
Blockchain consensus is the core element of a blockchain, which ensures the integrity and consistency of the blockchain data. Blockchain being a distributed system, in the first instance, it may appear that we can apply traditional distributed consensus protocols, such as Paxos or PBFT, to address the agreement and total order requirements in a blockchain. However, this can only work in consortium chains where participants are known and limited in number. In public chains, traditional consensus protocols cannot work due to the permissionless environment. However, in 2008 a new class of consensus algorithms emerged, which relied on proof of work to ensure random leader election by solving a mathematical puzzle. The elected leader wins the right to append to the blockchain. This is the so-called Nakamoto consensus protocol. This algorithm for the very first time solved the problem of consensus in a permissionless public environment with many anonymous participants.
We have already discussed distributed consensus from a traditional perspective in Chapter 3. In this chapter, we will cover what blockchain consensus is, how the traditional protocols can be applied to a blockchain, how proof of work works, how it was developed, and what the blockchain consensus requirements are, and we will analyze blockchain consensus such as proof of work through the lens of distributed consensus. Also, we’ll see how the requirements of consensus may change depending upon the type of blockchain in use. For example, for public blockchains proof of work might be a better idea, whereas for permissioned blockchains BFT-style protocols may work better.
Background
- 1.
Leader-based traditional distributed consensus or permissioned consensus
- 2.
Nakamoto and post-Nakamoto consensus or permissionless consensus
Leader-based protocols work on the principle of voting where nodes in a distributed system vote to perform an operation. These protocols are usually deterministic and have been researched since the 1970s. Some such protocols include Paxos, PBFT, and RAFT. Another different type of class emerged in 2008 with Bitcoin, which relied on the proof of work type of crypto puzzle. This type of protocol is probabilistic where a participant wins the right to append a new block to the blockchain by solving the proof of work.
Usually, in the blockchain world, Byzantine fault–tolerant protocols are used, especially because these blockchains are expected to either run publicly or in a consortium environment where malicious attacks are a reality. Perhaps not so much on consortium chains where the participants are known, but still due to the nature of the enterprise applications that run on these platforms, it’s best to consider a Byzantine fault–tolerant model. Applications related to finance, health, egovernance, and many other use cases run on consortium chains; therefore, it is necessary to ensure protection against any arbitrary faults including even active adversaries.
Traditional BFT vs. Nakamoto consensus
Property | Traditional BFT | Nakamoto |
|---|---|---|
Agreement | Deterministic | Eventual |
Termination | Deterministic | Probabilistic |
Energy consumption | Low | Very high |
Sybil resistance | No | Yes |
Finality | Immediate | Probabilistic |
Consistency | Stronger | Weaker (eventual) |
Communication pattern | Broadcast | Epidemic |
Throughput (TPS) | Higher | Low |
Scalability | Lower (10–100 nodes) | Higher (1000s of nodes) |
Forking | None | Possible |
Identity | Known | Anonymous (pseudonymous) |
Network | Peer to peer | Peer to peer |
Order | Temporal | Temporal |
Formal rigor (correctness proofs, etc.) | Yes | Mostly nonexistent |
Fault tolerance | 1/3, <=33% | <=25% computing power* >50% computing power |
Number of clients | Many | Many |
Another point to keep in mind is the distinction between a broadcast problem and a consensus problem. Consensus is a decision problem, whereas broadcast is a delivery problem. The properties of both are the same but with slightly different definitions. These properties include agreement, validity, integrity, and termination. In essence, broadcast and consensus are interrelated and deeply connected problems as it is possible to implement one from the other.
We will be focusing more on a consensus problem instead of a broadcast problem.
Blockchain Consensus
A blockchain consensus protocol is a mechanism that allows participants in a blockchain system to agree on a sequence of transactions even in the presence of faults. In other words, consensus algorithms ensure that all parties agree on a single source of truth even if some parties are faulty.
There are some properties that are associated with blockchain consensus. The properties are almost the same as standard distributed consensus but with a slight variation.
As a standard, there are safety and liveness properties. The safety and liveness properties change depending on the type of blockchain. First, we define the safety and liveness properties for a permissioned/consortium blockchain and then for a public blockchain.
Traditional BFT
There are several properties that we can define for traditional BFT consensus, which are commonly used in a permissioned blockchain. There are various variants, for example, Tendermint, that are used in a blockchain. We covered traditional BFT in detail in Chapter 3; however, in this section we will redefine that in the context of a blockchain and especially permissioned blockchain. Most of the properties remain the same as public permissionless consensus; however, the key difference is between deterministic and probabilistic termination and agreement.
Agreement
No two honest processes decide on a different block. In other words, no two honest processes commit different blocks at the same height.
Validity
If an honest process decides on a block b, then b satisfies the application-specific validity predicate valid (). Also, the block b agreed must be proposed by some honest node.
Termination
Every honest process decides. After GST, every honest process continuously commits blocks.
Agreement and validity are safety properties, whereas termination is a liveness property.
Integrity
A process must decide at most once in a consensus round.
Other properties can include the following.
Chain Progress (Liveness)
A blockchain must keep growing by continuously appending new blocks to it after GST.
Instant Irrevocability
Once a transaction has made it to the block and the block is finalized, the transaction cannot be removed.
Consensus Finality
Finality is deterministic and immediate. Transactions are final as soon as they’ve made it to the block, and blocks are final as soon as they’ve been appended to the blockchain.
While there are many blockchain consensus algorithms now, Nakamoto consensus is the first blockchain protocol introduced with Bitcoin, which has several novel properties. Indeed, it is not a classical Byzantine algorithm with deterministic properties; instead, it has probabilistic features.
Nakamoto Consensus
The Nakamoto or PoW consensus can be characterized with several properties. It is commonly used in public blockchains, for example, Bitcoin.
Agreement
Eventually, no two honest processes decide on a different block.
Validity
If an honest process decides on a block b, then b satisfies the application-specific validity predicate valid (). Also, the transactions within the block satisfy the application-specific validity predicate valid(). In other words, only valid and correct transactions make it to the block, and only correct and valid blocks make it to the blockchain. Only valid transactions and blocks are accepted by the nodes. Also, mining nodes (miners) will only accept the valid transactions. In addition, the decided value must be proposed by some honest process.
Termination
Every honest process eventually decides.
Agreement and validity are safety properties, whereas termination is a liveness property.
In public blockchain networks, an economic incentive is usually associated with the consensus properties so that participants who are working toward ensuring the safety and liveness of the network are economically incentivized to do so.
Remember we discussed randomized algorithms earlier in Chapter 3, where termination is guaranteed probabilistically. Randomized protocols are used to circumvent FLP impossibility. Usually, the termination property is made probabilistic to achieve an agreement to circumvent FLP impossibility. However, with the Bitcoin blockchain, the agreement property is made probabilistic instead of termination. Here, the safety property is somewhat sacrificed because in the Bitcoin blockchain, it is allowed that temporarily a fork can occur, and when the fork is resolved, some previously finalized transactions are rolled back. This is due to the longest chain rule.
There are a few other properties which we describe now.
Consensus Finality
With two correct processes p1 and p2, if p1 appends a block b to its local blockchain before another block b’, then no other correct node appends b’ before b.
For a proof of work blockchain point of view, we can further carve out some properties.
Chain Progress (Liveness)
A blockchain must keep growing steadily by new blocks continuously being appended to it every n interval. N can be a predefined time interval defined by the protocol.
Consistent/Consistency
The blockchain must eventually heal a forked chain to arrive at a single longest chain. In other words, everyone must see the same history.
Eventual Irrevocability
The probability of a transaction being rolled back decreases with more blocks appended to the blockchain. This is a crucial property from end users’ point of view as this property gives confidence to the users that after their transaction has been made part of a block and it’s been finalized and accepted, then new blocks being added to the blockchain further ensure that the transaction is permanently and irrevocably part of the blockchain.
Table 5-1 shows some key differences between traditional BFT and Nakamoto consensus.
Now we turn our attention to system models, which are necessary to describe as they capture the assumption that we make about the environment in which blockchain consensus protocols will operate.
System Model
Blockchain consensus protocols assume a system model under which they guarantee the safety and liveness properties. Here, I describe two system models, which are generally applicable to public and permissioned blockchain systems, respectively.
Public Blockchain System Model (Permissionless)
A blockchain is a distributed system where nodes communicate via message passing. The broadcast protocol is usually probabilistic in the case of a public blockchain where transactions (messages) are disseminated by utilizing a gossip-style protocol.
Usually, the network model is asynchronous as there is no bound on the processor delay or communication delay, especially because a public blockchain system is most likely to be heterogenous and geographically dispersed. Nodes do not know each other, nor do they know how many total nodes are there in the system. Nodes can arbitrarily join and drop off the network. Anyone can join by simply running the protocol software on the network.
Consortium Blockchain System Model (Permissioned)
In this model, blockchain nodes communicate via message passing. A broadcast protocol is usually a one-to-all communication within the consensus protocol. For example, in PBFT the leader broadcasts its proposal in one go to all replicas, instead of sending it to a few, and then those other nodes send it to other nodes, as we saw in gossip dissemination. Moreover, the network model is partially synchronous. More precisely, blockchain consensus protocols are modelled under an eventually synchronous model where after an unknown GST the system is guaranteed to make progress.
Now let’s turn our attention to the first blockchain consensus protocol and explore how it works: the proof of work protocol or Nakamoto consensus.
First Blockchain Consensus
The proof of work consensus algorithm or Nakamoto consensus was first introduced with the Bitcoin blockchain in 2008. It is fundamentally a leader election algorithm where a mandatory and random waiting time is imposed between leader elections. This also serves as a Sybil attack mechanism. One of the weaknesses in traditional distributed consensus protocols is that they need each participant to be known and identifiable in the protocol. For example, in PBFT all participants must be known and identifiable. This limitation (albeit useful in consortium chains) makes BFT-style protocols somewhat unsuitable for public chains. This is so because an attacker can create multiple identities and can use those multiple nodes/identities to vote in their favor. This is the so-called Sybil attack. If somehow we can make creating and then using that identity on a blockchain an expensive operation, then such a setup can thwart any Sybil attack attempts and will prevent an attacker from taking over the network by creating multiple fake identities.
The term Sybil attack is coined after a book named Sybil published in 1973, where the main character in the book named Sybil Dorsett has multiple personality disorder.
The first proof of work was introduced by Dwork and Naor in 1992 [1]. This work was done to combat junk emails whereby associating a computational cost, that is, pricing functions, with sending emails results in creating a type of access control mechanism where access to resources can only be obtained by computing a moderately hard function which prevents excessive use. Proof of work has also been proposed in Adam Back’s Hashcash proposal [10].
The key intuition behind proof of work in a blockchain is to universally slow down the proposals for all participants, which achieves two goals. First, it allows all participants to converge on a common consistent view, and, second, it makes Sybil attacks very expensive, which helps with the integrity of the blockchain.
It has been observed that it is impossible (impossibility results) to achieve an agreement in a network where participants are anonymous even if there is only one Byzantine node [2]. This is due to the Sybil attack, which can create arbitrarily many identities to game the system in attackers’ favor by voting many times. If there is a way to prevent such attacks, only then there is some guarantee that the system will work as expected; otherwise, the attacker can create arbitrarily many identities to attack the system. This problem was solved practically by proof of work consensus or Nakamoto consensus [3]. Before Bitcoin, the use of moderately hard puzzles to assign identities in an anonymous network was first suggested by Aspnes [4]. However, the solution that Aspnes introduced requires authenticated channels, whereas in Bitcoin unauthenticated communication is used, and puzzles are noninteractive and publicly verifiable.
So even in the presence of the abovementioned impossibility results in classical literature, Nakamoto consensus emerged, which for the first time showed that consensus can be achieved in a permissionless model.
Remember we discussed random oracles in Chapter 3. In proof of work, hash functions are used to instantiate random oracles. Since the output of hash functions is sufficiently long and random, an adversary cannot predict future hashes or can cause hash collisions. These properties make SHA-256 a good choice to use it as a hash function in the proof of work mechanism.
The key requirement in a blockchain is to totally order the transactions. If all participants are known and the scale is limited to a few nodes, then we can use traditional consensus like BFT; however, with thousands of unknown nodes, traditional BFT cannot be used. The proof of work consensus mechanism addresses this issue.

A graph plots performance versus node scalability. It has 3 horizontal parallel lines. The top line is A B F T at y equals 10000.
Performance vs. scalability
The proof of work or Nakamoto consensus protocol is a Byzantine fault–tolerant protocol because it can tolerate arbitrary faults. It can be seen as an eventual Byzantine agreement mechanism.
How PoW Works
Consistency: New blocks are replicated to all nodes.
Linked with previous block: A log is maintained in such a way that each new entry is linked with the previous entry forming a chain.
Permissionless and open participation: Nodes can join without any access control and can leave without notice.
Partition tolerance.
Geographically dispersed.
Thousands of nodes allowed where anyone anywhere in the world can download a client and become part of the network by running the client.
Highly adversarial environment, so Byzantine fault tolerance is of prime importance.
Heterogenous where a number of different types of computers and hardware devices can join.
Asynchronous in the sense that there is no bound on the CPU or communication delays, just an eventual guarantee that messages are expected to reach all nodes with high probability.
The question is, how do you design a consensus protocol for such a difficult environment? Yet, Bitcoin PoW has stood the test of time, and apart from some limited and carefully orchestrated attacks and some inadvertent bugs, largely the Bitcoin network has been running without any issues for the last 13 years. How? I’ll explain now.
Pedagogical Explanation of PoW
Imagine a scenario where a node has proposed a block and has broadcast it to the network. The nodes that receive it can do either of two things. Either they can accept the block and append it to a local blockchain, or they can reject it if the block is not valid. Now also imagine the block is indeed valid, then the receiving nodes can simply accept it and agree on the proposed block. Imagine there is only a proposer node ever in the entire system, and that node is honest and trustworthy. This means that there is no real consensus required; the proposer node simply proposes new blocks, and nodes agree to it, resulting in an eventual total order of blocks containing transactions. But this is a centralized system with a trusted third party that, if it stays honest, as a leader, can drive the whole system because everyone trusts it. What if it turned malicious, then it’s a problem?
Perhaps, we can allow other nodes to propose as well, to take away control from that single node, which is not trustworthy. Imagine that we now have two nodes proposing valid blocks and broadcasting them on the network. Now there is a problem; some of the receiving nodes will add one block and then the other. Some wouldn’t know which one to accept or which to reject. Proposals are made at the same time, and now nodes don’t know which block to insert; perhaps, they will insert both. Now some nodes have inserted blocks from proposer 1 and the others from proposer 2 only and some from both. As you can imagine, there is no consensus here.
Imagine another scenario where two nodes simultaneously announce a block; now the receiving nodes will receive two blocks, and instead of one chain, there are now two chains. In other words, there are two logs and histories of events. Two nodes proposed a block at the same time; all nodes added two blocks. Now it is no longer a single chain, it is a tree, with two branches. This is called a fork. In other words, if nodes learn about two different blocks pointing to the same parent at the same time, then the blockchain forks into two chains.
Now in order to resolve this, we can allow nodes to pick the longest chain of blocks at that time that they know of and add the new block to that chain and ignore the other branch. If it so happens that there are two or more branches somehow with the same height (same length), then just pick up randomly one of the chains and add the new block to it. This way, we can resolve this fork. Now all nodes, knowing this rule that only the longest chain is allowed to have new blocks, will keep building the longest chain. In the case of two or more same height chains, then just randomly add the block to any of these. So far, so good! This scheme appears to work. A node decides to add the new block into a randomly chosen chain and propagates that decision to others, and other nodes add that same block to their chains. Over time, the longest chain takes over, and the shorter chain is ignored because no new blocks are added to it, because it’s not the longest chain.
But now there is another problem. Imagine a situation where a node randomly chooses one chain after a fork, adds a block to it, propagates that decision to others, other nodes add as well, and, at this point, some nodes due to latency don’t hear about the decision. Some nodes add the block they heard from another node to one of its chains, another one does the opposite, and this cycle repeats. Now you can clearly see that there are two chains, both getting new blocks. There is no consensus. There is a livelock situation where nodes can keep adding to both chains.
At this point, let’s think about what the fundamental reason is and why this livelock is occurring. The reason is that blocks are generating too fast, and other nodes receive many different blocks from different nodes, some quickly, some delayed. This asynchrony results in a livelock. The solution? Slow it down! Give nodes time to converge to one chain! Let’s see how.
We can introduce a random waiting period, which will make miners to arbitrarily sleep for some time and then mine. The key insight here is that the livelock (continuous fork) problem can be resolved by introducing a variable speed timer at each node. When a node adds a new block to its chain, it stops its timer and sends it to other nodes. Other nodes are waiting for their timers to expire, but during that waiting time, if they hear about this new block from another node, they simply stop their timers and add this new block and reset the timers and start waiting again. This way, there will only be one block added to the chain, instead of two. If the timers are long enough, then chances of forking and livelocking decrease significantly. Another thing to note here is that if there are many nodes in the system, then there is a higher chance that some timer will expire soon, and as we keep adding more and more nodes, the probability of such occurrences increases because timers are random and there are many nodes now. In order to avoid the same livelock situations, we need to increase the sleeping time of these timers as we add more nodes, so that the probability of adding a block by nodes quickly is decreased to such a level that only one node will eventually succeed to add a new block to their chain and will announce that to the network. Also, the waiting period ensures with high probability that forks will be resolved during this waiting time. It is enough time to ensure complete propagation of a new valid block so that no other block for the same height can be proposed.
Bitcoin chooses this timeout period based on the rate of block generation of 2016 blocks, which is roughly two weeks. As the block generation should be roughly a single block every ten minutes, if the protocol observes that the block generation has been faster in the last two weeks, then it increases the timeout value, resulting in slower generation of blocks. If the protocols observe that the block generation has been slower, then it decreases the timeout value. Now one problem in this timeout mechanism is that if a single node turns malicious and always manages to somehow make its timer expire earlier than other nodes, this node will end up creating a block every time. Now the requirement becomes to build a timer which is resistant to such cheating. One way of doing this is to build a trusted mechanism with some cryptographic security guarantees to act as a secure enclave in which the timer code runs. This way, due to cryptographic guarantees, the malicious node may not be able to trick the time into always expiring first.
This technique is used in the PoET (proof of elapsed time) algorithm used in Hyperledger Intel Sawtooth blockchain. We will discuss this in Chapter 8.
Another way, the original way, Nakamoto designed the algorithm is to make computers do a computationally complex task which takes time to solve – just enough to be able to solve it almost every ten minutes. Also, the task is formulated in such a way that nodes cannot cheat, except to try to solve the problem. Any deviation from the method of solving the problem will not help, as the only way to solve the problem is to try every possible answer and match it with the expected answer. If the answer matches with the expected answer, then the problem is solved; otherwise, the computer will have to try the next answer and keep doing that in a brute-force manner until the answer is found. This is a brilliant insight by Satoshi Nakamoto which ensures with high probability that computers cannot cheat, and timers only expire almost every ten minutes, giving one of the nodes the right to add its block to the blockchain. This is the so-called proof of work, meaning a node has done enough work to demonstrate that it has spent enough computational power to solve the math problem to earn the right to insert a new block to the blockchain.
Proof of work is based on cryptographic hash functions. It requires that for a block to be valid, its hash must be less than a specific value. This means that the hash of the block must start with a certain number of zeroes. The only way to find such a hash is to repeatedly try each possible hash and see if it matches the criterion; if not, then try again until one node finds such a hash. This means that in order to find a valid hash, it takes roughly ten minutes, thus introducing just enough delay which results in resolving forks and convergence on one chain while minimizing the chance of one node winning the right to create a new block every time.
Now it is easy to see that proof of work is a mechanism to introduce waiting time between block creation and ensuring that only one leader eventually emerges, which can insert the new block to the chain.
So, it turns out that PoW is not, precisely speaking, a consensus algorithm; it is a consensus facilitation algorithm which, due to slowing down block generations, allows nodes to converge to a common blockchain.
Now as we understand the intuition behind the proof of work mechanism, next we will describe how exactly the proof of work algorithm works in Bitcoin.
PoW Formula
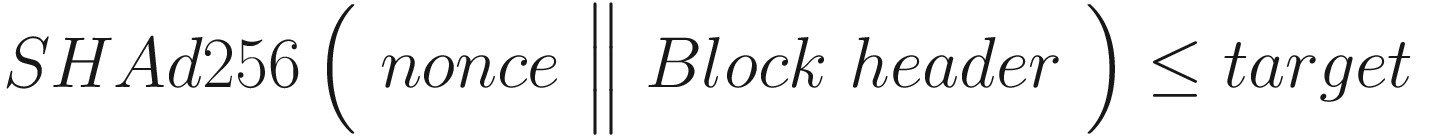
where SHAd256 represents a SHA-256 hash twice. In other words, double SHA-256 means the hash of the hash of the input. A block header consists of Version, hashPrevBlock, hashMerkleRoot, Time, Bits (difficulty target), and Nonce. Nonce is an arbitrary number that is repeatedly changed and fed into the proof of work algorithm to see if it results in a value which is less than or equal to the difficulty target.
The target value is calculated from the mining difficulty which changes every 2016 blocks, which is equivalent to roughly two weeks. If miners are mining too fast – let’s say every eight minutes, they manage to generate a block instead of ten minutes – it means there is too much hash power; therefore, as a regulation mechanism, the difficulty goes up. If miners are producing blocks over the course of the previous 2016 blocks too slowly, say 1 block every 12 minutes, then it is slower than expected; therefore, the difficulty is regulated down. Let’s go through some formulas.

This formula basically regulates the blockchain to produce new blocks roughly at a mean rate of ten minutes.
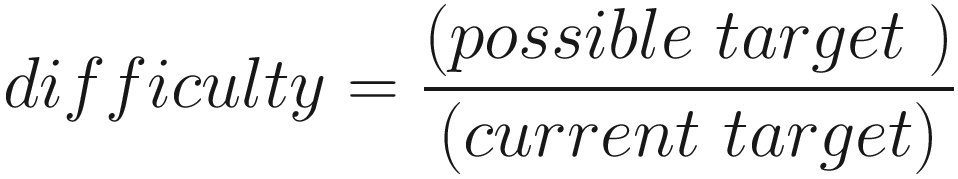
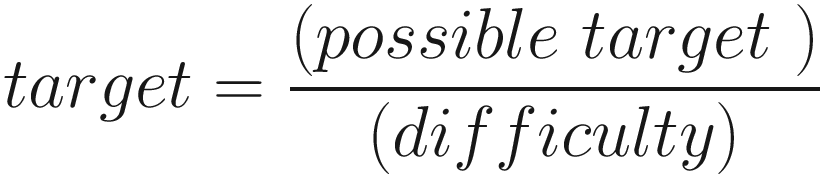
Now that we have established how the target value is calculated, let’s see what miners do and how they find a hash which satisfies the preceding equation, that is, the value obtained after hashing the block is less than the target value. In other words, the block hash must match a specific pattern where the hash starts with a certain number of zeroes. This is also known as the partial hash inversion problem. This problem is to find a partial preimage to the double SHA-256 hash function, which can only be found (if ever) by trying different inputs one by one until one of the inputs works.
Fundamentally, Bitcoin mining is the process of finding a nonce that, when concatenated with a block and hashed twice using the SHA-256 hash function, produces a number which starts with a specific number of zeroes.
So, what do miners do?
Task of Miners
Miners maintain transaction pools. They listen for incoming transactions and keep those in their pools.
They also listen for new blocks and append any new valid blocks to their chain. This is of course not only the task for a miner, other nonmining nodes also simply synchronize the blocks.
Create a candidate block by picking up transactions from the transaction pool.
Find a nonce by trying every nonce which when concatenated with the block and the previous hash results in a number which is less than the target as per formula 3 earlier.
Broadcast the newly mined block to the network.
Fetch the reward by receiving Coinbase on the address that the miner wants to send the reward to.
Let’s see what a candidate block contains and how it is created.
Block elements
Size | Description | Data Type | Explanation |
|---|---|---|---|
4 | Version | Integer | Block version |
32 | prev_block | Character | The hash value of the previous block Header |
32 | merkle_root | Character | Merkle root hash of all transaction in block |
4 | timestamp | Unsigned integer | Time of block creation in Unix time format |
4 | bits | Unsigned integer | Network difficulty target for the block |
4 | nonce | Unsigned integer | Nonce for this block |
1+ | txn_count | Variable integer | Total number of transactions |
variable | txns | tx[ ] | Transactions |

A schematic of the flow from the transaction pool to the Merkle tree root to the candidate block and finally to the Hash double S H A 256.
Transaction pool transactions to the Merkle tree and candidate block
A nonce is a number from 1 to 232 – 1, that is, a 32-bit unsigned integer which gets included in the block. Using this nonce in each iteration of checking if the resultant number is less than the target is what’s called a mining. If the resultant number is less than the target, then it’s a block mined and it’s valid, which is then broadcast to the network.
The nonce field in a block being an unsigned integer, there are only 232 nonces to try. As such, miners can run out of them quite quickly. In other words, it means that there are roughly four billion nonces to try which miners can quickly perform given the powerful mining hardware available. It also is very easy even for a normal computer to quickly check.
This of course can create an issue where no one is able to find the required nonce which produces the required hash. Even if miners try again, they will try the same thing again with the same results. At this stage, we can use other attributes of the block and use them as a variable and keep modifying the block until the hash of the block is less than the target, that is, SHAd256(Block header ‖ nonce ) < Target.
Drop the transactions, add new transactions, or pick up a new set of transactions. This modification will recalculate the Merkle root, and hence the header, and as a result, the hash will be different.
Modify the timestamp slightly (in the range of two hours; otherwise, it’s an invalid block). It can be done simply by adding just a second, which will result in a different header and consequently a different hash.
Modify Coinbase via unused ScriptSig, where you can put any arbitrary data. This will change the Merkle root and hence the header and consequently the hash.
And miners can keep modifying with different variations until they reach SHAd256(Block header ‖ nonce ) < target, which means that they’ve found a valid nonce that solves the proof of work.
The discovery of the valid hash is based on the concept known as partial hash inversion.
Proof of work has some key properties. Formally, we list them as follows.
Properties of PoW
Proof of work has five properties: completeness, computationally complex, dynamic cost adjustment, quick verification, and progress free.
Completeness
This property implies that proofs produced by the prover are verifiable and acceptable by the verifier.
Computationally Complex – Difficult to Compute – Slow Creation
The creation of proof of work is slow but not intractable. Creating proofs requires spending considerable computational resources and takes a considerable amount of time.
Auto-adjustable Cost – Dynamic Cost
This is the elegance of this protocol. First, PoW is difficult to compute. It takes considerable effort to generate proof of work. Roughly, it is more than quintillions of hashes that are checked per second on the Bitcoin network to solve the proof of work. Second, the parameters are adjustable, which means that even if blocks are produced faster or slower, no matter how much hash power is put in place or how much is removed from the network, the block generation rate roughly remains ten minutes per block. In the early days when the difficulty was one, blocks were still generated one per minute; now in 2022, even if the difficulty is roughly 25 tera hashes per second, still the protocol readjusts itself, and the block generation rate is still one per ten minutes. This is amazing and a testament to the robust design of the protocol. So, in summary if the block generation in a period of 2016 blocks is taking more than ten minutes per block, then in the next 2016 block period the difficulty will be readjusted to low. If the block generation is faster and taking less than ten minutes per block, for example, in case some bleeding-edge hardware is introduced for hashing in the network, then the difficulty will go up for the next 2016 blocks. This is how a state of balance is maintained in the network. Also note that many blocks are produced very quickly under ten minutes; some take a lot longer than that, but the average is ten minutes. This is due to the probabilistic nature of the protocol.
Quick and Efficient Verification – Quick Verification
This property implies that proofs are very quick and efficient to verify. It should not be computationally complex to verify the proof. In the case of Bitcoin, it is simply running a SHA-256 hash function twice on the block with the nonce produced by the miner, and if SHAd256(nonce ‖ block header) ≤ target, then the block is valid. It only takes as long as it takes to generate SHA-256 hash and then compare, which both are very compute-efficient processes. The key idea here is that it should be computationally complex to generate a block with a valid nonce; however, it should be easy for other nodes to verify its validity.
Progress Free
This property implies that the chance of solving the proof of work is proportional to the hash power contributed; however, it is still a chance, not a 100% guarantee that a miner with the highest hash power will always win. In other words, miners with more hash power get only proportional advantage, and miners with less power get proportional compensation too and get lucky sometimes to find blocks before even miners with more hash power.
In practice, this means that every miner is in fact working on a different candidate block to solve the proof of work. Miners are not working on the same block; they are not trying to find a valid nonce for the same hash. This is because of several differences, such as transactions, version number, Coinbase differences, and other metadata differences, which when hashed result in a totally different hash (SHA-256 twice). This means that every miner is solving a different problem and solving a different part of the double SHA-256 or conveniently written as SHAd256 search space.

A schematic of a progress-free property where each miner works on a separate block, hash, and search space in the order mentioned.
Progress free property – each miner working on a different part of double (SHA-256) search space
This is another elegant property of PoW which ensures that miners with more hash power may have some advantage, but it also means that a miner with less hash power can be lucky in finding the nonce that works before the large miners. The key point is miners are not working on the same block! If it were the same block every time, the most powerful miner would’ve won. This is called the progress free property of Bitcoin PoW.
It is however possible that many miners collaboratively work on the same block (same search space), hence dividing up the work between themselves. Imagine the search space is 1 to 100 for a block, it may be divided in 10 different parts, then all miners can collectively work on a single block. This divides up the work, and all miners can contribute and earn their share of the reward. This is called pool mining. Unlike solo mining where only one miner tries and the entire effort can be lost if it doesn’t find the nonce and tries again for the next block, in pool mining individual contribution is not wasted.

A schematic of pool mining where each miner works on the same block and hash but different search spaces.
Mining pool – many miners working on a single block (shad256 search space)
In Figure 5-4, there are different miners working on the same hash search space produced by the same block. This way, the pool operators split the proof of work into different pieces and distribute them to the miners in the pool. All miners work and put in the effort, and eventually one miner finds the block which is broadcast normally to the Bitcoin network. The pool operator receives the block reward which is split between the miners in proportion to the effort put in by the miners.
Probabilistic Aspects of Dynamic Parameters
Now let’s shed some light on the probabilistic aspects related to the property (dynamic and auto-adjustable parameters), where I will explain what the average of ten minutes means and what parameterization means.
In probability theory, a Bernoulli trial is an action that has two possible outcomes, either success or failure. The probability of success or failure is fixed between trials. For example, in coin flips the probability of heads or tails is 50%. The outcome is also independent. It is not the case that having three heads in a row will lead to a definite head for the fourth time too. Similarly, in Bitcoin mining, the outcome of success or failure, as shown in the following, remains independent and almost like coin flips roughly 50% probabilistic. We can see this in the following formula.
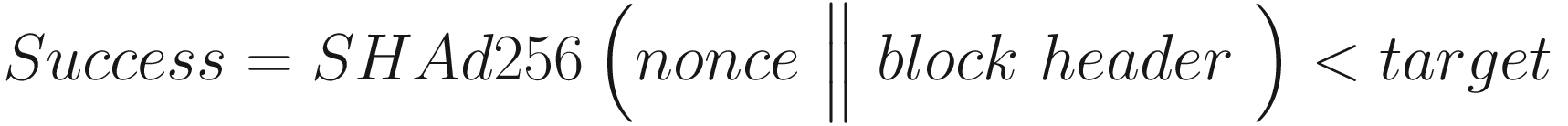
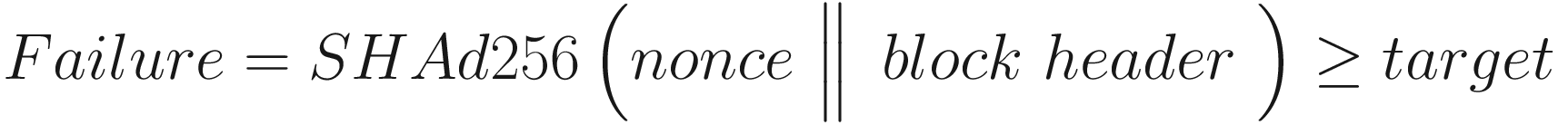
PoW is almost like roll dicing, for example, if I have rolled the dice a few times, I cannot know when the next six will occur; it might be that I get six in the first attempt, may never get six, or get six after several rolls. Similarly, whether a single nonce has been tried to find the valid nonce or trillions and trillions of nonces have been tried, the mean time until a miner finds the valid nonce remains probabilistic. It doesn’t matter whether 100 million nonces have been tried or only one; the probability of finding the valid nonce remains the same. So trying millions of nonces doesn’t make it more likely to find the valid nonce; even trying once or only a few times could find the valid nonce.
A Bernoulli trial iterated enough to achieve a continuous result instead of discrete is called a Poisson process. Formally, we can say that a Poisson process is a sequence of discrete events, where events occur independently at a known constant average rate, but the exact timing of events is random.
Events are independent of each other, that is, no influence of an outcome on some other.
The rate of events per time period is constant.
Two events cannot occur simultaneously.
The average time between events is known, but they are randomly spaced (stochastic). In Bitcoin, of course, we know the time between two block generation events is known, that is, roughly ten minutes, but the generations are randomly spaced.
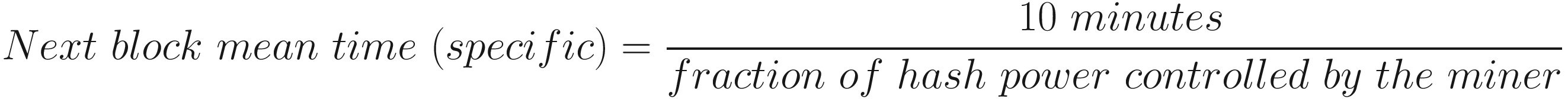
Probability of an Attacker Catching Up
In this section, we answer the question of what the probability is of an attacker to mine enough blocks to take over the chain. Suppose an attacker has some mining power, say q. A seller waits for z confirmation (z blocks) before accepting the payment, and the honest chain hash rate is denoted by p.

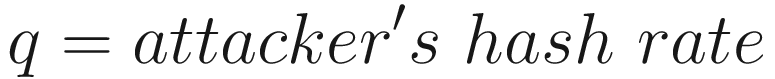

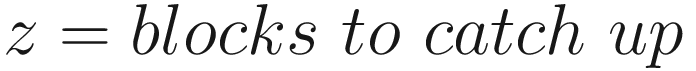
This means that if the honest hash rate is less than the attacker’s hash rate, then the probability of an attacker catching up is one, and if the honest hash rate is more than the attacker’s hash rate, then the probability of catching up is 
In the next section, we formally write the proof of work algorithm.
PoW Algorithm
In the preceding algorithm, the nonce is initialized as zero. The hash target which is the difficulty target of the network is taken from the nBits field of the candidate block header. The hash is initialized to null. After that, an infinite loop runs, which first concatenates the block header and the nonce and runs SHA-256 twice on it to produce the hash. Next, if the produced hash is less than the target hash, then it is accepted and appended to the blockchain; otherwise, the nonce is incremented and the process starts again. If no nonce is found, then the algorithm tries the next block.

A flowchart with the following flow. Candidate block header, double S H A 256, resultant hash, hash target; yes, stop, and no, increment.
Proof of work
In Figure 5-5, the previous block hash, transactions, and nonce are fed into a hash function to produce a hash which is checked against the target value. If it is less than the target value, then it’s a valid hash and the process stops; otherwise, the nonce is incremented, and the entire process repeats until the resultant hash is less than the target, where the process stops.
Game Theory and Proof of Work
Game theory is the study of behaviors in strategic interactive situations where an individual’s best course of action depends on the choice of others. Game theory models represent real-life situations in an abstract manner. Game theory is useful in many different fields, such as economics, biology, social science, finance, politics, computer science, and many more. For example, in economics, product launch decisions made by businesses are influenced by their competitor’s choice of product and marketing strategy. In computer networks, networked computers may compete for resources such as bandwidth. A Nash equilibrium is used to study political competition. In politics, politicians’ policies are influenced by announcements and promises made by their opponents.
A game can be defined as a description of all strategic actions that a player may take but without describing the likely outcome.
Players: Strategic rational decision makers in a game
Actions: Set of actions available to a player
Payoffs: A payout to be received by a player for a particular outcome
Games represent different strategic situations. There are some classical games such as Bach or Stravinsky, prisoner’s dilemma, Hawk-Dove, and matching pennies. In games, players are not aware of the actions of other players when making their own decisions; such games are called simultaneous move games.
Games can be analyzed by creating a table where all possible actions of players and payoffs are listed. This table is known as the strategic form of the game or payoff matrix.
A Nash equilibrium is a fundamental and powerful concept in game theory. In a Nash equilibrium, each rational player chooses the best course of action in response to the choice made by other players. Each player is aware of other players’ equilibrium strategies, and no player can make any gains by changing only their own strategy. In short, any deviation from the strategy does not result in any gain for the deviant.
Prisoner’s Dilemma
In this simultaneous move game, two suspects of a crime are put into separate cells without any way to communicate. If they both confess, then they both will be imprisoned for three years each. If one of them confesses and acts as a witness against the other, then charges against him will be dropped; however, the other suspect will get four years in prison. If none of them confesses, then both will be sentenced to only one year in prison. Now you can see that if both suspects cooperate and don’t confess, then it results in the best outcome for both. However, there is a big incentive of going free for both to not cooperate and act as a witness against the other. This game results in gains for both if they cooperate and don’t confess and results in only one year in prison each. Let’s name these characters Alice and Bob for ease and see what possible outcomes there are in this game.
- 1.
Alice does not confess, and Bob does not confess.
- 2.
Alice confesses, and Bob does not confess.
- 3.
Alice does not confess, and Bob confesses.
- 4.
Alice confesses, and Bob confesses.
If Alice and Bob can somehow communicate, then they can jointly decide to not confess, which will result in only a one-year sentence each. However, the dominant strategy here is to confess rather than don’t confess.
A dominant strategy is a strategy that results in the largest payoff regardless of the behaviors of other players in the game.

A 2 by 2 matrix of prisoner's payoff. The row and column headers are do not confess, confess. The entries are the points for Alice and Bob.
Prisoner’s dilemma payoff matrix
Alice and Bob are both aware of this matrix and know that they both have this matrix to choose from. Alice and Bob are players, “confess” and “don’t confess” are actions, and payoffs are prison sentences.
Regardless of what Alice does or Bob does, the other player still confesses. Alice’s strategy is that if Bob confesses, she should confess too because a one-year prison sentence is better than three. If Bob does not confess, she should still confess because she will go free. The same strategy is employed by Bob. The dominant strategy here is to confess, regardless of what the other player does.
Both players confess and go to prison for three years each. This is because even if Bob had somehow managed to tell Alice about his no confession strategy, Alice would have still confessed and became a witness to avoid prison altogether. Similar is the case from Alice’s perspective. Therefore, the best outcome for both becomes “confession” in a Nash equilibrium. This is written as {confess, confess}.
In the prisoner’s dilemma, there is a benefit of cooperation for both players, but the possible incentive of going free for each player entices contest. When all players in a game are rational, the best choice is to be in a Nash equilibrium.
Game theory models are highly abstract; therefore, they can be used in many different situations, once developed for a particular situation. For example, the prisoner’s dilemma model can be used in many other areas. In network communications where wireless network devices compete for bandwidth, energy supply, etc., there is a need to regulate node behavior in such a way that all devices on the network can work in harmony. Imagine a network where two cell towers working on the same frequency in close vicinity can affect each other’s performance. One way to counter this problem is to run both towers at low energy so that they don’t interfere with each other, but that will decrease the bandwidth of both the towers. If one tower increases its energy and the other don’t, then the one that doesn’t loses and runs on lower bandwidth. So, the dominant strategy here becomes to run towers at maximum power regardless of what the other tower does, so that they achieve maximum possible gain. This result is like the prisoner’s dilemma where confession is the best strategy. Here, maximum power is the best strategy.
Now in the light of the preceding explained concepts, we can analyze the Bitcoin protocol from a game theoretic perspective.
PoW and Game Theory
We can think of Bitcoin as a distributed system with selfish players; nodes might be trying to gain incentives without contributing or trying to gain more incentives than their fair share.
The Bitcoin protocol is a Nash equilibrium because no deviation from the protocol’s equilibrium strategy can result in a gain for the deviant. The protocol is designed in such a way that any deviation from the protocol is punished, and normal (good) behavior is economically incentivized. The dominant strategy in Bitcoin is to mine according to the protocol rules as there is no other strategy that would result in a better outcome. Each participant is better off by just sticking to the rules of the network.
If the other miners don’t switch their strategy, an attacker has no incentive to switch their own strategy. Neither player can increase their payoffs by switching to a different strategy if the other player doesn’t switch their strategy. This means that in Bitcoin if all other miners are honest, an adversary has no incentive to change their strategy and try to perform malicious mining.
Incentive mechanisms such as block reward and transaction fees in Bitcoin discourage malicious behavior. These incentives encourage participants to behave according to the protocol, which not only results in the creation of new bitcoins, that is, network progress is guaranteed, but also the security of the network is maintained.
Since 2009, the Bitcoin network has attracted so much investment in the form of mining farms and Bitcoin businesses, exchanges, and services that network participants will benefit more by protecting the network rather than destroying it. They gain by protecting the network. Even attackers cannot gain much. Imagine if some adversary managed to find a way to move all coins owned by Satoshi Nakamoto into another account. There probably is no incentive for an attacker to do so, because the moment it happens, the Bitcoin almost certainly will become worthless, because this event would imply that the very cryptography that protects the network has been broken (assuming that real Satoshi is not alive or has lost his private keys irrecoverably).
I have a feeling that Satoshi is not moving his coins because that can cause Bitcoin to lose its value drastically.
Similarly, even if an adversary somehow gains 51% of the network hash power, taking over the entire network may not be beneficial anymore. Why? Because the best course of action in such a situation for the adversary is to keep mining silently with some reasonable hash power to gain economic incentives (earn bitcoins) just like others on the network, instead of utilizing the entire 51% hash power announcing the attack to the world. That would just diminish the Bitcoin value almost entirely, and any gains by the attacker would be worthless. Therefore, attackers do not have incentive to take over the Bitcoin network, perhaps apart from some mishaps that occurred due to human errors and compromised keys. This is the elegance and beauty of Bitcoin that even attackers do not gain by attacking the network. All participants gain by just playing by the rules. The dominant strategy for miners is to be honest.
It could not be true but it was true.
—Mikhael Gromov

An illustration of the fusion of crypto-economics. Economics, cryptography, and distributed computing point to crypto-economics.
Fusion of distributed computing, economics, and cryptography – Bitcoin
We can also think of the fork resolution mechanism as a Schelling point solution. This is a game theory concept where a focal point or also called Schelling point is a solution that people choose by default in the absence of communication. Similarly, in the proof of work fork resolution mechanism, due to the longest (strongest) chain rule, nodes tend to choose the longest chain as a canonical chain to add the block that they’ve received without any communication or direction from other nodes. This concept of cooperating without communication was introduced by Thomas Schelling in his book The Strategy of Conflict.
Similarities Between PoW and Traditional BFT
Fundamentally, all consensus algorithms strive toward achieving safety and liveness properties. Either deterministic or probabilistic, basically all consensus algorithms have three main properties: agreement, validity, and termination. We have introduced these terms before. The question arises in Nakamoto consensus of whether we can redefine these properties in a way which is closer to the blockchain world. The answer is yes; agreement, validity, and liveness properties can be mapped to Nakamoto consensus–specific properties of common prefix, chain quality, and chain growth, respectively. These terms were first introduced in https://eprint.iacr.org/2014/765.pdf [7].
Common Prefix
This property implies that all honest nodes will share the same large common prefix.
Chain Quality
This property means that the blockchain contains a certain required level of correct blocks created by honest miners. If the chain quality is compromised, then the validity property of the protocol cannot be guaranteed.
Chain Growth
This property means that new correct blocks are constantly added to the blockchain regularly.
These properties can be seen as the equivalent of traditional consensus properties in the Nakamoto world. Here, the common prefix is an agreement property, the chain quality is a validity property, and chain growth can be seen as a liveness property.
PoW As State Machine Replication
A proof of work blockchain can be seen as a state machine replication mechanism where first a leader is elected who proposes a sequence of transactions batched in a block. Second, the finalized (mined) block is broadcast to other nodes via a gossip protocol, which is accepted and appended into their local blockchains, achieving log replication. We can think of it as if the leader is proposing an order and all nodes updating their log (local blockchain) based on this order of transactions set in the block.
Let’s first see the leader election algorithm and replication algorithm in detail.
Leader Election Algorithm
A node that solves the proof of work puzzle is elected to finalize and broadcast its candidate block. The leader in proof of work is elected as a function of computational power of the mining node. There is no voting required from other nodes as opposed to other traditional BFT protocols. Also, unlike traditional BFT protocols, the leader is rotated every block. This approach has been used in later blockchain BFT protocols as well where the leader is rotated every block to thwart any attempts to sabotage (compromise) the leader. Also, in traditional BFT protocols, usually the primary or leader is only changed when the primary fails, but in PoW a leader is elected every block. Leader election in PoW is based on computational power; However, several techniques have been used in other permissioned blockchains, from simply randomly choosing a leader or simple rotation formula to complex means such as verifiable random functions. We will cover these techniques in Chapter 8 in detail.
The leader election formula is simply the same PoW formula that we have already covered in the section “How PoW Works.” A soon as any miner solves the proof of work, it immediately is elected as a leader and earns the right to broadcast its newly mined block. At this point, the miner is also awarded 6.25 BTC. This reward halves every four years.
At the leader election stage, the miner node has successfully solved the PoW puzzle, and now the log replication can start.
Log Replication
It is append-only and immutable.
Each new batch of transactions (block) has a hash of the previous block, thus linking it in a so-called proof of work chain or hash chain or chain of blocks or blockchain.
The blocks (content in the log) are verifiable from the previous block.
Each block contains transactions and a block header. This structure was discussed in detail in Chapter 4.
When a new block is broadcast, it is validated and verified by each honest node on the network before it is appended to the blockchain. Log replication after leader election can be divided into three steps.
New Block Propagation

An illustration of the gossip protocol describes the relationships between nodes 14.
Gossip protocol in Bitcoin
This type of propagation ensures that eventually all nodes get the message with high probability. Moreover, this pattern does not overwhelm a single node with the requirement of broadcasting a message to all nodes.
Block Validation
The block is syntactically correct.
The block header hash is less than the network difficulty target.
The block timestamp is not more than two hours in future.
The block size is correct.
All transactions are valid within the block.
It is referring to the previous hash.
The protocol specifies very precise rules, details of which can be found at https://en.bitcoin.it/wiki/Protocol_rules; however, the preceding list is a high-level list of block validation checks a node performs.
Append to the Blockchain
The block is finally inserted into the blockchain by the nodes. When appending to the blockchain, it may happen that those nodes may have received two valid blocks. In that case, a fork will occur, and nodes will have to decide which chain to append the block to.

A schematic of replication. A transaction is broadcasted to a transaction pool to create a new candidate block that is validated and appended.
Proof of work as state machine replication
As shown in Figure 5-9, proof of work as a state machine replication consists of two main operations: leader election through proof of work and then replication via a gossip protocol and receiving node’s block validation and insertion mechanism. After proof of work on a node, if the proof of work is valid, then the block is treated the same as if it has been received from another node and eventually inserted into the local blockchain database after validation.
A component that chooses which chain is conclusive in case of a conflict is called a fork handler which embodies fork resolution rules on how to handle a fork.
Fork Resolution
Fork resolution can be seen as a fault tolerance mechanism in Bitcoin. Fork resolution rules ensure that only the chain that has the most work done to produce it is the one that is always picked up by the nodes when inserting a new block. When a valid block arrives for the same height, then the fork resolution mechanism allows the node to ignore the shorter chain and add the block only to the longest chain. Also note that this is not always the case that the longest chain has the most work done; it could happen that a shorter chain may have the most computational hash power behind it, that is, the accumulated proof of work, and in that case, that chain will be selected.

We can say that the accumulated proof of work for a chain is the sum of the difficulty of all blocks in the chain. The chain that has most proof of work behind it will be chosen for a new block to be appended.
The longest chain rule was originally simply the chain with the highest number of blocks. However, this simple rule was modified later, and the “longest” chain became the chain with the most work done to create it, that is, the strongest chain.
In practice, there is a chainwork value in the block which helps to identify the chain with the most work, that is, the correct “longest” or “strongest” chain.
Notice the chainwork value when converted to a decimal results in an extremely large number, 6663869462529529036756. This is the amount of work behind this head of the chain.
Regular fork
Hard fork
Soft fork
Byzantine fork
Regular fork
A fork can naturally occur in the Bitcoin blockchain when two miners competing to solve the proof of work happen to solve it almost at the same time. As a result, two new blocks are added to the blockchain. Miners will keep working on the longest chain that they are aware of, and soon the shorter chain with so-called orphan blocks will be ignored.

A schematic of the impact of forking includes the normal chain, the pruned shorter chain, and the strongest chain that wins.
Impact of forking on consensus finality
Due to the forking possibility, consensus is probabilistic. When the fork is resolved, previously accepted transactions are rolled back, and the longest (strongest) chain prevails.
The probability of these regular forks is quite low. A split of one block can occur almost every two weeks and is quickly resolved when the next block arrives, referring to the previous one as a parent. The probability of occurrence of a two-block split is exponentially lower, which is almost once in 90 years. The probability of occurrence of a four-block temporary fork is once in almost 700,000,000 years.
Hard fork
A hard fork occurs due to changes in the protocol, which are incompatible with the existing rules. This essentially creates two chains, one running on the old rules and the new one on new rules.

A chart of the hard fork includes the original software client categorized into an upgraded software client and the original software client.
Hard fork
Soft fork
A soft fork occurs when changes in the protocol are backward compatible. It means that there is no need to update all the clients; even if not all the clients are upgraded, the chain is still one. However, any clients that do not upgrade won’t be able to operate using the new rules. In other words, old clients will still be able to accept the new blocks.

A chart of the hard fork includes the original software client categorized into an upgraded software client and the original software client.
Soft fork
Byzantine fork
A Byzantine fork or malicious fork can occur in scenarios where an adversary may try to create a new chain and succeeds in imposing its own version of the chain.
With this, we complete our discussion on forks.
A core feature of proof of work consensus is the Sybil resistance mechanism which ensures that creating many new identities and using them is prohibitively computationally complex. Let’s explore this concept in more detail.
Sybil Resistance
A Sybil attack occurs when an attacker creates multiple identities, all belonging to them to subvert the network relying on voting by using all those identities to cast vote in their favor. Imagine if an attacker creates more nodes than the entire network, then the attacker can skew the network in their favor.

A flowchart of a Sybil attack includes an attacker controlling the Sybil node, Sybil nodes, and network of honest nodes, in the order mentioned.
Sybil attack
Proof of work makes it prohibitively expensive for an attacker to use multiple nodes controlled by them to participate in the network because each node will have to do computationally complex work in order to be part of the network. Therefore, an attacker controlling a large number of nodes will not be able to influence the network.
Significance of Block Timestamp
The Bitcoin network with its heterogenous geographically dispersed nodes running on the Internet appears to be an asynchronous network. This appears to be the case because there is no upper bound on the processor speeds and no upper bound on the message delay. Usually, in traditional BFT consensus protocols, there is no reliance on a global physical clock, and network assumptions are usually partially synchronous networks. However, in Bitcoin all blocks have a timestamp field, which is populated by the local node which mined the block. This is part of the block validation process where a block is accepted only if its timestamp is less than or equal to the median of the last 11 blocks. Also, timestamps are vital for maintaining block frequency, difficulty retargeting, and network difficulty calculations. From this point of view, we can think of the Bitcoin network as loosely synchronous, where loose clock synchrony is required for the network to make progress and ensure liveness.
Note that the Bitcoin network is not partially synchronous because we defined partially synchronous and its variations earlier, and the Bitcoin network doesn’t seem to fit in any of those definitions. It is synchronous in the sense that blocks have a timestamp generated from the local node on which the block was produced; however, from a processor delay perspective, it is almost asynchronous. Also, in the block validation mechanism, one of the rules requires that a block is produced within roughly the last two hours (median of the previous 11 blocks), making Bitcoin an “almost synchronous” system. This is so because timestamps are essential for the proper functioning of the Bitcoin system; however, due to large communication and processor delay tolerance, it can be thought of as a loosely synchronous system.
On the other hand, as timestamps are required only for proper functioning of the limited part of the system, that is, the difficulty calculations, and block validation and are not a requirement for achieving consensus (i.e., by choosing a leader by solving proof of work – mining), then from that point of view it is an asynchronous system, given that processor and communication delays have no defined upper bounds, except that messages will reach nodes eventually with a probabilistic guarantee of a gossip protocol.
In Bitcoin blocks, timestamps are not 100% accurate but enough to secure the proof of work mechanism. Originally, Satoshi envisioned a combination of a system clock, a median of other servers’ clocks, and NTP servers for clock adjustment. However, NTP was never implemented, and the median of other nodes’ clock remained as the primary source for clock adjustment in the network.
Block timestamps not only serve to provide some variation for the block hash, which is useful in proof of work, but also helps to protect against blockchain manipulation where an adversary could try to inject an invalid block in the chain. When a Bitcoin node connects to another node, it receives the timestamp in UTC format from it. The receiving node then calculates the offset of the received time from the local system clock and stores it. The network adjusted time is then calculated as the local UTC system clock plus the median offset from all connected nodes.
There are two rules regarding timestamps in Bitcoin blocks. A valid timestamp must be greater than the median timestamp of the previous 11 blocks. It should also be less than the median timestamp calculated based on the time received from other connected nodes (i.e., network adjusted time) plus two hours. However, this network time adjustment must never be more than 70 minutes from the local system clock.
The conclusion is that Bitcoin is in fact secure only under a synchronous network model. More precisely, it is a lockstep-free synchrony where there exists some known finite time bound, but execution is not in lockstep.
A Caveat
The order of transaction is not consensus driven. Each miner picks up a transaction in a hardcoded order within the client, and indeed there have been some attacks that can result in transaction censorship or ignoring or reordering. Consensus is achieved in fact on the block, and that is also not through voting; once a miner has solved PoW, it just simply wins the right to append a new block to the chain. Of course, it will be validated by other nodes when they receive it, but there is no real agreement or voting mechanism after the mined block has been broadcast by the successful miner. There is no voting or consensus which agrees on this new block; the miner who is the elected leader and because they solved PoW has won the right to add a new block. Other nodes just accept it if it passes the valid() predicate.
So, the caveat here is that when a candidate block is created by picking up transactions from the transaction pool, they are picked up in a certain order which a miner can influence. For example, some miners may choose not to include transactions without any fee and only include those which are paying fee. Fair for the miner perhaps, but unfair for the user and the overall Bitcoin system! However, eventually all transactions will be added, even those without a fee, but they might be considered only after some considerable time has elapsed since their inclusion in the transaction pool. If they’ve aged, then they’ll be eventually included. Moreover, under the assumption that usually there is a majority of honest miners always in the network, the transactions are expected to be picked up in a reasonable amount of time in line with the protocol specification.
Let us now see what is that order.
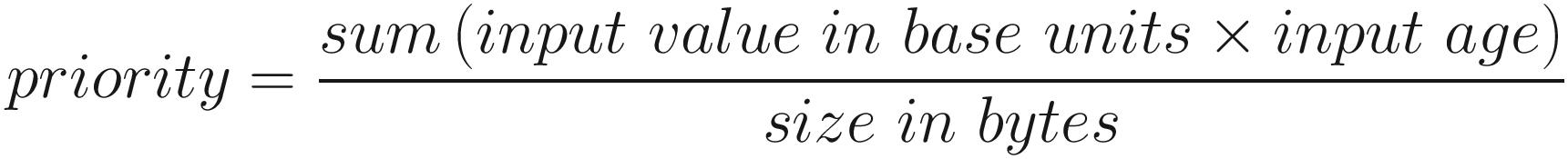
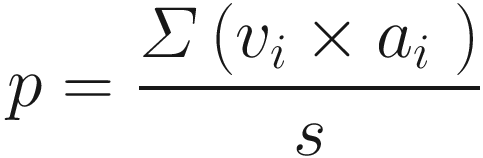
It is of concern that the ordering of transactions is not fair and leads to front running and other relevant attacks. We will discuss fair ordering in Chapter 10.
PoW As a Solution to Byzantine Generals Problem
This has been described by Satoshi Nakamoto himself in a post [5]. I will describe the logic here in a concise way.
Remember in the Byzantine generals problem, the problem is to agree on an attack time in the presence of treacherous generals and the possibility of captured messengers. In the case of proof of work, we can consider miners as generals where the understanding between generals is that any general can announce the attack time and the attack time heard first is accepted as the authoritative time to attack. The problem however is that if two generals propose different times almost simultaneously, it could happen due to messaging delays where some generals receive one of the attack times first, and some others receive the other attack time first, resulting in disagreement. In order to solve this problem, each general who receives an attack time starts to solve a complex math puzzle. When a general solves this math puzzle (proof of work), it broadcasts that to the network. When other generals receive it, they switch to this new time.
All generals are allowed to propose a time, but only one of the proposed times will eventually be accepted as valid by all generals.
For a proposed time to be valid, the condition is that each general must solve a mathematical puzzle and attach it with the proposed time message; if other generals receive this message and see that the solution to the math puzzle is valid, they accept that time. This mathematical puzzle serves two purposes; first, it is a proof that the general is honest as they have solved the math puzzle, and, second, it stops the generals from proposing too many times in quick succession, which will result in disagreement and confusion between the generals. We can see that this mechanism can be seen as a solution to the Byzantine generals problem; however, with a compromise, that temporary disagreement is acceptable.
Bitcoin PoW is a probabilistic consensus algorithm. The big question now arises whether deterministic consensus can be achieved when the number of nodes is unknown and in the presence of Byzantine nodes.
Now let’s revisit the validity, agreement, and termination properties defined at the start of this chapter in the light of what we have learned so far about the proof of work algorithm.
We can see clearly now that PoW is not a classical deterministic Byzantine consensus algorithm. It is a protocol with probabilistic properties.
Let’s revisit the properties now.
Agreement
An agreement property is probabilistic. This is the case because it can happen that two different miners produce a valid block almost simultaneously, and some nodes add a block from one miner and some other nodes from another. Eventually, however, the longest (strongest) chain rule will ensure that the chain with less proof of work behind it is pruned and the longest chain prevails. This will result in previously accepted transactions to be rolled back; thus, the agreement is probabilistic.
Validity – Predicate Based
This is a deterministic property agreement where honest nodes only accept those blocks which are valid. Formally, we can say that if a correct process p eventually decides on b, then v must satisfy the application-specific valid() predicate. We discussed the validity predicate, that is, the block validation criteria, in detail earlier in the chapter.
Termination
Termination is a probabilistic property. It is only achieved eventually due to the possibility of natural forks. This is because in the case of forks, the fork must be resolved in order to finally terminate a consensus process on the block. As there is a possibility that a previously accepted block is rolled back in favor of the heaviest/longest chain, the termination can only be guaranteed probabilistically. Usually, in order to ensure with high probability the finality of the transactions, in practice six confirmations are traditionally required. This means that the block is at least six blocks deeper in the chain, which means that the possibility of a rollback is so low that it can never happen or happen once in a millennia.
With this, we complete our discussion on proof of work.
PoW Concerns
There are several concerns regarding PoW, including attacks and extreme energy consumption.
In the next section, we discuss some of the attacks that can be carried out against the proof of work consensus, which adversely affects the Bitcoin network.
51% Attack
A 51% attack on Bitcoin can occur when more than 50% of the mining hash power is controlled by an adversary.
List of actions by adversary
Attack | Possibility | Explanation |
|---|---|---|
Censor transactions | Yes | Can ignore transactions |
Coin stealing | No | Controlled by a private key |
Double-spend | Yes | Can create a private off-chain fork and exclude the block which contains previously spent transaction |
Change protocol | No | A protocol cannot be changed as valid nodes will simply ignore the invalid blocks |
Note that some attacks are still impossible, while the most detrimental to a system are possible, such as double-spend.
Selfish Mining
This type of attack occurs when a miner who has found a block keeps it a secret instead of announcing it and keeps building on top of it privately. Imagine the attacker has managed to create another block. Now the attacker has two blocks in their private forked chain. At this point, the attacker waits for someone else to find a block. When the attacker sees this new block, they release their two-block chain. Because other miners are honest and abiding by the longest chain rule, they will accept this new chain being the longest. Now the block that was mined by someone else is orphaned despite spending resources on it, but that work is wasted. The attacker could also wait for a longer chain to be created, albeit mostly by luck, but if the attacker manages to create such a private fork which is longer than the honest chain, then the attacker can release that as soon as some other block is announced. Now when the nodes see this new longest chain, according to the rules, they will start mining on top of this new longer chain and orphaning the other chains, which could just be one block shorter than the attacker’s chain. All the work that has gone into creating the honest chain is now wasted, and the attacker gets the rewards, instead of other miners who did the work on the honest chain.
Race Attack
This attack can occur in a situation where the adversary can make a payment to one beneficiary and then a second one to themselves or someone else. Now if the first payment is accepted by the recipient after zero confirmations, then it could happen that the second transaction is mined and accepted in the next block, and the first transaction could remain unmined. As a result, the first recipient may never get their payment.
Finney Attack
The Finney attack can occur when a recipient of a payment accepts the payment with zero confirmations. It is a type of double-spend attack where an attacker creates two transactions. The first of these transactions is a payment to the recipient (victim) and the second to themselves. However, the attacker does not broadcast the first transaction; instead, they include the second transaction in a block and mine it. Now at this point, the attacker releases the first transaction and pays for the goods. The merchant does not wait here for the confirmations and accepts the payment. Now the attacker broadcasts the premined block with the second transaction that pays to themselves. This invalidates the first transaction as the second transaction takes precedence over the first one.
Vector76 Attack
This attack is a combination of Finney and race attacks. This attack is powerful enough to reverse a transaction even if it has one confirmation.
Eclipse Attack
This attack attempts to obscure a node’s correct view of the network, which can lead to disruption to service, double-spend attacks, and waste of resources. There are several solutions to fix the issue, which have been implemented in Bitcoin. More details can be found here: https://cs-people.bu.edu/heilman/eclipse/.
ESG Impact
ESG metrics represent an overall picture of environmental, social, and governance concerns. These metrics are used as a measure to assess a company’s exposure to environmental, social, and governance risks. They are used by investors to make investment decisions. Investors may not invest where ESG risks are higher and may prefer companies where ESG risk is low.
Proof of work has been criticized for consuming too much energy. It is true that currently at the time of writing, the total energy consumption of the Bitcoin blockchain is more than the entire country of Pakistan [9].
There are environmental, social, and governance concerns (ESG concerns) that have been the cause of low interest from savvy mainstream investors. Nonetheless, Bitcoin largely can be seen as a success despite its ESG concerns.
Not only has Bitcoin been criticized for its high energy consumption but often seen as a vehicle for criminal activities, where Bitcoin has been accepted as a mode of payment for illicit drugs and other criminal activities.
A centralization problem is also a concern where some powerful miners with mining farms take up most of the hash rate of the Bitcoin network. The ASICs that are used to build these mining farms are produced only by a few manufacturers, which means that this is also a highly centralized space. Moreover, a crackdown [13] on Bitcoin mining could also result in more centralization, where only the most powerful miners may be able to withstand this crackdown and survive, resulting in only a few surviving and powerful miners at the end.
There are however points in favor of Bitcoin. Bitcoin can be used as a cross-border remittance mechanism for migrant families. It can also be used as a mode of payment in struggling economies. It can serve the unbanked population, which is estimated to be 1.7 billion [12]. Bitcoin serves as a vehicle for financial inclusion.
Thermoelectric power generator, any of a class of solid-state devices that either convert heat directly into electricity or transform electrical energy into thermal power for heating or cooling. Such devices are based on thermoelectric effects involving interactions between the flow of heat and of electricity through solid bodies. [11]
—Encyclopaedia Britannica, March 1, 2007, www.britannica.com/technology/thermoelectric-power-generator
Bitcoin can be used in suppressed regimes.
Borderless payments.
Bank the unbanked.
Smooth cross-border remittance.
Alternative payment system which doesn’t have any intermediary.
Payments without a middleman.
In summary, Bitcoin, despite its energy consumption and not living up to its original philosophy of One CPU = One Vote, still can be seen as a successful project with many benefits.
Variants of PoW
CPU-bound PoW
Memory-bound PoW
CPU-Bound PoW
These puzzles run at the speed of the processor. CPU-bound PoW refers to a type of PoW where the processing required to find the solution to the cryptographic hash puzzle is directly proportional to the calculation speed of the CPU or hardware such as ASICs. Because ASICs have dominated Bitcoin PoW and provide somewhat undue advantage to the miners who can afford to use ASICs, this CPU-bound PoW is seen as shifting toward centralization. Moreover, mining pools with extraordinary hash power can shift the balance of power toward them. Therefore, memory-bound PoW algorithms have been introduced, which are ASIC resistant and are based on memory-oriented design instead of CPU.
Memory-Bound PoW
Memory-bound PoW algorithms rely on system RAM to provide PoW. Here, the performance is bound by the access speed of the memory or the size of the memory. This reliance on memory also makes these PoW algorithms ASIC resistant. Equihash is one of the most prominent memory-bound PoW algorithms.
There are other improvements and variations of proof of work, which we will introduce in Chapter 8.
Summary
Proof of work is the first blockchain consensus introduced with Bitcoin, which is also a solution to the Byzantine generals problem.
Blockchain consensus can be divided into two categories, the Nakamoto consensus and the traditional BFT based.
Traditional BFT is deterministic, whereas Nakamoto consensus is probabilistic.
Proof of work in Bitcoin is a Sybil resistance mechanism, a double-spending prevention mechanism, and a solution to the Byzantine generals problem.
Proof of work can be seen in the light of game theory where the protocol is a Nash equilibrium, and the dominant strategy for all players is to be honest.
Proof of work is effectively a Byzantine fault–tolerant protocol.
Proof of work is a state machine replication protocol where a mined block is announced and replicated to other nodes via a gossip protocol.
Proof of work consumes high energy, and there are ESG concerns; however, there are benefits as well.
Bibliography
- 1.
Proof of work originally introduced in: Cynthia Dwork and Moni Naor. Pricing via processing or combatting junk mail. In Ernest F. Brickell, editor, Advances in Cryptology – CRYPTO ’92, 12th Annual International Cryptology Conference, Santa Barbara, California, USA, August 16–20, 1992, Proceedings, volume 740 of Lecture Notes in Computer Science, pages 139–147. Springer, 1992.
- 2.
Okun, Michael. Distributed computing among unacquainted processors in the presence of Byzantine failures. Hebrew University of Jerusalem, 2005.
- 3.
- 4.
- 5.
- 6.
- 7.
These terms were first introduced in https://eprint.iacr.org/2014/765.pdf
- 8.
- 9.
Digiconomist: https://digiconomist.net/bitcoin-energy-consumption/
- 10.
- 11.
Strohl, G. Ralph and Harpster, Joseph W. "Thermoelectric power generator." Encyclopedia Britannica, Mar. 1, 2007, www.britannica.com/technology/thermoelectric-power-generator. Accessed June 25, 2021.
- 12.
- 13.
- 14.
Introduction to the Distributed Systems channel by Chris Colohan: www.distributedsystemscourse.com
- 15.
Bitcoin blockchain consensus: https://youtu.be/f1ZJPEKeTEY