
3.1. Introduction
Learning networks are commonly categorized in terms of supervised and unsupervised networks. In unsupervised learning, the training set consists of input training patterns only. In contrast, in supervised learning networks, the training data consist of many pairs of input/output patterns. Therefore, the learning process can benefit greatly from the teacher's assistance. In fact, the amount of adjustment of the updating coefficients often depends on the difference between the desired teacher value and the actual response. As demonstrated in Chapter 5, many supervised learning models have been found to be promising for biometric authentication; their implementation often hinges on an effective data-clustering scheme, which is perhaps the most critical component in unsupervised learning methods. This chapter addresses a data-clustering algorithm, called the expectation-maximization (EM) algorithm, when complete or partial information of observed data is made available.
3.1.1. K-Means and VQ algorithms
An effective data-clustering algorithm is known as K-means [85], which is very similar to another clustering scheme known as the vector quantization (VQ) algorithm [118]. Both methods classify data patterns based on the nearest-neighbor criterion.
Verbally, the problem is to cluster a given data set X = {xt; t = 1, …, T} into K groups, each represented by its centroid denoted by μ(i), j = 1, …, K. The task is (1) to determine the K centroids {μ(1), μ(2), …, μ(K)} and (2) to assign each pattern xt to one of the centroids. The nearest-neighbor rule assigns a pattern x to the class associated with its nearest centroid, say μ(i).
Mathematically speaking, one denotes the centroid associated with xt as μt, where μt ∊ {μ(1), μ(2), …, μ(K)}. Then the objective of the K-means algorithm is to minimize the following sum of squared errors:
Equation 3.1.1
![]()
where || · || is the Euclidean norm.
Let Xk denote the set of data patterns associated with the k-th cluster with the centroid μ(k) and Nk denotes the number of patterns in the cluster Xk, where k = 1, …, K. The learning rule of the K-means algorithm consists of the following two basic steps.
Sometimes, the variance of the data cluster is also of great interest (e.g., in Gaussian mixture models). In this case, the variance can be computed as
Equation 3.1.4
![]()
3.1.2. Gaussian Mixture Model
The EM scheme can be seen as a generalized version of K-means clustering. The main difference hinges on the notion of a hard-versus-soft membership. A hard membership is adopted in the K-means algorithm, (i.e., a data pattern is assigned to one cluster only). This is not the case with the EM algorithm, where a soft membership is adopted, (i.e., the membership of each data pattern can be distributed over multiple clusters).
The necessity of using a distributed (i.e., soft) membership is the most conspicuous for a Gaussian mixture model (GMM). Given a set of N-independent and identically distributed patterns X(i) = {xt; t = 1, 2, …, N} associated with class ωi, the likelihood function p(xt|ωi) for class ωi is a mixture of Gaussian distributions; that is,
Equation 3.1.5

where Θr|i represents the parameters of the r-th mixture component; R is the total number of mixture components; p(xt|wi, Θr|i) ≡ N(x; μr|i, ∑r|i) is the probability density function of the r-th component; and P(Θr|i|wi) is the prior probability of the r-th component. Typically, N(x; μr|i, ∑r|i) is a Gaussian distribution with mean μr|i and covariance ∑r|i.
In short, the output of a GMM is the weighted sum of R-component densities. The training of GMMs can be formulated as a maximum likelihood problem, where the mean vectors {μr|i}, covariance matrices {∑r|i}, and mixture coefficients {P(Θr|i|wi)} are often estimated by the iterative EM algorithm—the main topic of the current chapter.
3.1.3. Expectation-Maximization Algorithm
The expectation-maximization (EM) algorithm is an ideal candidate for solving parameter estimation problems for the GMM or other neural networks. In particular, EM is applicable to problems, where the observable data provide only partial information or where some data are "missing"—see Figure 3.1(a). Another important class of parameter estimation that can be addressed by EM involves a mixture-of-experts—see Figure 3.1(b). In this class of problems, there are two categories of unknown parameters: one pertaining to the membership function of an expert (or cluster) and the other consisting of the unknown parameters defining individual experts. Let's use a Gaussian mixture model shown in Figure 3.1(b) as an example, where π(i) denotes the prior probability of expert j and where φ(i) = {μ(i), ∑(i)} denotes the parameters (mean and variance) of the expert. This chapter explains why the EM method can serve as a powerful tool for estimating these parameters. It also demonstrates how the EM algorithm can be applied to data clustering.
Figure 3.1. Parameter estimation by EM. (a) EM for general missing data problems, where θ is the nonstructural parameters to be estimated and Z is the set of missing data. (b) EM for hidden-state problems in which the parameter θ can be divided into two groups:  and
and 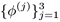 , where π(i) represents the prior probability of the j-th expert and φ(i) defines the density function associated with the j-th expert.
, where π(i) represents the prior probability of the j-th expert and φ(i) defines the density function associated with the j-th expert.

The EM algorithm is a very general parameter estimation method in that it is applicable to many statistical models, for example, mixture-of-experts (MOE), Gaussian mixture models (GMMs), and vector quantization (VQ). Figure 3.2 depicts the relationship among EM, MOE, GMM, and VQ. In particular, the figure highlights the fact that VQ is a special case of GMM, which in turn is a special case of the more general mixture-of-experts. More important, EM is applicable to all of these models.
Figure 3.2. Diagram depicting the relationship among EM, MOE, GMM, VQ and the class of problems known as missing- and partial-data problems.

The classic EM algorithm can be dated back to Dempster, Laird, and Rubin's paper in 1977 [74]. It is a special kind of quasi-Newton algorithm with a searching direction having a positive projection on the gradient of log-likelihood. Each EM iteration consists of two steps—Estimation (E) and Maximization (M). The M-step maximizes a likelihood function that is refined in each iteration by the E-step. Interested readers can refer to the references [74, 168, 297, 350]
One important feature of the EM algorithm is that it can be applied to problems in which observed data provide "partial" information only or when artificially introducing some information (referred to as "hidden"-state information hereafter) can greatly simplify the parameter estimation process. Figure 3.3 illustrates the concept of hidden and partial data. In Figure 3.3(a), all data (x1 to x7) are known.
Figure 3.3. One-dimensional example illustrating the concept of (a) hidden-state, (b) partial-data, and (c) combined partial-data and hidden-state. In (a) the information regarding the cluster membership of xt is hidden; in (b) y is partial in that its exact value is unknown; and in (c) data xt provide partial information only because none of their exact values are known. The cluster membership information is also hidden.

Let's assume that there are two clusters in the observed data. Although all data constituting the two clusters are observable, one does not know exactly to which cluster each of these data belongs. Lacking this hidden membership information results in a complicated parameter estimation procedure. The estimation procedure, however, can be greatly simplified if this membership information is assumed to be known. For example, if the cluster identities of x1 to x7 in Figure 3.3(a) were known, finding the cluster means is reduced to computing the mean of individual clusters separately. Figure 3.3(b) illustrates the idea of partial data. Unlike Figure 3.3(a), the partial-data problem in Figure 3.3(b) contains uncertain data y because y can be equal to 5.0 or 6.0. As a result, the true value of y is unobservable whereas those of xl to x4 are observable. The EM algorithm can solve this partial-data problem effectively by computing the expected value of y. Figure 3.3(c) illustrates the case in which cluster membership information is hidden and only partial information is available. The problem can be viewed as a generalization of the problems in Figure 3.3(a) and Figure 3.3(b). A new type of EM called doubly-stochastic EM is derived in Section 3.4 to address this kind of general problem. Numerical solutions for the problems in Figure 3.3 are provided in later sections.
The concepts of hidden and partial data have been applied to many scientific and engineering applications. For instance, in digital communication, the receiver receives a sequence consisting of +1's and — 1's without knowing which bit in the sequence is a +1 and which bit is a —1. In such cases, the state of each bit constitutes the missing information. In biometric applications, a MOE is typically applied to model the features of an individual. Each expert is designed to model some of the user-specific features. In such cases, the contribution of individual experts constitutes the hidden information.
EM has been shown to have favorable convergence properties, automatical satisfaction of constraints, and fast convergence. The next section explains the traditional approach to deriving the EM algorithm and proving its convergence property. Section 3.3 covers the interpretion the EM algorithm as the maximization of two quantities: the entropy and the expectation of complete-data likelihood. Then, the K-means algorithm and the EM algorithm are compared. The conditions under which the EM algorithm is reduced to the K-means are also explained. The discussion in Section 3.4 generalizes the EM algorithm described in Sections 3.2 and 3.3 to problems with partial-data and hidden-state. We refer to this new type of EM as the doubly stochastic EM. Finally, the chapter is concluded in Section 3.5.