
In this chapter, I introduce early protocols. First, we start with a background on distributed transactions and relevant protocols, such as the two-phase commit. After that, we’ll continue our journey, look at the agreement protocols, and conclude the chapter with some fundamental results in distributed computing. This chapter introduces early consensus algorithms such as those presented in the works of Lamport et al., Ben-Or et al., and Toueg et.al. It is helpful to understand these fundamental ideas before continuing our voyage toward more complex and modern protocols.
Introduction
In my view, the 1980s was the golden age for innovation and discovery in distributed computing. Many fundamental problems, algorithms, and results such as the Byzantine generals problem, FLP impossibility result, partial synchrony, and techniques to circumvent FLP impossibility were discovered during the late 1970s and 1980s. Starting from Lamport’s phenomenal paper “Time, Clocks, and the Ordering of Events in a Distributed System” to the Byzantine generals problem and then Schneider’s state machine replication paper, one after another, there were most significant contributions made to the consensus problem and generally in distributed computing.
Consensus can be defined as a protocol for achieving agreement. A high-level list of major contributions is described as follows.
In his seminal paper in 1978, “Time, Clocks, and Ordering of Events in a Distributed System”, Lamport described how to order events using synchronized clocks in the absence of faults. Then in 1980, the paper “Reaching Agreement in the Presence of Faults” posed the question if agreement can be reached in an unreliable distributed system. It was proven that agreement is achievable if the number of faulty nodes in a distributed system is less than one-third of the total number of processes, i.e. n>=3f+1, where n is the number of total nodes and f is the number of faulty processors. In the paper “The Byzantine Generals Problem” in 1982, Lamport et al. showed that agreement is solvable using oral messages if more than two-thirds of the generals are loyal. In 1982, the paper “The Byzantine generals strike again” by Danny Dolev showed that unanimity is achievable if less than one-third of the total number of processors are faulty and more than one-half of the network’s connectivity is available.
Unanimity is a requirement where if all initial values of the processes are the same, say v, then all processes decide on that value v. This is strong unanimity. However, a weaker variant called weak unanimity only requires this condition to hold if all processes are correct; in other words, no processes are faulty.
The paper also provided the first proof that the distributed system must have 3f + 1 nodes to tolerate f faults. However, the celebrated FLP result appeared a little later which proved that deterministic asynchronous consensus is not possible even if a single process is crash faulty. FLP impossibility implies that safety and liveness of a consensus protocol cannot be guaranteed in an asynchronous network.
Lamport’s algorithm was for a synchronous setting and assumed that eventually all the messages will be delivered. Moreover, it wasn’t fault tolerant because a single failure will halt the algorithm.
After the FLP impossibility result appeared, attempts started to circumvent it and solve the consensus problem nevertheless. The intuition behind circumventing FLP is to relax some stricter requirements of timing and determinism.
Ben-Or proposed the earliest algorithms to sacrifice some level of determinism to circumvent FLP. As FLP impossibility implies that under asynchrony, there will always be an execution that does not terminate, one way of avoiding that is to try and make termination probabilistic. So that instead of deterministic termination, probabilistic termination is used. The intuition behind these algorithms is to use the “common coin” approach, where a process randomly chooses its values if it doesn’t receive messages from other nodes. In other words, a process is allowed to select a value to vote on if it doesn’t receive a majority of votes on the value from the rest of the processes. This means that eventually more than half of the nodes will end up voting for the same value. However, this algorithm’s communication complexity increases exponentially with the number of nodes. Later, another approach that achieved consensus in a fixed number of rounds was proposed by Rabin. These proposals required 5f + 1 and 10f + 1 rounds, respectively, as compared to the 3f + 1 lower bound commonly known today.
Consensus protocols that relax timing (synchrony) requirements aim to provide safety under all circumstances and liveness only when the network is synchronous. A significant breakthrough was the work of Dwork, Lynch, and Stockmeyer, which for the first time introduced a more realistic idea of partial synchrony. This model is more practical as it captures how real distributed systems behave. More precisely, distributed systems can be asynchronous for arbitrary periods but will eventually return to synchrony long enough for the system to make a decision and terminate. This paper introduced various combinations of processor and network synchrony and asynchrony and proved the lower bounds for such scenarios.
We discussed partial synchrony in detail in Chapter 3.
Minimum number of processors for which a fault-tolerant consensus protocol exists
Type of Fault | Synchronous | Asynchronous | Partially Synch Comms and Processor |
|---|---|---|---|
Fail-stop | f | NA | 2f + 1 |
Omission | f | NA | 2f + 1 |
Authenticated Byzantine | f | NA | 3f + 1 |
Byzantine | 3f + 1 | NA | 3f + 1 |
This paper introduced the DLS algorithm which solved consensus under partial synchrony.
Lamport showed in LPS 82 that under a synchronous setting, n > 2f with authentication and n > 3f are at least required with oral messages.
The FLP result in 1982 showed that even with a single crash failure, consensus is impossible under asynchrony, and at least n > 3f are required for safety.
Ben-Or in 1983 proposed a randomized solution under asynchrony.
Now let’s go through distributed transaction which is a major concept in distributed systems.
Distributed Transactions
A distributed transaction is a sequence of events spread across multiple processes. A transaction either concludes with a commit or abort. If committed, all events are executed, and the output is generated, and if aborted, the transaction halts without complete execution. A transaction is atomic if it executes and commits fully; otherwise, it rolls back with no effect. In other words, atomic transactions either execute in full or not at all.
Atomicity: Either the transaction events fully execute or not at all.
Consistency: If a transaction commits, it results in a valid (consistent) state of the system. It satisfies some invariants.
Isolation: Unless the transaction is committed, no effects are visible.
Durability: A transaction once committed has a permanent effect.
One point to note here is that consistency is guaranteed much easily in monolithic architectures. In contrast, consistency is not immediate in distributed architectures, and distributed architectures rely on so-called eventual consistency. Eventual consistency means that all nodes in a system eventually (at some point in time in future) synchronize and agree on a consistent state of the system. ACID properties must hold even if some nodes (processes) fail.
Atomicity, isolation, and durability are easier to achieve in monolithic architectures, but achieving these properties in distributed settings becomes more challenging.
A two-phase commit protocol is used to achieve atomicity across multiple processes. Replicas should be consistent with one another. Atomic commit protocols are in fact a kind of consensus mechanism because in transaction commit protocols nodes must come to an agreement to either commit if all is well or roll back in case something goes wrong. Imagine if a transaction is expected to be committed on all nodes in a distributed system (a network), then either it must commit on all or none to maintain replica consistency. We cannot have a situation where a transaction succeeds on some nodes and not on others, leading to an inconsistent distributed system. This is where atomic commit comes in. It can be seen fundamentally as a consensus algorithm because this protocol requires an agreement between all nodes in a network. However, there are fundamental differences between atomic commit and consensus. In consensus, one or more nodes propose a value, and nodes decide on one of the values using the consensus algorithm. This is usually achieved by majority consensus. In contrast, in an atomic commit protocol, all nodes are required to vote whether they commit or abort the transaction. In consensus algorithms, there can be multiple values proposed out of which one can be agreed upon, whereas in atomic commit the protocol must commit if all nodes vote to commit; otherwise, even if one node doesn’t agree, then the transaction must be aborted by all nodes. A major distinction between atomic commit and consensus is that in consensus algorithms, faults (crashed nodes) are tolerated due to the quorum availability rule, whereas in atomic commit even if one node fails, the transaction must abort on all nodes. To handle crashed nodes, a complete and strongly accurate failure detector is used, which is implemented using a timeout mechanism.
In addition to the ACID consistency model, another common consistency model used in databases is the BASE model. BASE stands for basically available (BA), soft state (S), and eventually consistent (E). The databases using the BASE consistency model ensure availability by replicating data across nodes in the system. As the model does not provide immediate consistency, the data values could change over time, which results in eventual consistency. In the BASE model, consistency is only achieved eventually. However, it offers high availability, which is useful in many online services where immediate and strong consistency requirements are somewhat loose, like social networks and online video platforms. From a CAP theorem perspective, the BASE model sacrifices consistency and favors high availability.
Now we discuss the two-phase commit which is a famous commit protocol, achieving atomicity.
Two-Phase Commit
A two-phase commit (2PC) is an atomic commit protocol to achieve atomicity. It was first published in a paper by Lampson and Sturgis in 1979. A two-phase commit enables updating multiple databases in a single transaction and committing/aborting atomically.
As the name suggests, it works in two phases. The first phase is the vote collection phase in which a coordinator node collects votes from each node participating in the transaction. Each participant node either votes yes or no to either commit the transaction or abort the transaction. When all votes are collected, the coordinator (transaction manager) starts the second phase, called the decision phase. In the decision phase, the coordinator commits the transaction if it has received all yes votes from other nodes; otherwise, it aborts the transaction. Any node that had voted yes to commit the transaction waits until it receives the final decision from the coordinator node. If it receives no from the coordinator, it will abort the transaction; otherwise, it will commit the transaction. Nodes that voted no immediately terminate the transaction without waiting to receive a decision from the coordinator. When a transaction is aborted, any changes made are rolled back. The changes are made permanent after committing at nodes that said yes when they receive a commit decision from the coordinator. Any changes made by the transaction are not permanent, and any locks are released after a write operation is performed. All participants send the acknowledgment back to the coordinator after they’ve received the decision from the coordinator. As a failure handling mechanism, a logging scheme is used in two-phase commits. In this scheme, all messages are written to a local stable storage before they are sent out to the recipients in the network. When the coordinator fails (crashes), it writes its decision to the local disk in the log, and when it recovers, it sends its decision to other nodes. If no decision was made before the crash, then it simply aborts the transaction. When a node fails (other than the coordinator node), the coordinator waits until it times out, and a decision is made to abort the transaction for all.

A schematic with 4 right arrows labeled client, coordinator, participant 1 and 2. The lines are sectioned into 3 with multi-directional arrows.
The two-phase commit algorithm – a successful scenario
The two-phase commit is a blocking algorithm because if the coordinator goes down after the “prepare” phase but before sending out its decision, other nodes have no way of finding out what has been decided by the coordinator. Now they are stuck in an uncertain state where they have agreed earlier to commit by saying yes/ok in the prepare phase but are now waiting to hear the final decision from the coordinator. Nodes cannot either commit or abort on their own after responding yes in the prepare phase because it will violate the atomicity property. The protocol in this situation blocks until the coordinator recovers. This means that the two-phase commit algorithm is not fault tolerant if the coordinator or a participant fails. In other words, 2PC is not partition tolerant.
More precisely, if the coordinator crashes just after the prepare phase before sending the decision, other nodes then have no idea what decision is made by the coordinator. At this stage, participants cannot commit or abort, and the protocol is blocked until the coordinator comes back online and participants receive the decision. The coordinator is a single point of failure in this protocol. There are ways to overcome this problem using a consensus mechanism or total order broadcast protocol. The commit protocol can use consensus to elect a new coordinator.
Also, note that if we remove the second phase and hence no rolling back, it becomes a one-phase commit, that is, the primary/backup replication. Sounds familiar? We discussed this in Chapter 3.
Three-Phase Commit
As we saw in the two-phase commit, it is not fault tolerant and blocks until the failed coordinator recovers. If the coordinator or a participant fails in the commit phase, the protocol cannot recover reliably. Even when the coordinator is replaced or recovers, it cannot proceed to process the transaction reliably from where the failure occurred. The three-phase commit solves this problem by introducing a new pre-commit intermediate phase. After receiving a yes from all the participants, the coordinator moves to this intermediate phase. Unlike 2PC, here, the coordinator does not immediately broadcast commit; instead, it sends a pre-commit first, which indicates the intention to commit the transaction. When participants receive the pre-commit message, they reply with the ack messages. When the coordinator receives this ack from all participants, it sends the commit message and proceeds as in the two-phase commit. If a participant fails before sending back a message, the coordinator can still decide to commit the transaction. If the coordinator crashes, the participants can still agree to abort or commit the transaction. This is so because no actual commit or abort has taken place yet. The participants now have another chance to decide by checking that if they have seen a pre-commit from the coordinator, they commit the transaction accordingly. Otherwise, the participants abort the transaction, as no commit message has been seen from the coordinator.

A schematic with 2 vertical lines for coordinator and participant. They are sectioned into voting, commit, and decision phase.
Three-phase commit protocol
Roughly speaking, commit protocols can be seen as agreement protocols because participants need to decide whether to accept the value proposed by the coordinator or not. Of course, it is a simple protocol and not fault tolerant, but it does achieve an agreement among parties; hence, it can be seen as a consensus mechanism. Moreover, we can say that validity is achieved because a participant proposes a final agreed-upon value. Also, termination is guaranteed because every participant makes progress. If there are no failures, eventually all participants respond to the coordinator, and the protocol moves forward and, finally, both phases end. Strictly speaking, however, distributed commit protocols are not consensus protocols.
Now, after this introduction to the most straightforward consensus protocols or distributed commit protocols (depending on how you look at them), let us focus on some early fault-tolerant consensus protocols that provide the foundation of what we see today as consensus protocols in various distributed systems and blockchains.
Oral Message Algorithm
The oral message (OM) algorithm was proposed to solve the Byzantine generals problem in the “Byzantine Generals Problem” paper in 1982 by Lamport et.al. This recursive algorithm runs under the synchronous network model. It assumes a collection of N generals where all generals are connected as a complete graph. One general is the “commander” responsible for starting the protocol. Other generals (N – 1) called “lieutenants” orally pass around the message they receive. The commander knows that at most f generals will be faulty (traitors) and starts the consensus algorithm with a known value of f. There is also a default value, either “retreat” or “attack.” The intuition behind this algorithm is that you tell others what message you received on receiving every message. The participants accept the majority decision, which ensures the safety property of the algorithm.
- 1.
IC1: All loyal lieutenants obey the same order.
- 2.
IC2: If the commanding general is loyal, then every loyal lieutenant obeys its order.
- 1.
The absence of message can be detected. This is due to synchronous communication.
- 2.
Every sent message is delivered correctly.
- 3.
The receiver of the message knows who sent it.
An oral message is a message whose contents are under complete control of the sender. The sender can send any possible message.
Lemma 1: There is no solution to the Byzantine generals problem for 3m + 1 generals with > m traitors.
In other words, if n <= 3m, then a Byzantine agreement is not possible. The algorithm is recursive.
Algorithm
- 1.
The commander broadcasts a proposed value to every lieutenant.
- 2.
Every lieutenant accepts the received value. If no value is received, then it uses the DEFAULT value, either set to retreat or attack, at the start of the algorithm.
- 1.
The commander sends the proposed value to every lieutenant.
- 2.
Every lieutenant runs OM(m-1) and acts as the commander to send the value received in step 1 to all the other lieutenants.
- 3.
Each lieutenant maintains a vector from which it uses the majority value out of the values received.

Two schematics of OM cases with a commander and 3 lieutenants. The are connected via attack, on the left and attack and retreat on the right.
OM base case vs. OM(1) case, where the commander is the traitor

A schematic with a commander and 3 lieutenants, L 1 to 3. The commander orders an attack to the 3 lieutenants. L 3 sends retreat orders to L 1 and L 2.
OM case with M=1 where a lieutenant is a traitor
We can formally describe the algorithm as shown in the following code:
As you may have noticed, this algorithm, while it works, is not very efficient due to the number of messages required to be passed around. More precisely, from a communication complexity perspective, this algorithm is exponential in the number of traitors. If there are no traitors, as in the base case, then its constant, O(1), otherwise its O(mn), which means that it grows exponentially with the number of traitors, which makes it impractical for a large number of n.

A schematic with 4 right arrows, C, L 1, L 2, and L 3. An attack order is sent to L 1, L 2, and L 3 from C. The time arrow points to the right.
Oral message protocol – base case – with no traitors

A schematic of a message protocol with 4 right arrows, C traitor, L 1, L 2, and L 3. Each of them sends attack and retreat messages to one another.
Oral message protocol case where m =1, the commander is a traitor
In the digital world, commanders and lieutenants represent processes, and the communication between these processes is achieved by point-to-point links and physical channels.
So far, we have discussed the case with oral messages using no cryptography; however, another solution with signed messages is also possible where digital signatures are used to guarantee the integrity of the statements. In other words, the use of oral messages does not allow the receiver to ascertain whether the message has been altered or not. However, digital signatures provide a data authentication service that enables receiving processes to check whether the message is genuine (valid) or not.
Based on whether oral messages are used, or digital signatures have been used, Table 6-1, earlier in this chapter, summarizes the impossibility results under various system models.
Signed Message Solution to Byzantine Generals Problem
The main issue with the oral message algorithm is that it needs 3t + 1 (also denoted as 3f + 1) nodes to tolerate t (also denoted as f) failures, which is expensive in terms of computational resources required. It is also difficult because traitors can lie about what other nodes said. The time complexity of this algorithm is O(nm).
- 1.
The signature of a loyal general cannot be forged, and any modification of the general’s messages is detectable.
- 2.
Anyone can verify the authenticity of the general’s signature.
Under this model, each lieutenant maintains a vector of signed orders received. Then, the commander sends the signed messages to the lieutenants.
Generally, the algorithm works like this:
A lieutenant receives an order from either a commander or other lieutenants and saves it in the vector that he maintains after verifying the message's authenticity. If there are less than m signatures on the order, the lieutenant adds a signature to the order (message) and relays this message to other lieutenants who have not seen it yet. When a lieutenant does not receive any newer messages, he chooses the value from the vector as a decision consensus value.
The lieutenants can detect that the commander is a traitor by using signed messages because the commander's signature appears on two different messages. Our assumptions under this model are that signatures are unforgeable, and anyone can verify the signature's authenticity. This implies that the commander is a traitor because only he could have signed two different messages.
Formally, the algorithm is described as follows.
Algorithm: For n generals and m traitor generals where n > 0. In this algorithm, each lieutenant i keeps a set Vi of properly signed messages it has received so far. When the commander is honest, then the set Vi contains only a single element.
Algorithm SM(m)
Initialization:
- 1.
Commander C sends the signed message (value) to every lieutenant.
- 2.For each i
- a.
If lieutenant i receives a message of the form v : 0 from the commander and has not yet received any message (order) from the commander, that is, Vi is empty, then
- i.
Set Vi = {v}.
- ii.
It sends the message v : 0 : i to every other lieutenant.
- b.
If lieutenant i receives a message like v : 0 : j1. …jk and v is not in the set, Vi, then
- i.
Vi = Vi + {v}, that is, add v to Vi.
- ii.
If k < m, then send message v : 0 : j1…jk : i to every lieutenant other than j1…jk.
- 3.For each i
- a.
When no more messages received by lieutenant i, then it obeys the order (message) via the function choice (Vi), which obtains a single order from a set of orders. Choice(V) = retreat if set V is empty or it consists of more than one element. If there is only a single element v in set V, then choice(V) = v.
Here, v : i is the value v signed by general i, and v : i : j is the message v : i counter signed by general j. Each general i maintains a set Vi which contains all orders received.

A schematic with a traitor commander at the top and lieutenants L 1 and 2. The commander orders attack to L 1 and retreat to L 2.
Example of a signed message protocol with SM(1) – traitor commander
With signed messages, it’s easy to detect if a commander is a traitor because its signature would appear on two different orders, and by the assumption of unforgeable signature, we know that only the commander could have signed the message.
Formally, for any m, the algorithm SM(m) solves the Byzantine generals problem if there are at most m traitors. The lieutenants maintain a vector of values and run a choice function to retrieve the order choice {attack, retreat}. Timeouts are used to ascertain if no more messages will arrive. Also, in step 2, lieutenant i ignores any message v that is already in the set Vi.
This algorithm has message complexity O(nm + 1), and it requires m + 1 number of rounds. This protocol works for N ≥ m + 2.
In contrast with the oral message protocol, the signed message protocol is more resilient against faults; here, if at least two generals are loyal in three generals, the problem is solvable. In the oral message, even if there is a single traitor in three generals, the problem is unsolvable.
DLS Protocols Under Partial Synchrony
After the FLP impossibility result, one of the ways that researchers introduced to circumvent the FLP impossibility is to use the partial synchrony network model. There are some important concepts presented in this paper, such as rotating coordinators, consensus, termination under partial synchrony, and implementation of the round-based mechanism. We discussed various models, including partial synchrony, in Chapter 3.
The paper describes four algorithms for crash-stop, omissions, Byzantine, and authenticated Byzantine faults under partial synchrony. The key idea in these algorithms is that the agreement and validity are always satisfied, whereas termination is guaranteed when the system stabilizes, that is, has good episodes of synchrony.
A basic round model is introduced where protocol execution is divided into rounds of message exchange and local computations. Each round comprises a send step, a receive step, and a computation step. In addition, the basic round model assumes a round, called the global stabilization round, during which or after correct processes receive all messages sent from correct processes.
In this section, algorithm 2 is presented, a consensus algorithm for Byzantine faults with authentication. It assumes a network model with partially synchronous communications and processors that can be Byzantine. This model is also adopted for most, if not all, blockchain networks.
The algorithm achieves strong unanimity for a set V with an arbitrary value under Byzantine faults with authentication.
The algorithm progresses in phases. Each phase k consists of four consecutive rounds, from 4k – 3 to 4k. Each phase has a unique coordinator c which leads the phase. A simple formula k = i (mod n) is used to select the coordinator from all processes, where k is the phase, i is the process number, and n is the total number of processes.
A local variable PROPER, which contains a set of values that the process knows to be proper.
A local variable ACCEPTABLE, which contains value v that process p has found to be acceptable. Note that a value v is acceptable to process p if p does not have a lock on any value except possibly v. Also, value v is proper.
A local variable LOCK which keeps the locked value. A process may lock a value in a phase if it believes that some process may decide on this value. Initially, no value is locked. A phase number is associated with every lock. In addition, a proof of acceptability of the locked value is also associated with every lock. Proof of acceptability is in the form of a set of signed messages sent by n − t processes, indicating that the locked value is acceptable and proper, that is, it is in their PROPER sets at the start of the given phase.
Algorithm N ≥ 3t + 1 – Byzantine faults with authentication
Trying phase k
Rounds:
Round 1: Round 4k – 3
Each process including the current coordinator sends an authenticated list of all its acceptable values to the current coordinator. Processes use the message format E(list, k), where E is an authentication function, k is the phase, and list is all acceptable values.
Round 2: Round 4k – 2
The current coordinator chooses a value to propose. If a value is to be proposed by the coordinator, the coordinator must have received at least n – t responses from the processes suggesting that this value is acceptable and proper at phase k. If there is more than one possible value that the coordinator may propose, then it will choose one arbitrarily.
The coordinator broadcasts a message of the form E(lock, v, k, proof), where the proof is composed of the set of signed messages E(list, k) received from the n − t processes that found v acceptable and proper.
Round 3: Round 4k – 1
If any process receives an E(lock, v, k, proof) message, it validates the proof to ascertain that n − t processors do find v acceptable and proper at phase k. If the proof is valid, it locks v, associating the phase number k and the message E(lock, v, k, proof) with the lock, and sends an acknowledgment to the current coordinator. In this case, the processes release any earlier lock placed on v. If the coordinator receives acknowledgments from at least 2t + 1 processors, then it decides on the value v.
Round 4: Round 4k
This is where locks are released. Processes broadcast messages of the form E(lock v, h, proof), indicating that they have a lock on value v with associated phase h and the associated proof and that a coordinator sent the message at phase h, which caused the lock to be placed. If any process has a lock on some value v with associated phase h and receives a properly signed message E(lock, w, h’, proof′) with w ≠ v and h′ ≥ h, then the process releases its lock on v. This means that if a most recent properly signed message is received by a process indicating a lock on some value which is different from its locally locked value and the phase number is either higher or equal to the current phase number, then it will release the lock from the local locked value.
Notes
Assuming that the processes are correct, two different values cannot be locked in the same phase because the correct coordinator will never send conflicting messages which may suggest locks on two different values.
This algorithm achieves consistency, strong unanimity, and termination under partial synchrony, with Byzantine faults and authentication, where n ≥ 3t + 1. Authenticated Byzantine means that failures are arbitrary, but messages can be signed with unforgeable digital signatures.
Consistency means no two different processes decide differently. Termination means every process eventually decides. Unanimity has two flavors, strong unanimity and weak unanimity. Strong unanimity requires that if all processes have the same initial value v and if any correct process decides, then it only decides on v. Weak unanimity means that if all processes have the same initial value v and all processes are correct, then if any process decides, it decides on v. In other words, strong unanimity means that if all initial values are the same, for example, v, then v is the only common decision. Under weak unanimity, this condition is expected to hold only if all processes are correct.
Ben-Or Algorithms
The Ben-Or protocol was introduced in 1983. It is named after its author Michael Ben-Or. This was the first protocol that solved the consensus problem with probabilistic termination under a model with a strong adversary. The Ben-Or algorithm proposed how to circumvent an FLP result and achieve consensus under asynchrony. There are two algorithms proposed in the paper. The first algorithm tolerates t < n/2 crash failures, and the second algorithm tolerates t < n/5 for Byzantine failures. In other words, with N > 2t it tolerates crash faults and achieves an agreement, and with N > 5t the protocol tolerates Byzantine faults and reaches an agreement. The protocol achieves consensus under the conditions described earlier, but the expected running time of the protocol is exponential. In other words, it requires exponential running time to terminate in the worst case because it can require multiple rounds to terminate. It can however terminate in constant time if the value of t is very small, that is, O(√n).
This protocol works in asynchronous rounds. A round simulates time because all messages are tagged with a round number, and because of this, processes can figure out which messages belong to which round even if they arrive asynchronously. A process ignores any messages for previous rounds and holds messages for future rounds in a buffer. Each round has two phases or subrounds. The first is the proposal (suggestion) phase, where each process p transmits its value v and waits until it receives from other n − t processes. In the second phase, called the decision (ratification) phase, the protocol checks if a majority is observed and takes that value; otherwise, it flips a coin. If a certain threshold of processes sees the same majority value, then the decision is finalized. In case some other value is detected as a majority, then the processor switches to that value. Eventually, the protocol manages to terminate because at some point all processes will flip the coin correctly and reach the majority value. You may have noticed that this protocol only considers binary decision values, either a 0 or 1. Another important aspect to keep in mind is that the protocol cannot wait indefinitely for all processes to respond because they could be unavailable (offline).
This algorithm works only for binary consensus. There are two variables that need to be managed in the algorithm, a value which is either 0 or 1 and phase (p), which represents the stage where the algorithm is currently at. The algorithm proceeds in rounds, and each round has two subrounds or phases.
Note that each process has its own coin. This class of algorithms that utilize such coin scheme is called local coin algorithms. Local coin tossing is implemented using a random number generator that outputs binary numbers. Each process tosses its own coin and outputs 0 or 1, each with probability ½. The coin is tossed by a process to pick a new local value if a majority was not found.
Here, r is the round number; x is the initial preference or value proposed by the process; 1 is the first subround, round, or phase of the main round; 2 is the second subround, round, or phase of the main round; * can be 0 or 1; ? represents no majority observed; N is the number of nodes (processes); D is an indication of approval (ratification) – in other words, it is an indication that the process has observed a majority of the same value – t is the number of faulty nodes; v is the value; and coinflip() is a uniform random number generator that generates either 0 or 1.

A flowchart of an agreement protocol starts with set X equals 0 or 1 and r equals 1 passes through broadcast, receive, and so on.
Ben-Or crash fault tolerant only agreement protocol – (non-Byzantine)
If n > 2t, the protocol guarantees with probability 1 that all processes will eventually decide on the same value, and if all processes start with the value v, then within one round all processes will decide on v. Moreover, if in some round a process decides on v after receiving more than t D type messages, then all other processes will decide on v within the next round.
The protocol described earlier works for crash faults; for tolerating Byzantine faults, slight modifications are required, which we describe next.
Here, r is the round number; x is the initial preference or value proposed by the process; 1 is the first subround, round, or phase of the main round; 2 is the second subround, round, or phase of the main round; * can be 0 or 1; ? represents no majority observed; N is the number of nodes (processes); D is an indication of approval (ratification) – in other words, it is an indication that the process has observed a majority of the same value – t is the number of faulty nodes; v is the value; and coinflip() is a uniform random number generator that generates either 0 or 1.

A flowchart of an agreement protocol starts with set X equals 0 or 1 and r equals 1 passes through broadcast, receive, and so on.
Ben-Or Byzantine agreement protocol
In the first subround or phase of the protocol, every process broadcasts its proposed preferred value and awaits n − t messages. If more than 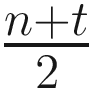 processes agree, then a majority is achieved, and the preferred value is set accordingly.
processes agree, then a majority is achieved, and the preferred value is set accordingly.
In the second subround or phase of the protocol, if a majority is observed in the first subround, then an indication of majority is broadcast (2, r, v, D); otherwise, if no majority (?) was observed in the first subround, then no majority is broadcast. The protocol then waits for n – t confirmations. If at least t + 1 confirmations of a majority of either 0 or 1 are observed, then the preferred value is set accordingly. Here, only the preferred value is set, but no decision is made. A decision is made by p if more than 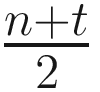 confirmations are received, only then the value is decided. If neither t + 1 confirmations nor
confirmations are received, only then the value is decided. If neither t + 1 confirmations nor  confirmations are received, then the coin is flipped to choose a uniform random value, either 0 or 1.
confirmations are received, then the coin is flipped to choose a uniform random value, either 0 or 1.
Note that, by waiting for n – t messages, the Byzantine fault case where Byzantine processes maliciously decide not to vote is handled. This is because in the presence of t faults, at least n is honest. In the second subround, t + 1 confirmations of a majority value mean that at least one honest process has observed a majority. In the case of 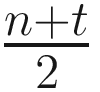 , it means a value has been observed by a majority.
, it means a value has been observed by a majority.
So, in summary, if n > 5t, this protocol guarantees with probability 1 that all processes will eventually decide on the same value, and if all processes start with the value v, then within one round all processes will decide on v. Moreover, if in some round an honest process decides on v after receiving more than  D type messages, then all other processes will decide on v within the next round.
D type messages, then all other processes will decide on v within the next round.
Note that I have used t to denote faulty processes, which is in line with the original paper on the subject. However, in literature f is also widely used to denote faults, either Byzantine or crash. So, t + 1 or f + 1 means the same thing, as t and f denote the same thing.
Now the question arises as to how this protocol achieves an agreement, validity, and termination. Let’s try to answer these questions.
An agreement is possible because at most one value can be in a majority in the first phase (subround) of the main round. If some process observes the t + 1 D type message (ratification message of the form (2, r, v, D)), then every process observes at least one ratification message of the form (2, r, v, D). Finally, if every process sees a ratification message of the form (2, r, v, D), then every process votes for value v (accepts value v) in the first subround (phase) of r + 1 and decides on v in the second subround (phase) unless it has decided already.
Validity is possible because if all processes vote for (accept) their common value v in a round, then all processes broadcast (2, r, v, D) and decide in the second subround of the round. Also, note that the preferred value of only one of the processes is broadcast in the first subround of the round.
The reason why Ben-Or terminates is because eventually the majority of the nonfaulty processes will flip a coin to achieve the same random value. This majority value is then observed by the honest processes, which then propagate the D type message (ratification message) with the majority value. Eventually, honest processes will receive the D type message (ratification message), and the protocol will terminate.
Also, note that the reason why two subrounds are required is because in the first phase the number of preferred value proposals is reduced to at most one, and then in the second subround, a simple majority vote is sufficient to make the decision. It is possible to design a consensus algorithm with only one round, but that will require a minimum number of processes to be 3f + 1. With two rounds under asynchrony, the 2f + 1 lower bound is met.
The Ben-Or algorithms described earlier do not use any cryptographic primitives and assume strong adversary. However, a lot of work has also been carried out where an asynchronous Byzantine agreement is studied under the availability of cryptographic primitives. Of course, under this model the adversary is assumed to be always computationally bounded. Some prominent early protocols under this model are described earlier, such as the signed message protocol and the DLS protocol for the authenticated Byzantine failure model. There are other algorithms that process coin tosses cooperatively or, in other words, use global or shared coin tossing mechanisms. A shared coin or global coin is a pseudorandom coin that produces the same result at all processes in the same round. This attribute immediately implies that convergence is much faster in the case of shared coin–based mechanisms. A similar technique was first used in Rabin’s algorithm [14] utilizing cryptographic techniques which reduced the expected time to the constant number of rounds.
After this basic introduction to early consensus protocols, I’ll now introduce early replication protocols, which of course are fundamentally based on consensus, but can be classified as replication protocols rather than just consensus algorithms.
We saw earlier, in Chapter 3, that replication allows multiple replicas to achieve consistency in a distributed system. It is a method to provide high availability in a distributed system. There are different models including primary backup replication and active replication. You can refer to Chapter 3 to read more about state machine replication and other techniques.
Consensus Using Failure Detectors
We discussed failure detectors and its different classes earlier in Chapter 3. Here, we present the outline of an algorithm called the Chandra-Toueg consensus protocol to solve consensus using an eventually strong ⋄S failure detector, which is the weakest failure detector for solving consensus [10]. Recall that an eventually strong failure detector satisfies strong completeness and eventual weak accuracy properties.
This protocol considers an asynchronous network model with  , that is, with at least
, that is, with at least  correct processes. Less than n/2 failed process assumption allows processes to wait to receive majority responses regardless of what the failure detector is suspecting.
correct processes. Less than n/2 failed process assumption allows processes to wait to receive majority responses regardless of what the failure detector is suspecting.
The protocol works in rounds under asynchrony with a rotating coordinator. The protocol uses reliable broadcast which ensures that any message broadcast is either not received (delivered) at all by any process or exactly once by all honest processes.
The algorithm works as follows.
Estimate of the decision value – proposed value
State
Process’s current round number
Last round in which the process updated its estimate (preference)
Until the state is decided, the processes go through multiple incrementing asynchronous rounds each divided into four phases or subrounds, and coordinators are rotated until a decision is reached. Coordinators are chosen in a round-robin fashion using the formula (r mod n) + 1, where r is the current round number, and n is the total number of processes:
- 1.
All processes send their estimate (preference) to the current coordinator using a message of type (process id, current round number, estimate, round number when the sender updated its estimate).
- 2.
The current coordinator waits to collect a majority
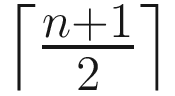 estimates and chooses the proposed value with the most recent (largest) value of the last updated round as its estimate and then proposes the new estimate to all processes.
estimates and chooses the proposed value with the most recent (largest) value of the last updated round as its estimate and then proposes the new estimate to all processes. - 3.
Each process waits for the new proposal (estimate) from the current coordinator or for the failure detector to suspect the current coordinator. If it receives a new estimate, it updates its preference, updates the last round variable to the current round, and sends the ack message to the current coordinator. Otherwise, it sends nack, suspecting that the current coordinator has crashed.
- 4.
The current coordinator waits for the
 – that is, a majority of replies from processes, either ack or nack. If the current coordinator receives a majority of acks, meaning
– that is, a majority of replies from processes, either ack or nack. If the current coordinator receives a majority of acks, meaning 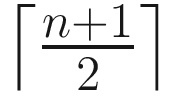 has accepted its estimate, then the estimate is locked, and the coordinator does a reliable broadcast of the decide message (decided value).
has accepted its estimate, then the estimate is locked, and the coordinator does a reliable broadcast of the decide message (decided value).
Finally, any undecided process that delivers a value via the reliable broadcast accepts and decides on that value.
Note that there are other algorithms in the paper [10] as well, but I have described here only the one that solves consensus using an eventually strong failure detector.
Now let’s see how agreement, validity, and termination requirements are met.
The agreement is satisfied. Let’s think about a scenario where it is possible that two coordinators broadcast, and some processes end up accepting a value from the first coordinator and some from the other. This will violate the agreement because, here, two processes are deciding differently, that is, two different values are both chosen. However, this cannot occur because for the first coordinator to send a decision, it must have received enough acknowledgments (acks) from the majority of the processes. All subsequent coordinators looking for the majority will see an overlap with the previous one. The estimate will be the most recent one. As such, any two coordinators broadcasting the decision are sending out the same decision.
Validity is also satisfied because every estimate is some process’s input value. The protocol design does not allow generating any new estimates.
The protocol eventually terminates because the failure detector, an eventually strong failure detector, will eventually stop suspecting some correct process, which will eventually become the coordinator. With the new coordinator, in some round, all correct processes will wait to receive this new coordinator’s estimate and will respond with enough ack messages. When the coordinator collects the majority of ack messages, it will send its decided estimate to all, and all processes will terminate. Note that if some process ends up waiting for a response from an already terminated process, it will also eventually get the message by retransmission through other correct nodes and eventually decide and terminate. For example, suppose a process gets stuck waiting for messages from a crashed coordinator. Eventually, due to the strong completeness property of the eventually strong failure detector, the failed coordinator will be suspected, ensuring progress.
Summary
This chapter covered early protocols that provide a solid foundation for most of the consensus research done today. With the advent of blockchains, many of these protocols inspired the development of new blockchain age protocols, especially for permissioned blockchains. For example, Tendermint is based on the DLS protocol, that is, algorithm 2 from the DLS paper.
We did not discuss every algorithm in this chapter, but this chapter should provide readers with a solid foundation to build on further. To circumvent FLP impossibility, randomness can be introduced into the system by either assuming the randomized model or local coin flips at the processes. The first proposal that assumes a randomized model (also called fair scheduling, randomized scheduling) mechanism is by Bracha and Toueg [17]. Algorithms based on the second approach where processes are provided with a local coin flip operation were first proposed by Ben-Or [2], which is the first randomized consensus protocol. The first approach to achieve the expected constant number of rounds by using the shared coin (global coin) approach implemented using digital signatures and a trusted dealer is published in Rabin [14]. Protocols utilizing failure detectors were proposed by Chandra and Toueg [15]. An excellent survey of randomized protocols for asynchronous consensus is by Aspnes [16].
Randomized protocols are a way to circumvent an FLP result, but can we refute the FLP impossibility result altogether? Sounds impossible, but we’ll see in Chapter 9 that refuting the FLP result might be possible.
In the next chapter, we will cover classical protocols such as PBFT, which is seen as a natural progression from the viewstamped replication (VR) protocol, which we will also introduce in the next chapter. While VR dealt with crash faults only, PBFT also dealt with Byzantine faults. We’ll cover other protocols, too, such as Paxos, which is the foundation of most if not all consensus protocols. Almost all consensus algorithms utilize the fundamental ideas presented in Paxos in one way or another.
Bibliography
- 1.
Impossibility of distributed consensus with one faulty process J. Assoc. Computer. Mach., 32 (No. 2) (1985), pp. 374–382.
- 2.
M. Ben-Or: Another advantage of free choice: Completely asynchronous agreement protocols.
- 3.
L. Lamport, R. Shostak, M. Pease, the Byzantine Generals problem, ACM Transactions on Programming Languages and Systems, vol. 4 (no. 3) (1982), pp. 382–401, July 1982.
- 4.
Lampson, Butler, and Howard E. Sturgis. “Crash recovery in a distributed data storage system.” (1979).
- 5.
Skeen, D., 1981, April. Nonblocking commit protocols. In Proceedings of the 1981 ACM SIGMOD international conference on Management of data (pp. 133–142).
- 6.
Dwork, C., Lynch, N., and Stockmeyer, L., 1988. Consensus in the presence of partial synchrony. Journal of the ACM (JACM), 35(2), pp. 288–323.
- 7.
G. Bracha, “Asynchronous Byzantine agreement protocols,” Inf. Comput., 1987.
- 8.
S. Toueg, “Randomized Byzantine agreements,” in PODC, 1984.
- 9.
G. Bracha and S. Toueg, “Resilient consensus protocols,” in PODC, 1983.
- 10.
Chandra, T.D. and Toueg, S., 1996. Unreliable failure detectors for reliable distributed systems. Journal of the ACM (JACM), 43(2), pp. 225–267.
- 11.
Martin Kleppmann’s lectures on distributed computing – Kleppmann, M., 2018. Distributed systems. www.cl.cam.ac.uk/teaching/2021/ConcDisSys/dist-sys-notes.pdf
- 12.
Distributed Algorithms: A Verbose Tour – by Fourre Sigs.
- 13.
Lindsey Kuper – lectures on distributed systems: https://youtube.com/playlist?list=PLNPUF5QyWU8PydLG2cIJrCvnn5I_exhYx
- 14.
Rabin, M.O., 1983, November. Randomized Byzantine generals. In 24th annual symposium on foundations of computer science (sfcs 1983) (pp. 403–409). IEEE.
- 15.
Chandra, T.D. and Toueg, S., 1996. Unreliable failure detectors for reliable distributed systems. Journal of the ACM (JACM), 43(2), pp. 225–267.
- 16.
Aspnes, J., 2003. Randomized protocols for asynchronous consensus. Distributed Computing, 16(2), pp. 165–175.
- 17.
Bracha, G. and Toueg, S., 1985. Asynchronous consensus and broadcast protocols. Journal of the ACM (JACM), 32(4), pp. 824–840.