
![]()
Advanced Sequential Files
In the previous chapter, you saw how sequential files are declared, written, and read. In this chapter, you continue your exploration of sequential files by examining advanced issues such as multiple-record-type files, print files, and variable-length records.
The previous chapter dealt with sequential files that contained only fixed-length records of a single record type. This chapter shows how a file may have records of different lengths either because the file contains a number of different types of fixed-length records or because it contains variable-length records. The discussion of files that contain multiple record types also considers the implications of these multiple record types for the record buffer.
When the WRITE verb was introduced in the previous chapter, I ignored some of the metalanguage because it dealt with print files. This chapter addresses the issue of print files and shows how they are declared and used. I also discuss the problem caused by the different types of print lines that must be sent to a print file.
Files with Multiple Record Types
Quite often, complex data sets cannot store all their data in just one record type. In such cases, a single file contains more than one type of record. For instance, consider the following problem specification.
A company has shops all over Ireland. Every night, a sequential file of cash register receipts is sent from each branch to the head office. These files are merged into a single, large, sequential file called the ShopReceiptsFile.
In the ShopReceiptsFile, there are two types of records:
- A ShopDetails record, used to record the ShopId and ShopLocation
- A SaleReceipt record, used to record the ItemId, QtySold, and ItemCost for each item sold
In the file, a single shop record precedes all the SaleReceipt records for a particular shop.
Write a program to process the ShopReceiptsFile and, for each shop in the file, produce a summary line that shows the ShopId of the shop and the total value of sales for that shop.
Implications of Files with Multiple Record Types
As you can see from the previous specification, the ShopReceiptsFile contains two different types of records. When a file contains different record types, the records will have different structures and, possibly, different lengths. In a specification, the different record types are usually represented as shown in Figure 8-1 and Figure 8-2. The ShopDetails record is 35 characters in size, but the SaleReceipt record is only 16 characters. For each shop in the file, there is one ShopDetails record but many SaleReceipt records.
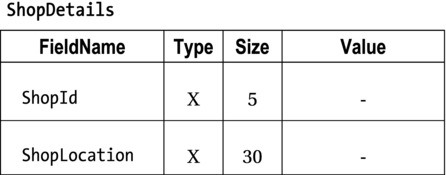
Figure 8-1. ShopDetails description

Figure 8-2. SaleReceipt description
The different types of records in the ShopReceiptsFile means you need more than one record description in the file’s file description (FD) entry. Because record descriptions always begin with level 01, you must provide a 01-level description for each type of record in the file.
Example 8-1 shows the file description for the ShopReceiptsFile. What is not obvious from this description is that even though there are two record descriptions, only one area of memory is reserved for the record buffer, and it is only able to store a single record at a time. Because only one area of memory is reserved, both record descriptions map on to the same record buffer. The size of that record buffer is the size of the largest record.
Example 8-1. File Description for the ShopReceiptsFile
FILE SECTION.
FD ShopReceiptsFile.
01 ShopDetails.
02 ShopId PIC X(5).
02 ShopLocation PIC X(30).
01 SaleReceipt.
02 ItemId PIC X(8).
02 QtySold PIC 9(3).
02 ItemCost PIC 999V99.
This is the magic of the FILE SECTION. When, in the FILE SECTION, multiple records are defined in a file’s FD entry, all the record descriptions share (map on to) the same area of memory, and all the record descriptions are current (live) at the same time.
Multiple Record Descriptions, One Record Buffer
When multiple records are described for the same FD entry, only a single area of storage (record buffer) is created (the size of the largest record). All the record descriptions map on to this single area of storage, and all the descriptions are current no matter which record is actually in the buffer. Obviously, though, even though both record descriptions are available, only one makes sense for the values in the buffer. For instance, Figure 8-3 is a graphical representation of the shared buffer for the ShopReceiptsFile, and the record currently in the buffer is a SaleReceipt record. If you execute the statement DISPLAY ItemId, the value ABC12345 is displayed. If you execute DISPLAY QtySold, you get the value 003. But because both record descriptions are current at the same time, you can also execute DISPLAY ShopLocation, which displays the nonsensical value 34500300399. It is up to the programmer to know what type of record is in the buffer and to use only the record description that makes sense for those values. The question is, how can you know what type of record has been read into the buffer?
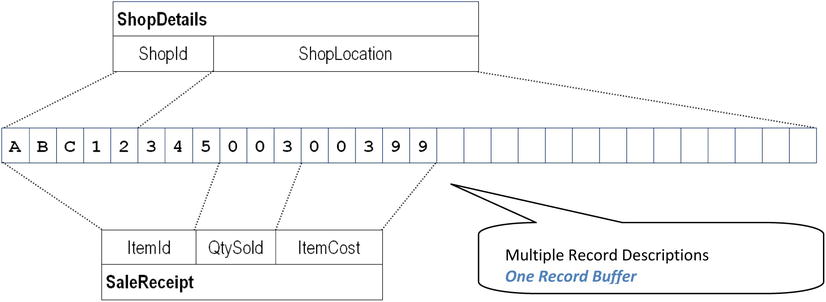
Figure 8-3. A graphical representation of the shared record buffer
When a record is read into a shared record buffer, it is your responsibility to discover what type of record has been read in and to refer only to the fields that make sense for that type of record. Looking at the record in Figure 8-3, you might wonder how you can discover what type of record had been read into the buffer. Sometimes you can determine the record type by looking for identifying characteristics that are unique to that type of record, such as a particular value or data type. However, generally it is not possible to establish reliably what type of record is in the buffer simply by examining the buffer values.
A special identifying data item called the type code is usually inserted into each record to allow you to distinguish between record types. The type code is usually one character in size and is the first field in each record, but its size and placement are merely conventions. The type code can be placed anywhere in the record and be of any size and any type.
The ShopReceiptsFile uses the character H to indicate the ShopDetails record (the header record) and S to indicate the SaleReceipt record (the sales record). To detect the type of record read into the buffer, you could use statements such as IF TypeCode = "H" or IF TypeCode = "S". But this is COBOL. It offers a better way. You can define condition names to monitor the type code so that if it contains H the condition name ShopHeader is set to true, and if it contains S the condition name ShopSale is set to true. The record descriptions required to accommodate these changes for the ShopReceiptsFile are shown in Example 8-2.
Example 8-2. ShopReceiptsFile Record Descriptions with Type Code
FILE SECTION.
FD ShopReceiptsFile.
01 ShopDetails.
02 TypeCode PIC X.
88 ShopHeader VALUE "H".
88 ShopSale VALUE "S".
02 ShopId PIC X(5).
02 ShopLocation PIC X(30).
01 SaleReceipt.
02 TypeCode PIC X.
02 ItemId PIC X(8).
02 QtySold PIC 9(3).
02 ItemCost PIC 999V99.
A graphical representation of the new record descriptions is shown in Figure 8-4. In this case, there is a ShopDetails record in the buffer. Again, both record descriptions are current (live), but only the ShopDetails record description makes sense for the values in the buffer.
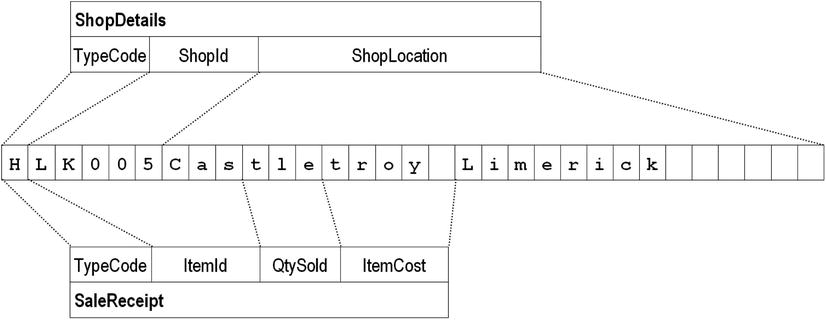
Figure 8-4. Representation of a record buffer that includes the TypeCode
When you examined the file description given in Example 8-2, perhaps it occurred to you to ask, why have condition names been defined only for the ShopDetails record and not for the SaleReceipt record? The answer is that TypeCode in both records maps on to the same area of storage; and that because both record descriptions, including the condition names, are current, it does not matter which record is read into the buffer—the condition names can detect it.
The program specification given at the beginning of the chapter required you to write a program to process the ShopReceiptsFile. For each shop in the file, you were asked to produce a summary line that shows the ShopId and the total value of sales for that shop. The program to implement the specification is given in Listing 8-1.
Listing 8-1. Summarizes the Header and Sale records of the ShopReceiptsFile
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing8-1.
AUTHOR. Michael Coughlan.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
Select ShopReceiptsFile ASSIGN TO "Listing8-1-ShopSales.Dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD ShopReceiptsFile.
01 ShopDetails.
88 EndOfShopReceiptsFile VALUE HIGH-VALUES.
02 RecTypeCode PIC X.
88 ShopHeader VALUE "H".
88 ShopSale VALUE "S".
02 ShopId PIC X(5).
02 ShopLocation PIC X(30).
01 SaleReceipt.
02 RecTypeCode PIC X.
02 ItemId PIC X(8).
02 QtySold PIC 9(3).
02 ItemCost PIC 999V99.
WORKING-STORAGE SECTION.
01 PrnShopSalesTotal.
02 FILLER PIC X(21) VALUE "Total sales for shop ".
02 PrnShopId PIC X(5).
02 PrnShopTotal PIC $$$$,$$9.99.
01 ShopTotal PIC 9(5)V99.
PROCEDURE DIVISION.
ShopSalesSummary.
OPEN INPUT ShopReceiptsFile
READ ShopReceiptsFile
AT END SET EndOfShopReceiptsFile TO TRUE
END-READ
PERFORM SummarizeCountrySales
UNTIL EndOfShopReceiptsFile
CLOSE ShopReceiptsFile
STOP RUN.
SummarizeCountrySales.
MOVE ShopId TO PrnShopId
MOVE ZEROS TO ShopTotal
READ ShopReceiptsFile
AT END SET EndOfShopReceiptsFile TO TRUE
END-READ
PERFORM SummarizeShopSales
UNTIL ShopHeader OR EndOFShopReceiptsFile
MOVE ShopTotal TO PrnShopTotal
DISPLAY PrnShopSalesTotal.
SummarizeShopSales.
COMPUTE ShopTotal = ShopTotal + (QtySold * ItemCost)
READ ShopReceiptsFile
AT END SET EndOfShopReceiptsFile TO TRUE
END-READ.
Some basic test data and the results produced by running the program against this test data are shown in Figure 8-5.
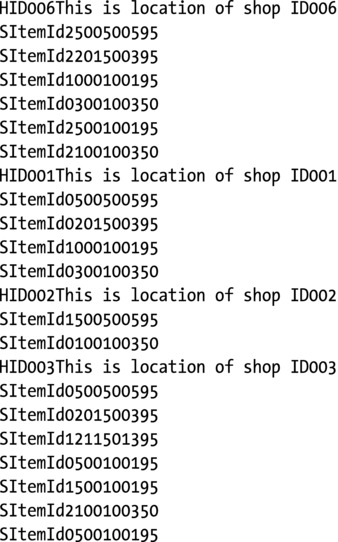

Figure 8-5. Basic test data for Listing 8-1
When you consider the solution produced in Listing 8-1, you may be a little puzzled. Where is the IF statement that checks whether the record is a ShopHeader or a ShopSale record? The answer to this question lies in the approach to the problem solution. Many programmers would solve the problem by having a loop to read the records in the file and an IF statement to check what kind type of record has been read. If a ShopSale record was read, then the required computations would be done; and if a ShopDetails record was read, the summary line would be produced and displayed. This is not a terrible solution for a problem of this size; but when you get to control breaks—a type of problem of which this is a near relation—this type of solution quickly becomes complicated.
The solution adopted in Listing 8-1 involves examining the structure of the records in the ShopReceiptsFile and producing a solution that reflects that structure. What do I mean by the structure of the file? The records in the file are not thrown randomly into the file: they are grouped by shop, and each grouping starts with a ShopDetails header record followed by many SaleReceipt records. The solution in Listing 8-1 reflects the structure of the file. It has a loop to process the SaleReceipt records and an outer loop to process the whole file. You know you have come to the end of the sales records for a particular shop when you encounter the ShopDetails record for the next shop. At that point, you display the summary information you have accumulated for the previous shop. A graphical representation of this solution as applied to the test data is given in Figure 8-6.

Figure 8-6. Representation of the solution as applied to the test data
![]() Note This solution uses the Micro Focus LINE SEQUENTIAL extension. The reason is that when a file contains records of different lengths, the system has to use a record terminator to detect when one record ends and the next begins. The record terminator is specified by the language implementer. Where the terminator is not a fixed implementer default, it can be specified by using the RECORD DELIMITER IS clause in the file’s SELECT and ASSIGN clause.
Note This solution uses the Micro Focus LINE SEQUENTIAL extension. The reason is that when a file contains records of different lengths, the system has to use a record terminator to detect when one record ends and the next begins. The record terminator is specified by the language implementer. Where the terminator is not a fixed implementer default, it can be specified by using the RECORD DELIMITER IS clause in the file’s SELECT and ASSIGN clause.
Because there is no generic, standard way of specifying the terminator, I chose to use the Micro Focus LINE SEQUENTIAL extension. When LINE SEQUENTIAL is used, each record is terminated by the carriage return and line feed ASCII characters. Adopting this extension has the added benefit that the test data can be written using a standard text editor such as Microsoft Notepad.
In a file such as ShopReceiptsFile, which consists of groups that contain a header record followed by many body records, there is often a third type of record. A footer record is frequently used to ensure that the group is complete and that none of the records in the group body has been lost. The footer record might simply contain a count of the records in the group body, or it might do some calculations to produce a checksum.
Let’s amend the ShopReceiptsFile to include the footer record; and let’s amend the specification to say that if the record count in the footer record is not the same as the actual record count, then an error message should be displayed instead of the sales total. The footer record is indicated by the F character.
A program to implement the specification is given in Listing 8-2.
Listing 8-2. Summarizes the Header, Sale, and Footer records of the ShopReceiptsFile
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing8-2.
AUTHOR. Michael Coughlan.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
Select ShopReceiptsFile ASSIGN TO "Listing8-2-ShopSales.dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD ShopReceiptsFile.
01 ShopDetails.
88 EndOfShopReceiptsFile VALUE HIGH-VALUES.
02 TypeCode PIC X.
88 ShopHeader VALUE "H".
88 ShopSale VALUE "S".
88 ShopFooter VALUE "F".
02 ShopId PIC X(5).
02 ShopLocation PIC X(30).
01 SaleReceipt.
02 TypeCode PIC X.
02 ItemId PIC X(8).
02 QtySold PIC 9(3).
02 ItemCost PIC 999V99.
01 ShopSalesCount.
02 TypeCode PIC X.
02 RecCount PIC 9(5).
WORKING-STORAGE SECTION.
01 PrnShopSalesTotal.
02 FILLER PIC X(21) VALUE "Total sales for shop ".
02 PrnShopId PIC X(5).
02 PrnShopTotal PIC $$$$,$$9.99.
01 PrnErrorMessage.
02 FILLER PIC X(15) VALUE "Error on Shop: ".
02 PrnErrorShopId PIC X(5).
02 FILLER PIC X(10) VALUE " RCount = ".
02 PrnRecCount PIC 9(5).
02 FILLER PIC X(10) VALUE " ACount = ".
02 PrnActualCount PIC 9(5).
01 ShopTotal PIC 9(5)V99.
01 ActualCount PIC 9(5).
PROCEDURE DIVISION.
ShopSalesSummary.
OPEN INPUT ShopReceiptsFile
PERFORM GetHeaderRec
PERFORM SummarizeCountrySales
UNTIL EndOfShopReceiptsFile
CLOSE ShopReceiptsFile
STOP RUN.
SummarizeCountrySales.
MOVE ShopId TO PrnShopId, PrnErrorShopId
MOVE ZEROS TO ShopTotal
READ ShopReceiptsFile
AT END SET EndOfShopReceiptsFile TO TRUE
END-READ
PERFORM SummarizeShopSales
VARYING ActualCount FROM 0 BY 1 UNTIL ShopFooter
IF RecCount = ActualCount
MOVE ShopTotal TO PrnShopTotal
DISPLAY PrnShopSalesTotal
ELSE
MOVE RecCount TO PrnRecCount
MOVE ActualCount TO PrnActualCount
DISPLAY PrnErrorMessage
END-IF
PERFORM GetHeaderRec.
SummarizeShopSales.
COMPUTE ShopTotal = ShopTotal + (QtySold * ItemCost)
READ ShopReceiptsFile
AT END SET EndOfShopReceiptsFile TO TRUE
END-READ.
GetHeaderRec.
READ ShopReceiptsFile
AT END SET EndOfShopReceiptsFile TO TRUE
END-READ.
The new test data and the result of running the program against that test data are shown in Figure 8-7.
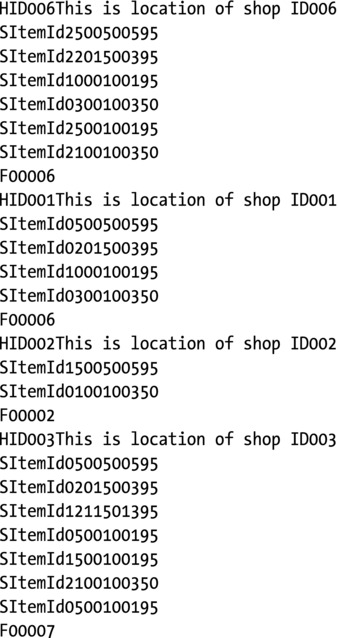

Figure 8-7. Test data and results for Listing 8-2
Some Comments about the Program
The GetHeaderRec paragraph has only one statement. Ordinarily this would be bad practice, but in this instance, I wanted to use the paragraph name to indicate the purpose of this particular READ statement. In a real program, the PERFORM GetHeaderRec statements would be replaced with the READ in the GetHeaderRec paragraph.
The logic of the program has been changed, because now the end of the shop group is indicated by the presence of a footer record. The sale records for each shop group are counted by means of the PERFORM..VARYING. For a variety of reasons, including book space constraints, the only error the program checks for is missing sale receipt records. It is assumed that in all other respects, the file is correct.
In a business or enterprise environment, the ability to print reports is an important property for a programming language. COBOL allows programmers to write to the printer, either directly or through an intermediate print file. COBOL treats the printer as a serial file but uses a special variant of the WRITE verb to control the placement of lines on the page. Printing is regarded as so important that not only does COBOL have the printer sequential files discussed in this section, but it also supports a special set of declarations and verbs that together constitute the COBOL Report Writer. The Report Writer introduces elements of declarative programming to COBOL. It is discussed in detail in a later chapter.
As with ordinary sequential files, the internal name used for the print file is associated with an external device, which could be an actual printer or a print file. A print file is a file that contains embedded printer control codes such as form feed. Generally, you write to a print file; but in a COBOL programming shop, your program may well have direct control of the printer. The metalanguage for print files is given in Figure 8-8. Since ORGANIZATION IS SEQUENTIAL is the default it may be omitted.

Figure 8-8. Print file SELECT and ASSIGN metalanguage
Notes
Where direct control of the printer is assumed, the internal print name is assigned to an ImplementerName, which depends on the vendor. For instance, in HP COBOL (really VAX COBOL), the ImplementerName is LINE-PRINTER (see Example 8-3) and the name is attached to an actual printer by a LINE-PRINTER IS DeviceName entry in the SPECIAL-NAMES paragraph (CONFIGURATION SECTION, ENVIRONMENT DIVISION).
Example 8-3. SELECT and ASSIGN clauses for a Print File and a Print Device
SELECT MembershipReport ASSIGN TO "MembershipRpt.rpt".
SELECT MembershipReport ASSIGN TO LINE-PRINTER.
Even when the Report Writer is not directly used, a report created with a printer sequential file consists of groups of printed lines of different types. For instance, suppose you want to print a report that lists the membership of your local golf club. This report might consist of the following types of print lines:
- Page Heading
Rolling Greens Golf Club - Membership Report - Page Footing
Page: PageNum - Column Headings
MemberID Member Name Type Gender - Membership detail line
MemberID MemberName MembershipType Gender - Report Footing
**** End of Membership Report ****
To set up the printer sequential file, you must create an FD for the file and a print record for each type of print line that will appear on the report. For instance, for the golf club membership report, you have to have the records shown in Example 8-4.
Example 8-4. Print Lines Required for the Golf Club Membership Report
01 PageHeading.
02 FILLER PIC X(44)
VALUE "Rolling Greens Golf Club - Membership Report".
01 PageFooting.
02 FILLER PIC X(15) VALUE SPACES.
02 FILLER PIC X(7) VALUE "Page : ".
02 PrnPageNum PIC Z9.
01 ColumnHeadings PIC X(41)
VALUE "MemberID Member Name Type Gender".
01 MemberDetailLine.
02 FILLER PIC X VALUE SPACES.
02 PrnMemberId PIC 9(5).
02 FILLER PIC X(4) VALUE SPACES.
02 PrnMemberName PIC X(20).
02 FILLER PIC XX VALUE SPACES.
02 PrnMemberType PIC X.
02 FILLER PIC X(4) VALUE SPACES.
02 PrnGender PIC X.
01 ReportFooting PIC X(38)
VALUE "**** End of Membership Report ****".
Problem of Multiple Print Records
When you reviewed the different types of print lines in Example 8-4, you may have realized that there is a problem. As you saw in the previous section, if a file is declared as having multiple record types, all the records map on to the same physical area of storage. This does not cause difficulties if the file is an input file, because only one type of record at a time can be in the buffer. But as you can see from the print line declarations in Example 8-4, the information in many print lines is static. It is assigned using the VALUE clause and instantiated as soon as the program starts. This means all the record values have to be in the record buffer at the same time, which is obviously impossible. In fact, to prevent the creation of print records in the FILE SECTION, there is a COBOL rule stating that, in the FILE SECTION, the VALUE clause can only be used with condition names (that is, it cannot be used to give an item an initial value).
Solution to the Multiple Print Record Problem
The solution to the problem of declaring print records is to declare the print line records in the WORKING-STORAGE SECTION and to declare a record in the file’s FD entry in the FILE SECTION, which is the size of the largest print line record. You print a print line by moving it from the WORKING-STORAGE SECTION, to the record in the FILE SECTION; then that record is written to the print file. This is shown graphically in Example 8-5.
Example 8-5. Writing to a Print File
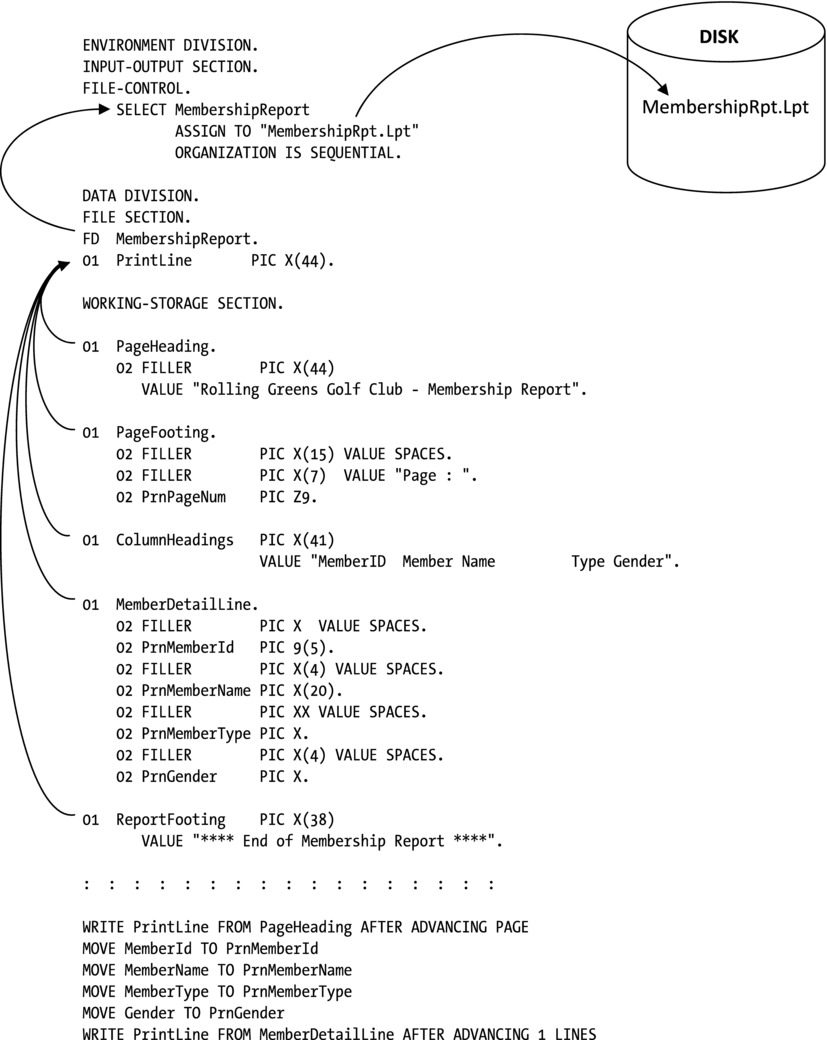
When I discussed the WRITE statement in the previous chapter, I noted that I was postponing discussion of the ADVANCING CLAUSE until I dealt with print files. To refresh your memory, the metalanguage for the WRITE statement is given in Figure 8-9.
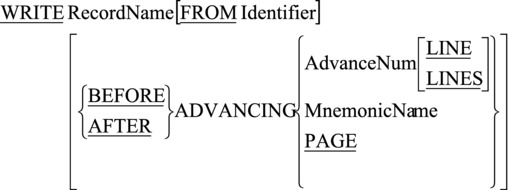
Figure 8-9. Metalanguage for the WRITE verb
The syntax for writing to print files is more complicated than that used for writing in ordinary sequential files because it must contain entries to allow you to control the vertical placement of the print lines. For instance, the statement WRITE PrintLine BEFORE ADVANCING 2 LINES sends the data in PrintLine to the printer, after which the printer advances two lines.
Notes on WRITE
The ADVANCING clause is used to position the lines on the page when writing to a print file or a printer. The ADVANCING clause uses the BEFORE or AFTER phrase to specify whether advancing is to occur before the line is printed or after.
The PAGE option writes a form feed (goes to a new page) to the print file or printer. MnemonicName refers to a vendor-specific page control command. It is defined in the SPECIAL-NAMES paragraph.
When you write to a print file, you generally use the WRITE..FROM option because the print records are described in the WORKING-STORAGE SECTION. When the WRITE..FROM option is used, the data in the source area is moved into the record buffer and then the contents of the buffer are written to the print file. WRITE..FROM is the equivalent of a MOVE SourceItem TO RecordBuffer statement followed by a WRITE RecordBuffer statement.
SOME IGNORED WRITE VERB ENTRIES
I have ignored some print-related formats of the WRITE verb on the basis that if you need this level of print sophistication, you should be using the Report Writer. The full WRITE syntax includes the END-OF-PAGE clause, as shown in the following illustration; this is connected to the LINAGE clause specified in the file’s FD entry. The LINAGE clause specifies the number of lines that can fit on a page, and this in turn allows the end of the page to be automatically detected. If you want to explore this further, you should read your implementer manual.
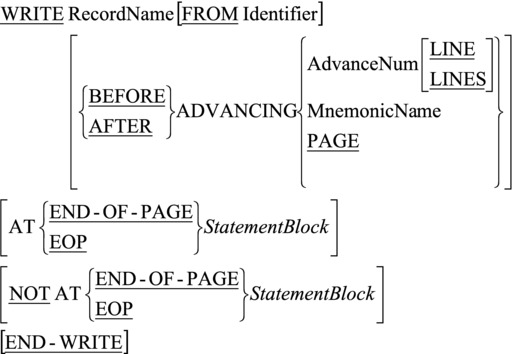
Listing 8-3 contains a program that produces a simple report to show a golf club’s membership list. The program keeps a count of the number of lines printed; it changes the page and prints the headings again when the line count is greater than 49. A page count is also kept, and this is printed at the bottom of each page. The report produced by running the program is shown in Figure 8-10.
Listing 8-3. Program to Print the Golf Club Membership Report
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing8-3.
AUTHOR. Michael Coughlan.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT MembershipReport
ASSIGN TO " Listing8-3-Members.rpt"
ORGANIZATION IS SEQUENTIAL.
SELECT MemberFile ASSIGN TO "Listing8-3Members.dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD MembershipReport.
01 PrintLine PIC X(44).
FD MemberFile.
01 MemberRec.
88 EndOfMemberFile VALUE HIGH-VALUES.
02 MemberId PIC X(5).
02 MemberName PIC X(20).
02 MemberType PIC 9.
02 Gender PIC X.
WORKING-STORAGE SECTION.
01 PageHeading.
02 FILLER PIC X(44)
VALUE "Rolling Greens Golf Club - Membership Report".
01 PageFooting.
02 FILLER PIC X(15) VALUE SPACES.
02 FILLER PIC X(7) VALUE "Page : ".
02 PrnPageNum PIC Z9.
01 ColumnHeadings PIC X(41)
VALUE "MemberID Member Name Type Gender".
01 MemberDetailLine.
02 FILLER PIC X VALUE SPACES.
02 PrnMemberId PIC 9(5).
02 FILLER PIC X(4) VALUE SPACES.
02 PrnMemberName PIC X(20).
02 FILLER PIC XX VALUE SPACES.
02 PrnMemberType PIC X.
02 FILLER PIC X(4) VALUE SPACES.
02 PrnGender PIC X.
01 ReportFooting PIC X(38)
VALUE "**** End of Membership Report ****".
01 LineCount PIC 99 VALUE ZEROS.
88 NewPageRequired VALUE 40 THRU 99.
01 PageCount PIC 99 VALUE ZEROS.
PROCEDURE DIVISION.
PrintMembershipReport.
OPEN INPUT MemberFile
OPEN OUTPUT MembershipReport
PERFORM PrintPageHeadings
READ MemberFile
AT END SET EndOfMemberFile TO TRUE
END-READ
PERFORM PrintReportBody UNTIL EndOfMemberFile
WRITE PrintLine FROM ReportFooting AFTER ADVANCING 5 LINES
CLOSE MemberFile, MembershipReport
STOP RUN.
PrintPageHeadings.
WRITE PrintLine FROM PageHeading AFTER ADVANCING PAGE
WRITE PrintLine FROM ColumnHeadings AFTER ADVANCING 2 LINES
MOVE 3 TO LineCount
ADD 1 TO PageCount.
PrintReportBody.
IF NewPageRequired
MOVE PageCount TO PrnPageNum
WRITE PrintLine FROM PageFooting AFTER ADVANCING 5 LINES
PERFORM PrintPageHeadings
END-IF.
MOVE MemberId TO PrnMemberId
MOVE MemberName TO PrnMemberName
MOVE MemberType TO PrnMemberType
MOVE Gender TO PrnGender
WRITE PrintLine FROM MemberDetailLine AFTER ADVANCING 1 LINE
ADD 1 TO LineCount
READ MemberFile
AT END SET EndOfMemberFile TO TRUE
END-READ.

Figure 8-10. Report produced by Listing 8-3
The Report Writer has been mentioned a number of times in this chapter, so it might be useful to compare the PROCEDURE DIVISION of the program in Listing 8-3 with the PROCEDURE DIVISION of the Report Writer version of the report shown in Example 8-6. How is it able to do so much work with so little PROCEDURE DIVISION code? A short answer is that that is the magic of the Report Writer and declarative programming. A detailed answer will have to wait until I examine the Report Writer in a later chapter.
Example 8-6. PROCEDURE DIVISION for Report Writer Version of the Golf Club Membership Report
PROCEDURE DIVISION.
PrintMembershipReport.
OPEN INPUT MemberFile
OPEN OUTPUT MembershipReport
INITIATE ClubMemebershipReport
READ MemberFile
AT END SET EndOfMemberFile TO TRUE
END-READ
PERFORM UNTIL EndOfMemberFile
GENERATE MemberLine
READ MemberFile
AT END SET EndOfMemberFile TO TRUE
END-READ
END-PERFORM
TERMINATE ClubMemebershipReport
CLOSE MemberFile, MembershipReport
STOP RUN.
COBOL programs normally process fixed-length records, but sometimes files contain records of different lengths. In the first section of this chapter, you saw that a file might consist of a number of different record types. But even though, taken as a whole, the records in the file vary in size, each record type is a fixed-length record. You can, however, have true variable-length records, meaning you do not know the structure or size of the records (although you have to know the maximum size and may know the minimum size). For instance, in an ordinary text file such as might be produced by MS Notepad, the lines of text have no structure and vary in size from line to line. This section demonstrates how files containing true variable-length records may be declared and processed.
FD Entries for Variable-Length Records
When the FD entry for sequential files was introduced, you only saw a simplified version that consisted of the letters FD followed by the file name. Actually, the FD entry can be more complex than you have seen so far, and it can have a large number of subordinate clauses (see your implementer manual or help files). Some of these clauses are not required for all computers. For instance, the BLOCK CONTAINS clause is only required for computers where the number of characters read or written in one I/O operation is under programmatic control. If the block size is fixed, it is not required. Other clauses are syntax retained from previous versions of COBOL and are now treated as comments. I ignore these. Some clauses are important for direct-access file organizations; I deal with these when I examine these file organizations. The RECORD IS VARYING IN SIZE clause allows you to specify that a file contains variable-length records. The metalanguage for the expanded FD entry is given in Figure 8-11 and Example 8-7 demonstrates how to use these new FD entries.
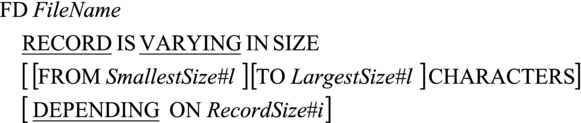
Figure 8-11. RECORD IS VARYING clause for variable-length records
Notes on Varying-Length Records
The RECORD IS VARYING IN SIZE clause without the DEPENDING ON phrase is not strictly required, because the compiler can work out this information from the record sizes. That is why it was not included in the multiple record-type declarations in the first section of this chapter.
The RecordSize#i in the DEPENDING ON phase must be an elementary unsigned integer data-item declared in the WORKING-STORAGE SECTION. When a record defined with the RECORD IS VARYING IN SIZE..DEPENDING ON phrase is read from a file, the length of the record read in to the buffer is moved into the RecordSize#i data item. When a record defined with RECORD IS VARYING IN SIZE..DEPENDING ON is written to a file, the length of the record to be written must first be moved to RecordSize#i data-item, and then the WRITE statement must be executed.
Example 8-7. FD Entries with the RECORD IS VARYING Phrase
FD Textfile
RECORD IS VARYING IN SIZE
FROM 1 TO 80 CHARACTERS
DEPENDING ON TextLineLength.
Orwe may define the file as -
FD Textfile
RECORD IS VARYING IN SIZE
DEPENDING ON TextLineLength.
Listing 8-4 is an example program that demonstrates how to read a file that contains variable-length records. One problem with variable-length records is that although the records are variable length, the buffer into which they are read is fixed in size. So if only the characters that have been read from the file are required, they must be extracted from the record buffer. In this program, reference modification and NameLength are used to slice NameLength number of characters from the buffer. Reference modification is a COBOL string-handling facility that you explore in a later chapter. To demonstrate that you have extracted only the required characters, asterisks are used to bracket the names. Figure 8-12 is a diagrammatic representation of how reference modification is used to extract the name from the record buffer.
Listing 8-4. Processing Variable-Length Records
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing8-4.
AUTHOR. Michael Coughlan.
* This program demonstrates how to read variable length records.
* It also demonstrates how a file may be assigned its actual name
* at run time rather than compile time (dynamic vs static).
* The record buffer is a fixed 40 characters in size but the
* lengths or names vary so Reference Modification is used to extract
* only the number of characters from the record buffer.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT LongNameFile
ASSIGN TO NameOfFile
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD LongNameFile
RECORD IS VARYING IN SIZE
DEPENDING ON NameLength.
01 LongNameRec PIC X(40).
88 EndOfNames VALUE HIGH-VALUES.
WORKING-STORAGE SECTION.
01 NameLength PIC 99.
01 NameOfFile PIC X(20).
PROCEDURE DIVISION.
Begin.
DISPLAY "Enter the name of the file :- "
WITH NO ADVANCING
ACCEPT NameOfFile.
OPEN INPUT LongNameFile.
READ LongNameFile
AT END SET EndOfNames TO TRUE
END-READ
PERFORM UNTIL EndOfNames
DISPLAY "***" LongNameRec(1:NameLength) "***"
READ LongNameFile
AT END SET EndOfNames TO TRUE
END-READ
END-PERFORM
CLOSE LongNameFile
STOP RUN.

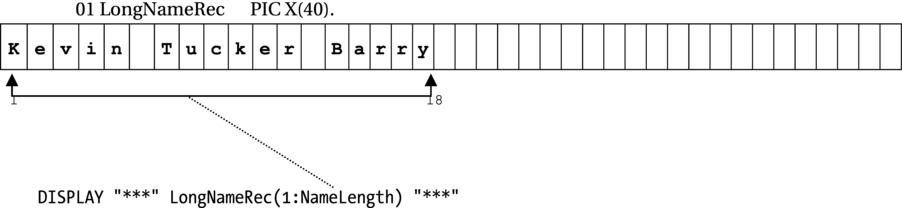
Figure 8-12. Using reference modification to extract the name from the record
Summary
This chapter examined how files that contain records of different lengths may be defined and used. The first section of the chapter dealt with files in which the record lengths are different because the file contains fixed-length records of different types. The last section dealt with files that contain real variable-length records. The middle section of the chapter discussed the problem of print files. It explained why the different types of print lines required when printing a report cannot be declared as different records in the file’s FD entry but must instead be declared in the WORKING-STORAGE SECTION.
In the next chapter, you continue your exploration of printed output by examining edited pictures. Edited pictures allow you to format data for output. In some of the example programs in this and previous chapters, I have used edited pictures without explanation because the context made obvious what was happening. But seeing edited pictures in action and knowing how to use them are different things. The next chapter examines edited pictures in detail and discusses how to format data so that leading zeros are suppressed; so that the currency symbol floats against the non-zero digits of the number; and so that blanks, commas, zeros, and slashes are inserted where they are required. Table 8-1 gives a preview of some of the formatting that can be applied to data.
Table 8-1. Preview of Some of the Edited Picture Formatting Effects
Effect |
Value |
|---|---|
Original value |
00014584.95 |
With commas inserted |
00,014,584.95 |
With zero-suppression added |
14,584.95 |
With check security and currency symbol added |
$***14,584.95 |
With floating + sign |
+14,584.95 |
With floating currency symbol |
$14,584.95 |
With zeros inserted after the decimal point |
$14,584.00 |
With slashes inserted in the middle of the number |
00/014/584.95 |
With three zeros inserted in the number |
00014000584.95 |
With three blanks inserted in the number |
00014 584.95 |
PROGRAMMING EXERCISE 1
It is exercise time again. Now, where did you put that 2B pencil? Write a program to satisfy the following specification.
University Entrants Summary Report
A program is required that will process the first-year-student entrants file (Entrants.dat) to produce a summary that shows the number of first-year students in each course. The summary should be displayed on the screen ordered by ascending CourseCode. An output template is given next.
Output Template
First Year Entrants Summary
Course Code NumOfStudents
LM999 9,999
LM999 9,999
: :
: :
LM999 9,999
LM999 9,999
Total Students: 99,999
Entrants File
The entrants file (Entrants.dat) is a sequential file sequenced on ascending CourseCode. The records in the file have the following description:
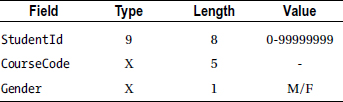
Some Statements You Need for Your Program
To make this programming exercise easier, some of the statements and data declarations required for your program are given next.
Executable Statements
DISPLAY Headingline1
DISPLAY Headingline2
DISPLAY CourseLine
DISPLAY SPACES
DISPLAY FinalTotalLine
MOVE CourseCode TO PrnCourseCode
MOVE CourseTotal TO PrnCourseTotal
MOVE FinalTotal TO PrnFinalTotal
READ EntrantsFile
AT END SET EndOfFile TO TRUE
END-READ
OPEN INPUT EntrantsFile
CLOSE EntrantsFile
ADD 1 TO CourseTotal, FinalTotal
MOVE ZEROS TO CourseTotal
MOVE ZEROS TO FinalTotal
MOVE CourseCode TO PrevCourseCode
Some Data Descriptions
01 HeadingLine1 PIC X(31) VALUE " First Year Entrants Summary".
01 HeadingLine2 PIC X(31) VALUE " Course Code NumOfStudents".
01 CourseLine.
02 FILLER PIC X(5) VALUE SPACES.
02 PrnCourseCode PIC X(5).
02 FILLER PIC X(10) VALUE SPACES.
02 PrnCourseTotal PIC Z,ZZ9.
01 FinalTotalLine.
02 FILLER PIC X(19) VALUE " Total Students:".
02 PrnFinalTotal PIC ZZ,ZZ9.
01 CourseTotal PIC 9(4).
01 FinalTotal PIC 9(5).
01 PrevCourseCode PIC X(5).
PROGRAMMING EXERCISE 2
Change the program you wrote for Programming Exercise 1 so that it now writes the report to a print file.
The answer to this exercise is given below. Because exercise 1 is substantially the same as exercise 2, the same answer should serve both.
PROGRAMMING EXERCISES 1 AND 2: ANSWER
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing8-5.
AUTHOR. Michael Coughlan.
* This program processes the first year students entrants file to produce
* a summary report sequenced on ascending Course Code that shows the number
* of first year students* in each course.
* The Entrants File is a sequential file sequenced on ascending CourseCode.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT EntrantsFile ASSIGN TO "Listing8-5-Entrants.Dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT SummaryReport ASSIGN TO "Listing8-5-Summary.Rpt"
ORGANIZATION IS SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD EntrantsFile.
01 StudentRecord.
88 EndOfEntrantsFile VALUE HIGH-VALUES.
02 StudentId PIC 9(8).
02 CourseCode PIC X(5).
02 Gender PIC X.
FD SummaryReport.
01 PrintLine PIC X(35).
WORKING-STORAGE SECTION.
01 HeadingLine1 PIC X(31) VALUE " First Year Entrants Summary".
01 HeadingLine2 PIC X(31) VALUE " Course Code NumOfStudents".
01 CourseLine.
02 FILLER PIC X(5) VALUE SPACES.
02 PrnCourseCode PIC X(5).
02 FILLER PIC X(10) VALUE SPACES.
02 PrnCourseTotal PIC BBZZ9.
01 FinalTotalLine.
02 FILLER PIC X(19) VALUE " Total Students:".
02 PrnFinalTotal PIC BZ,ZZ9.
01 CourseTotal PIC 9(4) VALUE ZEROS.
01 FinalTotal PIC 9(5) VALUE ZEROS.
01 PrevCourseCode PIC X(5) VALUE ZEROS.
PROCEDURE DIVISION.
ProduceSummaryReport.
OPEN INPUT EntrantsFile
OPEN OUTPUT SummaryReport
WRITE PrintLine FROM HeadingLine1 AFTER ADVANCING PAGE
WRITE PrintLine FROM HeadingLine2 AFTER ADVANCING 2 LINES
READ EntrantsFile
AT END SET EndOfEntrantsFile TO TRUE
END-READ
PERFORM UNTIL EndOfEntrantsFile
MOVE CourseCode TO PrnCourseCode, PrevCourseCode
MOVE ZEROS TO CourseTotal
PERFORM UNTIL CourseCode NOT = PrevCourseCode
ADD 1 TO CourseTotal, FinalTotal
READ EntrantsFile
AT END SET EndOfEntrantsFile TO TRUE
END-READ
END-PERFORM
MOVE CourseTotal TO PrnCourseTotal
WRITE PrintLine FROM CourseLine AFTER ADVANCING 1 LINE
END-PERFORM
MOVE FinalTotal TO PrnFinalTotal
WRITE PrintLine FROM FinalTotalLine AFTER ADVANCING 2 LINES
CLOSE EntrantsFile, SummaryReport
STOP RUN.