
Security has many dimensions including confidentially, privacy, trust, availability, and dependability among others. Our work has examined confidentiality, privacy, and trust (CPT) aspects of security for big data systems such as social media systems and cloud data systems where the data is represented using semantic web technologies and how they relate to each other. Confidentiality is essentially secrecy. Privacy deals with not disclosing sensitive data about the individuals. Trust is about the assurance one can place on the data or on an individual. For example, even though John is authorized to get salary data, can we trust John not to divulge this data to others? Even though the website states that it will not give out social security numbers of individuals, can we trust the website? Our prior work has designed a framework called CPT based on semantic web technologies that provides an integrated approach to addressing CPT [THUR07]. In this chapter, we will revisit CPT and discuss how it relates to big data such as social media data.
The organization of this chapter is as follows. Our definitions of CPT as well as the current status on administering the semantic web will be discussed in Section 29.2. This will be followed by a discussion of our proposed framework for securing the social media data that we call CPT in Section 29.3. Next, we will take each of the features, CPT, and discuss various aspects as they relate to social media in Sections 29.4 through 29.6, respectively. We have used social media systems as an illustrative example for big data systems. An integrated architecture for CPT as well as inference and privacy control will be discussed in Section 29.7. Relationship to a big data system such as a social media system is discussed in Section 29.8. Finally, this chapter is summarized and future directions are given in Section 29.9.
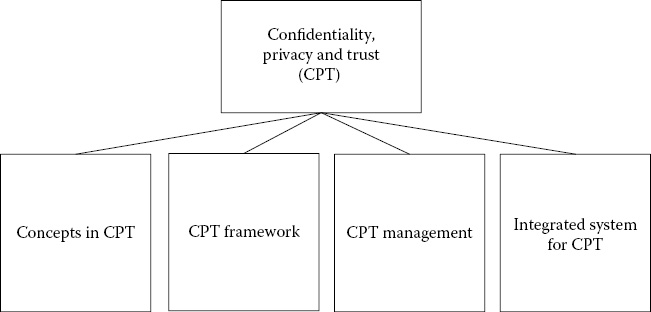
Figure 29.1 illustrates the concepts of this chapter. It should be noted that while we have focused on social media data for illustration purposes, the techniques can be applied to any type of big data system. The reason is the fact that such systems have reasoning capabilities and can learn from experiences, and, therefore, can be prone to both privacy attacks and attacks due to security violations via inference.
29.2 Trust, Privacy, and Confidentiality
In this section, we will discuss aspects of the security and privacy relationship to the inference problem with respect to social media data. In particular, confidentiality, privacy, trust, integrity, and availability will be briefly defined with an examination of how these issues specifically relate to the trust management and inference problem. Confidentiality is preventing the release of unauthorized information. One view of privacy is to consider it to be a subset of confidentiality in that it is the prevention of unauthorized information being released with regard to an individual. However, much of the recent research on privacy, especially relating to data mining, addresses the following aspect: How can we mine and extract useful nuggets about groups of people while keeping the values of the sensitive attributes of an individual private? That is, even though we can make inferences about groups, we want to maintain individual privacy. For example, we want to protect the fact that John has cancer. However, the fact that people who live in Dallas, Texas, are more prone to cancer is something we make public. More details on privacy and its relationship to data mining can be found in [AGRA00] and [KANT03].
Integrity of data is the prevention of any modifications made by an unauthorized entity. Availability is the prevention of unauthorized omission of data. Trust is a measure of confidence in data correctness and legitimacy from a particular source. Integrity, availability, and trust are all very closely related in the sense that data quality is of particular importance and all require individuals or entities processing and sending information to not alter the data in an unauthorized manner. If confidentiality, privacy, trust, integrity, and availability are all guaranteed, a system can be considered secure. Thus, if the inference problem can be solved such that unauthorized information is not released, the rules of CPT will not be broken. A technique such as inference can be used to either aid or impair the cause of integrity, availability, and trust. If correctly used, inference can be used to infer trust management policies. Thus, inference can be used for good or bad purposes. The intention is to prevent inferred, unauthorized conclusions and to use inference to apply trust management.
29.2.1 Current Successes and Potential Failures
The World Wide Web Consortium [W3C] has proposed encryption techniques for securing XML documents. Furthermore, logic, proof, and trust belong to one of the layers of the semantic web. However, by trust, in that context, is meant whether the semantic web can trust the statements such as data and rules. In our definition, by trust we mean to what extent we can believe that the user and the website will enforce the confidentiality and privacy policies as specified. Privacy has been discussed by the semantic web community. The main contribution of this community is developing the Platform for Privacy Preferences (P3P).
P3P requires the web developer of the server to create a privacy policy, validate it, and then place it in a specific location on the server as well as write a privacy policy in English. When the user enters the website, the browser will discover the privacy policy and if the privacy policy matches the user’s browser security specifications, then the user can simply enter the site. If the policy does not match the user’s specifications, then the user will be informed of the site’s intentions and the user can then choose to enter or leave.
While this is a great start, it is lacking in certain areas. One concern is the fact that the privacy policy must be placed in a specific location. If a website, for example, a student website on a school’s server, is to implement P3P and cannot place it in a folder directly from the school’s server, then the user’s browser will not find the privacy policy.
Another problem with P3P is that it requires the data collector on the server side to follow exactly what is promised in the privacy policy. If the data collections services on the server side decide to abuse the policy and instead do other things not stated in the agreement, then no real consequences occur. The server’s privacy policy can simply choose to state that it will correct the problem upon discovery, but if the user never knows it until the data is shared publicly, correcting it to show the data is private will not simply solve the problem. Accountability should be addressed, where it is not the server’s decision, but rather the lawmaker’s decisions. When someone breaks a law, or does not abide by contractual agreements, we do not turn to the accused and ask what punishment they deem necessary. Instead, we look to the law and apply each law when applicable.
Another point of contention is trust and inference. Before beginning any discussions of privacy, a user and a server must evaluate how much the other party can be trusted. If neither party trusts each other, how can either party expect the other to follow a privacy policy? Currently P3P only uses tags to define actions; it uses no web rules for inference or specific negotiations regarding confidentiality and privacy. With inference, a user can decide if certain information should not be given because it would allow the distrusted server to infer information that the user would prefer to remain private or sensitive.
29.2.2 Motivation for a Framework
While P3P is a great initiative to approaching the privacy problem for users of the semantic web, it becomes obvious from the above discussion that more work must be continued on this process. Furthermore, we need to integrate confidentiality and privacy within the context of trust management. A new approach to be discussed later must be used to address these issues such that the user can establish trust, preserve privacy and anonymity, and ensure confidentiality. Once the server and client have negotiated trust, the user can begin to decide what data can be submitted that will not violate his/her privacy. These security policies, one each for trust, privacy, and confidentiality, are described with web rules. Describing policies with web rules can allow an inference engine to determine what is in either the client or server’s best interest and help advise each party accordingly. Also with web rules in place, a user and server can begin to negotiate confidentiality. Thus, if a user does not agree with a server’s privacy policies but would still like to use some services, a user may begin negotiating confidentiality with the server to determine if the user can still use some services but not all (depending on the final conclusion of the agreement). The goal of this new approach is to simulate real-world negotiations, thus giving semantics to the current web and providing much needed security.
In this section, we will discuss a framework for enforcing CPT for the semantic web. We first discuss the basic framework where rules are enforced to ensure CPT. In the advanced framework, we include inference controllers that will reason about the application and determine whether CPT violations have occurred.
In the previous section, focus was placed on the client’s needs; now we will discuss the server’s needs in this process. The first obvious need is that the server must be able to evaluate the client in order to grant specific resources. Therefore, the primary goal is to establish trust regarding the client’s identity and, based on this identity, grant various permissions to specific data. Not only must the server be able to evaluate the client but also be able to evaluate its own ability to grant permission with standards and metrics. The server also needs to be able to grant or deny a request appropriately without giving away classified information or instead of giving away classified information, the server may desire to give a cover story. Either scenario, a cover story or protecting classified resources, must be completed within the guidelines of a stated privacy policy in order to guarantee a client’s confidentiality. One other key aspect is that all of these events must occur in a timely manner such that security is not compromised.
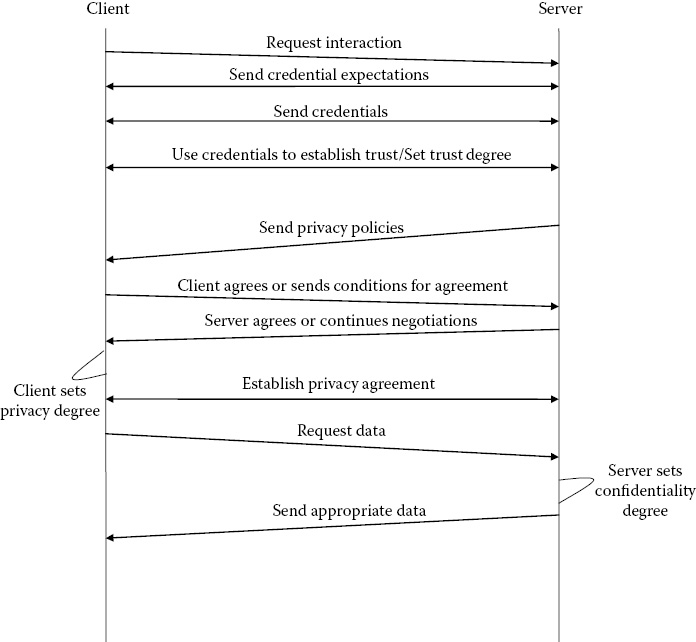
Now that the needs of the client and server have been discussed, focus will be placed on the actual process of our system CPT. First, a general overview of the process will be presented. After the reader has garnered a simple overview, this chapter will continue to discuss two systems—Advanced CPT and Basic CPT—based on the general process previously discussed. The general process of CPT is to first establish a relationship of trust and then negotiate privacy and confidentiality policies. Figure 29.2 shows the general process.

Notice that both parties partake in establishing trust. The client must determine the degree to which it can trust the server in order to decide how much trust to place in the resources supplied by the server and also to negotiate privacy policies. The server must determine the degree to which it can trust the client in order to determine what privileges and resources it can allow the client to access as well as how to present the data. The server and client will base their decisions of trust on credentials of each other. Once trust is established, the client and server must come to an agreement of privacy policies to be applied to the data that the client provides the server. Privacy must follow trust because the degree to which the client trusts the server will affect the privacy degree. The privacy degree affects what data the client chooses to send. Once the client is comfortable with the privacy policies negotiated, the client will then begin requesting data. Based on the initial trust agreement, the server will determine what and when the client views these resources. Based on its own confidentiality requirements and confidentiality degree, the client will make decisions regarding confidentiality and what data can be given to the user. It is also important to note that the server and client must make these decisions and then configure the system to act upon these decisions. The basic CPT system will not advise the client or server in any way regarding outcomes of any decisions. Figure 29.3 illustrates the communication between the different components.
The previous section discussed the basic CPT system, and the advanced CPT system is an extension of the basic system. The advanced CPT system is outlined in Figure 29.4, which incorporates three new entities not found in the basic system. These three new entities are the trust inference engine (TIE), the privacy inference engine (PIE), and the confidentiality inference engine (CIE). The first step of sending credentials and establishing trust is the same as the basic system except that both parties consult with their own TIE. Once each party makes a decision, the client receives the privacy policies from the server and then uses these policies in configuration with PIE to agree, disagree, or negotiate. Once the client and server have come to an agreement about the client’s privacy, the client will send a request for various resources. Based on the degree of trust that the server has assigned to a particular client, the server will determine what resources it can give to the client. However, in this step the server will consult the CIE to determine what data is preferable to give to the client and what data, if given, could have disastrous consequences. Once the server has made a conclusion regarding data that the client can receive, it can then begin transmitting data over the network.

29.3.4 Trust, Privacy, and Confidentiality Inference Engines
With regard to trust, the server must realize that if it chooses to assign a certain percentage of trust, then this implies the client will have access to the specific privileged resources and can possibly infer other data from granted permissions. Thus, the primary responsibility of the TIE is to determine what information can be inferred and is this behavior acceptable. Likewise, the client must realize that the percentage of trust it assigns to the server will affect permissions of viewing the site as well as affecting how data given to the client will be processed. The inference engine in the client’s scenario will guide the client regarding what can or will occur based on the trust assignment given to the server.
Once trust is established, the PIE will continue the inference process. It is important to note that the PIE only resides on the client side. The server will have its own privacy policies but these policies may not be acceptable to the client. It is impossible for the server to evaluate each client and determine how to implement an individual privacy policy without first consulting the client. Thus, the PIE is unnecessary on the server’s side. The PIE must guide the client in negotiating privacy policies. In order to guide the client through negotiations, the inference engine must be able to determine how the server will use data the client gives it as well as who else will have access to the submitted data. Once this is determined, the inference engine must evaluate the data given by the client to the server. If the inference engine determines that this data can be used to infer other data that the client would prefer to remain private, the inference engine must warn the client and then allow the client to choose the next appropriate measure of either sending or not sending the data.
Once the client and server have agreed on the privacy policies to be implemented, the client will naturally begin requesting data and the server will have to determine what data to send, based on confidentiality requirements. It is important to note that the CIE is located only on the server side. The client has already negotiated its personal privacy issues and is ready to view the data thus leaving the server to decide what the next appropriate action is. The CIE must first determine what data will be currently available to the client, based on the current trust assignment. Once the inference engine has determined this, the inference engine must explore what policies or data can be potentially inferred if the data is given to the client. The primary objective of the CIE is to ponder how the client might be able to use the information given to it and then guide the server through the process of deciding a client’s access to resources.
29.4 Our Approach to Confidentiality Management
While much of our previous work focused on security control in relational databases, our work discussed in this book focuses on extending this approach to social media data. The social network is augmented by an inference controller that examines the policies specified as ontologies and rules, and utilizes the inference engine embedded in the web rules language, reasons about the applications and deduces the security violations via inference. In particular, we focus on the design and implementation of an inference controller where the data is represented as RDF documents.
It should be noted that prior to the work discussed in this book, we designed and developed a preliminary confidentiality controller in 2005. Here, we utilized two popular semantic web technologies in our prototype called Intellidimension RDF Gateway and Jena (see [INTE] and [JENA]). RDF Gateway is a database and integrated web server, utilizing RDF and built from the ground up rather than on top of existing web servers or databases [RDF]. It functions as a data repository for RDF data and also as an interface to various data sources, external or internal, that can be queried. Jena is a Java application programming package to create, modify, store, query, and perform other processing tasks on RDF/XML documents from Java programs. RDF documents can be created from scratch or preformatted documents can be read into memory to explore various parts. The node-arc-node feature of RDF closely resembles how Jena accesses an RDF document. It also has a built-in query engine designed on top of RDFQL (RDF Query Language) that allows querying documents using standard RDFQL query statements. Our initial prototype utilized RDFQL while our current work has focused ion SPARQL queries.
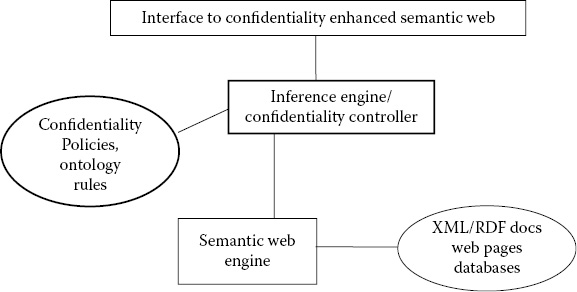
Using these technologies, we specify the confidentiality policies. The confidentiality engine ensures that the policies are enforced correctly. If we assume the basic framework, then the confidentiality engine will enforce the policies and will not examine security violations via inference. In the advanced approach, the confidentiality engine will include what we call an inference controller. While our approach has been to store the data in RDF, as the amount of data to be managed could become very large over the years, we need to apply the big data management technologies discussed in Chapter 7. Figure 29.5 illustrates an inference/confidentiality controller for the semantic web that has been the basis of our book.
29.5 Privacy for Social Media Systems
As discussed in Chapter 3, privacy is about protecting information about individuals. Furthermore, an individual can specify say to a web service provider the information that can be released about him or her. Social media systems are especially prone to privacy violations as the members post so much information about themselves. Therefore, such systems are prone to privacy attacks.
Privacy has been discussed to a great deal in the past, especially when it relates to protecting medical information about patients. Social scientists as well as technologists have been working on privacy issues. However, privacy has received enormous attention during the past year. This is mainly because of the advent of the web, the semantic web, counter-terrorism, and national security. For example, in order to extract information about various individuals and perhaps prevent and/or detect potential terrorist attacks, data mining tools are being examined. We have heard much about national security versus privacy in the media. This is mainly due to the fact that people are now realizing that to handle terrorism, the government may need to collect data about individuals and mine the data to extract information. Data may be in relational databases or it may be text, video, and images. This is causing a major concern with the civil liberties union ([THUR02], [THUR05]).
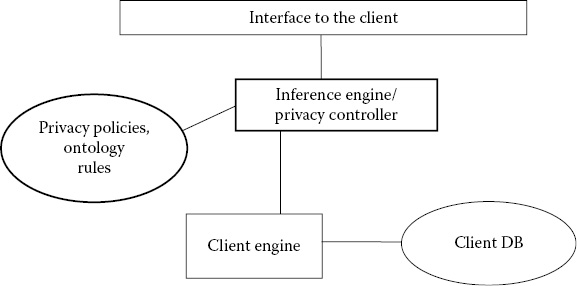
From a technology policy of view, a privacy controller could be considered to be identical to the confidentiality controller we have designed and developed. The privacy controller is illustrated in Figure 29.6. However, it is implemented at the client side. Before the client gives out information to a website, it will check whether the website can divulge aggregated information to the third party and subsequently result in privacy violations. For example, the website may give out medical records without the identity so that the third party can study the patterns of flu or other infectious diseases. Furthermore, at some other time, the website may give out the names. However, if the website gives out the link between the names and diseases, then there could be privacy violations. The inference engine will make such deductions and determine whether the client should give out personal data to the website.
As we have stated earlier, privacy violations could also result due to data mining and analysis. In this case, the challenge is to protect the values of the sensitive attributes of an individual and make public the results of the mining or analysis. This aspect of privacy is illustrated in Figure 29.7. A CPT framework should handle both aspects of privacy. Our work on privacy aspects of social networks addresses privacy violations that could occur in social networks due to data analytics. It should be noted that the amount of data collected about the individuals might grow rapidly due to better data collection technologies. This data may be mined and that could result in privacy breaches. Therefore, we need privacy enhanced big data analytics techniques to be integrated with our reasoning system.

29.6 Trust for Social Networks
Researchers are working on protocols for trust management. Languages for specifying trust management constructs are also being developed. In addition, there is research on the foundations of trust management. For example, if A trusts B and B trusts C, then can A trust C? How do you share the data and information on the semantic web and still maintain autonomy? How do you propagate trust? For example, if A trusts B say 50% of the time and B trusts C 30% of the time, then what value do you assign for A trusting C? How do you incorporate trust into semantic interoperability? What are the quality of service primitives for trust and negotiation? That is, for certain situations, one may need 100% trust while, for certain other situations, 50% trust may suffice [YU03].
Another topic that is being investigated is trust propagation and propagating privileges. For example, if you grant privileges to A, what privileges can A transfer to B? How can you compose privileges? Is there an algebra and/or calculus for the composition of privileges? Much research still needs to be done here. One of the layers of the semantic web is logic, proof, and trust. Essentially, this layer deals with trust management and negotiation between different agents and examining the foundations and developing logics for trust management. Some interesting work has been carried out by Finin et al. ([DENK03], [FINI02], [KAGA03]). For example, if given data A and B can someone deduce classified data X (i.e., A + B → X)? The inference engines will also use an inverse inference module to determine if classified information can be inferred if a user employs inverse resolution techniques. For example, if given data A and the user wants to guarantee that data X remains classified, the user can determine that B which combined with A implies X, must remain classified as well (i.e., A + ? → X; the question mark results with B). Once the expert system has received the results from the inference engines, it can conclude a recommendation and then pass this recommendation to the client or server who will have the option to either accept or reject the suggestion.
In order to establish trust, privacy, and confidentiality, it is necessary to have an intelligent system that can evaluate the user’s preferences. The system will be designed as an expert system to store trust, privacy, and confidentiality policies. These policies can be written using a web rules language with the foundations of the first-order logic. Traditional theorem provers can then be applied to the rules to check for inconsistencies and alert the user [ANTO08]. Once the user approves of all the policies, the system can take action and properly apply these policies during any transaction occurring on a site. Also, the user can place percentages next to the policies in order to apply probabilistic scenarios. Figure 29.8 gives an example of a probabilistic scenario occurring with a trust policy.

In Figure 29.8, the user sets the trust degree to 59%. Because the user trusts another person 59%, only policies 5–8 will be applied. Figure 29.9 shows some example policies. These example policies will be converted into a web rules language, such as the Semantics Web Rules Language [SWRL] and enforced by the trust engine. Figure 29.10 illustrates an integrated architecture for ensuring CPT for the semantic web. The web server as well as the client have trust management modules. The web server has a confidentiality engine, whereas client has a privacy engine. The inference controller is the first towards an integrated CPT system with XML, RDF, and web rules technologies. Some details of the modules are illustrated in Figure 29.11. Note that a version of an inference controller was discussed in Chapter 28.

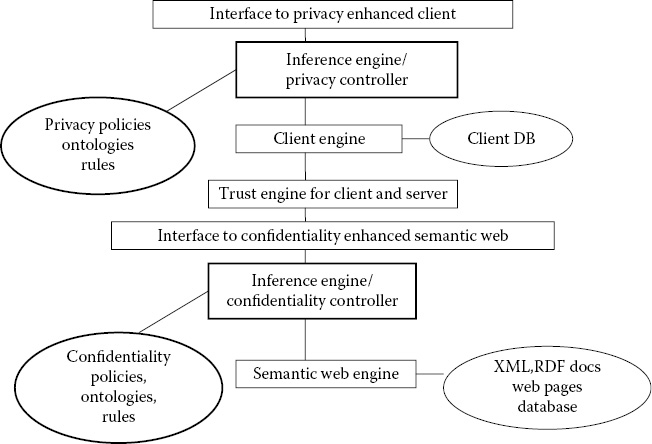

In Figure 29.11, ontologies, CPT policies, and credentials are given to the expert system such that the expert system can advise the client or server who should receive access to what particular resource and how these resources should further be regulated. The expert system will send the policies to the WCOP (web rules, credentials, ontologies, and policies) parser to check for syntax errors and validate the inputs. The information contained within the dashed box is a part of the system that is only included in the Advanced TP&C system. The inference engines (e.g., TIE, PIE, and CIE) will use an inference module to determine if classified information can be inferred.
29.8 CPT within the Context of Big Data and Social Networks
CPT are crucial services that must be built into a big data system such as a social network. Confidentiality policies will enable the members of the network to determine what information is to be shared with their friends in the network. Privacy policies will determine what a network can release about a member, provided these policies are accepted by the member. Trust policies will provide a way for members of a network to assign trust values to the others. For example, a member may not share all the data with his/her friends in the network unless he trusts the friends. Similarly, a network may enforce certain privacy policies and if one does not approve of these policies or not trust the network, he/she may not join the network. Therefore, we see that many of the concepts discussed in the previous sections are directly applicable to social networks.
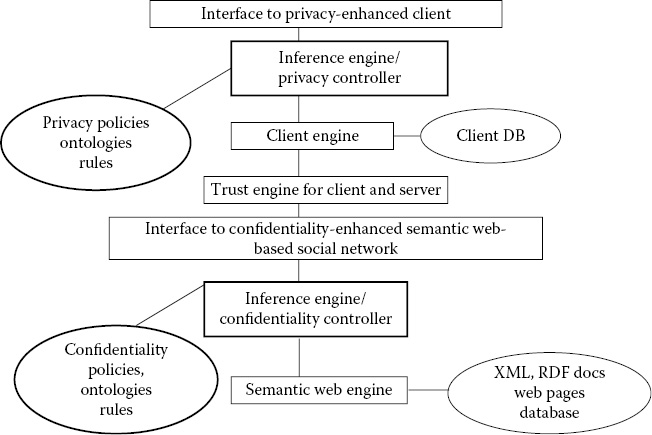
If the social networks are represented using semantic web technologies such as RDF graphs, then the reasoning techniques inherent in technologies such as RDF and OWL can be used to reason about the policies and determine whether any information should be shared with members. In addition to CPT policies, social networks also have to deal with information sharing policies, That is, member John of a network may share data with member Jane, provided Jane does not share with member Mary. We have carried out an extensive investigation of assured information sharing in the cloud and are extending this work to social media data and other big data systems. Figure 29.12 illustrates the adaptation of the CPT framework for big data systems such as social media data systems.
This chapter has provided an overview of CPT considerations with respect to inference with an emphasis on big data systems such as social media systems. We first discussed a framework for enforcing CPT for the semantic web. Next, we described our approach to confidentiality and inference control. Next, we discussed privacy for the semantic web. This was followed by a discussion of trust management as well as an integrated framework for CPT. Finally, we discussed how we can adapt the CPT framework for big data systems such as social media systems.
The discussion in this chapter provides a high-level discussion of CPT with semantic web technologies that may represent social network data or any type of big data system that can reason about the data. In Chapter 30, we will show the various components can be put together to design a big data system. There are many directions for further work. We need to continue with the research on CPT for the semantic web representing big data systems such as social media systems and subsequently develop the integrated framework for CPT. Finally, we need to formalize the notions of CPT and build a security model. That is, we need a unifying framework for incorporating confidentiality, privacy, trust, and information sharing policies for big data systems and some directions are provided in Chapter 30.
[AGRA00]. A. Rakesh and R. Srikant, “Privacy-Preserving Data Mining,” SIGMOD Conference, Dallas, TX, pp. 439–450, 2000.
[ANTO08]. G. Antoniou and F. V. Harmelen, A Semantic Web Primer, MIT Press, Cambridge, MA, 2008.
[DENK03]. G. Denker, L. Kagal, T. Finin, M. Paolucci, and K. Sycara, “Security for DAML Web Services: Annotation and Matchmaking,” In Proceedings of the International Semantic Web Conference, Sanibel Island, FL, pp. 335–350, 2003.
[FINI02]. T. Finin and A. Joshi, “Agents, Trust, and Information Access on the Semantic Web,” ACM SIGMOD Record, (4), 30–35, 2002.
[INTE]. Intellidimension, the RDF Gateway, http://www.intellidimension.com/.
[JENA]. Jena, http://jena.sourceforge.net/.
[KAGA03]. L. Kagal, T. Finin, A. Joshi, “A Policy Based Approach to Security for the Semantic Web,” In Proceedings of the International Semantic Web Conference, Sanibel Island, FL, 2003.
[KANT03]. M. Kantarcioglu, and C. Clifton, “Assuring Privacy When Big Brother is Watching,” In Proceedings of Data Mining Knowledge Discover (DMKD), San Diego, CA, pp. 829–93, 2003.
[RDF]. RDF Primer, http://www.w3.org/TR/rdf-primer/.
[SWRL]. Semantic Web Rules Language, 2004. http://www.w3.org/Submission/SWRL/.
[THUR02]. B. Thuraisingham, “Data Mining, National Security and Privacy,” ACM SIGKDD Explorations Newsletter, 4 (2), 1–5, December 2002.
[THUR05]. M. B. Thuraisingham, “Privacy Constraint Processing in a Privacy-Enhanced Database Management System,” Data and Knowledge Engineering, 55 (2), 159–188, 2005.
[THUR07]. B. Thuraisingham, N. Tsybulnik, A. Alam, “Administering the Semantic Web: Confidentiality, Privacy, and Trust Management,” International Journal of Information Security and Privacy, 1 (1), 129–134, 2007.
[W3C]. World Wide Web Consortium, www.w3c.org.
[YU03]. T. Yu, and M. Winslett, “A Unified Scheme for Resource Protection in Automated Trust Negotiation,” In Proceedings of IEEE Symposium on Security and Privacy, Oakland, CA, pp. 110–122, 2003.