
While operations keeps the services afloat and maintains status quo, for a service or a product to stay alive, barely surviving is far from enough. It needs to change, it needs to evolve, and it needs to transform. Without changes, a service or a product is as good as dead. Think of a service or a product that have stayed the same for a number of years. Hard, right? Impossible to name a couple? Yes, that’s true. Even a simple product like the day to day confectionaries changes because customers get bored and crave something new. Think about the avatars of Haribo or any of your favorite chocolates. Very few have stayed the same, and they keep the change constant. One other anomaly in this regard is “classic” coke. Although the old made way for the new, popular demand meant that the company had to bring the old formula back to revive the fortunes of the company.
Coming back to the products and services in IT, anomalies are rare to extinct. Every product or a service can survive by introducing improvements and making it better with every release. But bringing in the new and discarding the old cannot be done like we junk our old television sets. There needs to principles, processes, practices, and procedures to make it happen. After all, there will be several users who are accustomed to using products and services in a certain way, and change for them is going to be painful. Not only from the user perspective, changing a service must ensure that disruption from change is nil to minimal. Although the desire to change is high on the requirement index, the appetite for taking risks with service uptimes and availabilities is quite low. So, we need ITIL to provide a safe passage for changes to be done in the least disruptive manner, and here you go: this chapter deals with practices that manage change.
Service request management
Change control
In both practices, we shall delve deep to understand their nuances, and the expectation is that you get a good grip on both practices. From your career perspective, these practices are invaluable—especially change control. It is considered an equal next to the incident practice, and interviewers testing your knowledge of ITIL may start at incident management but will pass through or end at the change control practice.
Practices for managing changes is an important topic from the ITIL Foundation exam perspective. If you need to answer questions correctly, you need more than a cursory understanding of the topics. You can expect anywhere from seven to eight questions to appear from this chapter.
Service Request Management
ITIL Definition of Service Request Management Practice
The purpose of the service request management practice is to support the agreed quality of a service by handling all pre-defined, user-initiated service requests in an effective and user-friendly manner.
ITIL Definition of a Service Request
A request from a user or a user’s authorized representative that initiates a service action that has been agreed as a normal part of service delivery.
A customer can call a bank or use an online banking system to request a checkbook. The exhaustion of the previous checkbook is not considered as a service failure. Requesting a new one is a delivery that is agreed, and it gets done as per the predefined set of activities and predefined timelines.
You could call your company’s service desk and request open source software to be installed on your laptop. Installing software is a service, and as a user you are entitled to request it. Likewise, requesting a laptop, mobile phone, or a monitor are examples of service requests.
Suppose you need access to a portal; you raise a request to get the requisite access. This is an example of a service request as well. You are seeking something that you do not have, and you are asking for something that is already defined and you’re entitled to.
If you did not know how to get to the train station, you could call the people concerned and ask for information (directions in this case). The request for information is another example of a service request. The information could be anything that falls under the ambit of the services offered.
Finally, compliments, complaints, and feedback provided for the offered services or the people involved in offering it also fall under the service request definition.
The service request management practice was referred to as request fulfilment management in ITIL V3. In fact, it was called service request management back in ITIL V2. In my opinion, calling it request fulfilment didn’t go too well with companies, users, and practitioners, as the norm is that management of incidents is done through incidents and management of changes is done through change control. So why not service request management for managing service requests?
Service Catalog and the Confusion with Incidents
Service requests have to be predefined. A user cannot request something that has not been defined. They cannot call the service desk and say: “I want you to book a cab.” If booking a cab is not defined, then the team responsible for fulfilling service requests will not fulfill the request.
How does a user know what he can or cannot request? All the agreed and defined service requests are part of a service catalog. Generally speaking, the service catalog must be socialized with the user community so they know about services they can avail themselves of.
There was a time when incidents and service requests were put into the same bucket and treated similarly. I say this as though this practice does not happen anymore, which isn’t true. It still does, but the two sets of tickets are now better understood to define separate processes and manage them separately through their respective processes.
By clubbing incidents and service requests together, the service provider organization is doing gross injustice to those who have raised incidents, because incidents pertain to loss of service. And as we have established, service requests are not loss of service but rather getting something additional to what users already have.
The trouble with treating incidents and service requests the same is that the time taken to resolve incidents will go up. That leads to additional downtime, and generally a loss of service leads to productivity loss and hence financial losses. The implications from a service request are not on the same scale. Therefore, clubbing the two and not differentiating between them leads to higher service downtime and unhappy users, and it introduces inefficiencies in the system that are best avoided.
There is a practice called service catalog management, which delves into the processes and nuances of defining and managing the service catalog. However, the practice is outside the scope of ITIL Foundation.
Fulfilment of Service Requests
All service requests are predefined. In an ideal scenario, all the service requests are listed for the users to see. They can simply go in, select what they need, and submit it. For every service request, the steps required to fulfill it are well known, defined, documented, and proven to work. As they are predefined, it makes it much easier and straightforward to formalize them with standard operating procedures for initiating service requests, obtaining approvals, and to fulfill them.
- 1.
Request for a laptop
- 2.
Request for open source software to be installed
- 3.
Request for an experience letter from the HR dept.
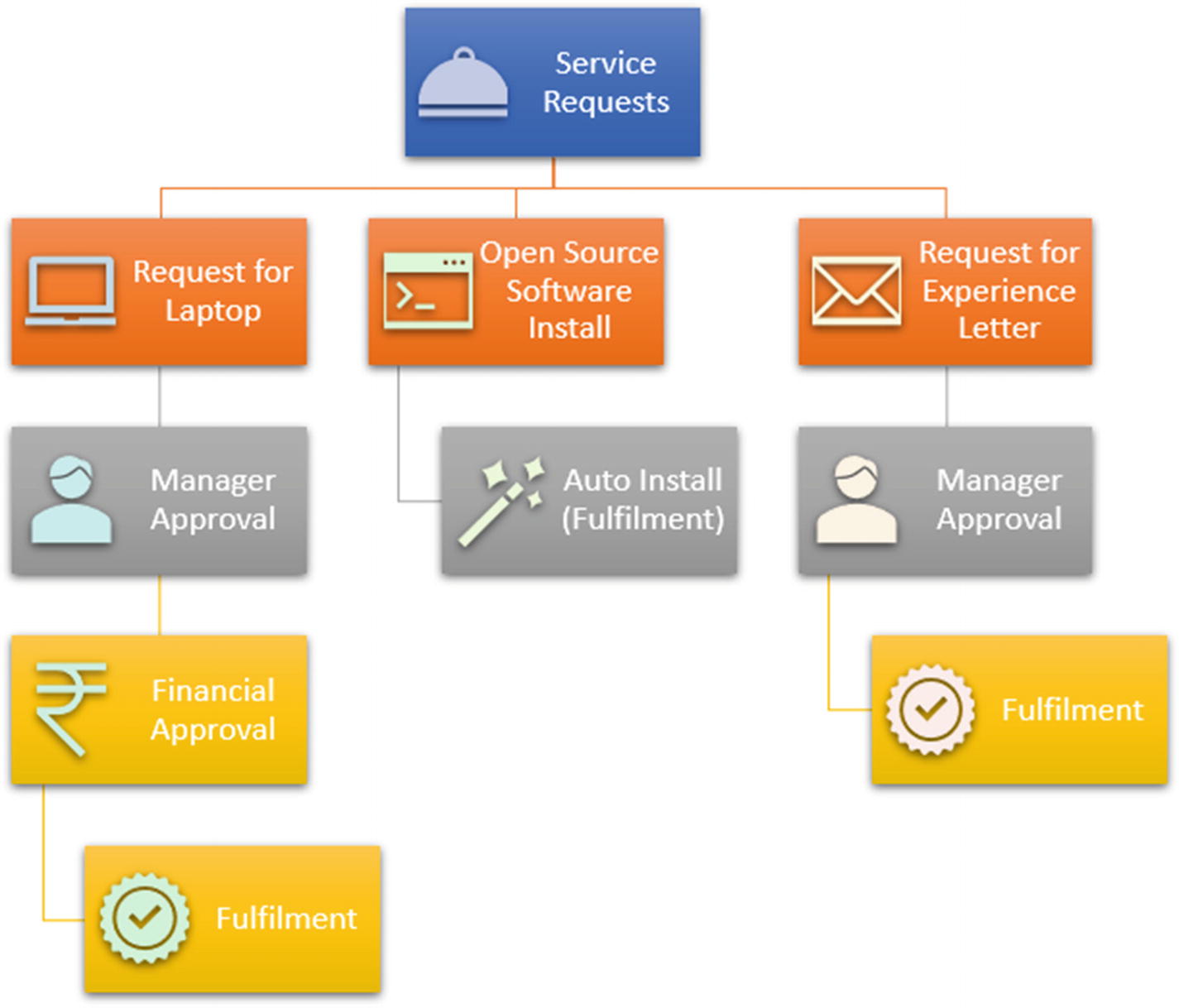
Fulfilment of service requests
Service Request Management in SVC
SVC Activity | Involvement | Details |
|---|---|---|
Plan | None | There is no engagement of the practice in the plan activity, due to its transactional and operational nature. |
Design and Transition | Medium | During transition, certain service assets could be moved into production on the back of a service request. |
Obtain/Build | Medium | Service assets and components for the lower environments could be obtained through the service request management practice. |
Engage | High | There is plenty of interaction between the practice and the user community in setting expectations and ensuring transparency of the hops and approvals. |
Deliver and Support | High | A good chunk of service delivery comes from the service request management practice. The fulfilment of service requests is an inherent part of this activity. |
Improve | Low | While service request management itself can go through the Improve churner, the practice is a medium for users to reach out to share complements, complaints, and improvement ideas. Many of these could be inputs to the Improve activity . |
Each of the service requests in this example follows a separate path. The laptop request has the most steps, as every request raised goes for a manager approval, and the next approval sought is a financial approval. Once the finance head clears the financial part of the request, the request goes to the team that allocates a laptop to the user.
In the next service request, open source software that is approved by a company for general installation by its users requires no approvals; in fact, it does not require any humans to fulfill it. As soon as the user requests it, it gets autoinstalled through preconfigured scripts and software that pushes the software to PCs.
In the third example, an employee requests an experience letter from the company. The manager validates the details put forth by the employee and provides the approval. The request flows to the HR dept., which fulfills it. Alternately, software could sit behind the service request that can automatically draft and deliver the experience letter after the approval.
In each of these examples, I wanted to highlight that the flow is different and the teams that are involved in fulfilment are most likely distinct as well. So each of these service requests would have a standard operating procedure written, along with clear instructions on what needs to be done at every step.
Generally, initiating service requests is best done through a portal where the user can authenticate and access the service requests that are available. For identifying a manager for the approval, systems generally access the HR database or an equivalent database that stores employee hierarchy. Financial approval and fulfilment teams are identified based on the business units and the type of fulfilment that the request seeks.
Service requests are a form of standard changes: the standard changes that are meant to service the user community. For example, a standard change for installing a security patch on a server is generally categorized as a standard change, and a software installation on a laptop as a service request. In principle, both follow the same set of guidelines: predefined, well known, and almost zero impact.
Guidelines for Implementation
- 1.
A clear boundary must be drawn through applicable policies that define the length and breadth of service requests. In other words, there must be no confusion about what qualifies as a service request, what is an incident, and what is a change.
- 2.
Every service request must be defined, and no shortcuts must be undertaken during the definitions phase.
- 3.
The service catalog must be made available to all users, preferably on a portal for users to choose from. For each of the service requests, the service levels associated with it must be defined, as well as the number of hops (approvals, etc.) that are involved.
- 4.
Service request flows must be standardized as much as possible unless certain service requests require special flows. For example, most of the service requests should be routed to the immediate manager for approval and not pick and choose managers, based on the service request type.
- 5.
There must be a conscious and sincere attempt made toward automating all the service requests that do not require human intervention. The example that I shared earlier of an experience letter is an excellent candidate for automation.
- 6.
The service request practice should come under the ambit of the Improve activity, where improvements can be introduced for increasing the effectiveness and efficiency of the practice.
Engagement with Service Value Chain
Change Control Practice
They say that change is the only constant. They also say that anything that does not grow withers away. This is so true in the IT industry. No matter how old the product or the service is, changes to it happen all the time. No matter how legacy the service is, it still needs to be maintained and made current to the organizational needs.
Changes are inevitable in any industry; therefore, the onus is on management. The question is not whether we make changes or not but rather how do we do it without impacting the product or service negatively.
It is also true that a majority of incidents are caused by mismanagement of changes. So, that is all the more reason that we need to tighten up the change management process to increase the overall uptime and reduce the number of outages.
ITIL Definition of Change
The addition, modification, or removal of anything that could have a direct or indirect effect on services.
A service is made up of various individual components; it could be servers, switches, software, middleware, mobile app, and networks. Changes done to any of these individual components or to the overall service itself constitute a change.
Change control is a popular topic on the foundation exam. You should likely see a question pertaining to the definition of a change appearing on the ITIL foundation exam. The question will center on identifying the right definition from a list of choices. So, it is prudent for you to understand and memorize the definition in verbatim.
Implementation of fiber optic Internet service to the customer organization
Transition of email services from Exchange to Gmail
Decommissioning of mainframe computers
Adding extra memory to servers
Changing ownership of a core switch
Adding an IP to a blacklist on firewall
Modification of a batch job
New version release of an iPhone app
Upgrade of an enterprise application
ITIL Definition of Change Control Practice
The purpose of the change control practice is to maximize the number of successful service and product changes by ensuring that risks have been properly assessed, authorizing changes to proceed, and managing the change schedule.
The change control practice exists solely to govern the changes to products and services. The objective of the governance is to ensure that the changes that go through are thoroughly vetted to ensure that all risks are known and mitigated, and to increase the probability of changes succeeding.
In IT as in life, nothing in guaranteed. So, any change proposed comes with associated risks. If an organization fears the effect of the risks and stops the changes in their tracks, then that organization will not improve their products and services and is doomed to fail. So, changes are necessary evils, and the art of change control is to control the changes to ensure that the beneficial aspects are amplified while minimizing risks through adequate mitigation actions.
For example, a bank’s online banking application has been upgraded using newer technologies and features. With over ten million customers, when the new application takes the incumbent’s place, any risk would have a profound effect. So how does the change control practice ensure that the risks are minimized? There are several options; one common option is to use a technique called canary testing. We release the application in parallel with the old application but for certain users only; say about 100 users agree to use the new version instead of the old. The new application gets used by its limited users and the chinks in the armor are detected and dealt with, before releasing the application to its entire user community.
The change control practice does not perform any of the technical activities, nor does it manage the technical activities. They are the gatekeepers of changes going into products and services. They ensure that adequate controls are in place, and when they are satisfied with the tests, approvals, and mitigations, they authorize changes to be implemented.
Scope of Change Control
ITIL per se does not specify the boundaries under which the change control practice is triggered for governing changes in the system. The actual scope definition depends on the service provider, the customer, and the suppliers.
An IT service can have multiple elements, including making use of the supplier’s network and data, among other dependencies. It is managed by IT professionals, and the service documentation also is critical. Does changing any of these peripheral components call in a change? Yes, but it depends on the agreement between the service provider and customer organization. Managing more items requires more time and resources, which adds to expenses. If the customer wants to have absolute control over the IT services, then yes, every single element that makes up a service must come into the purview of change control. In the real world, this is often not the case, owing to the financials. Many of the indirect components are ignored in the interests of reducing expenses, and some companies find innovative ways of controlling the peripheral objects using standard changes and service requests.
From my experience, there is much more to change control than addition, removal, and modification of IT services. Take the example of running an ad hoc report. You are not adding, removing, or modifying anything, just reading data from the database. Yet, you possess the power in your hands to break systems with the wrong set of queries that goes searching in each and every table, that utilizes the infrastructure’s resources, and could potentially cause performance issues to the IT service. In this case, if you bring this through to change management, they can possibly identify the resource-consuming queries and shelve them or schedule them to be run during off-peak hours.
- 1.
New or modified services, where functional requirements are changing, translating to resources and capabilities
- 2.
Management information systems (reporting and communication) and tools
- 3.
Technology and management architecture
- 4.
Policies, processes, and components derived from processes, such as templates, guidelines, etc.
- 5.
Measurement systems, metrics, key performance indicators (KPIs), and associated methodologies
The biggest success for a service provider comes from its scope definition of change control. And the best way is to synchronize the business goals and objectives with the services, and that to the scope of change control. What drives a customer and what is most critical to a customer need to be governed with utmost scrutiny. If the change control practice can do it, then the major battles would have been won.
Types of Changes
One size does not fit all the changes that happen in services. They come in all shapes and sizes. Therefore, you cannot use the same yardstick for all changes. You need a different set of protocols, policies, and processes to handle various types of changes. Say, for example, you trip over a water pipe and hurt your shoulder. You go to the hospital, and a doctor tends to you and does what is necessary with minimum fuss. Instead, if you were in a car wreck that required stitching you up and putting some dislodged organs back in their place, this process will require an operation, surgeons, an anesthesiologist, and nurses among others to be present, to ensure you survive and the operation is a success. Between the two instances, the processes carried out are expectedly different. One instance requires a host of professionals, utmost care, and some amount of planning, while the other can be done as and when needed with a basic medical skill set.
For the trip-over patient, you do not need to assemble surgeons and others. Likewise, in change management, some changes need to be done with proper attention, planning, and care, while others can be carried out with minimum scrutiny.
Normal changes
Emergency changes
Standard changes
For your organization, you can define as many types of changes as you need. ITIL is not prescriptive, so the types of changes serve at best as a guideline. I once worked for an organization that had a fourth type called an urgent change that was placed between a normal change and an emergency change
Normal Changes
Let’s say that a patient is ailing from a heart problem and needs to have open-heart surgery. The doctors and surgeons involved carefully and meticulously make all the plans, reserve the facilities, and then carry out the procedure. These are planned surgeries, and in the change control world, such changes that are planned in advance are called normal changes.
Most changes in any organization are normal changes, as no organization wants to make changes without proper plans in place. Such changes are often lengthy because of the planning sessions, stakeholder visibility, and approvals, and to ensure that all the dependencies are managed. In other words, they follow the entire process, which includes authorization, reviews, and scheduling.
Normal changes are generally associated with all the bells and whistles of the change control practice and are often well analyzed, tested, mitigated, and verified. The maturity of an organization’s change control practice is often measured through the normal change process, and the metrics and KPIs associated with it.
Normal changes will be associated with a priority to help focus on changes with maximum risk over others. For example, refreshing an Internet banking application will be a major change that would require the highest levels of reviews and assessments. Authorization will change authority and other dependent teams along with the customer organization review and approvals. Conversely, changing a configuration on an application to change a field from nonmandatory to mandatory will be done briskly with minimal stakeholder approvals.
Examples of normal changes include an application refresh to a newer version, a server migration from in-house to a cloud service provider, and the decommissioning of mainframe applications and servers.
All normal changes have to be registered; this is called a change request. They are logged on an ITSM tool such as ServiceNow. Then they go through the steps of prioritization, and based on the prioritization, the amount of scrutiny is decided. In the case of application of continuous deployment in a DevOps project, a single change request will be raised giving high level overview of the kind of changes that will be performed over a period. So in essence, for every change performed, there will be no new change raised. This will differ when the change is major.

Change model
Change Control Practice in SVC
SVC Activity | Involvement | Details |
|---|---|---|
Plan | Low | Making changes to plans—and its derivatives such as policies, processes, and frameworks—is governed by the change control practice. |
Design and Transition | High | When there are design changes to products and services, or when new products and services are introduced, changes are created to bring them into production. The majority of the change transition activity is run on the back of a change ticket. |
Obtain/Build | High | Products and services that are developed go through the change control practice to become operational. |
Engage | Low | Some changes may call for an engagement of customers, suppliers, or users in providing oversight for changes or taking a place in the change authority. |
Deliver and Support | High | It is no secret that changes are one of the primary sources of incidents, leading to increased deliver and support activity. And resolution of incidents and problems piggybacks on change control for implementation. |
Improve | High | Improvements that are recommended go through the change control practice for vetting against risks and to weigh the benefits against the depth of changes being introduced. |
A change model is a repeatable way of dealing with a particular category of change. A change model defines specific agreed-upon steps that will be followed for a change of this category.
Individual steps for processing changes, including mitigation and risks
Identifying dependencies and chronology of change activities
Identifying responsibilities and accountabilities (basically RACI [responsible, accountable, consulted, and informed]) for individual activities
Relating SLAs and KPIs for every activity
Escalation matrix associated with the process
Emergency Changes
During his REM sleep, a man clutches his chest in pain and starts to sweat. An ambulance is called, and he is transported swiftly to a nearby hospital. The doctors diagnose a series of heart attacks that were caused by a blockage in his heart. They don’t have the time to plan a surgery but rather need to do it right away if the patient is to survive. So, with minimum planning, they carry out the surgery. Such changes that are done during such firefighting exercises are called emergency changes in the change control practice.
Emergency changes are necessary to urgently fix an ongoing issue or a crisis. These changes are mostly carried out as a resolution to a major incident. The nature of such changes requires swift action, whether it is getting the necessary approvals or the testing that is involved. Generally, emergency changes are not thoroughly pretested, as the time availability is minimal. In some cases they may go through without any testing, although this is not recommended even for an emergency change. As much as possible, it is recommended that emergency changes go through the same level of scrutiny as normal changes but on an expedited schedule. However, the documentation portion of the change can be done retrospectively , and some shortcuts in testing are undertaken to restore services at the earliest.
The success of emergency changes reflects the agility of an organization and the change control practice to act on disruptions in a time-constrained environment. and to come out unscathed in the eyes of the customer and your competition.
Emergency change control practice supports the incident management practice in the resolution of incidents, especially major ones. Emergency changes are generally frowned upon and are not preferred. The number of such changes in an organization reflects poorly on the organization’s stability of the services it offers.
Examples of emergency changes are the replacement of hardware infrastructure and restoring customer data from backup volumes.
To manage emergency changes, it is possible that a separate governing authority is put in place that works closely with the operations team, and this governing authority is available round the clock .
Standard Changes
A patient with failed kidneys gets dialysis done multiple times a week. The process for carrying out a dialysis procedure is well known and rarely can it go south. Most patients set up dialysis treatments at home and do them fairly regularly. The risks involved are low, and if something goes wrong, the impact too is on the lower end of the spectrum because there are multiple workarounds available. Such changes for IT services that pose no danger to services and are low key are referred to as standard changes.
Standard changes are normal changes that are of low risk and low impact in nature. The categorization of changes as standard is at the discretion of the service provider and customer organizations. These types of changes are well understood, thoroughly assessed, and documented in detail. They are preapproved changes: not every single change but the type of changes. For example, if we consider blacklisting an IP address as a standard change, the action of blacklisting IPs is authorized. Then every time a new IP address is identified for blacklisting, the team involved simply raises a standard change and blacklists the IP without having to seek approvals.
Under service request management practice, I talked about service requests as being a type of standard changes. Service providers often take the route of service requests when dealing with individuals, and standard changes while dealing with service level changes.
Standard changes have distinct advantages and create value for customers. They follow a process that is less stringent and is free from the multiple approvals and lead times that are often associated with normal changes. This provides the service provider with the arsenal needed to implement changes on the fly, which increases productivity and also helps deliver better value to the customer.
Examples of standard changes include minor patch upgrades, database reindexing, and blacklisting IPs on firewalls.
It is believed that the maturity of the service management process of organizations offering services can be determined based on the number of standard changes in the system. That’s true, as standard changes present a system to segregate difficult changes from the usual ones. The commonly performed changes are like a well-oiled machine. It operates smoothly and can be relied upon in most circumstances. Around 60 percent to 70 percent of the changes in any organization are common, repeatable, and straightforward. If all these changes are standardized, imagine the number of approvals that don’t have to be sought and the number of meetings, telephone calls, and waiting around that can be skipped.
The advantage with standard changes is such that in most situations it can be done on the back of any defined trigger. When a team wants to perform a standard change, they don’t have to go to the change management team or to the change authority for authorization to present their change. They simply log a standard change in the system (yes, records are an absolute necessity), and then they can carry it out. Once it is successfully implemented (which is expected), the change is closed. Voila! There’s no need to do any post-change reviews.
Examples of standard changes can be anything and everything under the IT sun that is repetitive in nature and does not pose major risks. That sounds like every single deployment we do under DevOps, doesn’t it? Do you now see the connection between standard changes and DevOps? Typical examples include installing security patches on operating systems, running batch jobs, and performing nonintrusive backups .
Championing Standard Changes
Does a robust change control practice exist?
Are there provisions for standard changes?
How many changes are implemented as standard changes?
Are standard changes monitored and audited regularly?
Standard changes are the low-hanging value creation fruit for clients. Most service management experts and consultants have yet to come to grips with it, and that hurts their clients’ chances of making a difference through service management.
When I worked as an enterprise change manager for a retail organization in Sydney, Australia, I noticed that the organization did not have an active standard change process. A team of change managers reviewed and processed anywhere between 150 and 200 changes each day. They knew the changes so well that by reading the change summary, they would just scroll down to where the approval task became visible and hit Approve.
What struck me first was why this human effort was even required, as it amounted to a process to be followed rather than any visible value through the additional pair of eyes. I got down to work by pulling data for the past couple of years and identifying such changes that could potentially be categorized as standard changes. I did some arithmetic and some guesswork to crunch some numbers, and according to my analysis, the organization could save anywhere between 25 hours and 40 hours every single day. I considered modest numbers for my calculations, and this was the minimum savings that the organization could do, based on 200 hours of weekly savings and the average wages for a week typically in Australia being about $2,500 ($12,500 for the 200 hours saved). This saving translates to a monthly savings of around $50,000 ($12,500 × 4 weeks). Out of nowhere, the company could save over half a million every year, and they jumped on it, not without a number of warnings from the company old-timers.
I managed to convert about 60 percent of the overall changes into standard changes within 4 months, and the benefits showcased the power of Agile and DevOps. A number of business people in this organization were relieved not to have to worry about getting approvals for all their changes. The best part was that they did not have to bundle their changes into releases, so the changes went quickly to production and provided maximum benefits to the business .
Change Advisory
The change control practice alone may not have the necessary skills to judge changes on their merit. So, a body called change authority is set up to advise the change control practice on the risks posed by the change. They have the power to authorize changes for implementation or reject them, and the change control practice usually considers their judgment.
The change authority can be described as an extension of the change management role, and it exists to ensure that the proposed changes are nondisruptive, scheduled to minimize conflicts, prioritized based on risk and impact, and analyzed for every possible outcome to the hilt.
Earlier, an organization consisted of the change authority, which was dynamic in nature, but since the change control was central, the change authority too operated centrally. Today, in the swift decision-making world, having a single change authority is a bottleneck to speedy turnaround. Therefore, it is quite common to decentralize the process of change approvals through local change authorities. For example, an application portfolio may have its own change authority, and cloud infrastructure could have its own decentralized change approval system in place. This helps in moving ahead quickly and also to have decision makers who know the system, such as product and service owners. The primary change control or the policy making body could still be central, which can impose change freezes and other enterprise-wide policies and processes such as processes to define standard changes.
In a typical change authority meeting, a change representative (usually the technical lead) presents the change. Based on the presentation, the committee might choose to seek clarifications; ask questions; and approve, defer, or reject the change—purely based on the merit.
In ITIL V3, the change authority was referred to as the change advisory board (CAB). Both the change authority and the CAB are the same in principle and spirit; they only differ by name.
Change Schedule
The definition of the change control practice talks about a change schedule, which is an important terminology in the change control practice. A change schedule refers to a change calendar that consists of the changes that are in the pipeline, approved upcoming changes, and the changes that are implemented. Look at it through the eyes of a calendar. We use our calendars to plan the day, propose new slots for conflicting meetings, and delegate people to certain important meetings that we cannot make. Likewise, a change schedule is used for planning of the changes, especially where dependencies exist between one change and another; assigning resources to oversee and implement changes; and communicating to appropriate stakeholders on the change lifecycle. Conflicts in changes are quite common, and a calendar (change schedule) helps in identifying and mitigating them.
Other practices also leverage the change schedule. For example, the incident management practice uses the information to identify the changes that have been implemented, to identify the source of a cluster of incidents. That helps in identifying the cause of an incident and resolving it swiftly. Problem management too could use this information to identify the root cause of problems. The change schedule could be seen from the upcoming changes perspective as well, to identify the product bugs that are getting fixed. The applications of a change schedule are endless. It is important that an organization maintain a centralized change schedule to help identify conflicts and dependencies effectively .
In ITIL V3, change schedule was referred to as forward schedule of changes (FSC). Both the change schedule and the FSC are the same in principle and spirit, and only differ by name.
Engagement with Service Value Chain
Knowledge Check
- 12-1.Which of the following is the correct change definition?
- A.
Any change of state that is significant for a service or product or related configuration item
- B.
The addition, modification, or removal of anything that could have a direct or indirect effect on services
- C.
Any change of state for configuration items that correlates risks and issues to the service and service management processes
- D.
Any change that has significance for the management of a service or other additions, removals, and modifications
- A.
- 12-2.Why should incidents and service requests be treated separately?
- A.
Incidents are raised by monitoring tools and service requests by users, so the levels of service are different and therefore need to be treated differently.
- B.
Incidents are service disruptions, and service requests are additional requests. So, in order to avoid further service disruption, incidents should be prioritized over service requests.
- C.
Loss of service requests result in incidents being raised. So service requests need to be given priority.
- D.
Incidents and service requests should not be treated differently. Both provide inconvenience to the end users, so it is paramount that both of them be resolved at a quick pace.
- A.
- 12-3.The service request management practice exists for this reason:
- A.
To support the provisioning of services through the change control practice
- B.
To ensure that the services are restored to the end user to support in increasing the end user’s productivity and effectiveness
- C.
To support the agreed quality of a service by handling all predefined, user-initiated service requests
- D.
To provide an overarching framework for managing service requests and standard changes that are predefined and established
- A.
- 12-4.Which of the following is not a valid type of a change as per ITIL?
- A.
Urgent change
- B.
Normal change
- C.
Standard change
- D.
Emergency change
- A.
- 12-5.What is the primary role of change authority?
- A.
Advise the change control practice on the risks posed by the change
- B.
Approve or reject changes based on the change schedule
- C.
Authorize standard changes that are due for implementation
- D.
Provide recommendations to the change control practice for creating change requests
- A.
- 12-6.What does a change schedule consist of?
- A.
Approved changes
- B.
Approved and pipeline changes
- C.
Approved and rejected changes
- D.
Standard and emergency changes
- A.