
While big data management and analytics (BDMA) is evolving into a field called data science with significant progress over the past 5 years with various courses being taught at universities, there is still a lot to be done. We find that many of the courses are more theoretical in nature and are not integrated with real-world applications. Furthermore, big data security and privacy (BDSP) is becoming a critical need and there is very little being done not only on research, but also on education programs and infrastructures for BDSP. For example, BDMA techniques on personal data could violate individual privacy. With the recent emergence of the quantified self (QS) movement, personal data collected by wearable devices and smartphone apps is being analyzed to guide users in improving their health or personal life habits. This data is also being shared with other service providers (e.g., retailers) using cloud-based services, offering potential benefits to users (e.g., information about health products). But such data collection and sharing are often being carried out without the users’ knowledge, bringing grave danger that the personal data may be used for improper purposes. Privacy violations could easily get out of control if data collectors could aggregate financial and health-related data with tweets, Facebook activity, and purchase patterns. While some of our research is focusing on privacy protection in QS applications and controlling access to the data, education and infrastructure programs in BDSP are yet to be developed.
To address the limitations of BDMA and BDSP experimental education and infrastructure programs, we are proposing to design such programs at The University of Texas at Dallas and the purpose of this chapter is to share our plans. Our main objectives are the following: (1) to train highly qualified students to become expert professionals in big data management and analytics and data science. That is, we will be developing a course on big data management and analytics integrated with real-world applications as a capstone course. (ii) Leverage our investments in BDSP research, BDMA research and education, and cyber security education to develop a laboratory to carry out hands-on exercises for relevant courses as well as a capstone course in BDSP, including extensive experimental student projects to support the education.
To address the objectives, we are assembling an interdisciplinary team with expertise in big data management and mining, machine learning, atmospheric science, geospatial data management, and data security and privacy to develop the programs. Essentially, our team consists of computer and information scientists who will develop the fundamental aspects of the courses together with application specialists (e.g., atmospheric scientists) who will develop the experimental aspects of the courses as well as provide the data for the students to carry out experiments on. Specifically, we will be utilizing the planned case study discussed in Chapter 32 to design our education and experimental programs.
This chapter is organized in the following way. In Section 34.2, we will discuss some of our relevant current research and infrastructure development activities in BDMA and BDSP. Our new programs will be being built utilizing these efforts. In Section 34.3, we describe our plan for designing a program in BDMA. In Section 34.4, we describe our plan for designing a program in BDSP. This chapter is summarized in Section 34.5. Figure 34.1 illustrates our plan for developing a curriculum on integrated data science and cyber security.
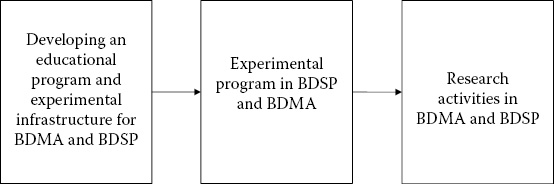
Figure 34.1 Developing an educational program and experimental infrastructure for big data management and analytics and big data security and privacy.
34.2 Current Research and Infrastructure Activities in BDMA and BDSP
Our experimental education program will focus mainly on developing a capacity surrounding our research on BDMA and BDSP. The topics include secure data provenance, cyber physical systems security, data analytics for insider threat detection, secure cloud, secure cyber-physical systems, and trusted execution environments (TEE). Our relevant research results will be transferred to the new infrastructures that we are designing to be discussed in this chapter. A discussion of some of our research and infrastructure activities is provided below.
34.2.1 Big Data Analytics for Insider Threat Detection
We have designed tools to determine insider threat over evolving stream activities. In particular, evidence of malicious insider activity is often buried within large data streams, such as system logs accumulated over months or years. Ensemble-based stream mining leverages multiple classification models to achieve highly accurate anomaly detection in such streams, even when the stream is unbounded, evolving, and unlabeled. This makes the approach effective for identifying insiders who attempt to conceal their activities by varying their behaviors over time. This project applies ensemble-based stream mining, supervised and unsupervised learning, and graph-based anomaly detection to the problem of insider threat detection. It demonstrates that the ensemble-based approach is significantly more effective than traditional single-model methods, supervised learning outperforms unsupervised learning, and increasing the cost of false negatives correlates to higher accuracy.
We are conducting research in collaboration with other universities on secure provenance data. In particular, we have developed a provenance management system for cyber infrastructure that includes different types of hosts, devices, and data management systems. The proof-of-concept system, referred to as Cyber-Provenance Infrastructure for Sensor-based Data-Intensive Research (CY-DIR), supports scientists throughout the lifecycle of their sensor-based data collection processes, including the continuous monitoring of sensors to ensure that provenance is collected and recorded, and the traceable use and processing of the data across different data management systems. CY-DIR provides researchers with provenance and metadata about data being collected by sensors. Provenance security will be assured by the use of efficient encryption techniques for use in sensors, secure logging techniques, and secure processors.
We have conducted research in designing and developing a cloud. In particular, the team designed a layered framework that includes the virtualization layer, the storage layer, the data layer, and the application layer. Research was carried out on encrypted data storage in the cloud as well as on secure cloud query processing. The secure cloud was demonstrated with assured information sharing as an application.
We are working on a number of efforts on binary code analysis. For example, the team is developing techniques for extracting address-independent data reference expressions for pointers through dynamic binary analysis. This novel pointer reference expression encodes how a pointer is accessed through the combination of a base address (usually a global variable) with certain offset and further pointer dereferences. The techniques have been applied to OS kernels, and the experimental results with a number of real-world kernel malware show that we can correctly identify the hijacked kernel function pointers by locating them using the extracted pointer reference expressions when only given a memory snapshot.
34.2.5 Cyber-Physical Systems Security
We are working on an effort on tackling the security and privacy of cyber-physical systems (CPS) by integrating the theory and best practices from the information security community as well as practical approaches from the control theory community. The first part of the project focuses on security and protection of cyber-physical critical infrastructures such as the power grid, water distribution networks, and transportation networks against computer attacks in order to prevent disruptions that may cause loss of service, infrastructure damage, or even loss of life. The second part of the project focuses on privacy of CPS and proposes new algorithms to deal with the unprecedented levels of data collection granularity of physical human activity.
34.2.6 Trusted Execution Environment
We are working on an effort that investigates how to enable application developers to securely use the SGX instructions, with an open source software support including a toolchain, programming abstractions (e.g., library), and operating system support (e.g., kernel modules). In addition, this research systematically explores the systems and software defenses necessary to secure the SGX programs from the enclave itself and defeat the malicious use of SGX from the underlying OS.
34.2.7 Infrastructure Development
We have developed hardware, software and data infrastructures for our students to carry out experimental research. These include secure cloud infrastructures, mobile computing infrastructures as well as social media infrastructures. The data collected includes both geospatial data, social media data, as well as malware data. Some of these infrastructures are discussed in our previous books ([THUR14], [THUR16]).
34.3 Education and Infrastructure Program in BDMA
We introduced our data science track in the Computer Science department for graduate students in Fall 2013 and it is the most popular track with numerous students enrolled in the program. The following courses are required for this track: statistical methods for data sciences; big data management and analytics; design and analysis of computer algorithms; and machine learning. In addition, students are required to take one of additional course such as natural language processing (NLP) or database design. The course we are designing integrates out BDMA course with real-world applications.
Our current BDMA course focuses on data mining and machine learning algorithms for analyzing very large amounts of data. MapReduce and NoSQL system are used as tools/standards for creating parallel algorithms that can process very large amounts of data. It covers basics of Hadoop, MapReduce, NoSQL systems (e.g., key–value stores, column-oriented data stores), Cassandra, Pig, Hive, MongoDB, Hbase, BigTable, SPARK, Storm, large-scale supervised machine learning, data streams, clustering, and applications including recommendation systems. The following reference books are used to augment the material presented in lectures:
•Jimmy Lin and Chris Dyer, Data-Intensive Text Processing with MapReduce, Morgan & Claypool Publishers, 2010. http://lintool.github.com/MapReduceAlgorithms/
•Anand Rajaraman and Jeff Ullman, Mining of Massive Datasets, Cambridge Press, http://infolab.stanford.edu/∼ullman/mmds/book.pdf
•Chuck Lam, Hadoop in Action, December, 2010|336 pages ISBN: 9781935182191.
•Spark: http://spark.apache.org/docs/latest/
Our capstone course to be designed will be titled Big Data and Machine Learning for Scientific Discovery. It will integrate several of the topics in the BDMA course as well as our course in machine learning as well as the theatrical concepts with experimental work using real-world applications such as Environmental and Remote Sensing Applications. The course will focus on the practical application of a variety of supervised and unsupervised machine learning approaches that can be used for nonlinear multivariate systems including neural networks, deep neural networks, support vector machines, random forests, and Gaussian processes. A variety of supervised and unsupervised classifiers such as self-organizing maps will be used. Many of these datasets are non-Gaussian so mutual information will be introduced. Using remote sensing from a wide variety of platforms, from satellites to aerial vehicles coupled with machine learning, multiple massive big datasets can be of great use for a wide variety of scientific, societal, and business applications. Remote sensing can provide invaluable tools for both improved understanding and making data-driven decisions and policies. This course will give an introduction to a wide range of big data applications in remote sensing of land, ocean, and atmosphere and their practical applications of major societal importance such as environmental health, drought and water issues, and fire. The experimental projects will include the processing of multiple massive datasets and machine learning. The skills developed from the big data curriculum may be used in a scenario where students can learn the practical techniques of designing algorithms using large datasets. For example, after learning NoSQL (MapReduce, Pig, Hive, SPARK) from the course, students can apply these techniques/tools to query from large datasets in a scalable manner using commodity hardware. In addition to the graduate education in BDMA, we are also planning on introducing senior design projects in collaboration with local corporations.
The Capstone BDMA course will consist of two modules. The data management part introduces various techniques and data structures to handle large data where traditional models or data structures do not efficiently scale to address the problems involving such voluminous data. The data analytics module introduces various algorithms which are widely used for analyzing the information in the large datasets. Supervised/unsupervised learning is a collection of algorithms used for classification, clustering, and pattern recognition. The module introduces generic problems, which can be ubiquitously applied to specific cases when working on a dataset in the relevant field when learning a model using the data values. For example, classification can be used for real-time anomaly detection where the anomalous data is to be classified from nonanomalous data either assuming class labels or no class labels. Relational learning is a general term used for data mining algorithms dealing with data and feature relationships. A real-world dataset may have multiple features and data items that may have specific relationships between them [CHAN14]. For example, an atmospheric dataset may have features of temperature, pressure, type of cloud, moisture content, and so on. In order to predict if a set of data indicates rain, the relationship between these features needs to be considered for a better prediction model. These relationships may be causal or noncausal in nature. A query (e.g., will it rain in the next few days?) would be better evaluated from a model that best represents the features and evidence given. Lastly, stream mining is a collection of algorithms used for handling continuously occurring data. Data streams are continuous flows of data. Examples of data streams include network traffic, sensor data, call center records, and so on. Data streams demonstrate several unique properties that together conform to the characteristics of big data (i.e., volume, velocity, variety, and veracity) and add challenges to data stream mining. Most existing data stream classification techniques ignore one important aspect of stream data: arrival of a novel class. We have addressed this issue and proposed a data stream classification technique that integrates a novel class detection mechanism into traditional classifiers, enabling automatic detection of novel classes before the true labels of the novel class instances arrive ([MASU09], [MASU11a], [MASU11b], [HAQU14], [HAQU15]). Overall, methodologies to perform such analytics from the data would be useful for students to understand the practical implications of using large datasets while designing an algorithm.
Figure 34.2 shows an example of case studies related to the planned Capstone BDMA course. The data management part of the course includes learning about NoSQL, Hadoop, Spark, Storm, and so on. These technologies will be used while studying cases in
1.GDELT (1 and 2) Political event data which use NoSQL and Hadoop MapReduce, Spark concepts in a supervised/semisupervised settings.
2.Timely Health Indicator (3 and 5) with data management techniques using Spark while performing supervised/semisupervised learning on a stream data.
3.Scalable Inference on Graphical Models (4 and 7) studies Relational Learning using concepts of Spark with Alchemy 2.0.
4.Real-Time Anomaly detection (6 and 9) using Spark to manage data while performing supervised stream mining.
5.Security and Privacy (8 and 10) issues in implementing supervised or unsupervised learning or in implementing big data management systems such as Spark or NoSQL.
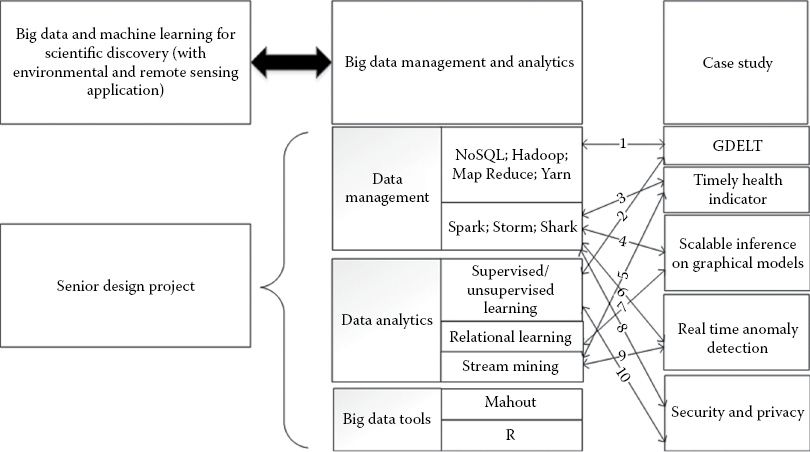
These case studies, part of our research related to Big Data, will be discussed in more detail later in this Chapter. Hence, they will be integrated with the planned education module. Further, these would be supported with the knowledge in Tools such as Mahout, R, and so on depending on the application and working environment. The planned case studies discussed in Chapter 33 will also be utilized for the experimental programs.
We discuss a sample of our research projects that have contributed a great deal to our Big Data education. These projects can be integrated into the case studies of the capstone course.
34.3.2.1 Geospatial Data Processing on GDELT
Collecting observations from all international news coverage and using TABARI software to code events, the Global Database of Event, Language, and Tone (GDELT) is the only global political georeferenced event dataset with 250+million observations covering all countries in the world from January 1, 1979 to the present with daily updates. The purpose of this widely used dataset is to help understand and uncover spatial, temporal and perceptual trends of the social and international system. To query such big geospatial data, traditional relational databases can no longer be used and the need for parallel distributed solutions has become a necessity [ALNA14].
The MapReduce paradigm has proved to be a scalable platform to process and analyze big data in the cloud. Hadoop as an implementation of MapReduce is an open source application that has been widely used and accepted in academia and industry. However, when dealing with spatial data, Hadoop is not equipped well and falls short as it does not perform efficiently in terms of running time. SpatialHadoop is an extension of Hadoop with the support of spatial data. We have developed the geographic information system querying framework to process massive spatial data ([ALNA14], [ALNA16]).
34.3.2.2 Coding for Political Event Data
Political event data has been widely used to study international politics. Dating back to the early stage, natural text processing and event generation required a great amount of human effort. Nowadays, we have high computing infrastructure with advance NLP metadata to leverage those tiresome efforts. TABARI, an open-source nondistributed event-coding software, was an early effort to generate events from a large corpus. It uses a shallow parser to identify political actors but ignores semantics and intersentence relations. PETRARCH is the successor of TABARI that encodes event data into “who-did-what-to-whom” format. It uses Stanford CoreNLP to parse sentences and a static CAMEO dictionary to encode data. In order to build a dynamic dictionary, we need to analyze more metadata from a sentence-like token, named entity recognition, coreference, and many more. Although the above tools make a dramatic impact in event collection, they are too slow and suffer scalability issues when we try to extract metadata from a single document. The situation gets worse for other languages like Spanish or Arabic and the time required to process them increases multifold. We have developed a novel distributed framework using Apache Spark, MongoDB, Stanford CoreNLP, and PETRARCH funded by NSF recently. The framework integrates both tools using distributed commodity hardware and reduces text processing time substantially with respect to nondistributed architecture. We have chosen Spark over traditional distributed frameworks like MapReduce, Storm, or Mahout. Spark has in-memory computation and lower processing time in both batch and stream processing compared to others [SOLA16]. These findings will be integrated as a case study in our planned capstone course. The GDELT and political event dataset will be given to students to query using our customized framework.
34.3.2.3 Timely Health Indicator
The atmospheric scientists in our team are leading projects on timely health indicators and collaborate with the Veterans Administration. As the use and combination of multiple big datasets becomes ubiquitous and the Internet of Things becomes a reality, we increasingly need to deal with large volumes of heterogeneous datasets. These datasets may be discrete data points, images, or gridded datasets (e.g., meteorological models or satellite data). They may also be observations, demographic or social data, or business transactions. They may also be publicly available or require varying levels of access control. Further, they may need to be streamed in real time with low latency, have a relaxed latency requirement, and be structured or unstructured. In Chapter 34, we discussed a practical case study that includes not only BDMA-related topics but also data security and privacy, machine learning, and real-time anomaly detection. This case study will be used to devise various experiments for the students.
34.4 Security and Privacy for Big Data
Organizations own and generate humongous amounts of data that can be analyzed for understanding the customers as well as for providing various services. Computations over big data may require massive computational resources and while an organization may have its own computational resources, it may use a third-party service to outsource some computations to be cost-effective. In these cases, data may be transferred to a third-party service. The issue of trustworthiness in computation and data security arises when these data contain sensitive information. For example, consider weather data collected by the special operations weather specialists (SOWT) for providing intelligence on various locations to say Air Force organizations. This dataset may have information of sensitive locations that may be necessary to use in an analytical solution. Similarly, intelligence data collected from airborne systems such as drones may have sensitive information of national importance. Analytics over these data such as simulation of wartime strategies based on weather conditions and object identification in images captured by drones may require large computational resources. When a third-party server is used for computation, data inherently becomes available in untrusted environments, that is, either observed by a man-in-the-middle during data transmission or insider threat from adversaries at the third-party location where computation is performed. In these cases, data owners may need to protect their data and require cryptographic guarantees about data security and integrity of computational output from these third-party services.
Recent advancements in embedded hardware technology to support TEE (e.g., TPM [PERE06], ARM Trust Zone [SANT14], AMD SVM [DOOR06]), and Intel SGX ([ANAT13], [HOEK13], [MCKE13]) have generated exciting opportunities for research in the field of cloud computing, trusted data analytics and applied cryptography. By protecting code and data within a secure region of computation, a cloud service can ensure confidentiality and integrity of data and computations. A few studies have shown the use of TEE for data analytics ([OHIR16], [RANE15]). Despite this progress, significant challenges remain in leveraging TEE for a multitude of analytical solutions including high-dimensional data, interactive techniques, data search and retrieval, and so on. Each of these does not inherently satisfy properties of TEE architectures and has different data flows.
To establish a scientific foundation for data analytical models to leverage TEEs, evaluate their limitations, explore performance overhead, and analyze security implications such as side channels, we plan to develop a framework to support legacy systems and establish benchmark schemes for trustworthy analytics. To facilitate projects in the capstone course, we will leverage this framework. We will also enhance some of our current courses in cybersecurity (CyS) (e.g., data and applications security and privacy, secure infrastructures, secure cloud computing and BDMA) by incorporating modules in BDSP. Our laboratory, a framework to carry out hands-on activities relevant to BDSP, will be used by our students, including our SFS students, for their course projects as well as anybody in the world via open source release. Our lab together with the lab manuals as well as our courses will be made available to the researchers and educators in CyS. Our research in BDSP as well as our education program in CyS will be integrated to build a strong capacity for BDSP education program. Essentially, we aim to address the security challenges, by providing a platform accessible to Big Data users (e.g., Iota users), developers, and researchers to provide better insights for further research in BDSP.
34.4.2.1 Extensions to Existing Courses
In order to integrate the proposed lab with these courses, we will design various modules to be integrated with its existing projects. An overview is provided in Figure 34.3. These modules will be derived from our existing research (detailed in Section 34.3) and/or our proposed virtual lab development (detailed in Section 34.4.1). For example, the modules, “Access Control for Secure Storage and Retrieval” may be integrated with our graduate course, “Data and Applications Security and Privacy.” The “Performance Overhead of Trusted Execution Environments” module will be integrated into the course “System Security and Binary Code Analysis.” The “Feature Extraction & (Un) Supervised Learning,” “Distributed Trusted Execution Environments,” and “Secure Encrypted Stream Analytics” modules will be integrated into the “Big Data Management and Analytics” course. Below we will describe a sample of our cyber security courses that are being enhanced with BDSP models.
1.Data and Applications Security: This course provides a comprehensive overview of database security, confidentiality, privacy and trust management, data security and privacy, data mining for security applications, secure social media, secure cloud computing, and web security. In addition to term papers, students also carry out a programming project that addresses any of the topics covered in class. Typical student projects have included data mining tools for malware detection as well as access control tools for social media systems. We have introduced a course module in access control for secure storage and retrieval of Big Data.
2.System Security and Binary Code Analysis: The goal of this course is to explain the low-level system details from compiler, linker, loader, to OS kernel and computer architectures; examine the weakest link in each system component, explore the left bits and bytes after all these transformations; and study the state-of-the-art offenses and defenses. The learning outcome is students shall be able to understand how an attack is launched (e.g., how an exploit is created) and how to do the defense (e.g., developing OS patches, analyzing the binary code, and detecting intrusions). We will introduce additional units on overhead of TEE for secure hardware extension.
3.Big Data Analytics and Management: As stated earlier, our current BDMA course focuses on data mining and machine learning algorithms for analyzing very large amounts of data or big data. MapReduce and NoSQL system are used as tools/standards for creating parallel algorithms that can process very large amounts of data. It covers the basics of Hadoop, MapReduce, NoSQL systems (Cassandra, Pig, Hive, MongoDB, Hbase, BigTable, HBASE, Spark), Storm, Large-scale supervised machine learning, data streams, clustering, and applications including recommendation systems, web, and security. This course focuses on large-scale feature extraction and learning to leverage the big data platform to perform parallel and distributed analysis. In addition, the course focuses on a stream analytics framework using secure hardware extension. We have also introduced a module on BDSP for this course.
4.Secure Cloud Computing: This course introduces the concepts of secure web services and service-oriented architecture and then describes in detail the various layers of a secure cloud. These include secure hypervisors, secure data storage, secure cloud query processing, and cloud forensics. The use of the cloud for computing intensive tasks such as malware detection is also discussed. We have introduced a module BDSP and will introduce additional modules on the set-up of TEE for secure hardware extension.
5.Secure Cyber-Physical Systems and Critical Infrastructures: This course introduces the security of cyber-physical systems from a multidisciplinary point of view, from computer science security research (network security and software security) to public policy (e.g., the Executive Order 13636), risk assessment, business drivers, and control-theoretic methods to reduce the cyber risk to cyber-physical critical infrastructures. We will introduce a module on feature extraction and (un/semi) supervised learning to find anomalies in cyber-physical systems.
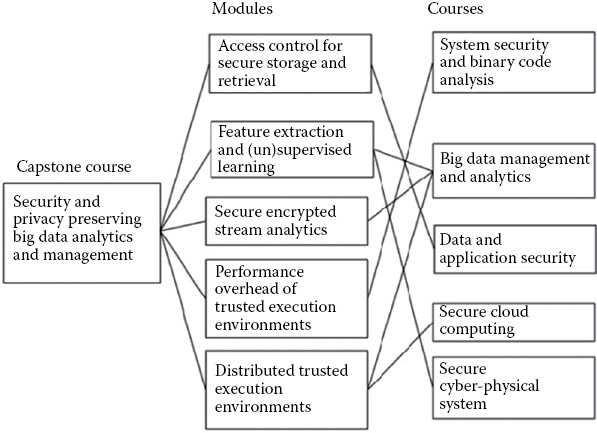
34.4.2.2 New Capstone Course on BDSP
Our capstone course to be designed will be motivated by (a) research and development in secure storage and retrieval of big data, (b) research and development of stream data analytics over evolving continuous stream data, and (c) the research and experimentation on performance overhead of TEEs. The modules created for all our cyber security courses will be aggregated and taught as part of the capstone course in addition to some new topics. The topics covered will include (i) access control for secure storage and retrieval, (ii) feature extraction and (un) supervised learning for big data, (iii) stream mining over continuous evolving streams, (iv) secure encrypted stream analytics, and (v) performance overhead of TEE. We will also discuss the various TEE system prototypes, products, and standards. Students will carry out the programming projects based on the lab resources to conduct secure and privacy-preserving big data analytics and management research.
The lab to be developed would be accessible to all of students who will enroll into relevant and capstone courses. First, we will leverage our current single Intel SGX-enabled machine and later will construct a cluster for the lab experiment. We use an Intel SGX-enabled Linux system with i7-6700 CPU (Skylake) and 64-GB RAM operating at 3.40 GHz with 8 cores, running Ubuntu 14.04. We have installed the latest Intel SGX SDK and SGX driver [SGXSDK]. While running SGX applications, the trusted hardware establishes an enclave by protecting isolated memory regions within the existing address space, called processor reserved memory (PRM), against other nonenclave memory accesses including kernel, hypervisor, and other privileged code.
Number of enclaves on single machine—A special region inside PRM called the Enclave Page Cache (EPC) stores sensitive code and data as encrypted 4 kB pages. EPC size can be configured inside BIOS setting to a maximum size of 128 MB. Hence, the number of enclaves that can be run efficiently inside a single machine is limited by EPC size.
The overhead of SGX application increases with the increase in number of enclaves run on a single machine. Typically, 5–8 enclaves can be run simultaneously on a single machine without producing significant performance overhead. SGX applications also show memory access overhead because every data read or write needs to be present inside the EPC cache. Thus, running heavy computations on large data inside the enclave can produce performance overhead. We will maintain secure enclave cluster. There are various challenges in developing such an enclave cluster. Building SGX-enabled cluster requires: (a) using SGX-enabled machine at each node and (b) securing communication between enclaves running on same machine or different machine. SGX-enabled machine protects local code and data running on a single machine. For secure communication between enclaves running on same or different machines, enclaves can first authenticate each other and establish a Diffie Hellman cryptography-based secure communication channel.
34.4.3.2 Programming Projects to Support the Lab
We will devise student programming projects to support the lab. We provide an overview of three sample projects and discuss samples of these projects. In particular, we first describe a secure data storage and retrieval mechanism for big data. Second, we describe a mechanism to estimate overhead of systematic performance study of TEE. Finally, we describe secure encrypted stream data processing using secure hardware extension.
34.4.3.2.1 Project 1: Secure Data Storage and Retrieval in the Cloud
With the advent of the World Wide Web and the emergence of e-commerce applications and social networks, organizations across the world generate a large amount of data daily. This data would be more useful to cooperating organizations if they were able to share their data. Two major obstacles to this process of data sharing are providing a common storage space and secure access to the shared data. We have addressed these issues by combining cloud computing technologies such as Hive and Hadoop with XACML policy-based security mechanisms that provide fine-grained access to resources [KHAD12]. We have further presented a web-based application that uses this combination and allows collaborating organizations to securely store and retrieve large amounts of data.
34.4.3.2.2 Project 2: Systematic Performance Study of TEE
Building trustworthy computing systems to execute trusted applications has been a grand challenge. This is simply because of the large attack surface an application could face from hardware, system management mode (SMM), BIOS, hypervisor (or virtual machine manager [VMM]), operating systems, libraries, and the application code itself. This problem becomes even worse in outsourced cloud computing since everything can be untrusted except the application code itself. While a large amount of effort has been focusing on using various layer-below security checks from hardware [MCCU07] (SMM [WANG10], BIOS [SUN12], or hypervisor ([CHEN08], [LI14], [MCCU10], [SESH07], [STEINBERG10], [ZHANG11]) to mitigate this problem, increasingly there is a growing interest of using hardware technologies (e.g., TPM [PERE06], ARM Trust Zone [SANT14], and AMD SVM [DOOR06]) to build TEE, and the most recent advancement in this direction is Intel SGX ([ANAT13], [HOEK13], [MCKE13]) which is able to reduce the trusted computing base to the smallest possible footprint, namely, just the hardware and the application code itself without trusting the hypervisor, operating systems, or the surrounding libraries.
At a high level, SGX allows an application or part of an application to run inside a secure enclave, an isolated execution environment in which code and data can execute without the fear of inspection and modification. SGX hardware, as a part of the CPU, protects the enclave against malicious software, including the operating systems, device drivers, hypervisor, or even low-level firmware code (e.g., SMM) from compromising its integrity and confidentiality. Also, physical attacks such as memory bus snooping, memory tampering, and cold boot attacks [HALD09] all will fail since the enclave secret will be only visible inside the CPUs. Coupled with remote attestation, SGX allows developers to build a root of trust even in an untrusted environment. Therefore, SGX provides an ideal platform to protect the secrets of an application in the enclave even when an attacker has full control of the entire system.
SGX is likely to make outsourced computing in data centers and the cloud practical. However, there is no study to precisely quantify the overhead of Intel SGX, partly because SGX requires programmers to use these instructions to develop the application or system software and currently there is no publicly available SGX test bed or benchmarks. To answer the question of how much overhead SGX could bring to an application, we have systematically measured the overhead of SGX programs using both macro-benchmarks and micro-benchmarks.
34.4.3.2.3 Project 3: Secure Encrypted Stream Data Processing Using Modern Secure Hardware Extensions
Data analysis involving sensitive encrypted data has been an enduring challenge in protecting data privacy and preventing misuse of information by an external adversary. While advancements in encrypted data processing have encouraged many data analytics applications, results from such mechanisms usually do not scale to very large datasets. Recent advances in trusted processor technology, such as Intel SGX, have rejuvenated the efforts of performing data analytics on sensitive encrypted data where data security and trustworthiness of computations are ensured by the hardware ([SCHU15], [DINH15] [GUPT16] [KIM15]). However, studies have shown that a powerful adversary may still be able to infer private information from side channels such as memory access, cache access, CPU usage, and other timing channels, thereby threatening data and user privacy. Though studies have proposed techniques to hide such information leaks using carefully designed data-independent access paths, these have only been shown to be applicable to traditional data analytics problems that assume a stationary environment, leaving data analytics in a nonstationary environment (e.g., data stream analytics) [MASU11c] as an open problem.
In particular, for stationary environments, studies have proposed multiple techniques to ensure data privacy and improve trustworthiness of computational results. Computations employing fully homomorphic encryption schemes [KOCH14] can be used to address these issues. In practice, however, they are known to be computationally inefficient for a wide range of operations [NAEH11]. This has encouraged developers to seek hardware solutions such as Intel SGX [ANAT13] which provides a secure region of computation to ensure data confidentiality and integrity. Applications using Intel SGX have focused on an untrusted cloud computing environment. For example, a popular big data analytics tool called Hadoop [SHVA10] is deployed over a SGX-enabled cloud service [DINH14]. While the above design can be directly applied to data streams as well, Hadoop is shown to be inefficient for data stream processing. The most relevant work to our planned efforts is the recently published data-oblivious methods for multiple machine learning algorithms [OHIR16]. This study inspired from [RANE15] details certain data-oblivious primitives to be used in a set of machine learning algorithms. However, they focused on stationary learning systems.
Data streams are a particular type of data with continuously occurring ordered instances. Sources of such streaming data include, among others, computer network traffic, social tweets, phone conversation, and so on. Data from these sources can be utilized in numerous data analytics tasks such as intrusion detection, terrorist watch list matching, and so on. With potentially unlimited data instances generated from a source, traditional learning techniques that require prior knowledge of data sizes and train once on a stationary data cannot be directly employed over a data stream.
As such, we would like to answer the following question “How can we perform computations on an encrypted dataset while remaining encrypted to an adversary?” for a large amount of continuously arriving data streams. Our goal is to keep the privacy-sensitive streaming data encrypted except while it is processed securely inside the secure enclave and perform interesting data analytics task on the encrypted data by leveraging the recent developments in secure hardware design (e.g., Intel SGX).
Therefore, we plan to develop a framework for performing data analytics over sensitive encrypted streaming data [MASU11c] using SGX to ensure data privacy. In particular, we plan to design data-oblivious mechanisms to address the two major problems of classification over continuous data streams (i.e., concept drift and concept evolution) when deployed over an Intel SGX processor. In addition, we will explore complex query processing over encrypted data streams. Using algorithmic manipulation of data access within a secure environment, we will prudently design and implement methods to perform data classification and data querying by adapting to changes in data patterns that occur over time while suppressing leakage of such information to a curious adversary via side channels. In addition to hiding data patterns during model learning or testing, we also aim to hide changes in those data patterns over time. Furthermore, we plan to support basic stream query processing on the encrypted sensitive streams in addition to building classification models. Our initial work indicates the adaptation of such algorithms perform equivalently to a data stream processing on unencrypted data, and achieve data privacy with a small overhead.
Concretely, we need to develop techniques to address the above challenges while utilizing encrypted streaming data containing sensitive and private information. As shown in Figure 34.4, encrypted data will be only decrypted inside the secure/trusted enclave protected by the hardware. Data decrypted inside the enclave cannot be accessed by the operating system or any other software running on the system. In addition, we appeal to the data obliviousness property required from an algorithm to guarantee data privacy. Here, data-obliviousness refers to the algorithmic property where memory, disk, and network accesses are performed independent of the input data. The main idea is to use appropriate data structures and introduce algorithmic “decoy” code whenever necessary. In addition to using oblivious testing mechanisms for predicting class label of test data instances, we develop data-oblivious learning mechanisms which are frequently invoked during model adaptation as needed.
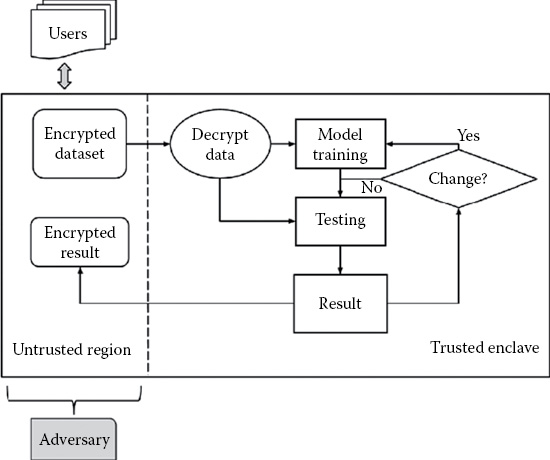
Furthermore, existing data stream classification techniques rely on ensemble of classifiers. These have been shown to outperform single classifiers. When developing an ensemble-based classification method over an encrypted data stream, it may be necessary to use multiple secure environments (enclaves). We plan to leverage the support of multiple enclaves by Intel SGX processors to perform such ensemble operations.
In this chapter, we have discussed our plans for developing an education curriculum, that is, integrated with an experimental program both in BDMA and BDSP. For BDMA we will enhance our current BDMA course with experiments dealing with real-world applications including in atmospheric science. For BDSP, we will design a capstone course as well as incorporate modules into several of our current courses including in secure cloud computing as well as in data and applications security and privacy. In addition, we also plan to develop a capability in TEE and will use the infrastructure in the courses.
We will also utilize the infrastructures we have developed for secure cloud, mobile computing, and social media that we have discussed in our previous books ([THUR14], [THUR16]) and integrate them into the new infrastructure to be developed as needed. Many of our students have become experts on programming with the Hadoop/MapReduce as well as the Spark frameworks. Working with the real-world applications and learning new technologies will enable them to design scalable machine learning techniques as well as privacy-enhanced machine learning techniques that have real-world significance.
The best evaluators of our courses, experiments, and infrastructures are our students. Therefore, we will obtain detailed evaluations from our students and discuss with them how we can enhance the programs for both BDMA and BDSP. We will also get inputs from our partners (e.g., industry and academic partners in related projects) on our programs. We strongly believe that research, design, and development efforts have to be tightly integrated with the education and infrastructure efforts so that our students can be well equipped for academic, industry, and government careers.
[ALNA14]. K.M. Al-Naami, S. Seker, L. Khan, “GISQF: An Efficient Spatial Query Processing System,” In 7th IEEE International Conference on Cloud Computing, June 27–July 2, 2014, Anchorage, AK.
[ALNA16]. K.M. Al-Naami, S.E. Seker, L. Khan, “GISQAF: MapReduce Guided Spatial Query Processing and Analytics System,” to appear in Journal of Software: Practice and Experience. John Wiley & Sons, Ltd., 46 (10), 1329–1349, 2016.
[ANAT13]. I. Anati, S. Gueron, S.P. Johnson, V.R. Scarlata, “Innovative Technology for CPU Based Attestation and Sealing,” In Proceedings of the 2nd International Work Shop on Hardware and Architectural Support for Security and Privacy (HASP), Tel Aviv, Israel, pp. 1–8, 2013.
[CHAN14]. S. Chandra, J. Sahs, L. Khan, B. Thuraisingham, C. Aggarwal, “Stream Mining Using Statistical Relational Learning,” In IEEE International Conference on Data Mining Series (ICDM), December, Shenzhen, China, pp. 743–748, 2014.
[CHEN08]. X. Chen, T. Garfinkel, E.C. Lewis, P. Subrahmanyam, C.A. Waldspurger, D. Boneh, J. Dwoskin, D.R. Ports, “Overshadow: A Virtualization-Based Approach to Retrofitting Protection in Commodity Operating Systems,” In Proceedings of the 13th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS XIII, ACM, Seattle, WA, USA, pp. 2–13, 2008.
[DINH14]. T.T. Anh Dinh, A. Datta, “Streamforce: Outsourcing Access Control Enforcement for Stream Data to The Clouds,” CODASPY, 2014, 13–24, 2014.
[DINH15]. T.T. Anh Dinh, P. Saxena, E.-C. Chang, B.C. Ooi, C. Zhang, “M2R: Enabling Stronger Privacy in MapReduce Computation,” USENIX Security Symposium 2015, Washington, DC, pp. 447–462, 2015.
[DOOR06]. L. Van Doorn, “Hardware Virtualization Trends,” In ACM/USENIX International Conference on Virtual Execution Environments: Proceedings of the 2nd International Conference on Virtual Execution Environments, Ottawa, Ontario, Canada, vol. 14, pp. 45–45, 2006.
[GUPT16]. D. Gupta, B. Mood, J. Feigenbaum, K. Butler, P. Traynor, “Using Intel Software Guard Extensions for Efficient Two-Party Secure Function Evaluation,” In Proceedings of the 2016 FC Workshop on Encrypted Computing and Applied Homomorphic Cryptography, Barbados, pp. 302–318, 2016.
[HALD09]. J.A. Halderman, S.D. Schoen, N. Heninger, W. Clarkson, W. Paul, J.A. Calandrino, A.J. Feldman, J. Appelbaum, E.W. Felten, “Lest We Remember: Cold-Boot Attacks on Encryption Keys,” Communications of the ACM, 52 (5), 91–98, 2009.
[HAQU14]. A. Haque, S. Chandra, L. Khan, C. Aggarwal, “Distributed Adaptive Importance Sampling on Graphical Models Using MapReduce,” In 2014 IEEE International Conference on Big Data (IEEE BigData 2014), Washington, DC, USA, pp. 597–602, 2014.
[HAQU15]. A. Haque, L. Khan, M. Baron, “Semi-Supervised Adaptive Framework for Classifying Evolving Data Stream,” PAKDD (2), Ho Chi Minh City, Vietnam, pp. 383–394, 2015.
[HOEK13]. M. Hoekstra, R. Lal, P. Pappachan, V. Phegade, J. Del Cuvillo, “Using Innovative Instructions to Create Trustworthy Software Solutions,” In Proceedings of the 2nd International Workshop on Hardware and Architectural Support for Security and Privacy (HASP), Tel Aviv, Israel, pp. 1–8, 2013.
[KHAD12]. V. Khadilkar, K.Y. Oktay, M. Kantarcioglu, S. Mehrotra, “Secure Data Processing over Hybrid Clouds,” IEEE Data Eng. Bull., 35(4), 46–54, 2012.
[KIM15]. S. Kim, Y. Shin, J. Ha, T. Kim, D. Han, “A First Step Towards Leveraging Commodity Trusted Execution Environments for Network Applications,” In Proceedings of the 14th ACM Workshop on Hot Topics in Networks (p. 7), November, ACM, 2015.
[KOCH14]. O. Kocabas and T. Soyata, “Medical Data Analytics in The Cloud Using Homomorphic Encryption,” Handbook of Research on Cloud Infrastructures for Big Data Analytics, P. R. Chelliah and G. Deka (eds), IGI Global, pp. 471–488, 2014.
[LI14]. Y. Li, J. McCune, J. Newsome, A. Perrig, B. Baker, W. Drewry, “MiniBox: A Two-Way Sandbox for x86 Native Code,” USENIX 2014, Philadelphia, PA, pp. 409–420.
[MASU09]. M.M. Masud, J. Gao, L. Khan, J. Han, B.M. Thuraisingham, “Integrating Novel Class Detection with Classification for Concept-Drifting Data Streams,” In Proceedings of European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD), Bled, Slovenia, pp. 79–94, 2009.
[MASU11a]. M.M. Masud, J. Gao, L. Khan, J. Han, K.W. Hamlen, N.C. Oza, “Facing the Reality of Data Stream Classification: Coping with Scarcity of Labeled Data,” International Journal of Knowledge and Information Systems (KAIS), 33 (1), 213–244, 2011, Springer, 2011.
[MASU11b]. M.M. Masud, J. Gao, L. Khan, J. Han, B.M. Thuraisingham,“Classification and Novel Class Detection in Concept-Drifting Data Streams under Time Constraints,” IEEE Transactions on Knowledge and Data Engineering, 23 (6), 859–874, 2011.
[MASU11c]. M. Masud, J. Gao, L. Khan, J. Han, B.M. Thuraisingham, “Classification and Novel Class Detection in Concept-Drifting Data Streams Under Time Constraints,” IEEE Transactions on Knowledge and Data Engineering, 23 (6), 859–874, 2011.
[MCCU07]. J.M. McCune, B. Parno, A. Perrig, M.K. Reiter, H. Isozaki, “An Execution Infrastructure for TCB Minimization,” Technical Report CMU-CyLab-07-018, Carnegie Mellon University, Dec. 2007.
[MCCU10]. J.M. McCune, Y. Li, N. Qu, Z. Zhou, A. Datta, V. Gligor, A. Perrig, “Trustvisor: Efficient TCB Reduction and Attestation,” In Proceedings of the 2010 IEEE Symposium on Security and Privacy, IEEE Computer Society, pp. 143–158, 2010.
[MCKE13]. F. McKeen, I. Alexandrovich, A. Berenzon, C.V. Rozas, H. Shafi, V. Shanbhogue, U.R. Savagaonkar, “Innovative Instructions and Software Model for Isolated Execution,” In Proceedings of the 2nd International Workshop on Hardware and Architectural Support for Security and Privacy (HASP), Tel Aviv, Israel, pp. 1–8, 2013.
[NAEH11]. M. Naehrig, K. Lauter, V. Vaikuntanathan, “Can Homomorphic Encryption be Practical?,” In Proceedings of the 3rd ACM Work Shop on Cloud Computing Security Workshop, ACM, Chicago, IL, pp. 113–124, 2011.
[OHIR16]. O. Ohrimenko, F. Schuster, C. Fournet, A. Mehta, S. Nowozin, K. Vaswani, M. Costa, “Oblivious Multi-Party Machine Learning on Trusted Processors.” USENIX Security Austin, TX, pp. 619–636, 2016.
[PERE06]. R. Perez, R. Sailer, L. van Doorn et al., “vTPM: Virtualizing the Trusted Platform Module,” USENIX Security Symposium, pp. 305–320, 2006.
[RANE15]. A. Rane, C. Lin, M. Tiwari, “Raccoon: Closing Digital Side-Channels through Obfuscated Execution,” In 24th USENIX Security Symposium (USENIX Security 15), Washington, DC, pp. 431–446, 2015.
[SANT14]. N. Santos, H. Raj, S. Saroiu, A. Wolman, “Using Arm Trustzone to Build A Trusted Language Runtime for Mobile Applications,” ACM SIGARCH Computer Architecture News, ACM, Vol. 42(1), pp. 67–80, 2014.
[SCHU15]. F. Schuster, M. Costa, C. Fournet, C. Gkantsidis, M. Peinado, G. Mainar-Ruiz, M. Russinovich, “VC3: Trustworthy Data Analytics in the Cloud Using SGX,” In 2015 IEEE Symposium on Security and Privacy, May, IEEE, San Jose, CA, pp. 38–54, 2015.
[SESH07]. A. Seshadri, M. Luk, N. Qu, A. Perrig, “Secvisor: A Tiny Hypervisor to Provide Lifetime Kernel Code Integrity for Commodity OSes,” In Proceedings of 21st ACM SIGOPS Symposium on Operating Systems Principles, SOSP ’07, Stevenson, WA, USA, pp. 335–350, 2007.
[SGXSDK]. Intel software guard extensions (intel sgx) sdk. https://software.intel.com/en-us/sgx-sdk.
[SHVA10]. K. Shvachko, H. Kuang, S. Radia, R. Chansler, “The Hadoop Distributed File System,” In 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), IEEE, Incline Village, NV, pp. 1–10, 2010.
[SOLA16]. M. Solaimani, R. Gopalan, L. Khan, B. Thuraisingham, “Spark-Based Political Event Coding,” to appear in the 2nd IEEE International Conference on Big Data Computing Service and Applications, IEEE BigDataService 2016, Oxford, UK, pp. 14–23, March 29–April 1, 2016.
[STEI10]. U. Steinberg and B. Kauer. NOVA: A Microhypervisor-Based Secure Virtualization Architecture,” ACM, Paris, France, pp. 209–222, 2010.
[SUN12]. K. Sun, J. Wang, F. Zhang, A. Stavrou. “SecureSwitch: BIOS-Assisted Isolation and Switch between Trusted and Untrusted Commodity OSes,” NDSS, San Diego, CA, 2012.
[THUR14]. B. Thuraisingham, Developing and Securing the Cloud. CRC Press, Boca Raton, FL, USA, 2014.
[THUR16]. B. Thuraisingham, S. Abrol, R. Heatherly, M. Kantarcioglu, V. Khadilkar, L. Khan, Analyzing and Securing Social Networks. CRC Press, Boca Raton, FL, USA, 2016.
[WANG10]. J. Wang, A. Stavrou, A.K. Ghosh, “Hypercheck: A Hardware-Assisted Integrity Monitor,” Recent Advances in Intrusion Detection, 13th International Symposium, RAID 2010, Ottawa, Ontario, Canada, September 15–17, Proceedings, pp. 158–177, 2010.
[ZHANG11]. F. Zhang, J. Chen, H. Chen, and B. Zang, “CloudVisor: Retrofitting Protection of Virtual Machines in Multi-Tenant Cloud with Nested Virtualization.” In Proceedings of the 23rd ACM Symposium on Operating Systems Principles (SOSP’11), Cascais, Portugal, pp. 203–216, 2011.