
6.2. Class-Based Modular Networks
An important goal of pattern recognition is determining to which class an input pattern best belongs. Therefore, it is natural to consider class-level modules as the basic partitioning units, where each module specializes in distinguishing its own class from the others. Consequently, the number of hidden nodes designated to each class tends to be very small. The class-level modules are adopted by the OCON network. In contrast to expert-level partitioning, this OCON structure facilitates a global (or mutual) supervised training scheme. In global interclass supervised learning, any dispute over a pattern region by (two or more) competing classes can be effectively resolved by resorting to the teacher's guidance. Such a distributed processing structure is also convenient for network upgrading when there is a need to add or remove memberships. Finally, such a distributed structure is especially appealing to the design of the RBF networks.
6.2.1. Class-Based OCON Structure
The most popular class-based modular networks are generally based on the OCON-type structure. One prominent example of the class-based grouping structure is the Gaussian mixture model (GMM) classifier. Figure 6.2 depicts the architecture of a K-class classifier in which each class is represented by a GMM. Gaussian mixture models make use of semiparametric techniques for approximating probability density functions (pdf). The output of a GMM is the weighted sum of R component densities, as shown in Figure 6.2. Given a set of N independent and identically distributed patterns X(i) = {Xt; t = 1, 2, …, N} associated with class wi, the class likelihood function p(xt|wi) for class wi is assumed to be a mixture of Gaussian distributions, that is,
Equation 6.2.1
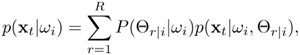

where Θr|i represents the parameters of the r-th mixture component, R is the total number of mixture components, p(xt|wi), Θr|i) ≡ N(x; μr|i Σr|i) is the probability density function of the r-th component, and P(Θr|i|wi) is the prior probability (also called a mixture coefficient) of the r-th component. Typically, N(x; μr|i Σr|i) is a Gaussian distribution with mean μr|i and covariance Σr|i.
The training of GMMs can be formulated as a maximum-likelihood problem, where the mean vectors {μr|i}, covariance matrices {Σr|i} and mixture coefficients {p(xt|wi), Θr|i)} are typically estimated by the EM algorithm (see Chapter 3). More specifically, the parameters of a GMM are estimated iteratively by[2]
[2] To simplify the notation, wi in Eqs. 6.2.2 through 6.2.4 has been dropped.
Equation 6.2.2
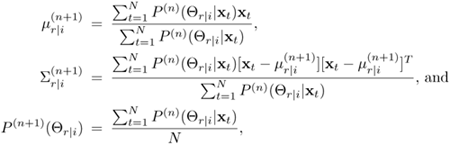
where n denotes the iteration index, p(n) (Θr|i|Xt) is the posterior probability of the r-th mixture (r = 1, …, R), and T denotes matrix transpose. The posterior probability can be obtained by Bayes's theorem, yielding
Equation 6.2.3

Equation 6.2.4
![]()
where D is the input dimension.
Unlike ACON, where an output node depends explicitly on all hidden nodes' outputs, the output of a GMM described before depends only on the hidden nodes of the corresponding class. This may restrict the classifier's ability to discriminate input patterns. One possible way of avoiding the complexity of ACON without sacrificing the modularity of the class-based grouping structure is to allow connections between the output nodes and all hidden nodes but to keep the hidden nodes class dependent. One typical example for this kind of structure is the multiclass RBF/EBF networks mentioned in Section 5.4. However, training time of this type of network is longer than that of the GMMs because connection weights from all hidden nodes must be trained for each output node.
6.2.2. ACON versus OCON Networks
Pandya and Macy [268] compared the performance of the ACON and OCON structures in handwritten character recognition. The authors observed that the OCON model achieves better training (99.5% vs 94%) and generalization (87% vs. 82%) accuracies, yet it requires only one-fourth of ACON's training time (cf. Table 6.1). Wang [369] uses an OCON model on computer-aided diagnosis for breast cancer and reports excellent experimental results.
| Training Accuracy | Generalization Accuracy | Training Time | |
|---|---|---|---|
| ACON | 94.0% | 82.0% | 1.00 |
| OCON | 99.5% | 87.0% | 0.25 |
One can argue that compared to the ACON structure, the OCON structure is slow in retrieving time when the number of classes is very large. This is not entirely true. As mentioned earlier, when the number of classes is large; the number of hidden neurons in the ACON structure also tends to be very large; therefore, ACON is also slow. Since the computation time in either an OCON or an ACON structure increases as the number of classes grows, a linear increase of computation time (i.e., OCON) can be expected. In fact, for a neural network-based recognition system, the recognition time is usually just a small portion of the entire system time and it will not affect system performance too much, even if the class number grows very large. Take the 200-person PDBNN face recognition system (see Chapter 8) as an example. For a 320 x 240 grayscale image, the entire recognition process (including preprocessing, detection, localization, feature extraction, and recognition) takes about one second. In this one-second system time, recognition (the retrieving) only takes 100ms, which is only one-tenth of the system time. The retrieving time will become 50% of the system time when the number of people in the database exceeds 2,000. In this case, the system time becomes two seconds, which is still fast enough for most security applications.