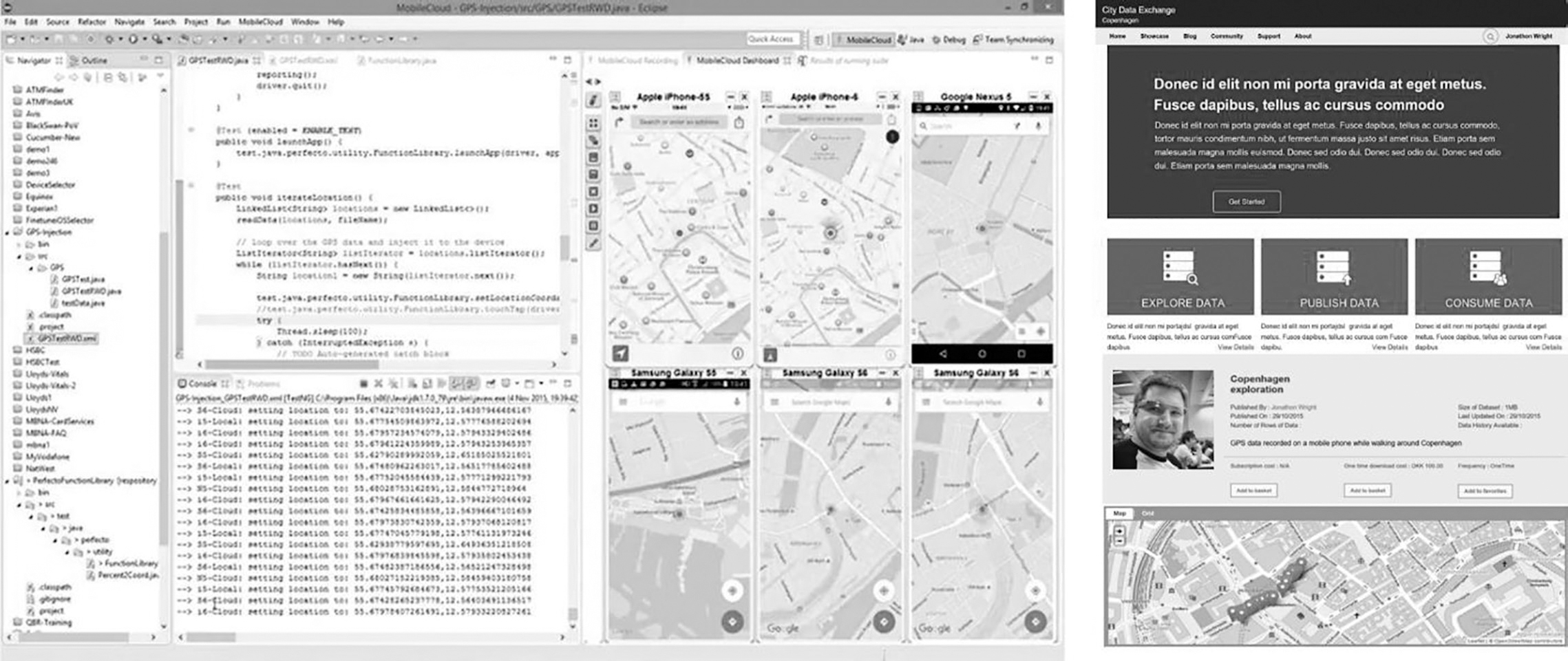
By exporting location data from Google Takeout, we were able to obtain the historical GPS data of Android devices (GPS location data logs that are generally available for up to 10 years). The bottom left of Figure 7.8 shows the GPS coordinates. By utilising Google Takeout, we extracted Google users’ pre-existing location data to find out what had been happening in the real world. Obtaining GPX (GPS Exchange format) data from hundreds and thousands of users constituted enough big data to warrant the creation of a data lake.
Applying cognitive engineering, we took this data lake and integrated machine learning, AI and deep learning technologies to process the structured GPX data based on schema-based generation (randomised algorithms) and neural networks (natural language processing, generative models) to maintain the statistical properties of location data and to synthesise realistic test data cubes. By using the synthetically generated data and injecting the GPX dataset from the model-based data scenarios into hundreds of real devices, the behaviour of each device exposure notification status could be observed.
Testing the COVID-19 contract tracing platform
Digital experiences (DX) are when user behaviours are combined with digital interactions. This approach enabled us to better understand what changes need to be made to optimise the user experience of information systems and applications. Within the context of this book, another way to say this is that we can learn from the real world, or the ‘right-hand side’ (an already available application or information system), and the user interaction information can be fed to a model (a digital twin of the real application).
The MIT project was next launched in Berkeley to help the health officials with contact tracing (Figure 7.9). For it to be successful, we needed real data inputs from people as we could not emulate historical user data. This is an example of where combining crowd testing and the shift-right approach was the best option to successfully test the solution in production.
CASE STUDY: SMART CITY DATA EXCHANGE – TESTING IN THE METAVERSE
There were a number of similarities between the approaches used for the Copenhagen Smart City Data Exchange and the MIT contact tracing initiatives. The biggest challenge in both projects was the ability to synthetically produce billions of historically accurate position data points and inject location data into GPS in real time.
The Smart City Data Exchange in Copenhagen used location data to help digital citizens become carbon neutral by 2020 (Figure 7.10). A smart city mobile app was rolled out to 38,000 people living and working in Copenhagen.
Metaverse concept applied to testing in the real world
Metaverse is blurring of the boundaries between technology (i.e. software and physical hardware) and the real world (originating back in 1992 in Neal Stephenson’s novel, Snow Crash).
As demonstrated in my 2017 TED talk on Cognitive Learning (Figure 7.11), the use of augmented and mixed reality (AR/MR) headsets from Google, Apple and Meta (Zuckerberg, 2021) (previously Facebook) overlaid metadata enabling DX interactions with the real world to create a digital-world-that-actually-mirrors-our-own and offering unprecedented interoperability of data and cross sharing through non-fungible tokens (NFTs).
A non-fungible token is a unique digital identifier that cannot be copied, substituted, or subdivided, that is recorded in a blockchain, and that is used to certify authenticity and ownership (as of a specific digital asset and specific rights relating to it) (Merriam-Webster, 2021).
Figure 7.11 TED talk: Cognitive Learning – ‘Digital Evolution, over Revolution’, 2017

The challenge with testing within the metaverse is the ability to identify multi-modal modes of transport used by the citizen in the physical world. These ranged from walking (2–3 mph), cycling (10–12 mph), taking the bus (stopping at various locations), taking the train, or taking the Tube (which can stop recording GPX data at one location and show up at another place). Each mode had a unique footprint that would need to be cross-referenced to identify the type of transportation used.
Going back to the COVID-19 project scenario, we already have the historical data from the mobile devices about where people are most likely to be gathered and the paths they have taken. Therefore, we can predict when and where people are going to be, for instance gathered around a certain area based on historical data. For example, during weekends, there are going to be a lot of people going to the beach; during weekdays there are going to be a lot of people using the commuter services around morning and evening rush hour time. In this way, we can predict where congestion is most likely to occur based on the behavioural data of a lot of people.
This is the same idea behind incorporating machine learning technologies within AIOps with predictive capabilities, by using historical data leveraging time series data.
AIOps uses artificial intelligence to simplify IT operations management and accelerate and automate problem resolution in complex modern IT environments. Such operations tasks include automation, performance monitoring and event correlations, amongst others (IBM Cloud Education, 2020).
SHIFTING RIGHT INTO THE METAVERSE
It is not uncommon to be awed by the user experience we get from our devices, whether we are using a smartphone, a tablet or any electronic gadget for that matter. This is no different when it comes to applications or information systems. We all like a very user-friendly, rich user experience when we interact with these devices.
However, we are moving further away from pure user experiences (UX) to fully immersive DX. For example, using your mobile phone or smart glasses while on a sightseeing walk, any photos taken are automatically uploaded to the metaverse. Your smart device likely also has associated metadata of GPS location, number of steps you have taken, identity of what was captured, and may even convert your digital media pictures, videos or audio into NFTs, which could be traded and sold on digital marketplaces on a digital ledger like blockchain, all thanks to next generation cognitive engineering capabilities such as computer vision, natural language processing (NLP) and machine learning built into physical edge artificial intelligence-enabled endpoint devices.
If we look at a few examples of how these structured data has been used by platforms to enrich user experiences, such as asking Alexa a question, we are interacting with the device using voice commands and the device is talking to many platforms to find the solution to our inquiry, giving us suggestions based on our likes and dislikes. Video streaming services such as Amazon Prime and Netflix, for instance, might suggest a movie to us based on a movie we watched or an actor we have been interested in recently.
These are all happening without our direct interference, to the betterment of the user experience. Now, imagine hundreds of millions of devices being carried by people on a single day and the amount of such unstructured data gathered from the user experiences. These unstructured data may be rendered useless until they have been extracted, transformed or loaded (ETL) into structured formats or associated metadata, utilising something like a schema registry or knowledge graph to become more context sensitive.
Gamification, permutations and lessons from Pokémon Go
Going back to the MIT COVID-19 project, user data are based on actual user interactions, that is, real people moving around in the real world with their smart devices. When it comes to a pandemic, using real human beings to gather GPS and Bluetooth information to test an app is not the safest idea because of the risk of these participants getting infected.
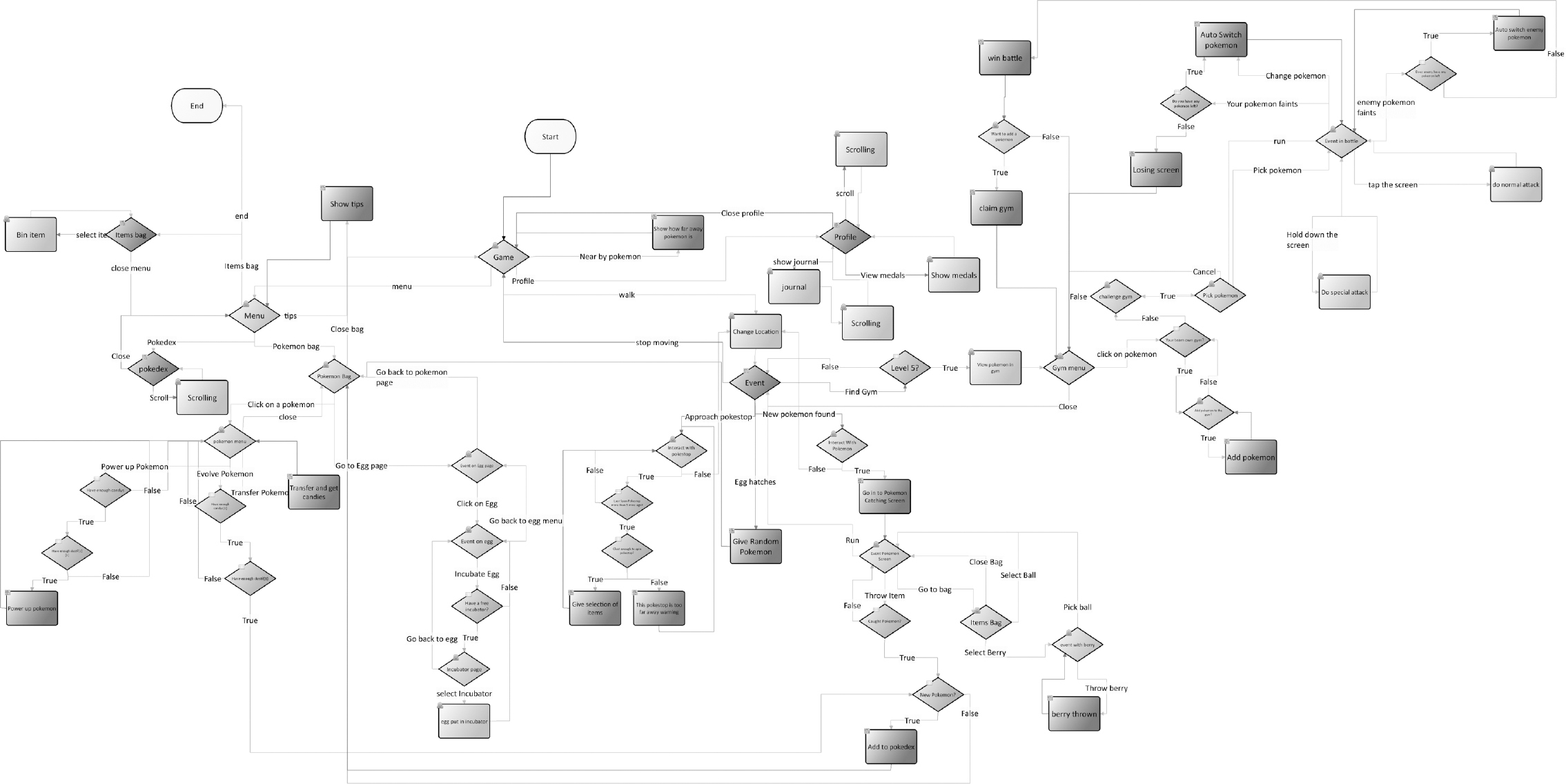
Instead of having real people, we could use location data and inject the locations to simulate visiting those places without having to go there. This is similar to the way people managed to cheat the GPS location-based mobile game Pokémon Go. This game is a fantastic example of augmented reality, gamification and the metaverse as it was intended to be played by the players physically going to places in the real world, unlocking location and time sensitive achievements and catching the Pokémon scattered around the globe.
In Figure 7.12 you can see the Pokémon example utilising model-based testing (MBT). Again, using a similar approach to testing the metaverse, we could magically appear to be at all the physical locations without having to actually be at any of them. This was achieved by combining location data with Google Street View to simulate the camera feed and catch the Pokémon by emulating gestures and digital interactions within the metaverse through augmented reality.
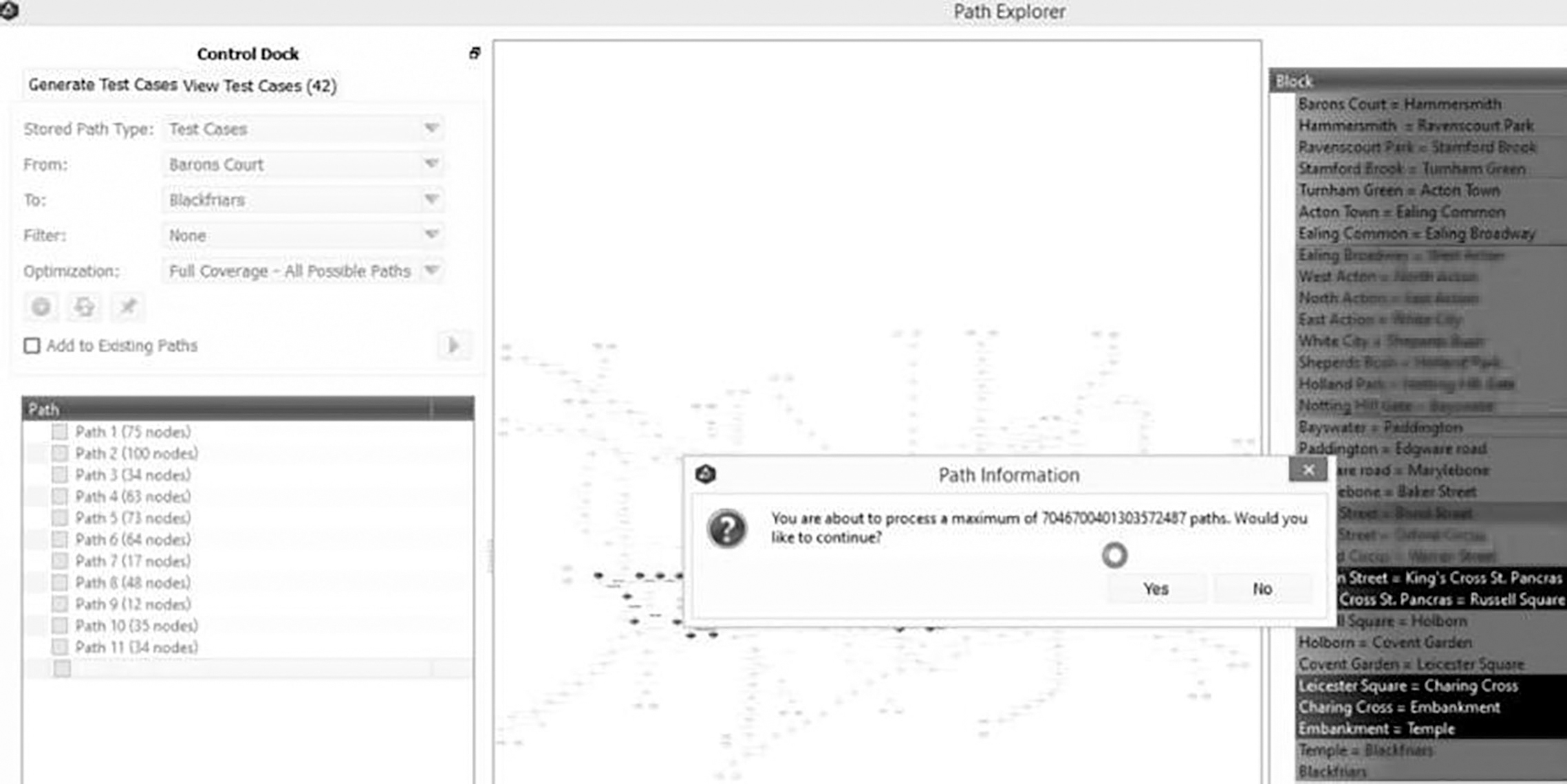
If we assume that we want to go from a point A to a point B in the real world, we have a lot of possible routes to take us to the destination (see Figure 7.13 for possible paths on the London Underground). Considering as many possible real-world variables and their permutations, such as if a person is walking, driving in a car or taking the bus or train, we can simulate near infinite possible digital experiences without physical effort or risk.
EVOLUTION, OVER REVOLUTION
Human advancements have brought about many revolutionary changes, starting from the first generation of evolution that was the steam-powered revolution, through the second generation that was electric and fossil fuel-powered, into the third generation that is driven by computers, electronics and telecommunications, to the fourth generation, soon to be powered by artificial intelligence. Within these revolutions, design disciplines used for developing computer systems and software have also seen a lot of change over the last few decades.
Back in 1939 Hewlett and Packard spearheaded the design principles used in developing computer systems. The waterfall method is a very linear process and was used to organise the manufacture of hardware products long before it was re-utilised to design software and information systems. Industry moved on, to more iterative methodologies. In the 1960s EVO (short for Evolutionary Project Management) introduced iterative development was first published in 1976 by Tom Gilb, followed by the widely adopted Agile Manifesto, which is now the most common method used in many industries. Although advances have been made in the design and test principles, the learning curve has largely remained on ‘shifting left’.
Cognitive learning, on the other hand, is a shift-right emphasis, complementary to conventional shift-left ‘design and solution thinking’ principles such as LeanUX.
We can also greatly benefit from the recent advances made in fields such as machine learning, artificial intelligence and deep learning, incorporating them into modern day software design and testing of information systems to deliver robust results within rich digital experiences, like the metaverse.
Moving forward, utilising disciplines such as ‘shifting right’ to introduce ‘failing fast and learning rapidly’ feedback loops from real-world user journeys and digital experiences, together with the help of machine learning, will help us to predict problems with software and systems being designed and tested.
We will also be able to rapidly change the design and validate the digital twin of the system or software based in real time. Digital experiences such as the metaverse, which blur the boundaries between the real world and technology, can be also tested based on predicted outcomes through cognitive learning capabilities only made possible by machine learning and AI.
SUMMARY
To reduce the massive upfront development work normally associated with introducing a new software system or solution, in the future we can opt for more rapid prototypes of concepts and the evolution of these ideas. Learning from what is going on in the real world and applying this feedback by shifting right will spearhead this ‘Evolution, Over Revolution’.