
![]()
Processing Sequential Files
Previous chapters introduced the mechanics of creating and reading sequential files. This chapter introduces the two most important sequential-file processing problems: control breaks and the file update problem.
Both control breaks and the file update problem involve manipulating ordered sequential files so the chapter begins with a discussion of how sequential files are organized and the difference between ordered and unordered sequential files.
The next section discusses control-break problems. These normally occur when a hierarchically structured printed report has to be produced. But control breaks are not limited to printed reports. Any problem that processes a stream of ordered data and requires action to be taken when one of the items on which the stream is ordered changes, is a control-break problem.
The final section introduces the file-update problem. This involves the thorny difficulty of how to apply a sequential file of ordered transaction records to an ordered sequential master file. This section starts gently by showing how transaction files containing updates of only a single type may be applied to a master file. I then discuss the record buffer implications of transaction files that contain different types of records and introduce a simplified version of the file-update problem. Finally, I discuss and demonstrate an algorithm, based on academic research, which addresses the full complexity of the file-update problem.
File Organization vs. Method of Access
Two important characteristics of files are data organization and method of access. Data organization refers to the way the file’s records are organized on the backing storage device. COBOL recognizes three main types of file organization:
- Sequential: Records are organized serially.
- Relative: A direct-access file is used and is organized on relative record number.
- Indexed: A direct-access file is used and has an index-based organization.
Method of access refers to the way in which records are accessed. Some approaches to organization are more versatile than others. A file with indexed or relative organization may still have its records accessed sequentially; but the records in a sequential file can only be accessed sequentially.
To understand the difference between file organization and method of access, consider them in the context of a library with a large book collection. Most of the books in the library are organized by Dewey Decimal number; but some, awaiting shelving, are organized in the order in which they were purchased. A reader looking for a book in the main part of the library might find it by looking up its Dewey Decimal number in the library index or might just go the particular section and browse through the books on the shelves. Because the books are organized by Dewey Decimal number, the reader has a choice regarding the method of access. But if the desired book is in the newly acquired section, the reader has no choice. They have to browse through all the titles to find the one they want. This is the difference between direct-access files and sequential files. Direct-access files offer a choice of access methods. Sequential files can only be processed sequentially.
Sequential Organization
Sequential organization is the simplest type of file organization. In a sequential file, the records are arranged serially, one after another, like cards in a dealing shoe. The only way to access a particular record is to start at the first record and read all the succeeding records until the required record is found or until the end of the file is reached.
Sequential files may be ordered or unordered (they should really be called serial files). In an ordered file, the records are sequenced (see Table 10-1) on a particular field in the record, such as CustomerId or CustomerName. In an unordered file, the records are not in any particular order.
Table 10-1. Ordered and Unordered Files
Ordered File |
Unordered File |
|---|---|
Record-KeyA |
Record-KeyM |
The ordering of the records in a file has a significant impact on the way in which it is processed and the processing that can be applied to it.
Control-break processing is a technique generally applied to an ordered sequential file in order to create a printed report. But it can also be used for other purposes such as creating a summary file. For control-break processing to work, the input file must be sorted in the same order as the output to be produced.
A control-break program works by monitoring one or more control items (fields in the record) and taking action when the value in one of the control items changes (the control break). In a control-break program with multiple control-break items, the control breaks are usually hierarchical, such that a break in a major control item automatically causes a break in the minor controls even if the actual value of the minor item does not change. For instance, Figure 10-1 partially models a file that holds details of magazine sales. When the major control item changes from England to Ireland, this also causes the minor control item to break even though its value is unchanged. You can see the logic behind this: it is unlikely that the same individual (Maxwell) lives in both countries.

Figure 10-1. Partial model of a file containing details of magazine sales. A major control break also causes a break of the minor control item
Specifications that Require Control Breaks
To get a feel for the kinds of problems that require a control-break solution, consider the following specifications.
Specification Requiring a Single Control Break
Write a program to process the UnemploymentPayments file to produce a report showing the annual Social Welfare unemployment payments made in each county in Ireland. The report must be printed and sequenced on ascending CountyName. The UnemploymentPayments file is a sequential file ordered on ascending CountyName.
In this specification, the control-break item is the CountyName. The processing required is to sum the payments for a particular county and then, when the county names changes, to print the county name and the total unemployment payments for that county.
Specification Requiring Two Control Breaks
A program is required to process the MagazineSales file to produce a report showing the total spent by customers in each country on magazines. The report must be printed on ascending CustomerName within ascending CountryName. The MagazineSales file is a sequential file ordered on ascending CustomerName within ascending CountryName. Figure 10-1 models the MagazineSales file and shows what is meant by “ordered on ascending CustomerName within ascending CountryName.” Notice how the records are in order of ascending country name, but all the records for a particular country are in order of ascending customer name.
In this specification, the control-break items are the CountryName (major) and the CustomerName (minor).
Specification Requiring Three Control Breaks
Electronics2Go has branches in a number of American states. A program is required to produce a report showing the total sales made by each salesperson, the total sales for each branch, the total sales for each state, and a final total of sales for the entire United States. The report must be printed on ascending SalespersonId within ascending BranchId within ascending StateName.
The report is based on the CompanySales file. This file holds details of sales made in all the branches of the company. It is a sequential file, ordered on ascending SalespersonId, within ascending BranchId, within ascending StateName.
In this specification, the control-break items are the StateName (major), the BranchId (minor), and the SalespersonId (most minor).
A major consideration in a control-break program is how to detect the control break. If you examine the data in Figure 10-1, you can see the control breaks quite clearly. When the country name changes from England to Ireland, a major control break has occurred. When the customer surname changes from Molloy to Power, a minor control break has occurred. It is easy for you to see the control breaks in the data file, but how can you detect these control breaks programmatically?
The way you do this is to compare the value of the control field in the record against the previous value of the control field. How do you know the previous value of the control field? You must store it in a data item specifically set up for the purpose. For instance, if you were writing a control-break program for the data in Figure 10-1, you might create the data items PrevCountryName and PrevCustomerName to store the control-break values. Detecting the control break then simply becomes a matter of comparing the values in these fields with the values in the fields of the current record.
Writing a Control-Break Program
The first instinct programmers seem to have when writing a control-break program is to code the solution as a single loop and to use IF statements (often nested IF statements) to handle the control breaks. This approach results in a cumbersome solution. A better technique is to recognize the structure of the data in the data file and in the report and to create a program that echoes that structure. This echoed structure uses a hierarchy of loops to process the control breaks. This idea is not original; it is essentially that advocated by Michael Jackson in Jackson Structured Programming (JSP).1
When you use this approach, the code for processing each control item becomes
Initialize control items (Totals and PrevControlItems)
Loop Until control break
Finalize control items (Print Totals)
Control-Break Program Template
Example 10-1 gives a template for writing a control-break program. The program structure echoes the structure of the input and output data. The control breaks are processed by a hierarchy of loops, where the inner loop processes the most minor control break.
Example 10-1. Template for Control-Break Programs
OPEN File
Read next record from file
PERFORM UNTIL EndOfFile
MOVE ZEROS TO totals of ControlItem1
MOVE ControlItem1 TO PrevControlItem1
PERFORM UNTIL ControlItem1 NOT EQUAL TO PrevControlItem1
OR EndOfFile
MOVE ZEROS TO totals of ControlItem2
MOVE ControlItem2 TO PrevControlItem2
PERFORM UNTIL ControlItem2 NOT EQUAL TO PrevControlItem2
OR ControlItem1 NOT EQUAL TO PrevControlItem1
OR EndOfFile
Process record
Read next record from file
END-PERFORM
Process totals of ControlItem2
END-PERFORM
Process totals of ControlItem1
END-PERFORM
Process final totals
CLOSE file
Let’s see how all this works in an actual example. As the basis for the example, let’s use a modified version of the three-control-break specification given earlier.
Electronics2Go has branches in a number of American states. A program is required to produce a summary report showing the total sales made by each salesperson, the total sales for each branch, the total sales for each state, and a final total of sales for the entire United States. The report must be printed on ascending SalespersonId in ascending BranchId in ascending StateName.
The report is based on the Electronics2Go sales file. This file holds details of sales made in all the branches of the company. It is a sequential file, ordered on ascending SalespersonId, within ascending BranchId, within ascending StateName. Each record in the sales file has the following description:
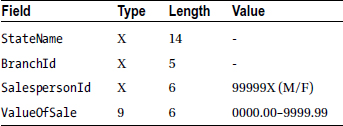
The report format should follow the template in Figure 10-2. In the report template, the SalesTotal field is the sum of the sales made by this salesperson. The Branch Total is the sum of the sales made by each branch. The State Total is the sum of the sales made by all the branches in the state. The Final Total is the sum of the sales made in the United States.

Figure 10-2. Template for the Electronics2Go sales report
In all sales value fields, leading zeros should be suppressed and the dollar symbol should float against the value. The State Name and the Branch should be suppressed after their first occurrence. For simplicity, the headings are only printed once, so no page count or line numbers need be tracked.
![]() Note The full state name is used in every record of the sales file. This is a waste of space. Normally a code representing the state would be used, and the program would convert this code into a state name by means of a lookup table. Because you have not yet encountered lookup tables, I have decided to use the full state name in the file.
Note The full state name is used in every record of the sales file. This is a waste of space. Normally a code representing the state would be used, and the program would convert this code into a state name by means of a lookup table. Because you have not yet encountered lookup tables, I have decided to use the full state name in the file.
Three-Level Control-Break Program
Listing 10-1 shows a program that implements the Electronics2Go Sales Report specification.
Listing 10-1. Three-Control-Break Electronics2Go Sales Report
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing10-1.
AUTHOR. Michael Coughlan.
* A three level Control Break program to process the Electronics2Go
* Sales file and produce a report that shows the value of sales for
* each Salesperson, each Branch, each State, and for the Country.
* The SalesFile is sorted on ascending SalespersonId within BranchId
* within Statename.
* The report must be printed in the same order
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT SalesFile ASSIGN TO "Listing10-1TestData.Dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT SalesReport ASSIGN TO "Listing10-1.RPT"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD SalesFile.
01 SalesRecord.
88 EndOfSalesFile VALUE HIGH-VALUES.
02 StateName PIC X(14).
02 BranchId PIC X(5).
02 SalesPersonId PIC X(6).
02 ValueOfSale PIC 9(4)V99.
FD SalesReport.
01 PrintLine PIC X(55).
WORKING-STORAGE SECTION.
01 ReportHeading.
02 FILLER PIC X(35)
VALUE " Electronics2Go Sales Report".
01 SubjectHeading.
02 FILLER PIC X(43)
VALUE "State Name Branch SalesId SalesTotal".
01 DetailLine.
02 PrnStateName PIC X(14).
88 SuppressStateName VALUE SPACES.
02 PrnBranchId PIC BBX(5).
88 SuppressBranchId VALUE SPACES.
02 PrnSalespersonId PIC BBBBX(6).
02 PrnSalespersonTotal PIC BB$$,$$9.99.
01 BranchTotalLine.
02 FILLER PIC X(43)
VALUE " Branch Total: ".
02 PrnBranchTotal PIC $$$,$$9.99.
01 StateTotalLine.
02 FILLER PIC X(40)
VALUE " State Total : ".
02 PrnStateTotal PIC $$,$$$,$$9.99.
01 FinalTotalLine.
02 FILLER PIC X(39)
VALUE " Final Total :".
02 PrnFinalTotal PIC $$$,$$$,$$9.99.
01 SalespersonTotal PIC 9(4)V99.
01 BranchTotal PIC 9(6)V99.
01 StateTotal PIC 9(7)V99.
01 FinalTotal PIC 9(9)V99.
01 PrevStateName PIC X(14).
01 PrevBranchId PIC X(5).
01 PrevSalespersonId PIC X(6).
PROCEDURE DIVISION.
Begin.
OPEN INPUT SalesFile
OPEN OUTPUT SalesReport
WRITE PrintLine FROM ReportHeading AFTER ADVANCING 1 LINE
WRITE PrintLine FROM SubjectHeading AFTER ADVANCING 1 LINE
READ SalesFile
AT END SET EndOfSalesFile TO TRUE
END-READ
PERFORM UNTIL EndOfSalesFile
MOVE StateName TO PrevStateName, PrnStateName
MOVE ZEROS TO StateTotal
PERFORM SumSalesForState
UNTIL StateName NOT = PrevStateName
OR EndOfSalesFile
MOVE StateTotal TO PrnStateTotal
WRITE PrintLine FROM StateTotalLine AFTER ADVANCING 1 LINE
END-PERFORM
MOVE FinalTotal TO PrnFinalTotal
WRITE PrintLine FROM FinalTotalLine AFTER ADVANCING 1 LINE
CLOSE SalesFile, SalesReport
STOP RUN.
SumSalesForState.
WRITE PrintLine FROM SPACES AFTER ADVANCING 1 LINE
MOVE BranchId TO PrevBranchId, PrnBranchId
MOVE ZEROS TO BranchTotal
PERFORM SumSalesForBranch
UNTIL BranchId NOT = PrevBranchId
OR StateName NOT = PrevStateName
OR EndOfSalesFile
MOVE BranchTotal TO PrnBranchTotal
WRITE PrintLine FROM BranchTotalLine AFTER ADVANCING 1 LINE.
SumSalesForBranch.
MOVE SalespersonId TO PrevSalespersonId, PrnSalespersonId
MOVE ZEROS TO SalespersonTotal
PERFORM SumSalespersonSales
UNTIL SalespersonId NOT = PrevSalespersonId
OR BranchId NOT = PrevBranchId
OR StateName NOT = PrevStateName
OR EndOfSalesFile
MOVE SalespersonTotal TO PrnSalespersonTotal
WRITE PrintLine FROM DetailLine AFTER ADVANCING 1 LINE
SET SuppressBranchId TO TRUE
SET SuppressStateName TO TRUE.
SumSalespersonSales.
ADD ValueOfSale TO SalespersonTotal, BranchTotal, StateTotal, FinalTotal
READ SalesFile
AT END SET EndOfSalesFile TO TRUE
END-READ.
Program Notes
The program in Listing 10-1 is fairly straightforward, once you understand that its structure mirrors the structure of the data and the report. It is interesting to contrast this program with a similar program given on the web site The American Programmer2. That program uses the single loop and IF statement approach mentioned earlier. One objection to this approach is that the three control items are tested for every record in the file.
I draw your attention to the way in which the StateName and BranchId are suppressed after their first occurrence in Listing 10-1. This is done to make the report look less cluttered. To implement the suppression, the condition-name technique that you have seen in a number of other example programs is used. I could have implemented the suppression using a statement such as MOVE SPACES TO PrnStateName, but it would not have been obvious why the data item was being filled with spaces. The purpose of the statement SET SuppressStateName TO TRUE is easier to understand.
Due to space constraints, Figure 10-3 shows only a portion of the test data file and the report produced from that data is shown.
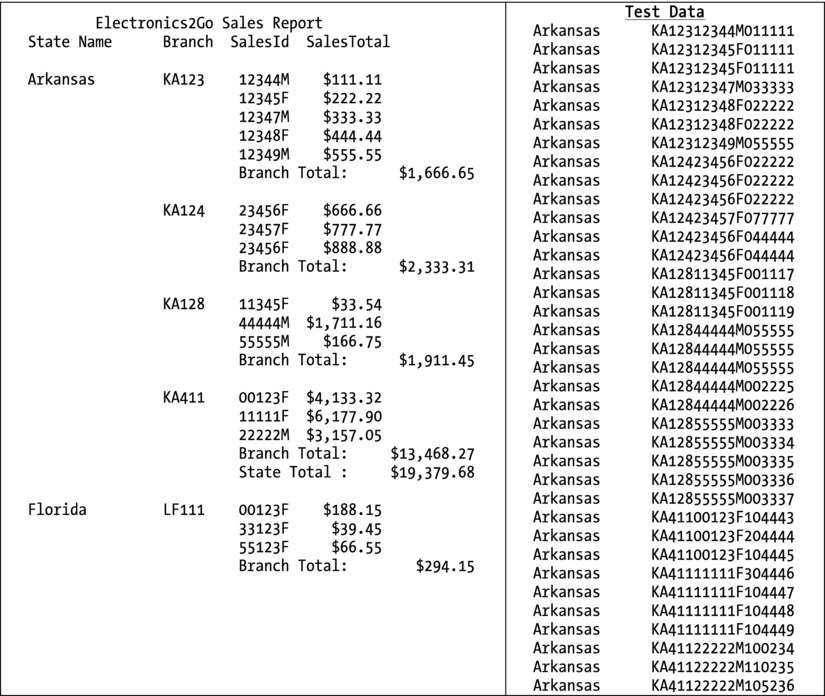
Figure 10-3. Fragment of the report produced and part of the test data file
The program in Listing 10-1 is a typical control-break program, but control-break problems come in a variety of shapes and sizes. For instance, you have probably realized by now that Exercise 1 at the end of the last chapter is a control-break problem but not a typical one. I didn’t provide a solution at the time because I wanted you discover for yourself some of the difficulties with this kind of problem and how easy it is to get dragged into a convoluted solution. Before I present my solution, let’s look at the specification again.
The Genealogists Society of Ireland wishes to discover the most popular surname used in each of the 26 counties in the Irish Republic. In order to obtain this information, the society has acquired a file containing a subset of data from the most recent census.
A program is required that will process the census file and produce a report that shows, for each county, the most popular surname and the number of times it occurs.
The census file is a standard sequential file with fixed-length fields. Each record contains a census number, a surname, and a county name. The file has been sorted and is now ordered on ascending Surname in ascending CountyName. Each record in the file has the following description:

The report should take the format shown in the following report template. The Count field is a count of the number of times the Surname occurs in the county. In the Count field, thousands should be separated using a comma, and the field should be zero-suppressed up to, but not including, the last digit:
Popular Surname Report
CountyName Surname Count
Carlow XXXXXXXXXXXXXXXXXXXX XXX,XXX
Cavan XXXXXXXXXXXXXXXXXXXX XXX,XXX
Clare XXXXXXXXXXXXXXXXXXXX XXX,XXX
:: :: :: :: :: :: :: :: :: :: ::
Westmeath XXXXXXXXXXXXXXXXXXXX XXX,XXX
Wicklow XXXXXXXXXXXXXXXXXXXX XXX,XXX
Wexford XXXXXXXXXXXXXXXXXXXX XXX,XXX
************* end of report ***************
Atypical Control-Break Program
This is not a typical control-break program (see Listing 10-2). Instead of printing the total number of occurrences of the surname when there is a change of surname (as a classic control-break program would do), there is a check to see if this surname is the most popular. A line is printed only when the major control item (the county name) changes. When that happens, the county name and the most popular surname are printed. There is a trap here for the unwary: when the control break occurs, it is too late to move the county name to the print line, because at this point the county name in the buffer is the next county. The solution is to move PrevCountyName to the print line or to, as is done in this program, prime the print line with the correct county name before entering the loop that processes all the surnames in that county.
Listing 10-2. Two-Level Control-Break Program Showing the Most Popular Surnames in the Counties of Ireland
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing10-2.
AUTHOR. Michael Coughlan.
* Control Break program to process the Census file and produce
* a report that shows, for each county, the most popular surname
* and the number of times it occurs.
* The Records in the sequential Census file are ordered on
* ascending Surname within ascending CountyName.
* The report must be printed in ascending CountyName order
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT CensusFile ASSIGN TO "Listing10-2TestData.Dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT SurnameReport ASSIGN TO "Listing10-2.RPT"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD CensusFile.
01 CensusRec.
88 EndOfCensusFile VALUE HIGH-VALUES.
02 CensusNum PIC 9(8).
02 Surname PIC X(20).
02 CountyName PIC X(9).
FD SurnameReport.
01 PrintLine PIC X(45).
WORKING-STORAGE SECTION.
01 ReportHeading.
02 FILLER PIC X(13) VALUE SPACES.
02 FILLER PIC X(22)
VALUE "Popular Surname Report".
01 SubjectHeading.
02 FILLER PIC X(42)
VALUE "CountyName Surname Count".
01 CountySurnameLine.
02 PrnCountyName PIC X(9).
02 FILLER PIC X(3) VALUE SPACES.
02 PrnSurname PIC X(20).
02 PrnCount PIC BBBZZZ,ZZ9.
01 ReportFooter PIC X(43)
VALUE "************* end of report ***************".
01 PrevCountyName PIC X(9).
01 PrevSurname PIC X(20).
01 MostPopularSurname PIC X(20).
01 MostPopularCount PIC 9(6).
01 SurnameCount PIC 9(6).
PROCEDURE DIVISION.
Begin.
OPEN INPUT CensusFile
OPEN OUTPUT SurnameReport
WRITE PrintLine FROM ReportHeading AFTER ADVANCING 1 LINE
WRITE PrintLine FROM SubjectHeading AFTER ADVANCING 1 LINE
READ CensusFile
AT END SET EndOfCensusFile TO TRUE
END-READ
PERFORM UNTIL EndOfCensusFile
MOVE CountyName TO PrevCountyName, PrnCountyName
MOVE ZEROS TO MostPopularCount
MOVE SPACES TO MostPopularSurname
PERFORM FindMostPopularSurname
UNTIL CountyName NOT EQUAL TO PrevCountyName
OR EndOfCensusFile
MOVE MostPopularCount TO PrnCount
MOVE MostPopularSurname TO PrnSurname
WRITE PrintLine FROM CountySurnameLine AFTER ADVANCING 1 LINE
END-PERFORM
WRITE PrintLine FROM ReportFooter AFTER ADVANCING 2 LINES
CLOSE CensusFile, SurnameReport
STOP RUN.
FindMostPopularSurname.
MOVE Surname TO PrevSurname
PERFORM CountSurnameOccurs VARYING SurnameCount FROM 0 BY 1
UNTIL Surname NOT EQUAL TO PrevSurname
OR CountyName NOT EQUAL TO PrevCountyName
OR EndOfCensusFile
IF SurnameCount > MostPopularCount
MOVE SurnameCount TO MostPopularCount
MOVE PrevSurname TO MostPopularSurname
END-IF.
CountSurnameOccurs.
READ CensusFile
AT END SET EndOfCensusFile TO TRUE
END-READ.
Program Notes
The census file is ordered on ascending Surname in ascending CountyName, and that is the same order required for the printed report. The control items are CountyName and Surname. The data items PrevSurname and PrevCountyName are used to detect the control breaks. Similar to Listing 10-1, the structure of this program echoes the structure of the input file and the output report.
Figure 10-4 shows the report produced by the program and a small portion of the test data file used.
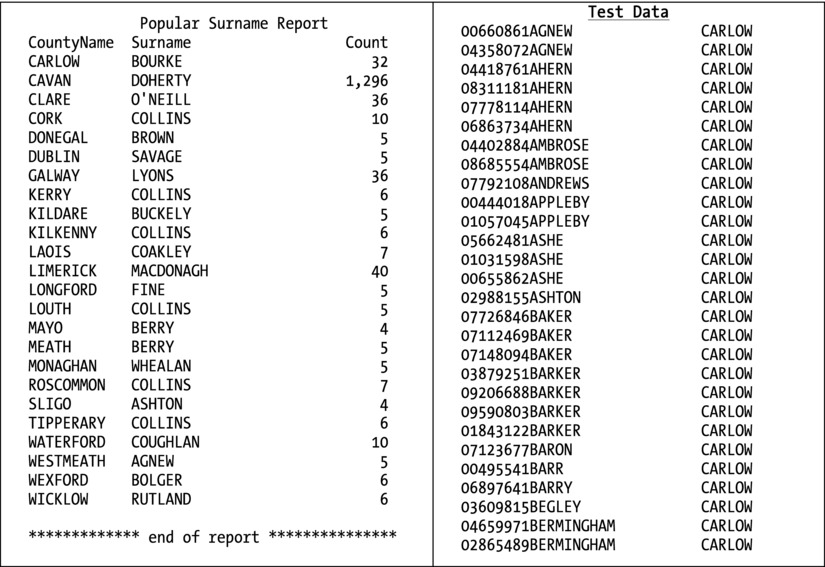
Figure 10-4. The report produced by the program, and part of the test data file
It is easy to add records to an unordered sequential file because you can simply add them to the end of the file by opening the file for EXTEND. For instance:
OPEN EXTEND UnorderedFile
WRITE UnorderedRec
When a file is OPENed for EXTEND, the Next Record Pointer is positioned at the end of the file. When records are written to the file, they are appended to the end.
Although you can add records to an unordered sequential file, the records in a sequential file cannot be deleted or updated in situ. The only way to delete records from a sequential file is to create a new file, which does not contain them; and the only way to update records is to create a new file that contains the updated records. A record update involves changing the value of one or more of its fields. For instance, you might change the value of the CustomerAddress or CustomerPhoneNumber field of a customer record, or you might change the value of the QtyInStock or ReorderLevel field of a stock record.
![]() COBOL Detail Although, in standard COBOL, sequential files cannot be deleted or updated in situ many vendors, including Micro Focus, allow this for disk-based files.
COBOL Detail Although, in standard COBOL, sequential files cannot be deleted or updated in situ many vendors, including Micro Focus, allow this for disk-based files.
Because updating or deleting records in a sequential file requires you to read all the records in the file and to create a new file that has the changes applied to it, it is computationally too expensive to apply these operations to the file one at a time. Updates to sequential files are normally done in batch mode. That is, all the updates are gathered together into what is often referred to as the transaction file and then applied to the target file in one go or batch. The target file is often referred to as the master file.
As you have seen, you can add records to an unordered sequential file by opening the file for EXTEND and writing the records to the end of it. But if you want to update or delete records, you must have a way of identifying the record you want to update or delete. A key field is normally used to achieve this. A key field is a field in the record whose value can be used to identify that record. For instance, in a stock record, the StockNumber might be used as the key field. When you apply transaction records to a master file, you compare the key field in the transaction record with that in the master file record. If there is a match, you can apply the delete or update to that master file record. This key-comparison operation is called record matching.
For record matching to work correctly, the transaction file and the master file must be ordered on the same key value. Record matching does not work if either file is unordered or if the files are ordered on different key fields. If you need convincing of this, PERFORM (that is, go there, do the exercise, and then come back) the Language Knowledge Exercise at the end of the chapter. That exercise will help you understand the problems of trying to apply batched transactions to an unordered master file.
Applying Transactions to an Ordered Sequential File
You start this section by looking at programming templates that show how to apply each type of transaction (insertion, deletion, and update) to an ordered sequential file. To complicate matters, most transaction files consist of a mixture of transaction types. Therefore, this section considers the data-declaration implications of mixed transaction types, and you examine an example program that applies a variety of transaction types to an ordered sequential file.
Inserting Records in an Ordered Sequential File
When you want to add records to an unordered sequential file, you just OPEN the file for EXTEND and then write the records to the file. You can’t do that with an ordered sequential file because if you do, the records will no longer be in order.
When you insert records into an ordered sequential file, a major consideration must be to preserve the ordering. To insert records, you must create a new file that consists of all the records of the old file with the new records inserted into their correct key-value positions. When you are inserting records into an ordered file, you also have to be aware of the possibility that the record you are trying to insert will have the same key value as one already in the file. This is an error condition. For instance, you can’t have two customer records with the same CustomerId value.
Figure 10-5 is a template that outlines the algorithm required to insert records from an ordered transaction file into their correct positions in an ordered master file. There are three files. The transaction file (TF) contains the three records you want to insert. The master file (MF) is the file into which you wish to insert these records. Because the MF is a sequential file, the only way to insert the records is to create a new file that contains the inserted records. This is the new master file (NMF).
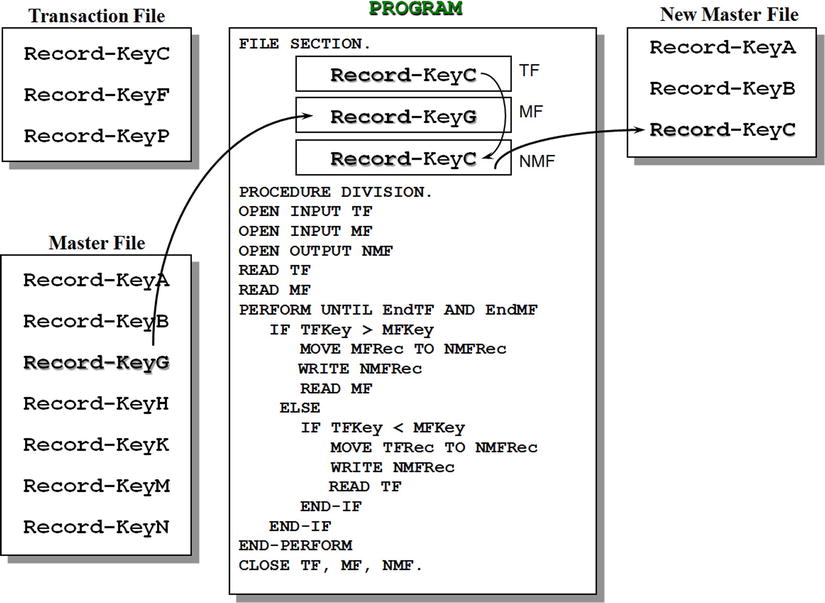
Figure 10-5. Inserting records into an ordered sequential file
The program starts by opening the files and reading a record from each of the two input files. This is the equivalent of the read-ahead technique that you saw in Chapter 5. Before you enter the loop that processes the files, you start with a record in each file buffer. The loop is executed until the end of both files, because regardless of which file ends first, the remaining records of the other must be written to the NMF.
With Record-KeyC in one buffer (TF) and Record-KeyA in the other (MF), the key field values are compared. When the transaction is greater than the master (as is the case here), the condition indicates that the position where the transaction record must be inserted has not yet been reached, so the MF record is written to the NMF. Because the MF record in the buffer has been dealt with (consumed), you read the MF to get a new record. This is the record: Record-KeyB.
When the key values are compared, the transaction key is still greater the master, so this record too is written to the NMF and another is read from the MF. This is the record: Record-KeyG.
Now you have reached the point in the program captured by Figure 10-5. This time, the key value in the TF is less than that of the MF, so the transaction record is written to the NMF. Because the record in the TF buffer has been consumed, a new record is read into the buffer, and the process continues until both files end.
To simplify the template, the condition where the key values are equal has been omitted. If this condition occurs, then a transaction error has occurred, because for record-matching purposes, the key values must be unique.
If you examine the algorithm provided, you might be puzzled that there appears to be no code to write out the remaining records to the NMF when one file ends before the other. The explanation for this lies in the end-of-file condition name associated with each file. These might be described as in Example 10-2.
Example 10-2. Partial Record Descriptions for the Transaction and Master Files
FD TransactionFile
01 TFRec.
88 EndTF VALUE HIGH-VALUES.
02 TFKey PIC X(?).
etc
FD MasterFile
01 MFRec.
88 EndMF VALUE HIGH-VALUES.
02 MFKey PIC X(?).
etc
When the end of either file is encountered, its associated condition name is set to true; this has the side effect of filling its record area (including its key field) with HIGH-VALUES (the highest possible character value). Subsequent key comparisons cause the remaining records to be written to the NMF. For instance, from the test data in Figure 10-1, it is clear that the TF will end first. When the EndTF condition name is set to true, TFkey contains HIGH-VALUES. In the key comparison, TFKey is greater than MFKey, and this results in the master record being written to the NMF. If the MF ends first, MFKey is filled with HIGH-VALUES, and the key comparisons then causes the remaining transaction records to be written to the NMF.
Updating Records in an Ordered Sequential File
The template for updating records in an ordered sequential file is shown in Figure 10-6. The diagram captures the program action at the point where Record-KeyH has been read into the TF record buffer and the MF record buffer. Both records are combined to produce the updated record Record-KeyH+, which is then sent to the NMF.
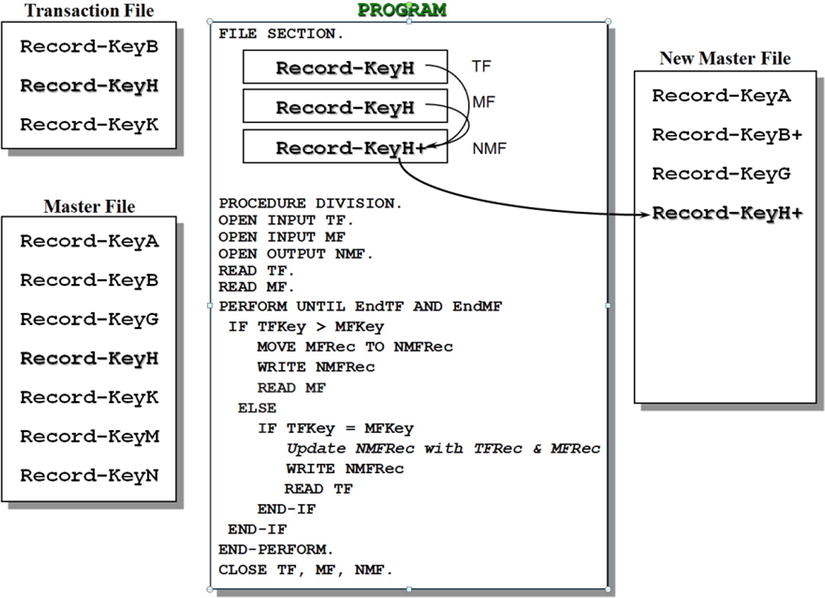
Figure 10-6. Updating records in an ordered sequential file
When you apply an update to the MF, you combine the records from the TF and the MF because the transaction record only consists of the key field and the field(s) to be updated. For instance, in a stock-file update, the update record in the TF might contain the fields shown in Example 10-3, whereas the MF might contain those shown in Example 10-4.
Example 10-3. Fields in the Update Record of a Transaction File
FD TransactionFile.
01 TFRec.
02 StockId-TF PIC X(?).
02 QtyInStock-TF PIC 9(?).
Example 10-4. Fields in the Record of a Stock Master File
FD StockMasterFile.
01 StockMFRec.
02 StockId-MF PIC X(?).
02 Description-MF PIC X(?).
02 ManfId-MF PIC X(?).
02 ReorderLevel-MF PIC 9(?).
02 ReorderQty-MF PIC 9(?).
02 QtyInStock-MF PIC 9(?).
The template in Figure 10-6 does not check for the error condition where the record to be updated does not exist in the MF. This condition is detected when the value in TFKey is less than that in MFKey. You can test this yourself by including the record Record-KeyD in the transaction file and then applying the transactions manually.
Deleting Records from an Ordered Sequential File
Figure 10-7 shows the template for deleting records from an ordered sequential file. The diagram captures the action just after Record-KeyK has been read into the MF record buffer. When the keys are equal, you have found the MF record to be deleted. So what action do you take to delete it? No action! You just don’t send it to the NMF. Because both the transaction record and the master record have been consumed, you need to get the next record from each file.
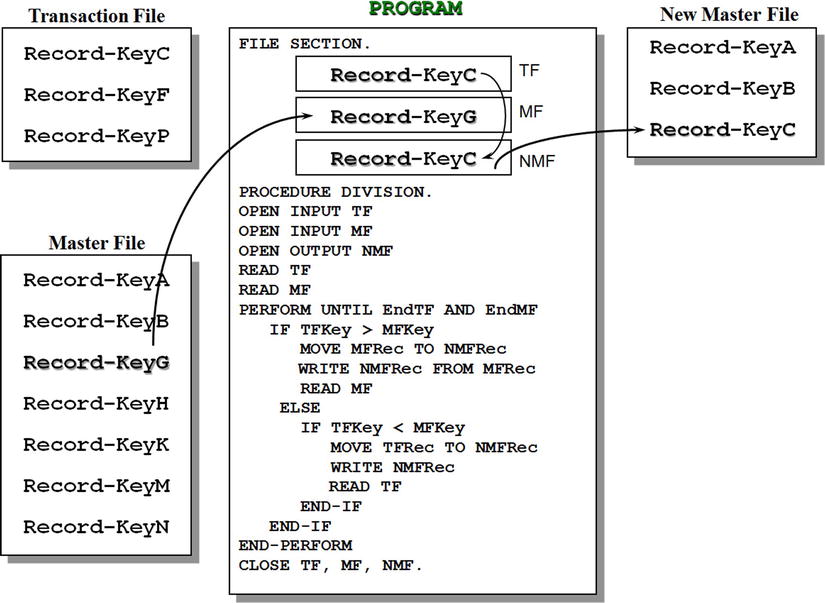
Figure 10-7. Deleting records from an ordered sequential file
When I discussed how to update an ordered sequential file, I noted that the transaction record contained fewer fields than the MF record. The delete operation takes this even further. To delete a record, the transaction record only needs the key field.
As before, the template does not check for the error condition where the record to be deleted does not exist in the MF. Just like the update operation, this condition is detected when the value in TFKey is less than that in MFKey. You can test this yourself by adding the record Record-KeyC to the records in the TF and then applying the transactions manually.
The File-Update Problem: Simplified
The previous section showed how various types of updates can be applied to an ordered sequential file. But you considered each of these types of updates in isolation. The TF consisted of records of only one type; it contained a batch of deletions, or a batch of insertions, or a batch of updates. In reality, all these different kinds of transaction records would be gathered together into one transaction file. Having multiple record types in the transaction file is good for processing efficiency, but it considerably complicates the update logic.
The problem of how to update an ordered sequential file is known as the file-update problem. The file-update problem is much more difficult than it appears on the surface and has been the subject of some research. Of particular interest is Barry Dwyer’s paper “One More Time—How to Update a Master File.3” The algorithm described in his paper is implemented in Listing 10-2.
This section considers a simplified version of updating a file containing multiple record types. In this version, multiple updates for a particular master record are allowed, but an insertion record cannot be followed by any other operation for the same record. That restriction reveals the further levels of complexity of the file-update problem. Obviously, in a stock file, there might be a number of stock movements (additions and subtractions from stock) for a particular stock item. But in some cases, there might be an insertion for a particular stock item followed by stock movements and other updates for that item. In such a situation, the order in which the transactions are applied is important, because obviously you want to insert the record before you apply updates to it. These and other issues considerably complicate the file-update problem.
Updating a Stock File: Problem Specification
To explore some of the complexities of applying transactions of different types to a master file, consider the following problem specification.
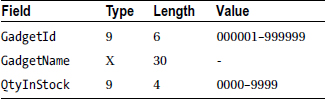
A stock file holds details of gadgets sold by Gadget Shop (GadgetShop.Com). It is a sequential file sorted on ascending GadgetId. Each record in the file has the following description:
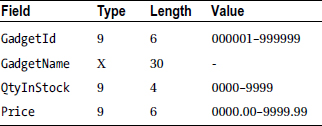
To update the stock file, a number of different kinds of update records have been gathered together into a sequential transaction file.
The records in transaction file have seen sorted into ascending GadgetId order. Within GadgetId, the transactions are sorted by the order in which they were submitted. There are three different types of transaction records: insertion records to add a new line of stock, deletion records to delete a line of stock, and price-change records change the Price of a line of stock. Obviously, you could also have stock-movement records to add and subtract inventory from the QtyInStock field, but that would needlessly complicate this example.
Because there are three different types of records in the transaction file, you need to have three different record descriptions. But as you discovered in Chapter 8, when a file contains multiple types of records, you must have some way of identifying which record type has been read into the record buffer. To distinguish one type of record from another, a special field called a type code is inserted into each transaction record. In the transaction file used to update Gadget Shop’s stock file, a type code value of 1 is used to represent insertions, 2 represents deletions, and 3 represents a price change. The records in the transaction file have the following descriptions:
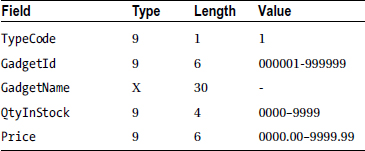
Deletion Record

Price Change Record
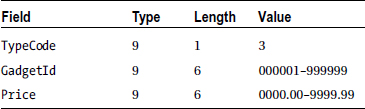
Because there are three different types of records in the file, you must have three record descriptions in the FD entry for the transaction file (see Example 10-5).
Example 10-5. Record Descriptions for the Transaction File
FD TransactionFile.
01 InsertionRec.
02 TypeCode PIC 9.
02 GadgetId PIC 9(6).
02 GadgetName PIC X(30).
02 QtyInStock PIC 9(4).
02 Price PIC 9(4)V99.
01 DeletionRec.
02 TypeCode PIC 9.
02 GadgetID PIC 9(6).
01 PriceChangeRec.
02 TypeCode PIC 9.
02 GadgetID PIC 9(6).
02 Price PIC 9(4)V99.
Buffer Implications of Multiple Record Types
You discovered in Chapter 8 that when a file contains multiple record types, a record declaration (starting with a 01 level number) must be created for each type of record. But even though there are different types of records in the file, and there are separate record declarations for each record type, only a single record buffer is created for the file. All the record descriptions map on to this area of storage, which is the size of the largest record. Figure 10-8 shows the mapping of the transaction records on to the record buffer. All the identifiers in all the mapped records are current/active at the same time, but only one set of identifiers makes sense for the particular record in the buffer. In Figure 10-8, the record in the buffer is an insertion record (TypeCode = 1), so even though you could execute the statement MOVE Price TO PrnPrice, it wouldn’t make sense to do so. Because there is an insertion record in the buffer, Price has the value “Ice Cr.”
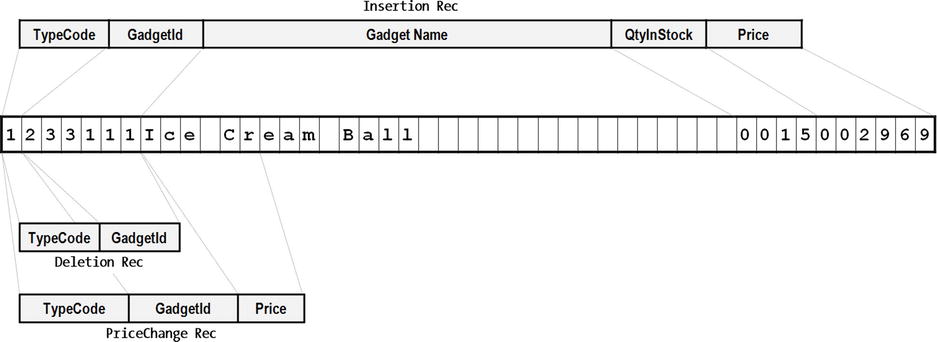
Figure 10-8. Schematic showing the mapping of records on to the record buffer
When you examine the record descriptions in Example 10-5 and the record schematic in Figure 10-8, you may notice that both TypeCode and GadgetId occur in all three record descriptions. You may wonder if is it permitted to use the same data name in different records. And if it is permitted, how can the data name be referenced uniquely?
Although it is legal to use the same data name in different records (but not in the same group item), in order to uniquely identify the record you want, you must qualify it with the record or group name. For instance, you can refer to the GadgetId in PriceChangeRec by using the form GadgetId OF PriceChangeRec.
But even though it is legal to declare GadgetId in all the records, and even though you must declare the storage for GadgetId in all the records, you don’t actually need to use the name GadgetId in all the records. Because all the records map on to the same area of storage, it does not matter which GadgetId you refer to—they all access the same value in the record. So no matter which record is in the buffer, a statement that refers to GadgetId OF InsertRec will still access the correct value.
The same logic applies to the TypeCode. The TypeCode is in the same place in all three record types, so it doesn’t matter which one you use—they all access the same area of memory. When an area of storage must be declared, but you don’t care what name you give it, you don’t have to make up a dummy name. You use the special name FILLER.
Example 10-6 shows a revised version of the three record descriptions. In this version, only the items that have to be named are given data names. The record schematic for this revised version is shown in Figure 10-9.
Example 10-6. Revised Record Descriptions
FD TransactionFile.
01 InsertionRec.
02 TypeCode PIC 9.
02 GadgetId PIC 9(6).
02 GadgetName PIC X(30).
02 QtyInStock PIC 9(4).
02 Price PIC 9(4)V99.
01 DeletionRec.
02 FILLER PIC 9(7).
01 PriceChangeRec.
02 FILLER PIC 9(7).
02 Price PIC 9(4)V99.

Figure 10-9. Mapping of transaction records on to the record buffer
The program required to apply the transaction file to the gadget stock file is shown in Listing 10-3.
Listing 10-3. File Update—Insert not followed by updates to inserted record
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing10-3.
AUTHOR. Michael Coughlan
* Applies the transactions ordered on ascending GadgetId-TF to the
* MasterStockFile ordered on ascending GadgetId-MF.
* Assumption: Insert not followed by updates to inserted record
* Multiple updates per master record permitted
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT MasterStockFile ASSIGN TO "Listing10-3Master.dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT NewStockFile ASSIGN TO "Listing10-3NewMast.dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT TransactionFile ASSIGN TO "Listing10-3Trans.dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD MasterStockFile.
01 MasterStockRec.
88 EndOfMasterFile VALUE HIGH-VALUES.
02 GadgetId-MF PIC 9(6).
02 GadgetName-MF PIC X(30).
02 QtyInStock-MF PIC 9(4).
02 Price-MF PIC 9(4)V99.
FD NewStockFile.
01 NewStockRec.
02 GadgetId-NSF PIC 9(6).
02 GadgetName-NSF PIC X(30).
02 QtyInStock-NSF PIC 9(4).
02 Price-NSF PIC 9(4)V99.
FD TransactionFile.
01 InsertionRec.
88 EndOfTransFile VALUE HIGH-VALUES.
02 TypeCode-TF PIC 9.
88 Insertion VALUE 1.
88 Deletion VALUE 2.
88 UpdatePrice VALUE 3.
02 GadgetId-TF PIC 9(6).
02 GadgetName-IR PIC X(30).
02 QtyInStock-IR PIC 9(4).
02 Price-IR PIC 9(4)V99.
01 DeletionRec.
02 FILLER PIC 9(7).
01 PriceChangeRec.
02 FILLER PIC 9(7).
02 Price-PCR PIC 9(4)V99.
WORKING-STORAGE SECTION.
01 ErrorMessage.
02 PrnGadgetId PIC 9(6).
02 FILLER PIC XXX VALUE " - ".
02 FILLER PIC X(45).
88 InsertError VALUE "Insert Error - Record already exists".
88 DeleteError VALUE "Delete Error - No such record in Master".
88 PriceUpdateError VALUE "Price Update Error - No such record in Master".
PROCEDURE DIVISION.
Begin.
OPEN INPUT MasterStockFile
OPEN INPUT TransactionFile
OPEN OUTPUT NewStockFile
PERFORM ReadMasterFile
PERFORM ReadTransFile
PERFORM UNTIL EndOfMasterFile AND EndOfTransFile
EVALUATE TRUE
WHEN GadgetId-TF > GadgetId-MF PERFORM CopyToNewMaster
WHEN GadgetId-TF = GadgetId-MF PERFORM TryToApplyToMaster
WHEN GadgetId-TF < GadgetId-MF PERFORM TryToInsert
END-EVALUATE
END-PERFORM
CLOSE MasterStockFile, TransactionFile, NewStockFile
STOP RUN.
CopyToNewMaster.
WRITE NewStockRec FROM MasterStockRec
PERFORM ReadMasterFile.
TryToApplyToMaster.
EVALUATE TRUE
WHEN UpdatePrice MOVE Price-PCR TO Price-MF
WHEN Deletion PERFORM ReadMasterFile
WHEN Insertion SET InsertError TO TRUE
DISPLAY ErrorMessage
END-EVALUATE
PERFORM ReadTransFile.
TryToInsert.
IF Insertion MOVE GadgetId-TF TO GadgetId-NSF
MOVE GadgetName-IR TO GadgetName-NSF
MOVE QtyInStock-IR TO QtyInStock-NSF
MOVE Price-Ir TO Price-NSF
WRITE NewStockRec
ELSE
IF UpdatePrice
SET PriceUpdateError TO TRUE
END-IF
IF Deletion
SET DeleteError TO TRUE
END-IF
DISPLAY ErrorMessage
END-IF
PERFORM ReadTransFile.
ReadTransFile.
READ TransactionFile
AT END SET EndOfTransFile TO TRUE
END-READ
MOVE GadgetId-TF TO PrnGadgetId.
ReadMasterFile.
READ MasterStockFile
AT END SET EndOfMasterFile TO TRUE
END-READ.
Program Notes
Three files are used in the program. The master file, the transaction file and the new master file. The gadget stock file is known as the MasterStockFile, the transaction file is called the TransactionFile, and the new master file, produced by applying the transactions to the master file is known as the NewStockFile.
Applying the updates requires a considerable amount of data movement from fields in one stock record to another. To avoid the tedium of having to qualify each field reference, a suffix has been applied to the relevant fields to distinguish them from one another. The suffix MF (master File) is applied to records of the MasterStockFile, NSF is applied to records of the NewStockFile, and TF is applied to the common fields (TypeCode and GadgetId) of the TransactionFile.
Reading the TransactionFile and the MasterStockFile are operations that occur in a number of places. To avoid having to write out the READ statement in full each time, I have placed them in a paragraph which I then invoke by means of a PERFORM. While this makes the program textually shorter, you should be aware that performance will be impacted. Similarly, I have placed the statement MOVE GadgetId-TF TO PrnGadgetId in the ReadTransFile paragraph where it sets the GadgetId into the ErrorMessage every time a record is read. This placement means only one instance of this statement is required but again this saving is achieved at the cost of a slight impact on performance (because you really only need to do this if there is an error).
The GadgetId is moved into the ErrorMessage area every time a transaction record is read but you may be wondering how the actual error message gets into the ErrorMessage area. I won’t go into a full explanation here but I will remind you that when a condition name is set to TRUE it pushes its value item into the associated data item. If that isn’t a sufficient hint, then you may need to review Chapter 5 where condition names were discussed.
The paragraph CopyToNewMaster copies the MasterStockFile record to the NewStockFile when there are no transactions to be applied to the MasterStockFile record (GadgetId-TF > GadgetId-MF) but it is also the paragraph that writes the MasterStockRec after updates have been applied to it. How does this happen? Consider this sequence of events happening in the program:
GadgetId-TF = GadgetId-MF and an update is applied to the MasterStockRec
The next transaction record is read
GadgetId-TF = GadgetId-MF and another update is applied to the MasterStockRec
The next transaction record is read (because the transaction records are in ascending sequence this transaction must be equal to or greater than the master)
GadgetId-TF > GadgetId-MF and the updated MasterStockRec is written to the NewStockFile
When the keys are equal, the update is applied to the MasterStockRec, when eventually the transaction key is greater than the master file key (the only possible condition because the files are ordered), the updated record is written to the new master file.
The test data files for the program are given Figure 10-10. As usual, I’ve kept them short because of space constraints and to make them easy to understand. For the transaction file, I have taken advantage of the fact the record buffer is the size of the largest record, to add text that identifies the purpose of each test. For instance, a delete record in a real transaction file would only consist of the type code and the key.
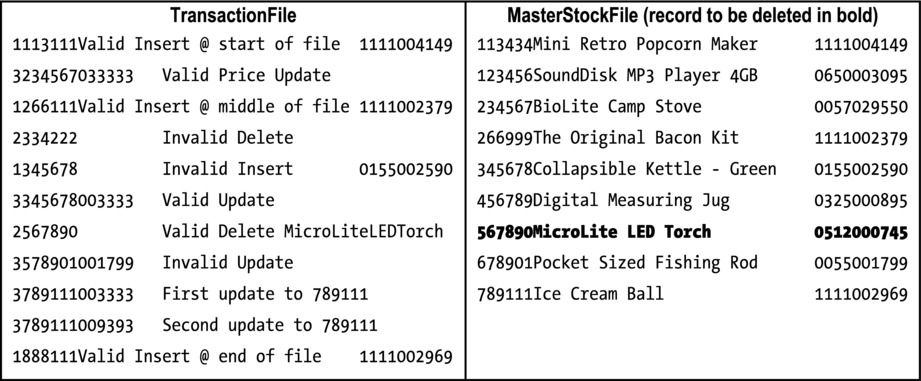
Figure 10-10. Test data and results
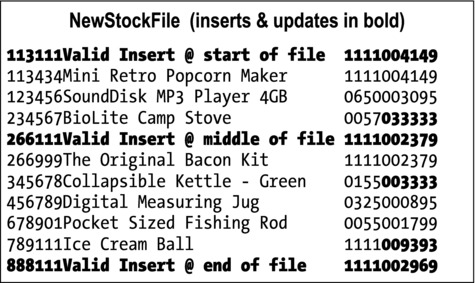
The results from running the program are shown in Figure 10-11.

Listing 10-3 provides a gentle introduction to the file update problem but the algorithm used in that program only works for a limited form of the problem. The algorithm does not work when an insert can be followed by updates to the record to be inserted. The reason the algorithm does not work for the extended version of problem is that now the updates can be applied to either the master file or the transaction file. In the Listing 10-3 algorithm, the updates are applied only to the master file. This seemingly small change makes the task a very slippery fish indeed. The moment you think you have solved the problem by placing a read here or a write there some other difficulty rears its ugly head. The best way to get a feel for the complications that this simple specification change causes, is to try it yourself. Using Listing 10-3 as the basis for your program, attempt to change the program so that it also allows an insertion to be followed by updates to the inserted record.
Fortunately, you don’t have to rely on your own resources to come up with a solution. People have gone before you, and you can stand on their shoulders. Listing 10-4 demonstrates a solution to the problem based on the algorithm described by Barry Dwyer in “One More Time - How to Update a Master File.”3
The main elements of the algorithm are the ChooseNextKey and SetInitialStatus paragraphs, the RecordInMaster and RecordNotInMaster condition names, and the loop PERFORM ProcessOneTransaction UNTIL GadgetID-TF NOT = CurrentKey.
ChooseNextKey allows the program to decide if the transaction file or the master file will be the focus of updates. The key of whichever file is the focus is recorded in CurrentKey.
SetInitialStatus uses the condition names RecordInMaster and RecordNotInMaster to record whether or not the record is currently included in the master file. Later the RecordInMaster condition name is used to decide whether the record is to be included in the new master file.
The ProcessOneTransaction loop applies all the transactions that apply to the record of focus while the keys are equal. When the loop exits, the RecordInMaster condition name is tested to see if the record of focus should be included in the new master file.
Listing 10-4 is the final program.
Listing 10-4. Caption
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing10-4.
AUTHOR. Michael Coughlan
* File Update program based on the algorithm described by Barry Dwyer in
* "One more time - How to update a Master File"
* Applies the transactions ordered on ascending GadgetId-TF to the
* MasterStockFile ordered on ascending GadgetId-MF.
* Within each key value records are ordered on the sequence in which
* events occurred in the outside world.
* All valid, real world, transaction sequences are accommodated
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT MasterStockFile ASSIGN TO "Listing10-4Master.dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT NewStockFile ASSIGN TO "Listing10-4NewMast.dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT TransactionFile ASSIGN TO "Listing10-4Trans.dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD MasterStockFile.
01 MasterStockRec.
88 EndOfMasterFile VALUE HIGH-VALUES.
02 GadgetID-MF PIC 9(6).
02 GadgetName-MF PIC X(30).
02 QtyInStock-MF PIC 9(4).
02 Price-MF PIC 9(4)V99.
FD NewStockFile.
01 NewStockRec.
02 GadgetID-NSF PIC 9(6).
02 GadgetName-NSF PIC X(30).
02 QtyInStock-NSF PIC 9(4).
02 Price-NSF PIC 9(4)V99.
FD TransactionFile.
01 InsertionRec.
88 EndOfTransFile VALUE HIGH-VALUES.
02 TypeCode-TF PIC 9.
88 Insertion VALUE 1.
88 Deletion VALUE 2.
88 UpdatePrice VALUE 3.
02 RecordBody-IR.
03 GadgetID-TF PIC 9(6).
03 GadgetName-IR PIC X(30).
03 QtyInStock-IR PIC 9(4).
03 Price-IR PIC 9(4)V99.
01 DeletionRec.
02 FILLER PIC 9(7).
01 PriceChangeRec.
02 FILLER PIC 9(7).
02 Price-PCR PIC 9(4)V99.
WORKING-STORAGE SECTION.
01 ErrorMessage.
02 PrnGadgetId PIC 9(6).
02 FILLER PIC XXX VALUE " - ".
02 FILLER PIC X(45).
88 InsertError VALUE "Insert Error - Record already exists".
88 DeleteError VALUE "Delete Error - No such record in Master".
88 PriceUpdateError VALUE "Price Update Error - No such record in Master".
01 FILLER PIC X VALUE "n".
88 RecordInMaster VALUE "y".
88 RecordNotInMaster VALUE "n".
01 CurrentKey PIC 9(6).
PROCEDURE DIVISION.
Begin.
OPEN INPUT MasterStockFile
OPEN INPUT TransactionFile
OPEN OUTPUT NewStockFile
PERFORM ReadMasterFile
PERFORM ReadTransFile
PERFORM ChooseNextKey
PERFORM UNTIL EndOfMasterFile AND EndOfTransFile
PERFORM SetInitialStatus
PERFORM ProcessOneTransaction
UNTIL GadgetID-TF NOT = CurrentKey
* CheckFinalStatus
IF RecordInMaster
WRITE NewStockRec
END-IF
PERFORM ChooseNextKey
END-PERFORM
CLOSE MasterStockFile, TransactionFile, NewStockFile
STOP RUN.
ChooseNextKey.
IF GadgetID-TF < GadgetID-MF
MOVE GadgetID-TF TO CurrentKey
ELSE
MOVE GadgetID-MF TO CurrentKey
END-IF.
SetInitialStatus.
IF GadgetID-MF = CurrentKey
MOVE MasterStockRec TO NewStockRec
SET RecordInMaster TO TRUE
PERFORM ReadMasterFile
ELSE SET RecordNotInMaster TO TRUE
END-IF.
ProcessOneTransaction.
* ApplyTransToMaster
EVALUATE TRUE
WHEN Insertion PERFORM ApplyInsertion
WHEN UpdatePrice PERFORM ApplyPriceChange
WHEN Deletion PERFORM ApplyDeletion
END-EVALUATE.
PERFORM ReadTransFile.
ApplyInsertion.
IF RecordInMaster
SET InsertError TO TRUE
DISPLAY ErrorMessage
ELSE
SET RecordInMaster TO TRUE
MOVE RecordBody-IR TO NewStockRec
END-IF.
ApplyDeletion.
IF RecordNotInMaster
SET DeleteError TO TRUE
DISPLAY ErrorMessage
ELSE SET RecordNotInMaster TO TRUE
END-IF.
ApplyPriceChange.
IF RecordNotInMaster
SET PriceUpdateError TO TRUE
DISPLAY ErrorMessage
ELSE
MOVE Price-PCR TO Price-NSF
END-IF.
ReadTransFile.
READ TransactionFile
AT END SET EndOfTransFile TO TRUE
END-READ
MOVE GadgetID-TF TO PrnGadgetId.
ReadMasterFile.
READ MasterStockFile
AT END SET EndOfMasterFile TO TRUE
END-READ.
Program Notes
I have incorporated an optimization in Listing 10-4 that might welcome some explanation. Before you write an insert record to the master file in Listing 10-3, the fields in the record are transferred one by one to the NewStockRec. You couldn’t just move the InsertionRec to the NewStockRec because the InsertionRec also includes the TypeCode field. In Listing 10-4, this problem has been solved by restructuring the Insertion records so that the fields you have to move to the NewStockRec are subordinate to a group item called RecordBody-IR. This means in Listing 10-4, instead of moving the contents of the insertion record to the new master record field by field, you just MOVE RecordBody-IR TO NewStockRec. The record schematic for this restructured record is shown in Figure 10-12. The record remains the same size. But now you have an additional data name with which to manipulate the data in the record.
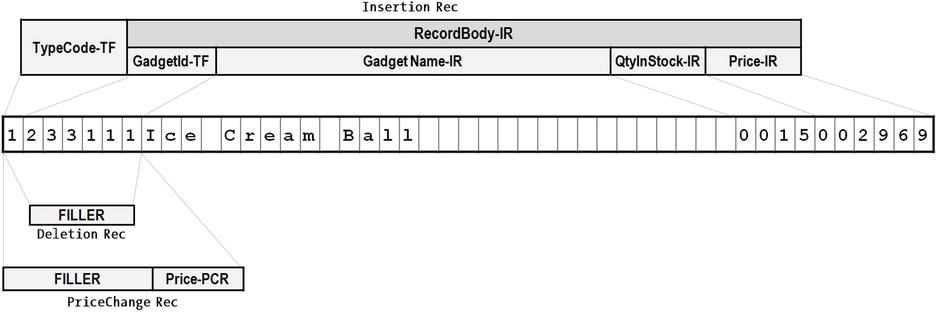
Figure 10-12. Revised record schematic showing the restructured Insertion record
The test data for the program is shown in Figure 10-13.
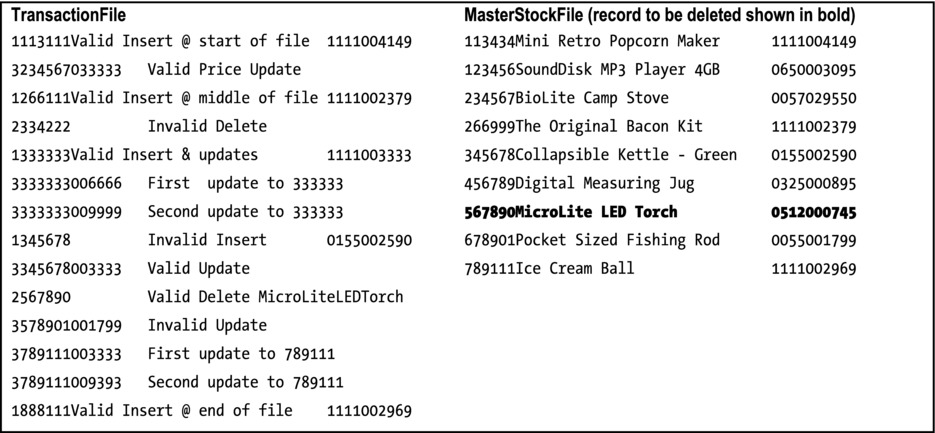
Figure 10-13. Test data for Listing 10-4
The result of running the program against that test data is shown in Figure 10-14.
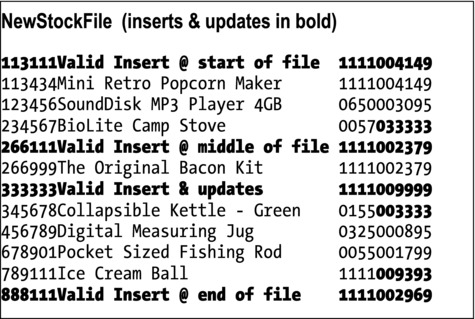
Figure 10-14. Results of running Listing 10-4
Summary
This chapter introduced two of the most important sequential file processing problems. The chapter began by examining how sequential files are organized and discussing the difference between ordered and unordered sequential files. The next section introduced the class of problems known as control-break problems. The final section introduced the thorny problem of the sequential File Update.
The section that discussed control-break problems included an example program to produce a printed report involving a three level control break. A second example program implemented an atypical control break problem and was intended to show that a control break solution may be applied to a number of different types of problem.
In the final section, I discussed how to apply updates to an ordered sequential file and included two examples programs. The first example implemented a solution to a simplified version of the file update problem while the second applied the algorithm described by Dwyer3 and Dijkstra.4
In the specification for Listing 10-1, I mentioned that using the full state name in every record was very wasteful and that a more realistic scenario would use a state code instead of the full name. I noted that in that case you would have to convert the state code to a state name by means of a lookup table. In the next chapter, which will discuss how tabular data is implemented in COBOL, you revisit the Listing 10-1 specification to create a more realistic scenario that will require you to incorporate a state lookup table into the program.
LANGUAGE KNOWLEDGE EXERCISE
Unleash your 2B pencil once more. It is time for some exercises. These exercises are designed to allow you to prove to yourself that it is not possible to update an unordered sequential file.
No answers are provided for these questions.
- The transaction file and the master file in Figure 10-15 are unordered sequential files. Using the algorithm outlined in Figure 10-15 manually attempt to update the master file records to produce a new master file that contains the updated records.
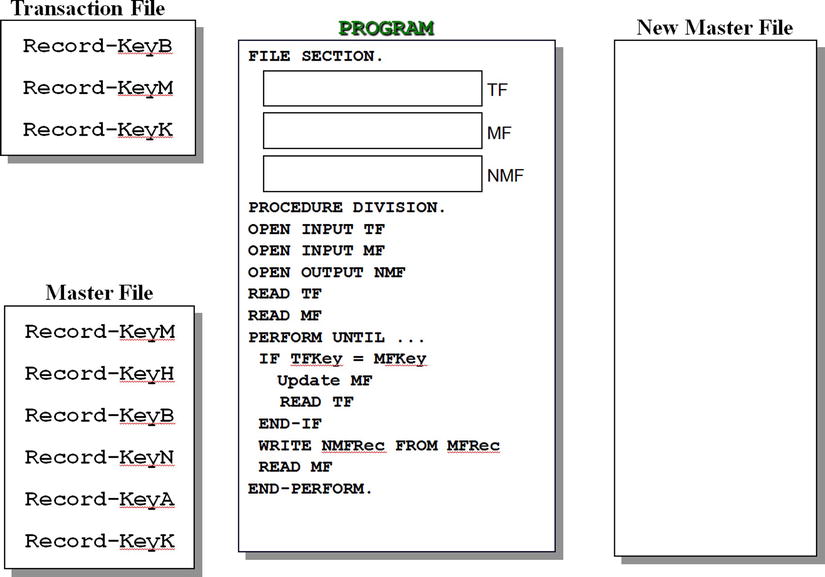
Figure 10-15. Attempting to update an unordered sequential file
- The transaction file and the master file in Figure 10-15 are unordered sequential files. Using the algorithm outlined in Figure 10-16 manually attempt to delete the master file records to produce a new master file that does not contain the deleted records.
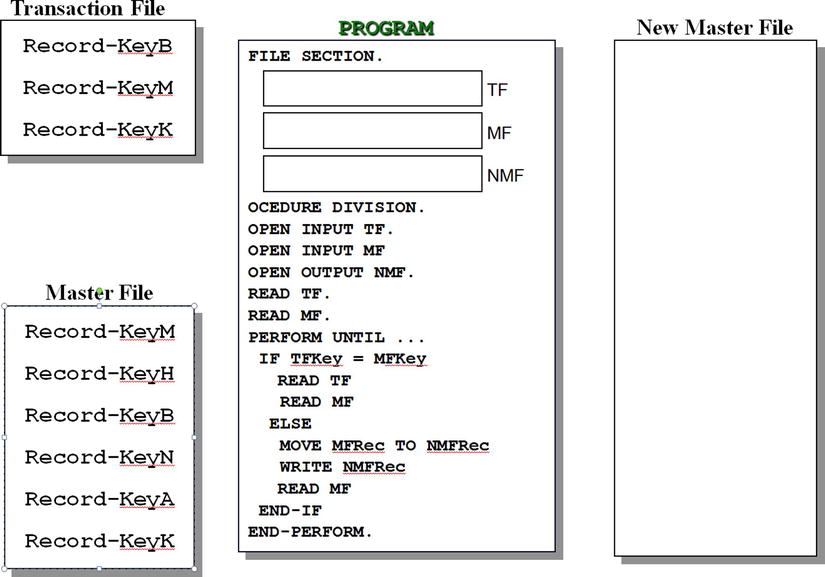
Figure 10-16. Attempting to delete from an unordered sequential file
PROGRAMMING EXERCISE
Listing 10-4 applies the File Update algorithm described by Dwyer3 to implement an update of the Gadget Shop’s Stock MF. However, in that implementation only the Price field is updated. Now you need to modify that program so that it can also update the QtyInStock field.
Change the program in Listing 10-4 so that it handle stock movement updates as well as price change updates. To accommodate this change in the specification two new record types will have to be added to the transaction file. These new transaction records are the AddToStock record indicated by a type code of 4 and the SubtractFromStock record indicated by a type code of 5.
The record descriptions for the MF and the new version of the TF are given here.
The Stock MF is a sequential file ordered on ascending GadgetId. Each record has the following description.
StockMaster Record
The TF is a sequential file ordered on ascending GadgetId. In each set of records with the same GadgetId the records are ordered in sequence in which the transactions occurred in the real world. Records in the TF have the following descriptions:
Insertion record
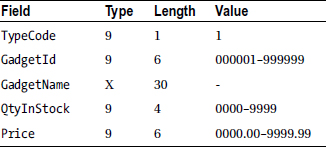
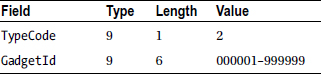
PriceChange record

AddToStock record
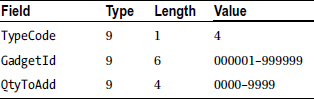
SubtractFromStock record
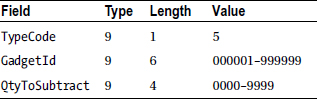
TestData
To test your program you can use the test data shown below in Figure 10-17.
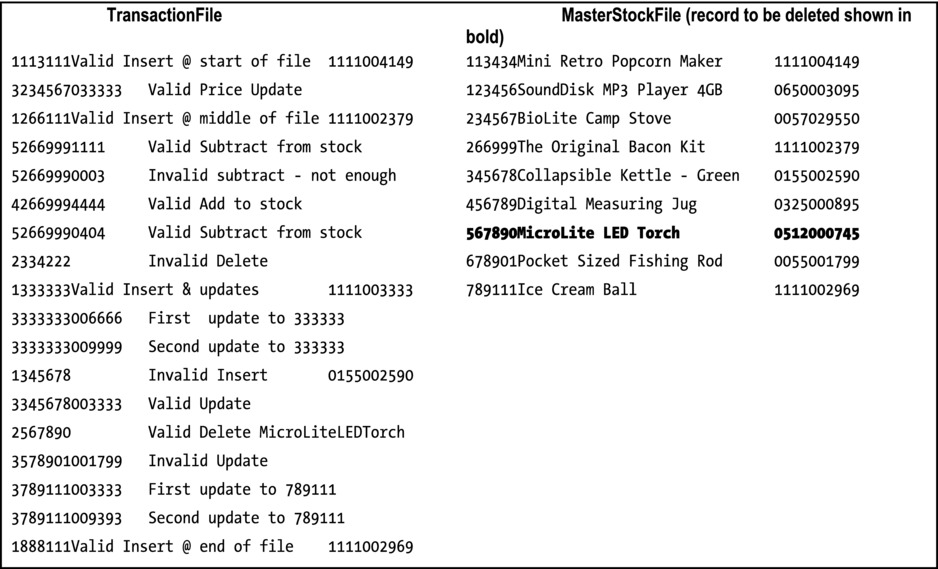
Figure 10-17. Test data including add and subtract from stock transactions
Notes
There is an additional error conditions to be noted. If the GadgetId-TF < GadgetId-MF and the type code is 4 or 5 then an error has occurred (no matching master file record) but it is also an error if the transaction is a SubtractFromStock record but the QtyInStock in the MF is less than the QtyToSubtract in the SubtractFromStock record
PROGRAMMING EXERCISE - ANSWER
Listing 10-5. Update with added AddToStock and SubtractFromStock transactions
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing10-5.
AUTHOR. Michael Coughlan
* File Update program based on the algorithm described by Barry Dwyer in
* "One more time - How to update a Master File"
* Applies the transactions ordered on ascending GadgetId-TF to the
* MasterStockFile ordered on ascending GadgetId-MF.
* Within each key value records are ordered on the sequence in which
* events occurred in the outside world.
* All valid, real world, transaction sequences are accommodated
* This version includes additions and subtractions from QtyInStock
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT MasterStockFile ASSIGN TO "Listing10-5Master.dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT NewStockFile ASSIGN TO "Listing10-5NewMast.dat"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT TransactionFile ASSIGN TO "Listing10-5Trans.dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD MasterStockFile.
01 MasterStockRec.
88 EndOfMasterFile VALUE HIGH-VALUES.
02 GadgetID-MF PIC 9(6).
02 GadgetName-MF PIC X(30).
02 QtyInStock-MF PIC 9(4).
02 Price-MF PIC 9(4)V99.
FD NewStockFile.
01 NewStockRec.
02 GadgetID-NSF PIC 9(6).
02 GadgetName-NSF PIC X(30).
02 QtyInStock-NSF PIC 9(4).
02 Price-NSF PIC 9(4)V99.
FD TransactionFile.
01 InsertionRec.
88 EndOfTransFile VALUE HIGH-VALUES.
02 TypeCode-TF PIC 9.
88 Insertion VALUE 1.
88 Deletion VALUE 2.
88 UpdatePrice VALUE 3.
88 StockAddition VALUE 4.
88 StockSubtraction VALUE 5.
02 RecordBody-IR.
03 GadgetID-TF PIC 9(6).
03 GadgetName-IR PIC X(30).
03 QtyInStock-IR PIC 9(4).
03 Price-IR PIC 9(4)V99.
01 DeletionRec.
02 FILLER PIC 9(7).
01 PriceChangeRec.
02 FILLER PIC 9(7).
02 Price-PCR PIC 9(4)V99.
01 AddToStock.
02 FILLER PIC 9(7).
02 QtyToAdd PIC 9(4).
01 SubtractFromStock.
02 FILLER PIC 9(7).
02 QtyToSubtract PIC 9(4).
WORKING-STORAGE SECTION.
01 ErrorMessage.
02 PrnGadgetId PIC 9(6).
02 FILLER PIC XXX VALUE " - ".
02 FILLER PIC X(46).
88 InsertError VALUE "Insert Error - Record already exists".
88 DeleteError VALUE "Delete Error - No such record in Master".
88 PriceUpdateError VALUE "Price Update Error - No such record in Master".
88 QtyAddError VALUE "Stock Add Error - No such record in Master".
88 QtySubtractError VALUE "Stock Subtract Error - No such record in Master".
88 InsufficientStock VALUE "Stock Subtract Error - Not enough stock".
01 FILLER PIC X VALUE "n".
88 RecordInMaster VALUE "y".
88 RecordNotInMaster VALUE "n".
01 CurrentKey PIC 9(6).
PROCEDURE DIVISION.
Begin.
OPEN INPUT MasterStockFile
OPEN INPUT TransactionFile
OPEN OUTPUT NewStockFile
PERFORM ReadMasterFile
PERFORM ReadTransFile
PERFORM ChooseNextKey
PERFORM UNTIL EndOfMasterFile AND EndOfTransFile
PERFORM SetInitialStatus
PERFORM ProcessOneTransaction
UNTIL GadgetID-TF NOT = CurrentKey
* CheckFinalStatus
IF RecordInMaster
WRITE NewStockRec
END-IF
PERFORM ChooseNextKey
END-PERFORM
CLOSE MasterStockFile, TransactionFile, NewStockFile
STOP RUN.
ChooseNextKey.
IF GadgetID-TF < GadgetID-MF
MOVE GadgetID-TF TO CurrentKey
ELSE
MOVE GadgetID-MF TO CurrentKey
END-IF.
SetInitialStatus.
IF GadgetID-MF = CurrentKey
MOVE MasterStockRec TO NewStockRec
SET RecordInMaster TO TRUE
PERFORM ReadMasterFile
ELSE SET RecordNotInMaster TO TRUE
END-IF.
ProcessOneTransaction.
* ApplyTransToMaster
EVALUATE TRUE
WHEN Insertion PERFORM ApplyInsertion
WHEN UpdatePrice PERFORM ApplyPriceChange
WHEN Deletion PERFORM ApplyDeletion
WHEN StockAddition PERFORM ApplyAddToStock
WHEN StockSubtraction PERFORM ApplySubtractFromStock
END-EVALUATE.
PERFORM ReadTransFile.
ApplyInsertion.
IF RecordInMaster
SET InsertError TO TRUE
DISPLAY ErrorMessage
ELSE
SET RecordInMaster TO TRUE
MOVE RecordBody-IR TO NewStockRec
END-IF.
ApplyDeletion.
IF RecordNotInMaster
SET DeleteError TO TRUE
DISPLAY ErrorMessage
ELSE SET RecordNotInMaster TO TRUE
END-IF.
ApplyPriceChange.
IF RecordNotInMaster
SET PriceUpdateError TO TRUE
DISPLAY ErrorMessage
ELSE
MOVE Price-PCR TO Price-NSF
END-IF.
ApplyAddToStock.
IF RecordNotInMaster
SET QtyAddError TO TRUE
DISPLAY ErrorMessage
ELSE
ADD QtyToAdd TO QtyInStock-NSF
END-IF.
ApplySubtractFromStock.
IF RecordNotInMaster
SET QtySubtractError TO TRUE
DISPLAY ErrorMessage
ELSE
IF QtyInStock-NSF < QtyToSubtract
SET InsufficientStock TO TRUE
DISPLAY ErrorMessage
ELSE
SUBTRACT QtyToSubtract FROM QtyInStock-NSF
END-IF
END-IF.
ReadTransFile.
READ TransactionFile
AT END SET EndOfTransFile TO TRUE
END-READ
MOVE GadgetID-TF TO PrnGadgetId.
ReadMasterFile.
READ MasterStockFile
AT END SET EndOfMasterFile TO TRUE
END-READ.
1Michael Jackson. Principles of Program Design. Academic Press, 1975.
2The Three Level Subtotal (Control Break) COBOL Program, TheAmericanProgrammer.Com, http://theamericanprogrammer.com/programming/08-brklv3.shtml.
3Barry Dwyer. 1981. One more time — how to update a master file. Commun. ACM 24, 1 (January 1981), 3-8. DOI=10.1145/358527.358534 http://doi.acm.org/10.1145/358527.358534.
4Dijkstra, E.W. A Discipline of Programming. Prentice-Hall, Englewood Cliffs, N.J.,1976.