
As stated in Chapter 31, Internet of things (IoT) systems generate massive amounts of data that have to be managed, integrated, and analyzed to extract useful patterns and trends. However, the pervasive nature of these devices is also prone to attack. That is, it is not only the device that is attacked but also the data that is generated and integrated possibly in a cloud. In Chapter 31, we discussed some of the security challenges for IoT devices in general. In this chapter, we will focus on a particular IoT system, that is, a connected smartphone system. These connected smartphone devices generate massive amounts of data and can be considered to be an IoT system. We discuss how big data analytics may be applied for detecting malware in smartphones.
The smartphone has rapidly become an extremely prevalent computing platform, with just over 968 million devices sold in 2013 around the world [GART14b], a 36% increase in the fourth quarter of 2013. In particular, Android devices accounted for 78.4% of the market share, an increase of 12% year-on-year. This popularity has not gone unnoticed by malware authors. Despite the rapid growth of the Android platform, there are already well-documented cases of Android malware, such as DroidDream [BRAD11] which was discovered in over 50 applications on the official Android market in March 2011. Furthermore, a study by [ENCK11] found that Android’s built-in security features are largely insufficient, and that even nonmalicious programs can (unintentionally) expose confidential information. A study of 204,040 Android applications conducted in 2011 found 211 malicious applications on the official Android market and alternative marketplaces [ZHOU12]. In addition, sophisticated Trojans have been reported recently [UNUC13], spreading via mobile botnets. Various researchers around the globe track reported security threats [SOPH14], wherein well over 300 Android malware families have been recorded.
On the other hand, smartphone apps on App Stores have been on a steady rise, with app download reaching 102 billion in 2013 [GART13] with a total revenue of $26 billion. This shows an ever increasing popularity in smartphone apps used in a multitude of applications including banking among others. In addition, private companies, military, and government organizations also develop apps to be used for processing and storing extremely strategic data including control jets, tanks, or machine guns. These applications make such apps targets for malicious attacks, where an attacker can gain information that negatively affects the peace and security of the users or the general population at large. This shows that it is prudent to empower app users with an ability to estimate the security thread of using an app in their smartphone. In addition, there is also a need to educate developers on various security threats and defense mechanisms and encourage them to incorporate these into the app design methods. A recent report [GART14c] suggested that by 2016, 25% of the top 50 banks would have an app. In addition, it is also reported in [GART14a] that 75% of mobile security breaches result from app misconfiguration.
To address the limitations of current secure mobile platforms, we have been conducting research as well as infrastructure development efforts in securing the connected smartphones for the past 6 years. In particular, we have designed and developed solutions for behavior-based intrusion detection/mitigation for mobile smartphones. In addition, we are also investigating privacy aspects for smartphones as well as integrating our secure mobile computing framework with the cloud. We are integrating the research in an experimental infrastructure for our students and developing a curriculum for them which will eventually be a part of an IoT education program.
The organization is as follows. Our approach is discussed in Section 32.2. The experimental evaluation efforts will be discussed in Section 32.3. The infrastructure we are developing is discussed in Section 32.4. Finally, our education program for connected smartphones will be discussed. The concepts discussed in this chapter are illustrated in Figure 32.1.

Behavioral analysis offers a promising approach to malware detection since behavioral signatures are more obfuscation resilient than the binary ones. Indeed, changing behavior while preserving the desired (malicious) functions of a program is much harder than changing only the binary structure. More importantly, to achieve its goal, malware usually has to perform some system operations (e.g., registry manipulation). Since system operations can be easily observed and they are difficult to obfuscate or hide, malicious programs are more likely to expose themselves to behavioral detection. This approach requires a database of specific behavioral signatures, but its size and the rate of increase of such a database are incomparably lower than those in the case of binary signatures. However, the behavioral detector has to be able to distinguish malicious operations from benign ones (executed by benign programs) which is often difficult. Moreover, maliciousness of an executed functionality can often be determined only by its context or environment. Therefore, the challenge of behavioral detection is in devising a good model of behavior which is descriptive enough to allow for discrimination of benign versus malicious programs and which can be tuned to the target environment.
In principle, there are two kinds of behavior detection mechanisms: misuse detection and anomaly detection. Misuse detection looks for specific behavioral patterns known to be malicious, while the anomaly-based approach responds to unusual (unexpected) behavior. The advantage of anomaly-based detection is in its ability to protect against previously unseen threats; however, it usually suffers from a high false positive rate. Misuse detection is usually more reliable in terms of detection performance (fewer false positives and often no false negatives) but it has two major drawbacks. First, defining a set of malicious patterns (signatures) is a time-consuming and error-prone task that calls for periodic updating, similarly to how binary signatures are used today. Second, it cannot detect any malicious code that does not expose known malicious behavior patterns and thus its capabilities to detect a zero day attack are limited. Consequently, it seems logical to combine both detection mechanisms thus resulting in a highly dependable intrusion detection systems (IDS) technology.
The main challenge of the approach is the development of the appropriate behavior models suitable for the task of dependable and efficient intrusion detection. Behavior analysis can be performed on the basis of system call data. To facilitate kernel-level operations, a computer issues system calls that being monitored and properly processed provide ample information for understanding the process behavior. However, system calls represent the lowest level of behavior semantics and mere aggregation of system calls has inherent limitations in terms of behavior analysis. Instrumental behavior analysis must involve all levels of the semantic pyramid, from its foundation to application program interface (API) functions and to its highest level, that is, functionality defined as a sequence of operations achieving well-recognized results in the programs environment. In our approach functionalities constitute the basis of the behavioral model.
We need to achieve the expressiveness of behavioral signatures, that is, crucial for the success of IDS in detecting new realizations of the same malware. Since most malware incidents are derivatives of some original code, a successful signature must capture invariant generic features of the entire malware family, that is, the signature should be expressive enough to reflect the most possible malware realizations. We also need to address possible behavioral obfuscation, that is, attempts to hide the malicious behavior of software, including the multipartite attacks perpetrated by a coordinated operation of several individually benign codes. This is an emerging threat that, given the extensive development of behavior-based detection, is expected to become a common feature of future information attacks. Finally, we need to develop an efficient model building process utilizing system call data and incorporating unsupervised learning (where no training is required) along with supervised learning (where training is required), as well as mathematically rigorous and heuristic data mining procedures. Some of the work we have carried with respect to big data analytics for malware detection in smartphones will be discussed next.
32.2.2 Behavioral Feature Extraction and Analysis
The main goal of behavior mining is to construct behavioral models that have a low false positive rate and a high detection rate. The traditional approach to generating behavioral models requires human effort and expertise which is an expensive, time-consuming, and error-prone process that does not provide any guarantee regarding the quality of the resultant models. Therefore, developing an automatic technique for building such models is a major goal for the cyber security community. An automated technique will not only reduce the response time to new attacks, but also guarantee more accurate behavioral models.
32.2.2.1 Graph-Based Behavior Analysis
Malware behavior modeling is a more effective approach than purely syntax-directed modeling. This is because although polymorphic and metamorphic obfuscations can defeat content-based signature detection techniques, they cannot easily defeat the behavior-based detection techniques as the behavior of malware is more difficult to obfuscate automatically. Specifications of malware behavior have long been generated manually which are both time and cost intensive. Graph-based behavior analysis is an effort to build malware specifications automatically. The basic approach followed here is to build a malware behavior specification from a sample of malicious and benign applications. A graph is generated for each executable in the sample, where each node in the graph represents an event (such as a system call) and the edges represent a dependency (such as a dataflow from one system call’s output to another’s input) between two events. We build upon the graph-based behavior analysis for detecting malicious executables [MASU11a]. The approach we use is supervised learning.
We also explore unsupervised learning to detect malware. Eberle and Holder. treat data as a graph and apply unsupervised learning to detect anomalies [EBER07]. They find the normative substructures of the graph and identify anomalies as a small X% difference from the normative substructure. Finding the best normative substructure in this case means minimizing the description length M, which is represented as
where G is the entire graph, S is the substructure being analyzed, DL(G|S) is the description length of G after being compressed by S, and DL(S) is the description length of the substructure being analyzed. The description length DL(G) of a graph G is the minimum number of bits necessary to describe G. This framework is not easily extensible to dynamic/evolving streams (dynamic graphs) because the framework is static in nature. Our work relies on their normative substructure-finding methods but extends it to handle dynamic graphs or stream data by learning from evolving streams. Recently we have tested this graph-based algorithm with stream analysis on insider threat data and observed better results relative to traditional approaches ([PARV11a], [PARV11b]). Therefore, we intend to apply both unsupervised and supervised learning in the graph-based technique.
32.2.2.2 Sequence-Based Behavior Analysis
Gathered data stream can be repeated sequences of events (i.e., system calls) of variable length. These repeated sequences of events could reveal the regular/normal behavior of an android application.
It is very important to identify sequences of events in an unsupervised manner and find the potential normative patterns/sequences observed within these sequences that identify the normal pattern. In order to achieve this, we need to generate a dictionary which contains any combination of possible potential patterns existing in the gathered data. Potential variations that could emerge within the data are caused/occurred by commence of new events, missing or modification of existing events, or reordering of events in the sequence.
One way to extract patterns having variable length is to preprocess and manually segment the data which is not very suitable with this continuous incoming flow of data.
Therefore, in our automated method, we consider how we can continually generate the possible patterns for the dictionary using a single pass. Another challenge would be the size of the dictionary that could be extraordinarily large in bulk as it contains any possible observed patterns. Hence, we address the above two challenges in the following ways. First, we extract patterns using single-pass algorithm (e.g., Lempel–Ziv–Welch (LZW) algorithm [WELC84]) to prepare a dictionary. Next, our goal would be to compress the dictionary by keeping the longest frequent set of patterns and discarding other patterns [CHUA11]. We use edit distance to find the longest patterns. This process is a lossy compression, but would be sufficient enough to handle the gathered data.
For example, suppose the sequences of system call traces are liftliftliftlift, where each unique letter represents a particular system call. The possible patterns in our dictionary would be li, if,ft, lif,ift, ftl, lift, iftl, ftli, and so on. Then, we extract the longest and frequent pattern “lift” from this dictionary while discarding the others. There could be many possible patterns.
Once, we identify the pattern “lift,” any X% (=%30 say) deviation from the original pattern would be considered as anomaly. Here, we use edit distance to identify the deviation.
32.2.2.3 Evolving Data Stream Classification
Model update (Figure 32.2) can be done in a number of ways. Since we have continuous flows of data, namely stream data, our techniques need to be adaptive in nature. In real-world data stream classification problems, such as malware applications, novel classes may appear at any time in the stream (e.g., a new intrusion). Traditional data stream classification techniques (supervised one) would be unable to detect the novel class until the classification models are trained with labeled instances of the novel class. Thus, all novel class instances go undetected (i.e., misclassified) until the novel class is manually detected by experts, and training data with the instances of that class is made available to the learning algorithm. For example, in case of malware detection, a new kind of android malware application might go undetected by a traditional classifier, but our approach should not only be able to detect the malware but also deduce that it is a new kind of malware.

This evolving nature creates several challenges in classifying the data. Two of the most widely studied issues with data stream classification are one-pass learning and concept-drift issues. One-pass learning is required because of limited resource (memory and processing power) and continuous delivery of the data stream. Concept drift occurs in dynamic streams and is approached in different ways by different techniques, all of which have the same goal: to keep the classification model up-to-date with the most recent concept ([MASU11b], [MASU11b], [MASU10], [SPIN08], [HULT01]).
Data stream classifiers can be broadly divided into two categories based on how they update the classification model, namely, single model incremental approaches [HULT01], and ensemble techniques. Ensemble techniques have been more popular than their single model counterparts because of their simpler implementation and higher efficiency [MASU11a]. Most of these ensemble techniques use a chunk-based approach for learning ([MASU11b], [MASU10], [SPIN08]), in which they divide the data stream into chunks, and train a model from one chunk. We refer to these approaches as “chunk-based” approaches. In our work we investigate both techniques to update models.
32.2.3 Reverse Engineering Methods
With only the binary executable of a program, it is useful to discover the program’s data structures and infer their syntactic and semantic definitions. Such knowledge is highly valuable in a variety of security and forensic applications. Although there exist efforts in program data structure inference, the existing solutions are not suitable for our targeted application scenarios. We have developed sophisticated reverse engineering techniques to automatically reveal program data structures from binaries [LIN10]. Our technique, called REWARDS, is based on dynamic analysis. More specifically, each memory location accessed by the program is tagged with a time-stamped type attribute. Following the program’s runtime data flow, this attribute is propagated to other memory locations and registers that share the same type. During the propagation, a variable’s type gets resolved if it is involved in a type-revealing execution point or “type sink.” More importantly, besides the forward-type propagation, REWARDS involves a backward-type resolution procedure where the types of some previously accessed variables get recursively resolved starting from a type sink. This procedure is constrained by the timestamps of relevant memory locations to disambiguate variables reusing the same memory location. In addition, REWARDS is able to reconstruct in-memory data structure layout based on the type information derived. We demonstrated that REWARDS provides unique benefits to two critical applications: memory image forensics and binary fuzzing for vulnerability discovery.
Machine learning-based approaches need to be complemented by a risk framework. Certain parameters need to be set based on real-life experiments. We believe that we can find optimal values for each parameter by running different simulations combined with a risk analysis framework. Essentially, for different domains, the cost of having a false positive and false negative could be different. In addition, software that is used for some critical tasks need to be thoroughly analyzed (e.g., a software that is accessing top secret data). On the other hand, we may not need to be as stringent if the software tested by our tool runs on unclassified data. This observation implies that for different use cases, we may need to set different parameter values. To create a risk-based parameter setting framework, we create an interface where a user could enter the information related to the software that is being tested by our tool. Based on the given information (e.g., what kind of data the software will be run on, whether it is sandboxed by a virtual machine while it is used), and our previous runs on real data, we come up with optimal parameters to minimize the risks for given software by adjusting the false positive and false negative rates of our tool. It should be noted that we have conducted extensive research on risk-based security analysis ([CELI07], [CANI10]) as well as related areas ([HAML06], [WART11]). We utilize this experience in developing the risk framework.
32.2.5 Application to Smartphones
With the prevalence of smartphones with computer-like capabilities, there are more platforms and devices subject to attack by malware. According to a study from IDC [U4], smartphone manufacturers shipped 100.9 million units in the last quarter of 2010, compared to 92.1 million units of PCs shipped worldwide. It is the first time in history that smartphones are outselling personal computers. The demand for smartphones is still continuing to rise and grow exponentially. The popularity and availability of smartphones running the Android operating system is driving further growth in the smartphone market. Sales of Android phones are projected to grow 50% over the next 4 years [U2].
As an open platform, Android is especially vulnerable to attack because there is no official verification of software’s trustworthiness. For example, unlike Apple’s official scrutinization process, Android applications can be uploaded without any check of their trustworthiness. Developers self-sign the applications without the intervention of any certification authority. Hence, malware and Trojan horses have already been spread through the Android market, and it is even possible to install applications from outside the Android marketplace [U1]. Jupiter Networks report that Android malware increases 400% as compared to summer 2010 [U3]. “Fake Player,” “Geinimi,” “PJApps,” and “HongToutou” are a few examples. A number of standard applications have been modified and the malware have been binded, packed, and spread through unofficial repositories. More than 50 infected Android applications were found in March of 2011 alone where all of them were infected with “DroidDream” trojan [U1] application.
Malicious applications have been spread across thousands of phones before detection. There is some work to detect those android malicious applications. Blasing et al. [BLAS10] use static analysis first and then dynamic analysis in a simulated environment. Enck et al. [ENCK10] monitor sensitive information on smartphones. Thus, they can track a suspicious third-party application that uses sensitive data as GPS location information or address book information. Portokalidis et al. [PORT10] propose a system where researchers can perform a complete malware analysis in the cloud using mobile phone replicas. Shabtai et al. [SHAB10] present a methodology to detect suspicious temporal patterns as malicious behavior, for anomaly detection on Android smartphones. This approach does not exploit behavior as features. There is a work based on behavior [BURG11]. This approach exploits clustering to detect malware. The detection algorithm is very simple and static in nature. Furthermore, none of these techniques is capable of detecting brand new malwares.
We are building on our prior research and development work [MASU12] and developing highly novel, innovative, and adaptive approaches for analyzing the Android applications. This approach allows malicious application to be detected by recognizing application anomalies based on supervised and unsupervised learning in constraint resources. In addition, we can detect brand new malware that can adapt and reinvent. Also, our goal is to collect the data generated and store them in the cloud and apply some of our BDMA techniques for malware detection and connected smartphones.
At the heart of our approach is the classification model (Figure 32.2). This model is incrementally updated with feature vector data obtained from new benign/malware applications. When a new benign executable or malware instance is chosen as a training example, it is analyzed and its behavioral and binary patterns are recorded. This recorded data will be stored in a temporal database that holds the data for a batch of N applications at a time. Note that the temporal database can be stored in the Android device itself in a lightweight way or at the server side. When a batch of data has been processed, it is discarded, and a new batch is stored. Each batch of data will undergo a feature extraction and selection phase. The selected features are used to compute feature vectors (one vector per executable). These vectors are used to update the existing classification model using an incremental learning technique. When an unknown application appears in the system, at first its runtime and network behavior (e.g., system call traces) are monitored and recorded. This data then undergoes a similar feature extraction phase and feature vector is created. This feature vector is classified using the classification model. Based on the class label, appropriate measures are taken.
We also complement our behavioral-based malware detection algorithms with reverse engineering techniques so that we can provide a compressive solution to the malware evolution problem.
Data acquisition is responsible for obtaining data from Android applications. Collected data is composed by basic device information, installed applications list, and the result of monitoring applications with system behavior monitoring tool including both control (such as system call traces) and data (such as API/system call arguments, the return values, the sent and received messages). Next it collects, extracts, and analyzes received information from the system control and data behavior log file, and stores in a temporal database. Finally, system behavior traces are processed to produce the feature vectors that are used for classification. In addition, we may extract some static features such as request numerous permissions onto various hardware devices, certain restricted system calls, and access to other applications and possible execution paths that an application can take using a control flow graph.
First, we apply the graph-based behavior analysis in a static setting with a fixed training set containing both benign and malicious applications. Then, we extend these analysis techniques to the stream environment.
32.2.5.3 Data Reverse Engineering of Smartphone Applications
While our behavior model is largely built on top of system call sequences (which is related to program control flow), the data aspect of an Android application is also crucial in our behavior model because data provides a more readable and verifiable view of a program. To this end, our framework also includes a data reverse engineering component. The basic idea for data reverse engineering is to extract the semantic information exported by an operating systems (OS) such as system call arguments and return values, and then use data flow analysis to capture the semantic data propagations. We have an earlier effort of data reverse engineering in x86 code, called REWARDS [LIN10], for the Linux platform. We believe REWARDS technique is general and can be applied to the Android platform. We are investigating the new challenges while porting it to Android, such as the program execution model has changed to Dalvik virtual machine, and in Android, it is no longer in x86 binary code and instead most applications are written in Java.
32.3 Our Experimental Activities
The purpose of the experiments is to identify which approaches are working, and to demonstrate and validate each improvement achieved. Therefore, we are performing experiments to evaluate the components developed. Furthermore, these experiments are being carried out as we complete the implementation of each component. In many cases, the experiments simply verify that we are improving the system with the new part.
We have collected the malware dataset from two sources, one is publicly available (VX Heavens—http://vx.netlux.org) and the other is a restricted access repository for malware researchers only (Project malfease—http://malfease.oarci.net/), to which we have access. VX Heavens contains close to 80,000 malware samples, and Project malfease also contains around 90,000 malware samples. Furthermore, these repositories are being enriched with new malware every day. VX Heavens also serves many malware generation engines with which we may generate a virtually infinite number of malware samples. Using these malware samples, we can easily construct a data stream such that new types of malware appear in the stream at certain (not necessarily uniform) intervals. Evaluation of the data occurs in either or both of the following ways:
1.We partition the dataset into two parallel streams (e.g., a 50–50 division), where one stream is used to train and update the existing classifier and the other stream is used to evaluate the performance of the classifier in terms of true positive, false positive, successful novel class detection rate, and so on. For example, one suitable partitioning simply separates the stream of odd-indexed members from the even-indexed ones.
2.A single, nonpartitioned stream may be used to train and evaluate as follows. The initial classification model can be trained from the first n data chunks. From the n + 1st chunk, we evaluate the performance of the classifier on the instances of the chunk (in terms of true positive, false positive, successful novel class detection, etc.) Then that chunk is used to update the classifier.
Below we discuss some of the systems we have developed and our initial evaluation. It should be noted that at present the evaluation is at the component stage. Our ultimate goal is to integrate the various components and carry out the evaluation of the system as a whole.
32.3.1 Covert Channel Attack in Mobile Apps
Mobile OS such as Android provide mechanisms for data protection by restricting the communication between apps within the device. However, malicious apps can still overcome such restrictions via various means such as exploiting the software vulnerability in systems or using covert channels for data transferring. In a recent paper [CHAN14], we have shown a systematic analysis of various resources available on Android for the possible use of covert channels between two malicious apps. We identified two new hardware resources, namely battery and phone call, that can also be used as covert channels. We also found new features to enrich the existing approaches for a better covert channel such as using the audio volume and screen brightness. Our experimental results show that high throughput data transmission can be achieved using these resources for covert channel attacks.
32.3.2 Detecting Location Spoofing in Mobile Apps
As the use of smartphones has increased, so has the presence of location-aware smartphone apps. Often, location data is used by service providers to personalize information and allow users to check into locations, among other uses. Therefore, it is in the best interests of app developers to determine whether reported locations are accurate. In light of this, we have designed taxonomy of location spoofing attacks, in which an attacker attempts to provide an app with fake location data. To defeat such an attack, we have designed a novel system that uses semantics analysis such as system property and velocity-based behavior analysis on a device to detect the presence of a location spoofing attack [GREE15]. Experimental results with a number of Android apps show that our approach is highly effective and has a very small overhead.
32.3.3 Large Scale, Automated Detection of SSL/TLS Man-in-the-Middle Vulnerabilities in Android Apps
Many Android apps use SSL/TLS to transmit sensitive information securely. However, developers often provide their own implementation of the standard SSL/TLS certificate validation process. Unfortunately, many such custom implementations have subtle bugs, have built-in exceptions for self-signed certificates, or blindly assert all certificates as valid, leaving many Android apps vulnerable to SSL/TLS man-in-the-middle attacks. In another recent work [SOUN14], we have implemented a system for the automatic, large-scale identification of such vulnerabilities that combines both static and dynamic analyses for identifying vulnerable apps using an active man-in-the-middle attack. We are conducting experimentation of the tools we have designed.
32.4 Infrastructure Development
We discuss two major components: (i) virtual laboratory development and (ii) curriculum development.
32.4.1 Virtual Laboratory Development
The lab would be accessible to all of its users, around the world. A web-based interface is provided and user account is password protected. A graphical user interface (GUI) is developed using Restful API. Initially, the project is set up a virtual lab accessible to students 24/7. The students can leverage the resources and services offered by the virtual lab to undertake academic projects related to android security and forensics. For example, the students can learn how to develop secure apps capable of detecting potential malicious activities by performing static and dynamic analysis in the virtual lab’s remote servers. Furthermore, the lab can facilitate mobile forensics courses by offering remote services such as forensic analysis of data acquired from the mobile hardware.
A typical scenario for using our system is as follows. A user can typically download an app onto a smartphone from an App Store, which provides numerous apps. In general, a student can either download an app or develop an app to be installed on a phone. The user then submits a request to analyze the app by logging onto our system. The APK file of the app is downloaded or submitted for analysis including static and dynamic analysis or for a data mining application, along with required information of the app. The system would perform the required operations and provide the result in terms of a report or an intractable interface, where the user can provide inputs for further analysis.
There are various challenges in developing such a system. These include requirement of high computational resources and other inherent issues of program analysis. There are two basic techniques in program analysis: static analysis and dynamic analysis. Each has its pros and cons. At a high level, static analysis is fast, scalable, complete but not precise, and dynamic analysis is precise but often very expensive. More specifically, with respect to the security analysis of Android programs, in static analysis the application is often decompiled and various heuristics are applied to determine if the application is malicious or vulnerable. Though static analysis is a powerful technique, it fails when dynamic code loading, asynchronous callbacks, or other runtime specific features are used. To tackle this problem, dynamic analysis is used. In dynamic analysis, the application is installed in a controlled environment—usually a modified version of an emulator or a device with customized OS—where the behavior of the application can be extracted at the system and at the network levels. Even though dynamic analysis promises to provide access to the applications runtime behavior, it is not without its shortcomings, especially when applied to GUI apps that are prevalent in the Android market.
The system extracts metadata from the APK file using static analysis and combines them with other information (raw data) to form a feature set, using a feature extractor. The feature is then used in a data mining algorithm based on the analysis desired by the user. The analysis is performed and a complete report is generated at the end for the user to view. This includes a rated decision to classify the app as a malware. The complete information as desired by the user can be used for further analysis or study regarding the app. This virtual lab would be then used by integrating it with cyber security courses, as shown in Figure 32.3. Our goal is to process user requests in real time or near time and support multiuser requests simultaneously. For this, we utilize our cluster (which is essentially a cloud) and utilize parallel processing (NoSQL systems). For example, Spark can be used to process requests. Spark has faster processing power than its counterpart such as Storm and Hadoop/MapReduce (see e.g., [SOLA14a], [SOLA14b], and [SOLA14c]).
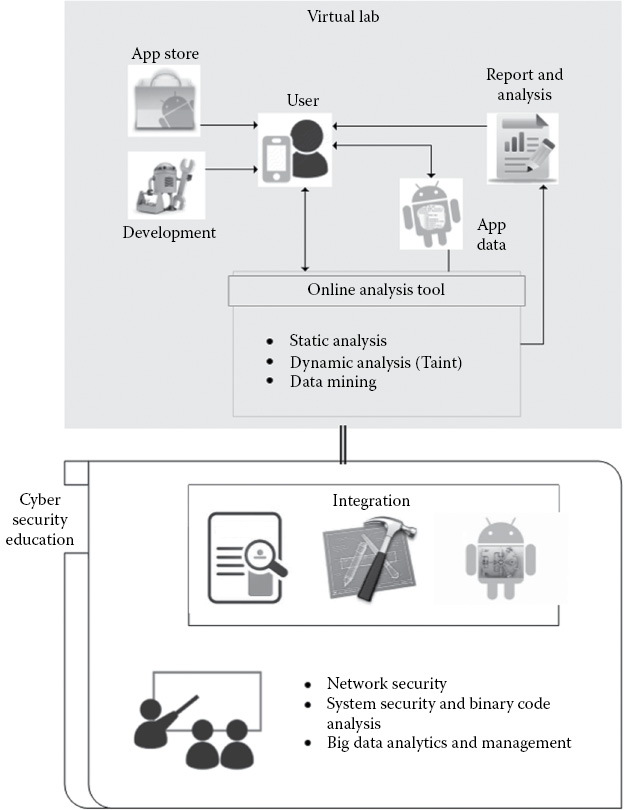
As evident, the online system serves parallel analysis requests. Such a deployment would require multiple emulator-based feature extraction (using dynamic analysis) and ensemble of stochastic models to be maintained. This would involve emulator and model management system that would be developed to handle these scenarios, extending our previous work on large-scale vulnerability detection techniques.
32.4.1.2 Programming Projects to Support the Virtual Lab
We are devising student programming projects to support the virtual lab. We provide an overview of two sample projects and a discussion of these projects. In particular, we first describe an automatic testing tool that can be used for large-scale user-input generation. Next, we discover a tool for addressing data leaks by viewing it as a transaction over the system state.
32.4.1.3 An Intelligent Fuzzier for the Automatic Android GUI Application Testing
The recent proliferation of mobile phones has led to many software vendors shifting their services to the mobile domain. There are >700,000 Android applications in the Google Play market alone with over 500 million activated devices [WOMA12]. On the other hand, software inevitably contains bugs (because of its complexity), some of which often lead to vulnerabilities. Identifying the buggy applications (i.e., apps.) in such huge Android market calls for new efficient and scalable solutions.
To get encouraging results out of dynamic analysis with Android apps, the user interface (UI) of the application has to be exercised in a way that all possible code paths are executed. An intuitive approach could work around this problem by either recording/replaying the user’s actual behavior or by manually exercising the UI elements. This shortcoming cripples the ability to perform large-scale dynamic analysis. Recently novel techniques have emerged where UI enumeration is performed and input is provided to the UI elements such that automated UI traversal is possible. This advancement enables large-scale dynamic analysis. But the new UI Automation approach still uses handcrafted input to the UI input elements like text boxes.
Essentially, for Android GUI app testing, the key challenge lies in how to simulate user interactions, which requires an understanding of what is being displayed on the screen and providing intelligent input. As an example, consider the login screen of a banking application. A typical login screen contains username and password text boxes, possibly a “remember me” check box, and a login button which submits the user’s credentials when clicked. The user typically provides input to these elements in this order, starting with the username and ending with tapping the login button. A useful UI automation system should be able to simulate this behavior without the need for human intervention or guidance.
After analyzing existing tools for UI automation, we have concluded we still require novel techniques. Google’s Monkey tool [GOOG1] cannot accurately simulate the controlled behavior of the user because it provides randomized UI events. Another existing UI automation framework is Robotium [ROBO] which is a popular tool used widely by Android developers for testing. This framework is tightly coupled with Android’s instrumentation framework which causes Robotium test scripts to be tightly coupled with the target applications. This makes the framework unsuitable as a generic UI automation solution as it requires a unique test script for each target application.
Therefore, our work aims to take the UI automation to the next level by integrating systems engineering approaches and novel data mining techniques to identify and understand the UI presented by the application and provide an appropriate input, thereby providing better coverage and usability than the existing methods. The UI automation fuzzier has two major goals: understanding the interface as it is displayed and providing an intelligent input to the application.
32.4.1.5 Understanding the Interface
The first step in automating the UI is to decompose the UI into its component elements. For each of these elements, the system extracts properties such as the coordinates that define its boundaries and what form of input (e.g., text or tap) it expects. With this information, the system crafts the appropriate input events and sends them to the application. To identify the Window’s elements and extract their properties, we utilize the Android ViewServer [GUY], an internal component of the Android application tooling framework. The ViewServer provides a set of commands that can be used to query the Android WindowManager [GOOG2], which handles the display of UI elements and the dispatch of input events to the appropriate element.
32.4.1.6 Generating Input Events
Generating intelligent input for the input fields in a displaying window has always been a challenging problem in the area of UI automation. All the existing approaches have taken the route of hardcoded or handcrafted input. We solve this problem by utilizing the state-of-the-art machine learning and data mining techniques, in a data-driven manner [SAHS12]. We provide the intelligent input for input field using semisupervised clustering and label propagation [MASU12]. In general, input fields are often tagged with a text label explaining the user about the input that they have to provide. For example, in a simple application, a text label “User Name” alongside the text input box is displayed in a typical user registration screen. Furthermore, another application may have a similar screen and the developer has given the input text label as “User ID.” Therefore, we expect the same input for input fields, “User Name” and “User ID.” For “Zipcode” and “Postal Code” fields, we also expect the same input. Here, we treat input field (“User name”) as data and input type (i.e., text pattern/integer pattern) as a class label.
To tackle this issue, (1) we need to group similar input fields together and (2) assign the same input (class label) for a group having the similar input fields. With regard to the first issue, we apply clustering algorithm (e.g., K-means) or semisupervised clustering algorithm. To measure similarity, we exploit edit distance between two input fields or external knowledge (Ontology-WordNet) [JIN03]. With respect to second issue, we apply a label propagation technique to provide input type as class label for input field.
32.4.1.7 Mitigating Data Leakage in Mobile Apps Using a Transactional Approach
To mitigate risks such as information leakage, we develop an oblivious sandbox that minimizes the leakage of sensitive input by conforming untrusted apps to predefined security policies, and also enhances usability and data security in the case of application updates. Most apps are proprietary and close-sourced (even intensively using native code) and thus arbitrarily store and transform sensitive information before sending it out. The approach works seamlessly and transparently with such apps by viewing app communication as a transactional process which coordinates access to shared resources. In particular, the vulnerability might be caused due to information leakage by an input method editor (IME) used in an app, or a bug may be introduced after an app update that may break critical functionality of the app and/or create a new vulnerability. For the case of a vulnerability based on user input, we first checkpoint the app’s state before a transaction involving an user input, monitor and analyze users’ input, and roll back the app’s state to the most recent checkpoint if there is potential danger of leaking the user’s sensitive input. In the case of app updates, a similar checkpoint and rollback functionality can be performed by checkpointing an app prior to applying an update, and rolling back if the update fails subsequent in-device testing or at the user’s request. Our system is built for Android and would be tested on publicly available apps from the Google Play Market. We perform experimental validation of our techniques to mitigate the leakage of sensitive input for untrusted apps, with the goal of incurring only small runtime overhead and little impact on user experience.
An example scenario involves the use of a third-party IME typically used to enhance user experience and efficiency in providing input. A typical usage of a third-party IME may involve the editor unintentionally leaking user inputs. This can have serious consequences in the security of confidential information. For example, consider a mobile app used by an Immigration and Customs Enforcement (ICE) agent/officer to obtain and update criminal records. If the officer uses such an IME while searching criminal records or inputting a new record, an attacker may be able to obtain confidential information.
Since security is evaluated with every request instead of only at installation time, information leaks/security breaches will be challenging. With regard to the example scenario, first, commercial IME applications extensively use native code, making it very difficult to understand how they log and process user input. Second, many of them use unknown proprietary protocols, which obscure the process of collecting and transforming user input. Finally, many IME applications use encryption. Therefore, we must eventually treat most IME applications as black boxes for current privacy-preserving techniques on mobile devices. Thus, end users are faced with the choice of trusting these IME applications completely and risking leakage of sensitive input or giving up the improved user experience and instead relying only on the default IME application.
At a high level, it seems that existing techniques such as taint tracking would be an appealing approach to precisely tracking sensitive input data and preventing it from being leaked. For example, TaintDroid ([BRAD11], [ENCK14], [ENCK11], [HORN11]) has been shown to be able to track sensitive user input and detect leakage. AppFence [HORN11] extended this system to block outgoing communications when sensitive data is about to be sent out. However, there are a number of additional challenges remaining. First, IME applications tend to make extensive use of native code, but TaintDroid currently does not track tainted data through native code. Second, TaintDroid only tracks the propagation through data flows. It is a well-known problem that such data-flow-based tracking cannot capture control-based propagation. In fact, many of the keystrokes are generated through lookup tables as reported in an earlier study. Third, sensitive information is often composed of a sequence of keystrokes. It is challenging to have a well-defined policy to differentiate sensitive from nonsensitive keystrokes in TaintDroid (and AppFence).
Figure 32.4 shows an overview of the experimental system that the students are developing to handle transactional methods in Android. The IME/Update app is installed in the user space which intercepts communication with client apps. The daemon controls communication between a client app with other apps within the device or with an external entity via the network. The policy engine can be used to extract communication policies involving data exchange or access. In particular, we can checkpoint the state of an application before each input transaction or a range of responses. User input/responses from the application can be analyzed to detect whether it is sensitive. The checkpoint or rollback logic is used to perform logical checks for each client application component in the case of a rollback. A kernel module installed in the kernel space is used for the checkpoint/rollback mechanism for saving and restoring the states of this app or client app as needed.
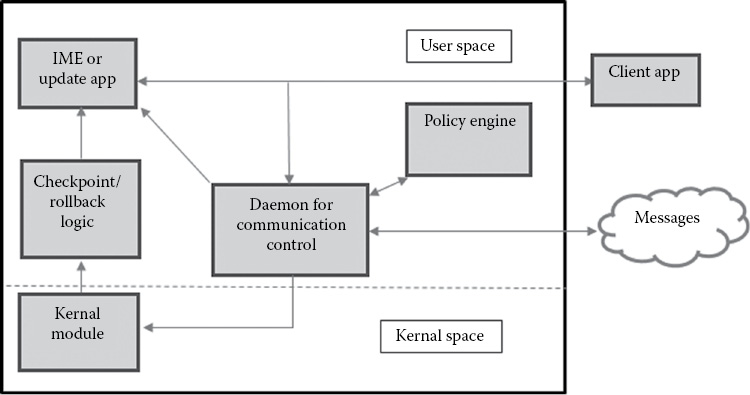
One approach is to use an oblivious IME sandbox that prevents IME applications from leaking sensitive user input. The key idea is to make an IME application oblivious to sensitive input by running the application transactionally, wiping off sensitive data from untrusted IME applications when sensitive input is detected. Specifically, we can checkpoint the state of the IME application before each input transaction. Then, user input can be analyzed by the policy engine to detect whether it is sensitive. If it is, the IME application state can be rolled back to the saved checkpoint, making it oblivious of what the user entered. Otherwise, the checkpoint can be discarded.
The policy engine is used for sensitive data identification based on handcrafted and mined rules to check vulnerability. A rule may identify typical sensitive data such as social security numbers or passwords. The policy engine may be used to design specific tests. To improve efficiency and avoid degrading user experience, we can augment on-device testing with off-device testing that leverages static and dynamic analysis and data mining techniques [SOUN14] to categorize apps as benign/invulnerable, unknown, or malicious/vulnerable. As a part of the data mining process, we plan to cluster the apps into groups based on their functionality. Using this automatically learned group behavior, any app that deviates from group behavior could be singled for more examination. In addition, when off-device testing determines that an app is benign/invulnerable, we can forgo on-device testing and discard the checkpoint. When off-device testing categorizes an app as malicious/vulnerable, we can immediately initiate a rollback. Only when off-device testing is inconclusive do we fall back to on-device testing.
32.4.2.1 Extensions to Existing Courses
In order to integrate the virtual lab with these courses, we would design various modules that would be integrated with its existing projects. An overview is provided in Figure 32.5. These modules are derived from our existing research and/or our virtual lab development. For example, the modules, “APK file analysis” and “taint analysis,” may be integrated our regular graduate course, “digital forensic analysis” and “system security and binary code analysis.” The “feature extraction” module is being integrated with our “big data management and analytics” course.
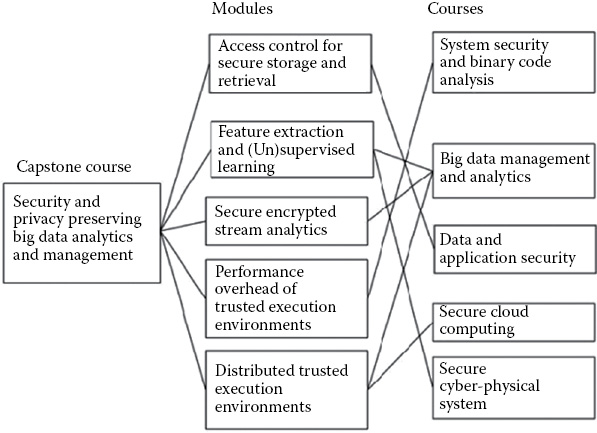
Below is a sample of our cyber security courses that are relevant to our wok in smartphones.
32.4.2.1.1 Systems Security and Binary Code Analysis
This course covers the practical aspect of computer systems, especially the low-level system details with the real system implementations. In particular, this course covers binary code analysis, OS kernel internals, Linker and Loader, and system virtualization. In support of this, this course comes with four hands-on labs. One is to design a taint analysis using dynamic binary instrumentation, the second one is to perform malware unpacking, the third one is to use library interposition to transparently harden software, and the last one is to use virtual machine introspection to monitor OS activities. These hands-on labs greatly enforce the concepts discussed in the class. This course would integrate the study of smartphone security analysis by studying program analysis on APK files to detect malware from binary data, Android taint analysis using existing tools, or development of new tools.
32.4.2.1.2 Network Security
This course covers both theoretical and practical aspects of network security. The course includes various hands-on activities to expose students to tools and techniques that are commonly used in penetration testing and securing computer networks and related technologies. We have also created a lab manual for this course as part of our current capacity building project. Students use John the Ripper to break passwords; use nmap and nessus to scan systems for known vulnerabilities; and use metasploit to exploit vulnerabilities in a system all done in an isolated environment in our Computer Networks and Security Instructional Lab (CNSIL) facilities. In addition, we conduct an in-class cyberwar class attack and defense activity. Finally, we conduct a 48-h data science competition where students work on solving various types of data science challenges. These hands-on sessions would also involve study of various attacks and defenses of Android apps over the Internet, including study of communication protocols with Android apps.
32.4.2.1.3 Data and Applications Security
This course provides a comprehensive overview of database security, confidentiality, privacy and trust management, data security and privacy, data mining for security applications, secure social media, secure cloud computing, and web security. In addition to term papers, students also carry out a programming project that addresses any of the topics covered in class. Typical student projects have included data mining tools for malware detection as well as access control tools for social media systems. More recent versions of the course focus on more extensive data privacy topics as well as on querying encrypted data. We are introducing a module on mobile data security and privacy as well as developing programming projects such as location privacy for mobile system as well as access control for mobile data.
32.4.2.1.4 Digital Forensics
This is an undergraduate course that covers various aspects of digital forensics. Topics include digital forensics basics such as evidence collection and analysis, crime scene reconstruction as well as database forensics, network forensics, and more recently modules on cloud forensics. Students are taken on a field trip to visit the North Texas FBI lab and are exposed to state-of-the-art techniques used by the FBI for forensics. Students also have practical experience with tools such as ENCASE. While we briefly cover mobile system forensics, we are introducing more in depth material on this topic with special emphasis on Android forensics.
32.4.2.1.5 Developing and Securing the Cloud
This course covers several aspects of cloud security. Modules include basics of cloud security such as securing infrastructure, platform, and application as a service, secure cloud data management, secure cloud data storage, and cloud forensics. Student programming projects include developing access control, modules for the cloud as well as modules for secure cloud query processing. We are introducing a unit on integrating cloud, mobile, and security technologies.
32.4.2.1.6 Big Data Analytics and Management
This course focuses on data mining and machine learning algorithms for analyzing very large amounts of data or big data. MapReduce and NoSQL systems are used as tools/standards for creating parallel algorithms that can process very large amounts of data. It covers basics of Hadoop, MapReduce, NoSQL systems (Cassandra, Pig, Hive, MongoDB, Hbase, BigTable, HBASE, and SPARK), Storm, large-scale supervised machine learning, data streams, clustering, and applications including recommendation systems, web, and security. We are introducing a module on large-scale feature extraction and learning to leverage the big data platform to perform parallel and distributed analysis on Android security threats to perform large-scale behavior or stochastic analysis for security threats from malicious apps.
32.4.2.1.7 Security for Critical Infrastructure
The Critical Infrastructure Security course introduces security for infrastructures, control systems and cyber-physical systems. This course covers the security of cyber-physical systems from a multidisciplinary point of view, from computer science security research (network security and software security), to public policy (e.g., the Executive Order 13636), risk assessment, business drivers, and control-theoretic methods to reduce the cyber risk to cyber-physical critical infrastructures. There is increasing interest to integrate secure mobile computing technologies with critical infrastructures [BARR14]. Mobile interfaces are being developed for automatic control experiments. These mobile devices should be secured so that the infrastructures are not attacked. We are introducing a module into our course that addresses this integration.
32.4.2.1.8 Language-Based Security
The aim of the course is to allow each student to develop a solid understanding of at least one of the following topics, along with a more general familiarity with the range of research in the field. This course provides students with an array of powerful tools for addressing software security issues include certifying, compilers, in-lined reference monitors, software fault isolation, address space randomization, formal methods, web scripting security, and information flow control. We are introducing a module on language-based security for mobile devices in general and Android in particular.
32.4.2.2 New Capstone Course on Secure Mobile Computing
Our capstone course is motivated by (a) research and development in secure mobile computing; (b) emerging secure mobile computing research, prototypes, products, and standards; and (c) the research and experimentation on Android malware detection and the results of our virtual. The modules created for all our cyber security courses are aggregated and will be taught as part of the capstone course. The topics covered include (i) security for mobile devices and the Android operating system, (ii) secure mobile data and identity management, (iii) mobile data privacy and privacy-aware mobile computing, (iv) secure networking for mobile devices, (v) malware detection for mobile devices, (vi) mobile forensics, (vii) integrating mobile devices for secure critical infrastructures, and (viii) language-based security for mobile devices. In addition, we discuss the various secure mobile system prototypes, products, and standards. Students carry out the programming projects that contribute toward the virtual laboratory.
This chapter has discussed malware detection in one type of IoT system, that is, connected smartphones. We discussed the security challenges for smartphones and then discussed our approach to malware detection for smartphones based on the Android operating system. Next, we discussed our virtual laboratory for experimentation. The technologies include Hadoop/MapReduce as well as Storm and Spark for designing scalable systems. We also discussed the course module we are introducing for security of smartphones. These include mobile system forensics as well as mobile data management security.
We believe that the future is in the integration of cyber security with cloud computing, mobile computing, and big data analytics. That is, scalable techniques for BDMA together with the cloud and mobile systems are essential for many applications. The challenge will be to secure such applications. The focus in this chapter is on malware detection. We need to design a comprehensive security framework for mobile systems that include access control, malicious code detection, and privacy protection.
[BARR14] C. Barreto, J.A. Giraldo, A.A. Cárdenas, E. Mojica-Nava, N. Quijano, “Control Systems for the Power Grid and Their Resiliency to Attacks,” IEEE Security and Privacy, 12 (6), 15–23, 2014.
[BLAS10] T. Blasing, A.-D. Schmidt, L. Batyuk, S.A. Camtepe, S. Albayrak, “An Android Application Sandbox System for Suspicious Software Detection,” In 5th International Conference on Malicious and Unwanted Software (Malware 2010) (MALWARE’2010), Nancy, France, 2010.
[BRAD11] T. Bradley, DroidDream Becomes Android Market Nightmare. March 2011, http://www.pcworld.com/article/221247/droiddream_becomes_android_market_nightmare.html.
[BURG11] I. Burguera, U. Zurutuza, S. Nadjm-Tehrani, “Crowdroid: Behavior-Based Malware Detection System for Android,” In Workshop on Security and Privacy in Smartphones and Mobile Devices 2011—SPSM 2011, ACM, Chicago, IL, pp. 15–26, October 2011.
[CANI10] M. Canim, M. Kantarcioglu, B. Hore, S. Mehrotra, “Building Disclosure Risk Aware Query Optimizers for Relational Databases,” In Proceedings of the VLDB Endowment, Singapore, Vol. 3, No. 1, September 2010.
[CELI07] E. Celikel, M. Kantarcioglu, B.M. Thuraisingham, E. Bertino, “Managing Risks in RBAC Employed Distributed Environments,” OTM Conferences, November 25–30, Vilamoura, Portugal, pp. 1548–1566, 2007.
[CHAN14] S. Chandra, Z. Lin, A. Kundu, L. Khan, “A Systematic Study of the Covert Channel Attacks in Smartphones,” 10th International Conference on Security and Privacy in Communication Networks, Beijing, China, 2014.
[CHUA11] S.L. Chua, S. Marsland, H.W. Guesgen, “Unsupervised Learning of Patterns in Data Streams Using Compression and Edit Distance,” In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, Vol. 2, pp. 1231–1236, 2011.
[EBER07] W. Eberle, L.B. Holder, “Anomaly Detection in Data Represented as Graphs,” Intell. Data Anal., 11 (6), 663–689, 2007.
[ENCK10] W. Enck, P. Gilbert, B.-G. Chun, L.P. Cox, J. Jung, P. McDaniel, A.N. Sheth, “Taintdroid: An Information-Flow Tracking System for Realtime Privacy Monitoring on Smartphones, In OSTI ’10: Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation, Berkeley, CA, pp. 1–6, USENIX Association, 2010.
[ENCK11] W. Enck, D. Octeau, P. McDaniel, S. Chaudhuri, “A Study of Android Application Security,” USENIX Security Symposium, San Francisco, CA, pp. 21–21, 2011.
[ENCK14] W. Enck, P. Gilbert, B.-G. Chun, L.P. Cox, J. Jung, P. McDaniel, A.N. Sheth, “TaintDroid: An Information Flow Tracking System for Real-Time Privacy Monitoring on Smartphones,” Communications of the ACM, 57 (3), pp. 99–106, 2014.
[GART13] Gartner. 2013. Gartner Says Mobile App Stores Will See Annual Downloads Reach 102 Billion in 2013. September. http://www.gartner.com/newsroom/id/2592315.
[GART14a] Gartner. Gartner Says 75 Percent of Mobile Security Breaches Will Be the Result of Mobile Application Misconfiguration. May, 2014. http://www.gartner.com/newsroom/id/2753017.
[GART14b] Gartner. 2014. Gartner Says Annual Smartphone Sales Surpassed Sales of Feature Phones for the First Time in 2013. February, 2014. http://www.gartner.com/newsroom/id/2665715.
[GART14c] Gartner. 2014. Gartner Says by 2016, 25 Percent of the Top 50 Global Banks Will have Launched a Banking App Store for Customers. June. http://www.gartner.com/newsroom/id/2758617.
[GREE15] G. Greenwood, E. Bauman, Z. Lin, L. Khan, B. Thuraisingham, “DLSMA: Detecting Location Spoofing in Mobile AppsDLSMA: Detecting Location Spoofing in Mobile Apps,” Technical Report, University of Texas at Dallas.
[GOOG1] Google. n.d. UI/Application Exerciser Monkey. http://developer.android.com/tools/help/monkey.html.
[GOOG2] Google. n.d. WindowManager. http://developer.android.com/reference/android/view/WindowManager.html.
[GUY] R. Guy. n.d. Local server for Android’s HierarchyViewer. https://github.com/romainguy/ViewServer.
[HAML06] K.W. Hamlen, G. Morrisett, F.B. Schneider, “Certified In-Lined Reference Monitoring on.NET. PLAS 2006,” In Proceedings of the 2006 Workshop on Programming Languages and Analysis for Security, PLAS 2006, Ottawa, Ontario, Canada, pp. 7–16, 2006.
[HORN11] P. Hornyack, S. Han, J. Jung, S. Schechter and D. Wetherall, “These Aren’t the Droids You’re Looking For, Retrofitting Android to Protect Data from Imperious Applications,” In CCS, Chicago, IL, pp. 639–652, 2011.
[HULT01] G. Hulten, L. Spencer, P. Domingos, “Mining Time-Changing Data Streams,” In KDD ‘01 Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, pp. 97–106, August 26–29, 2001.
[JIN03] Y. Jin, L. Khan, L. Wang, M. Awad, “Image Annotations by Combining Multiple Evidence & Wordnet,” In MULTIMEDIA ‘05 Proceedings of the 13th Annual ACM International Conference on Multimedia, Hilton, Singapore, pp. 706–715, November 6–11, 2005, ACM.
[LIN10] Z. Lin, X. Zhang, D. Xu, “Reverse Engineering Input Syntactic Structure from Program Execution and Its Applications,” IEEE Transactions on Software Engineering, 36(5), 688–703, 2010.
[MASU10] M.M. Masud, Q. Chen, L. Khan, C. C. Aggarwal, J. Gao, J. Han, B.M. Thuraisingham, “Addressing Concept-Evolution in Concept-Drifting Data Streams,” In Proceedings of ICDM ’10, Sydney, Australia, pp. 929–934.
[MASU11a] M.M. Masud, J. Gao, L. Khan, J. Han, B. M. Thuraisingham, “Classification and Novel Class Detection in Concept-Drifting Data Streams under Time Constraints,” IEEE TKDE, 23(1), 859–874, 2011.
[MASU11b] M.M. Masud, T.M. Al-Khateeb, L. Khan, C.C. Aggarwal, J. Gao, J. Han, B.M. Thuraisingham, “Detecting Recurring and Novel Classes in Concept-Drifting Data Streams.” In Proceedings of ICDM ’11, Vancouver, BC, pp. 1176–1181.
[MASU12] M.M. Masud, W. Clay, G. Jing, L. Khan, H. Jiawei, K.W. Hamlen, N.C. Oza, “Facing the Reality of Data Stream Classification: Coping with Scarcity of Labeled Data,” Knowledge and Information Systems, 33 (1), 213–244, 2012.
[PARV11a] P. Parveen, J. Evans, B. Thuraisingham, K.W. Hamlen, L. Khan, “Insider Threat Detection Using Stream Mining and Graph Mining,” In Proceedings of the 3rd IEEE International Conference on Information Privacy, Security, Risk and Trust (PASSAT 2011), October, Boston, MA, MIT Press, 2011.
[PARV11b] P. Parveen, Z.R. Weger, B. Thuraisingham, K. Hamlen, L. Khan, “Supervised Learning for Insider Threat Detection Using Stream Mining,” In Proceedings of 23rd IEEE International Conference on Tools with Artificial Intelligence (ICTAI2011), November 7–9, Boca Raton, FL (Best Paper Award), 2011.
[PORT10] G. Portokalidis, P. Homburg, K. Anagnostakis, H. Bos, “Paranoid Android: Versatile Protection for Smartphones,” In Proceedings of the 26th Annual Computer Security Applications Conference (ACSAC’10), pp. 347–356, New York, NY, ACM, 2010.
[ROBO] Robotium. n.d. Robotium, http://robotium.com/.
[SPIN08] E.J. Spinosa, A.P. de Leon, F. de Carvalho, J. Gama, “Cluster-Based Novel Concept Detection in Data Streams Applied to Intrusion Detection in Computer Networks,” In Proceedings of ACM SAC, pp. 976–980, 2008.
[SHAB10] A. Shabtai, U. Kanonov, Y. Elovici, “Intrusion Detection for Mobile Devices Using the Knowledge-Based, Temporal Abstraction Method,” Journal of System Software, 83, 1524–1537, August 2010.
[SAHS12] J. Sahs and L. Khan, “A Machine Learning Approach to Android Malware Detection,” Intelligence and Security Informatics Conference (EISIC), 2012 European. IEEE, Odense, Denmark, pp. 141–147, 2012.
[SOPH14] Sophos. “Security Threat Report,” Sophos, 2014. http://www.sophos.com/en-us/threat-center/medialibrary/PDFs/other/sophos-security-threat-report-2014.pdf.
[SOUN14] D. Sounthiraraj, J. Sahs, G. Greenwood, Z. Lin, L. Khan, “SMV-Hunter: Large Scale, Automated Detection of ssl/tls Man-in-the-Middle Vulnerabilities in Android Apps,” In Proceedings of the 19th Network and Distributed System Security Symposium. San Diego, CA, 2014.
[SOLA14a] M. Solaimani, L. Khan, B. Thuraisingham, “Real-Time Anomaly Detection Over VMware Performance Data Using Storm,” In The 15th IEEE International Conference on Information Reuse and Integration (IRI), San Francisco, CA, 2014.
[SOLA14b] M. Solaimani, M. Iftekhar, L. Khan, B. Thuraisingham, J.B. Ingram, “Spark-Based Anomaly Detection Over Multi-Source VMware Performance Data In Real-Time,” In Proceedings of the IEEE Symposium Series on Computational Intelligence (IEEE SSCI 2014), Orlando, FL, 2014.
[SOLA14c] M. Solaimani, M. Iftekhar, L. Khan, B. Thuraisingham, “Statistical Technique for Online Anomaly Detection Using Spark Over Heterogeneous Data from Multi-Source VMware Performance Data,” In the IEEE International Conference on Big Data 2014 (IEEE BigData 2014), Washington DC, 2014.
[U1] 50 Malware applications found on Android Official Market. http://m.guardian.co.uk/technology/blog/2011/mar/02/android-market-apps-malware?cat=technology&type=article.
[U2] Google Inc. Android market. https://market.android.com/.
[U3] Juniper Networks Inc, “Malicious Mobile Threats Report 2010/2011,” Technical Report, Juniper Networks, Inc., 2011.
[U4] R.T. Llamas, W. Stofega, S.D. Drake, S.K. Crook, “Worldwide Smartphone, 2011–2015 Forecast and Analysis,” Technical Report, International Data Corporation, 2011.
[UNUC13] R. Unuchek, The Most Sophisticated Android Trojan. June, 2013. https://securelist.com/blog/research/35929/the-most-sophisticated-android-trojan/
[WART11] R. Wartell, Y. Zhou, K.W. Hamlen, M. Kantarcioglu, B.M. Thuraisingham, “Differentiating Code from Data in x86 Binaries,” ECML/PKDD (3), 522–536, 2011.
[WELC84] T.A. Welch, “A Technique for High-Performance Data Compression,” Computer, 17 (6), 8–19, 1984.
[WOMA12] B. Womack, Google Says 700,000 Applications Available for Android. October, 2012. http://www.businessweek.com/news/2012-10-29/google-says-700-000-applications-available-for-android-devices.
[ZHOU12] Y. Zhou, Z. Wang, W. Zhou, X. Jiang, “Hey, You, Get Off of My Market: Detecting Malicious Apps in Official and Alternative Android Markets,” NDSS, 2012.