
In this chapter, we explore the foundations of distributed computing. First, we will answer the questions about a distributed system, its fundamental abstractions, system models, and relevant ideas.
Distributed Systems
In the literature, there are many different definitions of distributed systems. Still, fundamentally they all address the fact that a distributed system is a collection of computers working together to solve a problem.
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.
—Leslie Lamport
https://lamport.azurewebsites.net/pubs/distributed-system.txt
A distributed system is a collection of autonomous computing elements that appears to its users as a single coherent system.
—Tanenbaum
Here is my own attempt!
A distributed system is a collection of autonomous computers that collaborate with each other on a message-passing network to achieve a common goal.
Usually, this problem is not solvable by a single computer, or the distributed system is inherently distributed such as a social media application.
Some everyday examples of distributed systems are Google, Facebook, Twitter, Amazon, and the World Wide Web. Another class of recently emerged and popular distributed systems is blockchain or distributed ledgers, which we will cover in Chapter 4.
In this chapter, we lay the foundations and look at the distributed systems in general, their characteristics and properties, motivations, and system models that help reason about the properties of a distributed system.
While distributed systems can be quite complex and usually have to address many design aspects, including process design, messages (interaction between processes), performance, security, and event management, a core problem is consensus.
Consensus is a fundamental problem in distributed systems where despite some failures in the system, the processes within the distributed system always agree to the state of the system. We will do more of this in Chapter 3.
In the first chapter, we will lay the foundation of distributed systems and build an intuition about what they are and how they work. After this, we will cover cryptography, blockchain, and consensus, which will provide a solid foundation to then move on and read the rest of the chapters, covering more in-depth topics such as consensus protocols, design and implementation, and some latest research on quantum consensus.
But first, let’s have a closer look at the distributed system foundations and discuss what characteristics a distributed system has.
Characteristics
- 1.
No global physical clocks
- 2.
Autonomous processors/independent processors/indepedently failing
- 3.
No global shared common memory
- 4.
Heterogeneous
- 5.
Coherent
- 6.
Concurrency/concurrent operation
No global physical clock implies that the system is distributed in nature and asynchronous. The computers or nodes in a distributed system are independent with their own memory, processor, and operating system. These systems do not have a global shared clock as a source of time for the entire system, which makes the notion of time tricky in distributed systems, and we will shortly see how to overcome this limitation. The fact that there is no global shared memory implies that the only way processes can communicate with each other is by consuming messages sent over a network using channels or links.
All processes or computers or nodes in a distributed system are independent, with their own operating system, memory, and processor. There is no global shared memory in a distributed system, which implies that each processor has its own memory and its own view of its state and has limited local knowledge unless a message from other node(s) arrives and adds to the local knowledge of the node.
Distributed systems are usually heterogeneous with multiple different types of computers with different architecture and processors. Such a setup can include commodity computers, high-end servers, IoT devices, mobile devices, and virtually any device or "thing" that runs the distributed algorithm to solve a common problem (achieve a common goal) the distributed system has been designed for.
Distributed systems are also coherent. This feature abstracts away all minute details of the dispersed structure of a distributed system, and to an end user, it appears as a single cohesive system. This concept is known as distribution transparency.
Concurrency in a distributed system is concerned with the requirement that the distributed algorithm should run concurrently on all processors in the distributed system.

A chart of a distributed system with 5 connected computers. Each computer comprise a memory, a processor, and an operating system.
A distributed system
There are several reasons why we would want to build a distributed system. The most common reason is scalability. For example, imagine you have a single server serving 100 users a day; when the number of users grows, the usual method is to scale vertically by adding more powerful hardware, for example, faster CPU, more RAM, bigger hard disk, etc., but in some scenarios, you can only go so much vertically, and at some point, you have to scale horizontally by adding more computers and somehow distributing the load between them.
Why Build Distributed Systems
Reliability
Performance
Resource sharing
Inherently distributed
Let’s have a look at each one of these reasons separately.
Reliability
Reliability is a key advantage of distributed systems. Imagine if you have a single computer. Then, when it fails, there is no choice but to reboot it or get a new one if it had developed a significant fault. However, there are multiple nodes in distributed systems in a system that allows a distributed system to tolerate faults up to a level. Thus, even if some computers fail in a distributed network, the distributed system keeps functioning. Reliability is one of the significant areas of study and research in distributed computing, and we will look at it in more detail in the context of fault tolerance shortly.
Availability simply means that when a request is made by a client, the distributed system should always be available.
Integrity ensures that the state of the distributed system should always be in stable and consistent state.
Fault tolerance enables a distributed system to function even in case of some failures.
Performance
In distributed systems, better performance can be achieved naturally. For example, in the case of a cluster of computers working together, better performance can be achieved by parallelizing the computation. Also, in a geographically dispersed distributed network, clients (users) accessing nodes can get data from the node which is closer to their geographic region, which results in quicker data access. For example, in the case of Internet file download, a mirror that is closer to your geographic region will provide much better download speed as compared to the one that might be in another continent.
Performance of a distributed system generally encompasses two facets, responsiveness and throughput.
Responsiveness
This property guarantees that the system is reasonably responsive, and users can get adequate response from the distributed system.
Throughput
Throughput of a distributed system is another measure by which the performance of the distributed system can be judged. Throughput basically captures the rate at which processing is done in the system; usually, it is measured in transactions per second. As we will see later in Chapter 5, high transaction per second rate is quite desirable in blockchain systems (distributed ledgers). Quite often, transactions per second or queries executed per second are measured for a distributed database as a measure of the performance of the system. Throughput is impacted by different aspects of the distributed system, for example, processing speeds, communication network quality, speed and reliability, and the algorithm. If your hardware is good, but the algorithm is designed poorly, then that can also impact the throughput, responsiveness, and the overall performance of the system.
Resource Sharing
Resources in a distributed system can be shared with other nodes/participants in the distributed system. Sometimes, there are expensive resources such as a supercomputer, a quantum computer, or some industrial grade printer which can be too expensive to be made available at each site; in that case, resources can be shared via communication links to other nodes remotely. Another scenario could be where data can be divided into multiple partitions (shards) to enable quick access.
Inherently Distributed
There are scenarios where there is no option but to build a distributed system because the problem can only be solved by a distributed system. For example, a messaging system is inherently distributed. Mobile network is inherently by nature distributed. In these and similar use cases, a distributed system is the only one that can solve the problem; therefore, the system has to be distributed by design.
With all these benefits of distributed systems, there are some challenges that need to be addressed when building distributed systems. The properties of distributed systems such as no access to a global clock, asynchrony, and partial failures make designing reliable distributed systems a difficult task. In the next section, we look at some of the primary challenges that should be addressed while building distributed systems.
Challenges
Distributed systems are hard to build. There are multiple challenges that need to be addressed while designing distributed systems. A collection of some common challenges is presented as follows.
Fault Tolerance
With more computers and at times 100s of thousands in a data center, for example, in the case of cloud computing, inevitably something somewhere would be failing. In other words, the probability of failing some part of the distributed system, be it a network cable, a processor, or some other hardware, increases with the number of computers. This aspect of distributed systems requires that even if some parts of the distributed system fail (usually a certain threshold), the distributed system as a whole must keep operating. To this end, there are various problems that are studied in distributed computing under the umbrella of fault tolerance. Fault-tolerant consensus is one such example where the efforts are made to build consensus algorithms that continue to run correctly as specified even in the presence of a threshold of faulty nodes or links in a distributed system. We will see more details about that in Chapter 3.
A relevant area of study is failure detection which is concerned with the development of algorithms that attempt to detect faults in a distributed system. This is especially an area of concern in asynchronous distributed systems where there is no upper bound on the message delivery times. The problem becomes even more tricky when there is no way to distinguish between a failed node and a node that is simply slower and a lost message on the link. Failure detection algorithms give a probabilistic indication about the failure of a process. This up or down status of the node then can be used to handle that fault.
Another area of study is replication which provides fault tolerance on the principle that if the same data is replicated across multiple nodes in a distributed system, then even if some nodes go down the data is still available, which helps to keep the system stable and continue to meet its specification (guarantees) and remain available to the end users. We will see more about replication in Chapter 3.
Security
Being a distributed system with multiple users using it, out of which some might be malicious, the security of distributed systems becomes a prime concern. This situation is even more critical in geographically dispersed distributed systems and open systems such as blockchains, for example, Bitcoin blockchain. To this, the fundamental science used for providing security in distributed systems is cryptography, which we will cover in detail in Chapter 2, and we will keep referring to it throughout the book, especially in relation to blockchain consensus. Here, we study topics such as cryptography and address challenges such as authentication, confidentiality, access control, nonrepudiation, and data integrity.
Heterogeneity
A distributed system is not necessarily composed of exactly the same hardware nodes. It is possible and is called homogenous distributed system, but usually the hardware and operating systems are different from each other. In this type of scenario, different operating systems and hardware can behave differently, leading to synchronization complexities. Some nodes might be slow, running a different operating system which could have bugs, some might run faster due to better hardware, and some could be resource constrained as mobile devices or IoT devices. With all these different types of nodes (processes, computers) in a distributed system, it becomes challenging to build a distributed algorithm that works correctly on all these different types of systems and continues to operate correctly despite the differences in the local operating environment of the nodes.
Distribution Transparency
One of the goals of a distributed system is to achieve transparency. It means that the distributed system, no matter how many individual computers and peripherals it is built of, it should appear as a single coherent system to the end user. For example, an ecommerce website may have many database servers, firewalls, web servers, load balancers, and many other elements in their distributed system, but all that should be abstracted away from the end user. The end user is not necessarily concerned about these backend "irrelevant" details but only that when they make a request, the system responds. In summary, the distributed system is coherent if it behaves in accordance with the expectation of the end user, despite its heterogeneous and dispersed structure. For example, think about IPFS, a distributed file system. Even though the files are spread and sharded across multiple computers in the IPFS network, to the end user all that detail is transparent, and the end user operates on it almost as if they are using a local file system. Similar observation can be made about other systems such as online email platforms and cloud storage services.
Timing and Synchronization
Synchronization is a vital operation of a distributed system to ensure a stable global state. As each process has its view of time depending on their internal physical clocks which can drift apart, the time synchronization becomes one of the fundamental issues to address in designing distributed systems. We will see some more details around this interesting problem and will explore some solutions in our section on timing, orders, and clocks in this chapter.
Global State
As the processes in a distributed system only have knowledge of their local states, it becomes quite a challenge to ascertain the global state of the system. There are several algorithms that can be used to do that, such as the Chandy-Lamport algorithm. We will briefly touch upon that shortly.
Concurrency
Concurrency means multiple processes running at the same time. There is also a distinction made between logical and physical concurrency. Logical concurrency refers to the situation when multiple programs are executed in an interleaving manner on a single processor. Physical concurrency is where program units from the same program execute at the same time on two or more processors.
Distributed systems are ubiquitous. They are in everyday use and have become part of our daily routine as a society. Be it the Internet, the World Wide Web, Bitcoin, Ethereum, Google, Facebook, or Twitter, distributed systems are now part of our daily lives. At the core of distributed systems, there are distributed algorithms which form the foundation of the processing being performed by the distributed system. Each process runs the same copy of the algorithm that intends to solve the problem for which the distributed system has been developed, hence the term distributed algorithm.
A process can be a computer, an IoT device, or a node in a data center. We abstract these devices and represent these as processes, whereas physically it can be any physical computer.
Now let’s see some of the relevant technologies and terminologies.
Parallel vs. Distributed vs. Concurrency
The key difference between a parallel system and a distributed system is that parallel systems’ primary focus is on high performance, whereas distributed systems are concerned with tolerating partial failures. Also, parallel processing systems have direct access to a shared memory, whereas in distributed systems all processors have their own local memory.
Parallel vs. distributed systems
Resource/Property | Parallel | Distributed |
|---|---|---|
Memory | Shared memory, a common address space | Each processor has its own memory |
Coupling | Tightly coupled | Loosely coupled |
Synchronization | Through a global shared clock | Through synchronization algorithms |
Goal | High performance | Scalability |
Algorithms | Concurrent | Distributed |
Messaging | No network, shared memory | Message-passing network |
There are some overlapping ideas in the distributed computing, and sometimes it becomes a bit difficult for beginners to understand. In the next section, I will try to clarify some of the pertinent terminology and some ambiguities.
Centralized vs. Decentralized vs. Distributed
A centralized system is a typical distributed system where clients connect to a central server or a service provider. There is usually an administrator in control of the entire system. A typical example is the standard client-server architecture, where all clients send requests to a central server and receive responses. These systems are usually easier to develop and maintain. However, they are not fault tolerant (in the stricter sense of client-server where there is only one central server); if the central server fails, the clients cannot connect and make requests.
A decentralized system is where there is no central owner of the system. Instead, there can be multiple owners in different locations who oversee different parts of the system, or there is no controller as in blockchain systems.
A distributed system compared to a centralized and decentralized system can be thought of as a system where there may or may not be a central controller in the system; however, the resources and nodes are distributed.

Three irregular structures titled centralized, decentralized, and distributed systems with various nodes. All the nodes are connected together via links.
Centralized vs. decentralized vs. distributed

Five structures are grouped into centralized, decentralized, and distributed systems. Each structure has various nodes connected together via links.
Centralized vs. distributed vs. decentralized
Notice that in Figure 1-3 the topology of distributed and decentralized systems may be the same, but there is a central controller, depicted by a symbolic hand on top of the figure. However, in a decentralized system notice that there is no hand shown, which depicts there is no single central controller or an authority.
So far, we have focused mainly on the architecture of distributed systems and generally defined and explored what distributed systems are. Now let’s look at the most important fundamental element of a distributed system, that is, the distributed algorithm that enables a distributed system to do what it is supposed to do. It is the algorithm that runs on each node in a distributed system to accomplish a common goal. For example, a common goal in a cryptocurrency blockchain is to disallow double-spending. The logic to handle that is part of the distributed algorithm that runs on each node of the cryptocurrency blockchain, and collectively and collaboratively, the blockchain (the distributed system) accomplishes this task (goal) to avoid double-spending. Don’t worry if some of these terms don’t make sense now; they will become clear in Chapter 4.
Distributed Algorithm
A distributed algorithm runs on multiple computers concurrently to accomplish something in a distributed system. In a distributed system, the same algorithm runs on all computers concurrently to achieve a common goal.
In contrast with a sequential algorithm where each operation in execution comes one after another, distributed algorithms are algorithms where the operations are performed concurrently. Concurrent algorithms and concurrency are quite common in computing, for example, multiple threads running simultaneously in a processor, multiple applications running in a computer, multicore processors in a computer, or multiple processes running concurrently in a distributed system.
We can define a distributed algorithm as an algorithm that runs concurrently on multiple machines.
There are several advantages of distributed algorithms, including but not limited to better performance where some computation can be parallelized to achieve higher performance as compared to sequential algorithms. In addition, distributed algorithms allow for fault tolerance; for example, if a certain threshold (which we will explain in Chapter 3) of nodes fails, the distributed algorithms continue to operate.
There are message-passing algorithms where processes communicate over the network by sending and receiving messages. Another type is shared memory distributed algorithms, where the algorithms communicate by reading and writing from shared memory.
Centralized algorithms execute sequentially, whereas distributed algorithms execute concurrently. Centralized algorithms are not usually characterized by failures, whereas distributed algorithms are designed to tolerate various types of failures. Sequential algorithms tend to be more intuitive as they are designed for sequential execution, whereas distributed algorithms can be challenging to understand. This is one of the reasons why the correctness proofs of centralized algorithms are comparatively easier to do and, in most cases, even apparent by observation. This is not the case in distributed algorithms, where correctness can be deceiving. A seemingly correct algorithm may not behave correctly in practice and could be subject to various failures and violations of properties. For this purpose, several formal specifications and verification techniques are used to ascertain the correctness of distributed algorithms. We will cover some of these methods in Chapter 9. Distributed algorithms tend to be more challenging to design, debug, and implement as compared to sequential algorithms. Moreover, from a complexity measure point of view, it’s generally the measure of the number of instructions in a sequential centralized algorithm; however, the complexity of distributed algorithms is measured in the number of messages.
Elements of Distributed Computing/Pertinent Terms/Concepts
A distributed system is composed of several elements. We are only interested in an abstracted view of the system instead of specific hardware or network details. The abstracted view allows designers to design and reason about the system under some assumptions by building a system model. More on that later but let’s first look at the basic elements in a distributed system.

A hexagon and a square with circles on each vertex are labeled ring and clique. An irregular structure with branches is labeled tree.
Distributed system topologies depicted as graphs
A distributed system is usually represented as a graph composed of nodes and vertices. Nodes represent processes in the network, whereas vertices represent communication links between the processes. These graphs also show the structural view or topology of the network and help to visualize the system.
A distributed system can have different topologies (structures) and can be presented as graphs. Common topologies include ring which depicts a topology where each node has two adjacent nodes. A tree structure is acyclic and connected. Clique is a fully connected graph where all processes are connected to each other directly.
- Processes
Events
Executions
Links
State
Global state
Cuts
Let’s look at them in detail now.
Processes
A process in a distributed system is a computer that executes the distributed algorithm. It is also called a node. It is an autonomous computer that can fail independently and can communicate with other nodes in the distributed network by sending and receiving messages.
Events
Internal events occur when something happens locally in a process. In other words, a local computation performed by a process is an internal event.
Message send events occur when a process (node) sends a message out to other nodes.
Message receive events occur when a process (node) receives a message.
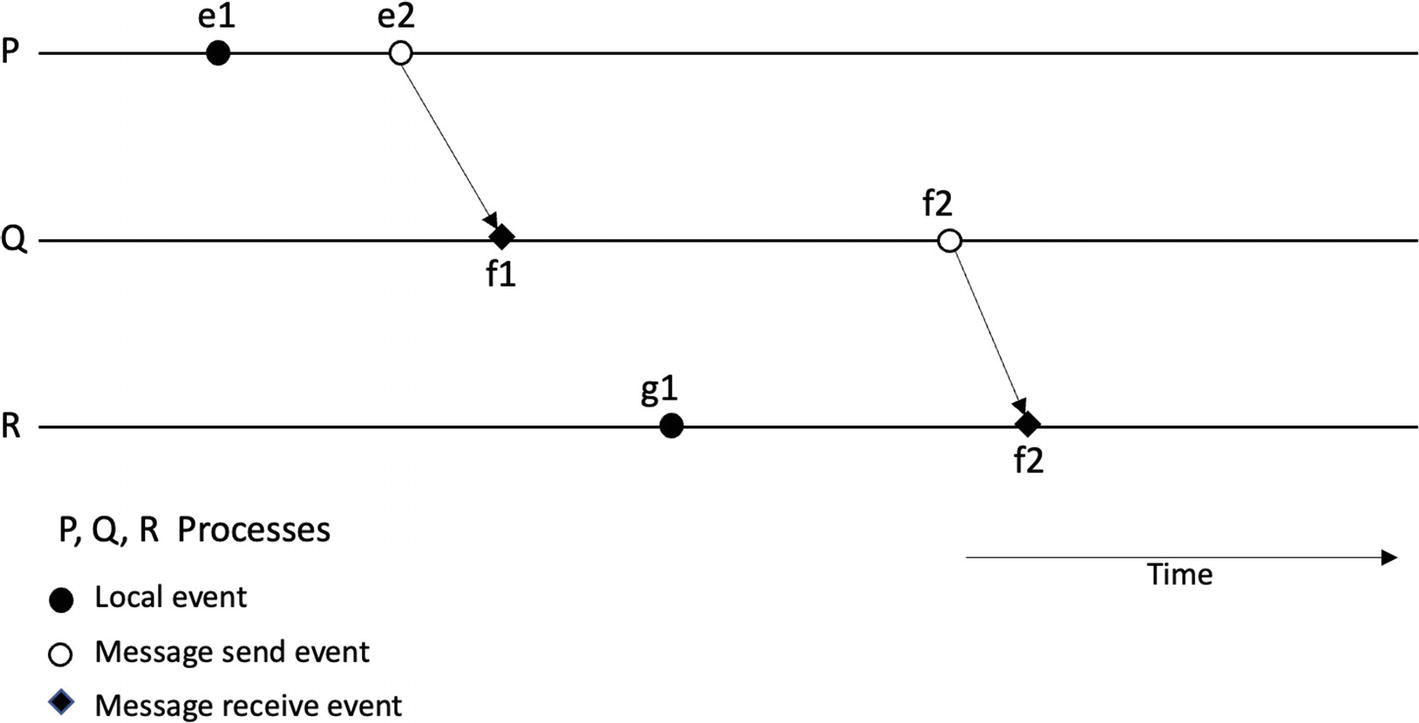
A schematic with 3 lines, P, Q, and R, has events like local, message sent, and message received. Some of the events are connected together via time.
Events and processes in a three-node distributed system
State
The concept of state is critical in distributed systems. You will come across this term quite a lot in this book and other texts on distributed systems, especially in the context of distributed consensus. Events make up the local state of a node. In other words, a state is composed of events (results of events) in a node. Or we can say that the contents of the local memory, storage, and program as a result of events make up the process’s state.
Global State
The collection of states in all processes and communication links in a distributed system is called a global state.
This is also known as configuration which can be defined as follows:
The configuration of a distributed system is composed of states of the processes and messages in transit.
Execution
Synchronous execution
Asynchronous execution
Cuts
A cut can be defined as a line joining a single point in time on each process line in a space-time diagram. Cuts on a space-time diagram can serve as a way of visualizing the global state (at that cut) of a distributed computation. Also, it serves as a way to visualize what set of events occurred before and after the cut, that is, in the past or future. All events on the left of the cut are considered past, and all events on the right side of the cut are said to be future. There are consistent cuts and inconsistent cuts. If all received messages are sent within the elapsed time before the cut, that is, the past, it is called a consistent cut. In other words, a cut that obeys causality rules is a consistent cut. An inconsistent cut is where a message crosses the cut from the future (right side of the cut) to the past (left side of the cut).
If a cut crosses over a message from the past to the future, it is a graphical representation of messages in transit.

A schematic with 3 lines, P, Q, and R, has events like E P 1, E P 2, and so on. All the events are grouped into 2 cuts labeled C 1 and C 2.
A space-time diagram depicting cuts in a distributed system execution
Algorithms such as the Chandy-Lamport snapshot algorithm are used to create a consistent cut of a distributed system.
Taking a snapshot of a distributed system is helpful in creating a global picture of the system. A snapshot or global snapshot captures the global state of the system containing the local state of each process and the individual state of each communication link in the system. Such snapshots are very useful for debugging, checkpointing, and monitoring purposes. A simple solution is to synchronize all clocks and create a snapshot at a specific time, but accurate clock synchronization is not possible, and we can use causality to achieve such an algorithm that gives us a global snapshot.
- An initiator process initiating the snapshot algorithm does the following:
Records its own state
Sends a marker message (a control message) to all processes
Starts recording all incoming messages on its channels
A process receiving the marker message does the following:
- If it is the first time it sees this message, then it
Records its own local state
Marks the channel as empty
Sends out a marker to all processes on its channels
Starts recording all incoming channels, except the one it had marked empty previously
- If not the first time
Stops recording
A snapshot is considered complete, and algorithm terminates, when each process has received the marker on all its incoming channels.
The initiator process is now able to build a complete snapshot containing the saved state of each process and all messages.
Note that any process can initiate the snapshot, the algorithm does not interfere with the normal operation of the distributed system, and each process records the state of incoming channels and its own.
Types of Distributed Systems
There are two types of distributed systems from the communication point of view. Shared memory systems are those where all nodes have direct access to the shared memory. On the other hand, message-passing systems are those where nodes communicate with each other via passing messages. In other words, nodes send and receive messages using communication links to communicate with each other.
Now let’s discuss some software architecture models of distributed systems. Software architecture models describe the design and structure of the system. Software architecture answers questions such as what elements are involved and how they interact with each other. The central focus of the distributed system software architecture is processes, and all other elements are built around them.
Software Architecture Models
There are four main software architecture types which include the client-server model, multiple server model, proxy server model, and peer-to-peer model.
Client-Server

A schematic of a server connected to 3 clients. The request is sent from the client to the server, and a reply is sent from the server to the client.
Client-server architecture
Multiserver
A multiserver architecture is where multiple servers work together. In one style of architecture, the server in the client-server model can itself become a client of another server. For example, if I have made a request from my web browser to a web server to find prices of different stocks, it is possible that the web server now makes a request to the backend database server or, via a web service, requests this pricing information from some other server. In this scenario, the web server itself has become a client. This type of architecture can be seen as a multiserver architecture.
Another quite common scenario is where multiple servers act together to provide a service to a client, for example, multiple database servers providing data to a web server. There are two usual methods to implement such collaborative architecture. The first is data partitioning, and another is data replication. Another closely related term to data partitioning is data sharding.
Data partition refers to an architecture where data is distributed among the nodes in a distributed system, and each node becomes responsible for its partition (section) of the data. Partitioning of data helps to achieve better performance, easier administration, load balancing, and better availability. For example, data for each department of a company can be divided into partitions and stored separately on different local servers. Another way of looking at it is that if we have a large table with one million rows, I might put half a million rows on one server and another half on another server. This scheme is called data sharding or horizontal partitioning, or horizontal sharding depending on how the sharding is performed.

A schematic of data partitioning. Citizen database from all regions are connected to regional offices at London, Bradford, and Montgomery
Data partitioning
Note that data partitioning shown in Figure 1-8 is where a large central database is partitioned into smaller datasets relevant to each region, and a regional server then manages the partition. However, in another type of partitioning, a large table can be partitioned into different tables, but it remains on the same physical server. It is called logical partitioning.

A set of 5 tables. A table at the top is titled table. 2 tables are titled vertical shards and 2 are titled horizontal shards.
Sharding
Data replication refers to an architecture where each node in the distributed system holds an identical copy of the data. A typical simple example is that of the RAID 0 system; while they are not separate physical servers, the data is replicated across two disks, which makes it a data replication (commonly called mirroring) architecture. In another scenario, a database server might run a replication service to replicate data across multiple servers. This type of architecture allows for better performance, fault tolerance, and higher availability. A specific type of replication and fundamental concept in a distributed system is state machine replication used to build fault-tolerant distributed systems. We will cover more about this in Chapter 3.

A schematic with connected servers and a client. Another client at the bottom sends a request and receives a reply.
Multiple servers acting together (client-server and multiple servers coordinating closely/closely coupled servers)

A schematic of data replication. The citizen database at the headquarters is connected to 3 citizen databases at the regional offices.
Data replication
In summary, replication refers to a practice where a copy of the same data is kept on multiple different nodes, whereas partitioning refers to a practice where data is split into smaller subsets, and these smaller subsets are then distributed across different nodes.
Proxy Servers
A proxy server–based architecture allows for intermediation between clients and backend servers. A proxy server can receive the request from the clients and forward it to the backend servers (most commonly, web servers). In addition, proxy servers can interpret client requests and forward them to the servers after processing them. This processing can include applying some rules to the request, perhaps anonymizing the request by removing the client’s IP address. From a client’s perspective, using proxy servers can improve performance by caching. These servers are usually used in enterprise settings where corporate policies and security measures are applied to all web traffic going in or out of the organization. For example, if some websites need to be blocked, administrators can use a proxy server to do just that where all requests go through the proxy server, and any requests for blocked sites are intercepted, logged, and ignored.

A schematic. The client receives a request from a proxy server and sends its reply. The proxy server is connected to 2 other servers.
Proxy architecture – one proxy between servers and clients
Peer to Peer
In the peer-to-peer architecture, the nodes do not have specific client or server roles. They have equal roles. There is no single client or a server. Instead, each node can play either a client or a server role, depending on the situation. The fact that all nodes have an equal role resulted in the term "peer."

A schematic of peer architecture. 4 peers are connected together via arrows labeled request and reply.
Peer-to-peer architecture
In some scenarios, it is also possible that not all nodes have equal roles; some may act as servers and clients to each other. Generally, however, all nodes have the same role in a peer-to-peer network.
Now that we have covered some architectural styles of distributed systems, let’s focus on a more theoretical side of the distributed system, which focuses on the abstract view of the distributed systems. First, we explore the distributed system model.
Distributed System Model
A system model allows us to see a distributed system abstractly. It captures the assumptions about the behavior of the distributed system. It will enable us to define some properties we expect from our distributed system and then reason about them. All of this is at an abstract level without worrying about any technology or implementation details. For example, a communication link abstraction only captures the fact that a channel allows messages to be communicated/exchanged between processes without specifying what it is. From an implementation point of view, it could be a fiber optic cable or a wire.
We are not concerned with the specifics of the implementation of hardware technology in a distributed system model. For example, a process is a node that performs some events, and we do not concern ourselves with worrying about the exact hardware or computer type.

Two schematics. The left has interconnected components from P 1 to 11. On the right, P 1 to 11 form 2 linear chains, joined to a network.
Physical architecture (left) vs. abstract system model (right)
Now let’s see what the three fundamental abstractions in a distributed system are. Failures characterize all these abstractions. We capture our assumption about what fault might occur in our system. For example, processes or nodes can crash or act maliciously in a distributed system. A network can drop messages, or messages can be delayed. Message delays are captured using timing assumptions.
So, in summary, when a distributed system model is created, we make some assumptions about the behavior of the system. This process includes timing assumptions regarding processes and the network. We also make failure assumptions regarding the network and the processors, for example, how a process can fail and whether it can exhibit arbitrary failures, how an adversary can affect the processors or the network, and whether processes can crash or recover after a crash. Is it possible that the network links drop messages? In the next section, we discuss all these scenarios in detail.
Processes
A process or node is a fundamental element in a distributed system which runs the distributed algorithm to achieve that common goal for which the distributed system has been designed.
Now imagine what a process can do in a distributed system. First, let’s think about a normal scenario. If a process is behaving according to the algorithm without any failures, then it is called a correct process or honest process. So, in our model we say that a node running correctly is one of the behaviors a node can exhibit. What else? Yes, of course, it can fail. If a node fails, we say it’s faulty; if not, then it is nonfaulty or correct or honest.
Crash-stop
Omission
Crash with recovery
Eavesdropping
Arbitrary
Crash-Stop Failure
Crash-stop faults are where a process crashes and never recovers. This model of faults or node behavior captures an irreparable hardware fault, for example, short circuit in a motherboard causing failure.
Omission Failure
Omission failures capture the fault scenarios where a processor fails to send a message or receive a message. Omission failures are divided into three categories: send omissions, receive omissions, and general omissions. Send omissions are where a processor doesn’t send a message out which it was supposed to as per the distributed algorithm; receive omissions occur when a process does not receive an expected message. In practical terms, these omissions arise due to physical faults, memory issues, buffer overflows, malicious actions, and network congestions.
Crash with Recovery
A process exhibiting crash with recovery behavior can recover after a crash. It captures a scenario where a process crashes, loses its in-memory state, but recovers and resumes its operation later. This occurrence can be seen as an omission fault too, where now the node will not send or receive any messages because it has crashed. In practical terms, it can be a temporary intentional restart of a process or reboot after some operating system errors. Some examples include resumption of the normal operation after rebooting due to a blue screen in Windows or kernel panic in Linux.
When a process crashes, it may lose its internal state (called amnesia), making a recovery tricky. However, we can alleviate this problem by keeping stable storage (a log) which can help to resume operations from the last known good state. A node may also lose all its state after recovery and must resynchronize with the rest of the network. It may also happen that a node is down for a long time and has desynchronized with the rest of the network (other nodes) and has its old view of the state. In that case, the node must resynchronize with the network. This situation is especially true in blockchain networks such as Bitcoin or Ethereum, where a node might be off the network for quite some time. When it comes back online, it synchronizes again with the rest of the nodes to resume its full normal operation.
Eavesdropping
In this model, a distributed algorithm may leak confidential information, and an adversary can eavesdrop to learn some information from the processes. This model is especially true in untrusted and geographically dispersed environments such as a blockchain. The usual defense against these attacks is encryption which provides confidentiality by encrypting the messages.
Arbitrary (Byzantine)
A Byzantine process can exhibit any arbitrary behavior. It can deviate from the algorithm in any possible way. It can be malicious, and it can actively try to sabotage the distributed algorithm, selectively omit some messages, or covertly try to undermine the distributed algorithm. This type of fault is the most complex and challenging in a distributed algorithm or system. In practical terms, it could be a hacker coming up with novel ways to attack the system, a virus or worm on the network, or some other unprecedented attack. There is no restriction on the behavior of a Byzantine faulty node; it can do anything.
A relevant concept is that of the adversary model, where the adversary behavior is modelled. We will cover this later in the section “Adversary Model”.
Now we look at another aspect of the distributed system model, network.
Network
In a distributed network, links (communication links) are responsible for passing messages, that is, take messages from nodes and send to others. Usually, the assumption is a bidirectional point-to-point connection between nodes.
A network partition is a scenario where the network link becomes unavailable for some finite time between two groups of nodes. In practice, this could be due to a data center not speaking to another or an incorrect/unintentional or even intentional/malicious firewall rule prohibiting connections from one part of the network to another.
Link Failures
Links can experience crash failure where a correctly functioning link may stop carrying messages. Another type of link failure is omission failure, where a link carries some messages, and some don’t. Finally, Byzantine failures or arbitrary failures can occur on links where the link can create rogue messages and modify messages and selectively deliver some messages, and some don’t.
With this model, we can divide the communication links into different types depending on how they fail and deliver the messages.
Two types of events occur on links (channels), the send event where a message is put on the link and the deliver event where the link dispenses a message, and a process delivers it.
Fair-Loss Links
In this abstraction, we capture how messages on this link can be lost, duplicated, or reordered. The messages may be lost but eventually delivered if the sender and receiver process is correct and the sender keeps retransmitting. More formally, the three properties are as follows.
Fair-Loss
This property guarantees that the link with this property does not systematically drop every message, which implies that, eventually, delivery of a message to the destination node will be successful even if it takes several retransmissions.
Finite Duplication
This property ensures that the network does not perform more retransmissions than the sender does.
No Creation
This property ensures that the network does not corrupt messages or create messages out of thin air.
Stubborn Links
This abstraction captures the behavior of the link where the link delivers any message sent infinitely many times. The assumption about the processes in this abstraction is that both sender and receiver processes are correct. This type of link will stubbornly try to deliver the message without considering performance. The link will just keep trying regardless until the message is delivered.
Formally, there are two properties that stubborn links have.
Stubborn Delivery
This property means that if a message m is sent from a correct process p to a correct process q once, it will be delivered infinitely many times by process q, hence the term "stubborn"!
No Creation
This means that messages are not created out of the blue, and if a message is delivered by some process, then it must have been sent by a process. Formally, if a process q delivers a message m sent from process p, then the message m is indeed sent from process p to process q.
Perfect (Reliable) Links
This is the most common type of link. In this link, if a process has sent a message, then it will eventually be delivered.
In practice, TCP is a reliable link. There are three properties.
Reliable Delivery
If a message m is sent by a correct process p to a correct process q, then m is eventually delivered by q.
No Duplication
A correct process p does not deliver a message m more than once.
No Creation
This property ensures that messages are not created out of thin air, and if they are delivered, they must have been created and sent by a correct process before delivering.
Logged Perfect Links
This type of link delivers messages into the receiver’s local message log or persistent storage. This is useful in scenarios where the receiver might crash, but we need the message to be safe. In this case, even if the receiver process crashes, the message is not lost because it persisted in the local storage.
Authenticated Perfect Links
This link guarantees that a message m sent from a process p to process q is indeed sent from process p.
Arbitrary Links
In this abstraction, the link can exhibit any behavior. Here, we consider an active adversary who has the power to control the messages. This link depicts scenarios where an attacker can do malicious actions, modify the messages, replay them, or spoof them. In short, on this link, any attack is possible.
In practical terms, this depicts a typical Internet connection where a hacker can eavesdrop, modify, spoof, or replay the messages. But, of course, this could also be due to Internet worms, traffic analyzers, and viruses.
Here, we are talking about point-to-point links only; we will introduce broadcast later in Chapter 3.
Synchrony and Timing
In distributed systems, delays and speed assumptions capture the behavior of the network.
In practical terms, delays are almost inevitable in a distributed system, first because of inherent asynchrony, dispersion, and heterogeneity and specific causes such as message loss, slow processors, and congestion on the network. Due to network configuration changes, it may also happen that unexpected or new delays are introduced in the distributed system.
Synchrony assumption in a distributed system is concerned with network delays and processor delays incurred by slow network links or slow processor speeds.
In practical terms, processors can be slow because of memory exhaustion in the nodes. For example, java programs can pause execution altogether during the "stop the world" type of garbage collection. On the other hand, some high-end processors are inherently faster than low-end processors on resource-constrained devices. All these differences and situations can cause delays in a distributed system.
In the following, we discuss three models of synchrony that capture the timing assumption of distributed systems.
Synchronous
A synchronous distributed system has a known upper bound on the time it takes for a message to reach a node. This situation is ideal. However, in practice, messages can sometimes be delayed. Even in a perfect network, there are several factors, such as network link quality, network latency, message loss, processing speed, or capacity of the processors, which can adversely affect the delivery of the message.
In practice, synchronous systems exist, for example, a system on a chip (SoC), embedded systems, etc.
Asynchronous
Asynchronous distributed systems are on the other end of the spectrum. In this model, there is no timing assumption made regarding the timing. In other words, there is no upper bound on the time it takes to deliver a message. There can be arbitrarily long and unbounded delays in message delivery or processing in a node. The processes can run at different speeds.
Also, a process can arbitrarily pause or delay the execution or can process faster than other processes. You can probably imagine now that distributed algorithms designed for such a system can be very robust and resilient. However, many problems cannot be solved in an asynchronous distributed system. A whole class of results called "impossibility results" captures the unsolvable problems in distributed systems. We will look at impossibility results in more detail later in the chapter and then in Chapter 3. As several types of problems cannot be solved in an asynchronous model and the synchronous model is too idealistic, we have to compromise. The compromise is called a partially synchronous network.
Partially Synchronous
A partially synchronous model captures the assumption that the network is primarily synchronous and well behaved, but it can sometimes behave asynchronously. For example, processing speeds can differ, or network delays can occur, but the system ultimately returns to a synchronous state to resume normal operation.
Another way to think about this is that the network usually is synchronous but can unpredictably, for a bounded amount of time, behave asynchronously, but there are long enough periods of synchrony where the system behaves correctly.
Another way to think about this is that the real systems are synchronous most of the time but can behave arbitrarily and unpredictably asynchronous at times. During the synchronous period, the system is able to make decisions and terminate.
Time stays long enough for anyone who will use it.

A graph plots processor delay versus time with a sinusoidal curve. The curve is sectioned as synchronous and asynchronous.
Partially synchronous network
Eventually Synchronous
In the eventually synchronous version of partial synchrony, the system can be initially asynchronous, but there is an unknown time called global stabilization time (GST), unknown to processors, after which the system eventually becomes synchronous. Also, it does not mean that the system will forever remain synchronous after GST. That is not possible practically, but the system is synchronous for a long enough period after GST to make a decision and terminate.

A schematic with a double-headed arrow labeled synchronous on the right and asynchronous on the left, with partially synchronous in the center.
Synchrony models in distributed systems
Both message delivery delay and relative speed of the processes are taken into consideration in synchrony models.
Formal Definitions
Delta Δ denotes a fixed upper bound on the time required for a message to reach from one processor to another.
Phi Φ denotes a fixed upper bound on the relative speed of different processors.
GST is the global stabilization time after which the system behaves synchronously.
Asynchronous systems are those where no fixed upper bounds Δ and Φ exist.
Synchronous systems are those where fixed upper bounds Δ and Φ are known.
Where fixed upper bounds Δ and Φ exist, but they are not known.
Where fixed upper bounds Δ and Φ are known but hold after some unknown time T. This is the eventually synchronous model. We can say that eventually synchronous model is where fixed upper bounds Δ and Φ are known but only hold after some time, known as GST.
In another variation after GST Δ holds for long enough to allow the protocol to terminate.
We will use synchrony models more formally in Chapter 3 in the context of circumventing FLP and consensus protocols. For now, as a foundation the concepts introduced earlier are sufficient.

Two schematics each with 3 lines, P, Q, and R, and multi-directional arrows. The right has no upper bounds and the left has known upper bounds.
Synchronous and asynchronous system
Now that we have discussed the synchrony model, let’s now turn our attention to the adversary model, which allows us to make assumptions about the effect of adversary on a distributed system. In this model, we model how an adversary can behave and what powers an adversary may have in order to adversely influence the distributed system.
Adversary Model
In addition to assumptions about synchrony and timing in a distributed system model, there is another model where assumptions about the power of the adversary and how it can adversely affect the distributed system are made. This is an important model which allows a distributed system designer to reason about different properties of the distributed system while facing the adversary. For example, a distributed algorithm is guaranteed to work correctly only if less than half of the nodes are controlled by a malicious adversary. Therefore, adversary models are usually modelled with a limit to what an adversary can do. But, if an adversary is assumed to be all-powerful who can do anything and control all nodes and communication links, then there is no guarantee that the system will ever work correctly.
Adversary models can be divided into different types depending on the distributed system and the influence they can have on the distributed system and adversely affect them.
In this model, it is assumed there is an external entity that has corrupted the processes and can control and coordinate faulty processes’ actions. This entity is called an adversary. Note that there is a slight difference compared to the failure model here because, in the failure model, the nodes can fail for all sorts of reasons, but no external entity is assumed to take control of processes.
Adversaries can affect a distributed system in several ways. A system designer using an adversary model considers factors such as the type of corruption, time of corruption, and extent of corruption (how many processes simultaneously). In addition, computational power available to the adversary, visibility, and adaptability of the adversary are also considered. The adversary model also allows designers to specify to what limit the number of processes in a network can be corrupted.
We will briefly discuss these types here.
Threshold Adversary
A threshold adversary is a standard and widely used model in distributed systems. In this model, there is a limit imposed on the number of overall faulty processes in the system. In other words, there is a fixed upper bound f on the number of faulty processes in the network. This model is also called the global adversary model. Many different algorithms have been developed under this assumption. Almost all of the consensus protocols work under at least the threshold adversary model where it is assumed that an adversary can control up to f number of nodes in a network. For example, in the Paxos protocol discussed in Chapter 7, classical consensus algorithms achieve consensus under the assumption that an adversary can control less than half of the total number of nodes in the network.
Dynamic Adversary
Also called adaptive adversary, in this model the adversary can corrupt processes anytime during the execution of the protocol. Also, the faulty process then remains faulty until the execution ends.
Static Adversary
This type of adversary is able to perform its adversarial activities such as corrupting processes only before the protocol is executed.
Passive Adversary
This type of adversary does not actively try to sabotage the system; however, it can learn some information about the system while running the protocol. Thus, it can be called a semi-honest adversary.
An adversary can cause faults under two models: the crash failure model and the Byzantine failure model.
In the crash failure model, the adversary can stop a process from executing the protocol it has control over anytime during the execution.
In the Byzantine failure model, the adversary has complete control over the corrupted process and can control it to deviate arbitrarily from the protocol. Protocols that work under these assumptions and tolerate such faults are called crash fault–tolerant protocols (CFT) or Byzantine fault–tolerant protocols (BFT), respectively.
Time, Clocks, and Order
Time plays a critical role in distributed systems. Almost always, there is a need to measure time. For example, timestamps are required in log files in a distributed system to show when a particular event occurred. From a security point of view, audit timestamps are needed to indicate when a specific operation occurred, for example, when a specific user logged in to the system. In operating systems, timing is required for scheduling internal events. All these use cases and countless other computer and distributed systems operations require some notion of time.

A schematic with 3 lines, P, Q, and R, has events like local, message sent, and message received. Some of the events are connected together via time.
Events and processes in a three-node distributed system

A schematic of the exam. A horizontal line labeled me has 2 events of the exam and the result. Below it is a right arrow labeled time.
Exam happened before the result – a happened-before relation
Usually, we are familiar with the physical clock, that is, our typical day-to-day understanding and the notion of time where I can say something like I will meet you at 3 PM today, or the football match is at 11 AM tomorrow. This notion of time is what we are familiar with. Moreover, physical clocks can be used in distributed systems, and several algorithms are used to synchronize time across all nodes in a distributed system. These algorithms can synchronize clocks in a distributed system using message passing.
Let’s first have a look at the physical clocks and see some algorithms that can be used for time synchronization based on internal physical clocks and external time source.
Physical Clocks

A quartz crystal in its natural form is on the left, and in a circuit on the right. In the center is the crystal in its component form.
A quartz crystal in a natural form (left), in a component form (middle), and in a circuit (right)
Quartz-based clocks are usually accurate enough for general-purpose use. However, several factors such as manufacturing differences, casing, and operating environment (too cold, too hot) impact the operation of a quartz crystal. Usually, too low or high a temperature can slow down the clock. Imagine if an electronic device operating in the field is exposed to high temperatures; the clock can run slower than a clock working in normal favorable conditions. This difference caused by the clock running faster or slower is called drift. Drift is measured in parts per million (ppm) units.
In almost all quartz clocks, the frequency of the quartz crystal is 32,768 kHz due to its cut and size and how it is manufactured. This is a specific cut and size which looks like a tuning fork, due to which the frequency produced is always 32,768 Hertz. I decided to do a small experiment with my oscilloscope and an old clock lying around to demonstrate this fact.

An oscilloscope connected to a quartz crystal clock measures 32.7680 kilohertz
Quartz crystal clock measured using an oscilloscope
In Figure 1-21, the probes from the oscilloscope are connected to the quartz crystal component on the clock circuit, and the waveform is shown on the oscilloscope screen. Also, the frequency is displayed at the right bottom of the oscilloscope screen, which reads 32.7680KHz.
Clock Skew vs. Drift
Due to environmental factors such as temperature and manufacturing differences, quartz crystal clocks can slow down, resulting in skew and drift. The immediate difference between the time shown by two clocks is called their skew, whereas the rate at which two clocks count time differently is called drift. Note that the difference between physical clocks between nodes in a heterogeneous distributed system may be even more significant than homogenous distributed systems where hardware, OS, and architecture are the same for all nodes.
Generally, it is expected that roughly a drift of one second over 11 days can develop, which over time can lead to an observable and significant difference. Imagine two servers running in a data center with no clock synchronization mechanism and are only dependent on their internal quartz clock. In a month, they will be running two to three seconds apart from each other. All time-dependent operations will run three seconds apart, and over time this will continue to worsen. For example, a batch job that is supposed to start at 11 AM will begin at 11 + 3 seconds in a month. This situation can cause issues with time-dependent jobs, can cause security issues, and can impact time-sensitive operations, and software may fail or depict an arbitrary behavior. A much more accurate clock than a quartz clock is an atomic clock.
Atomic Clocks
Atomic clocks are based on the quantum mechanical properties of atoms. Atoms such as cesium or rubidium and mercury are used, and resonant frequencies (oscillations) of atoms are used to record accurate and precise times.
Our notion of time is based on astronomical observations such as changing seasons and the Earth’s rotation. The higher the oscillation, the higher the frequency and the more precise the time. This is the principle on which atomic clocks work and produce highly precise time.

A set of 6 of the Cesium Beam atomic clocks with various electrical racks. They have a printout halfway through their height.
Cesium-based atomic clocks: image from https://nara.getarchive.net/media/cesium-beam-atomic-clocks-at-the-us-naval-observatory-provide-the-basis-for-29fa0c
Now imagine a scenario where we discover a clock skew and see that one clock is running behind ten seconds. We can usually and simply advance it to ten seconds to make the clock accurate again. It is not ideal but not as bad as the clock skew, where we may discover a clock to run ten seconds behind. What can we do in that case? Can we simply push it back to ten seconds? It is not a very good idea because we can then run into situations where it would appear that a message is received before we sent it.
To address clock skews and drifts, we can synchronize clocks with a trusted and accurate time source.
You might be wondering why there is such a requirement for more and more precise clocks and sources of time. Quartz clocks are good enough for day-to-day use; then we saw GPS as a more accurate time source, and then we saw atomic clocks that are even more accurate and can drift only a second in about 300 million years!1 But why do we need such highly accurate clocks? The answer is that for day-to-day use, it doesn’t matter. If the time on my wristwatch is a few seconds different from other clocks, it’s not a problem. If my post on a social media site has a timestamp that is a few seconds apart from the exact time I posted it, perhaps that is not an issue. Of course, as long as the sequence is maintained, the timestamp is acceptable within a few seconds. But the situation changes in many other practical scenarios and distributed systems. For example, high-frequency trading systems require (by regulation MiFID II) that the mechanism format the timestamp on messages in the trading system in microseconds and be accurate within 100 microseconds. From a clock synchronization point of view, only 100 microseconds divergence is allowed from UTC. While such requirements are essential for the proper functioning and regulation of the trading systems, they also pose technical challenges. In such scenarios, the choice of source of accurate time, choice of synchronization algorithms, and handling of skews and drifts become of prime importance.
You can see specific MiFID requirements here as a reference:
https://ec.europa.eu/finance/securities/docs/isd/mifid/rts/160607-rts-25-annex_en.pdf
There are other applications of atomic clocks in defense, geology, astronomy, navigation, and many others.
Recently, Sapphire clocks have been developed, which are much more precise than even cesium-based atomic clocks. It is so precise that it can lose or gain a second in three billion years.
Usually, there are two ways in which time is represented in computers. One is epoch time, also called Unix time, which is defined as the number of seconds elapsed since January 1, 1970. Another common timestamp format is ISO8601, which defines a date and time format standard.
Synchronization Algorithms for Physical Clocks
- 1.
External synchronization
- 2.
Internal synchronization
In the external clock synchronization method, there is an external and authoritative source of time to which nodes in a distributed system synchronize with.
In the internal synchronization method, clocks in nodes (processes) are synchronized with one another.
NTP
The network time protocol (NTP) allows clients to synchronize with UTC. In NTP, servers are organized in so-called strata, where stratum 1 servers (primary time servers) are directly connected to an accurate time source in stratum 0, for example, GPS or atomic clock. Stratum 2 servers synchronize with stratum 1 servers over the network, and stratum 2 servers synchronize with stratum 3 servers. This type of architecture provides a reliable, secure, and scalable protocol. Reliability comes from the use of redundant servers and paths. Security is provided by utilizing appropriate authentication mechanisms, and scalability is characterized by NTP’s ability to serve a large number of clients. While NTP is an efficient and robust protocol, inherent network latency, misconfigurations in the protocol setup, network misconfigurations that may block the NTP protocol, and several other factors can still cause clocks to drift.
GPS As a Time Source
A GPS receiver can be used as an accurate source of time. All 31 GPS satellites have atomic clocks on board, which produce precise time. These satellites broadcast their location and time, where GPS receivers receive and calculate time and position on earth after applying some corrections for environmental factors and time dilation. Remember, time runs slightly faster on GPS satellites than objects on the earth’s surface due to relativity. Other relativity-related effects include time dilation, gravitational frequency shift, and eccentricity effects. All these errors are handled, and many other corrections are made before an accurate time is displayed on the GPS receiver. While the GPS as a source of precise time is highly accurate, the inherent latency introduced even after the existence of correct and accurate time at the GPS receiver in the network can lead to drift and skew of clocks over time. There is a need to introduce some clock synchronization algorithms to address this limitation.
A combination of atomic clocks and GPS is used in Google’s spanner (Google’s globally distributed database) for handling timing uncertainties.
However, note that even with all the efforts, the clocks cannot be perfectly synchronized, which is good enough for most applications. However, these very accurate clocks are still not enough to capture the causality relationship between events in a distributed system. The causality relationship between events and the fundamental monotonicity property can be accurately captured by logical clocks.
In distributed systems, even if each process has a local clock and is synchronized with some global clock source, there is still a chance that each local processor would see the time differently. The clocks can drift over time, the processors can experience bugs, or there can be an inherent drift, for example, quartz clocks or GPS systems, making it challenging to handle time in a distributed system.
Imagine a distributed system with some nodes in the orbit and some in other geographical locations on earth, and they all agree to use UTC. The physical clocks in satellites or ISS will run at a different rate, and skew is inevitable. The core limitation in depending on physical clocks is that even if trying to synchronize them perfectly, timestamps will be slightly apart. However, these physical clocks cannot (should not) be used to establish the order of events in a distributed system because it is difficult to accurately find out the global order of events based on timestamps in different nodes.
Physical clocks are not very suitable for distributed systems because they can drift apart. Even with one universal source, such as the atomic clock through NTP, they can still drift and desynchronize over time with the source. Even a difference of a second can sometimes cause a big issue. In addition, there can be software bugs in the implementation that can cause unintentional consequences. For example, let’s look at a famous bug, the leap second bug that is a cause of significant disruption of Internet services.
UTC Time
- International atomic time (TAI)
TAI is based on around 400 atomic clocks around the world. A combined and weighted output from all these atomic clocks is produced. This is extremely accurate where they only deviate one second in around 100 million years!
- Astronomical time
This time is based on astronomical observations, that is, the rotation of the Earth.
While TAI is highly accurate, it doesn’t consider the Earth’s rotation, that is, the astronomically observed time that determines the true length of the day. Earth’s rotation is not constant. It is occasionally faster and is slowing down overall. Therefore, days are not exactly 24 hours. The impact on Earth’s rotation is due to celestial bodies such as the moon, tides, and other environmental factors. Therefore, UTC is kept in constant comparison with the astronomical time, and any difference is added to UTC. This difference is added in the form of leap second; before the difference between TAI and astronomical time reaches 0.9, a leap second is added to the UTC. This is the practice since 1972.
OK, this seems like a reasonable solution to keep both times synced; however, computers don’t seem to handle this situation well. Unix systems use Unix time (epoch), simply the number of seconds elapsed since January 1, 1970. When a leap second is added, this is how the clock looks like: in a normal case, it is observed that after 23:59:59, there is 00:00:00. However, adding a leap second seems as if after 23:59:59, there is 23:59:60 and then 00:00:00. In other words, 23:59:59 happens twice. When Unix time deals with this addition of an extra second, it can produce arbitrary behavior. In the past, when a leap second is added, servers across the Internet experienced issues and services as critical as airline booking systems were disrupted.
A technique called "leap smear" has been developed, which allows for the gradual addition of a few milliseconds over a day to address this issue of sudden addition and problem associated with this sudden one-second additional.
OK, so far, we have seen that UTC and astronomical time are synced by adding a leap second. With the "leap second smear" technique, we can gradually add a leap second over time, which alleviates some of the issues associated with sudden additional leap second. There are also calls to abolish this ritual altogether. However, so far, we see adding a leap second as a reasonable solution, and it seems to work somewhat OK. We just add a leap second when the Earth’s rotation slows down, but what if the Earth is spinning faster? In 2020, the Earth indeed spun faster, during the pandemic, for whatever reason. Now the question is, do we remove one second from UTC? In other words, introduce the negative leap second! This situation can pose some more challenges – perhaps even more demanding to address as compared to adding a leap second.
The question is, what to do about this, ignore this? What algorithm can help to remove one second and introduce a negative leap second?
So far, it is suggested that simply skip 23:59:59, that is, go from 23:59:58 to 00:00:00 directly. It is expected that this is easier to deal with as compared to adding a leap second. Perhaps, a solution is unnecessary because we may ignore the Earth spinning faster or slower altogether and abolish the leap second adjustment practice, either negative or positive. It is not ideal, but we might do that to avoid issues and ambiguity associated with handling leap seconds, especially adding leap seconds! At the time of writing, this is an open question.
Some more info are found here: https://fanf.dreamwidth.org/133823.html (negative leap second) and www.eecis.udel.edu/~mills/leap.html.
To avoid limitations and problems associated with physical clocks and synchronization, for distributed systems, we can use logical clocks, which have no correlation with physical clocks but are a way to order the events in a distributed system. Although, as we have seen, ordering of events and a causal relationship is an essential requirement in distributed systems, logical clocks play a vital role in ensuring this in distributed systems.
From a distributed system point of view, we learned earlier that the notion of global state is very important, which allows us to observe the state of a distributed system and helps to snapshot or checkpoint. Thus, time plays a vital role here because if time is not uniform across the system (each processor running at a different time), and we try to read states from all different processors and links in a system, it will result in an inconsistent state.
Types of Physical Clocks
- 1.
Time-of-day clocks
- 2.
Monotonic clocks
Time-of-day clocks are characterized by the representation of time since a fixed point in time. For example, Unix time that is calculated from January 1, 1970 is an example of a time-of-day clock. The time can be adjusted via synchronization to a time source and can move backward or forward. However, moving the time backward is not a good idea. Such a scenario can lead to situations where, for example, it would appear that a message is received before it was sent. This issue can happen due to the timestamp being adjusted and moving backward in time due to adjustments made by the synchronization algorithms, for example, NTP.
As the time always increases, time shouldn’t go backward; we need monotonic clocks to handle such scenarios.
With physical clocks, it is almost impossible to provide causality. Even if time synchronization services are used, there is still a chance that the timestamp of one process differs from another just enough to impact the order of events adversely. Thus, the ordering of events is a fundamental requirement in distributed systems. To fully understand the nature of this ordering requirement, we use a formal notion of something called "happens-before relationship."
Just before we introduce the happens-before relationship and causality, let us clarify some basic math concepts first. This will help us to not only understand causality but will also help with concepts explained later in this book.
Set

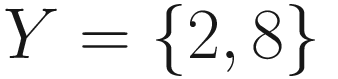

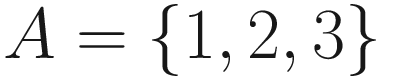

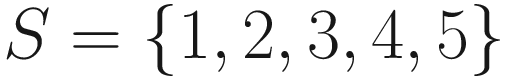
The cartesian product of two sets A and B is the set of ordered pairs (a, b) for each element in sets A and B. It is denoted as A × B. It is a set of ordered pairs (a, b) for each a ∈ A and b ∈ B.
An ordered pair is composed of two elements inside parentheses, for example, (1, 2) or (2, 1). Note here that the order of elements is important and matters in the case of ordered pairs, whereas in sets the order of elements does not matter. For example, (1, 2) is not the same as (2, 1), but {1,2} and {2,1} are the same or equal sets.
An example of a cartesian product, A × B, for sets shown earlier is
{(1,3), (1,4), (1,5), (2,3), (2,4), (2,5), (3,3), (3,4), (3,5)}
Note that in the ordered pair, the first element is taken from set A and the second element from set B.
Relation
A relation (binary) between two sets A and B is a subset of the cartesian product A × B.
The relationship between two elements is binary and can be written as a set of ordered pairs. We can express this as a R b (infix notation) or (a, b) in R, meaning the ordered pair (a, b) is in relation R.
When a binary relation on a set S has properties of reflexivity, symmetry, and transitivity, it is called an equivalence relation.
When a binary relation on a set S has three properties of reflexivity, antisymmetry, and transitivity, then it is called a partial ordering on S.
Partial Order
It is a binary relation ≤ (less than or equal to – for comparison) between the elements of a set S. A binary relation on a set S, which is reflexive, antisymmetric, and transitive, is known as a partial ordering on S. We now define the three conditions.
Reflexivity
This property means that every element is related to itself. Mathematically, we can write it like this: ∀a ∈ S, a ≤ a.
Antisymmetry
This means that two elements cannot be related in both directions. Mathematically, it can be written as ∀a, b ∈ S, if a ≤ b ∧ b ≤ a, a = b.
Transitivity
The transitive property indicates a comparative relationship where if a < b and b < c, it implies that a < c. Mathematically, it can be written as ∀a, b, c ∈ S, if a ≤ b ∧ b ≤ c then a ≤ c.
A set with a partial order is called a partially ordered set or poset. In terms of the happens-before relationship, the set S is a set of all events.
Irreflexive Partial Order
The irreflexive partial order or strict partial order is irreflexive, antisymmetric, and transitive.
Irreflexive
This property means that there is no element that is related to itself. Mathematically, we can write it like ∀a ∈ S, a ≰ a, or given a relation R on a set S, R is irreflexive if ∀s ∈ S : (s, s) ∉ R.
Total Order
A total order or linear order is a partial order in which each pair of elements is comparable.
After this brief introduction to some math concepts, let us now look into what causality is and what is a happens-before relationship.
Happens-Before Relationship and Causality
We saw earlier that a node could perform some events. It can either do the local computation, send a message, or receive a message. All events happen in a sequential order on a single node, and it is easy to see what happened before the next event. It is a strict total order imposed on each node.
A happens-before relationship is an irreflexive partial order (strict partial order) with three properties: irreflexivity, antisymmetry, and transitivity.
Now imagine there are two events e and f that have happened. To ascertain if event e happened before event f, we use the following rules.
If e and f occurred on the same process and e executed before f on this process, then we can deduce that e precedes f, that is, a sequential order.
Event e is a message send event of some (unique) message m, and event f is the receipt of message m.
If there exists an event g such that e→g and g→f, then e→f. This is called a transitive relationship.

A schematic with 3 right arrows labeled P and 2 right arrows labeled Q below it. The lines have elements like E, F, and G.
Happens-before rules

A schematic with 3 right arrows labeled P, Q, and R. The arrows have elements like E, F, G, H, I, and J. Some of the elements are connected together.
Example happens-before relationship
In Figure 1-24, the relations e → f, g → h, i → j are due to the order in which processes execute the events. The relations f → g, h → j are due to messages m1 and m2. Moreover e → g, e → h, e → j, f → h, f → j, g → j represent transitive relation. Finally, the concurrent events are e ∥ i, f ∥ i, g ∥ i, h ∥ i.
Logical Clocks
Logical clocks do not depend on physical clocks and can be used to define the order of events in a distributed system. Logical clocks only measure the order of events without any reference to external physical time.
Lamport Clocks
A Lamport clock is a logical counter that is maintained by each process in a distributed system, and with each occurrence of an event, it is incremented to provide a means of maintaining and observing a happens-before relationship between events occurring in the distributed system.
The key idea here is that each event is assigned a number which increments as the event occurs in the system. This number is also called the Lamport clock. A Lamport clock captures causality.
Every process maintains a local counter which is set to zero at initialization.
With every event on a process, the counter is incremented by one by that process.
When a message is sent, a process includes its current value of the counter.
When a message is received, a process sets its counter value to max(local + received) + 1.
In a happens-before relationship where e → f, we can say that possibly e caused f. This means that the happens-before relationship captures causality of the events.
Lamport clock
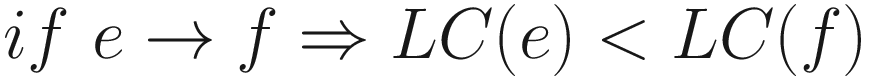
This means that if e happened before f, then it implies that the timestamp (Lamport clock – LC) of event e is less than the timestamp of event f.
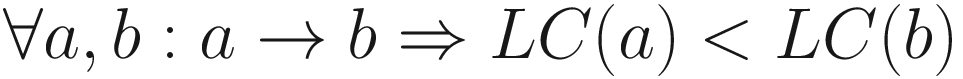
This is read as follows: for all a and b, a happened before b implies that the Lamport clock (timestamp) of a is less than the Lamport clock (timestamp) of b.
This means that if event A happens before event B, then it implies that the Lamport clock of event A is less than the Lamport clock of event B.
Now we can see a picture emerging. Without using physical clocks, we can now see how events in a distributed system can be assigned a number which can be used for ordering them by using Lamport clocks.
Now let’s run this algorithm on a simple distributed system composed of three processes (nodes, computers) – P, Q, and R.
- 1.
If a → b, then LC(a) < LC(b).
- 2.
But LC(a) < LC(b) does not mean that a → b.

A schematic with 3 lines labeled P, Q, and R. The lines have events like (P, 1), (Q, 3), and so on. Some of the events are connected together via time.
Example run of a Lamport clock algorithm
One obvious way to fix this is to use an identifier for the process with the timestamp. This way, the total order can be achieved.

A schematic with 3 lines labeled P, Q, and R. The lines have events like (P, 1), (Q, 3), and so on. Some of the events are connected together via time.
Example run of a Lamport clock with a total order
Knowing the order of events in a distributed system is very useful. The order of events allows us to find the causality between the events. The knowledge of causality in distributed systems helps to solve several problems. Some examples include but are not limited to consistency in replicated databases, figuring out causal dependency between different events, measuring the progress of executions in a distributed system, and measuring concurrency.
We can use it to build distributed state machines. If events are timestamped, we can also see when exactly an event has occurred and what happened before and what occurred after, which can help debug and investigate distributed systems’ faults. This knowledge can be instrumental in building debuggers, snapshotting a point in time, pruning some data before a point in time, and many other use cases.
The limitation that LC(a) < LC(b) does not mean that a → b. This means that Lamport clocks cannot tell if two events are concurrent or not. This problem can be addressed using vector clocks.
Vector Clocks
At the start, all vector clocks in a distributed system are set to zero, that is, [0,0,0,0,0].
Whenever an internal event occurs at a process, the process’s logical clock value in the vector increments by one.
Whenever a process sends a message, the process’s logical clock value in the vector increments by one.
Whenever a process receives a message, the process’s logical clock value in the vector increments by one.
Each element in the vector increments.
Faults and Fault Tolerance
Faults in a distributed system are inevitable. In fact, distributed systems are characterized by faults. A large body of work is dedicated to fault tolerance and is at the core of the distributed systems research. To understand faults, let’s look at a small example.

A schematic of distributed system with 2 nodes P 1 and P 2 joined together via communication link.
A simplest distributed system
The processor p1 or p2 may crash.
Communication link can fail.
Latency on the communication link.
Slow processing at p1 or p2.
P1 can pretend that it sent some message; in fact, it has not.
Process/program faults
Communication/link faults
Storage faults
There are several types of faults that have been formally defined in distributed systems literature. These types are categorized under the so-called fault model which basically tells us which kind of faults can occur.
We now define each one of these as follows.
Crash-Stop
In this scenario, a process can fail to stop a function at any point in time. This can happen when a hardware fault may have occurred in a node. Other nodes are unable to find out about the crash of the node in this model.
Fail-Stop
In this model, a process can fail by stopping execution of the algorithm. Other nodes in the distributed system can learn about this failure, usually by using failure detectors.
Omission Faults
Omission faults are where a message can be lost.
Send Omission
This is where a process fails to send a message.
Receive Omission
This is where a process fails to receive a message.
General Omission
This is where a process may exhibit either a send omission or a receive omission.
Covert Faults
This model captures a behavior where a failure might remain hidden or undetected.
Computation Faults
In this scenario, we capture the situation where a processor responds incorrectly.
Byzantine Faults
This model captures the arbitrary faults where a process may fail in arbitrarily many ways.
Byzantine Faults with Authentication
In this model, a process can exhibit arbitrary behavior; however, there is a verification of received messages to this process, which is possible by using authentication and digital signatures. This nonrepudiation and verification can make dealing with Byzantine faults a bit easier.
Byzantine Faults Without Authentication
In this model, a process can exhibit arbitrary behavior, but no message verification is possible to ascertain the validity of the messages.
Timing Faults
This is where a process can exhibit slow behavior or may run faster than other processes. This can initially look like a partially synchronous behavior, but a node that has not received a message for a very long time can be seen as one example of this type of fault. This covers scenarios where an expected message delivery is not in line with the expected delivery time or lies outside the specified time interval.
Failures can be detected using failure detectors where a process can be suspected of a failure. For example, a message not received for an extended period of time or that has gone past the threshold of timeout can be marked as a failed process.
More on failure detector in Chapter 3; now let’s discover what a fault model is and fault classes.

A schematic with 5 non concentric circles. The components from the outer circle are byzantine, computation, timing, omission, crash faults.
Diagram of fault models and fault classes
Fault classes allow us to see what faults can occur, whereas fault models help us to see what kind of faults the system can exhibit and what types of faults should be tolerated in our distributed algorithm.
A system or algorithm that can tolerate crash faults only is called a crash fault tolerant or CFT in short. In contrast, a system that can handle Byzantine faults is called the Byzantine fault–tolerant system or algorithm. Usually, this applies to consensus mechanisms categorized and developed with the goal of crash fault tolerance or Byzantine fault tolerance. We will see more about this in Chapter 3, where we discuss consensus algorithms.
Safety and Liveness
Remember we discussed in communication abstractions that broadcast protocols and point-to-point links have some properties. For example, a fair-loss property ensures that messages sent will eventually be delivered under fair-loss links. This type of property where something will eventually happen is considered a liveness property. Colloquially speaking, this means that something good will eventually occur.
Also, remember that under the finite duplication property for fair-loss links, we said that there are finite message duplications. This type of property where something can be measured and observed infinite time is called a safety property. Colloquially speaking, this means that something bad never happens. Of course, if you don’t do anything, then nothing will ever happen, which theoretically satisfies the safety property; however, the system is not making any progress in this scenario. Therefore, the liveness property, which ensures the progress of the system, is also necessary.
These properties are used in many different distributed algorithms to reason about the correctness of the protocols. In addition, they are frequently used in describing the safety and liveness requirements and properties of consensus protocols. We will cover distributed consensus in detail in Chapter 3.
Safety and liveness are correctness properties of a distributed algorithm. For example, the safety and liveness of traffic signals at a crossing can be described as follows. The safety properties in this scenario are that, at a time, only one direction must be a green light, and no signal should have all lights turned on at the same time. Another safety property could be that the system should turn off no signals. And the liveness property is that, eventually, each signal must get the green light.
For example, in a partially synchronous system, to prove safety properties, it is assumed that the system is asynchronous, whereas to prove the liveness of the system, the partial synchrony assumption is used. The progress of liveness of the system is ensured in a partially synchronous system, for example, after GST when the system is synchronous for long enough to allow the algorithm to achieve its objective and terminate.
For a distributed system to be practical, safety and liveness properties must be specified and guaranteed.
Forms of Fault Tolerance
A correct program (distributed algorithm) satisfies both its safety and liveness properties. If a program tolerates a given class of faults and remains alive and safe, we call this type of fault tolerance masking. If a program can remain safe but not live, we call this type of fault tolerance fail-safe. Similarly, in the presence of faults, a program cannot remain safe (not safe) but remains live. Such behavior is called nonmasking. If a program is neither live nor safe in the presence of faults, it means that this program does not depict any form of fault tolerance.
CAP Theorem
The CAP theorem states that a distributed system can only deliver two of three desired features, that is, consistency, availability, and partition tolerance. Let’s first define these terms, and then we’ll investigate the theorem in more detail.
Consistency
The consistency property means that data should be consistent across all nodes in the distributed system, and the client connecting to the distributed system at the same time should see the same consistent data. This is commonly achieved using replication.
Availability
Availability means the distributed system responds to the client requests even in the presence of faults. This is achieved using fault tolerance techniques such as replication, partitioning, or sharding.
Partition Tolerance
A partition refers to a scenario where the communication link between two or more nodes breaks. A distributed system should be able to tolerate that and continue to operate correctly.
We know that partitions in a network are almost inevitable; sooner or later, there will be some communication disruption. This means that as network partitions are unavoidable, the choice really becomes to choose between availability and consistency. The question becomes, in the case of partitions, what we are willing to sacrifice, consistency or availability. It all depends on the use case. For example, in a financial application, it’s best to sacrifice availability in favor of consistency, but perhaps on web search results, we could sacrifice a bit of consistency in favor of availability. It should be noted that when there are no network partitions, consistency and availability are both provided. But then again, if a network partition occurs, then what do we choose, availability or consistency?

A schematic with 3 intersecting circles for consistency, availability, and partition. C A, A P, and C P are the intersection areas.
CAP theorem
The CAP theorem allows us to categorize databases (NoSQL DBs) based on the properties they support. For example, a CP database provides consistency and partition tolerance but sacrifices availability. In the case of a partition, the nonconsistent nodes are shut down until the network partition heals. An AP database sacrifices consistency but offers availability and partition tolerance. In the case of a network partition, there is a chance that nodes that have not been able to get the updates due to a network partition will continue to serve old data. This might be acceptable in some scenarios, such as a web search. When the partition heals, the out-of-sync nodes are synchronized with the latest updates. On the other hand, a CA database is not partition tolerant and can provide both consistency and availability only if the network is healthy. As we saw earlier, network partitions are inevitable; therefore, CA databases only exist in an ideal world where no network partitions occur.
While the CAP theorem is helpful, there are many other more precise impossibility results in distributed computing.
Let’s now discuss what eventual consistency is. Eventual consistency refers to a situation where nodes may disagree or not update their local database, but, eventually, the state is agreed upon and updated.
One example of such a scenario could be when an electronic voting system captures voters’ votes and writes them to a central vote registration system. However, it could happen that due to a network partition, the communication link in the central vote registration system is lost, and this voting machine is now not able to write data to the backend voting registration system. It could now keep receiving votes from the user and record them locally, and when the network partition heals, it can write the ballots back to the central vote registration system. During the network partition from the central vote registration system’s point of view, the count of votes is different from what the voting machine can see. The machine can write back to the central vote registration system when the partition heals to achieve consistency. The consistency between the backend server storage and local storage is not achieved immediately, but, over time, this type of consistency is called eventual consistency.
A now established example of an eventually consistent system is Bitcoin. We will learn more about this in Chapter 4 and see how Bitcoin is eventually consistent.
The domain name system (DNS) is the most prevalent system that implements eventual consistency. When a name is updated, it is distributed as per a configured pattern, and, eventually, all clients see the update.
Through the lens of the CAP theorem, the distributed consensus is a CP system where availability is sacrificed in favor of consistency. As a result, the distributed consensus is used to provide strong consistency guarantees.
For example, if you have a five-node system and three nodes go down, then the whole system stalls until the other three nodes come up. This is so that a consistency guarantee can be maintained, even if the system is not available for some time.
If we look at Bitcoin, it appears that it is an AP system where consistency is sacrificed for some time due to forks, but, eventually, the consistency is achieved. Therefore, Bitcoin can also be considered a CP system where consistency is eventually strong.
Usually, strong consistency (also called linearizability) is for what distributed consensus is used for; however, eventual consistency in systems like Bitcoin is also acceptable.
Cryptography in Distributed Systems
Distributed systems operate under challenging conditions where they are exposed to adversaries, faults, and untrusted users. In such conditions, it becomes critical to protect the distributed system against all these threats. Therefore, appropriate security measures are put in place to thwart any attempts to disrupt the system.
The usual security services required in a distributed system include confidentiality, integrity, access control, and authentication. To this end, cryptography plays a vital role in distributed systems.
Cryptographic protocols provide security services in a distributed system by utilizing cryptographic primitives such as symmetric cryptography, asymmetric cryptography, and hash functions.
We will cover this topic in Chapter 2, where we study cryptography in general and its applications in distributed systems and blockchain. Chapter 2 will introduce several primitives that are useful in consensus protocols and blockchain for achieving data integrity and relevant security purposes.
Summary
A distributed system is a set of interconnected computers coordinating together via messages to achieve a common goal.
Distributed systems face several challenges. The most prominent are (1) no common global knowledge, (2) no global time, (3) achieving consistency, and (4) failures.
A distributed system model allows us to reason about the system and abstract away all unnecessary details.
The leap second bug that is a cause of significant disruption of Internet services and several techniques has been developed to address this.
Safety and liveness properties must be ensured in distributed systems.
Crash fault–tolerant distributed algorithms only handle crash faults, whereas Byzantine fault–tolerant algorithms are designed to handle arbitrary faults.
Logical clocks do not depend on physical clocks and can be used to define the order of events in a distributed system.
In a distributed system, the same algorithm runs on all computers concurrently to achieve a common goal.
The CAP theorem states that a distributed system can only deliver two of three desired features, that is, consistency, availability, and partition tolerance.
Bibliography
- 1.
Safety and liveness properties were first formalized in a paper by Alpern, B. and Schneider, F.B., 1987. Recognizing safety and liveness. Distributed computing, 2(3), pp. 117–126.
- 2.
Notion of timing and ordering of events was first introduced in 1978 in "Lamport, L., 2019. Time, clocks, and the ordering of events in a distributed system. In Concurrency: the Works of Leslie Lamport (pp. 179–196)."
- 3.
Cachin, C., Guerraoui, R., and Rodrigues, L., 2011. Introduction to reliable and secure distributed programming. Springer Science & Business Media.
- 4.
Brewer, E.A., 2000, July. Towards robust distributed systems. In PODC (Vol. 7, No. 10.1145, pp. 343477–343502).
- 5.
Van Steen, M. and Tanenbaum, A., 2002. Distributed systems principles and paradigms. Network, 2, p. 28.
- 6.
Coulouris, G., Dollimore, J., and Kindberg, T. Distributed Systems: Concepts and Design Edition 3. System, 2(11), p. 15.
- 7.
Kleppmann, M., 2017. Designing data-intensive applications: The big ideas behind reliable, scalable, and maintainable systems. O’Reilly Media, Inc.
- 8.
Kleppmann, M., Distributed Systems. Vancouver.
- 9.
Sapphire clocks: https://sciencemeetsbusiness.com.au/sapphire-clock/
- 10.
Sapphire clocks: https://spectrum.ieee.org/for-precision-the-sapphire-clock-outshines-even-the-best-atomic-clocks?utm_campaign=post-teaser&utm_content=7190c3vu
- 11.
Bashir, I., 2020. Mastering Blockchain: A deep dive into distributed ledgers, consensus protocols, smart contracts, DApps, cryptocurrencies, Ethereum, and more. Packt Publishing Ltd.
- 12.
Baran, Paul. On Distributed Communications: I. Introduction to Distributed Communications Networks. Santa Monica, CA: RAND Corporation, 1964. www.rand.org/pubs/research_memoranda/RM3420.html. Also available in print form.