
6.5. Biometric Authentication Application Examples
There are a number of examples in which a MOE has been successfully applied to face and speaker authentication systems. For example, in Gutta et al. [124], the mixture-of-experts is implemented based on the divide-and-conquer modularity principle, taking fully into account the granularity and locality of information. The proposed MOE consists of ensembles of local RBF experts, and a gating network is implemented by inductive decision trees and support vector machines (SVMs). The gating network is responsible for deciding which expert should be used to determine classification output. The learning model was successfully applied to pose classification and gender and ethnic classification of human faces.
In Zhang and Guo [401], a modular structure built on autoassociative RBF modules was applied to the XM2VTS and ORL face database and reportedly achieved satisfactory face recognition rates. Kuritaa and Takahashib [193] applied MOE to face recognition, in which viewpoint-dependent classifiers (experts) were independently trained based on facial images captured from different angles. During the recognition phase, classifier outputs from different viewpoints were combined by a gating network. Experiments were conducted on recognizing the face of 10 individuals, each taken from 25 different angles. Given a facial image taken at a particular angle, one of the 25 viewpoint classifiers could be properly selected. Nevertheless, a mixture of classifiers seemed to outperform a single classifier.
The HME model has been applied to system identification [167], speech recognition [373], motion estimation [375], face recognition, and speaker recognition. In the latter case, a modified hierarchical mixture-of-experts (HME) architecture was applied to text-dependent speaker identification [54]. The expectation-maximization (EM) algorithm (see Chapter 3) was adopted to train the HME model. A novel gating network was introduced to help incorporate instantaneous and transitional spectral information into text-dependent speaker identification. The authors further extended the modified HMEs to the fusion of diverse speech features—including different orders of LPCCs, delta LPCCs, MFCCs, and delta MFCCs (see Section 2.6.1)—in a speaker identification task [53]. The idea is based on the understanding that no unique speech feature is highly superior to others for all kinds of speech. Therefore, it is reasonable to expect that a probabilistic fusion of diverse features should achieve a better performance than a single feature. The fusion is carried out by dividing N expert networks into K groups for K-diverse features so that networks in the same group receive the same feature vector, while expert networks in different groups receive different feature vectors. Likewise, there are K gating networks, each of which receives a different set of feature vectors. The outputs of the gating networks are N-component weighting vectors used for weighing the contribution of the N expert networks. Simulation results demonstrate that using an HME to fuse different features achieves better performance than using an HME on a single feature or on a composite of features.
There are many other ways of generalizing the global hierarchical structure to integrate information from various local modules or from different sensors. Several successful face and speaker verification systems that apply the class-based OCON modular networks are proposed in Chapter 7. In Chapters 7 through 9, several enhanced hierarchical architectures are shown to be effective for numerous biometric applications—even for those applications with complex decision regions. More important, the hierarchical structure lends itself to a natural extension of fusion architectures amenable to multimodality and/or multisample sensor fusion. This is illustrated in Chapter 10.
Problems
The ACON and OCON differ significantly in the total number of synaptic weights. For convenience, all subnets of OCON are assumed to have a uniform size, say k. The number of hidden units in the ACON supernetwork is denoted as K. We denote the input dimension and output dimension as n and N respectively. Verify the following analyses.
When the number of outputs N is relatively small with respect to n, the ratio between the numbers of ACON weights and OCON weights is
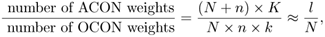
where
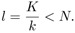
Therefore, ACON should have fewer weights, and the two numbers of weights are compatible if K ≈ N × k.
When N is very large (compared with n), the ratio becomes
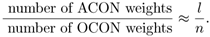
When N is very large, it is plausible that
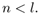
Therefore, OCON should have an advantage in terms of the number of weights used.
Design an MOE model to classify the two distinctive regions shown in Figure 6.4. It is required that the model make proper use of two linear experts depicted in the figure.
A hierarchical neural network of the experts-in-class architecture has eight inputs, four outputs, and two experts.
Draw a flow graph of this network.
State the conditions under which the experts-in-class architecture of the network degenerates to the EBF-based classifier shown in Figure 5.6.
For the retrieval phase of the network in (b), determine the computational complexity in term of MACs (multiplier-accumulations).
Repeat (a) and (b) if the network has a classes-in-expert architecture.
Construct a four-input and two-output hierarchical network with three levels
based on the experts-in-class architecture using two experts per class.
based on the classes-in-expert architecture, assuming three experts are used.
Compare the expert-based versus class-based modular networks in terms of overall computation costs.
Identify plausible application scenarios such that the expert-based modular networks hold a clear computational advantage over class-based models.
Conversely, describe possible scenarios under which the class-based models could become more advantageous than the expert-based models.
There are three learning paradigms for neural networks: (1) supervised learning, (2) unsupervised learning, and (3) combined supervised/unsupervised learning. Identify which learning paradigm would be most accurate in describing the following neural models:
EM
SVM
LBF multi-layer network
RBF multi-layer network
MOE
HME
Give a brief justification for each case.
Design some new variants of hierarchical networks by incorporating as many as possible of the following design features:
Use of unsupervised learning paradigms such as principle components, K-means/EM clustering, and other competition-based learning rules.
Use of supervised learning paradigms such as reinforced/antireinforced learning and positive versus negative training strategies.
Soft versus hard memberships (i.e., soft vs. hard decision) in local levels.
Use of prior information.