
This chapter explains the principles of the centralized mode and how to work in this mode using Bazaar.
The centralized mode assumes one or more central branches, where collaborators share write access, and require the commit operations of all the users to be synchronized. This is the basic workflow enforced by centralized version control systems. This mode of operation is widely used today in many projects, and it is often preferred in corporate environments.
Although Bazaar is distributed in nature, it includes features to fully support the classic centralized mode. With Bazaar, you can switch in and out of the centralized mode at any time, and implement sophisticated workflows using both centralized and distributed elements.
The following topics will be covered in this chapter:
- The centralized mode
- Using Bazaar in the centralized mode
- Working with bound branches
- Working with multiple branches
- Setting up a central server
- Creating branches on the central server
- Practical use cases
In the centralized mode, multiple users have write access to one or more branches on a central server. In addition, this mode requires that all commit operations be applied to the central branches directly. This is in contrast with the default behavior of Bazaar, where all commits are local only, and thus private by default.
In order to prevent multiple users from overwriting each other's changes, commits must be synchronized and performed in lock-step—if two collaborators try to commit at the same time, only the first commit will succeed. The second collaborator has to synchronize first with the central server, merging in the changes done by others, and try to commit again. In short, a commit operation can only succeed if the server and the user are on the same revision right before the commit.
First, we will learn about the core operations, advantages, and disadvantages of the centralized mode in a general context. In the next section, we will learn in detail how the centralized mode works in Bazaar.
The core operations in centralized mode are checkout, update, and commit:
- Checkout: This operation creates a working tree by downloading the project's files from a central server. This is similar to the branch operation in Bazaar.
- Update: This operation updates the working tree to synchronize with the central server, downloading any changes committed to the server by others since the last update. This is similar to the pull operation in Bazaar.
- Commit: This operation records the pending changes in the working tree as a new revision on the central server. This is different from the commit operation we used in the earlier chapters, because in the centralized mode, the commit must be performed on the central server.
Bazaar supports all these core operations, and it provides additional operations to switch between centralized and decentralized modes, such as bind, unbind, and the notion of local commits, which we will explain later.
Since the centralized mode requires that all the commits be performed on the central server, it naturally enforces a centralized workflow. After getting the project's files using the checkout operation, the workflow is essentially a cycle of update and commit operations:
- Do a "checkout" to get the project's files.
- Work on the files and make some changes.
- Before committing, update the project to get the changes committed by others in the meantime.
- Commit the changes and return to step 2.
Given the central repository with its branches, the first step for a collaborator is to get the latest version of the project. Typically, you only need to do this once in the lifetime of the project. Later on, you can use the update operation to get the changes that were committed by the other collaborators on the server:
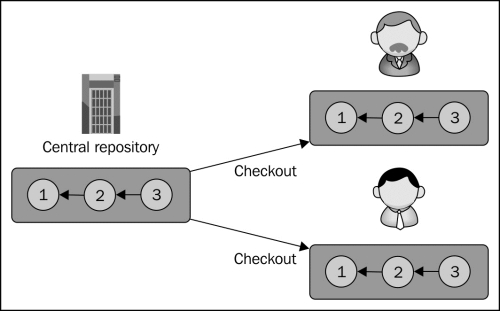
As a result of the checkout, collaborators have their own private copy of the project to work on.
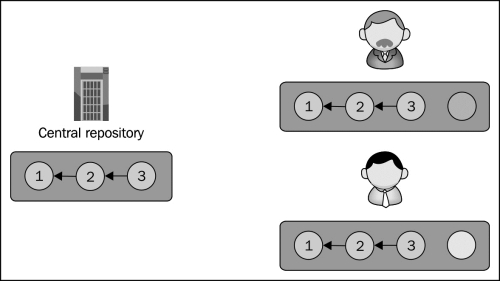
Collaborators make changes independently in their own working trees, possibly working on copies of the same files simultaneously. Their environments are independent of each other and of the server too. Their changes are local and typically private until they commit them to the repository:
Commit operations are atomic—they cannot be interrupted or performed simultaneously in parallel. Therefore, collaborators can only commit new revisions one by one, not at the same time:
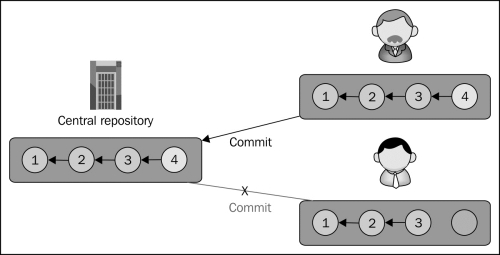
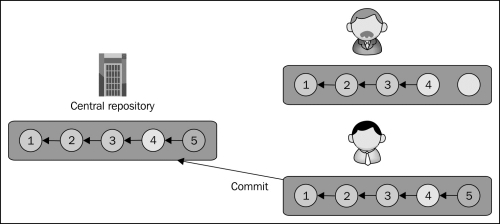
If two collaborators try to commit at the same time as in this example, only the first one will succeed. The second one will fail because his copy of the project will be out of date as compared to the server, where another revision has been added by the other collaborator. At this point, the second collaborator will have to update his working tree to bring it to the latest revision, downloading the revision added by the other user who succeeded to commit first.
The update operation brings the working tree up-to-date by copying any revisions that have been added on the server since the last update or checkout. If there are uncommitted changes in the working tree, they will be merged on top of the incoming changes:
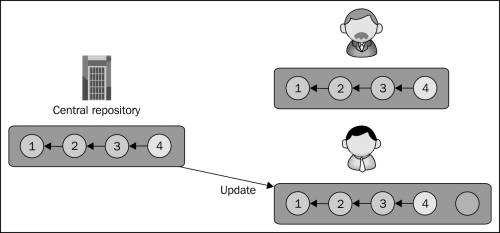
After the update, the local branch will be on the same revision as the server, and now the user may commit the pending changes:
When there are pending changes in the working tree, the update operation will try to rebase those changes on top of the incoming revisions. That is, the working tree is first synchronized with the server to be on the same revision, and after that the pending changes are applied on top of the updated working tree.
Similar to a merge operation, if the pending changes conflict with the incoming changes, the conflicts must be resolved manually. Since there is no systematic way to return to the same original pending state, the update operation can be dangerous in this situation. The more pending changes and the more time has elapsed since the last update or checkout, the greater the risk of conflicts.
The centralized mode has several useful properties that are worth considering.
The concept of a central server, where all the changes are integrated and the work of all collaborators is kept synchronized, is simple and easy to understand. In projects using the centralized mode, the central server is an explicit and unambiguous reference point.
Since all the commits of the collaborators are performed on the central server in lock-step, the independent local working trees cannot diverge too far from each other; it's as if they are always at most one revision away from the central branch. In this way, the centralized mode helps the collaborators to stay synchronized.
The centralized mode has several drawbacks that are important to keep in mind.
Any central server is, by definition, a potential single point of failure. Since in the centralized mode all commits must go through the central server, if it crashes or becomes unavailable, it can slow down, hinder, or in the worst case completely block further collaboration.
When multiple users have write access to a branch, it raises questions and issues about access control, server configuration, and maintenance:
- Who should have write access? An access control policy must be defined and maintained.
- How to implement write access of multiple users on the central branches? The central server must be configured appropriately to enforce the access control policy.
- Whenever a collaborator joins or leaves the project, the server configuration must be updated to accommodate changes in the team.
- Whenever the access policy changes, the server configuration must be updated accordingly.
The centralized mode heavily relies on an inherently unsafe operation—updating the working tree from the server while it has pending changes. Since the pending changes are, by definition, not recorded anywhere, there is no systematic way to return to the original state after performing the update operation.
When collaborators work on different topics in parallel, if they continuously commit their changes, then unrelated changes will be interleaved in the revision history. As a result, the revision history can become difficult to read, and if a feature needs to be rolled back later, the revisions that were a part of the feature can be difficult to find.