
This chapter explains the common distributed workflows and how to implement them using Bazaar. Distributed workflows are suitable for projects of any size, and these are the only workflows that are scalable enough to use in very large projects.
Distributed workflows are essentially about organizing branches in a certain way, and naturally involve a lot of branch operations. If you have a good understanding of the various branch operations, especially the techniques covered in the previous chapters, then there should be no big surprises for you here. The techniques in this chapter should serve as new practical examples of working with branches, further solidifying your knowledge.
The following topics will be covered in this chapter:
- Using a human gatekeeper
- Using an automatic gatekeeper
- Using a shared mainline
The essence of the distributed workflow is that collaborators don't have write access to a common central branch or to each other's branches. They only have write access to their own branches, and can propose those branches to others to merge from, and likewise, they can merge from the branches of others.
In their most primitive form, the branches of collaborators simply evolve in parallel, each collaborator working independently, occasionally merging from another collaborator; for example:
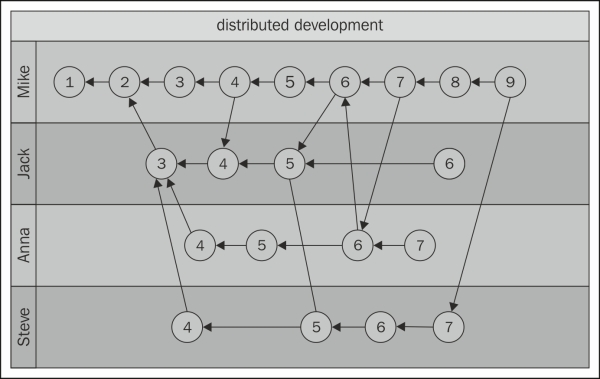
The arrows in this graph represent child-parent relationships, child revisions pointing to one or more parent revisions that they were derived from. All collaborators can only commit in their own branches. They cannot write to the branches of others, and can only share and propose their own branches for merge. That's the only way to get one's work into other users' branches.
The graph does not identify any of the branches as central, and indeed there is no central branch. Development takes place in a distributed manner, with no clear "official" branch. However, and especially, as the number of collaborators grows, the need for designating a branch as the mainline emerges. After all, without an "official" branch, it is impossible to know which branch to use as the base when starting a new development, for example, when a new member joins the team.
Designating a central branch does not require any special setup. It is only a convention, ideally explained in the project's documentation or website, not a hard rule. The only technical requirement of a mainline branch is simply that it should be accessible by the intended audience.
Ideally, the mainline branch should be a branch which has merged much of the work done in all the other branches, something stable, mature, and well-maintained. In this example, Mike's branch seems a good choice, as it has merged most of the revisions, though not all, from all the other branches. However, such a branch remains the mainline only as long as it is well-maintained, regularly merging the work that is being done in other branches.
The challenge in a distributed collaboration is bringing all the work going on in the various branches together into the mainline branch of the project. That said, there is nothing really difficult or complicated about this, and it can be accomplished easily by using the usual branching and merging operations. Doing so is not a technical issue, but more about good organization and communication between the members.
The graph of branches and revisions in the preceding example is the most primitive form of a distributed workflow. We can barely call it a workflow—it is a jumble of branches, with no apparent system or organization, and no mainline branch. Essentially, this is a peer-to-peer workflow—the team members are completely free and independent, they merge from each other whenever they want. This working style is not scalable if there are sufficiently many members in the project. The goal of distributed workflows is to organize the branches in such a way that it makes good, logical sense.
There are many ways of organizing branches in a distributed workflow; the most suitable method depends upon the project and its members. We will introduce some common techniques that you can use as they are, or as a baseline to build more suitable solutions depending upon your use case.
Before we get into the details of specific techniques, let's clarify some of the main principles of the distributed mode in general.
First and foremost, all collaborators work independently; their workspaces are physically disconnected from the mainline and other collaborator branches. They can implement any workflow locally in their own workspaces and use as many branches as they want.
Collaborators can share their work with each other in an ad-hoc manner if they want, by publishing their local branches at some location where others have read access. This can be accomplished by pushing selected, or all branches to a central repository server, an SSH server, a web server, a shared folder on the local area network, or just about any other way that permits read access to the intended audience.
The ultimate purpose of all the work done in the independent branches is to merge back into the mainline development, or release branches, and thus become easily accessible as a part of the official version of the project.
Even in distributed workflows, typically there are one or more mainline branches that are commonly understood and accepted as the official version of the project. Having an official mainline branch makes good sense, as it makes the workflow easy to understand, and it can serve as the starting point for new development branches.
However, a branch being "the mainline" is just a convention. In terms of technical details and configuration, it is no different from any other regular Bazaar branch. The mainline is the mainline simply because the drivers of the project agree that it is. Any other branch can become the mainline, if necessary. For example, in an open source project if the current mainline branch becomes unmaintained or disputed, then another branch that is better maintained can emerge as the de-facto new mainline.
In short, distributed workflows have central branches too just like in a centralized workflow. They give great flexibility to collaborators, but the end result is the same—collaborator branches get merged into mainline branches, enriching and driving forward the project.
In distributed workflows, collaborators have write access only to their own branches. This greatly simplifies access control—there is no need to configure and maintain access control. Only a single person has write access to any branch. Access control cannot get simpler than that.
Branches can be made visible to others for collaboration or sharing, but there is really no need to give write access to anybody else other than the branch owner.
In order to get their work into the mainline branches, collaborators propose their branches for merging to maintainers of the mainline. Alternatively, it is possible to create merge directives, which can be sent by e-mail and are very similar to, but much more powerful than, conventional patch files.
In distributed workflows, there are no technical restrictions with regard to the method of sharing work. A distributed version control tool doesn't get in the way—collaborators are free to use it in whatever way in their local workspaces, their work ultimately culminating in a branch to propose for merging into the project's mainline.
Whether a branch is fit or not to merge into the mainline is never a technical issue. If the work is good, there are many ways in which it can be merged into the mainline, with proper tracking of the revision history and attribution to the original authors.
Many technical issues inherent in centralized workflows simply don't exist in the distributed mode, such as the hassle of configuring access control, the dangers in update operations, or having a single point of failure. Having fewer technical rules and restrictions, the distributed workflow is more simple, easier to set up and maintain, and much more scalable.
Since collaborators cannot write to each other's branches, the only way to get your work into the branch of another collaborator is by convincing him to merge from your branch. If the proposed branch is about a single feature, bugfix, or other specific improvement, merging it should be relatively easy. However, if the branch contains a mix of unrelated changes, then the merge proposal is likely to get rejected because it is unclear and confusing. As such, distributed workflows naturally encourage the use of feature branches.
Feature branches keep the history clean and well organized by grouping related changes together. In this way, you can read the merge commits of feature branches as the large steps in the evolution of the project, and you can always drill down to the individual commits to see the full details. For example:
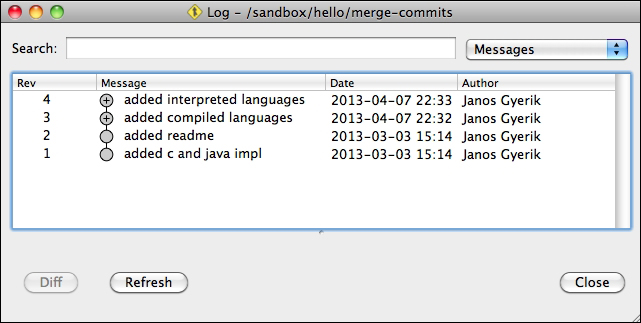
The same history with merge commits expanded looks similar to the following screenshot:
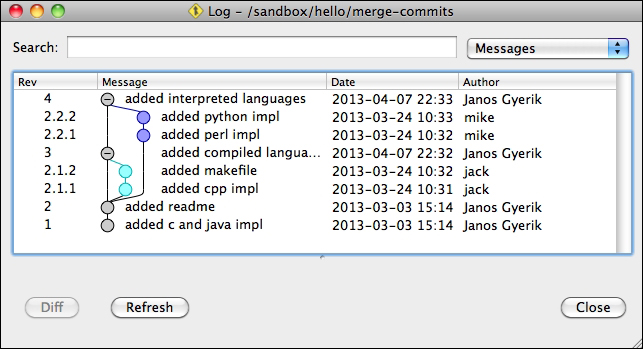
This also makes rolling back an entire feature trivially easy, by reverting the single commit that merged the feature branch.
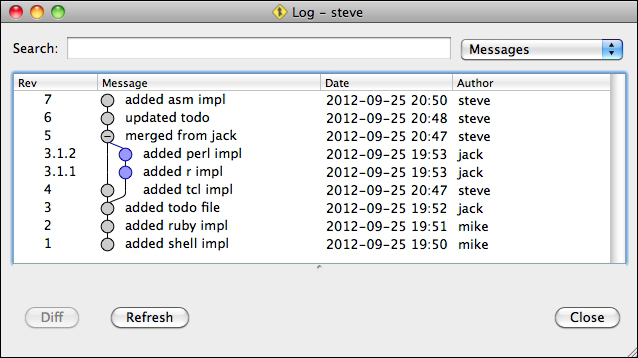
It is a somewhat minor, but sometimes important detail to remember that the graph of the revision history may depend on the perspective of each collaborator. When looking at the revision history of a branch, revisions added by the owner are called mainline revisions, revisions merged from other branches are called merged revisions. Mainline revisions are numbered with increasing integers, while merged revisions are numbered using a dot notation.
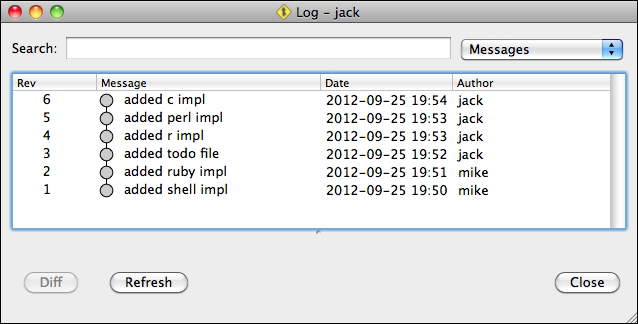
In the preceding example, Jack's view of the history is the most simple—he never merged from other branches. Thus his view of the history is basically a straight sequence of revisions following one another:
Steve has merged Jack's revision 4 and 5. Therefore, in his view of the history these show up as merged revisions renamed as 3.1.1 and 3.1.2, respectively:
Mike's perspective is even more complex, as he merged from all other branches:
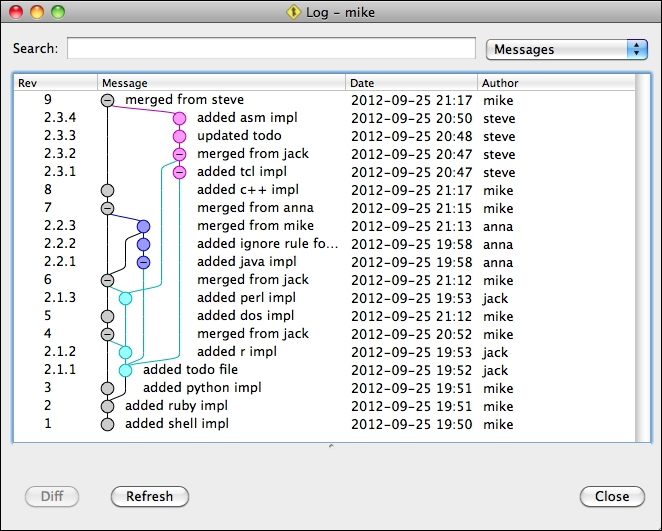
If we create a new branch from Mike's at revision 2.3.4, we get a perfect clone of Steve's branch, and therefore the same perspective as his. In this case, revisions 2.3.x are renamed to 4, 5, 6, and 7, naturally, as they are mainline revisions in Steve's branch.