
Consensus and replication protocols that appeared in the 1980s have made profound contributions in consensus protocol research. Early replication protocols like viewstamped replication provided deep insights into how fault-tolerant replication can be designed and implemented. Around the same time, Paxos was introduced, which offered a practical protocol with rigorous formal specification and analysis. In 1999, the first practical Byzantine fault–tolerant protocol was introduced. This chapter covers these classical protocols in detail, their design, how they work, and how they provide safety and liveness guarantees. Moreover, some ideas on how and if we can use them in the blockchain are also presented. Additionally, recently developed protocols such as RAFT are also discussed, which builds on previous classical protocols to construct an easy-to-understand consensus protocol.
Viewstamped Replication
A viewstamped replication approach to replicate among peers was introduced by Brian Oki and Barbara Liskov in 1988. This is one of the most fundamental mechanisms to achieve replication to guarantee consistency (consistent view) over replicated data. It works in the presence of crash faults and network partitions; however, it is assumed that eventually nodes recover from crashes, and network partitions are healed. It is also a consensus algorithm because to achieve consistency over replicated data, nodes must agree on a replicated state.
Viewstamped replication has two primary purposes. One is to provide a distributed system which is coherent enough that the clients see that as if they are communicating with a single server. The other one is to provide state machine replication. State machine replication requires that all replicas start in the same initial state and operations are deterministic. With these requirements (assumptions), we can easily see that if all replicas execute the same sequence of operations, then they will end up in the same state. Of course, the challenge here is to ensure that operations execute in the same order at all replicas even in the event of failures. So, in summary the protocol provides fault tolerance and consistency. It is based on a primary backup copy technique.
Normal operation protocol: Handles client requests and achieves replication under normal conditions
View change protocol: Handles primary failure and starts a new view with a new primary
Replica recovery protocol: Handles rejoining of a failed replica that has now recovered
VR is inspired by the two-phase commit protocol, but unlike the two-phase commit, it’s a failure-resilient protocol and does not block if the primary (coordinator in 2PC terminology) or replicas fail. The protocol is reliable and ensures availability if no more than f replicas are faulty. It uses replica groups of 2f + 1 and tolerates crash failures under asynchrony with f+1 quorum sizes.
Every replica maintains a state which contains information such as configuration, replica number, current view, current status – normal or view change or recovering, assigned op number to the latest request, log containing entries which contain the requests received so far with their op numbers, and the client table which consists of the most recent client request, with status if it has been executed or not and associated result for that request.
op: Client operation
c: Client ID
s: Number assigned to the request
v: View number known to the client
m: Message received from the client
n: The op number assigned to the request
i: Nonprimary replica
x: Result
Protocol Steps
- 1.
A client sends a request message of the form <REQUEST op, c, s, v> message to the primary replica.
- 2.When received by the primary
- a.
It increments the op number.
- b.
It adds the request message at the end of the log.
- c.
It sends a <PREPARE m, v, n> to other replicas.
- 3.When replicas receive the prepare message, they do the following:
- a.
The prepare message is only accepted if all previous requests preceding the op number in the prepare message have entries in their log.
- b.
Otherwise, they wait until the missing entries are updated – via state transfer.
- c.
They append the request to their log.
- d.
They send the <PREPAREOK v, n, i> message to the primary replica.
- 4.The primary waits for f PREPAREOK messages from other replicas; when received, it
- a.
Considers the operation to be committed
- b.
Executes any pending operations
- c.
Executes the latest operation
- d.
Sends the message <REPLY v, s, x> to the client
- 5.
After the commit, the primary replica informs other replicas about the commit.
- 6.
Other replicas execute it after appending it in their log but only after executing any pending operations.

A diagram of the V R protocol has lines for client, primary, replica 1 and 2. The lines are phased into request, prepare, prepare work, and reply.
VR protocol – normal operation
v: View number
l: Replica’s log/new log
k: The op number of the latest known committed request that the replica is aware of
I: Replica identifier
View Change
- 1.When a replica suspects the primary of failure, it
- a.
Increments its view number
- b.
Changes its status to view change
- c.
Sends a <DOVIEWCHANGE v, l, k, i> message to the primary of the next view
- 2.When the new primary gets f+1 of the DOVIEWCHANGE message, it
- a.
Chooses the most recent log in the message and picks that as its new log
- b.
Sets the op number to that of the latest entry in the new log
- c.
Changes its status to normal
- d.
Sends the <STARTVIEW v, l, k> message to other replicas, indicating the completion of the view change process
- 3.Now the new primary
- a.
Sequentially executes any unexecuted committed operations
- b.
Sends a reply to the client
- c.
Starts accepting new client requests
- 4.Other replicas upon receiving the startview message
- a.
Replace their log with the one in the message
- b.
Set their op number to the one in the latest entry in the log
- c.
Set their view number to what is in the message
- d.
Change their status to normal
- e.
Send PREPAREOK for uncommitted messages
The view change protocol repeats if even a new primary fails.

A diagram of the view change in V R has lines for primary, new primary, replica 1 and 2. The lines are phased into view change and new view.
View change in VR
The key safety requirement here is that all committed operations make it to the next views with their order preserved.
VR is not discussed with all intricate details on purpose, as we focus more on mainstream protocols. Still, it should give you an idea about the fundamental concepts introduced in VR, which play an essential role in almost all replication and consensus protocols, especially PBFT, Paxos, and RAFT. When you read the following sections, you will see how PBFT is an evolved form of VR and other similarities between VR and different protocols introduced in this chapter. When you read the section on RAFT, you will find good resemblance between VR and RAFT.
Let’s look at Paxos first, undoubtedly the most influential and fundamental consensus protocol.
Paxos
Leslie Lamport discovered Paxos. It was proposed first in 1988 and then later more formally in 1998. It is the most fundamental distributed consensus algorithm which allows consensus over a value under unreliable communications. In other words, Paxos is used to build a reliable system that works correctly, even in the presence of faults. Paxos made state machine replication more practical to implement. A version of Paxos called multi-Paxos is commonly used to implement a replicated state machine. It runs under a message-passing model with asynchrony. It tolerates fewer than n/2 crash faults, that is, it meets the lower bound of 2f + 1.
Earlier consensus mechanisms did not handle safety and liveness separately. The Paxos protocol takes a different approach to solving the consensus problem by separating the safety and liveness properties.
Proposer: Proposes values to be decided. An elected proposer acts as a single leader to propose a new value. Proposers handle client requests.
Acceptor: Acceptors evaluate and accept or reject proposals proposed by the proposers according to several rules and conditions.
Learner: Learns the decision, that is, the agreed-upon value.
There are also some rules associated with Paxos nodes. Paxos nodes must be persistent, that is, they must store what their action is and must remember what they’ve accepted. Nodes must also know how many acceptors make a majority.
Paxos can be seen as similar to the two-phase commit protocol. A two-phase commit (2PC) is a standard atomic commitment protocol to ensure that the transactions are committed in distributed databases only if all participants agree to commit. Even if a single node does not agree to commit the transaction, it is rolled back completely.
Similarly, in Paxos, the proposer sends a proposal to the acceptors in the first phase. Then, the proposer broadcasts a request to commit to the acceptors if and when they accept the proposal. Once the acceptors commit and report back to the proposer, the proposal is deemed final, and the protocol concludes. In contrast with the two-phase commit, Paxos introduced ordering, that is, sequencing, to achieve the total order of the proposals. In addition, it also introduced a majority quorum–based acceptance of the proposals rather than expecting all nodes to agree. This scheme allows the protocol to make progress even if some nodes fail. Both improvements ensure the safety and liveness of the Paxos algorithm.
The protocol is composed of two phases, the prepare phase and the accept phase. At the end of the prepare phase, a majority of acceptors have promised a specific proposal number. At the end of the accept phase, a majority of acceptors have accepted a proposed value, and consensus is reached.
The algorithm works as follows:
The proposer receives a request to reach consensus on a value by a client.
The proposer sends a message prepare(n) to a majority or all acceptors. At this stage, no value is proposed for a decision yet. The majority of acceptors is enough under the assumption that all acceptors in the majority will respond. Here, the n represents the proposal number which must be globally unique and must be greater than any proposal number this proposer has used before. For example, n can be a timestamp in nanoseconds or some other incrementing value. If a timeout occurs, then the proposer will retry with a higher n. In other words, if the proposer is unable to make progress due to a lack of responses from the acceptors, it can retry with a higher proposal number.
- When an acceptor receives this prepare(n) message, it makes a “promise.” It performs the following:
If no previous promise has been made by responding to the prepare message, then the acceptor now promises to ignore any request less than the proposal number n. It records n and replies with message promise(n).
If the acceptor has previously promised, that is, already responded to another prepare message with some proposal number lower than n, the acceptor performs the following:
If the acceptor has not received any accept messages already from a proposer in the accept phase, it stores the higher proposal number n and then sends a promise message to the proposer.
If the acceptor has received an accept message earlier with some other lower proposal number, it must have already accepted a proposed value from some proposer. This previous full proposal is now sent along with the promise message to the proposer, indicating that the acceptor has already accepted a value.
Phase 2 – accept phase
The proposer waits until it gets responses from the majority of the acceptors for n.
- When responses are received, the proposer evaluates what value v to be sent in the accept message. It performs the following:
If the proposer received one or more promise messages with full proposals, it chooses the value v in the proposal with the highest proposal number.
If no promise messages received by the proposer include a full proposal, the proposer can choose any value it wants.
The proposer now sends an accept message – a full proposal of the form accept(n, v) – to the acceptors, where n is the promised proposal number and v is the actual proposed value.
- When an acceptor receives this accept(n, v) message, it does the following:
If the acceptor has promised not to accept this proposal number previously, it will ignore the message.
Otherwise, if it has responded to the corresponding prepare request with the same n, that is, prepare(n), only then it replies with accepted(n, v) indicating acceptance of the proposal.
Finally, the acceptor sends accepted(n, v) to all learners.
If a majority of acceptors accept the value v in the proposal, then v becomes the decided value of the protocol i.e., consensus is reached.

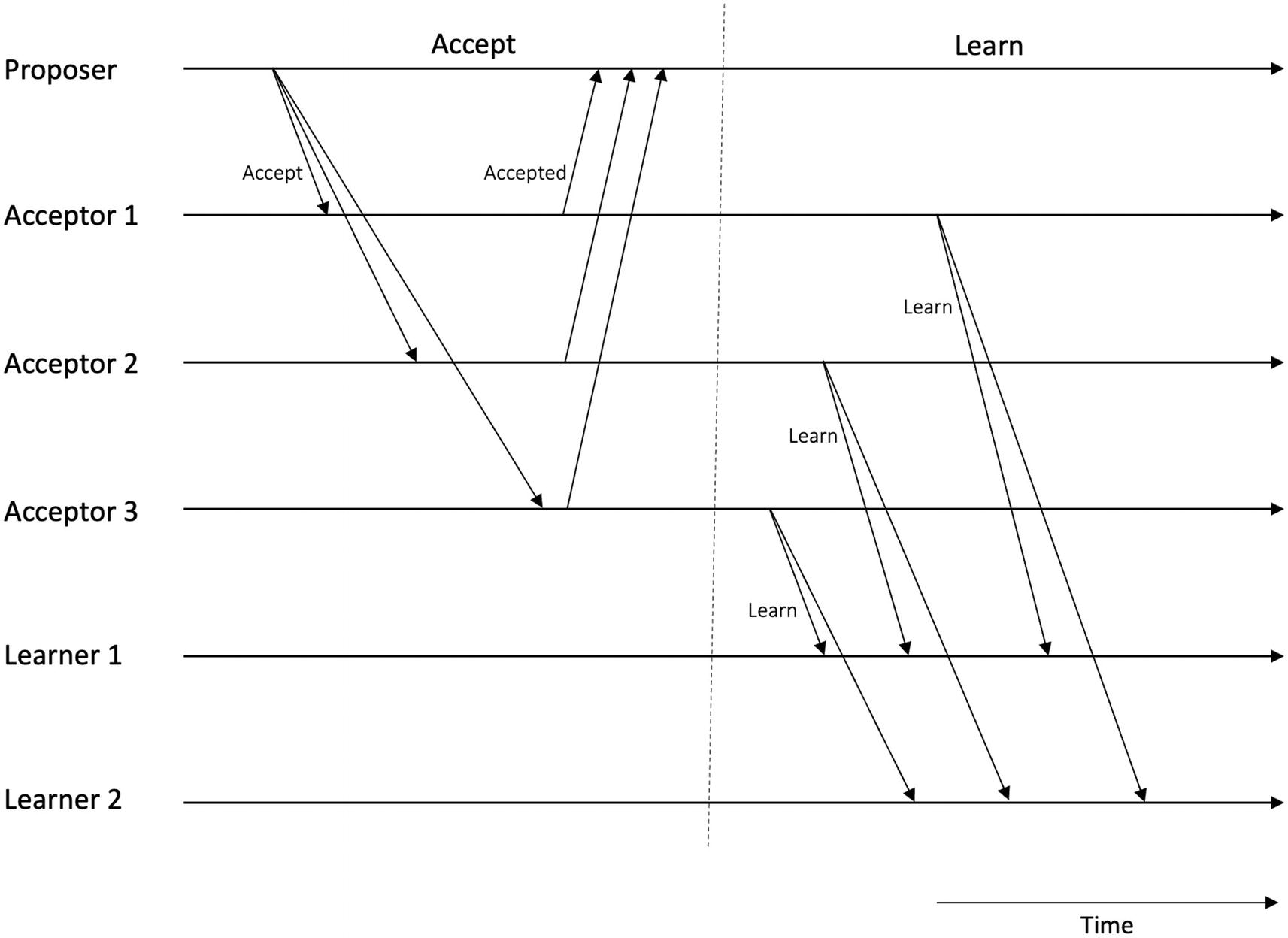
A diagram of a normal run of Paxos has lines for proposer, acceptor 1, 2, 3, learner 1, and 2. The lines are phased into prepare, accept, and learn.
A normal run of Paxos
We have used the term majority indicating that a majority of acceptors have responded to or accepted a message. Majority comes from a quorum. In the majority quorum, every quorum has 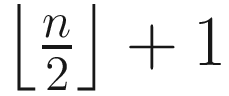 nodes. Also note that in order to tolerate f faulty acceptors, at least a set consisting of 2f + 1 acceptors is required. We discussed quorum systems in Chapter 3.
nodes. Also note that in order to tolerate f faulty acceptors, at least a set consisting of 2f + 1 acceptors is required. We discussed quorum systems in Chapter 3.
The protocol is illustrated in Figure 7-3.
Note that the Paxos algorithm once reached a single consensus will not proceed to another consensus. Another run of Paxos is needed to reach another consensus. Moreover, Paxos cannot make progress if half or more than half of the nodes are faulty because in such a case a majority cannot be achieved, which is essential for making progress. It is safe because once a value is agreed, it is never changed. Even though Paxos is guaranteed to be safe, liveness of the protocol is not guaranteed. The assumption here is that a large portion of the network is correct (nonfaulty) for adequately enough time, and then the protocol reaches consensus; otherwise, the protocol may never terminate.
Usually, learners learn the decision value directly from the acceptors; however, it is possible that in a large network learners may learn values from each other by relaying what some of them (a small group) have learned directly from acceptors. Alternatively, learners can poll the acceptors at intervals to check if there’s a decision. There can also be an elected learner node which is notified by the acceptors, and this elected learner disseminates the decision to other learners.
Now let’s consider some failure scenarios.
Failure Scenarios
Imagine if an acceptor fails in the first phase, that is, the prepare phase, then it won’t send the promise message back to the proposer. However, if a majority quorum can respond back, the proposer will receive the responses, and the protocol will make progress. If an acceptor fails in the second phase, that is, the accept phase, then the acceptor will not send the accepted message back to the proposer. Here again, if the majority of the acceptors is correct and available, the proposer and learners will receive enough responses to proceed.
What if the proposer failed either in the prepare phase or the accept phase? If a proposer fails before sending any prepare messages, there is no impact; some other proposer will run, and the protocol will continue. If a proposer fails in phase 1, after sending the prepare messages, then acceptors will not receive any accept messages, because promise messages did not make it to the proposer. In this case, some other proposer will propose with a higher proposal number, and the protocol will progress. The old prepare will become history. If a proposer fails during the accept phase after sending the accept message which was received by at least one acceptor, some other proposer will send a prepare message with a higher proposal number, and the acceptor will respond to the proposer with a promise message that an earlier value is already accepted. At this point, the proposer will switch to proposing the same earlier value bearing the highest accepted proposal number, that is, send an accept message with the same earlier value.
Another scenario could be if there are two proposers trying to propose their value at the same time. Imagine there are two proposers who have sent their prepare messages to the acceptors. In this case, any acceptor who had accepted a larger proposal number previously from P1 would ignore the proposal if the proposal number proposed by the proposer P2 is lower than what acceptors had accepted before. If there is an acceptor A3 who has not seen any value before, it would accept the proposal number from P2 even if it is lower than the proposal number that the other acceptors have received and accepted from P1 before because the acceptor A3 has no idea what other acceptors are doing. The acceptor will then respond as normal back to P2. However, as proposers wait for a majority of acceptors to respond, P2 will not receive promise messages from a majority, because A3 only is not a majority. On the other hand, P1 will receive promise messages from the majority, because A1 and A2 (other proposers) are in the majority and will respond back to P1. When P2 doesn’t hear from a majority, it times out and can retry with a higher proposal number.
Now imagine a scenario where with P1 the acceptors have already reached a consensus, but there is another proposer P2 which doesn’t know that and sends a prepare message with a higher than before proposal number. The acceptors at this point, after receiving the higher proposal number message from P2, will check if they have accepted any message at all before; if yes, the acceptors will respond back to P2 with the promise message of the form promise(nfromp2,(nfromp1, vfromp1)) containing the previous highest proposal number they have accepted, along with the previous accepted value. Otherwise, they will respond normally back to P2 with a promise message. When P2 receives this message, promise(nfromp2,(nfromp1, vfromp1)), it will check the message, and value v will become vfromp1 if nfromp1 is the highest previous proposal number. Otherwise, P2 will choose any value v it wants. In summary, if P2 has received promise messages indicating that another value has already been chosen, it will propose the previously chosen value with the highest proposal number. At this stage, P2 will send an accept message with its n and v already chosen (vfromp1). Now acceptors are happy because they see the highest n and will respond back with an accepted message as normal and will inform learners too. Note that the previously chosen value is still the value proposed by P2, just with the highest proposal number n now.
There are scenarios where the protocol could get into a livelock state and progress can halt. A scenario could be where two different proposers are competing with proposals. This situation is also known as “dueling proposers.” In such cases, the liveness of Paxos cannot be guaranteed.
Imagine we have two proposers, P1 and P2. We have three acceptors, A1, A2, and A3. Now, P1 sends the prepare messages to the majority of acceptors, A1 and A2. A1 and A2 reply with promise messages to P1. Imagine now the other proposer, P2, also proposes and sends a prepare message with a higher proposal number to A2 and A3. A3 and A2 send the promise back to P2 because, by protocol rules, acceptors will promise back to the prepare message if the prepare message comes with a higher proposal number than what the acceptors have seen before. In phase 2, when P1 sends the accept message, A1 will accept it and reply with accepted, but A2 will ignore this message because it has already promised a higher proposal number from P2. In this case, P1 will eventually time out, waiting for a majority response from acceptors because the majority will now never respond. Now, P1 will try again with a higher proposal number and send the prepare message to A1 and A2. Assume both A1 and A2 have responded with promise messages. Now suppose P2 sends an accept message to get its value chosen to A2 and A3. A3 will respond with an accepted message, but A2 will not respond to P2 because it has already promised another higher proposal number from P1. Now, P2 will time out, waiting for the majority response from the acceptors. P2 now will try again with a higher proposal number. This cycle can repeat again and again, and consensus will never be reached because there is never a majority response from the acceptors to any proposers.
This issue is typically handled by electing a single proposer as the leader to administer all clients’ incoming requests. This way, there is no competition among different proposers, and this livelock situation cannot occur. However, electing a leader is also not straightforward. A unique leader election is equivalent to solving consensus. For leader election, an instance of Paxos will have to run, that election consensus may get a livelock too, and we are in the same situation again. One possibility is to use a different type of election mechanism, for example, the bully algorithm. Some other leader election algorithms are presented in works of Aguilera et.al. We may use some other kind of consensus mechanism to elect a leader that perhaps guarantees termination but somewhat sacrifices safety. Another way to handle the livelock problem is to use random exponentially increasing delays, resulting in a client having to wait for a while before proposing again. I think these delays may well also be introduced at proposers, which will result in one proposer taking a bit of precedence over another and getting its value accepted before the acceptors could receive another prepared message with a higher proposal number. Note that there is no requirement in classical Paxos to have a single elected leader, but in practical implementations, it is commonly the case to elect a leader. Now if that single leader becomes the single point of failure, then another leader must be elected.
A key point to remember is that 2f + 1 acceptors are required for f crash faults to be tolerated. Paxos can also tolerate omission faults. Suppose a prepare message is lost and didn’t make it to acceptors, the proposer will wait and time out and retry with a higher proposal number. Also, another proposer can propose meanwhile with a higher proposal number, and the protocol can still work. Also, as only a majority of acceptor responses are required, as long as a majority of messages (2f + 1) made it through to the proposer from acceptors, the protocol will progress. It is however possible that due to omission faults, the protocol takes longer to reach consensus or may never terminate under some scenarios, but it will always be safe.
Safety and Liveness
The Paxos algorithm solves the consensus problem by achieving safety and liveness properties. We have some requirements for each property. Under safety, we mainly have the agreement and validity. An agreement means that no two different values are chosen. Validity or sometimes called nontriviality means no value is decided unless proposed by some process participating in the protocol. Another safety requirement which stems from the validity property and may be called “valid learning” is that if a process learns a value, the value must have been decided by a process. An agreement ensures that all processes decide on the same value. Validity and valid learning requirements ensure that processes decide only on a proposed value and do not trivially choose to not decide or just choose some predefined value.
Under liveness, there are two requirements. First, the protocol eventually decides, that is, a proposed value is eventually decided. Second, if a value is decided, the learners eventually learn that value.
Let’s now discuss how these safety and liveness requirements are met.
Intuitively, the agreement is achieved by ensuring that a majority of acceptors can vote for only one proposal. Imagine two different values v1 and v2 are somehow chosen (decided). We know that the protocol will choose a value only if a majority of the acceptors accept the same accept message from a proposer. This condition implies that a set of majority acceptors A1 must have accepted an accept message with a proposal (n1,v1). Also, another accept message with proposal (n2, v2) must have been accepted by another set of majority acceptors A2. Assuming that two majority sets A1 and A2 must intersect, meaning they will have at least one acceptor in common due to the quorum intersection rule. This acceptor must have accepted two different proposals with the same proposal number. Such a scenario is impossible because an acceptor will ignore any prepare or accept messages with the same proposal number they have already accepted.
If n1 <> n2 and n1 < n2 and n1 and n2 are consecutive proposal rounds, then this means that A1 must have accepted the accept message with proposal number n1 before A2 accepted the accept messages with n2. This is because an acceptor ignores any prepare or accept messages if they have a smaller proposal number than the previously promised proposal number. Also, the proposed value by a proposer must be from either an earlier proposal with the highest proposal number or the proposer’s own proposed value if no proposed value is included in the accepted message. As we know, A1 and A2 must intersect with at least one common acceptor; this common acceptor must have accepted the accept messages for both proposals (n1,v1) and (n2,v2). This scenario is also impossible because the acceptor would have replied with (n1,v1) in response to the prepare message with proposal number n2, and the proposer must have selected the value v1 instead of v2. Even with nonconsecutive proposals, any intermediate proposals must also select v1 as the chosen value.
Validity is ensured by allowing only the input values of proposers to be proposed. In other words, the decided value is never predefined, nor is it proposed by any other entity that is not part of the cluster running Paxos.
Liveness is not guaranteed in Paxos due to asynchrony. However, if some synchrony assumption, that is, a partially synchronous environment, is assumed, then progress can be made, and termination is achievable. We assume that after GST, at least a majority of acceptors is correct and available. Messages are delivered within a known upper bound, and an elected unique nonfaulty leader proposer is correct and available.
In Practice
Paxos has been implemented in many practical systems. Even though the Paxos algorithm is quite simple at its core, it is often viewed as difficult to understand. As a result, many papers have been written to explain it. Still, it is often considered complicated and tricky to comprehend fully. Nevertheless, this slight concern does not mean that it has not been implemented anywhere. On the contrary, it has been implemented in many production systems, such as Google’s Spanner and Chubby. The first deployment of Paxos was in a Petal distributed storage system. Some other randomly chosen examples include Apache ZooKeeper, NoSQL Azure Cosmos database, and Apache Cassandra. It proves to be the most efficient protocol to solve the consensus problem. It has been shown that the two-phase commit is a special case of Paxos, and PBFT is a refinement of Paxos.
Variants
There are many variants of classical Paxos, such as multi-Paxos, Fast Paxos, Byzantine Paxos, Dynamic Paxos, Vertical Paxos, Disk Paxos, Egalitarian Paxos, Stoppable Paxos, and Cheap Paxos.
Multi-Paxos
In classical Paxos, even in an all-correct environment, it takes two round trips to achieve consensus on a single value. This approach is slow, and if consensus is required on a growing sequence of values (which is practically the case), this single value consensus must repeatedly run, which is not efficient. However, an optimization can make classical Paxos efficient enough to be used in practical systems. Recall that Paxos has two phases. Once phases 1 and 2 both have completely run once, then, at that point, a majority of acceptors is now available to that proposer who ran this round of phases 1 and 2. This proposer is now a recognized leader. Instead of rerunning phase 1, the proposer (leader) can keep running phase 2 only, with the available majority of acceptors. As long as it does not crash, or some other proposer doesn’t come along and propose with a higher proposal number, this process of successive accept messages can continue. The proposer can keep running the accept/accepted round (phase 2) with even the same proposal number without running the prepare/promise round (phase 1). In other words, the message delays are reduced from four to two. When another proposer comes along or the previous one fails, this new proposer can run another round of phases 1 and 2 by following classical Paxos. When this new proposer becomes the leader by receiving a majority from the acceptors, the basic classical Paxos protocol upgrades to multi-Paxos, and it can start running phase 2 only. As long as there is only a single leader in the network, no acceptor would notify the leader that it has accepted any other proposal, which will let the leader choose any value. This condition allows omitting the first phase when only one elected proposer is the leader.
A diagram of multi-Paxos has lines for proposer, acceptor 1, 2, 3, learner 1, and 2. The lines are phased into accept and learn.
Multi-Paxos – note the first phase, prepare phase, skipped
Original Paxos is a leaderless (also called symmetric) protocol, whereas multi-Paxos is leader driven (also called asymmetric). It is used in practical systems instead of classical Paxos to enable state machine replication. Commonly in implementations, the role of the proposer, acceptor, and learner is contracted to so-called servers, which may all assume these three roles. Eventually, only a client-server model emerges. With roles collapsed, a steady leader and prepare phase removed, the protocol becomes efficient and simple.
Paxos is seen as a difficult protocol to understand. This is mostly due to underspecification. Also, the original protocol described by Lamport is a single decree protocol, which is not practical to implement. There have been several attempts, such as multi-Paxos, and several papers that try to explain Paxos, but, overall, the protocol is still considered a bit tricky to understand and implement. With these and several other points in mind, a protocol called RAFT was developed. We introduce RAFT next.
RAFT
RAFT is designed in response to shortcomings in Paxos. RAFT stands for Replicated And Fault Tolerant. The authors of RAFT had the main aim of developing a protocol which is easy to understand and easy to implement. The key idea behind RAFT is to enable state machine replication with a persistent log. The state of the state machine is determined by the persistent log. RAFT allows cluster reconfiguration which enables cluster membership changes without service interruption. Moreover, as logs can grow quite large on high throughput systems, RAFT allows log compaction to alleviate the issue of consuming too much storage and slow rebuild after node crashes.
No Byzantine failures.
Unreliable network communication.
Asynchronous communication and processors.
Deterministic state machine on each node that starts with the same initial state on each node.
Nodes have uncorruptible persistent storage with write-ahead logging, meaning any write to storage will complete before crashing.
The Client must communicate strictly with only the current leader. It is the Client’s responsibility as clients know all nodes and are statically configured with this information.
The leader receives client requests, manages replication logs, and manages communication with the followers.
Follower nodes are passive in nature and only respond to Remote Procedure Call (RPCs). They never initiate any communication.
A candidate is a role that is used by a node that is trying to become a leader by requesting votes.
Time in RAFT is logically divided into terms. A term (or epoch) is basically a monotonically increasing value which acts as a logical clock to achieve global partial ordering on events in the absence of a global synchronized clock. Each term starts with an election of a new leader, where one or more candidates compete to become the leader. Once a leader is elected, it serves as a leader until the end of the term. The key role of terms is to identify stale information, for example, stale leaders. Each node stores a current term number. When current terms are exchanged between nodes, it is checked if one node’s current term number is lower than the other node’s term number; if it is, then the node with the lower term number updates its current term to the larger value. When a candidate or a leader finds out that its current term number is stale, it transitions its state to follower mode. Any requests with a stale term number received by a node are rejected.

A schematic of the terms in R A F T. The terms 1, 2, and 5 are labeled normal operation. The terms 3 and 4 are labeled no leader elected.
Terms in RAFT
A RAFT protocol works using two RPCs, AppendEntries RPC, which is invoked by a leader to replicate log entries and is also used as a heartbeat, and RequestVote RPC, which is invoked by candidates to collect votes.
RAFT consists of two phases. The first is leader election, and the second is log replication. In the first phase, the leader is elected, and the second phase is where the leader accepts the clients’ requests, updates the logs, and sends a heartbeat to all followers to maintain its leadership.
First, let’s see how leader election works.
Leader Election
A heartbeat mechanism is used to trigger a leader election process. All nodes start up as followers. Followers will run as followers as long as they keep receiving valid RPCs from a leader or a candidate. If a follower does not receive heartbeats from the leader for some time, then an “election timeout” occurs, which indicates that the leader has failed. The election timeout is randomly set to be between 150ms and 300ms.
Now the follower node undertakes the candidate role and attempts to become the leader by starting the election process. The candidate increments the current term number, votes for itself, resets election timer, and seeks votes from others via the RequestVote RPC. If it receives votes from the majority of the nodes, then it becomes the leader and starts sending heartbeats to other nodes, which are now followers. If another candidate has won and became a valid leader, then this candidate would start receiving heartbeats and will return to a follower role. If no one wins the elections and election timeout occurs, the election process starts again with a new term.
Note that votes will only be granted by the receiver node in response to the RequestVote RPC if a candidate’s log is at least as up to date as the receiver’s log. Also, a “false” will be replied if the received term number is lower than the current term.

A flowchart of the R A F T leader election process starts with transition to candidate state and ends at become follower.
RAFT leader election

A flowchart for the node states in R A F T starts with node start up and ends at the follower. The flows pass from follower to candidate and leader.
Node states in RAFT
Once a leader is elected, it is ready to receive requests from clients. Now the log replication can start.
Log Replication
The log replication phase of RAFT is straightforward. First, the client sends commands/requests to the leader to be executed by the replicated state machines. The leader then assigns a term and index to the command so that the command can be uniquely identified in the logs held by nodes.
It appends this command to its log. When the leader has a new entry in its log, at the same time it sends out the requests to replicate this command via the AppendEntries RPC to the follower nodes.

A chart lists the log indexes of leader, follower 1, 2, 3, and 4. A horizontal line at the bottom, under the last index, is labeled committed entries.
Logs in RAFT nodes
Notice that entries up to log index number 6 are replicated on a majority of servers as the leader, follower 3, and follower 4 all have these entries, resulting in a majority – three out of five nodes. This means that they are committed and are safe to apply to their respective state machines. The log on followers 1 and 3 is not up to date, which could be due to a fault on the node or communication link failure. If there is a crashed or slow follower, the leader will keep retrying via the AppendEntries RPC until it succeeds.

A flowchart of the log replication process. The flow is leader, command, replicate append entries R P C from node 1 to 2 and 3, and reply.
RAFT log replication and state machine replication
When a follower receives an AppendEntries RPC for replication of log entries, it checks if the term is less than the current term it replies false. It appends only new entries that are not already in the logs. If an existing entry has the same index as the new one, but different terms, it will delete the existing entry and all entries following it. It will also reply false if the log does not have an entry at the index of the log entry immediately preceding the new one but the term matches.
If there is a failed follower or candidate, the protocol will keep retrying via the AppendEntries RPC until it succeeds.
If a command is committed, the RAFT cluster will not lose it. This is the guarantee provided by RAFT despite any failures such as network delays, packet loss, reboots, or crash faults. However, it does not handle Byzantine failures.
Each log entry consists of a term number, an index, and a state machine command. A term number helps to discover inconsistencies between logs. It gives an indication about the time of the command. An index identifies the position of an entry in the log. A command is the request made by the client for execution.
Guarantees and Correctness
- Election correctness
Election safety: At most, one leader can be elected in each term.
Election liveness: Some candidate must eventually become a leader.
Leader append-only: A leader can only append to the log. No overwrite or deletion of entries in the log is allowed.
Log matching: If two logs on two different servers have an entry with the same index and term, then these logs are identical in all previous entries, and they store the same command.
Leader completeness: A log entry committed in a given term will always be present in the logs of the future leaders, that is, leaders for higher-numbered terms. Also, nodes with incomplete logs must never be elected.
State machine safety: If a node has applied a log entry at a given index to its state machine, no other node will ever apply a different log entry for the same index.
Election correctness requires safety and liveness. Safety means that at most one leader is allowed per term. Liveness requires that some candidate must win and become a leader eventually. To ensure safety, each node votes only once in a term which it persists on storage. The majority is required to win the election; no two different candidates will get a majority at the same time.
Split votes can occur during leader election. If two nodes get elected simultaneously, then the so-called “split vote” can occur. RAFT uses randomized election timeouts to ensure that this problem resolves quickly. This helps because random timeouts allow only one node to time out and win the election before other nodes time out. In practice, this works well if the random time chosen is greater than the network broadcast time.
Log matching achieves a high level of consistency between logs. We assume that the leader is not malicious. A leader will never add more than one entry with the same index and same term. Log consistency checks ensure that all previous entries are identical. The leader keeps track of the latest index that it has committed in its log. The leader broadcasts this information in every AppendEntries RPC. If a follower node doesn’t have an entry in its log with the same index number, it will not accept the incoming entry. However, if the follower accepts the AppendEntries RPC, the leader knows that the logs are identical on both. Logs are generally consistent unless there are failures on the network. In that case, the log consistency check ensures that nodes eventually catch up and become consistent. If a log is inconsistent, the leader will retransmit missing entries to followers that may not have received the message before or crashed and now have recovered.
Reconfiguration and log compaction are two useful features of RAFT. I have not discussed those here as they are not related directly to the core consensus protocol. You can refer to the original RAFT paper mentioned in the bibliography for more details.
PBFT
Remember, we discussed the oral message protocol and the Byzantine generals problem earlier in the book. While it solved the Byzantine agreement, it was not a practical solution. The oral message protocol only works in synchronous environments, and computational complexity (runtime) is also high unless there is only one faulty processor, which is not practical. However, systems show some level of communication and processor asynchrony in practice. A very long algorithm runtime is also unacceptable in real environments.
A practical solution was developed by Castro and Liskov in 1999 called practical Byzantine fault tolerance (PBFT). As the name suggests, it is a protocol designed to provide consensus in the presence of Byzantine faults. Before PBFT, Byzantine fault tolerance was considered impractical. With PBFT, the duo demonstrated that practical Byzantine fault tolerance is possible for the first time.
PBFT constitutes three subprotocols called normal operation, view change, and checkpointing. The normal operation subprotocol refers to a mechanism executed when everything is running normally, and the system is error-free. The view change is a subprotocol that runs when a faulty leader node is detected in the system. Checkpointing is used to discard the old data from the system.
The PBFT protocol consists of three phases. These phases run one after another to complete a single protocol run. These phases are pre-prepare, prepare, and commit, which we will cover in detail shortly. In normal conditions, a single protocol run is enough to achieve consensus.
The protocol runs in rounds where, in each round, a leader node, called the primary node, handles the communication with the client. In each round, the protocol progresses through the three previously mentioned phases. The participants in the PBFT protocol are called replicas. One of the replicas becomes primary as a leader in each round, and the rest of the nodes act as backups. PBFT enables state machine replication, which we discussed earlier. Each node maintains a local log, and the logs are kept in sync with each other via the consensus protocol, PBFT.
We know by now that to tolerate Byzantine faults, the minimum number of nodes required is n = 3f + 1 in a partially synchronous environment, where n is the number of nodes and f is the number of faulty nodes. PBFT ensures Byzantine fault tolerance as long as the number of nodes in a system stays n ≥ 3f + 1.
When a client sends a request to the primary (leader), a sequence of operations between replicas runs, leading to consensus and a reply to the client.
Pre-prepare
Prepare
Commit
A service state
A message log
A number representing that replica’s current view
Let’s look at each of the phases in detail.
Pre-prepare phase – phase 1
When the primary node receives a request from the client, it assigns a sequence number to the request. It then sends the pre-prepare message with the request to all backup replicas.
Whether the digital signature is valid.
Whether the current view number is valid, that is, the replica is in the same view.
Whether the sequence number of the operation’s request message is valid, for example, if the same sequence number is used again, the replica will reject the subsequent request with the same sequence number.
If the hash of the request message is valid.
No previous pre-prepare message received with the same sequence number and view but a different hash.
If all these checks pass, the backup replicas accept the message, update their local state, and move to the prepare phase.
Accepts a request from the client.
Assigns to it the next sequence number. This sequence number is the order in which the request is going to be executed.
Broadcasts this information as the pre-prepare message to all backup replicas.
This phase assigns a unique sequence number to the client request. We can think of it as an orderer that applies order to the client requests.
Prepare phase – phase 2
Whether the prepare message has a valid digital signature.
The replica is in the same view as in the message.
The sequence number is valid and within the expected range.
The message digest (hash) value is correct.
If all these checks pass, the replica updates its local state and moves to the commit phase.
Accepts the pre-prepare message only if the replica has not accepted any pre-prepare messages for the same view or sequence number before
Sends the prepare message to all replicas
This phase ensures that honest replicas in the network agree on the total order of requests within a view.
Commit phase
Each replica sends a commit message to all other replicas in the network in the commit phase. Like the prepare phase, replicas wait for 2f + 1 commit messages to arrive from other replicas. The replicas also check the view number, sequence number, digital signature, and message digest values. If they are valid for 2f + 1 commit messages received from other replicas, the replica executes the request, produces a result, and finally updates its state to reflect a commit. If some messages are queued up, the replica will execute those requests first before processing the latest sequence numbers. Finally, the replica sends the result to the client in a reply message.
The client accepts the result only after receiving 2f + 1 reply messages containing the same result.
The replica waits for 2f + 1 prepare messages with the same view, sequence, and request.
It sends a commit message to all replicas.
It waits until a 2f + 1 valid commit message arrives and is accepted.
It executes the received request.
It sends a reply containing the execution result to the client.
This phase ensures that honest replicas in the network agree on the total order of client requests across views.
In essence, the PBFT protocol ensures that enough replicas process each request so that the same requests are processed and in the same order.

A diagram has lines for client, primary, replica 2, 3, and 4. The lines are phased into request, pre-prepare, prepare, commit, and reply.
PBFT normal mode operation
During the execution of the protocol, the protocol must maintain the integrity of the messages and operations to deliver an adequate level of security and assurance. Digital signatures fulfill this requirement. It is assumed that digital signatures are unforgeable, and hash functions are collision resistant. In addition, certificates are used to ensure the proper majority of participants (nodes).
Certificates in PBFT
Certificates in PBFT protocols establish that at least 2f + 1 replicas have stored the required information. In other words, the collection of 2f + 1 messages of a particular type is considered a certificate. For example, suppose a node has collected 2f + 1 messages of type prepare. In that case, combining it with the corresponding pre-prepare message with the same view, sequence, and request represents a certificate, called a prepared certificate. Likewise, a collection of 2f + 1 commit messages is called a commit certificate.
v: View number
o: Operation requested by a client
t: Timestamp
c: Client identifier
r: Reply
m: Client’s request message
n: Sequence number of the message
h: Hash of the message m
i: Identifier of the replica
s: Stable checkpoint – last
C: Certificate of the stable checkpoint (2f + 1 checkpoint messages)
P: Set of prepared certificates for requests
O: Set of pre-prepare messages to be processed
V: Proof of the new view (2f + 1 view change messages)
Let’s now look at the types of messages and their formats. These messages are easy to understand if we refer to the preceding variable list.
Types of Messages
PBFT protocol messages
Message | From | To | Format | Signed by |
|---|---|---|---|---|
Request | Client | Primary | <REQUEST, o, t, c> | Client |
Pre-prepare | Primary | Replicas | <<PRE-PREPARE, v, n, h>, m>> | Primary |
Prepare | Replica | Replicas | <PREPARE, v, n, h, i> | Replica |
Commit | Replica | Replicas | <COMMIT, v, n, h, i> | Replica |
Reply | Replicas | Client | <REPLY, r, i> | Replica |
View change | Replica | Replicas | <VIEWCHANGE, v+1, n, s, C, P, i> | Replica |
New view | Primary | Replicas | <NEWVIEW, v + 1, V, O> | Replica |
Checkpoint | Replica | Replicas | <CHECKPOINT, n, h, i> | Replica |
Note that all messages are signed with digital signatures, which enable every node to identify which replica or client generated any given message.
View Change
A view change occurs when a primary replica is suspected faulty by other replicas. This phase ensures protocol progress. A new primary is selected with a view change, which starts normal mode operation again. The new primary is chosen in a round-robin fashion using the formula p = v mod n, where v is the view number and n is the total number of nodes in the system.
When a backup replica receives a request, it tries to execute it after validating the message, but for any reason, if it does not execute it for a while, the replica times out. It then initiates the view change subprotocol.
During the view change, the replica stops accepting messages related to the current view and updates its state to a view change. The only messages it can receive in this state are checkpoint, view change, and new view messages. After that, it broadcasts a view change message with the next view number to all replicas.
When this message reaches the new primary, the primary waits for at least 2f view change messages for the next view. If at least 2f + 1 view change messages are acquired, it broadcasts a new view message to all replicas and runs normal operation mode once again.
When other replicas receive a new view message, they update their local state accordingly and start the normal operation mode.
- 1.
Stop accepting pre-prepare, prepare, and commit messages for the current view.
- 2.
Construct a set of all the certificates prepared so far.
- 3.
Broadcast a view change message with the next view number and a set of all the prepared certificates to all replicas.

A diagram of view change protocol has lines for primary, new primary, replica 3, and 4. The lines are phased into view-change and new view.
View change protocol
- 1.
A replica that has broadcast the view change message waits for 2f+1 view change messages and then starts its timer. If the timer expires before the node receives a new view message for the next view, the node will start the view change for the next sequence but increase its timeout value. This situation will also occur if the replica times out before executing the new unique request in the new view.
- 2.
As soon as the replica receives f+1 view change messages for a view number greater than its current view, the replica will send the view change message for the smallest view it knows of in the set so that the next view change does not occur too late. This is also the case even if the timer has not expired; it will still send the view change for the smallest view.
- 3.
As the view change will only occur if at least f + 1 replicas have sent the view change message, this mechanism ensures that a faulty primary cannot indefinitely stop progress by successively requesting view changes.
It can happen especially in busy environments that storage becomes a bottleneck. To solve this issue, checkpointing is used in the PBFT protocol.
The Checkpoint Subprotocol
Checkpointing is a crucial subprotocol. It is used to discard old messages in the log of all replicas. With this, the replicas agree on a stable checkpoint that provides a snapshot of the global state at a certain point in time. This is a periodic process carried out by each replica after executing the request and marking that as a checkpoint in its log. A variable called “low watermark” (in PBFT terminology) is used to record the last stable checkpoint sequence number. This checkpoint is broadcast to other nodes. As soon as a replica has at least 2f + 1 checkpoint messages, it saves these messages as proof of a stable checkpoint. It discards all previous pre-prepare, prepare, and commit messages from its logs.
PBFT Advantages and Disadvantages
PBFT is a groundbreaking protocol that has introduced a new research area of practical Byzantine fault–tolerant protocols. The original PBFT have many strengths, but it also has some weaknesses. We introduce those next.
Strengths
PBFT provides immediate and deterministic transaction finality. In comparison, in the PoW protocol, several confirmations are required to finalize a transaction with high probability.
PBFT is also energy efficient as compared to PoW, which consumes a tremendous amount of electricity.
Weaknesses
PBFT is not very scalable. This limitation is why it is more suitable for consortium networks than public blockchains. It is, however, considerably faster than PoW protocols.
Sybil attacks are possible to perform on a PBFT network, where a single entity can control many identities to influence the voting and, consequently, the decision.
High communication complexity.
Not suitable for public blockchains with anonymous participants.
PBFT guarantees safety and liveness. Let’s see how.
Safety and Liveness
Liveness means that a client eventually gets a response to its request if the message delivery delay does not increase quicker than the time itself indefinitely. In other words, the protocol ensures progress if latency increases slower than the timeout threshold.
A Byzantine primary may induce delay on purpose. However, this delay cannot be indefinite because every honest replica has a view change timer. This timer starts whenever the replica receives a request. Suppose the replica times out before the request is executed; the replica suspects the primary replica and broadcasts a view change message to all replicas. As soon as f + 1 replicas suspect the primary as faulty, all honest replicas enter the view change process. This scenario will result in a view change, and the next replica will take over as the primary, and the protocol will progress.
Liveness is guaranteed, as long as no more than 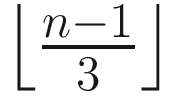 replicas are faulty, and the message delay does not grow faster than the time itself. It means that the protocol will eventually make progress with the preceding two conditions. This weak synchrony assumption is closer to realistic environments and enables the system to circumvent the FLP result. A clever trick here is that if the view change timer expires before a replica receives a valid new view message for the expected new view, the replica doubles the timeout value and restarts its view change timer. The idea is that the timeout timer doubles the wait time to wait for a longer time as the message delays might be more extensive. Ultimately, the timer values become larger than the message delays, meaning messages will eventually arrive before the timer expires. This mechanism ensures that eventually a new view will be available on all honest replicas, and the protocol will make progress.
replicas are faulty, and the message delay does not grow faster than the time itself. It means that the protocol will eventually make progress with the preceding two conditions. This weak synchrony assumption is closer to realistic environments and enables the system to circumvent the FLP result. A clever trick here is that if the view change timer expires before a replica receives a valid new view message for the expected new view, the replica doubles the timeout value and restarts its view change timer. The idea is that the timeout timer doubles the wait time to wait for a longer time as the message delays might be more extensive. Ultimately, the timer values become larger than the message delays, meaning messages will eventually arrive before the timer expires. This mechanism ensures that eventually a new view will be available on all honest replicas, and the protocol will make progress.
Also, a Byzantine primary cannot do frequent view changes successively to slow down the system. This is so because an honest replica joins the view change only when it has received at least f + 1 view change messages. As there are at most f faulty replicas, only f replicas cannot cause a view change when all honest replicas are live, and the protocol is making progress. In other words, as at most f successive primary replicas can be faulty, the system eventually makes progress after at most f + 1 view changes.
Replicas wait for 2f + 1 view change messages and start a timer to start a new view which avoids starting a view change too soon. Similarly, if a replica receives f + 1 view change messages for a view greater than its current view, it broadcasts a view change. This prevents starting the next view change too late.
Safety requires that each honest replica execute the received client request in the same total order, that is, execute the same request in the same order in all phases.
PBFT is assumed safe if the total number of nodes is 3f + 1. In that case, f Byzantine nodes are tolerated.
Let’s first recall what a quorum intersection is. If there are two sets, say S1 and S2, with ≥2f + 1 nodes each, then there is always a correct node in S1 ∩ S2. This is true because if there are two sets of at least 2f + 1 nodes each, and there are 3f + 1 nodes in total, then the pigeonhole principle implies that the intersection of S1 and S2 will have at least f + 1 nodes. As there are at most f faulty nodes, the intersection, S1 ∩ S2 must contain at least 1 correct node.
Each phase in PBFT must acquire 2f + 1 certificate/votes to be accepted. It turns out that at least one honest node must vote twice on the same sequence number to result in a safety violation, which is not possible because an honest node cannot vote maliciously. In other words, if the same sequence number is assigned to two different messages by a malicious primary to violate safety, then at least one honest replica will reject it due to a quorum intersection property. This is because a 2f + 1 quorum means that there is at least one honest intersecting replica.
The commit phase ensures that the correct order is achieved even across views. If a view change occurs, the new primary replica acquires prepared certificates from 2f + 1 replicas, which ensures that the new primary gets at least one prepared certificate for every client request executed by a correct replica.
Order Within a View
If a replica acquires a prepared certificate for a request within a view and a unique sequence number, then no replica can get a prepared certificate for a different request with the same view and sequence number. Replicas can only get a prepared certificate for the same request with the same view and sequence number.
Imagine two replicas have gathered prepared certificates for two different requests with the same view and sequence number. We know that a prepared certificate contains 2f+1 messages, which implies that a correct node must have sent a pre-prepare or prepare message for two different requests with the same sequence and view due to quorum intersection. However, a correct replica only ever sends a single pre-prepare for each view and sequence, that is, a sequence number is always incremented when the client request is received by the primary and assigned to the request. Also, a correct replica only sends one prepare message in each view and for a sequence. It sends out a prepare message only if it has not accepted any pre-prepare messages for the same view or sequence number before. This means that the prepare must be for the same request. This achieves order within a view.
Order Across Views
The protocol guarantees that if a correct replica has executed a client request in a view with a specific sequence number, then no correct replica will execute any other client request with the same sequence number in any future view or current view. In other words, every request executed by an honest replica must make it to the next view in the same order assigned to it previously.
We know that a request only executes at a replica if it has received 2f + 1 commit messages. Suppose an honest replica has acquired 2f + 1 commit messages. In that case, it means that the client request must have been prepared at, at least, f + 1 honest replicas, and each of these replicas has a prepare certificate for it and all the previous client requests. We also know that at least one of these f + 1 honest replicas will participate in the view change protocol and report these requests along with their certificates. This implies that the request will always carry the same sequence number in the new view.
This completes our discussion on PBFT. However, it’s a vast subject, and you can further explore the original papers and thesis to learn more.
Blockchain and Classical Consensus
We can implement classical algorithms in the blockchain. However, the challenge is modifying these protocols to make them suitable for blockchain implementations. The core algorithm remains the same, but some aspects are changed to make the protocol suitable for the blockchain. One issue is that these traditional consensus algorithms are for permissioned environments where all participants are known and identifiable. But blockchain networks are public and anonymous, for example, Bitcoin and Ethereum. Therefore, classical algorithms are primarily suitable for permissioned blockchain networks for enterprise use cases where all participants are known. Also, blockchain network environments are Byzantine, where malicious actors may try to deviate from the protocol. And Paxos and RAFT are CFT protocols that are not suitable for Byzantine environments. As such, either these protocols need to be modified to BFT protocols to tolerate Byzantine faults, or different BFT protocols need to be used. These BFT protocols can be a modification of existing classical CFT or BFT protocols or can be developed specifically for blockchains from scratch. One attempt to modify an existing classical protocol to suit a permissioned blockchain environment is IBFT, which we will introduce in Chapter 8. We will discuss more about blockchain protocols in the next chapter.
Dynamic membership (reconfiguration) and log compaction using snapshots are two very useful features which RAFT supports. These two features are particularly useful in consortium blockchains. Over time, the blockchain can grow significantly large, and snapshotting would be a useful way to handle that storage issue. Also, membership management can be a useful feature where a new consortium member can be onboarded in an automated fashion. RAFT, however, is CFT only, which is not quite suitable for consortium chains. Nevertheless, introducing Byzantine fault tolerance in RAFT is possible, as Tangaroa shows - a BFT extension to RAFT. Some issues however are reported in Tangaroa, but it is quite possible to build a BFT version of RAFT. Alternatively, these two features can be implemented in a PBFT variant for blockchain networks. Variants of PBFT include IBFT, HotStuff, LibraBFT, and many others.
Summary
In this chapter, we covered a number of topics including viewstamped replication, practical Byzantine fault tolerance, RAFT, and Paxos. Paxos and viewstamped replication are fundamentally important because they provide very fundamental ideas in the history of the distributed consensus problem. Paxos especially provided formal description and proofs of protocol correctness. VR bears resemblance with multi-Paxos. RAFT is a refinement of Paxos. PBFT is in fact seen as a Byzantine-tolerant version of Paxos, though PBFT was developed independently.
This chapter serves as a foundation to understand classical protocols before blockchain age protocols in the next chapter. Many ideas originate from these classical protocols that lead to the development of newer protocols for the blockchain.
Bibliography
- 1.
A Google TechTalk, 2/2/18, presented by Luis Quesada Torres. https://youtu.be/d7nAGI_NZPk
- 2.
Lindsey Kuper’s lectures on distributed systems: https://youtu.be/fYfX9IGUiVw
- 3.
Bashir, I., 2020. Mastering Blockchain: A deep dive into distributed ledgers, consensus protocols, smart contracts, DApps, cryptocurrencies, Ethereum, and more. Packt Publishing Ltd.
- 4.
Bully algorithm: https://en.wikipedia.org/wiki/Bully_algorithm
- 5.
Zhao, W., 2014. Building dependable distributed systems. John Wiley & Sons.
- 6.
Unique Leader election is equivalent to solving consensus – Gray, J. and Lamport, L., 2006. Consensus on transaction commit. ACM Transactions on Database Systems (TODS), 31(1), pp. 133–160.
- 7.
Leader election algorithms – Aguilera, M.K., Delporte-Gallet, C., Fauconnier, H., and Toueg, S., 2001, October. Stable leader election. In International Symposium on Distributed Computing (pp. 108–122). Springer, Berlin, Heidelberg.
- 8.
- 9.
Aspnes, J., 2020. Notes on theory of distributed systems. arXiv preprint arXiv:2001.04235.
- 10.
Howard, H., 2014. ARC: analysis of Raft consensus (No. UCAM-CL-TR-857). University of Cambridge, Computer Laboratory.
- 11.
Ongaro, D. and Ousterhout, J., 2015. The raft consensus algorithm.
- 12.
Ongaro, D. and Ousterhout, J., 2014. In search of an understandable consensus algorithm. In 2014 USENIX Annual Technical Conference (Usenix ATC 14) (pp. 305–319).
- 13.
Tangaroa issues: Cachin, C. and Vukolić, M., 2017. Blockchain consensus protocols in the wild. arXiv preprint arXiv:1707.01873.
- 14.
Liskov, B., 2010. From viewstamped replication to Byzantine fault tolerance. In Replication (pp. 121–149). Springer, Berlin, Heidelberg.
- 15.
Wattenhofer, R., 2016. The science of the blockchain. Inverted Forest Publishing.