
3.3. An Entropy Interpretation
The previous section has shown that the EM algorithm is a powerful tool in estimating the parameters of finite-mixture models. This is achieved by iteratively maximizing the expectation of the model's completed-data likelihood function. The model's parameters, however, can also be obtained by maximizing an incomplete-data likelihood function, leading to an entropy interpretation of the EM algorithm.
3.3.1. Incomplete-Data Likelihood
The optimal estimates are obtained by maximizing
Equation 3.3.1
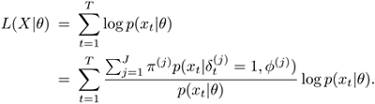
Define
![]()
such that ![]() . [3]
Eq. 3.3.1 becomes
. [3]
Eq. 3.3.1 becomes
[3] Note that h(j) (xt) equals the probability of xt belonging to the j-th cluster, given xt and the model—that is, h(j) (xt) = Pr(xt ∊ j-th cluster|xt, θ); it can be considered a "fuzzy" membership function.
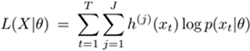
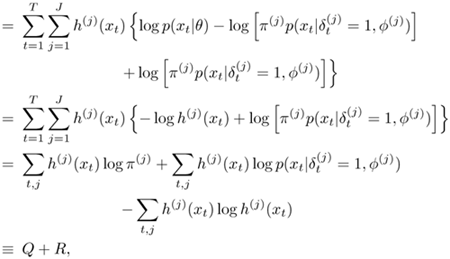
where the first two terms correspond to the Q-term in Eq. 3.2.4 and the second terms corresponds to the R-term in Eq. 3.2.5. This means the maximization of L can be accomplished by maximizing the completed-data likelihood Q, as well as maximizing an entropy term R.
Now, define ![]() so that the likelihood L(X|θ) can be expressed as:
so that the likelihood L(X|θ) can be expressed as:
Equation 3.3.2
![]()
In Eq. 3.3.2, the following three terms have different interpretations:
The first term can be interpreted as the entropy term, which helps induce the membership's fuzziness.
The second term represents the prior information. For each sample xt, this term grasps the influence (prior probability) of its neighboring clusters; the larger the prior probability, the larger the influence.
The third term is the observable-data term, where s(xt, φ(j)) represents the influence of the observable data xt on the total likelihood L.
3.3.2. Simulated Annealing
To control the inference of the entropy terms and the prior information on the total likelihood, one can introduce a temperature parameter σt similar to simulated annealing; that is,
Equation 3.3.3
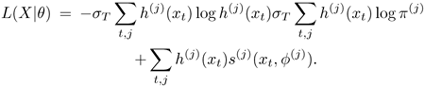
Equation 3.3.4
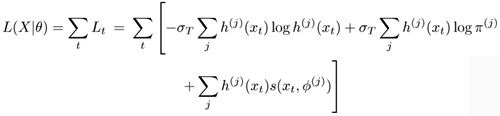
can be reformulated as the maximization of Lt under the constraint that
![]()
This is achieved by introducing a Lagrange multiplier λ such that
Equation 3.3.5
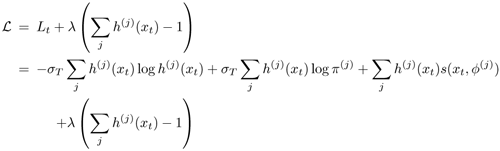
is to be maximized. To solve this constrained optimization problem, one needs to apply two different kinds of derivatives, as shown here:
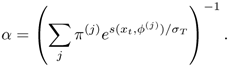
Hence, the optimal membership (Eq. 3.3.6) for each data is
Equation 3.3.9
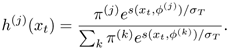
It is interesting to note that both Eqs. 3.3.9 and 3.2.14 have the same "marginalized" form. They can be connected by observing that ![]()
![]() in the case of mixture-of-experts. As an additional bonus, such a connection leads to a claim that the expectation of hidden-states (Eq. 3.2.14) provides an optimal membership estimation.
in the case of mixture-of-experts. As an additional bonus, such a connection leads to a claim that the expectation of hidden-states (Eq. 3.2.14) provides an optimal membership estimation.
The role of σT can be illustrated by Figure 3.6. For simplicity, only two clusters are considered and both π(1) and π(2) are initialized to 0.5 before the EM iterations begin. Refer to Figure 3.6(a), where the temperature σT is extremely high, there exists a major ambiguity between clusters 1 and 2 (i.e., they have almost equivalent probability). This is because according to Eq. 3.3.9, h(j)(xt) ≃ 0.5 at the first few EM iterations when σT → ∞. When σT decreases during the course of EM iterations, such ambiguity becomes more resolved—cf. Figure 3.6(b). Finally, when σT approaches zero, a total "certainty" is reached: the probability that either cluster 1 or 2 will approach 100%—cf. Figure 3.6(c). This can be explained by rewriting Eq. 3.3.9 in the following form (for the case J = 2 and j = 2):
Equation 3.3.10
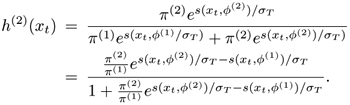
Figure 3.6. This figure demonstrates how the temperature σT can be applied to control the convergence of the EM algorithm.

In Eq. 3.3.10, when σT→ 0 and s(xt, φ(2)) > s(xt, φ(1)), h(2)(xt) ≃ 1.0, and h(1) (xt) ≃ 0.0. This means that xt is closer to cluster 2 than to cluster 1. Similarly, h(2)(xt) ≃ 0.0 and h(1)(xt) ≃ 1.0 when s(xt,φ(2)) < s(xt,φ(1)). Therefore, Eq. 3.3.10 suggests that when σT → 0, there is a hard-decision clustering (i.e., with cluster probabilities equal to either 1 or 0). This demonstrates that σT plays the same role as the temperature parameter in the simulated annealing method. It is a common practice to use annealing temperature schedules to force a more certain classification (i.e., starting with a higher σT and then gradually decreasing σT to a lower value as iterations progress).
3.3.3. EM Iterations
Next, the optimization formulation described in Section 3.2 is slightly modified (but causes no net effect). The EM problem can be expressed as one that maximizes L with respect to both (1) the model parameters θ = {θ(j), ∀j}and (2) the membership function {h(j)(xt),∀t and j}. The interplay of these two sets of variables can hopefully induce a bootstrapping effect facilitating the convergence process. The list that follows further elaborates on this.
- In the E-step, while fixing the model parameter {θ = {θ(j), ∀j}, one can find the best cluster probability h(j)(xt) to optimize L with the constraint
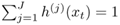 , which gave Eq. 3.3.9.
, which gave Eq. 3.3.9. - In the M-step, one searches for the best model parameter θ = {θ(j), ∀j} that optimizes L, while fixing the cluster probability h(j)(xt), ∀t and j.
3.3.4. Special Case: GMM
When θ defines a GMM, s(xt, φ(j)) becomes
Equation 3.3.11
![]()
Ignoring terms independent of h(j)(xt), μ(j) Σ(j), and π(j), the likelihood function in Eq. 3.3.2 can be rewritten as:
Equation 3.3.12
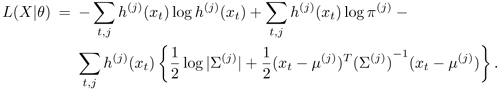
Note that the maximization of Eq. 3.3.12 with respect to θ leads to the same maximum likelihood estimtates as shown in Section 3.2.4.
For RBF- and EBF-type likelihood functions, the parameters that maximize s(xt, φ(j)) can be obtained analytically (see Section 3.2.4), which simplifies the optimization process. On the other hand, if a linear model (e.g. LBF) is chosen to parameterize the likelihood, an iterative method is needed to achieve the optimal solutions in the M-step. In other words, the EM algorithm becomes a double-loop optimization known as the generalized EM. For example, Jordan and Jacobs [168] applied a Fisher scoring method called iteratively reweighted least squares (IRLS) to train the LBF mixture-of-experts network.
3.3.5. K-Means versus EM
K-means [85] and VQ [118] are often used interchangeably: They classify input patterns based on the nearest-neighbor rule. The task is to cluster a given data set X = {xt; t = 1,..., T} into K groups, each represented by its centroid denoted by μ(j), j = 1, . . . , K. The nearest-neighbor rule assigns a pattern x to the class associated with its nearest centroid, say μ(i)). K-means and VQ have simple learning rules and the classification scheme is straightforward. In Eq. 3.3.12, when h(j)(xt) implements a hard-decision scheme—that is, h(j) (xt) = 1 for the members only, otherwise h(j)(xt) = 0—and ∑(j) = c2 I b∀j, where c is a constant and I is an identity matrix, the maximization of Eq. 3.3.12 reduces to the minimization of
Equation 3.3.13
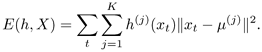
Therefore, the K-means algorithm aims to minimize the sum of squared error with K clusters.
The EM scheme can be seen as a generalized version of K-means clustering. In other words, K-means clustering is a special case of the EM scheme (cf. Figure 3.2). Table 3.3 summarizes the kinds of learning algorithms that the EM formulation Eq. 3.3.12 can produce.
| Kernel Type | ∑(j) | h(j)(xt) | Learning Algorithm |
|---|---|---|---|
| RBF | Diagonal | Hard | K-means with Euclidean distance |
| Soft | EM with Euclidean distance | ||
| EBF | Nondiagonal, symmetric | Hard | K-means with Mahalanobis distance |
| Soft | EM with Mahalanobis distance |