
![]()
Getting to Know Neo4j
Now that we’ve been over the theory of the various types of database, and even had a bit of a history lesson on the origins of graph theory, it’s time to get into the good stuff, Neo4j. This chapter will give you a full overview on Neo4j, how it works, who’s using it, and of course, why you should be using it. To kick things off, let’s get a bit of information about Neo4j, and have a look at why you should be using it.
Neo4j is an open-source project, backed by Neo Technology which started back in 2003, with the application being publicly available since 2007. You can install Neo4j on Windows, OS X, or Linux so you can pretty much install it wherever you like, provided the machine meets the minimum requirements. The minimum requirements are detailed in the “Under the hood” section of this chapter.
The source code and issue tracker are available on GitHub so the community can help with the development of the product. There is an enterprise option of the application which has additional features, support, and is essentially a different product. This version is also closed-source, so it’s only available when you pay for the license. You would only need to use the Enterprise edition if you had a very large Neo4j-backed application, and would be more comfortable having dedicated support. There is also a free Personal license which is applicable if you’re in a company that has less than three employees, you are self-funded, and don’t have more than US$100K in annual bookings. Essentially, if you’re working on some kind of small application, you’ll be fine with the personal license.
The current release (2.2.5) shows a great improvement over previous versions with speed increases, reliability increases, an optimized browser, faster Cypher queries, and a fancy new logo which can be seen in Figure 2-1. This will be the version used throughout the book, so in newer versions there may be some differences in the user interface and functionality, but wherever possible, I’ll be trying to keep everything as relevant as possible. Technical books have to deal with this issue a lot, where versions change, and after the time of printing sometimes the code samples no longer work. To try and keep these instances down to a minimum I’ll be hosting certain code samples and code online, so that if changes do happen the hosted code can be updated, to help keep things relevant. In the cases where this is applicable throughout the book, where the code can found will be made clear as and when it’s needed.

Figure 2-1. The new logo for Neo4j as of the 2.2.0 release
Neo4j has always touted itself as “the World’s Leading Graph Database” (it’s even in the website title) and based on the releases mentioned on their website, they seem to put out new versions of the site every month on average. The 2.0 release came out back in 2013 and since then, they’d been maintaining the 1,9.* version of the application (which now sits as version 1.9.9, and is not recommended for use, but is still available) as well as the new version. This shows the software is being frequently updated with bug fixes and optimizations. You can read more about the different releases at http://neo4j.com/release-notes should you be interested.
Although the release history is good to know, it’s not what’s most important here. We’re here to talk about the current release (2.2.5) so let’s get on with that, shall we?
To communicate with Neo4j, you use its REST API via HTTP. For those unfamiliar with what REST is, then this is for you. Representational state transfer, or REST is a style used when designing network applications, and in pretty much all cases, HTTP is used to send the needed data to the application. When an application implements this protocol, it uses the HTTP verbs: GET, PUT, POST, and DELETE to perform certain actions within the application. In a nutshell this is how REST works, and it’s what Neo4j uses to manage its data. This is just a heads up if you see REST later in the book and aren’t sure what it is.
Why Choose Neo4j?
Of course there are a lot of reasons to use Neo4j, some of which I’ll explain in a bit more detail, and a few others that are just worth mentioning. Neo4j has a huge community built around its 1,000,000+ downloads (which is mentioned on the website as one off the top 10 reasons to use it), and that figure is growing every month. They’re also able to boast 500+ Neo4j events a year, 20,000+ meetup members, and a whole lot more.
These organized meetups mean that all over the world there are people who are passionate about Neo4j and want to talk about it, or so the website claims. Technology-based Meetups (whether it’s about Neo4j, or any other technology) allow you to get insight into new techniques, use cases, examples, or even ideas that you had never thought of. When you’re in a room with a lot of like-minded people, everyone is able to help each other and share ideas, you never know what’ll happen when you go to a meetup.
Since 2000, Neo4j has been growing into its position as the top graph database on the web today, and there’s a lot of work that’s gone into getting it that far. Now, some 15 years later, Neo4j is a hugely dependable product offering scaling capabilities, incredible read and write speed, and of course full ACID compliance.
One of the big benefits of Neo4j (which will be seen as we go through the book) is that it’s easy to pick up and learn. Although it’ll be covered below, the query language, Cypher, has been designed to be descriptive to make it easier to understand, and also to learn. The Neo4j team has also published a number of helpful articles on different use cases for Neo4j, with how-to guides included. These can be found on their website, should you want to take a look.
When you’re building an application around a particular technology, you want to have confidence that you’ll be able to host said technology and that it’ll be able to cope with the large amount of traffic you’re application will get (we can all dream for that, right?), and Neo4j is no exception. This is reliant on two factors though, Neo4j itself and where it’s hosted. Hosting options for Neo4j will be covered in Chapter 9, so you’ll be able to learn more about the hardware side of things there, but as long as you have a solid hosting platform, Neo4j is designed to deal with large amounts of traffic.
In addition to many other features, Neo4j offers cluster support and high availability (HA) which means that, thanks to its master/slave design and its ability to propagate changes between the other instances in the cluster, your application will not only stay up under pressure, it’ll be fast too.
When the developers behind Neo4j were working on the query language to power it, they wanted something easy to use and easy to read. As mentioned above, Cypher was designed to be easy to read, and is described as “like SQL a declarative, textual query language” on the Neo4j website. The reasoning for developing Cypher this way comes down to ease of use, but also to help those coming from an SQL background feel more at ease using a non-SQL-like database. There’s a full chapter dedicated to Cypher and all of its glory, so there won’t be too much detail here, but you can’t mention the reasons for choosing Neo4j without mentioning Cypher.
To make things as easy as possible, Cypher queries are descriptively written, and when the syntax finally clicks it makes it so easy to familiarize yourself with how it all fits together. When I was first using Cypher, I had to keep referring to the documentation to see where I was going wrong, but eventually it clicked and all made sense. We’ll be going into a lot more detail about how Cypher works in a later chapter, so more complex actions will be covered for there. As with everything it’s best to start with the basics. The basic Cypher syntax is as follows:
() Node
{} Properties
[] Relationships
These can be combined in a number of ways to achieve different queries. When searching through data, adding a property can filter the result set down, based on the value of that property. The same can be said for relationships, adding a relationship constraint to a query can give a more relevant and condensed result set, rather than seeing everything. One basic query that you may use a lot (I know I do) is:
MATCH (n) RETURN n;
This query returns every node in the database, which in the query itself is aliased with `n`. When I say every node, I do mean that, so it’s advisable that you only run this on local environments, and not in production. If you ran this on a database with millions of nodes, it would take a long time and could also block some important transactions from happening. A property constraint could have to be added to the query to make it return a smaller subset of results, but sometimes, you just like to look at all the nodes in the graph. Using constraints would be recommended if are querying data on a large database to reduce to load time and make your result set smaller.
Relationships are one of the things Cypher tried to keep simple. It was also important to make the query language look descriptive, which you can see in the following query.
MATCH (a)-[:CONNECTED]->(b) RETURN a, b;
This query illustrates getting all nodes that are related to each other by the `CONNECTED` relationship, and then returning these nodes for use somewhere else. The main thing about relationships is the direction, illustrated by the --> in the above. In the example it’s looking for any nodes related to any other nodes by that relationship, so depending on your dataset, that could be a lot of nodes. In this case though, any node `a` with an directed relationship `CONNECTED` to another node `b`. There are multiple ways this could be made more specific, such as searching for nodes with a specific label, or a specific property.
Although this overview is quite basic, it should hopefully give a taste of what Cypher can do, but also how easy it is to use, even with something like relationships. In the coming chapters, there will be a more detailed overview on Cypher itself, how to use it, and some of the more complex operations it’s capable of. It’s still possible to see that thanks to the way it’s written, it makes the learning curve quite low, so you can be working on complex queries quickly. The use of Cypher also goes hand in hand with Neo4j’s Browser, which is amazing, and a very powerful tool when it comes to learning the language. With that being said, let’s talk about the Browser.
With the release of 2.2.0 came a new version of the Browser bundled with Neo4j (as shown in Figure 2-2). Before the update it was nice, but the improved design, layout, and speed make it so much better. The browser gives you the ability to query your database using Cypher, where you’ll be able to view live results.
Figure 2-2. The screen that greets you when you navigate to the Neo4j browser
Working this way offers a number of advantages, including instant feedback, so if you make a mistake, you know what went wrong. The results returned from these queries can be seen in a graph (if applicable) or as a list of results. Each of these has their advantages, being able to see the graph allows you to see relationships, and potentially modify your query to make it more optimized.
When you set up Neo4j, you’ll have a blank database, but to make the process of learning Cypher easier, a number of sample graphs are included within the browser that you can load in and experiment with. One of these graphs is the movie graph, which is provided by the lovely people at Neo Technology, and is simple to install. You can type `:play movie graph` to view the instructions required to load in this data into your database.
To demonstrate what the different result types look like, I’ll be running `MATCH (n) RETURN n;` against this database. If you have access to Neo4j (installation instructions are available in Chapter 3) I’d advise you do the same. Whether you’re performing the query yourself, or just following along (which is of course perfectly fine) then the results will look similar to Figure 2-3.
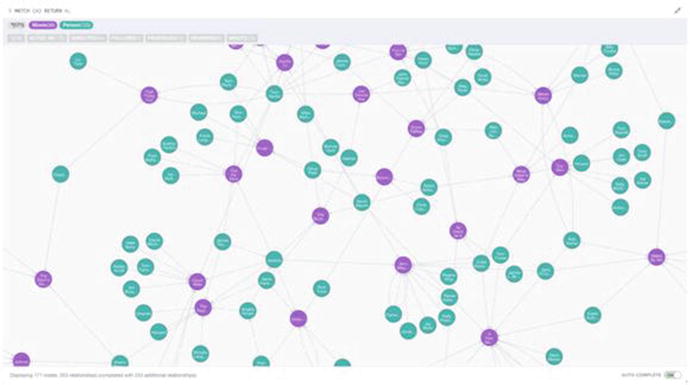
Figure 2-3. The graph view of running a MATCH (n) RETURN n; query on the Neo4j movie database
Although you can’t see it from Figure 2-3, the result graph is very interactive. You can click on Nodes to get their individual properties, relationships, and an overview of your data. You can also see labels attached to nodes, and different labels can even be color coded to make it easier. If a node has multiple relationships, the graph will do its best to make these all visible, although some overlapping can occur if there are a lot of nodes. To make things even easier, you can also change the color or size of a relationship or node to make things easier to distinguish.
In Figure 2-4 you can see the list view with no display options, just data. The list view allows you to see all of the properties associated with your nodes, in a more traditional table-style layout. If you have a lot of data in your database, being able to see queries in this way is better because it allows you to see all of the properties of your returned nodes at a glance.
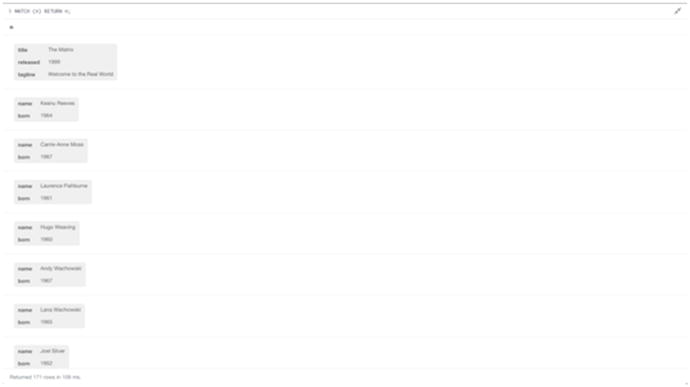
Figure 2-4. The rows view of running a MATCH (n) RETURN n; query on the Neo4j movie database
Whenever possible, you’ll be given the chance to view your results in both views; however it’s not always possible to plot the results on a graph. This can happen when you’re returning specific properties from a node or relationship. In this case you would only be presented with the table view. Essentially, if your result set can be viewed as a graph, the option to view it will be available.
Every query performed is still visible on the screen when you perform another (unless you delete it manually, that is) so you always have a history to refer back to if you aren’t quite sure which results were returned from a particular query. In addition, you can also stop slow/inefficient queries (that’s a new feature as of 2.2.0) so that it doesn’t crash the application. You can also export the graph in a number of formats, including SVG, CSV, JSON, and PNG, if you want to export that set of results, or use it in a presentation. You can also export the table-based output as a CSV or JSON.
The browser allows you to easily interact with Cypher so you could create your entire data structure from the browser. Having the browser can be useful when hosting Neo4j, as it allows you to interact with your data easily, directly from the browser. It also contains a number useful links, the option to read tutorials, manage user settings, and more. You can also save queries for later if you have certain ones you like to run more often, or to make running a demo easier.
Thanks to Neo4j’s REST interface (which will be covered in just a moment) you may never need to use the browser, but it’s a great resource, especially when learning. It’s useful to use when texting queries that are going to be used in applications, as it gives not only the query results, but also shows any errors, and provides the execution time, so if a query is running a bit slow, you can tweak it in the browser to get it right, then put it in your application.
If you run a system with registrations or user-created content, being able to quickly jump into the browser and run a simple query allows you to see new registrants, new nodes/relationships, and more. You could even save these queries for later use (using the star icon) to make it even easier. If you want to use the result for something, then you can just export it into the previously mentioned formats, nice and simple.
Another interface available through the browser is webadmin, which can be found by clicking the information icon in the sidebar and then clicking the “Webadmin” link at the bottom of the panel. This is essentially an administration section for Neo4j, where it’s possible to view rough stats, check configuration values, and much more. For most beginners, this section won’t really be of much use, but knowing it’s there and what it can be do is useful.
When you first navigate to webadmin (http://localhost:7474/webadmin/) you’ll be presented with a presentation about the features available within the section, should you need it. If not though, it can be closed and you’ll gain access to the first tab, the dashboard. If you close it accidentally, or you’d like to have another look at the guide, a link to it is available from the top-right corner of the screen.
On the dashboard you’ll be able to see some statistics about your database; however it’s worth noting these values are approximate because this data is intended to give a status of the system, rather than giving exact stats. Either way, you can see counts for: nodes, properties, relationships, relationship types, and approximate values for database disk usage and logical log disk usage.
In addition, you get access to a graph for the counts of the nodes, properties, and relationships, which can be broken down into various time increments. This allows you to see the growth (or fall, if your application removes values) of the values within your database, and also a breakdown of when certain spikes or surges occur. When trying to debug issues, or gain additional insight into your application, being able to see at a minimum the last 30 minutes’ values, right up to a years’ worth of data is useful.
That’s just the dashboard! The webadmin also allows you to interact with Neo4j in a number of ways, including easily updating node values, indexes, and more. You can also gain access to the configuration values being used for Neo4j, the underlying JVM, and more. This section within the browser provides multiple means of access to your data and easy interfaces for updating values. Although a beginner may not use this tool much, it has many features, and Neo4j allows you to overview the configuration straight from the browser, rather than having to access the server directly.
Under the hood
To make an application this universal and powerful, you need to use a quality tool. In this case, Neo Technology opted for Java, well, Java 7 to be precise. Java has been around for at least 20 years, and the fact it tries to make it so its developers will write the code once, and (hopefully) run it anywhere, makes Neo4j’s cross-platform nature a lot easier. I could very easily go into a lot of detail about Java; however for the purposes on Neo4j, or at least the beginning aspects of it, all that needs to be taken from the use of JVM (Java Virtual Machine) is that it’s a good choice.
To make the building of the various applications Neo4j is responsible for easier, it also utilizes Apache Maven. Apache Maven is an open-source project management tool that makes aspects of the managing the codebase for the project a lot easier.
The browser that comes with Neo4j is built using Node.js which is built on Google Chrome’s Javascript engine, and is fast, lightweight, and efficient. Using Neo4j’s REST interface allows the browser to interact with the data within Neo4j really easily. It’s good to see that the browser is built using the same REST interface that anybody has access to in Neo4j, so if you wanted to, you could build your own browser.
With all of these specs you’d think you’d need a beast of a machine, and if you go off the recommended specifications, you’d be correct. If you’re going to be processing a huge database, then you’ll need a pretty powerful machine, the specs of which can be seen in Table 2-1.
Table 2-1. The minimum and recommended specifications for Neo4j
Requirement | Minimum | Recommended |
|---|---|---|
CPU | Intel Core i3 | Intel Core i7 |
Memory | 2GB | 16—32GB or more |
Disk | 10GB SATA | SSD w/ SATA |
Filesystem | ext4 (or similar) | ext4, ZFS |
The specs themselves aren’t actually too bad, part of the use of Java requires a bit more RAM than normal for caching and other operations, and the better CPU is for better graph computation, so they’re reasonable recommendations. The recommended disk is an SSD to increase the speed of reads and writes, and the filesystem needs to be ext4 or ZFS (Standard in UNIX based filesystems) to ensure it can be fully ACID compliant, because they take advantage of ext4 and ZFS ACID-compliant writes. Compared to some, this application isn’t as hungry, and this level of specification is only needed if Neo4j is going to be powering a large amount of data, and handling a lot of operations.
Who’s Using it?
With Neo4j launching back in 2003, you can imagine that there are a number of people using it by now, and you’d be correct! With downloads for this graph database now over a million, among all of those downloads are some high-profile clients, such as Ebay, Walmart, and Cisco. In these cases each of the clients, high profile or not, happen to have their own use case for Neo4j, be it for recommendations or social aspects, and Neo4j is the tool for the job. Some of the other companies said to be using Neo4j (according to the Neo4j website) are as follows:
- onefinestay
- Zephyr Health
- FiftyThree
- Gamesys
- Lufthansa Systems
- Wanderu
- Tomtom
- Telenor
- Infojobs
- Zeebox
- classmates
- spring
- HP
- National Geographic
Social and recommendation aspects aren’t the only reasons to use Neo4j. Clients also boast being able to use it for Fraud Detection, Identity and Access management, Data management, and more. This is of course a small subset of actual clients and use cases, and with 200 enterprise subscription customers, including 50+ of the Global 2000, there is certainly no shortage in companies, big or small, that see Neo4j as the solution to their various graph database problems. For more information on Neo4j users, go to http://neo4j.com/customers/.
If you’re from the database world at all, then you’ll know about an index. A database index is a copy of information in the database for the sole purpose of making retrieving said data more efficient. This does come at the cost of additional storage space and slower writes. With Neo4j, an index can be created for a particular property on a node, that has a certain label. Applying the index is done using the following query:
CREATE INDEX ON :Person(name)
This query will make an index on all of the name properties for any node with the label `Person` so if that query is one that is used often in your code, then this will be a lot faster. To save on speed, when Neo4j adds an index, it is not immediately available, and will be added in the background. When the index is ready, it’ll be automatically used within your existing queries if it’s possible to do so.
Being able to use indexes in this way means you can monitor your application for potential places for improvement, and then apply an index to help speed up the operation. The index will also be kept up to date without any additional maintenance, so if it’s done correctly you’d just apply an index, forget about it, then reap the sweet optimized rewards. For some reason though, an index may not be working out for you. If that’s the case, an index can easily be dropped. Again with no change to any existing code, Neo4j will work out whether an index is applicable to use by itself. There will be a more in-depth look at indexes in Chapter 4, this was just a brief overview to show that indexes are available within Neo4j, and are easy to use.
Caching
To help Neo4j be as fast as possible, two different caching systems are used: a file buffer cache and an object cache. These two systems have very different roles. The file buffer cache is intended to speed up queries by storing a copy of the information retrieved from the graph, whereas the object cache stores optimized versions of nodes, properties, and relationships to speed up graph traversal.
When data is returned from the database, it’s then stored in the cache in the same format, so if the same data is asked for again, it can be quickly retrieved. In addition when writing to the cache, each action is written to the transaction log, so if something does happen, Neo4j’s ACID nature will stop this from being written, and the data will be available in the logs for recovery. This however is just an edge case as the cache is perfectly safe to use, and gives a speed increase as a bonus. The cache will also try and optimize things where it can as well. For example, if lots of small transactions are taking place, these will be combined to have fewer page rights, and therefore, you guessed it, more speed.
Of course you can’t just cache the whole database, but that would take up a lot of storage, and that just isn’t a viable option, so to avoid this, you’ll set a cache limit. The more cache you have, the more space it’ll take up, so essentially the bigger the cache you have, the more disk space you require. This can then have additional cost constraints if you’re hosting provider is capped by size because increasing the limit usually results in an increased cost.
Data stored within the cache isn’t always needed. Sometimes an action may be a one-off, whereas other repeated actions remain uncached. To get around this, Neo4j will keep an eye on the size of the cache, when it begins to reach capacity, it’ll swap out old, unused items with better ones that will make the system faster. It’s all very clever.
Depending on your needs, it’s possible to change the amount of space dedicated to this cache. Since the data in this cache is stored within RAM, it’s not always possible to dedicate large amounts to it; however, it cannot be disabled, so it’s highly recommended you have at least a few megabytes dedicated to it. Although it’s a useful cache to have enabled, it’s good to know you can strip its RAM dependency right down, especially on systems where there isn’t a lot of RAM available.
The other caching system within Neo4j is the object cache, which allows for fast traversal of the graph and is split into two types: reference caches and high-performance caches. The reference cache system utilizes the fact it’s built on Java to maximize as much of the JVM heap memory as possible. Now this could be a very greedy process, but luckily, the cache is the lowest rung in the ladder, and will only maximize its use of the heap memory if it’s safe to do so. Essentially, any shared applications running on the same JVM aren’t using it, and Neo4j itself doesn’t need it for anything else, so on that side, it keeps itself clean.
The cache system itself stores nodes and their relationships, so with this cache in place, if you’ve done a lookup already and the data hasn’t changed, the query will hit the cache and give a response immediately, just as you’d expect from a cached system.
The other variant of the object cache, high-performance, is only available in the Enterprise edition of Neo4j, and stores nodes, their relationships, and their properties. This on the surface sounds great, if there’s more stuff in the cache, then that makes everything faster, right? Although this can be the case, it won’t always be. This caching system relies heavily on Java’s garbage collection to ensure the cache doesn’t get too large. Although this cache can be very powerful, it’s one that must be monitored to ensure there weren’t any large pauses or performance losses when the caches were cleared.
Extending Neo4j
It’s possible to add additional functionality to Neo4j with the use of plugins. If there is a particular bit of functionality you want in Neo4j, there may be well be a plugin for it, or if you’re feeling up to the task, you could write the plugin yourself. One of the more popular plugins is the Spatial plugin, which extends Neo4j to allow it to do location-based queries. This gives some very powerful functionality to Neo4j, by exposing a series of location-based tools and shows the power of plugins and how extendable Neo4j is.
Plugins can be installed in a variety of ways, depending on how they’re built. For example, the Spatial plugin can be installed using Apache Maven, as well as being placed in the plugins directory (/var/lib/neo4j/plugins, if you’ve installed in the default location) directly. Although plugins can be installed in a number of ways, the fact that it’s possible to use them in the first place is the main thing.
Summary
This chapter provided more insight into Neo4j and some of its many features. As the book progresses, a number of these features will be explained in more detail, especially Cypher since it’s Neo4j’s query language and will be used to interact with Neo4j throughout the book. Not only is Neo4j currently boasting a new release, 1,000,000+ downloads, and more than 10 years in production, it has also made a solid place for itself in the market, that isn’t going to change any time soon.
With its ever-growing time in production, the community, and resources for the community continue to grow, if you ever have a query, StackOverflow, the Google group, or even the dedicated support staff at Neo Technologies can help. If you’re having a problem, odds are that someone has had that problem before, so have a search and you may well find your answer. Failing that, if you create a post on either StackOverflow or the Google group, somebody will be able to help you.
A very brief look at Cypher has shown the potential power it has as a language, and how easy it is to use. The descriptive nature of the query language keeps it easy to pick up, and you can try and much as you like in Neo4j’s browser, using the demo data, or your own. The browser is a brilliant accompaniment to an equally brilliant platform, and adds a set of tutorial and data-management tools, as well as the console where you can interact with your Neo4j data live, with the chance to view the results in table or graph format.
We’ve talked enough about why Neo4j is good to use, and have also learned a bit more about it in this chapter. Now, it’s time to actually get Neo4j up and running on your system, which is covered in the next chapter.