
8.5. PDBNN Face Recognition System Case Study
A PDBNN-based face recognition system was developed through a collaboration between Siemens Corporate Research, Princeton, and Princeton University [188, 208—210]. The total system diagram is depicted in Figure 8.7. All four main modules— face detector, eye localizer, feature extractor, and face recognizer—were implemented on a Sun Spare 10 workstation. An RS-170 format camera with 16mm, f1.6 lens was used to acquire image sequences. The S1V digitizer board digitized the incoming image stream into 640x480 8-bit grayscale images and stored them into the frame buffer. The image-acquisition rate was approximately 4 to 6 frames per second. The acquired images were downsized to 320x240 for the following processing [212].
Figure 8.7. System configuration of the face recognition system, which acquires images from a video camera. The face detector determines whether there are faces inside the images, and the eye localizer indicates the exact coordinates of both eyes. The coordinates are passed to a facial feature extractor to extract low-resolution facial features for the face recognizer.
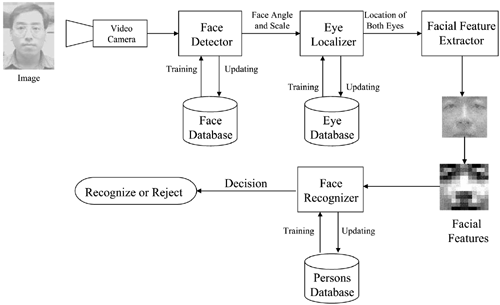
Figure 8.7 shows that the processing modules were executed sequentially. A module was activated only when the incoming pattern passed the preceding module (with an agreeable confidence level). After a scene was obtained by the image-acquisition system, a quick detection algorithm based on binary template matching was applied to detect the presence of a properly sized moving object. A PDBNN face detector was then activated to determine the presence of a human face. If positive, a PDBNN eye localizer was activated to locate both eyes. A subimage (approximately 140×100) corresponding to the face region was then extracted [212]. Finally, the feature vector was fed into a PDBNN face recognizer for recognition and subsequent verification.
This method is applicable under reasonable variations of pose and lighting and is very robust against large variations in facial features, eye shape, presence of eyeglasses, and cluttered backgrounds [207]. The algorithm took only 200ms to find human faces in an image with 320×240 pixels on the Sun workstation. For a 320×240 pixel facial image, the algorithm took 500ms to locate two eyes. In the face recognition stage, the computation time was linearly proportional to the number of persons in the database. For a 200-person database, it took less than 100ms to recognize a face. Because of the inherent parallel and distributed processing nature of a DBNN, this technique can be easily implemented via specialized hardware for realtime performance.
8.5.1. Face Detection and Eye Localization
The training patterns of the PDBNN face detector and eye localizer were from a set of manually annotated facial images. Using these annotated coordinates, the 12×12 facial feature vector was extracted from the original facial image by the method described in Section 8.5.2. In operation mode, the face detector was activated when a moving object was detected from the video stream. A multiresolution window search was applied, and at each searching step the 12×12 feature vector was extracted and fed into the PDBNN face detector. A confidence score was produced by the PDBNN, indicating the system's confidence in the detection result. The presence of a face was declared if the score was above a predefined threshold. The network has consistently and reliably determined actual face positions, based on experiments performed on more than 1,000 testing patterns.
After the face detection phase, a PDBNN eye localizer was applied to a face image to locate the left and right eyes. Figure 8.8 shows an example of a detected face and the search windows for eye localization. Because the locations of both eyes were used to normalize face size and reorient the facial image, the detection result requires high precision. One prerequisite is that the pattern resolution used for the eyes is much higher than that used for faces. The proposed technique is insensitive to small changes in head size, face orientation (up to approximately 30%), and eyeglass style. It is also insensitive to partial occlusion by specular lens reflection.
8.5.2. Facial Region
Based on the given location of left and right eyes, a facial region—eyes, eyebrows, and nose—was extracted. An example is shown in Figure 8.9(a). Such a facial region—consisting of eyes and nose, but excluding mouth—provides distinctive facial features and also offers stability against different facial expressions, hair styles, and mouth movement. Hairline and mouth are suitable for secondary facial features; compare to Section 8.5.7.
Feature normalization and resolution reduction are important tasks for the creation of facial features. Two kinds of features were used for face recognition: intensity and edge. Pixel intensities were reconditioned by histogram modification techniques and edges were obtained by Sobel filtering. These two feature vectors were fed into two PDBNNs. The final recognition result was the fusion of the outputs of these PDBNNs. Intensities and edges in the facial region were normalized (to a range of 0 and 1) to compensate for changing illumination. The normalized and reconditioned (e.g., 140×100) images were then reduced to coarser (e.g., 14×10) feature vectors. The advantages of adopting lower-resolution facial features are (1) alleviating the curse of dimensionality, (2) reducing computational cost and storage space, and (3) increasing tolerance of location errors incurred by previous face detection and eye localization steps. Figure 8.9 shows an example of such extracted features.
8.5.3. Frontal View Faces
The experiment was conducted on three image databases: the SCR 80×20 database, the ARPA/ARL FERET database, and the ORL database.[3] The SCR 80×20 database consists of 80 people of different race, age, and gender and has 20 images for each person. (If a person wears glasses, 10 of the images were taken with glasses and 10 without.) All images were taken under natural indoor conditions with uniform backgrounds. The facial orientations are roughly between -15 and 15 degrees. In many images, the person's head is tilted up to 15 degrees. A training data set was created by using four images per person (two with eyeglasses and two without, if the person wore eyeglasses). The testing image set included 16 images per person—1,280 images total. For all images, the face detector always correctly detected the center of the face (i.e., 100% success rate). Eye localization is a more difficult task than face detection, in particular when eyeglasses are present. The eye is typically 20 pixels wide and 10 pixels high. Among the 1,280 images, there were 5 images in which the eye localizer could not locate the eyes within the displacement tolerance of 5 pixels. For the remaining 1,275 images (in which the eyes were successfully located), the PDBNN face recognizer achieved a 100% recognition rate.
The ARPA/ARL FERET database contains 304 individuals, each having two frontal view images. The variation between the two images is much larger than those of SCR 80×20 and SCR 40×150 in terms of illumination, size, and facial expression. Phillips [274] achieved a 97% top-one identification rate on a preselected 172 faces from the FERET database. Moghaddam and Pentland [251] reported a 99% recognition rate on 155 preselected faces using a PCA-based eigenface method. In this experiment, because the confidence scores on the face detector and eye localizer reflect the accuracy of the detected pattern position, the images whose confidence scores were above the threshold were selected. Among the 304 × 2 = 608 images, 491 images passed both the face detector and eye localizer (success rate = 80.8%). Two hundred individuals passed both frontal view images; therefore, their images were used in the face recognition experiment; one image per person was used for training and the other for testing. The face recognition results are shown in Table 8.5.
| Training Accuracy | Testing Accuracy | |
|---|---|---|
| Probabilistic DBNN | 97.0% | 99.0% |
| Traditional DBNN | 100.0% | 96.0% |
| Multi-layer perceptron | 99.5% | 87.5% |
Under reasonably high training accuracy (97%), PDBNN achieved a higher recognition rate (99%) than traditional DBNN (96%). MLPs were also used to implement the face recognizer, but their performance was inferior to both types of DBNN. The recognition results of this experiment do not imply that the PDBNN face recognizer has superior performance to the eigenspace approach [251] (99% for 155 people) because some of the images chosen may not be selected by the PDBNN face detector and eye localizer. Still, three conclusions can be drawn from these experimental results: (1) the PDBNN face recognizer can recognize up to 200 people with only one training pattern per person, (2) the face detector and eye localizer can help choose recognizable images automatically, and (3) PDBNN has better recognition performance than multi-layer perceptrons.
An experiment was also conducted on the face database from the Olivetti Research Laboratory in Cambridge, UK (the ORL database). The database contains 10 different images of 40 different people with variations in facial expression (open/closed eyes, smiling/nonsmiling), facial details (glasses/no glasses), scale (up to 10%), and orientation (up to 20 degrees). An HMM-based approach was applied to this database and a 13% error rate was achieved [329]. The eigenface algorithm of Turk and Pentland [356] reported an error rate around 10% [195, 329]. In Samaria [333], a pseudo two-dimensional HMM method was used and achieved 5% at the expense of long computation time (4 minutes/pattern on a Sun Spare II). Lawrence et al. [195] used the same training and test set size as Samaria did and used a combined neural network (self-organizing map and convolutional neural network) to perform the recognition. This scheme spent 4 hours training the network and less than 1 second recognizing one facial image—the error rate was 3.8%. The PDBNN-based system reached similar performance (4%) but with a much faster training and recognition speed (20 minutes for training and less than 0.1 second for recognition). Both approaches were run on a SGI Indy. Table 8.6 summarizes the ORL database's performance.
| System | Error Rate | Classification Time | Training Time |
|---|---|---|---|
| PDBNN | 4% | < 0.1 seconds | 20 minutes |
| SOM + CN | 3.8% | < 0.5 seconds | 4 hours |
| Pseudo 2D HMM | 5% | 240 seconds | n/a |
| Eigenface | 10% | n/a | n/a |
| HMM | 13% | n/a | n/a |
8.5.4. Presence of Intruder Patterns
It is crucial for a recognition system to have the ability to reject intruders. An experiment was conducted to investigate the false acceptance and false rejection of the face recognition system. Among the 80 persons in the frontal-view database, 20 were chosen as "known persons" and 40 as "intruders." The remaining 20 individuals served as "negative examples" for network training. The training data sets were formed by randomly choosing two images per person from the database and then generating 50 virtual training patterns (cf. Section 8.5.6) from each image. Both the known person group and negative training set have 20 x 2 x 50 training patterns. The test sets were formed by selecting four images from each person. There were 20 x 4 test patterns from the known persons and 40x4 patterns from the intruders. If a test pattern is from a known person but is rejected by the network, the pattern is falsely rejected. If it's accepted but categorized to the wrong identity, the pattern is misclassified. If the pattern is from an intruder but is misrecognized to a known person, this pattern is falsely accepted.
The performance of probabilistic DBNNs, traditional DBNNs [192], and multilayer perceptrons (MLPs) were compared. The number of clusters (or hidden neurons) that generated the best performance were chosen. There were two clusters for each subnet in either probabilistic or traditional DBNNs and 30 hidden neurons in the MLPs. The thresholds were adjusted so that all three networks had zero false rejection and misclassification rates [195]. The FARs are shown in Table 8.7. As mentioned in Section 7.5.2, likelihood density generates more locally conserved decision regions than posterior probability, so the probabilistic DBNN achieved a lower FAR than the traditional DBNN and MLP, whose outputs were proved to converge to posterior probabilities [311, 324]. Using negative training examples significantly reduced the false acceptance rate. This effect can be observed in all three networks.
| W/o Negative Examples | W/ Negative Examples | |
|---|---|---|
| Probabilistic DBNN | 13.75% | 8.13% |
| Traditional DBNN | 33.75% | 22.5% |
| Multi-layer perceptron | 33.75% | 12.5% |
8.5.5. Invariance Assurance
To understand the performance of the PDBNN face recognizer under the influence of different variation factors, an experiment was conducted on a face database of 55 known persons. The variation of this training set is similar to that in the IM66 database (five different head orientations, four different lighting conditions, and three expressions; see Section 8.5.7). Four PDBNNs were trained on different subsets of the training data, and were evaluated on a test set containing many variations that were not found in the training set (e.g., different head orientations, facial expressions, outdoor lighting, spotlight, heavy shadows, etc.). The variation is larger than that in the FERET database or the ORL database. Figure 8.10 depicts the ROC curves of the four PDBNNs—the PDBNN trained by the complete set achieved the best performance.
Figure 8.10. PDBNN face recognition experiment in which four PDBNNs were trained on the four different training data sets depicted here. The test set consisted of images of 55 known persons and 100 intruders, and the results show that the PDBNNs are insensitive to facial expression but sensitive to lighting variation.

The performance of the PDBNN trained by the set without expression patterns was close to the best performance because the facial region chosen for feature extraction was not sensitive to facial expressions. The figure shows that performance deteriorates rapidly when the training patterns in one illumination condition are missing (dotted line), especially for those test images taken in an outdoor lighting environment. (All of the training patterns were taken under indoor lighting conditions.) The experimental results imply two directions of improvement for the PDBNN recognition system. First, although PDBNNs are immune to variations, such as facial expression, head size, and head orientation, performance varies under different lighting conditions. Second, current illumination normalization procedures (e.g., histogram normalization, edge preserving filtering) need to be improved.
8.5.6. Training Pattern Generation
The training pattern generation scheme for PDBNNs has the following three main aspects.
Virtual training patterns. To ensure sufficient diversity of real facial images in the training set, the algorithm took the acquired sensor image and transformed it in various ways to create additional training exemplars called virtual training patterns. As many as 200 virtual training patterns were generated from one original pattern by applying various affine transformations (e.g., rotation, scaling, shifting) and mirroring processes. The robustness of the trained network was consistently improved with the use of a virtual training set.
Positive and negative training patterns. Not all virtual training patterns were considered to be good face or eye patterns. If a virtual pattern was slightly perturbed from the original exemplar pattern, it was included in the positive training set. On the other hand, if the perturbation exceeded a certain threshold (predefined empirically), the virtual pattern was included in the negative training set. When training PDBNNs, positive patterns were used for reinforced learning, and negative patterns were used for antireinforced learning.
Runtime negative pattern generation. During the training phase, the PDBNN— while still under training—could be used to examine the whole image database every k epochs. If the network falsely detected a face (eye), that particular subimage was added to the negative training set.
8.5.7. Hierarchical Face Recognition System
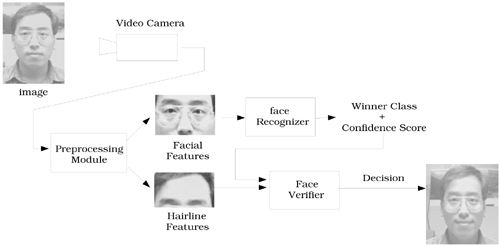
The PDBNN face recognizer described in the preceding sections can be extended to a hierarchical recognition system in order to increase recognition accuracy. One example appears in Figure 8.11. A face verifier was cascaded with the face recognizer. Possible candidates of verifier input are facial regions with not as much discriminating information in the eye-nose region, such as hairline or mouth area. In this system, the forehead/hairline region was captured and downsampled to a 12×8 image before being fed to the face verifier, which was another PDBNN classifier. Its function was to verify/reject the decision of the primary recognizer. Because the hairline (forehead) region is smoother than the eye-nose region, it is easier to normalize lighting effects in this area. Therefore, the influence of lighting variation on final recognition results was reduced by the presence of the hairline verifier.
Figure 8.11. Hierarchical information processing system based on PDBNN. Primary features are from the facial region, and hairline features are used as a supporting verifier.
The verification scheme is as follows. After the PDBNN verifier was trained, an auxiliary data structure called the similarity list was constructed for each object class. The similarity list of class j records the IDs of all classes in the database that appear to be similar to class j from the face verifier's viewpoint. In other words, if the highest score of a class k training pattern comes from the j-th subnet, j is then recorded into class k's similarity list. The construction process of the lists is completed when all of the training patterns in the known-person database have been presented to the system. After the similarity lists were constructed, the following rules were used to verify the face recognizer's decisions.
If the highest confidence score of the face recognizer is from subnet i but is below the recognizer threshold, the input pattern is recognized as class i if (a) the highest score of the face verifier is also from subnet i, and (b) the score exceeds the verifier's threshold. Otherwise, the pattern is rejected.
If the highest confidence score of the face recognizer is from subnet i and is above the recognizer threshold, the input pattern is recognized as class i if (a) the highest score of the face verifier is from one of the classes on the similarity list of class i, and (b) the score exceeds the verifier's threshold. Otherwise, the pattern is rejected.
A face database (IM66) containing images of 66 individuals was used for the experiment. There were more variations in this database than in SCR 80×20 and SCR 40×150. For each person, the database has images of five different head orientations, four illumination conditions, and two images of three facial expressions (smile, frown, and surprised), thus yielding a total of 4 × 5 + 3 × 2 = 26 images per person. A 38-class hierarchical PDBNN face recognition system was built. This system successfully recognized the 38 persons in the positive training data set and rejected the remaining 28 who were considered intruders.
To handle the high feature dimension (13×9 for the face recognizer and 12×8 for the face verifier), EBF was applied for both face recognizer and face verifier as the discriminant function. The K-means algorithm was used for LU learning. For both face recognizer and face verifier, 10 images per person in the 38-person group formed the training set, and the remaining 16 images were used for evaluation. The images in the ORL face database were used as negative training patterns (for the face recognizer only). The images of the other 28 individuals in the IM66 database were used as intruder test patterns.
The face recognizer's recognition result is summarized in Table 8.8. The rates on the first three rows were calculated from the known-person data set, so they sum to 100% in each column. The FARs, which are in the fourth row, were obtained from the intruder data set. Because the recognition rate is the percentage of patterns in the known persons database correctly recognized by the system, the summation of recognition, false rejection and misclassification rates sum to 100%. This experiment shows that with face recognition alone the performance was worse than that of SCR 80×20. This is not surprising because the variation in IM66 was larger than that of SCR 80×20. With the help of the face verifier, the combined error rate was greatly reduced. In Table 8.8, the decision thresholds of the PDBNNs were set to lower the false acceptance and misclassification rates. Such a setting is favorable if the recognition system is for access-control applications.
| Without Face Verifier | With Face Verifier | |
|---|---|---|
| Recognition | 92.65% | 97.75% |
| False rejection | 7.29% | 2.25% |
| Misclassification | 0.06% | 0.00% |
| False acceptance | 9.35% | 0.00% |