
New ways of working, or new methodologies, begin to unearth because of a problem—yes, it all starts with a problem. DevOps too had its own reasons. Businesses craved fast turnarounds of their solutions. And often businesses found out in the midst of development that they did not have all the information they needed to make the right decisions. They wanted to recommend a few more changes to the requirements and still expected the delivery to happen on time. DevOps was born to solve this problem.
Well, DevOps did not just show up as the DevOps we have today. It has evolved over time. It was clear to those who started solving the problem around agility that DevOps has a lot of potential to not just solve the problem of agility but also increase productivity by leaps and bounds. Further, the quality of the software developed had the potential to be at a historic best. Thus, to this day, DevOps keeps changing and changing for the better.
DevOps is not just a methodology for developers. Operations too gets its share of the benefits pie. With increased automation, operations went from being a mundane job to an innovative one. Operations folks just got themselves a new lease on life through various tools that can make their working lives a whole lot better, and they could start looking forward to integrating and configuring tools to do advanced stuff, rather than the repetitive workload that is generally associated with operations. Here too, the productivity shot up, and human errors became a rarity.
The software development was carried out on the back of the software delivery life cycle (SDLC) and managed through waterfall project management. On the operations front, ITIL ruled the roost. Through DevOps, development and operations essentially came together to form a union. In the mix, the waterfall methodology gave way to Agile methodologies, and still people who design DevOps processes did not have a good understanding of how ITIL would come into DevOps. So, a lot of noise started to circulate that the dawn of DevOps is the end for ITIL. This is plainly noise without any substance.
What Exactly Is DevOps
There are multiple perceptions about DevOps. In fact, if you search the Web, you will be surprised to find multiple definitions for DevOps and that no two original definitions converge on common aspects and elements.
I have trained thousands in the area of DevOps, and the best answer I have is that it brings together the development and operations teams, and that’s about it. Does bringing two teams together create such a strong buzz across the globe? In fact, if it was just the culmination of two teams, then probably DevOps would have been talked of in the human resources ecosphere, and it would have remained a semicomplex HR management process.
During the beginning of the DevOps era, to amuse my curiosity, I spoke to a number of people to understand what DevOps is. Most bent toward automation; some spoke of that thing they do in startups; and there were very few who spoke of it as a cultural change. Interesting! Who talks of culture these days, when the edge of our seats burns a hole if we don’t act on our commitments? A particular example made me sit up and start joining the DevOps dots, and it all made sense eventually.
DevOps Explained with an Example
Let us say that you are a project manager for an Internet banking product. The past weekend you deployed a change to update a critical component of the system after weeks of development and testing. The change was deployed successfully; however, during the postimplementation review, it threw out an error that forced you to roll back the change.
The rollback was successful, and all the artifacts pertaining to the release were brought to the table to examine and identify the root cause the following Monday. Now what happens? The root cause is identified, a developer is pressed into action to fix the bug, and the code goes through the scrutiny of various tests, including the tests that were not originally done that could have caught the bug in the functional testing stage rather than in production. All tests run OK; a new change is planned; it gets approved by the change advisory board; and the change gets implemented, tested, and is given all green lights.
These are the typical process activities that are undertaken when a deployment fails and has to be replanned. However, the moment things go south, what is the first thing that comes to your mind as the project manager? Is it what objective action you should take next, or do you start thinking of the developer who worked in this area, the person responsible for the bug in the first place? Or do you think about the tester who identified the scenarios, wrote the scripts, and performed exploratory testing? Yes, it is true that you start to think about the people responsible for the mess. Why? It is because of our culture. We live in a culture that blames people and tries to pass the buck.
I mentioned earlier about some respondents telling me that DevOps is about culture. So, what culture am I talking about within the context of this example? The example depicts a blameful culture where the project manager is trying to pin the blame on the people within his team directly responsible for the failure. He could be factually right in pinning the blame on people directly responsible, but I am focusing on the practice of blaming individuals.
How is this practice different from a DevOps culture? In DevOps, the responsibility of completing a task is not considered as an individual responsibility but rather a shared responsibility. Although an individual works on a task, if the person fails or succeeds, the entire team gets the carrot or the stick. Individuals are not made responsible when we look at the overall DevOps scheme of things, and we do not blame individuals. We follow a blameless culture. This culture of blamelessness arises from the fact that we all make mistakes because we are humans after all and far from being perfect. We make mistakes. So, what is the point in blaming people? In fact, we expect that people do make mistakes—not based on negligence but from the experimentation mindset.
This acceptance (of developers making mistakes) has led us to develop a system where the mistakes that are made get identified and rectified in the developmental stages, well before they reach production.
How is this system (to catch mistakes) built? To make it happen, we brought the development and operations teams together (to avoid disconnect); we developed processes that are far more effective and efficient than what was out there; and finally we took umbrage under automation to efficiently provide us with feedback on how we are doing (as speed is one of the main objectives we intend to achieve).
DevOps is a common phrase, and with its spread reaching far and wide, there are multiple definitions coming from various quarters. No two definitions will be alike, but they will have a common theme: culture. So, for me, DevOps is a cultural transformation that brings together people from across disciplines to work under a single umbrella to collaborate and work as one unit with an open mind and to remove inefficiencies.
Blameless culture does not mean that the individuals who make repeated mistakes go scot-free. Individuals will be appraised justly and appropriately but in a constructive manner.
Why DevOps

Waterfall project management methodology
When the Internet boomed, the software was far more accessible than the earlier era, and this generated demand not seen earlier. When the software industry started to expand, the waterfall model’s limitations were exposed. The need to complete a detailed planning exercise and the sequential practice of flow did seem like an impediment to the advancement of the software industry.
Then in 2001 at a ski resort in Utah, the Agile Manifesto was born. Several prevalent Agile methodologies came together to form a common goal that would remove the cast-in-stone waterfall sequential activities.
Agile was more fluid because it did not conceive of all the requirements at the beginning and try to solve everything overnight. It was an approach that was based on iterations, where all the activities of project management just cycled repeatedly.
In between, if a requirement were to change, that’s OK because there were provisions to make changes that were neither bureaucratic nor tedious in nature. In fact, the Agile methodology puts the emphasis on the response to changes in requirements rather than a map to be followed.
The flexibility and dynamism that came about through Agile spread its wings across the software industry. Several software projects migrated to the Agile way of working, and to this day there are projects that are undergoing serious coaching during this transformational phase.
The Agile methodology is simple, where you keep things small enough to manage and large enough to be rendered meaningful. The time frames that defined iterations in Agile did not carry too much wriggle room. From an efficiency perspective, Agile was far better than the waterfall model. However, the demands from the market were out of sync with what Agile could provide. While the market shouted out for faster deliveries, the need to increase quality (reducing defect rate) was perennially being pursued. The Agile project management methodology needed something, like an elixir to run things faster. It needed automation. Enter DevOps!
Automation by itself is like giving a drone to a kid without really teaching him the process to make it fly. Generally speaking, technology by itself has no meaning if there are no underlying functional architecture, process, and embedded principles. DevOps, therefore, is not just automation but a whole lot more. You will find out the nitty-gritty details in the coming sections.
A Note on DevOps Scope
The word DevOps gives away the scope through its conjunction of two parts of a software life cycle. While Agile existed mainly to put an end to the rigidity brought forth by the waterfall model, it was said that the methodology can be used for operations as well. But, without an overarching process or a framework, using Agile for operations with the same rigor was not going to work. DevOps bridged this gap by bringing in the operational phases along with the developmental activities under a single umbrella, and applying common processes and principles to be employed across the board.
DevOps comes into play when you get started with the software development process, which is the requirement gathering phase. It ends when the software retires from service. DevOps spans the entire wavelength of a software life cycle, and if you read between the lines, you cannot just implement and execute DevOps until deployment and be done with it. It will continue to function until the software is used by its designated users. In other words, DevOps is here to stay, and stay for as long as services are delivered. So, in practice, the operational phase runs perpetually, and DevOps will deliver the required optimization and automation. The processes to run operations will be borrowed from the ITIL service management framework.
The word DevOps came into existence thanks to Twitter. The first Devopsdays conference was held in Ghent, Belgium, in 2009. While people tweeted about it, the #devopsdays tag ate way 11 characters out of a possible 140. In a way of shortening it, one of the tweeters used #devops, and others followed suit. This led to the advent of what we know today as DevOps.
Benefits of Transforming into DevOps
Several software companies have been delivering applications for a number of years now. Why do we need DevOps to tell us how we must develop now?
Our services are being delivered to several customers including top banks and mines around the globe. I am running simply fine with my service management framework. Why DevOps?
People have lived for thousands of years now. They did just fine, reproducing and surviving. What has changed in the past 100 years? We have changed the modes of transport for better efficiency; we communicate faster today; and overall, our quality of life has gone up several notches. The fact that something is working is not a barrier for improvements to be brought about and to transform. DevOps introduces several enhancements in the areas of working culture, process, technology, and organization structure. The transformation has been rooted in practices that were developed by some like-minded organizations that were willing to experiment, and the results have vastly gone in favor of DevOps over other ancient methodologies that still exist today.
Amazon, Netflix, Etsy, and Facebook are some of the organizations that have taken their software deliveries to a whole new level, and they don’t compete anymore with the laggards. They have set new benchmarks that are impossible to meet with any of the other methodologies.
At the 2011 Velocity conference, Amazon’s director of platform analysis, Jon Jenkins, provided a brief insight into Amazon’s ways of working. He supported it with the following statistics.
During weekdays, Amazon can deploy every 11.6 seconds on average. Most organizations struggle to deploy weekly consistently, but Amazon does more than 1,000 deployments every hour (1,079 deployments to be precise). Further, 10,000 hosts receive deployments simultaneously on average, and the highest Amazon has been able to achieve is 30,000 hosts simultaneously receiving deployments. Wow! These numbers are really out of this world. And these are the statistics from May 2011. Imagine what they can do today!
Outages owing to software deployments have reduced by a whopping 75 percent since 2006. Most outages are caused by new changes (read software deployments), and the reduction in outages points to the success achieved in deploying software changes.
The downtime owing to software deployments too has reduced drastically, by about 90 percent.
On an average, there has been an outage for every 1,000 software deployments, which is about a 0.1 percent failure rate. This looks great for a moderate software delivery organization, but for Amazon, the number seems high because of the 1,000+ deployments every hour.
Through automation, Amazon has introduced automatic failovers whenever hosts go down.
Architecture complexity has reduced significantly.
DevOps Principles

DevOps principles (image credit: devopsnet.com)
Culture
Automation
Lean
Measurement
Sharing
Culture
There is a popular urban legend that the late Peter Drucker, known as the founder of modern management, famously said, “Culture eats strategy for breakfast.” If you want to make a massive mind-boggling earth-shaking change, start by changing the culture that can make it happen and adapt to the proposed new way of working. Culture is something that cannot be changed by a swift switching process. It is embedded into human behavior and requires an overhaul of people’s behavior.
Take responsibility for the entire product and not just the work that you perform.
Step out of your comfort zone and innovate.
Experiment as much as you want; there’s a safety net to catch you if you fall
Communicate, collaborate, and develop affinity with the involved teams.
For developers especially: you build it, you run it.
Automation
Automation is a key component in the DevOps methodology. It is a massive enabler for faster delivery and also crucial for providing rapid feedback. Under the culture principle, I talked about a safety net with respect to experimentation. This safety net is made possible through automation.
The objective is to automate whatever possible in the software delivery life cycle. The kinds of activities that can be efficiently automated are those that are repetitive and those that don’t ask for human intelligence. For example, building infrastructure was a major task that involved hardware architects and administrators; and most importantly, building servers took a significant amount of time. This was time that was added to the overall software delivery. Thanks to the advancement of technology, we have cloud infrastructure today, and servers can be spun up through code. Additionally, we don’t need hardware administrators to do it. Developers can do it themselves. Wait, there’s more! Once the environment provisioning script is written, it can be used to automate spinning up servers as many times as necessary. Automation has really changed the way we see infrastructure.
Activities involving executing tasks such as running a build or running a test script can be automated. But, the activities that involve human cognizance are hard to automate today. The art of writing the code or test scripts requires the use of human intelligence, and the machines of today are not in a position to do it. Tomorrow, artificial intelligence can be a threat to the activities that are dependent on humans today .
Lean
DevOps has borrowed heavily from Lean methodology and the Toyota Production System (TPS). The thinking behind the Lean methodology is to keep things simple and not to overcomplicate them. It is natural that the advent of automation can decrease the complexity of architecture and simplify complicated workflows. The Lean principle aids in keeping us on the ground so we can continue working with things that are easy to comprehend and simple to work with.
There are two parts to the Lean principle. The primary one is not to bloat the logic or the way we do things; keep it straightforward and minimal. An example is the use of microservices, which support the cause by not overcomplicating the architecture. We are no longer looking to build monolithic architectures that are cumbersome when it comes to enhancements, maintenance, and upgrades. A microservice architecture solves all the problems that we faced yesterday with monolithic architectures; it is easy to upgrade, troubleshoot (maintain), and enhance.
The second part of the principle is to reduce the wastage arising from the methodology. Defects are one of the key wastes. Defects are a nuisance. They delay the overall delivery, and the amount of effort that goes into fixing them is just a sheer waste of time and money. The next type of waste focuses on convoluted processes. If something can be done by passing the ball from A to B, why does it have to bounce off C? There are many such wastes that can be addressed to make the software delivery more efficient and effective.
Measurement
If you seek to automate everything, then you probably need a system to provide feedback whenever something goes wrong. Feedback is possible if you know what the optimum results are and what aren’t. The only way you can find out whether the outcome is optimum or not is by measuring it. So, it is essential that you measure everything if you are going to automate everything!
Measurement principle provides direction on the measures to implement and keep tabs on the pulse of the overall software delivery. It is not a simple task to measure everything. Many times we do not even know what we should measure.
Even if we do it, the how part can be an obstacle. A good DevOps process architect can help solve this problem. For example, if you are running static analysis on your code, the extent of passable code must be predetermined. It is not a random number, but a scientific reasoning must be behind it. Several companies allow a unit test to pass even if it parses 90 percent of the code. We know that ideally it must be 100 percent, so why should anybody compromise for 90 percent? That is the kind of logic that must go behind measuring everything and enabling fast feedback, to be realistic about the kind of feedback that you want to receive.
In operations, monitoring applications, infrastructure, performance, and other parameters come under this principle. Measurements in monitoring will imply when an event will be categorized as a warning or an exception. With automation in place, it is extremely important that all the critical activities, and the infrastructure that supports them, be monitored and optimized for measurement.
There are other measurements as well that are attached to contracts and SLAs and are used for reporting on a regular basis. These measurements are important as well in the overall scheme of things.
Sharing
The final principle is sharing, which hinges on the need for collaboration and knowledge sharing between people. If we aim to significantly hasten the process of software delivery, it is only possible if people don’t work in silos anymore. The knowledge, experience, thoughts, and ideas must be put out into the open for others to join in the process of making them better, enhanced, and profound.
One of the key takeaways of this principle is to put everyone who works on a product or a service onto a single team and promote knowledge sharing. This will lead to collaboration rather than competition and skepticism.
There are a number of collaboration tools on the market today that help support the cause. People do not even have to be colocated to share and collaborate. Tools such as Microsoft Teams and Slack help in getting the information across not only to a single person but to all those who matter (such as the entire team). With information being transparent, there will be no reason for others to worry or be skeptical about the dependencies or the outcome of the process.
Elements of DevOps
DevOps is not a framework; it is a set of good practices. It got started out of a perfect storm that pooled several practices together (which is discussed later in this chapter), and today we consider them under the DevOps umbrella. You might have seen a graphic with an elephant (Andrew Clay Shafer’s “The Panel Experiment and Ignite DevOps,” May 16, 2010, devopsdays.org). The IT industry around software development is so vast that several practices are followed across the board. This is depicted as the elephant. DevOps, which is a cultural change, can be applied to any part of the software industry and to any activity that is being carried out today. So, you can identify any part of the elephant (say testing) and design DevOps-related practices and implement them and you are doing DevOps!
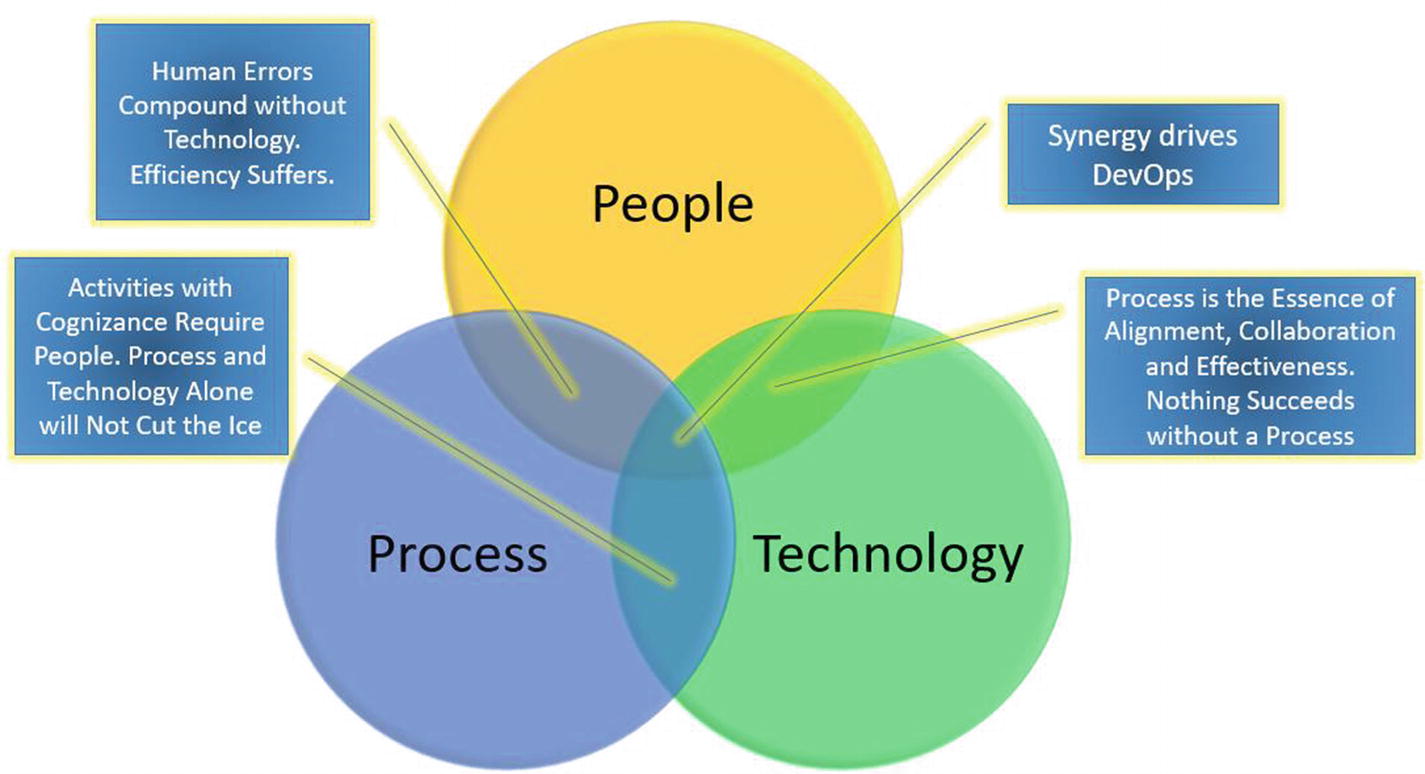
Three elements of DevOps
People, process, and technology are the three elements that are common to all DevOps practices. In fact, they are the enablers to effect change in the DevOps culture. Only when the three elements come together in unison are we able to realize the complete benefits of DevOps.
Let’s examine the three elements and see how they fit together. To bring in a cultural change, we most definitely need people, and people cannot operate without the aid of processes. By bringing in people and processes, we have achieved the functional design to implement a DevOps solution. However, the question to ask is whether it is efficient.
Humans are known to make mistakes. We cannot avoid it. How can processes alone support humans in identifying the mistakes committed? There may be a way to do it, but it is most definitely not efficient. To make things move faster and in an efficient manner, we need the technology stack to help us achieve the process objectives.
Today, people talk of DevOps through the lens of technology. They throw around several tool names and claim that they do DevOps. So, the question to ponder is whether you can really do DevOps by tools alone. Can people and technology elements suffice without an underlying process? You probably guessed the answer, and the answer is no.
Nothing succeeds without a process in place, not only in DevOps but in every objective that you want to achieve, IT or otherwise.
This is the age of artificial intelligence. Some experts claim that the machines will take over the world and replace the work people used to do. There are several movies such as “Terminator Genisys” and “Ex Machina” that play to the tunes of AI taking over the reins and putting humans in jeopardy. I love fiction, and AI making decisions is something I like to think of as fiction (for now anyway because the technology advancements are breaking new barriers every day). However, coming back to DevOps, just employing technology with underlying processes is not going to cut it. Without people, creation does not happen. Yes, technology can automate a number of preprogrammed activities, but can it develop new solutions on its own? I don’t think so; not today anyway. People are the driving force of creation and the agents of cultural change.
All the three elements of people, process, and technology are essential to build the DevOps methodology and to achieve the objectives that are set forth before us. By the union of all three elements, we can create an unmatched synergy that can fuel developments at an unparalleled pace
People
The word DevOps is derived from the conjunction of two words, development, and operations. I have already familiarized you with what DevOps is all about: a change of culture in the way we deliver and operate software. People are at the heart of this cultural transformation, and they are one of the three critical elements that enable the DevOps culture.
The development and operation teams are amalgamated to bring about a change in culture. The thinking behind it is quite straightforward. Let’s say that an application is developed, and it comes to the change advisory board (CAB) for approval. One of the parties on the CAB is the operational teams. They specifically ask questions around the testing that has been performed for this software, and even though the answer from development is yes for the success rate of all the tests, the operational teams tend to be critical. They don’t want to be blockers, yet they find themselves in a position where they have to support software that they haven’t been familiarized with yet. The bugs and defects that come with the software will become their problem after the warranty period (usually between 1 and 3 months). Most importantly, they only have the confirmation of the developers to go with when the quality of the software is put on the line.
In the same scenario, imagine if the operational teams were already part of the same team as development. Being on the same team will give them an opportunity to become familiar with the development process and the quality controls put in place. Instead of asking questions in the CAB, they can work progressively with the development teams in ensuring that the software is maintainable, and all possible operational aspects are undertaken beforehand. This is one such case study that showcases the benefit of having a single team.

Conflict between development and operations
Let’s play out the priorities for both teams. The development team still has a job because there is a need to develop new features. That is their core area, and that is what they must do to remain relevant. The operations team’s big-ticket goal is to keep the environment stable, in the most basic sense. They need to ensure that even if something was to go wrong, they are tasked to bring it back to normal, in other words, maintain the status quo. So, here we have a development team intending to create new features and an operations team looking to keep the environment stable.
Does it have to be rocket science to have evolved into a methodology called DevOps that promises to shake the industry from its roots? Well, the environment is going to remain stable if there are no changes introduced to it. As long as it stays stagnant, nothing ever will bother its stability, and the operations team would have been awarded for a stellar job. But we have the development team waiting in the wings to develop new features. New features that are developed will be deployed in the production environment, and there is every chance that the deployment of new features could impact stability. So, stability is something that can never be achieved as long as new features are introduced, and no software will remain stagnant without enhancements and expansion.
A decent way to tackle this conundrum between the development and operation teams is to put them together and create channels of communication within the team members. Both the development and operations teams have a shared responsibility to ensure that development, testing, deployment, and other support activities happen smoothly and without glitches. Every team member takes responsibility for all the activities being carried out, which translates to the development and operation teams jointly working on the solution that begins with coding and ends with deployment. The operations teams will have no reason to mistrust the test results and can confidently deploy onto the production environment.
Process
Processes are a key component in ensuring the success of any project. However, we often find that most DevOps implementations focus more on automation and technology and give a backseat to processes that are supposed to be the basis for automation. They say that backseat driving is dangerous, so placing processes in this position and hoping that the destination would be reached in record time with no mishaps is a gamble that plays with unpredictability. Therefore, it is important that processes are defined first along with a functional DevOps architecture and then translated into tooling and automation. The process must always drive tools and never the other way around.
With DevOps combining different disciplines under a single banner, the processes too need to be rejigged to fit the new objectives. This section covers the processes pertaining to the development area.
Waterfall project management methodology (such as PMI-backed Project Management and PRINCE for projects in controlled environments) are not favored in the IT field anymore. There are various reasons going against this methodology, mainly stemming from the rigidity it brings into the project management structure.
Most IT projects are run on Agile project management methodologies because of the flexibility it offers in this ever-changing market. According to PMI’s “Pulse of Profession” 2017 publication (www.pmi.org/-/media/pmi/documents/public/pdf/learning/thought-leadership/pulse/pulse-of-the-profession-2017.pdf), 71 percent of organizations have been leveraging Agile. Another study by PricewaterhouseCoopers, named “Agile Project Delivery Confidence (July 2017)” (www.pwc.com/gx/en/actuarial-insurance-services/assets/agile-project-delivery-confidence.pdf), reported that Agile projects are 28 percent more successful than their waterfall counterparts. This is huge considering that Agile is still new and emerging and the waterfall methodology has existed since the 1960s.
When we talk about Agile project management, there are a number of methodologies to pick from. Scrum, Kanban, Scrumban, Extreme Programming (XP), Dynamic Systems Development Method (DSDM), Crystal, and Feature Driven Development (FDD) are some examples. However, all the methodologies are aligned by a manifesto that was formulated in a ski resort in Utah in 2001. And there are a set of 12 Agile principles that provide guidance in setting up the project management processes .
Technology
Technology is the third element of DevOps and is often regarded as the most important. It is true in a sense that without automation, we cannot possibly achieve the fast results that I have shared earlier through some statistics. It is also true that technology on its own, without the proper synchrony of people (roles) and processes, is like a spaceship in the hands of kindergarteners. It is a must that the people and process sides of DevOps are sorted out first before heading this way.
The number of tools that claim to support DevOps activities is enormous—too many to count.
DevOps Practices
The word DevOps has become synonymous with certain practices such as continuous integration, continuous delivery, and continuous deployment. This section explains and declutters the practices and the differences between them.
Continuous Integration
Several developers work together on the same piece of code, which is referred to as the mainline in software development lingo. When multiple developers are at work, conflicts arising due to changes performed on pieces of code and the employed logic are quite common. Software developers generally integrate their pieces of code into the mainline once a day.
When conflicts arise, they discuss and sort it out. This process here of integrating the code manually at a defined time slows down the development. Conflicts at times can have drastic results, with hundreds of lines of code having to be rewritten. Imagine the time and effort lost due to manual integration. If I can integrate code in almost real time with the rest of the developers, the potential amount of rework can significantly be reduced. This is the concept of continuous integration.
To be more specific, continuous integration is a process whereby developers integrate their code into the source code repository (mainline) on a regular basis, say multiple times a day. When the code is integrated with the mainline, any conflicts will come out into the open as soon as it is integrated. The resolution of conflicts does not have to be an affair where all developers sit across the codebase and break their heads. Only those who have conflicts need to sort them out manually. By doing this conflict resolution multiple times a day, the extent of conflicts is drastically minimized .
The best definition of continuous integration was coined by Martin Fowler from ThoughtWorks, who is also one of the founding members of the Agile Manifesto.
Continuous integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily, leading to multiple integrations per day. Each integration is verified by an automated build (including tests) to detect integration errors as quickly as possible. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly (source: www.martinfowler.com/articles/continuousIntegration.html).
Integrating the code with the mainline is just the beginning. Whenever the code is integrated, the entire mainline is built, and other quality checks such as unit testing and code-quality checks (static and dynamic analysis) also are carried out.
Build is a process where the human-readable code is converted into machine-readable language (executable code), and the output of a build activity is a binary.
Unit testing is a quality check where the smallest testable parts of an application are tested individually and in a componentized manner.
Static analysis is an examination of the source code against the coding standards set forth by the industry/software company, such as naming conventions, blank spaces, and comments.
Dynamic analysis is an examination of the binary during runtime. Such an examination will help identify runtime errors such as memory leaks.

Continuous integration
With nine integrations on a daily basis, we are staring at a possibility of having nine unit tests, nine builds on the entire mainline, and nine code quality checks.
Suppose one of the builds or unit tests or code quality checks fail. The flow gets interrupted, and the developer gets down to work to fix the defect at the earliest. This ensures that the flow of code does not get hampered and other coders can continue coding and integrate their work onto the mainline.
Continuous integration allows for fast delivery of software, and any roadblocks are avoided or identified as early as possible, thanks to rapid feedback and automation. The objective of continuous integration is to hasten the coding process and to generate a binary without integration bugs.
Continuous Delivery
A binary is generated successfully.
Code-level and runtime checks and analysis are completed.

Continuous delivery
Figure 2-6 depicts a continuous delivery pipeline. After every successful cycle of continuous integration, the binary is automatically subjected to an integration test. When the integration test is successful, the same binary is automatically system tested. The cycle passes on up to the preproduction environment as long as the tests (regression and user acceptance testing [UAT] in this illustration) are successful. When the same binary is successfully deployed in the preproduction environment (in this illustration) or any other environment that comes before the production environment, the binary becomes qualified to be deployed on to production. The deployment into the production environment is not done automatically but requires a trigger to make it happen. The entire cycle starting from the code push into the source code repository up to the manual deployment into the production environment is continuous delivery.
In the illustration, I have shown three developers integrating their code and three deployable binaries. Continuous delivery does not dictate that all three binaries have to be deployed into production. The release management process can decide to deploy only the latest binary every week. Remember that the latest binary will consist of the code changes performed by all the developers up until that point in time.
The sequence of automation for the activities beginning in the continuous integration process up until the production environment is referred to as a pipeline, or continuous delivery pipeline in this case .
Continuous Deployment

Continuous deployment
As soon as all the tests are successful, the binary is deployed to the preproduction environment. When the deployment to preproduction goes as planned, the same binary is deployed into production directly. In continuous delivery (Figure 2-7), the binaries were qualified as deployable, and the release manager was in a position to not deploy every single qualified binary into production. On the contrary, in continuous deployment, every single qualified binary gets deployed onto the production instance.
You might think that this is far too risky. How can you deploy something into production without any checks and balances and approvals from all stakeholders? Well, every single test that is performed and all the quality checks executed are the checks that are qualifying binaries as deployables . It is all happening in an automated fashion. You would do the same set of things otherwise but manually. Instead of deploying multiple times a day, you might deploy once a week. All the benefits that you derive from going early into the market are missing from the manual processes.
Let us say that one of the deployments were to fail. No problem! There is an automated rollback mechanism built into the system that rolls back the deployment within seconds. And it is important to note that the changes that are being discussed here are tiny changes. So, the chances of these binaries bringing down a system are remote.
Continuous Delivery vs. Continuous Deployment
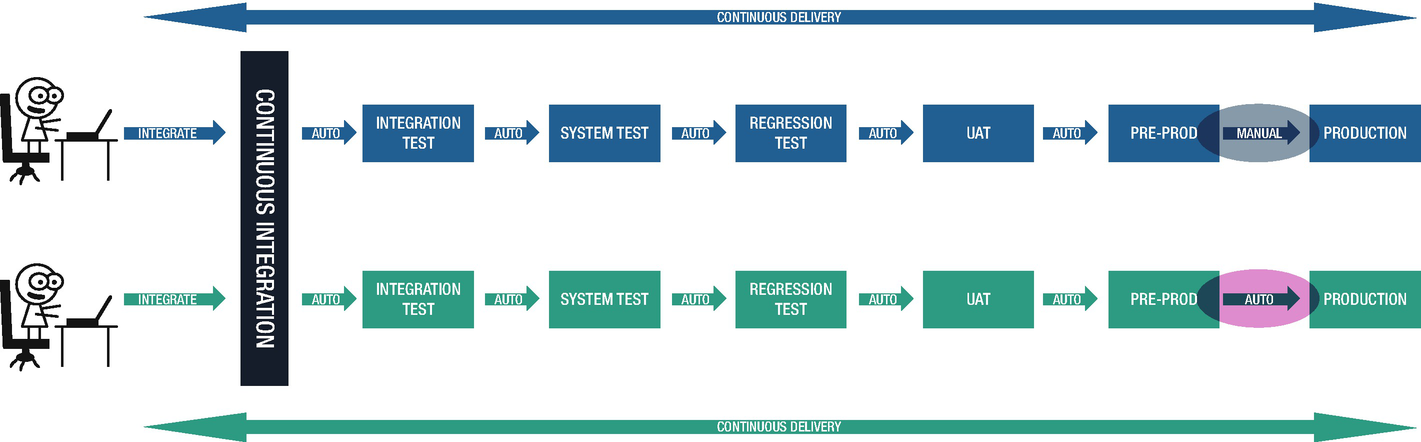
Continuous delivery vs. continuous deployment
Any organization on a journey of implementing DevOps will implement the continuous delivery process and upon gaining sufficient maturity will move toward the pinnacle of DevOps maturity: the continuous deployment process.
Organizations that feel a need to keep total control of their production environment through a formal structure of approvals and visibility tend to opt for continuous delivery. Banking and other financial segments fall into this category.
There are other organizations that have scaled the DevOps maturity ladder and are quite confident that the automatic deployment doesn’t cause significant impact to their production environment. Even if something was to fail, the rollback will be rapid too, even before anybody can notice it. Companies like Amazon, Netflix, and Google have been in this space for a while now. I shared a statistic earlier about Amazon managing a deployment every 11.6 seconds. How is it even possible? Look no further than continuous deployment.
Here is a cheat sheet for continuous delivery and continuous deployment:
Continuous delivery: You can deploy.
Continuous deployment: You will deploy
Is DevOps the End of Ops?
With the introduction of continuous integration, continuous delivery, and continuous deployment, the focus has been to plug defects, increase quality, and not sacrifice efficiency. The thinking behind the notion of DevOps ending the operational activities is based on the premise that lack of defects will not give rise to operational work. If there are no defects, there are potentially no incidents or problems, which translates to a massive reduction in operational work. Another example is if we implement continuous deployment, the change and release management processes as we know them will be automated to a great extent and will diminish the need for approvals and subsequent approvals, release planning, and release deployment.
Let’s get one thing straight: no matter how much we try with the use of technology and automation, defects will always exist. The number of defects will come down due to the rapid feedback and automation, but to state that all the defects would be identified and rectified is absurd. With the reduction of defects, the amount of operational work will definitely go down. With the argument around change and release management processes, the execution of changes and releases can be automated through continuous delivery and continuous deployment, but the planning bit will always remain the cognizance of human experience. To an extent, the operational work involving change and release management processes are starting to go down as well.
Innovation is a double-edged sword. With the introduction of tools and automation, there is a new operational requirement to set up and configure the tool stack and to maintain it as long as the project is underway. This is an operational activity that is added to the traditional operations work. While some areas have seen a reduction, there are new ones that have sprouted to take their place. The manual, repetitive, and boring activities are going away. In their place, exciting DevOps tooling work has come to the fore and is making the operational roles all the more lucrative.
So, if you are an operational person, it is time to scale up and scale beyond managerial activities alone. The new wave of role mapping requires people to be techno-managerial in talent and be multiskilled. T-shaped resources, not only for operations but also in development, are being sought after. I-shaped resources must look toward getting acquainted with areas of expertise that complement their line of work.
With the advent of DevOps, there is a turbulence created in software projects. This is a good turbulence because it seeks to raise the level of delivery and to make teams, rather than individuals, accountable for the outcomes. From an operations front, it is clear that their role has gone up a couple of notches where the mundane, boring, repetitive activities have been replaced with imaginative and challenging jobs such as configuring pipelines, integrating toolsets, and automating configuration management. The nature of work for operations has changed but not the role they play as guardians of environments and troubleshooters of incidents and problems. DevOps has not spelled the end of operations but rather rejuvenated it to an exciting journey that will keep the wits of people working in operations alive.