
6.1. Introduction
Multi-layer networks are perhaps the simplest and most popular supervised learning model and can be adopted for most biometric authentication applications. Structurally, a multi-layer network has full connectivity, as illustrated in Figure 6.1(a). More precisely, all hidden nodes of one lower layer are fully connected to all nodes in its immediate subsequent layer. In other words, the model adopts a flat network structure such that all synaptic weights of a layer are lumped together in one supernetwork. This type of network is also termed "all-class-one-network" (ACON) [186].
Figure 6.1. Different types of architectures for feed-forward neural networks: (a) ACON structure, (b) class-based, and (c) expert-based grouping structure.
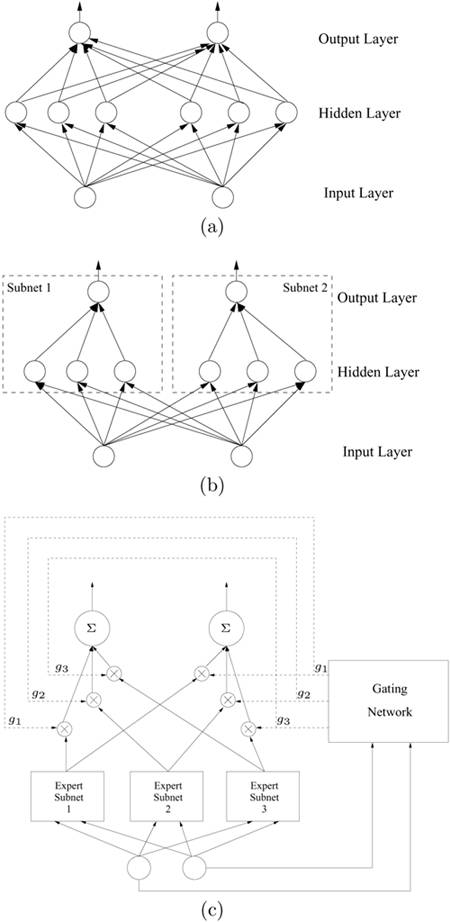
During the training phase, the fully connected network must be trained to simultaneously satisfy the specification given by all teachers. This results in two undesirable consequences. First, the number of hidden units required to meet the specification tends to become very large, especially for complex decision boundaries. Second, for every training pattern, all the synaptic weights must be trained. As a result, the training process is potentially influenced by conflicting signals from different teachers. Thus, the convergence rate of a fully connected multi-layer model degrades drastically with respect to network size, and the training time required may become excessively long.[1]
[1] Note that this problem can be partially alleviated by restricting one group of neurons to be responsible for one class only, as exemplified by the RBF/EBF network shown in Figure 5.6.
A more flexible and effective structure is a modular network built on many smaller modules. "An information processing network is said to be modular if the computation performed by the network can be decomposed into two or more modules (subsystems) that operate on distinct inputs without communicating with each other" [128]. The modular architecture follows the "divide-and-conquer" principle, solving a complex computation task by dividing it into simple subtasks and integrating the individual results in a postprocessing layer.
There are two prominent types of modular architecture: class and expert-based.
Class-Based Modular Networks. The goal of a machine learning model is to determine the class to which an input pattern best belongs. Therefore, it is natural to use class-based modules as the basic partitioning units. In a class-based modular model, one subnet is designated to one pattern class, as illustrated in Figure 6.1(b). Each subnet specializes in distinguishing its own class from the others, so the number of hidden units is usually small. (This type of structure is also referred to as "one-class-one-network" (OCON) [186].) The design of class-based modular networks is briefly introduced in Section 6.2 and is covered in greater detail in Chapter 7.
Expert-Based Modular Networks. Another prominent type of modular structure is the expert-based modular model, shown in Figure 6.1(c), in which an individual module reflects one local expert's subjective viewpoint on how to distinguish different classes. In this type of structure, each subnet is a local classifier working only on local regions within the entire pattern space. The gating network is responsible for integrating the results from local classifiers and reaching a final decision. A typical example of such modular networks is the mixture-of-experts (MOE), illustrated in Section 6.3.
The two modular network types are similar in that both divide a complex classification problem into simpler subproblems and adaptively incorporate the results from individual modules into the final decision. The difference in the two structures is that the division used in the class-based structure is pattern class oriented, whereas the structure used in the expert-based networks is pattern space oriented.
Ultimately, the information made available by the functional modules in a modular network must be globally integrated to reach a final decision or recommendation. A hierarchical structure provides a systematic framework to integrate or fuse information from various local modules. Section 6.4 provides a comprehensive analysis of several important variants of hierarchical network structures. In particular, one prominent hierarchical model, the so-called hierarchical mixture-of-experts (HME), is explored in this chapter.