
Inference is the process of forming conclusions from premises. The inferred knowledge is harmful when the user is not authorized to acquire such information from legitimate responses that he/she receives. Providing a solution to the inference problem where users issue multiple requests and consequently infer unauthorized knowledge is an open problem. An inference controller is a device that is used to detect or prevent the occurrence of the inference problem. However, an inference controller will never know in full the inferences possible from the answers to a query request since there is always some prior knowledge available to the querying user. This prior knowledge could be any subset of all possible knowledge available from other external sources. The inference problem is complex and, therefore, an integrated and/or incremental domain-specific approach is necessary for its management. For a particular domain, one could take several approaches, such as (1) building inference controllers that act during query processing, (2) building inference controllers that enforce constraints during the knowledge base design, and (3) building inference controllers that provide explanations to a system security officer. Over time, the provenance data as well as the data deduced from the provenance data combined could become massive and therefore we need big data management techniques for handling the inference problem.
This chapter discusses the implementation of these incremental approaches for a prototype inference controller for provenance in a medical domain. The inference controller that we have designed and developed protects the sensitive information stored in a provenance database from unauthorized users. The provenance is represented as a directed acyclic graph. This graph-based structure of provenance can be represented and stored as an RDF graph [KLYN04], thereby allowing us to further exploit various semantic web technologies. In our work, we have built a prototype to evaluate the effectiveness of the proposed inference controller. We store the provenance information as an Web Ontology Language (OWL) knowledge base and use OWL-compliant reasoners to draw inferences from the explicit information in the provenance knowledge base. We enforce policy constraints at the design phase, as well as at runtime.
Provenance is metadata that captures the origin of a data source; the history or ownership of a valued object or a work of art or literature. It allows us to verify the quality of information in a data store to repeat manipulation steps and to discover dependences among data items in a data store. In addition, provenance can be used to determine the usefulness and trustworthiness of shared information. The utility of shared information relies on: (i) the quality of the source of information and (ii) the reliability and accuracy of the mechanisms (i.e., procedures and algorithms) used at each step of the modification (or transformation) of the underlying data items. Furthermore, provenance is a key component for the verification and correctness of a data item which is usually stored and then shared with information users.
Organizations and individual users rely on information sharing as a way of conducting their day-to-day activities. However, ease of information sharing comes with a risk of information misuse. An electronic patient record (EPR) is a log of all activities, including patient visits to a hospital, diagnoses and treatments for diseases, and processes performed by healthcare professionals on a patient. This EPR is often shared among several stakeholders (e.g., researchers, and insurance and pharmaceutical companies). Before this information can be made available to any third party, the sensitive information in an EPR must be circumvented or hidden before releasing any part of the EPR. This can be addressed by applying policies that completely or partially hide sensitive attributes within the information being shared. The protection of sensitive information is often required by regulations that are mandated by a company or by laws, such as Health Insurance Portability and Accountability Act (HIPAA) [ANNA03].
While the technologies that we have used are mainly semantic web technologies, we believe that the amount of data that has to be handled by the inference controller could be massive. This is because the data not only includes the data in the database, but also previously released data as well as real-world information. Therefore, traditional database management techniques will be inadequate for implementing the inference controllers. As an example, we designed and implemented inference controllers in the 1990s, and it took us almost two years for the implementation discussed in [THUR93] and [THUR95]. Furthermore, we could not store all of the released data as well as the real-world data. That is, we purged the data that was least recently used from the knowledge base. We re-implemented the inference controllers with semantic web technologies in the late 2000s and early 2010s, and it took us just a few months for these implementations. Furthermore, our knowledge base was quite large and stored much of the released data and the real-world data. However, for the inference controller to be truly effective, it needs to process massive amounts of data, and we believe that we need a cloud-based implementation with big data management technologies. Our initial implementation of a policy engine in the cloud, which is a form of the inference controller, was discussed in Chapter 25. We need to implement he complete inference controller in the cloud using big data technologies.
The organization of this chapter is as follows. Our system architecture will be discussed in Section 28.2. Some background on data provenance as well as semantic web technologies will be discussed in Section 28.3. Our system design with examples is presented in Section 28.4. Details regarding the implementation of the inference controller are provided in Section 28.5. Implementing the inference controller using big data management techniques is discussed in Section 28.6. Finally, this chapter is concluded in Section 28.7. Details of our inference controller are given in our prior book [THUR15].
28.2 Architecture for the Inference Controller
In this section, we present the design of an inference controller that employs inference strategies and techniques built around semantic web technologies. Our architecture takes a user’s input query and returns a response that has been pruned using a set of user-defined policies (i.e., constraints on the underlying data items and provenance). We assume that a user could interact with our system to obtain both traditional data and its associated provenance. However, since the emphasis of this chapter is on protecting the provenance of data items, we will mainly focus on the design of the inference controller with respect to provenance data and less on the protection of traditional data items. Note that our inference controller can complement policies used to protect traditional data items by adding an extra layer of protection for provenance data.
The architecture is built using a modular approach; therefore, it is very flexible in that most of the modules can be extended or replaced by another application module. A modular design also allows a policy designer to focus on designing policies and abstracts them from the management of user interaction tasks.
Provenance data has a logical graph structure; therefore, it can also be represented and stored in a graph data model, without being limited to any particular data format. Although our focus in this chapter is on building an inference controller over the graph representation of provenance, our inference controller could also be used to protect data within a traditional database. Also, the use of an RDF data model is not restrictive since other data formats are well served by an RDF data model. Furthermore, tools such as D2RQ [BIZE03] could be used to convert traditional relational data into RDF data, thus allowing users to view both types of data as RDF graphs.
In our design, we will assume that the available information is divided into two parts: the actual data and provenance. Both the data and provenance can be represented as RDF graphs. The reader should note that we do not make any assumptions about how the actual information is stored. A user may have stored data and provenance in two different triple stores or in the same store. In addition, a user’s application can submit a query for access to the data and its associated provenance or vice versa. Figure 28.1 presents the design of our proposed inference controller over provenance. We next present a description of the major modules in Figure 28.1.
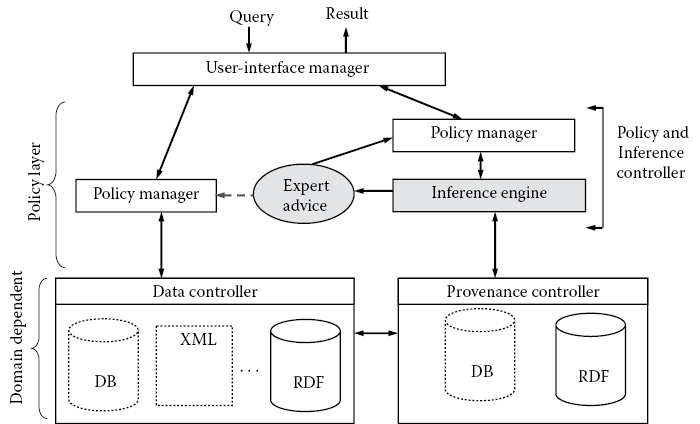
User-Interface Manager: A user-interface manager is responsible for processing a user’s requests, authenticating a user and providing suitable responses back to a user. The interface manager also provides an abstraction layer that allows a user to interact with the system. A user can therefore poses either a data query or a provenance query to this layer. The user-interface manager also determines whether the query should be evaluated against the data or its provenance.
The user interacts with the provenance inference controller via an interface layer. This layer accepts a user’s credentials and authenticates the user. The interface manager hides the actual internal representation of an inference controller from a user by providing a simple question–answer mechanism. This mechanism allows a user to pose standard provenance queries such as why a data item was created, where in the provenance graph it was generated, and how the data item was generated and when and where it was created. This layer also returns results after they are examined against a set of policies. Figure 28.2 shows a more detailed view of the interface manager that allows a user to interact with the underlying provenance store(s) via the inference controller. The interface manager’s role is to authenticate users, process input queries, and check for errors that may occur during query processing. In addition, it carries out other functions; for example, it performs some preprocessing operations before submitting a query to the inference controller layer.

Policy Manager: A policy manager is responsible for ensuring that the querying user is authorized to use the system. It evaluates policies against a user’s query and associated query results to ensure that no confidential information is released to unauthorized users. The policy manager may enforce policies against data or its associated provenance. Each data type may have its own policy manager, for example, data may be stored in a different format from provenance data. Hence, we may require separate implementations of the policy manager for data and provenance. Figure 28.3 shows the details of the policy manager. The policy manager interacts with the user via the query-processing module. Each query passed to the policy manager from the query-processing module is evaluated against a set of policies. As previously mentioned, these policies can be encoded as access control rules via any access control mechanism or other suitable policy languages ([CADE11a], [CADE11b]). They can be expressed as rules that operate directly over a directed graph or they can be encoded as description logic (DL) [LEVY98] constraints or using web rule languages, such as the Semantic Web Rule Language (SWRL) [HORR04]. The policy layer is responsible for enforcing any high-level policy defined by an application user or administrator. The policies are not restricted to any particular security policy definition, model, or mechanism. In fact, we can support different policies, for example, role-based access control (RBAC), access control based on context, such as time (TRBAC) and location (LBAC). The policy manager also handles RBAC policies specified in OWL and SWRL [CADE10a]. In addition, it handles certain policies specified in OWL for inference control such as association-based policies. Besides the traditional and well-established security models built on top of access control mechanisms, the inference controller also supports redaction policies. Redaction policies are based on sharing data for ongoing mutual relationships among businesses and stakeholders. Redaction policies are useful when the results of a query are further sanitized. For example, the literal value of an assertion by an RDF triple in a result graph may contain the nine-digit social security number of employees, as 999-99-9999, but for regulatory purposes, the four-digit format 9999 is the correct format for disclosure. The redaction policies can also be used to redact (block out or hide) any node in an RDF triple (i.e., block out a literal value, hide a resource, etc.).

Finally, the policy layer interacts with various reasoners in the inference layer, which offer further protection against inference attacks. The inference layer enforces policies that are in the form of DL constraints [ZHAN09], OWL restrictions [MCGU04a], or SWRL rules. Note that some of the access control policies can be expressed as inference rules (for more expressive power) or as queries via query rewriting ([OULM10a, OULM10b]), or in the form of view definitions [RIZV04]. The policy manager therefore has many layers equipped with security features, thus ensuring that we offer the maximal protection over the underlying provenance store.
The Query-Processing Module: It is responsible for accepting a user’s query from the user interface, parsing it, and submitting it to the policy manager. In addition, the module also evaluates results against the user-defined set of policies and rules, after which the results are returned to the user via the user-interface layer. The query-processing module can accept any standard provenance query, as well as any query written using SPARQL [PRUD06]. The query-processing module also provides feedback to the user via the user interface. This feedback includes errors due to query syntax in addition to the responses constructed by the underlining processes of the policy and inference controller layers.
Inference Engine: The inference engine is the heart of the inference controller. The engine is equipped to use a variety of inference strategies, each requiring a reasoner. Since there are many implementations of reasoners available, our inference controller offers an added feature of flexibility, whereby we can select a reasoner from amongst a variety of OWL-compliant reasoning tools based on different reasoning tasks or domains. For example, decisions in a medical domain may require all the facts in a triple store or only the facts related to a particular EPR in the triple store. Therefore, one can limit a task involving inferences to the local information (available in the EPR and the related provenance).
A modular approach [CADE10b] can improve the efficiency of the inference controller. The approach given in [CADE10b] allows each inference process to be executed on a separate processor; therefore, we can take advantage of designs based on partitioning and parallelism. For example, the code implementing a strategy based on heuristic reasoning [THUR90] could be executed in parallel with the code that implements a strategy based on inference by semantic association [THUR93]. Furthermore, an inference engine typically uses software programs that have the capability of reasoning over a relevant subset of facts that are in some data representation of a domain, for example, a relational data model or an RDF graph representation.
Data Controller: The data controller is a suite of software programs that stores and manages access to data. The data could be stored in any format such as in a relational database, in XML files or in an RDF store. The controller accepts requests for information from the policy layer if a policy allows the requesting user to access the data items in the data stores (e.g., the triple stores). This layer then executes the request over the stored data and returns the results back to the policy layer where they are re-evaluated before being returned to the user-interface layer.
Provenance Controller: The provenance controller is used to store and manage provenance information that is associated with data items that are present in the data controller. In the case when we represent provenance as an RDF graph, the provenance controller stores information in the form of a logical graph structure in any appropriate data representation format (e.g., RDF serialization format). The provenance controller also records the ongoing activities associated with the data items stored in the data controller. The provenance controller takes as input a graph query and evaluates it over the provenance data. The provenance controller then returns a resultant RDF graph back to the policy layer where it is re-examined using a set of policies before returning it to the querying user. A re-examination of the resulting RDF graph allows the policy designer to transform the result graph further by applying other graph transformation techniques (e.g., redaction, sanitization, etc.) that can alter triples in the resulting RDF graph. Note that the original provenance graphs are not altered during the transformation; instead, copies of the original graph (created by queries) undergo transformations. This protects the integrity of the provenance data; the effect of modifying the provenance changes the provenance.
Policy Managers: An application user may wish to write policies at a high level using domain-specific business rules. Thus, an application user can continue using his/her business policies independent of our software implementation of the provenance inference controller. A suitable policy parser module could handle the parsing of high-level policies and their transformation into low-level policy objects used by the system. Therefore, modifying or extending a policy manager module is facilitated since it is not hard-wired to any implementation of other modules in the architecture.
Inference Tools: Newly published data, when combined with existing public knowledge, allows for complex and sometimes unintended inferences. Therefore, we need semi-automated tools for detecting these inferences prior to releasing provenance information. These tools should give data owners a fuller understanding of the implications of releasing the provenance information, as well as helping them adjust the amount of information they release in order to avoid unwanted inferences.
The inference controller is a tool that implements some of the inference strategies that a user could use to infer confidential information that is encoded into a provenance graph. Our inference controller leverages existing software tools that perform inferencing, for example, Pellet [SIRI07], Fact++ [TSAR06], Racer [HAAR01], Hermit [SHEA08], CWM [BERN00], and third party plugins [CARR04]. A modular design also takes advantage of theories related to a modular knowledge base in order to facilitate collaborative ontology construction, use, and reuse ([BAO06], [FARK02], [BAO04]). In addition, there exists a trade-off between expressivity and decidability; therefore, a policy designer or an administrator should have flexibility when selecting an appropriate reasoner software for a particular application. In addition to the reasoner, the policy designer should take into consideration the expressiveness of the representational language for the concepts in an application domain. For example, one may prefer urgency in a medical or intelligence domain when making appropriate decisions and therefore decide on an optimized reasoner for a representational language (e.g., RDF, RDFS, OWL-DL).
28.3 Semantic Web Technologies and Provenance
28.3.1 Semantic Web-Based Models
Provenance data can be stored in the relational data model, the XML data model, or the RDF data model. Each of these in their current form has drawbacks with respect to provenance [HOLL08]. The directed nature of a provenance graph presents major challenges. A relational model suffers from the fact that it needs expensive joins on relations (tables) for storing edges or paths. In addition, current SQL languages that support transitive queries are complex and awkward to write. XML supports path queries, but the current query languages such as XQuery and XPath only support a tree structure. RDF naturally supports a graph structure, but the current W3C recommendation for SPARQL (the standard query language for RDF) lacks many features needed for path queries. There are recent works on extending SPARQL with path expressions and variables. These include SPARQL Query 1.1 [HARR10], which is now a W3C recommendation. Of these three data models, we represent provenance using an RDF data model. This data model meets the specification of the open provenance model (OPM) recommendation [MORE11]. In addition, RDF allows the integration of multiple databases describing the different pieces of the lineage of a resource (or data item) and naturally supports the directed structure of provenance. This data model has also been successfully applied for provenance capture and representation ([DING05, ZHAO08]). In addition to RDF, [KLYN04], RDF Schema (RDFS) can be used for the reasoning capabilities.
Other representation schemes are the OWL [MCGU04a,b] and the SWRL [HORR04]. OWL is an ontology language that has more expressive power and reasoning capabilities than RDF and RDFS. It has an additional vocabulary along with a formal semantics. The formal semantics in OWL are based on DLs, which are a decidable fragment of first-order logics. OWL consists of a Tbox that comprises the vocabulary that defines the concepts in a domain, and an Abox that is made up of assertions (facts about the domain). The Tbox and Abox make up an OWL knowledge base. The SWRL extends the set of OWL axioms to include Horn-like rules, and it extends these rules to be combined with an OWL knowledge base. Using these languages allows us to later perform inference over the provenance graph. Therefore, we could determine the implicit information in the provenance graph.
28.3.2 Graphical Models and Rewriting
Graphs are a very natural representation of data in many application domains, for example, precedence networks, path hierarchy, family tree, and concept hierarchy. In addition, directed graphs are a natural representation of provenance ([BRAU08, MORE11, MORE10, ZHAO10]). We begin by giving a general definition of a labeled graph, and then we introduce a specific labeled graph representation for provenance. This specific representation is referred to as RDF, which will serve to represent and store a provenance graph. Note that an RDF graph is a set of triples, which may have one or more machine-processable formats, such as RDF/XML, TURTLE, and NTRIPLE.
The OPM [MORE11] is an abstract vocabulary that describes provenance as a set of objects that is represented by a causality graph that is a directed acyclic graph. This graph is enriched with annotations that capture information about an execution. The objects are nodes and their relationships are arcs. The provenance model of causality is timeless since time precedence does not imply causality. We define the nodes in the provenance graph using the nomenclature in [MORE11].
A graph-rewriting system is well suited for performing transformations over a graph. Furthermore, provenance is well represented in a graphical format. Thus, a graph-rewriting system is well suited for specifying policy transformations over provenance. Graph rewriting is a transformation technique that takes as input an original graph and replaces a part of that graph with another graph. This technique, also called graph transformation, creates a new graph from the original graph by using a set of production rules. Popular graph-rewriting approaches include the single-pushout approach and the double-pushout approach ([ROZE97, CORR97]).
A graph-rewriting system should be capable of specifying under what conditions a graph-manipulation operation is valid. The embedding instructions normally contain a fair amount of information and are usually very flexible; however, allowing the policy designer to specify the embeddings may become error-prone. The OPM nomenclature places a restriction on the set of admissible RDF graphs, which we call valid OPM graphs. These restrictions serve to control a graph-transformation process (also a graph-rewriting process) by ruling out transformations that lead to nonadmissible graphs.
28.4 Inference Control through Query Modification
An inference controller offers a mechanism that (1) protects confidential information, (2) mimics a user’s strategy for inferring confidential information, and (3) performs inference over the provenance graph data. Data provenance in general contains both sensitive and public information. We need to disclose provenance information in order to ensure that the user gets high-quality information. Provenance data has a unique characteristic that makes it different from traditional data [BRAU08]. This characteristic is the directed acyclic graph (DAG) structure of provenance that captures single-data items and the causal relationships between them. Additionally, the DAG structure complicates any efforts to successfully build an inference controller over provenance data and surprisingly this area has been unexplored by the research community. Although the research community has applied inference over provenance data, in particular, the inference web that has used provenance to provide proofs as justifications for data items [MCGU04b], it has not considered inferencing from the point of view of provenance security.
Provenance and RDF define different domain spaces from traditional database problems. Provenance is mainly used for justification and proofs, verification and detection, gauging the trustworthiness of data items, for auditing and maintaining the history of a workflow process, establishing high integrity and quality data, and the reliability of information sources. RDF is mainly used for the knowledge representation of a domain, to formulate a problem with a graph representation, to name things with URIs and assert relationships between them, to link data in an open environment for information discovery, to support interoperability among data sources, and to add semantics to data and support reasoning. Traditional databases, on the other hand, are best suited for problems with fixed schemas. RDF technologies have been used to build inference engines that support inferences [CARR05] and also to represent and store provenance information ([CARR05], [DING05], [ZHAO08]). In addition, OWL has been used to model different domains with private information [FINI08], and DLs have been applied to the privacy problem [STOU09]. Our goal is to combine some of these efforts in order to build an inference controller over provenance. Therefore, provenance will be represented as RDF graphs, and DLs will be used to support the inference tasks of our inference controller.
Traditionally, we protect data using various policies. These include access control policies that specify what can be accessed, sanitization and anonymization policies that specify how to share released information, and randomization and encryption techniques that can be used to scramble the data in transmission. These techniques alone do not prevent the inference problem. Therefore, our inference controller will serve as a key security tool on top of the existing ones, thereby complementing the existing techniques in order to protect provenance data.
Different approaches have been used to apply access control policies to provenance ([NI09], [CADE11a], [SYAL09], [ROSE09]). For example, an approach that annotates OPM entities with access control attributes is given in [ROSE09]. Another approach that defines policies for artifacts, processes, and path dependences is given in [CADE11c]. Our approach takes into consideration the structure of provenance and instead represents it as RDF data in order to leverage existing SWRLs that have been used to encode extremely complicated access control policies ([ZHAN09], [FINI08], [LI05], [SHIE06]). Furthermore, our approach encodes some of the simpler access control policies as SPARQL queries (by the use of a rewrite procedure); we use DL to compactly write the rules formally to avoid ambiguity, and we also use SWRL to write rules that are very expressive. Note that there is a trade-off between expressiveness and decidability (e.g., SWRL [HORR05] vs. OWL-DL [MCGU04a,b]).
Protecting provenance by applying access control policies alone, however, ignores the utility of the provenance given to the querying user. Therefore, an important feature of our inference controller is to build mechanisms for associating a high utility with the query responses while ensuring that policies are not compromised. We rely on a formal graph-transformation approach for visualizing the provenance after a policy is enforced (see Definition 6). At each transformation step, the policy that preserves the highest utility is applied. We continue to apply policies at different transformation steps until all policies are enforced. Throughout this chapter, we refer to the policies that utilize a graph-transformation approach as redaction policies (see [CADE11b] for further details). This graph transformation technique can also be used to modify the triple patterns in an SPARQL query; this is called query rewriting. As previously mentioned, the inference controller will therefore use a combination of policies. When appropriate, we will: protect data by using access control policies to limit access to the provenance data; use redaction policies to share the provenance information; and also use the graph-transformation technique for sanitizing the initial query results.
Inferences may be obtained during two stages:
1.Data collection: This includes data in the data stores that is accessible to users and real-world knowledge (which is not represented in the data stores) about an application domain.
2.Reasoning with the collected data: This is the act of deriving new information from the collected data.
The data collection and the reasoning stages are performed repeatedly by the adversary (i.e., by a human user or an autonomous agent) until the intended inference is achieved or the adversary gives up. Each query attempts to retrieve data from the internal data stores, but the adversary may also collect data from external data stores as part of the background-knowledge-acquisition process. The data that adversaries want to infer may include the existence of a certain entity in the data stores (i.e., the knowledge base of the facts about a domain) or the associations among data (i.e., the relationships among the facts).
In some cases, instead of inferring the exact data (facts) in a knowledge base (precise inference), users may be content with a set of possible data values (imprecise inference or approximate inference). For instance, assume that a user wants to infer the disease of a patient from the patient’s record, which is a part of the provenance graph. Further, assume that the provenance captures the record’s history that records that a heart surgeon performed an operation on the patient. Revealing the fact that a heart surgeon is part of the provenance could enable the user to infer that the patient has some disease related to heart problems but not necessarily the exact nature of the surgery or the exact disease of the patient.
28.4.3 Inference Controller with Two Users
An approach to tackling the inference problem is to explicitly represent all information available to a user, and mimic the reasoning strategies of that user. A query log has a context ([BAI07], [SHEN05]) and therefore could be used to identify the activities of the user. In addition, a designated database could be used to record all information released to the user so far. This could help in identifying some background profile of the user, as well as to know what the user already knows [CADE10a]. However, there are major challenges to this approach. An example challenge is related to the storage used to track the released information. Another challenge is the duplication of facts (the facts in the released database are copies of facts in the original knowledge base). Instead of materializing the query results and storing them, another approach is to re-evaluate the queries from the query logs at query execution time, but this could impact the performance of the data manager. The query logs contain pieces of information that can be revealing and can therefore reveal queries targeting private information in the provenance stores. Queries for phone numbers, addresses, and names of individuals are all useful in narrowing down the target space for individuals, and thus increase the chance of a successful attack. In addition, the query logs show the distribution of queries for a user as well as the query sequencing; the query logs also aid the reconstructing of results for previous queries. Finally, it is possible to cluster users based on query behaviors. More significantly, there also exist correlations among queries (e.g., those who query for X also query for Y).
The inference controller comprises a knowledge base for storing provenance. This is represented by a set of RDF triples. The provenance is encoded using a provenance vocabulary. The user submits queries; each query is first examined to determine if it is a valid query before submitting it to the inference layer. The query is then submitted and executed over the knowledge base. We model this as two machines (or automated tools): the user (e.g., an automated agent) and the controller.
We assume that the user builds a machine, M′, that contains the history of all the answers given to the user, the modified background knowledge with relevant domain information and a prior set of rules about the system. Further, the user can infer a subset of the private information using M′. Likewise, we build a machine M″ that simulates the inferencing mechanism of the user, but with certain modifications to compensate for any differences. This machine, M″, combines the history of all previous answers, the current query and associated provenance and the rules that enforce the security policies. We use M″ to determine certain inferences occurring in M′. The major difference between M′ and M″ is the user’s background information. M′ and M″ contain different sets of rules and M″ keeps a repository of a user’s input queries. This repository (or query log) is a rich source of information about the context of the user. For example, if the logged queries could compromise the knowledge base, the user is flagged as an attacker.
The inferencing capabilities of M″ are best realized by a language with formal semantics. The Resource Description Framework (RDF), RDFS and the Web Ontology Language (OWL) are knowledge representation languages that fit this criterion; these languages all use the RDF data model. RDF data model is also a natural fit for a directed graph such as provenance. Also, to realize policy rules using SWRL and DLs, the provenance is stored in an OWL knowledge base.
The queries are written in the SPARQL language. These queries are extended with regular expressions in order to select graph patterns for both the user’s query and the protected resources. In order to write the policy constraints (as rules), we use a mixture of queries, DL rules and SWRL. These constraints (rules) specify the concepts, triples and facts that are to be protected. The concepts are the definitions (or descriptions) of resources in a provenance graph; these are normally written formally to avoid ambiguity in policy specification languages such as DLs. Each DL concept can also be successfully defined by an SPARQL query or an SWRL rule. In some cases, the constraints may require more expressive languages for defining the concept and so we sometimes choose SWRL rules over DL rules.
28.4.4 SPARQL Query Modification
RDF is being increasingly used to store information as assertions about a domain. This includes both confidential and public information. SPARQL has been selected as a query language that extracts data from RDF graphs. Since confidential data is accessed during the querying process, we need to filter the results of SPARQL queries so that only authorized information is released with respect to some confidentiality policy. Our aim is to rewrite the SPARQL queries so that the results returned are compliant with the confidentiality policies.
Existing work has been done in the area of data management, data warehousing and query optimization that apply query modification techniques ([RIZV04], [LEVY95], [BEER97]). These traditional approaches use rewrite procedures to modify the original query for purposes of query optimization, query pruning or fulfilling policy requirements. Other works [ORAC], [OULM10a], [OULM10b], [LE11], [HOLL10], and [CORR10] describe query modification techniques based on SPARQL queries over RDF data. Our focus will be on applying similar query modification techniques to the input SPARQL queries.
We design security mechanisms that control the evaluation of SPARQL queries in order to prevent the disclosure of confidential provenance information. Our approach is to modify the graph patterns in the SPARQL query by adding filters and/or property functions that are evaluated over the provenance data. These approaches may return answers different from the user’s initial query intent. It may be necessary to decide on appropriate actions in these cases. We identify two approaches that may be followed. The first approach checks the query validity against that of the initial query and notifies the user that the query validity is not guaranteed. The second approach takes into consideration that a feedback about the validity of a query result may lead the user to draw undesirable inferences.
In some cases, it may be possible to return only the answers that comply with the policy constraints. One approach is to replace a set of triples satisfying a query with another set of triples by applying transformation rules over the first set of triples. Another approach may be to lie about the contents in the knowledge base. Yet another approach is to use polyinstantiation similar to that in multilevel secure databases, where users at different clearance levels see different versions of reality [STAC90].
Approaches for modifying the graph patterns in an SPARQL query make use of different techniques, for example, SPARQL filters and property functions, graph transformations and match/apply pattern. In order to determine the type of triple with respect to a security classification, the inference engine would use a domain ontology to determine the concept each data item belongs to as well as a query modification based on an SPARQL BGP transformation.
There is a difference between a query engine that simply queries an RDF graph but does not handle rules and an inference engine that also handles rules. In the literature, this difference is not always clear. The complexity of an inference engine is a lot higher than a query engine. The reason is that rules permit us to make sequential deductions. In the execution of a query, these deductions are to be constructed. This is not necessary in the case of a query engine. Note that there are other examples of query engines that rely on a formal model for directed labeled graphs such as DQL [FIKE02] and RQL [KARV12].
Rules also support a logic base that is inherently more complex than the logic in the situation without rules. For an RDF query engine, only the simple principles of entailment on graphs are necessary. RuleML is an important effort to define rules that are usable for the World Wide Web. The inference web [MCGU04a,b] is a recent realization that defines a system for handling different inference engines on the semantic web.
28.5 Implementing the Inference Controller
We now present the design of an inference controller for provenance. The inference controller is implemented using a modular approach; therefore, it is very flexible in that most of the modules can be extended by a domain user. For example, an application user may substitute the policy parser module that handles the parsing of high-level policies into low-level policy objects with a custom-built parser. Internally, the rules associated with a policy could be converted to SPARQL queries so that they are evaluated over an RDF graph. Therefore, the application user can continue using his/her high-level business policies independent of our software implementation.
We describe the phases through which the knowledge base is populated with domain data and provenance. The first phase is the selection of a domain. This is followed by data collection and data representation of the concepts and relationships among the concepts in the domain. Once the domain data is represented in a suitable machine readable format (i.e., RDF, OWL), the next phase is to generate provenance workflow data, which is also recorded using a provenance vocabulary. The policies are internally written as suitable semantic web rules (e.g., SWRL, DL, and/or SPARQL). Once the policies are in place, a user can interact with the system by posing SPARQL queries which are then evaluated over the knowledge base.
28.5.2 Implementation of a Medical Domain
We describe a medical domain with respect to online sources (for example, WebMD, which is available at http://www.webmd.com/). The medical domain is made up of patients, physicians, nurses, technicians, equipments, medical procedures, etc. Note that we use a fictitious hospital, which complies with real procedures described at online sources (e.g., http://www.nlm.nih.gov/ and http://www.mghp.com/services/procedure/). These procedures include heart surgery, the hip replacement procedure, etc. Since the procedures are described by actual documents on the Web, the generated workflow structures encode a set of guidelines that are also known to the users of the system. However, most real-world hospitals follow guidelines related to a patient’s privacy, so our fictitious hospital generates provenance workflows whose contents correspond to the confidential data found in patients’ records. Therefore, the record (i.e., an artifact), the agent who generated a version of a record, the time when the record was updated and the processes that contributed to the changes of the record are part of the provenance. Furthermore, the laws governing the release of provenance (i.e., the contents of the generated workflow) are enforced by constraints which are implemented as semantic web rules in our prototype system. The use of a fictitious hospital here reflects the fact that real data and provenance from real hospitals are difficult to obtain and are usually not released in their original form, since they are protected by domain and regulatory laws.
28.5.3 Generating and Populating the Knowledge Base
A set of seeds, each consisting of a first name, a last name, a state and city, were used to create queries which are issued against the yellowpages and the whitepages web sites. The pages matching an initial query are crawled, and the results are converted and stored in an appropriate format for later use. The crawl routines were executed off-line in a predefined sequence. The first crawl gathers a list of patients. With the zip codes of the patients, we formulate web queries to further search for hospitals, doctors and their specialties. The results of these queries are also stored in a predetermined format. A set of generators are responsible for extracting background information which is normally available online. A provenance workflow generator also produces the provenance. Note that this workflow generator produces synthetic provenance data that is not available online.
We use real information on current web pages so that we can demonstrate the effectiveness of the inference controller with respect to the prior knowledge of the querying agent. Parameters such as city, state and zip in the USA were initialized and sent to freely available web sites, such as the yellow pages (http://www.yellowpages.com/) and white pages (http://www.whitepages.com/). These websites were crawled and important attributes such as the name, address, telephone numbers, age, sex, relatives of various individuals were extracted. These attributes make up the patients in our knowledge base.
We selected a list of hospitals which were located in the zip codes of the patients. Each hospital has a name, address, and telephone number. Because many hospitals do not release the names of their staff, additional searches for doctors and their specialties were carried out; these searches were also limited to the zip codes of the hospitals. Note that it is normal to assume most specialists are affiliated with a particular hospital close to their location of practice. Some insurance companies do provide a list of the doctors and their affiliations on their websites, but many of these websites require a login id or a different verification code each time it is accessed (i.e., preventing automated crawls). Due to these obstacles, the knowledge base reflects a less accurate picture of the personnel of an actual hospital. The procedures that populate the domain knowledge are independent of the user-interface and policy/inference layers of the architecture. Furthermore, the data manager is not integrated with any procedure for loading the domain data into the data stores. Therefore, application users will have the freedom to populate the knowledge base with their own domain data using their own procedures.
The choice of real-web data vs. pure synthetic data makes the inference controller more realistic. A querying user can combine the responses from the system with actual accessible background information (from the publicly available websites given previously) to draw inferences about the information in a knowledge base.
28.5.4 Background Generator Module
Figure 28.4 is a diagram of the different background generators. Each generator is built to target specific websites (or web pages) which contain some information of interest. For example, http://www.ratemd.com provides structured information about doctors at a specified zip code. The patient generator extracts the attributes of a person from a set of web pages. A provenance workflow generator updates the record for a patient. The recorded provenance is not publicly available and therefore can be treated as confidential data in the system. The intent here is to give the querying user an opportunity to guess the information in a patient’s record and the associations between each electronic version of a patient’s record. This information includes the patient’s disease, medications, procedures or tests, physicians, etc. Provenance data is more challenging than the traditional data in a database (or the multilevel databases described in [THUR93], [STAC90], and [CHEN05] because the inference controller not only anticipates inferences involving the users prior knowledge, but also the inferences associated with the causal relationships among the provenance entities.

28.6 Big Data Management and Inference Control
It should be noted that the RDF-based policy engine that we discussed in Chapter 25 has essentially adapted the inference controller discussed in this chapter to a cloud environment. That is, we have used the policy engine which is essentially our inference controller to determine whether access should be allowed to the data. Based on this access control decision, information is then shared between the organization that would also depend on the information sharing policies. That is, before the information is shared, the policy engine will determine whether the information sharing policy would permit the sharing of the information and then whether the receiver is authorized to access the data to be shared.
We note that by re-implementing the policy engine in the cloud we were able to achieve a significant improvement in performance. Massive amounts of provenance data are generated due to the inferencing capabilities, therefore our initial implementation the inference controller had to be implemented in the cloud to achieve scalability. In addition, some of the technologies such as the Lucene index manager also supported scalability.
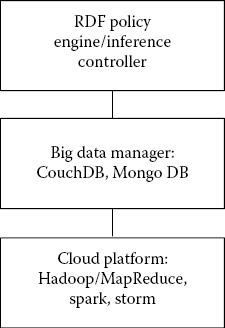
However, as stated in Section 28.1, we believe that the knowledge base managed by the inference controller could become massive over time due to not just the raw data, but also the derived data, released data, and the real-world knowledge. Therefore, we believe that several of the big data technologies discussed in Chapter 7 including the Hadoop/MapReduce framework, the Apache Storm and Spark frameworks are needed to provide the infrastructure to handle the massive data generated by the inference controller. In addition, several of the big data management systems such as the NoSQL databases (e.g., HBase and CouchDB) need to be utilized to design a big data management system that can not only manage massive amounts of data but also be able to carry out inferencing and prevent unauthorized violations due to inference. Figure 28.5 illustrates our approach to Big Data Management and Inference Control.
This chapter has described the first of a kind inference controller that will control certain unauthorized inferences in a data management system. Our approach is powerful due to the fact that we have applied semantic web technologies for both policy representation and reasoning. Furthermore, we have described inference control for provenance data represented as RDF graphs. Our approach can be applied for any kind of data represented in a graphical structure. We have also argued that inference control is an area that will need the use of BDMA systems for managing the data as well as reasoning about the data.
Our current work involves extending the inference controller to include more sophisticated types of policies, such as information sharing policies, and implementing our policy engine on the cloud [CADE12]. We are also using big data management techniques to manage the massive amounts of data that has to be managed by the inference controller. Essentially, our cloud-based inference controller will process powerful policies applied to large quantities of data. This will enable multiple organizations to share data without violating confidentiality and privacy and at the same time ensure that unauthorized inferences are controlled.
[ANNA03]. G. J. Annas, “HIPAA Regulations—A New Era of Medical-Record Privacy?,” The New England Journal of Medicine, 348 (15), 1486–1490, 2003.
[BAI07]. J. Bai, J. Y. Nie, G. Cao, H. Bouchard, “Using Query Contexts in Information Retrieval,” In SIGIR’07: Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, July 23–27, Amsterdam, The Netherlands, pp. 15–22, 2007.
[BAO04]. J. Bao and V. G. Honavar, “Ontology Language Extensions to Support Localized Semantics, Modular Reasoning, and Collaborative Ontology Design and Ontology Reuse.” Technical Report, Computer Science, Iowa State University 2004.
[BAO06]. J. Bao, D. Caragea, V. G. Honavar, “Modular Ontologies—A Formal Investigation of Semantics and Expressivity,” In ASWC 2006: Proceedings of the 1st Semantic Web Conference, September 3–7, Beijing, China, pp. 616–631, 2006.
[BEER97]. C. Beeri, A. Y. Levy, M. C. Rousset, “Rewriting Queries Using Views in Description Logics,” In PODS’97: Proceedings of the 16th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, May 11–15, Tucson, AZ, USA, pp. 99–108, 1997.
[BERN00]. T. Berners-Lee and others. CWM: A General Purpose Data Processor for the Semantic Web, 2000, http://www.w3.org/2000/10/swap/doc/cwm.html.
[BIZE03]. C. Bizer, “D2R MAP—A Database to RDF Mapping Language,” WWW (Posters), May 20–24, 2003, Budapest, Hungary, 2003.
[BRAU08]. U. Braun, A. Shinnar, M. Seltzer, “Securing Provenance,” In Proceedings of the 3rd Conference on Hot Topics in Security, USENIX Association, 2008.
[CADE10a]. T. Cadenhead, M. Kantarcioglu, B. Thuraisingham, “Scalable and Efficient Reasoning for Enforcing Role-Based Access Control,” In DBSec’10: Proceedings of the 24th Annual IFIP WG 11.3 Working Conference on Data and Applications Security and Privacy, June 21–23, Rome, Italy, pp. 209–224, 2010.
[CADE10b]. T. Cadenhead, M. Kantarcioglu, B. Thuraisingham, “An Evaluation of Privacy, Risks and Utility with Provenance,” In SKM’10: Secure Knowledge Management Workshop, New Brunswick, NJ, 2010.
[CADE11a]. T. Cadenhead, V. Khadilkar, M. Kantarcioglu, B. Thuraisingham, “A Language for Provenance Access Control” In CODASPY’11: Proceedings of the 1st ACM Conference on Data and Application Security and Privacy, February 21–23, San Antonio, TX, USA, pp. 133–144, 2011.
[CADE11b]. T. Cadenhead, V. Khadilkar, M. Kantarcioglu, B. Thuraisingham, “Transforming Provenance Using Redaction,” In SACMAT’11: Proceedings of the 16th ACM Symposium on Access Control Models and Technologies, June 15–17, Innsbruck, Austria, pp. 93–102, 2011.
[CADE11c]. T. Cadenhead, M. Kantarcioglu, B. Thuraisingham, “A Framework for Policies over Provenance,” In TaPP’11: 3rd USENIX Workshop on the Theory and Practice of Provenance, Heraklio, Crete, Greece, 2011.
[CADE12]. T. Cadenhead, V. Khadilkar, M. Kantarcioglu, B. Thuraisingham, “A Cloud-Based RDF Policy Engine for Assured Information Sharing,” In SACMAT’12: Proceedings of the 17th ACM Symposium on Access Control Models and Technologies, June 20–22, Newark, NJ, USA, pp. 113–116, 2012.
[CARR04]. J. J. Carroll, I. Dickinson, C. Dollin, D. Reynolds, A. Seaborne, K. Wilkinson, “Jena: Implementing the Semantic Web Recommendations,” In ACM WWW 2004, New York, NY, pp. 74–83, 2004.
[CARR05]. J. J. Carroll, C. Bizer, P. Hayes, P. Stickler, “Named Graphs, Provenance and Trust,” In ACM WWW, Chiba, Japan, pp. 613–622, 2005.
[CHEN05]. X. Chen and R. Wei, “A Dynamic Method for Handling the Inference Problem in Multilevel Secure Databases,” In IEEE ITCC 2005, Vol. II, Las Vegas, NV, pp. 751–756, 2005.
[CORR97]. A. Corradini, U. Montanari, F. Rossi, H. Ehrig, R. Heckel, M. Löwe, “Algebraic Approaches to Graph Transformation, Part I: Basic Concepts and Double Pushout Approach,” Handbook of Graph Grammars and Computing by Graph Transformation, 1, 163–245, 1997.
[CORR10]. G. Correndo, M. Salvadores, I. Millard, H. Glaser, N. Shadbolt, “SPARQL Query Rewriting for Implementing Data Integration Over Linked Data,” In ACM EDBT, Article #4, Lausanne, Switzerland, 2010.
[DING05]. L. Ding, T. Finin, Y. Peng, P. P. Da Silva, D. L. McGuinness, “Tracking RDF Graph Provenance Using RDF Molecules,” Technical Report, 2005. http://ebiquity.umbc.edu/paper/html/id/263/Tracking-RDF-Graph-Provenance-using-RDF-Molecules.
[FARK02]. C. Farkas and S. Jajodia, “The Inference Problem: A Survey,” ACM SIGKDD Explorations Newsletter, 4 (2), 6–11, 2002.
[FIKE02]. R. Fikes, P. Hayes, I. Horrocks, “DQL—A Query Language for the Semantic Web,” Knowledge Systems Laboratory, 2002.
[FINI08]. T. Finin, A. Joshi, L. Kagal, J. Niu, R. Sandhu, W. Winsborough, B. Thuraisingham, “ROWLBAC: Representing Role Based Access Control in OWL,” In ACM SACMAT 2008, Estes Park, CO, pp. 73–82, 2008.
[HAAR01]. V. Haarslev and R. Möller, “RACER System Description,” IJCAR 2001: Automated Reasoning, Seattle, WA, pp. 701–705, 2001.
[HARR10]. S. Harris and A. Seaborne, “SPARQL 1.1 Query Language,” W3C Working Draft, 14, 2010.
[HOLL08]. D. A. Holland, U. Braun, D. Maclean, K. K. Muniswamy-Reddy, M. Seltzer, “Choosing a Data Model and Query Language for Provenance,” In Provenance and Annotation of Data and Processes: Proceedings of the 2nd International Provenance and Annotation Workshop (IPAW ‘08), June 17–18, 2008, Salt Lake City, UT, ed. Juliana Freire, David Koop, and Luc Moreau. Berlin: Springer. Special Issue. Lecture Notes in Computer Science 5272.
[HOLL10]. V. Hollink, T. Tsikrika, A. Vries, “De.The Semantics of Query Modification,” In Le Centre De Hautes Etudes Internationales D’informatique Documentaire, pp. 176–181, 2010.
[HORR04]. I. Horrocks, P. F. Patel-Schneider, H. Boley, S. Tabet, B. Grosof, M. Dean, “SWRL: A Semantic Web Rule Language Combining OWL and RuleML,” W3C Member Submission, 21, 2004. https://www.w3.org/Submission/SWRL/.
[HORR05]. I. Horrocks, P. F. Patel-Schneider, S. Bechhofer, D. Tsarkov, “OWL Rules: A Proposal and Prototype Implementation,” Web Semantics: Science, Services and Agents on the World Wide Web, 3 (1), 23–40, 2005.
[KARV12]. G. Karvounarakis, S. Alexaki, V. Christophides, D. Plexousakis, M. Scholl, RQL: A Declarative Query Language for RDF, In ACM WWW 2002, Honolulu, HI, pp. 592–603, 2002.
[KLYN04]. G. Klyne, J. J. Carroll, B. McBride, “Resource Description Framework (RDF): Concepts and Abstract Syntax,” In W3C Recommendation, February 10, 2004. https://www.w3.org/TR/2004/REC-rdf-concepts-20040210/.
[LE11]. W. Le, S. Duan, A. Kementsietsidis, F. Li, M. Wang, “Rewriting Queries on SPARQL Views,” In ACM, WWW 2011, Hyderabad, India, pp. 655–664, 2011.
[LEVY95]. A. Y. Levy, A. O. Mendelzon, Y. Sagiv, “Answering Queries Using Views,” In ACM PODS 1995, San Jose, CA, pp. 95–104, 1995.
[LEVY98]. A. Y. Levy and M. C. Rousset, Combining Horn Rules and Description Logics in CARIN, Elsevier, New York, pp. 165–209, 1998.
[LI05]. H. Li, X. Zhang, H. Wu, Y. Qu, “Design and Application of Rule Based Access Control Policies,” Semantic Web and Policy Workshop, Galway, Ireland, pp. 34–41, 2005.
[MCGU04a]. D. L. McGuinness, F. van Harmelen, and others. “OWL Web Ontology Language Overview,” W3C Recommendation, 10, 2004–3, 2004.
[MCGU04b]. D. L. McGuinness P. Pinheiro da Silva, “Explaining Answers from the Semantic Web: The Inference Web Approach,” Web Semantics: Science, Services and Agents on the World Wide Web, 397–413, 2004.
[MORE10]. L. Moreau, Open Provenance Model (OPM) OWL Specification. Latest version: http://openprovenance.org/model/opmo 2010.
[MORE11]. L. Moreau et al. “The Open Provenance Model Core Specification (v1. 1),” Future Generation Computer Systems, 27 (6), 743–756, 2011.
[NI09]. Q. Ni, S. Xu, E. Bertino, R. Sandhu, W. Han, “An Access Control Language for a General Provenance Model,” Secure Data Management, Proceedings of 6th VLDB Workshop, SDM 2009, Lyon, France, pp. 68–88, August 28, 2009.
[ORAC]. Oracle® Database Semantic Technologies Developer’s Guide 11 g Release 2 (11.2). Available at http://docs.oracle.com/cd/E14072_01/appdev.112/e11828/toc.htm.
[OULM10a]. S. Oulmakhzoune, N. Cuppens-Boulahia, F. Cuppens, S. Morucci, “fQuery: SPARQL Query Rewriting to Enforce Data Confidentiality,” Data and Applications Security and Privacy, XXIV, 146–161, 2010.
[OULM10b]. S. Oulmakhzoune, N. Cuppens-Boulahia, F. Cuppens, S. Morucci, “Rewriting of SPARQL/Update Queries for Securing Data Access,” ICICS’10 Proceedings of the 12th International Conference on Information and Communications Security, Barcelona, Spain, pp. 4–15, 2010.
[PRUD06]. E. Prud and A. Seaborne, Sparql query language for rdf, 2006.
[RIZV04]. S. Rizvi, A. Mendelzon, S. Sudarshan, P. Roy, “Extending Query Rewriting Techniques for Fine-Grained Access Control,” In ACM SIGMOD, Paris, France, pp. 551–562, 2004.
[ROSE09]. A. Rosenthal, L. Seligman, A. Chapman, B. Blaustein, “Scalable Access Controls for Lineage,” In USENIX TAPP’09 First workshop on Theory and Practice of Provenance, San Francisco, CA, Article No. 3, pp. 1–10, 2009.
[ROZE97]. G. Rozenberg and H. Ehrig, Handbook of Graph Grammars and Computing by Graph Transformation, World Scientific, River Edge, NJ, 1997.
[SHEA08]. R. Shearer, B. Motik, I. Horrocks, T. Hermi, “A Highly-Efficient OWL Reasoner,” In Proceedings of the 5th International Workshop on OWL: Experiences and Directions (OWLED 2008), pp. 26–27, 2008.
[SHEN05]. X. Shen, B. Tan, C. X. Zhai, “Context-Sensitive Information Retrieval Using Implicit Feedback,” In ACM SIGIR, Salvador, Brazil, pp. 43–50, 2005.
[SHIE06]. B. Shields, O. Molloy, G. Lyons, J. Duggan, “Using Semantic Rules to Determine Access Control for Web Services” In ACM WWW 2006, Edinburgh, Scotland, pp. 913–914, 2006.
[SIRI07]. E. Sirin, B. Parsia, B. C. Grau, A. Kalyanpur, Y. Katz, “Pellet: A Practical Owl-dl Reasoner,” Web Semantics: Science, Services and Agents on the World Wide Web, 5 (2), 51–53, 2007.
[STAC90]. P. D. Stachour and B. Thuraisingham, “Design of LDV: A Multilevel Secure Relational Database Management System,” Knowledge and Data Engineering, IEEE Transactions on, 2 (2), 190–209, 1990.
[STOU09]. P. Stouppa and T. Studer, “Data Privacy for ALC Knowledge Bases,” In Intl Symposium of the LFCS 2009, Deerfield Beach, FL, pp. 409–421, 2009.
[SYAL09]. A. Syalim, Y. Hori, K. Sakurai, “Grouping Provenance Information to Improve Efficiency of Access Control” Advances in Information Security and Assurance, Third Intl Conference and Workshops, ISA, Seoul, Korea, pp. 51–59, 2009.
[THUR90]. B. Thuraisingham, “Novel Approaches to Handle the Inference Problem” Proceedings of the 3rd RADC Database Security Workshop, New York, pp. 58–67, 1990.
[THUR93]. B. Thuraisingham, W. Ford, M. Collins, J. O’Keeffe, “Design and Implementation of a Database Inference Controller,” Data & Knowledge Engineering, 11(3), 271–297, 1993.
[THUR95]. B. Thuraisingham, W. Ford. “Security Constraints in a Multilevel Secure Distributed Database Management System.” IEEE Transactions on Knowledge and Data Engineering, 7 (2), 274–293, 1995.
[THUR15]. B. Thuraisingham, T. Cadenhead, M. Kantarcioglu, V. Khadilkar, Secure Data Provenance and Inference Control with Semantic Web. CRC Press, Boca Raton, FL, 2015.
[TSAR06]. D. Tsarkov and I. Horrocks, “FaCT++ Description Logic Reasoner: System Description,” International Joint Conference on Automated Reasoning, Seattle, WA, pp. 292–297, 2006
[ZHAN09]. R. Zhang, A. Artale, F. Giunchiglia, B. Crispo, “Using Description Logics in Relation Based Access Control,” In CEUR Workshop Proceedings, Grau, B. C., Horrocks, I., Motik, B., & Sattler, U. editors, 2009.
[ZHAO08]. J. Zhao, C. Goble, R. Stevens, D. Turi, “Mining Taverna’s Semantic Web of Provenance,” Concurrency and Computation: Practice and Experience, 20 (5), 463–472, 2008.
[ZHAO10]. J. Zhao, Open Provenance Model Vocabulary Specification. Latest version: http://open-biomed.sourceforge.net/opmv/ns.html 2010.