
![]()
When I learned COBOL many years ago, direct access files, and particularly indexed files, were the jewel in COBOL’s crown. No other mainstream programming language provided native support for file organizations of such versatility. Nowadays, the predominance of databases means that the importance of direct access files in modern COBOL programming is greatly reduced. Nevertheless, the huge inventory of legacy programs that still use direct access files makes these file organizations a worthwhile topic of discussion.
This chapter introduces you to COBOL’s direct access file organizations: indexed and relative files. These organizations are called direct access organizations because they allow you to access data records directly based on a key field. Direct access files are more versatile than sequential files. They let you update or delete records in situ and access records sequentially or directly using a key field. Needless to say, direct access files only work on direct access media such as hard disks. You can’t use indexed or relative files with serial media such as magnetic tapes. To take advantage of the versatility of direct access files, you use a number of new COBOL verbs and concepts. This chapter introduces the DELETE, REWRITE, and START verbs and the concepts of file status, the key of reference, and the next-record pointer.
Sequential, indexed, and relative file organizations all have strengths and weaknesses. No one organization is best for all situations. This chapter concludes with a discussion of the advantages and disadvantages of all the COBOL file organizations and when you should use one rather than another.
Direct Access vs.Sequential Files
As you learned in Chapter 10, access to records in a sequential file is serial. To reach a particular record, you must read all the preceding records. You also learned that if the sequential file is unordered, the only practical operations are to read records from the file or add records to the end of the file. It is impractical to update records or delete records in an unordered sequential file. In addition, even if the file is ordered, inserting, updating, or deleting records is a problem because when you apply these operations, you must preserve the ordering of the file—and the only way to do that is to create a copy of the file to which these operations have been applied.
Although sequential files have a number of advantages over other types of file organization (as discussed in the final section of this chapter), the fact that you must create a new file when you delete, update, or insert records is problematic.
These problems are addressed by direct access files. Direct access files allow you to read, update, delete, and insert individual records in situ on the basis of a key value. For instance, to delete a customer record in a direct access file, you supply the customer ID of the record to be deleted and then execute a DELETE statement.
In COBOL, there are two direct access file organizations: relative files and indexed files.
Organization of Relative Files
Before you see how relative files are declared and used, let’s look at how they are organized. As you can see from the schematic representation in Figure 17-1, the records in a relative file are organized on ascending relative record number. You can visualize a relative file as a one-dimensional table stored on disk, and you can think of the relative record number as the index into that table.
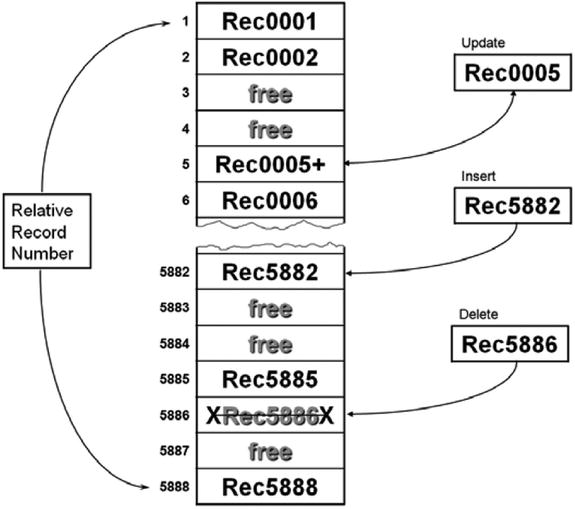
Figure 17-1. Schematic representation of a relative file
Some restrictions should be obvious from Figure 17-1. First, only one relative key is supported, and that key must be numeric and take a value between 1 and the number of the highest relative record written to the file. Another restriction is that, even when the file is only sparsely populated, enough disk space has to be allocated to hold all the records between 1 and the record with the highest relative record number. For instance, if a record with a relative record number of 150,000 is written to the file, then room sufficient for 150,000 records is allocated to the file—even though that may be the only record actually written to the file. You can see this illustrated in Figure 17-1. In the example file, the record with the highest relative record number is 5,888, so disk space sufficient to store 5,888 records has been allocated. However, not all the record locations contain records. The record areas labelled “free” have been allocated but have not yet had record values written to them.
Being restricted to a single numeric key in a defined range is onerous, but there are ways to loosen the shackles. For instance, you might add a base value to the relative record number to change the range. For instance, in Figure 17-1 you could use a base of 10,000 so that the first record key value would be 10,001 and the last would be 15,888. Obviously, before you used the key, you would subtract 10,000 to convert it into the relative record number.
Using a base value is a very simple key transformation, and in COBOL this is probably about as much manipulation as you want to do. In other languages, you might write a sophisticated hashing algorithm to map even alphanumeric keys onto range of relative record numbers; but in COBOL, when you need keys with this level of sophistication, you use indexed files.
In addition to showing how records are organized in a relative file, Figure 17-1 also shows how updates, insertions and, deletions are applied:
- To update a record, you use the relative record number to READ the record from the file into the record buffer. Then you make the changes to the record data and REWRITE the record to the file.
- To insert a record, you use the relative record number to tell the system where to WRITE the record. Obviously, the allocated space must be free, or an error condition will occur.
- To delete a record, you use the relative record number to tell the system which record to DELETE. Obviously, the record must exist. For instance, in Figure 17-1, an error condition would occur if you tried to delete the record with the relative record number 5,887 because there is no record in that position. In a relative file, when you delete a record, all the file system does is to mark it as deleted. It does not really delete the record.
As mentioned at the beginning of this chapter, direct access files are declared and processed using a number of new declaration clauses and verbs. Instead of boring you with a dry, formal introduction, this section shows you some simple examples. Once you have a feel for how it all works, I introduce the required clauses and verbs more formally.
Let’s start with a simple program that reads a relative file both sequentially and directly. Then you learn how to create a relative file from a sequential file. Most programming environments have tools that allow you to do this, but it is interesting to see how to do it by hand. The final example shows you how to apply a file of transactions to the relative file.
The program in Listing 17-1 reads a relative file either sequentially or directly, depending on the choice made by the user.
Listing 17-1. Reading a Relative File Sequentially or Directly Using a Key
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-1.
AUTHOR. MICHAEL COUGHLAN.
* Reads a Relative file directly or in sequence
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT VehicleFile ASSIGN TO "Listing17-1.DAT"
ORGANIZATION IS RELATIVE
ACCESS MODE IS DYNAMIC
RELATIVE KEY IS VehicleKey
FILE STATUS IS VehicleStatus.
DATA DIVISION.
FILE SECTION.
FD VehicleFile.
01 VehicleRec.
88 EndOfVehiclefile VALUE HIGH-VALUES.
02 VehicleNum PIC 9(4).
02 VehicleDesc PIC X(25).
02 ManfName PIC X(20).
WORKING-STORAGE SECTION.
01 VehicleStatus PIC X(2).
88 RecordFound VALUE "00".
01 VehicleKey PIC 9(4).
01 ReadType PIC 9.
88 DirectRead VALUE 1.
88 SequentialRead VALUE 2.
01 PrnVehicleRecord.
02 PrnVehicleNum PIC 9(4).
02 PrnVehicleDesc PIC BBX(25).
02 PrnManfName PIC BBX(20).
PROCEDURE DIVISION.
BEGIN.
OPEN INPUT VehicleFile
DISPLAY "Read type : Direct read = 1, Sequential read = 2 --> "
WITH NO ADVANCING.
ACCEPT ReadType
IF DirectRead
DISPLAY "Enter vehicle key (4 digits) --> " WITH NO ADVANCING
ACCEPT VehicleKey
READ VehicleFile
INVALID KEY DISPLAY "Vehicle file status = " VehicleStatus
END-READ
PERFORM DisplayRecord
END-IF
IF SequentialRead
READ VehicleFile NEXT RECORD
AT END SET EndOfVehiclefile TO TRUE
END-READ
PERFORM UNTIL EndOfVehiclefile
PERFORM DisplayRecord
READ VehicleFile NEXT RECORD
AT END SET EndOfVehiclefile TO TRUE
END-READ
END-PERFORM
END-IF
CLOSE VehicleFile
STOP RUN.
DisplayRecord.
IF RecordFound
MOVE VehicleNum TO PrnVehicleNum
MOVE VehicleDesc TO PrnVehicleDesc
MOVE ManfName TO PrnManfName
DISPLAY PrnVehicleRecord
END-IF.
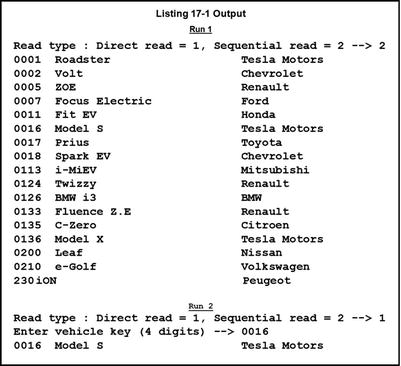
The first thing to note is that the SELECT and ASSIGN clause has a number of new entries. First, ORGANIZATION is now RELATIVE. Second, because a relative file allows you to access the records in the file directly or sequentially, you must have an ACCESS MODE phrase to say what kind of access you desire on the file. Three types of access are available: RANDOM (key-based access only), SEQUENTIAL (sequential only), and DYNAMIC (a mixture of keyed and sequential access). Third, to allow key-based access, you must specify a RELATIVE KEY phrase to tell the system where it can find the key value used for direct access. Note that the key mentioned here cannot be part of the record description.
The final entry is the FILE STATUS clause. The FILE STATUS clause allows you to identify a two-character area of storage to hold the result of every I/O operation for the file. The FILE STATUS data item is declared as PIC X(2) in the WORKING-STORAGE SECTION. Whenever an I/O operation is performed on the file, some value is returned to FILE STATUS indicating whether the operation was successful. I introduce these FILE STATUS values as and when they occur; for this program, you only need to know that a value of "00" indicates that the operation (READ, in this case) was successful.
The FILE STATUS clause is not restricted to direct access files. You can use it with sequential files, but that isn’t necessary because with those files there are not many states that you need to detect. However, with direct access files, a number of file states need to be detected. For instance, you need to detect when an attempt is made to READ, DELETE, or REWRITE a record when a record with that key value does not exist in the file. Similarly, you need to be able to detect when an attempt to WRITE a record finds that there is already a record with that key value in the file.
The next item of note is the change to the READ verb. The direct READ now takes the INVALID KEY clause. This clause allows you to execute some code when an error condition is detected. The sequential read may now use the NEXT RECORD phrase. This phrase is required when ACCESS MODE is DYNAMIC, to indicate that this is a sequential read. If ACCESS MODE is SEQUENTIAL, then you use the standard READ statement.
Creating a Relative File from a Sequential File
Listing 17-2 shows how to create a relative file from a sequential file. A relative file is a binary file. It can’t be edited in a standard text editor. This makes it a bit awkward to create test data, but most COBOL programming environments have tools that allow you to generate a relative file from a sequential one. Of course, you don’t have to use the tools; you can write a program to do it, as in this example.
Listing 17-2. Creating a Relative File from a Sequential File
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-2.
AUTHOR. MICHAEL COUGHLAN.
* Reads a Relative file directly or in sequence
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT VehicleFile ASSIGN TO "Listing17-2.DAT"
ORGANIZATION IS RELATIVE
ACCESS MODE IS RANDOM
RELATIVE KEY IS VehicleKey
FILE STATUS IS VehicleStatus.
SELECT Seqfile ASSIGN TO "Listing17-2.SEQ"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD VehicleFile.
01 VehicleRec.
02 VehicleNum PIC 9(4).
02 VehicleDesc PIC X(25).
02 ManfName PIC X(20).
FD SeqFile.
01 VehicleRec-SF.
88 EndOfSeqfile VALUE HIGH-VALUES.
02 VehicleNum-SF PIC 9(4).
02 VehicleDesc-SF PIC X(25).
02 ManfName-SF PIC X(20).
WORKING-STORAGE SECTION.
01 VehicleStatus PIC X(2).
88 RecordFound VALUE "00".
01 VehicleKey PIC 9(4).
PROCEDURE DIVISION.
BEGIN.
OPEN INPUT SeqFile
OPEN OUTPUT VehicleFile
READ SeqFile
AT END SET EndOfSeqFile TO TRUE
END-READ
PERFORM UNTIL EndOfSeqFile
MOVE VehicleNum-SF TO VehicleKey
WRITE VehicleRec FROM VehicleRec-SF
INVALID KEY DISPLAY "Vehicle file status = " VehicleStatus
END-WRITE
READ SeqFile
AT END SET EndOfSeqFile TO TRUE
END-READ
END-PERFORM
CLOSE SeqFile, VehicleFile
STOP RUN.
In this program, the first thing to note is that because the relative file only uses direct access, the ACCESS MODE specified is RANDOM.
The relative file is created as follows. For each record in the sequential file, the program reads the record, moves the contents of the VehicleNum field to the relative key VehicleKey, and then writes the relative record from the sequential record. The record is written into the position indicated by the relative record number in VehicleKey.
Applying Transactions to a Relative File
In this final example program (see Listing 17-3), you see how to apply a sequential file of transactions to the relative vehicle master file. The transaction file contains only enough transactions to demonstrate valid and invalid insertions, valid and invalid updates (VehicleDesc is updated), and valid and invalid deletions. To keep the program short, it uses displays to report transaction errors. To make the updates clear, the contents of the vehicle master file are displayed before and after the transactions are applied. The contents of the transaction file are shown in Example 17-1.
Example 17-1. Contents of the Transaction File
I0001 *** invalid insert *** Tesla Motors
D0006 *** invalid delete ***
U0017FCV +valid update
U0117 *** invalid update ***
D0135 +valid delete
I0205Model C +valid insert Tesla Motors
I0230 *** invalid insert *** Peugeot
Listing 17-3. Applying a Sequential File of Transactions to a Relative File
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-3.
AUTHOR. MICHAEL COUGHLAN.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT VehicleMasterFile ASSIGN TO "Listing17-3.DAT"
ORGANIZATION IS RELATIVE
ACCESS MODE IS DYNAMIC
RELATIVE KEY IS VehicleKey
FILE STATUS IS VehicleFileStatus.
SELECT TransFile ASSIGN TO "Listing17-3Trans.DAT"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD VehicleMasterFile.
01 VehicleRec-VMF.
88 EndOfVehiclefile VALUE HIGH-VALUES.
02 VehicleNum-VMF PIC 9(4).
02 VehicleDesc-VMF PIC X(25).
02 ManfName-VMF PIC X(20).
FD TransFile.
01 InsertionRec.
88 EndOfTransFile VALUE HIGH-VALUES.
02 TransType PIC X.
88 InsertRecord VALUE "I".
88 DeleteRecord VALUE "D".
88 UpdateRecord VALUE "U".
02 VehicleNum-IR PIC 9(4).
02 VehicleDesc-IR PIC X(25).
02 ManfName-IR PIC X(20).
01 DeletionRec PIC X(5).
01 UpdateRec.
02 FILLER PIC X(5).
02 VehicleDesc-UR PIC X(25).
WORKING-STORAGE SECTION.
01 VehicleFileStatus PIC X(2).
88 OperationSuccessful VALUE "00".
88 VehicleRecExists VALUE "22".
88 NoVehicleRec VALUE "23".
01 VehicleKey PIC 9(4).
01 ReadType PIC 9.
PROCEDURE DIVISION.
Begin.
OPEN INPUT TransFile
OPEN I-O VehicleMasterFile
DISPLAY "Vehicle Master File records before transactions"
PERFORM DisplayVehicleRecords
DISPLAY SPACES
READ TransFile
AT END SET EndOfTransFile TO TRUE
END-READ
PERFORM UNTIL EndOfTransFile
MOVE VehicleNum-IR TO VehicleKey
EVALUATE TRUE
WHEN InsertRecord PERFORM InsertVehicleRec
WHEN DeleteRecord PERFORM DeleteVehicleRec
WHEN UpdateRecord PERFORM UpdateVehicleRec
WHEN OTHER DISPLAY "Error - Invalid Transaction Code"
END-EVALUATE
READ TransFile
AT END SET EndOfTransFile TO TRUE
END-READ
END-PERFORM
DISPLAY SPACES
DISPLAY "Vehicle Master File records after transactions"
PERFORM DisplayVehicleRecords
CLOSE TransFile, VehicleMasterFile
STOP RUN.
InsertVehicleRec.
MOVE ManfName-IR TO ManfName-VMF
MOVE VehicleDesc-IR TO VehicleDesc-VMF
MOVE VehicleNum-IR TO VehicleNum-VMF
WRITE VehicleRec-VMF
INVALID KEY
IF VehicleRecExists
DISPLAY "InsertError - Record at - " VehicleNum-IR " - already exists"
ELSE
DISPLAY "Unexpected error. File Status is - " VehicleFileStatus
END-IF
END-WRITE.
DeleteVehicleRec.
DELETE VehicleMasterFile RECORD
INVALID KEY
IF NoVehicleRec
DISPLAY "DeleteError - No record at - " VehicleNum-IR
ELSE
DISPLAY "Unexpected error1. File Status is - " VehicleFileStatus
END-IF
END-DELETE.
UpdateVehicleRec.
READ VehicleMasterFile
INVALID KEY
IF NoVehicleRec
DISPLAY "UpdateError - No record at - " VehicleNum-IR
ELSE
DISPLAY "Unexpected error2. File Status is - " VehicleFileStatus
END-IF
END-READ
IF OperationSuccessful
MOVE VehicleDesc-UR TO VehicleDesc-VMF
REWRITE VehicleRec-VMF
INVALID KEY DISPLAY "Unexpected error3. File Status is - " VehicleFileStatus
END-REWRITE
END-IF.
DisplayVehicleRecords.
* Position the Next Record Pointer to the start of the file
MOVE ZEROS TO VehicleKey
START VehicleMasterFile KEY IS GREATER THAN VehicleKey
INVALID KEY DISPLAY "Unexpected error on START"
END-START
READ VehicleMasterFile NEXT RECORD
AT END SET EndOfVehiclefile TO TRUE
END-READ
PERFORM UNTIL EndOfVehiclefile
DISPLAY VehicleNum-VMF SPACE VehicleDesc-VMF SPACE ManfName-VMF
READ VehicleMasterFile NEXT RECORD
AT END SET EndOfVehiclefile TO TRUE
END-READ
END-PERFORM.
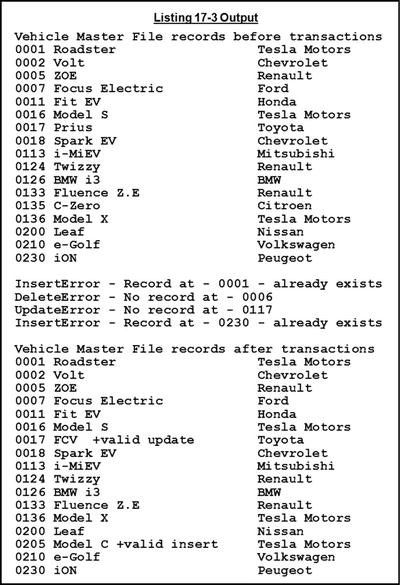
The most interesting thing about this program is that it uses all five of the direct access file processing verbs: READ, WRITE, REWRITE, DELETE, and START. The program begins by displaying the current contents of the vehicle master file. You may wonder what the purpose of the START verb is at the beginning of DisplayVehicleRecords. For relative files, the START verb is used to position the next-record pointer. When a file is accessed sequentially, the next-record pointer points to the position in the file where the next record will be read from or written to.
This first time through DisplayVehicleRecords, the START verb is not strictly necessary, because when you open the file, the next-record pointer points to the first record in the file by default. But the second time through the file, the START verb is required in order to position the next-record pointer at the beginning of the file—when you read through the file the first time, the next-record pointer was left pointing to the last record in the file. Closing the file and opening it again also positions the next-record pointer at the first record in the file, but doing so carries a significant processing penalty.
Note how you use the START verb. You move zeros into the relative-key data item; then, when START executes, its meaning is this: position the next-record pointer such that the relative record number of the record pointed to is greater than the current value of the relative-key data item. Because the current value of the relative-key data item is zero, the first valid record in the file satisfies the condition.
The first statement in the PERFORM UNTIL EndOfTransFile iteration is MOVE VehicleNum-IR TO VehicleKey. This takes the key value in the transaction record and places it in the relative-key data item. Now any direct access operation such as WRITE, REWRITE, or DELETE will use that key value.
If the transaction is an insertion, then a direct WRITE is used to write the transaction record to the vehicle master file at the relative record number indicated by the value in VehicleKey. If the WRITE fails, then INVALID KEY activates, and the file status is checked to see if it has failed because there is already a record in that relative record number position or because of an unexpected error. If the anticipated error condition occurs, an error message is displayed, indicating the offending record’s key value; otherwise, an error message and the current value of the file status are displayed. The second part of the IF statement is there as an alert regarding a possible programming or test data error; you don’t expect this branch of IF to be triggered.
If the transaction is a deletion, then the direct DELETE is used to delete the record at the relative record number position pointed to by the value in VehicleKey. If there is no record at that position, INVALID KEY activates.
If the transaction is an update, then a direct READ is used to fetch the record from the file and place it in the record buffer. If the record exists, the VehicleDesc-VMF field is updated, and REWRITE is used to write the record back to the file. REWRITE has to be used because WRITE would return an error if it found a record already in place.
Relative Files: Syntax and Semantics
This section provides a formal introduction to the file-processing verbs and declarations specific to relative files.
Relative Files: SELECT and ASSIGN Clause
The metalanguage for the SELECT and ASSIGN clause for relative files is shown in Figure 17-2.
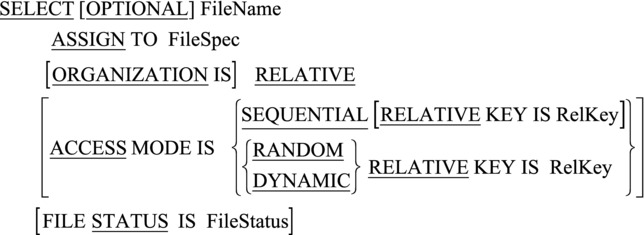
Figure 17-2. Metalanguage for the specific relative SELECT and ASSIGN clause
Normally, when a file is opened for INPUT, I-O, or EXTEND, the file must exist or an error condition occurs. The OPTIONAL phrase allows you to specify that the file does not have to exist (presumably because you are going to write records to and read records from it) when OPEN INPUT, OPEN I-O, or OPEN EXTEND executes.
ACCESS MODE refers to the way in which the file is to be used. If you specify that ACCESS MODE is SEQUENTIAL, then it is only possible to process the records in the file sequentially. If RANDOM is specified, it is only possible to access the file directly. If DYNAMIC is specified, the file may be accessed both directly and sequentially.
The RECORD KEY phrase is used to define the relative key. There can be only one key in a relative file. RelKey must be a numeric data item and must not be part of the file’s record description, although it may be part of another file’s record description. It is normally described in the WORKING-STORAGE SECTION.
The FILE STATUS clause identifies a two-character area of storage that holds the result of every I/O operation for the file. The FILE STATUS data item is declared as PIC X(2) in the WORKING-STORAGE SECTION. Whenever an I/O operation is performed, some value is returned to FILE STATUS, indicating whether the operation was successful.
There are a large number of FILE STATUS values, but three of major interest for relative files are as follows:
- "00" means the operation was successful.
- "22" indicates a duplicate key. That is, you are trying to write a record, but a record already exists in that position.
- "23" means the record was not found. That is, you are trying to access a record, but there is no record in that position.
Direct access files are more versatile than sequential files and support a greater range of operations. In addition to the new file-processing verbs DELETE, REWRITE, and START, many of the verbs you already know—such as OPEN, CLOSE, READ, and WRITE—operate differently when processing direct access files.
INVALID KEY Clause
If you examine the metalanguage of any of the direct access verbs, you see that the INVALID KEY clause is in square brackets, indicating that this clause is optional. In reality, the INVALID KEY clause is mandatory unless declaratives have been specified. Declaratives allow you to create specialized exception-handling code. You explore declaratives in the next chapter.
When the INVALID KEY clause is specified, any I/O error, such as attempting to read or delete a record that does not exist or write a record that already exists, activates the clause and causes the statement block following it to be executed.
OPEN/CLOSE
The CLOSE syntax is the same for all file organizations.
The syntax for OPEN changes when used with direct access files: an I-O (input/output) entry is added. I-O is used with direct access files when you intend to update or both read from and write to the file. The full metalanguage for the OPEN verb is given in Figure 17-3.
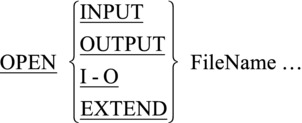
Figure 17-3. Full metalanguage for the OPEN verb
Consider the following:
- If the file is opened for INPUT, then only READ and START are allowed.
- If the file is opened for OUTPUT, then only WRITE is allowed.
- If the file is opened for I-O, then READ, WRITE, START, REWRITE, and DELETE are allowed.
- If OPEN INPUT is used, and the file does not possess the OPTIONAL clause, the file must exist or the OPEN will fail.
- If OPEN OUTPUT or I-O is used, the file will be created if it does not already exist, as long as the file possesses the OPTIONAL clause.
There are two new formats for the READ verb. One format is used for a direct READ on a relative file, and the other is used when you want to read the file sequentially but an ACCESS MODE of DYNAMIC has been specified for the file. When an ACCESS MODE of SEQUENTIAL is specified, all file organizations use the standard READ format.
The metalanguage in Figure 17-4 shows the READ format used to read a relative file sequentially when an ACCESS MODE of DYNAMIC has been specified. The only difference between this format and the format of the ordinary sequential READ is the NEXT RECORD phrase. This format of READ reads the record pointed to by the next-record pointer (the current record if positioned by START, or the next record if positioned by a direct READ).

Figure 17-4. Metalanguage for the sequential READ when the ACCESS MODE is DYNAMIC
The format of READ used for a direct read on a relative file is shown in Figure 17-5. To read a relative file using a key, the relative record number of the required record is placed in the RELATIVE KEY data item (specified in the RELATIVE KEY phrase of the file’s SELECT and ASSIGN clause), and then READ is executed. When READ executes, the record with the relative record number equal to the present value of the relative key is read into the file’s record buffer (defined in the FD entry). If READ fails to retrieve the record, the INVALID KEY activates, and the statement block following the clause is executed. If READ is successful, NOT INVALID KEY (if present) activates, and the next-record pointer is left pointing to the next valid record in the file.
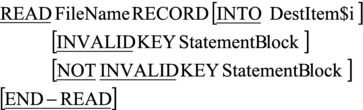
Figure 17-5. Metalanguage for the direct READ
The format for writing sequentially to a direct access file is the same as that used for writing to a sequential file. But when you want to write directly to a relative file, a key must be used, and this requires the WRITE format shown in Figure 17-6.

Figure 17-6. Metalanguage for writing to a relative file using a key
Writing a record to a relative file using a key requires you to place the record in the record buffer, place the key value in the RELATIVE KEY data item, and then execute the WRITE statement. When WRITE executes, the data in the record buffer is written to the record position with a relative record number equal to the present value of the key.
If WRITE fails, perhaps because a record already exists at that relative record number position, the INVALID KEY clause activates, and the statements following the clause are executed.
The REWRITE verb is used to update a record in situ by overwriting it. The format of REWRITE is given in Figure 17-7. The REWRITE verb is generally used with READ because you can only update a record by bringing it into the record buffer first. Once the record is in the buffer, you can make the changes to the required fields; when the changes have been made, you REWRITE the record to the file.
To use REWRITE to update fields in a record, you first place the key value in the RELATIVE KEY data item and do a direct READ. This brings the required record into the record buffer. Next you make the required changes to the data in the record. Then you execute a REWRITE to write the record in the buffer back to the file.

Figure 17-7. Metalanguage for the REWRITE verb
Keep the following in mind:
- If the file has an ACCESS MODE of SEQUENTIAL, then the INVALID KEY clause cannot be specified, and the record to be replaced must have been the subject of a READ or START before the REWRITE is executed.
- For all access modes, the file must be opened for I-O.
The syntax for the DELETE verb is given in Figure 17-8. To delete a record, you place the key value in the RELATIVE KEY data item and then execute DELETE. The record in the relative record number position indicated by the RELATIVE KEY data item is marked as deleted (it is not actually deleted). If the DELETE attempt fails, perhaps because there is no record at that position, INVALID KEY activates.
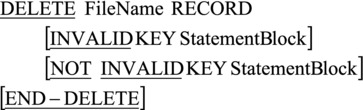
Figure 17-8. Metalanguage for the DELETE verb
Note the following:
- To use DELETE, the file must have been opened for I-O.
- When ACCESS MODE is SEQUENTIAL, a READ statement must have accessed the record to be deleted (that’s how the system knows which record to delete).
START Verb
For relative files, the START verb is only used to control the position of the next-record pointer. Where the START verb appears in a program, it is usually followed by a sequential READ or WRITE because START does not get data from or put data into the file. It merely positions the next-record pointer.
To use the START verb to position the next-record pointer at a particular record (so that subsequent sequential accesses will use that record position), you place the key value of the record at the desired position into the RELATIVE KEY data item and then execute a START..KEY IS EQUAL TO statement.
To use the START verb to position the next-record pointer at the first active record in the file, you move zeros to the RELATIVE KEY data item and then execute a START..KEY IS GREATER THAN statement. You can’t move the number 1 to the RELATIVE KEY data item, because there may be no active record in the first record position.
The metalanguage for the START verb is given in Figure 17-9. When START executes, it has the following interpretation: position the next-record pointer such that the relative record number of the record pointed to is EQUAL TO or GREATER THAN or NOT LESS THAN or GREATER THAN OR EQUAL TO the current value of the RELATIVE KEY data item.

Figure 17-9. Metalanguage for the START verb
Unlike relative files, which only allow a single, numeric key, an indexed file may have up to 255 alphanumeric keys. The key on which the data records are actually ordered is called the primary key. The other keys are called alternate keys. Although a relative file allows you to access records sequentially or directly by key, an indexed file lets you access the records directly or sequentially using any of its keys. For instance, suppose an indexed file supporting a video rental system has VideoId as its primary key and VideoTitle and SupplierId as its alternate keys. You can read a record from the file using any of the keys, and you can also read through the file in VideoId sequence, VideoTitle sequence, or SupplierId sequence. This versatility is what makes indexed files so useful.
How is this flexibility achieved? How can it be possible to read through the file sequentially in different sequences?
The data records in an indexed file are sequenced in ascending primary-key order. Over the data records, the file system builds an index. This arrangement is shown schematically in Figure 17-10.
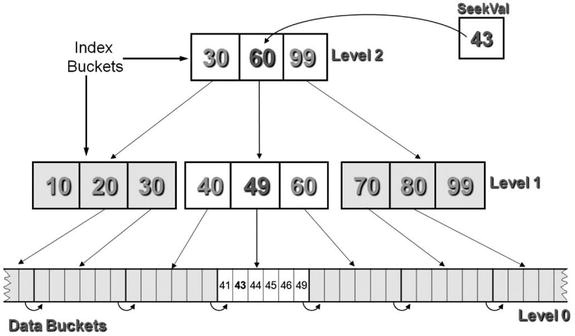
Figure 17-10. Primary-key index: seeking a record with a key value of 43
A number of terms relating to Figure 17-10 need clarification. A bucketis the smallest number of characters of disk storage that can be read or written in one I/O operation. It is the equivalent of a block on a PC disk—the smallest segment of disk space that can be addressed. Index depth is the number of levels of index above level 0, which is the data bucket (or base bucket) level (in Figure 17-10, the index depth is 2).
When direct access is required, the file system uses the index to find, read, insert, update, or delete the required record. Figure 17-11 shows how the index is used to locate the record with a key value of 43. The file system starts at the first level of index (one I/O operation is required to bring the records in this bucket into memory). In the index buckets, each index record contains a pointer to the highest key value in the next-level buckets. Using the condition IF SeekVal <= IndexKeyVal, a bucket is retrieved from the next level of index (another I/O operation is required to bring the records in this bucket into memory). Again the condition is applied, and the bucket at level 0 (the data buckets) is retrieved (another final I/O is required to bring the records in this bucket into memory). Once the actual data records are in memory, the file system searches them sequentially until the required record is found.
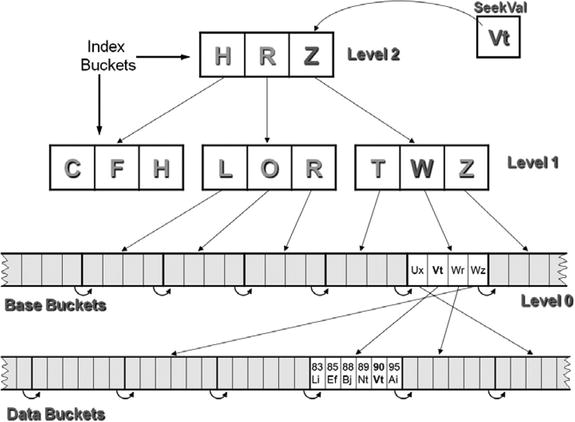
Figure 17-11. Alternate-key index: seeking a record with a key value of Vt
In addition to allowing direct access to records on the primary key or any of the 254 alternate keys, indexed files may also be processed sequentially. When you process an indexed file sequentially, you can read the records in ascending order on the primary key or on any of the alternate keys.
Because the data records are held in ascending primary-key sequence, it is easy to see how the file may be accessed sequentially on the primary key. It is not quite so obvious how you achieve sequential access on the alternate keys. For this, you need to examine the alternate index schematic in Figure 17-11.
For each of the alternate keys specified in an indexed file, an alternate index is built. However, unlike the primary-key index, which contains the data buckets at the lowest level of the index, the lowest level of an alternate index is made up of base records that contain only the alternate-key value and a pointer to where the actual record is. These base records are organized in ascending alternate-key order; by reading though these base records in sequence, you achieve sequential access using the alternate key. This arrangement is shown schematically in Figure 17-11.
Figure 17-11 shows how the index is used to locate the record with a key value of Vt. As with the primary key, each level of index points to the next level until level 0 is reached. Each of the base buckets at level 0 contains records that consist of the alternate-key value and a pointer to the data bucket where the record with that key value is to be found. In Figure 17-11, for example, the Vt record in the base buckets points to a bucket that actually contains the record. Note that the records in this bucket are in ascending primary key order.
Just as with relative files, this section introduces indexed files by showing you some simple examples. When you have a feel for how it all works, you learn about the required clauses, verbs, and concepts more formally.
Let’s start with a simple program that reads an indexed file both sequentially and directly on a number of keys. Then you see how to create an indexed file from a sequential file. In the third example, you learn how to use indexed files in combination: you use an indexed file of film directors and an indexed file containing film details together to display all the films directed by a particular director. In the final example, you apply a set of transactions to the film file and cover the issue of referential integrity that crops up when a new film record is inserted.
Listing 17-4 displays the contents of an indexed file in the key sequence chosen by the user and then displays one record directly using the key chosen by the user.
Listing 17-4. Reading an indexed file sequentially and then directly using any key
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-4.
AUTHOR. Michael Coughlan.
*Reads the file sequentially and then directly on any key
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
SELECT FilmFile ASSIGN TO "Listing17-4Film.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS FilmId
ALTERNATE RECORD KEY IS FilmTitle
WITH DUPLICATES
ALTERNATE RECORD KEY IS DirectorId
WITH DUPLICATES
FILE STATUS IS FilmStatus.
DATA DIVISION.
FILE SECTION.
FD FilmFile.
01 FilmRec.
88 EndOfFilms VALUE HIGH-VALUES.
02 FilmId PIC 9(7).
02 FilmTitle PIC X(40).
02 DirectorId PIC 999.
WORKING-STORAGE SECTION.
01 FilmStatus PIC XX.
88 FilmOK VALUE ZEROS.
01 RequiredSequence PIC 9.
88 FilmIdSequence VALUE 1.
88 FilmTitleSequence VALUE 2.
88 DirectorIdSequence VALUE 3.
PROCEDURE DIVISION.
Begin.
OPEN INPUT FilmFile
DISPLAY "*** Get Records Sequentially ***"
DISPLAY "Enter key : 1 = FilmId, 2 = FilmTitle, 3 = DirectorId - "
WITH NO ADVANCING.
ACCEPT RequiredSequence.
EVALUATE TRUE
WHEN FilmIdSequence PERFORM DisplayFilmData
WHEN FilmTitleSequence MOVE SPACES TO FilmTitle
START FilmFile KEY IS GREATER THAN FilmTitle
INVALID KEY DISPLAY "FilmStatus = " FilmStatus
END-START
PERFORM DisplayFilmData
WHEN DirectorIdSequence MOVE ZEROS TO DirectorId
START FilmFile KEY IS GREATER THAN DirectorId
INVALID KEY DISPLAY "FilmStatus = " FilmStatus
END-START
PERFORM DisplayFilmData
END-EVALUATE
DISPLAY SPACES
DISPLAY "*** Get Records Directly ***"
DISPLAY "Enter key : 1 = FilmId, 2 = FilmTitle, 3 = DirectorId - "
WITH NO ADVANCING.
ACCEPT RequiredSequence.
EVALUATE TRUE
WHEN FilmIdSequence PERFORM GetFilmByFilmId
WHEN FilmTitleSequence PERFORM GetFilmByFilmTitle
WHEN DirectorIdSequence PERFORM GetFilmByDirectorId
END-EVALUATE
CLOSE FilmFile
STOP RUN.
DisplayFilmData.
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
PERFORM UNTIL EndOfFilms
DISPLAY FilmId SPACE FilmTitle SPACE DirectorId
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
END-PERFORM.
GetFilmByFilmId.
DISPLAY "Enter the FilmId - " WITH NO ADVANCING
ACCEPT FilmId
READ FilmFile
KEY IS FilmId
INVALID KEY DISPLAY "Film not found - " FilmStatus
NOT INVALID KEY DISPLAY FilmId SPACE FilmTitle SPACE DirectorId
END-READ.
GetFilmByFilmTitle.
DISPLAY "Enter the FilmTitle - " WITH NO ADVANCING
ACCEPT FilmTitle
READ FilmFile
KEY IS FilmTitle
INVALID KEY DISPLAY "Film not found - " FilmStatus
NOT INVALID KEY DISPLAY FilmId SPACE FilmTitle SPACE DirectorId
END-READ.
GetFilmByDirectorId.
DISPLAY "Enter the Director Id - " WITH NO ADVANCING
ACCEPT DirectorId
READ FilmFile
KEY IS DirectorId
INVALID KEY DISPLAY "Film not found - " FilmStatus
NOT INVALID KEY DISPLAY FilmId SPACE FilmTitle SPACE DirectorId
END-READ.

There is quite a bit to talk about in this program. The first thing to note is the new entries in the SELECT and ASSIGN clause. Because an indexed file has a primary key and, perhaps, some alternate keys, you must have entries in SELECT and ASSIGN for each key, and you must distinguish the primary key from the alternate keys. One very important thing to remember is that whereas the key defined in the RELATIVE KEY entry of a relative file cannot be a field in the relative file’s record description, the keys defined for an indexed file must be fields in the record defined for the file.
Another item of interest is the WITH DUPLICATES phrase, which is specified with the ALTERNATE KEY clause in the SELECT and ASSIGN clause. In a relative file, the key must be unique; and in an indexed file, the primary key defined in the RECORD KEY clause must be unique, but the alternate keys may have duplicates if they use the WITH DUPLICATES phrase. For instance, in this program, the same DirectorId appears for many films. If the WITH DUPLICATES phrase is omitted, the alternate key has to be unique.
The program starts by asking the user what key to use when displaying the contents of the file sequentially. This raises an interesting question. If you examine the code in the paragraph DisplayFilmData, you see that the READ format used is the one for reading a file sequentially. So the question is, how does the system know to read through the file in FilmId order on one occasion, in FilmTitle order on another occasion, and in DirectorId order on yet another occasion? The answer is that the system relies on a concept called the key of reference. The key of reference refers to the key that is used to process an indexed file sequentially. A particular key is established as the key of reference by using that key with START or a direct READ. You can see this in the program. If FilmTitleSequence is selected, START is used with the FilmTitle key to both establish FilmTitle as the key of reference and position the next-record pointer at the first record. Similarly, if DirectorIdSequence is selected, START is used to establish DirectorId as the key of reference and to position the next-record pointer at the first record in the file. What about FilmIdSequence, though? Why doesn’t that WHEN branch have a START verb? I could have used START with that branch, too, but I wanted to make the point that when the file is opened, the primary key is the default key of reference and the next-record pointer is pointing at the first record in the file.
When the program has displayed the contents of the file in the required sequence, the user is asked which key they wish to use for a direct READ. Then that key is used to read the required record from the file. If you examine the READ operation in any of the paragraphs that read the record from the file, you see that this format of READ is different from that used for relative files. For relative files, READ does not require a KEY IS phrase because there is only one key; but because indexed files use many keys, you have to say which key you are using to read the record.
One final issue needs to be discussed. The paragraph GetFilmByDirectorId returns only one record, but the same director occurs many times in the file. How can you show the other films made by this director? The answer lies once more in the key of reference. When a direct READ is made, the key used is established as the key of reference, and the next-record pointer is pointing at the next record in the file. You can display all the films made by a particular director by doing a direct READ followed by sequential READs. You stop reading the records when the Director Id changes. This procedure is shown in the revised version of GetFilmByDirectorId in Example 17-2.
Example 17-2. Revision of GetFilmByDirectorId to Show All of a Director’s Films
GetFilmByDirectorId.
DISPLAY "Enter the Director Id - " WITH NO ADVANCING
ACCEPT DirectorId
READ FilmFile
KEY IS DirectorId
INVALID KEY DISPLAY "Film not found - " FilmStatus
NOT INVALID KEY DISPLAY FilmId SPACE FilmTitle SPACE DirectorId
PERFORM GetOtherFilmsByThisDirector
END-READ.
GetOtherFilmsByThisDirector.
MOVE DirectorId TO PrevDirectorId
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
PERFORM UNTIL DirectorId NOT EQUAL TO PrevDirectorId
OR EndOfFilms
DISPLAY FilmId SPACE FilmTitle SPACE DirectorId
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
END-PERFORM.
Creating an Indexed File from a Sequential File
In Listing 17-5, an indexed file is created from a sequential file. Sequential files are useful because you can create them with an ordinary editor. There are tools available that can convert a sequential file into an indexed file, but this program does the job itself.
Listing 17-5. Creating an Indexed File from a Sequential File
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-5.
AUTHOR. Michael Coughlan.
*Creating an Indexed File from a Sequential File
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
SELECT FilmFile ASSIGN TO "Listing17-5Film.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS FilmId
ALTERNATE RECORD KEY IS FilmTitle
WITH DUPLICATES
ALTERNATE RECORD KEY IS DirectorId
WITH DUPLICATES
FILE STATUS IS FilmStatus.
SELECT SeqFilmFile ASSIGN TO "Listing17-5Film.SEQ"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD FilmFile.
01 FilmRec.
02 FilmId PIC 9(7).
02 FilmTitle PIC X(40).
02 DirectorId PIC 999.
FD SeqFilmFile.
01 SeqFilmRec PIC X(50).
88 EndOfFilmFile VALUE HIGH-VALUES.
WORKING-STORAGE SECTION.
01 FilmStatus PIC XX.
88 FilmOK VALUE ZEROS.
PROCEDURE DIVISION.
Begin.
OPEN INPUT SeqFilmFile
OPEN OUTPUT FilmFile
READ SeqFilmFile
AT END SET EndOfFilmFile TO TRUE
END-READ
PERFORM UNTIL EndOfFilmFile
WRITE FilmRec FROM SeqFilmRec
INVALID KEY DISPLAY "Error writing to film file"
END-WRITE
READ SeqFilmFile
AT END SET EndOfFilmFile TO TRUE
END-READ
END-PERFORM
CLOSE SeqFilmFile, FilmFile
STOP RUN.
The first issue to bring to your attention is the statement WRITE FilmRec FROM SeqFilmRec. When you consider this statement, you may wonder why there is no KEY IS phrase as there is with the direct READ. The reason is that records are always written to an indexed file based on the value in the primary key, so no KEY IS phrase is required.
You may also wonder why I don’t put the key value into the primary-key data item before the WRITE is executed. The answer is that I do put the key value into the primary-key data item—but I do it in a different way. WRITE FilmRec FROM SeqFilmRec has the same effect as
MOVE SeqFilmRec TO FilmRec
WRITE FilmRec
INVALID KEY DISPLAY "Error writing to film file"
END-WRITE
Using Indexed Files in Combination
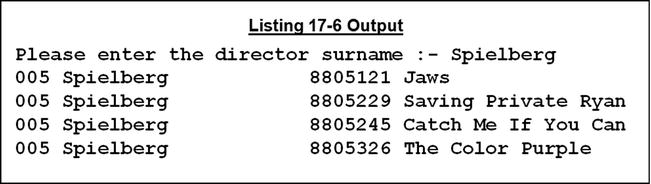
Listing 17-6 uses an indexed file of film directors and an indexed file containing film details in combination to display all the films directed by a particular director. The program accepts the name of a director from the user and then displays all the films made by that director. For each film, the director ID, the surname of the director, the film ID, and the title of the film are displayed.
Listing 17-6. Using Indexed Files in Combination
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-6.
AUTHOR. Michael Coughlan.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
SELECT FilmFile ASSIGN TO "Listing17-6Film.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS FilmId-FF
ALTERNATE RECORD KEY IS FilmTitle-FF
WITH DUPLICATES
ALTERNATE RECORD KEY IS DirectorId-FF
WITH DUPLICATES
FILE STATUS IS FilmStatus.
SELECT DirectorFile ASSIGN TO "Listing17-6Dir.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS DirectorId-DF
ALTERNATE RECORD KEY IS DirectorSurname-DF
FILE STATUS IS DirectorStatus.
DATA DIVISION.
FILE SECTION.
FD FilmFile.
01 FilmRec-FF.
88 EndOfFilms VALUE HIGH-VALUES.
02 FilmId-FF PIC 9(7).
02 FilmTitle-FF PIC X(40).
02 DirectorId-FF PIC 999.
FD DirectorFile.
01 DirectorRec-DF.
88 EndOfDirectors VALUE HIGH-VALUES.
02 DirectorId-DF PIC 999.
02 DirectorSurname-DF PIC X(20).
WORKING-STORAGE SECTION.
01 AllStatusFlags VALUE ZEROS.
02 FilmStatus PIC XX.
88 FilmOk VALUE "02", "00".
02 DirectorStatus PIC XX.
01 DirectorName PIC X(20).
PROCEDURE DIVISION.
Begin.
OPEN INPUT FilmFile
OPEN INPUT DirectorFile
DISPLAY "Please enter the director surname :- "
WITH NO ADVANCING
ACCEPT DirectorSurname-DF
READ DirectorFile
KEY IS DirectorSurname-DF
INVALID KEY DISPLAY "-DF ERROR Status = " DirectorStatus
NOT INVALID KEY PERFORM GetFilmsForDirector
END-READ
CLOSE FilmFile
CLOSE DirectorFile
STOP RUN.
GetFilmsForDirector.
MOVE DirectorId-DF TO DirectorId-FF
READ FilmFile
KEY IS DirectorId-FF
INVALID KEY DISPLAY "-FF ERROR Status = " FilmStatus
END-READ
IF FilmOk
PERFORM UNTIL DirectorId-DF NOT Equal TO DirectorId-FF OR EndOfFilms
DISPLAY DirectorId-DF SPACE DirectorSurname-DF SPACE
FilmId-FF SPACE FilmTitle-FF
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
END-PERFORM
END-IF.
This program uses two indexed files in combination. Used this way, indexed files are similar to a database where each file is a table, the records in the file are the table rows, and the fields in the records are the table columns.
The program starts by getting the name of the director from the user. This name is used as the key value for a direct READ on the director file. When the record is retrieved, DirectorId-DF is used to get all the director’s film titles.
One item of interest in the program is the file status for FilmFile. Note that one of two codes is specified to indicate the operation was successful. Normally, "00" indicates that the operation was successful; but in this case, the code "02" indicates success and also carries extra information. A code of "02" may be returned for indexed files only and is returned in these cases:
- When after a READ operation, the next record has the same key value as the key used for the READ
- When a WRITE or a REWRITE creates a duplicate key value for an alternate key that has the WITH DUPLICATES phrase
If you want to detect when you have processed all the films directed by a particular director without having to compare keys, you can use the returned "02" code as shown in Example 17-3.
Example 17-3. Using the "02" File Status to Create a More Succinct Loop
01 AllStatusFlags VALUE ZEROS.
02 FilmStatus PIC XX.
88 AnotherFilmForThisDirector VALUE "02".
: : : : : : : : : : : : : : : :
GetFilmsForDirector.
MOVE DirectorId-DF TO DirectorId-FF
READ FilmFile
KEY IS DirectorId-FF
INVALID KEY DISPLAY "-FF ERROR Status = " FilmStatus
NOT INVALID KEY DISPLAY DirectorId-DF SPACE DirectorSurname-DF SPACE
FilmId-FF SPACE FilmTitle-FF
END-READ
PERFORM UNTIL NOT AnotherFilmForThisDirector
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
DISPLAY DirectorId-DF SPACE DirectorSurname-DF SPACE
FilmId-FF SPACE FilmTitle-FF
END-PERFORM.
Applying Transactions to an Indexed File
Listing 17-7 applies a set of transactions (deletions, insertions, and updates) to the film file. The result of applying the transactions is shown in Figure 17-12. Applying the insertions to the film file is complicated by the issue of referential integrity. It should not be valid to insert a new film record when there is no record in the directors file for the director of the film. In a relational database system, referential integrity is automatically enforced by the database; but in COBOL, you have to do it yourself. The failure of programs to enforce referential integrity in COBOL legacy systems is one of the problems of legacy data. If you try to load such legacy data into a relational database that does enforce referential integrity, uniqueness, and other standards, the database system will probably crash.
Listing 17-7. Applying Transactions to an Indexed File
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-7.
AUTHOR. Michael Coughlan.
*Applies transactions to the Indexed FilmFile and enforces referential integrity
*with the Indexed Directors File
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
SELECT FilmFile ASSIGN TO "Listing17-7Films.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS FilmId-FF
ALTERNATE RECORD KEY IS FilmTitle-FF
WITH DUPLICATES
ALTERNATE RECORD KEY IS DirectorId-FF
WITH DUPLICATES
FILE STATUS IS FilmStatus.
SELECT DirectorsFile ASSIGN TO "Listing17-7Dir.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS DirectorId-DF
ALTERNATE RECORD KEY IS DirectorSurname-DF
FILE STATUS IS DirectorStatus.
SELECT TransFile ASSIGN TO "Listing17-7Trans.dat"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD FilmFile.
01 FilmRec-FF.
88 EndOfFilms VALUE HIGH-VALUES.
02 FilmId-FF PIC 9(7).
02 FilmTitle-FF PIC X(40).
02 DirectorId-FF PIC 9(3).
FD DirectorsFile.
01 DirectorsRec-DF.
88 EndOfDirectors VALUE HIGH-VALUES.
02 DirectorId-DF PIC 9(3).
02 DirectorSurname-DF PIC X(20).
FD TransFile.
01 DeletionRec-TF.
88 EndOfTrans VALUE HIGH-VALUES.
02 TypeId-TF PIC X.
88 DoDeletion VALUE "D".
88 DoInsertion VALUE "I".
88 DoUpdate VALUE "U".
02 FilmId-TF PIC 9(7).
01 InsertionRec-TF.
02 FILLER PIC 9.
02 InsertionBody-TF.
03 FILLER PIC X(47).
03 DirectorId-TF PIC 9(3).
01 UpdateRec-TF.
02 FILLER PIC X(8).
02 FilmTitle-TF PIC X(40).
WORKING-STORAGE SECTION.
01 AllStatusFlags VALUE ZEROS.
02 FilmStatus PIC XX.
88 FilmOK VALUE ZEROS.
02 DirectorStatus PIC XX.
88 MatchingDirectorFound VALUE ZEROS.
PROCEDURE DIVISION.
Begin.
OPEN I-O FilmFile
OPEN INPUT DirectorsFile
OPEN INPUT TransFile
DISPLAY "*** Film file before updates ***"
PERFORM DisplayFilmFileContents
DISPLAY SPACES
READ TransFile
AT END SET EndOfTrans TO TRUE
END-READ
PERFORM UpdateFilmFile UNTIL EndofTrans
DISPLAY SPACES
DISPLAY "*** Film file after updates ***"
PERFORM DisplayFilmFileContents
CLOSE FilmFile, DirectorsFile, TransFile
STOP RUN.
DisplayFilmFileContents.
MOVE ZEROS TO FilmId-FF
START FilmFile KEY IS GREATER THAN FilmId-FF
INVALID KEY DISPLAY "Error1 - FilmStatus = " FilmStatus
END-START
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
PERFORM UNTIL EndOfFilms
DISPLAY FilmId-FF SPACE DirectorId-FF SPACE FilmTitle-FF
READ FilmFile NEXT RECORD
AT END SET EndOfFilms TO TRUE
END-READ
END-PERFORM.
UpdateFilmFile.
EVALUATE TRUE
WHEN DoDeletion PERFORM DeleteFilmRec
WHEN DoInsertion PERFORM InsertFilmRec
WHEN DoUpdate PERFORM UpdateFilmRec
END-EVALUATE
READ TransFile
AT END SET EndOfTrans TO TRUE
END-READ.
DeleteFilmRec.
MOVE FilmId-TF TO FilmId-FF
DELETE FilmFile RECORD
INVALID KEY DISPLAY FilmId-FF " - Delete Error. No such record"
END-DELETE.
InsertFilmRec.
*To preserve Referential Integrity check director exists for this Film
MOVE DirectorId-TF TO DirectorId-DF
START DirectorsFile
KEY IS EQUAL TO DirectorId-DF
INVALID KEY DISPLAY FilmId-FF " - Insert Error. No matching entry for director - " DirectorId-TF
END-START
IF MatchingDirectorFound
MOVE InsertionBody-TF TO FilmRec-FF
WRITE FilmRec-FF
INVALID KEY DISPLAY FilmId-FF " - Insert Error. That FilmId already exists."
END-WRITE
END-IF.
UpdateFilmRec.
MOVE FilmId-TF TO FilmId-FF
READ FilmFile RECORD
KEY IS FilmId-FF
INVALID KEY DISPLAY FilmId-FF " - Update error. No such record exists"
END-READ
IF FilmOk
MOVE FilmTitle-TF TO FilmTitle-FF
REWRITE FilmRec-FF
INVALID KEY DISPLAY "Unexpected Error1. FilmStatus - " FilmStatus
END-REWRITE
END-IF.
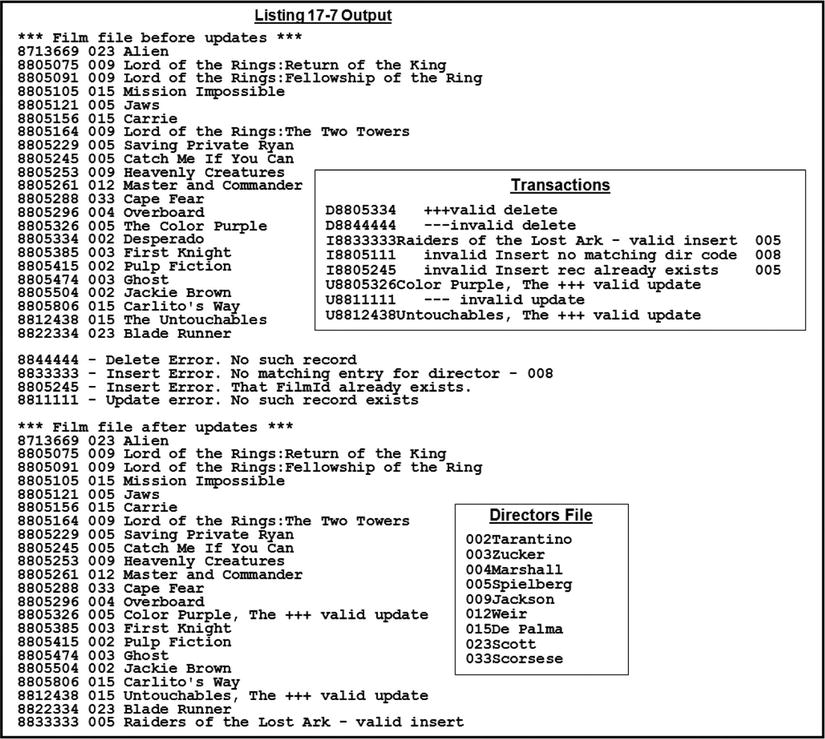
Figure 17-12. Output from Listing 17-7
There is not much to talk about here that I have not already discussed in relation to relative files, but let’s touch once more on the issue of referential integrity. When an insertion record has to be applied to FilmFile, you must make sure the director of that film has an entry in DirectorsFile. You do this in InsertFilmRec by using START with DirectorsFile and the director ID from TransFile to make sure there is a director with that ID in DirectorsFile. If there is a director with that ID, you try to apply the insertion.
Indexed Files: Syntax and Semantics
This section formally introduces the specific verb formats, clauses, and concepts required for indexed files.
Indexed Files: SELECT and ASSIGN Clause
The metalanguage for the SELECT and ASSIGN clause for indexed files is shown in Figure 17-13.

Figure 17-13. Metalanguage for SELECT and ASSIGN specific to indexed files
Consider the following:
- The key defined for a relative file by the RELATIVE KEY phrase in the SELECT and ASSIGN clause cannot be a field in the record of the relative file. In total contrast to this, every key (primary and alternates) defined for an indexed file must be a field in record of the indexed file.
- Every indexed file must have a primary key and may have up to 254 alternate keys.
- The primary key must be unique for each record and must be a numeric or alphanumeric data item. The primary key is identified by the RECORD KEY IS phrase in the SELECT and ASSIGN clause.
- Each alternate key must be numeric or alphanumeric and may be unique or may have duplicate values. The alternate keys are identified by the ALTERNATE RECORD KEY IS phrase in the SELECT and ASSIGN clause.
- If an alternate key can have duplicate values, then the WITH DUPLICATES phrase must be used. If WITH DUPLICATES is not used and you attempt to write a record that contains an alternate-key value that is already present in another record in the file, WRITE will fail, and a file status "22" (record already exists) will be returned.
When you define an indexed file with ACCESS MODE IS SEQUENTIAL, the file is always processed in ascending primary-key order. But if the file is defined with ACCESS MODE IS DYNAMIC and is processed sequentially, the file system must be able to tell which of the keys to use as the basis for processing the file. Because the format of the sequential READ does not have a key phrase, the file system refers to a special item called the key of reference to discover which key to use for processing the file. Before reading a file defined as ACCESS MODE IS DYNAMIC sequentially, you must establish one of the file’s keys as the key of reference. You do so by using the key in a START or a direct READ. When the file is opened, the primary key is by default the key of reference, and the next-record pointer is pointing at the first record.
Indexed files use the same verbs for file manipulation as relative files, but in some cases there are syntactic or semantic differences. This section examines only those verbs that differ in syntax or semantics from those used with relative files.
When an indexed file is defined with ACCESS MODE IS SEQUENTIAL, the READ format is the same as for sequential files. But when the file is defined with ACCESS MODE IS DYNAMIC, sequential processing of the file is complicated by the presence of a number of indexes. The order in which the data records are read depends on which index is being processed sequentially, and the index used is established by the key of reference.
For indexed files, the format of the READ used to read sequentially is the same as for relative files. But in the case of the direct READ, the format requires a KEY IS phrase to specify the key on which the file is to be read. The metalanguage for this format of READ is given in Figure 17-14.

Figure 17-14. READ format used to read an indexed file directly
To read a record directly from an indexed file, a key value must be placed in the KeyName data item (the KeyName data item is the area of storage identified as the primary key or one of the alternate keys in the SELECT and ASSIGN clause). When READ executes, the record with a key value equal to the present value of KeyNameis read into the file buffer.
After the record has been read, the next-record pointer points to the next logical record in the file. If the key of reference is the primary key, then this record is an actual data record; but if the key of reference is one of the alternate keys, the pointer points to the next alternate index base record.
If duplicates are allowed, only the first record in a group with duplicates can be read directly. The rest of the duplicates must be read sequentially using the READ NEXT RECORD format.
Here are some things to remember:
- If the record does not exist, the INVALID KEY clause activates, and the statement block following the clause is executed.
- If the KEY IS clause is omitted, the key used is the primary key.
- When READ is executed, the key mentioned in the KEY IS phrase is established as the key of reference.
- If there is no KEY IS phrase, the primary key is established as the key of reference.
- The file must have an ACCESS MODE of DYNAMIC or RANDOM and must be opened for I-O or INPUT.
The WRITE, REWRITE and DELETE Verbs
The syntax and semantics of the WRITE, REWRITE, and DELETE verbs is the same as for relative files, except that
- Direct access for all these verbs is based on the primary key only.
- Although REWRITE may not change the value of the primary key, it may change the value of any of the alternate keys.
The syntax for the START verb is the same as for relative files, except that instead of the format START FileName KEY Condition RelKey, the format is as is shown in Figure 17-15. The key of comparison is any of the keys specified in the indexed file’s SELECT and ASSIGN clause.
Just as with relative files, the START verb may be used to control the position of the next-record pointer. In addition, with indexed files, the START verb may be used to establish a particular key as the key of reference.

Figure 17-15. Metalanguage for the START verb
The primary key or one of the alternate keys is the key of comparison. To establish a particular key as the key of reference and position the next-record pointer at a particular record, you first move the key value to the key-of-comparison data item. Then you execute the statement START..KEY IS EQUAL TO .. if you want to position the next-record pointer at the record with a key equal to the value in the key of comparison, or START..KEY IS GREATER THAN .. if you want to position the next-record pointer at the succeeding record.
Remember these things:
- The file must be opened for INPUT or I-O when START is executed.
- Execution of the START statement does not change the contents of the record area (that is, START does not read the record—it merely positions the next-record pointer and establishes the key of reference).
- When START is executed, the next-record pointer is set to the first logical record in the file whose key satisfies the condition. If no record satisfies the condition, the INVALID KEY clause is activated.
Comparison of COBOL File Organizations
Now that you have examined all the COBOL file organizations, you may wonder which is the best one to use. The answer is that it depends. This section examines the advantages and disadvantages of each organization; from this information, you should be able to figure out which organization to use in a given situation.
First some terminology. The hit rate refers to the number of records in the file that are impacted when you process a file. For instance, if only 100 records are affected by an insert, a delete, or an update operation in a file of 100,000 records, the hit rate is low. But if 90,000 records are affected, the hit rate is high.
The records in a sequential file are held serially, one after another, on disk, tape, or other media. This organization has both advantages and disadvantages.
Disadvantages of Sequential File Organization
Sequential files have the following disadvantages:
- They are slow when the hit rate is low. To read a particular record, you have to read all the preceding records. To update records, you have to read all the records in the file and write them to a new file. This is a lot of work if all you are doing is changing a few of the records in the file.
- They are complicated to change. Changes to sequential files are batched together in a transaction file to minimize the low-hit-rate problem, but this makes updating sequential files much more complicated than updating direct access files. The complications arise from having to match the records in the transaction file with those in the master file (that is, the file to be updated).
- They take up double the storage when they are updated. The records in sequential files cannot be updated in situ; instead, a new file must be created that consists of all the records in the old file plus the insertions and minus the deletions. Of course, this storage problem may be transient, because once the new file has been created, you can delete the old file.
Advantages of Sequential File Organization
Sequential file organization also has a number of advantages:
- When the hit rate is high, it is the fastest file organization because the record position does not have to be calculated and no indexes have to be traversed. Because the records are stored contiguously, this organization takes advantage of the fact that the file system doesn’t access records on a per-record basis but instead scoops up a block or bucket at a time. When a block contains a number of records, the number of disk accesses required to process the file is greatly reduced.
- It is the most storage efficient of all the file organizations. No indexes are required, the space from deleted records is recovered, and only the storage actually required to hold the records is allocated to the file.
- It is the simplest file organization. Records are held serially, so you read them one after another.
- It allows the space from deleted records to be recovered. To delete records from a sequential file, you create a new file that does not contain the deleted records. Once you delete the old file, all the storage previously used by the deleted records is recovered and can be used for storing something else.
- Sequential files may be stored and processed on serial media such as magnetic tape. These media are cheap, removable, and voluminous.
You can think of the records in a relative file as a one-dimensional table stored on disk. The file system can calculate where each record is on the disk because it knows the start location for the file, and it knows the amount of storage required to store each record. The record location is calculated as RecordLocation = BaseLocation + (SizePerRecord * (RelativeRecordNumber - 1)).
Disadvantages of Relative File Organization
Relative file organization has a number of disadvantages:
- It wastes storage if the file is only partially populated with records. The file is allocated enough disk storage to hold records from 1 to the highest relative record number used, even if only a few records have been written to the file. For instance, if the first record written to the file has a relative record number of 100,000, room for that many records is allocated to the file.
- It cannot recover the space from deleted records. When a record is deleted in a relative file, it is marked as deleted, but the space that was occupied by the record is still allocated to the file. This means if a relative file takes up 1.5MB of disk space when full, it still occupies 1.5MB when 99% of the records have been deleted.
- It allows only a single, numeric key. The single key is limiting because often you need to access a file on more than one key. For instance, in a file of student records, you might want to access the records on student ID, student name, course code, or module code. The mention of using student name, course code, or module code highlights another drawback with relative files: you frequently need to access a file using an alphanumeric key.
- The relative file key must map on to the range of the relative record numbers for the file. The facts that the key must be in the range between 1 and the highest key value and that the file system allocates space for all the records between 1 and the highest relative record number used impose severe constraints on the key. For instance, even though StudentId is numeric, you can’t use it as a key because the file system allocates space for records between 1 and the highest StudentId written to the file. If the highest StudentId written to the file is 9976683, the file system will allocate space for 9,976,683 records. Universities rarely have this many students, so most of the file will be wasted space.
Sometimes you can get around the limitations of the relative key by using a transformation function to map the actual key onto the range of relative record numbers. There are a number of possible transformation or hashing functions. These transformations include truncation (using only some of the digits in the key as the relative record number), folding (breaking the key into two or more parts and summing the parts), digit manipulation (manipulating some of the digits in the key to produce a relative record number), and modulus division (using the remainder of a division operation as the relative record number). Some sophisticated transformation functions may even allow alphanumeric keys.
- Relative files must be stored and processed on direct access media. Because relative files are direct access files, they must be processed on direct access media such as a hard disk. They cannot be processed on magnetic tape or other cheap serial media; and if stored on tape, they must be loaded onto a hard disk before they can be used.
Advantages of Relative File Organization
Although relative file organization has many disadvantages, it also has the following advantages:
- It is the fastest direct access organization. Only a few simple calculations have to be done to locate a particular record.
- Records in a relative file have very little storage overhead. Unlike indexed files, which must store the indexes as well as the data, relative files have only a small storage overhead for each record (such as the record-deletion indicator).
- Records in a relative file can be read sequentially. In addition to allowing direct access, relative files allow sequential access to the records in the file.
As shown in the Figure 17-10 earlier, the records in an indexed file are arranged in ascending primary-key order in a series of chained buckets/blocks. In addition to the actual data records, the primary key has a number of index records. For each alternate key specified for the file, there is a similar arrangement; but instead of data records at the final level, there are records arranged in ascending alternate-key order that consist only of the key and a pointer to where the actual record may be found. As shown earlier in Figure 17-11, in addition to the records at the base level, there are a number of alternate-key index records.
Disadvantages of Indexed File Organization
Indexed file organization has many disadvantages:
- It is the slowest direct access organization, because indexed files achieve direct access by traversing a number of levels of index. Indexed files must have a primary-key index and an index for each alternate key. Each level of index implies an I/O operation on the hard disk. For instance, three I/O operations are required to read the record shown earlier in Figure 17-10: two for the index records and one for data record).
- It especially slow when writing or deleting records because then the primary-key index and the alternate-key indexes may need to be rebuilt.
- It is not very storage efficient, because indexed files must store the index records, the alternate index records, the data records, and the alternate data records.
- Space from deleted records is only partially recovered until the indexes are rebuilt (which has to be done periodically).
- Indexed files may only be processed on direct access media, because they are direct access files. They cannot be processed on magnetic tape.
Advantages of Indexed File Organization
As you have seen, indexed files have many disadvantages, but these are far outweighed by their advantages:
- They can use multiple, alphanumeric keys.
- They can have duplicate alternate keys.
- They can be read sequentially on any of their keys.
- They can partially recover space from deleted records.
- They can have multiple alphanumeric keys, and only the primary key must be unique.
Although indexed files have their disadvantages, the versatility afforded by having multiple, alphanumeric keys and being able to process the file both directly and sequentially on any of its keys overrides all their disadvantages. As a result, indexed files are the most widely used direct access file organization.
Summary
This chapter introduced COBOL’s direct access file organizations: indexed and relative files. You learned about the arrangement of records in each of these file organizations, along with new concepts such as file status, the next-record pointer, and key of reference. You explored the syntactic and semantic changes that allow the existing file-processing verbs to process direct access files, and you were introduced to new COBOL file-processing verbs such as DELETE, REWRITE, and START. In the final section of the chapter, you saw the advantages and disadvantages of each of the COBOL file organizations.
The next chapter discusses the COBOL Report Writer. The Report Writer allows you to write programs that produce reports using declarative rather than procedural/imperative techniques. In imperative programming, you tell the computer how to do what you want done. In declarative programming, you tell the computer what you would like done, and the computer works out how to do it.
The Report Writer also uses a kind of specialized exception handling called declaratives. You can also use declaratives with files. When you specify the declaratives for a file, an exception that would normally activate the AT END or INVALID KEY clause instead executes the code you have written in the DECLARATIVE SECTION to deal with the problem.
By way of introduction, the answer to the exercise at the end of this chapter uses the Report Writer to print a small report. Because you don’t know how to use the Report Writer yet, you have to do the exercise the hard way. There is nothing like the pain of coding a report program to make you appreciate the benefits of the Report Writer!
PROGRAMMING EXERCISE
Time for a little exercise. Whip out your 2B pencil and see if you can come up with a solution to this problem.
Introduction
Acme Automobile Parts Limited sells motorcycle and automobile spare parts. Recently, the company purchased a computer and retained your firm to write the programs required. Your supervisor has asked you to write the program detailed next.
General Description
The program is required to perform file maintenance on the vehicle master file using a transaction file of validated amendment records. The transaction file has been sorted on ascending date (YYYYMMDD). If an error is encountered when attempting to apply transactions to the vehicle master file, then the transaction record must be written to an error file (Listing17-8-Err.DAT). When a vehicle record is deleted, the spare parts stocked for that vehicle are no longer required and so must be printed to a redundant stock report (Listing17-8-Stk.RPT).
There are two types of records in the transaction file, and they are distinguished from one another by the codes "I" (insert vehicle record) and "D" (delete vehicle record) in the first character position of the record.
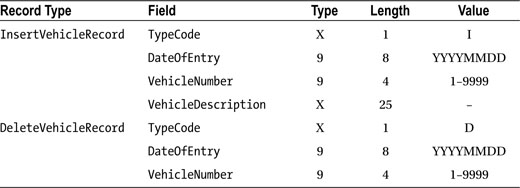
The vehicle master file (Listing17-8-VMF.DAT) is a relative file. VehicleNumber is used for the relative record number. Each record has following description:

The stock master file (Listing17-8-SMF.DAT) is an indexed file. It is required so that you can report all the stock records that are affected when a vehicle is deleted from the vehicle master file. Each record in the stock master file has the following record description:

Type Code |
Action |
|---|---|
I |
If a record with this VehicleNumber already exists in either the stock or vehicle master file, then write the transaction record to the error file. Otherwise, insert the record. |
D |
If the record does not exist in the vehicle master file, then write the transaction record to the error file. |
If there is no error, then read all the stock records with the same VehicleNumber as the record to be deleted and write the details to the redundant stock report. | |
Rewrite the VehicleNumber field in each of these stock records with zeros. Delete the vehicle master file record. |
Headings should be printed at the top of each page. See the print specification in Figure 17-16 for further details.
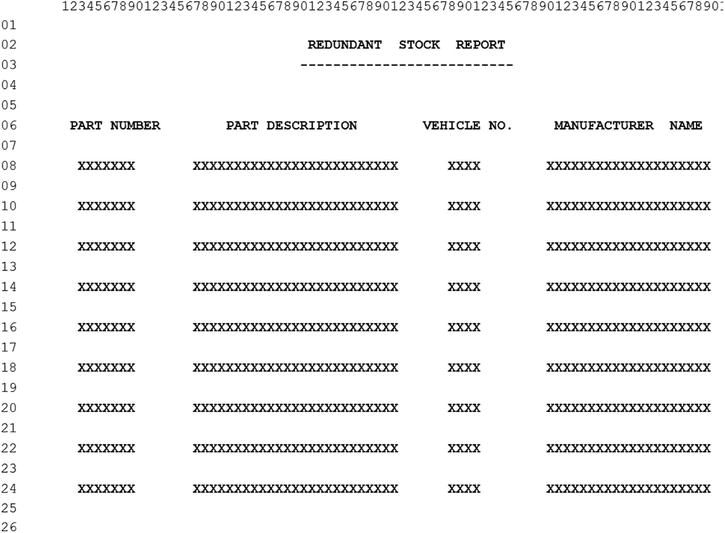
Figure 17-16. Print specification. Line numbers and column numbers added
PROGRAMMING EXERCISE: ANSWER
IDENTIFICATION DIVISION.
PROGRAM-ID. Listing17-8.
AUTHOR. MICHAEL COUGHLAN.
*Applies Insertions and Deletions in TransFile to the VehicleFile.
*For Insertions - If a vehicle already exists in either the Stock or
*Vehicle file, the transaction record is written to the Error File otherwise inserted
*For Deletions - If the vehicle does not exist in the Vehicle File the transaction
*record is written to the Error File otherwise the Vehicle record is deleted
*If the vehicle record is deleted all the Stock records with the same VehicleNumber
*as the deleted record are written to the Redundant Stock Report and the VehicleNumber
*field in each of these Stock records is overwritten with zeros.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT StockFile ASSIGN TO "Listing17-8-SMF.DAT"
ORGANIZATION IS INDEXED
ACCESS MODE IS DYNAMIC
RECORD KEY IS PartNumSF
ALTERNATE RECORD KEY IS VehicleNumSF
WITH DUPLICATES
FILE STATUS IS StockErrStatus.
SELECT VehicleFile ASSIGN TO "Listing17-8-VMF.DAT"
ORGANIZATION IS RELATIVE
ACCESS MODE IS DYNAMIC
RELATIVE KEY IS VehicleNumKey
FILE STATUS IS VehicleErrStatus.
SELECT TransFile ASSIGN TO "Listing17-8-TRANS.DAT"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT ErrorFile ASSIGN TO "Listing17-8-ERR.DAT"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT RedundantStockRpt ASSIGN TO "Listing17-8-STK.RPT".
DATA DIVISION.
FILE SECTION.
FD StockFile.
01 StockRecSF.
02 PartNumSF PIC 9(7).
02 VehicleNumSF PIC 9(4).
02 PartDescSF PIC X(25).
FD VehicleFile.
01 VehicleRecVF.
02 VehicleNumVF PIC 9(4).
02 VehicleDescVF PIC X(25).
02 ManfNameVF PIC X(20).
FD TransFile.
01 TransRecTF.
02 TransTypeTF PIC X.
88 InsertionRec VALUE "I".
88 DeletionRec VALUE "D".
02 DateTF PIC X(8).
02 VehicleNumTF PIC 9(4).
02 VehicleDescTF PIC X(25).
02 ManfNameTF PIC X(20).
FD RedundantStockRpt REPORT IS StockReport.
FD ErrorFile.
01 ErrorRec PIC X(56).
WORKING-STORAGE SECTION.
01 ErrorStatusCodes.
02 StockErrStatus PIC X(2).
88 StockFileOpOK VALUE "00", "02".
88 StockRecExistis VALUE "22".
88 NoStockRec VALUE "23".
02 VehicleErrStatus PIC X(2).
88 VehicleFileOpOK VALUE "00".
88 VehicleRecExists VALUE "22".
88 NoVehicleRec VALUE "23".
01 FileVariables.
02 VehicleNumKey PIC 9(4).
02 PrevVehicleNum PIC 9(4).
01 ConditionNames.
02 FILLER PIC X.
88 EndOfStockFile VALUE HIGH-VALUES.
88 NotEndOfStockFile VALUE LOW-VALUES.
02 FILLER PIC X.
88 EndOfTransFile VALUE HIGH-VALUES.
REPORT SECTION.
RD StockReport
PAGE LIMIT IS 66
HEADING 1
FIRST DETAIL 6
LAST DETAIL 50
FOOTING 55.
01 TYPE IS PAGE HEADING.
02 LINE 2.
03 COLUMN 31 PIC X(24) VALUE
"REDUNDANT STOCK REPORT".
02 LINE 3.
03 COLUMN 30 PIC X(26) VALUE ALL "-".
02 LINE 6.
03 COLUMN 2 PIC X(36) VALUE
"PART NUMBER PART DESCRIPTION".
03 COLUMN 45 PIC X(35) VALUE
"VEHICLE NO. MANUFACTURER NAME".
01 DetailLine TYPE IS DETAIL.
02 LINE IS PLUS 2.
03 COLUMN 3 PIC 9(7) SOURCE PartNumSF .
03 COLUMN 17 PIC X(25) SOURCE PartDescSF.
03 COLUMN 48 PIC 9(4) SOURCE VehicleNumSF.
03 COLUMN 60 PIC X(20) SOURCE ManfNameVF.
PROCEDURE DIVISION.
Begin.
OPEN INPUT TransFile.
OPEN I-O StockFile
VehicleFile.
OPEN OUTPUT ErrorFile
RedundantStockRpt.
INITIATE StockReport
READ TransFile
AT END SET EndOfTransFile TO TRUE
END-READ
PERFORM UNTIL EndOfTransFile
MOVE VehicleNumTF TO VehicleNumKey
VehicleNumSF
EVALUATE TRUE
WHEN InsertionRec PERFORM CheckStockFile
WHEN DeletionRec PERFORM DeleteVehicleRec
WHEN OTHER DISPLAY "NOT INSERT OR DELETE"
END-EVALUATE
READ TransFile
AT END SET EndOfTransFile TO TRUE
END-READ
END-PERFORM
TERMINATE StockReport
CLOSE ErrorFile
RedundantStockRpt
TransFile
StockFile
VehicleFile
STOP RUN.
CheckStockFile.
READ StockFile KEY IS VehicleNumSF
INVALID KEY CONTINUE
END-READ
IF StockFileOpOK
PERFORM WriteErrorLine
ELSE IF NoStockRec
PERFORM InsertVehicleRec
ELSE
DISPLAY "Unexpected Read Error on Stockfile"
DISPLAY "Stockfile status = " StockErrStatus
END-IF
END-IF.
InsertVehicleRec.
MOVE ManfNameTF TO ManfNameVF
MOVE VehicleDescTF TO VehicleDescVF
MOVE VehicleNumTF TO VehicleNumVF
WRITE VehicleRecVF
INVALID KEY CONTINUE
END-WRITE
IF VehicleRecExists PERFORM WriteErrorLine
ELSE IF NOT VehicleFileOpOK
DISPLAY "Unexpected Write Error on VehicleFile."
DISPLAY "Vehicle file status = " VehicleErrStatus
END-IF
END-IF.
DeleteVehicleRec.
READ VehicleFile
INVALID KEY CONTINUE
END-READ
IF NoVehicleRec PERFORM WriteErrorLine
ELSE IF VehicleFileOpOK
DELETE VehicleFile RECORD
INVALID KEY
DISPLAY "Unexpected Delete Error on VehicleFile"
DISPLAY "Vehicle file status = " VehicleErrStatus
END-DELETE
PERFORM UpdateStockFile
ELSE
DISPLAY "DeleteProblem = " VehicleErrStatus
END-IF
END-IF.
WriteErrorLine.
MOVE TransRecTF TO ErrorRec
WRITE ErrorRec.
UpdateStockFile.
MOVE VehicleNumSF TO PrevVehicleNum
READ StockFile KEY IS VehicleNumSF
INVALID KEY CONTINUE
END-READ
IF StockFileOpOK
SET NotEndOfStockFile TO TRUE
PERFORM PrintStockRpt
UNTIL VehicleNumSF NOT EQUAL TO PrevVehicleNum
OR EndOfStockFile
END-IF.
PrintStockRpt.
GENERATE DetailLine
MOVE ZEROS TO VehicleNumSF
REWRITE StockRecSF
INVALID KEY DISPLAY "ERROR ON REWRITE"
END-REWRITE
READ StockFile NEXT RECORD
AT END SET EndOfStockFile TO TRUE
END-READ.