
Chapter 6. Objects, Inputs, Scope, and Mechanism
Having answered the three key questions posed in Chapter 5 (see Asking the Right Questions), you should have a pretty good idea of what you want to accomplish with your system. In this chapter, we start showing you how to accomplish those goals. We’ll start identifying the components of your reputation system and we systematically determine these details:
Which objects (people or things) will play a part in the reputation system? Some objects will themselves be reputable entities and will accrue and lose reputation over time. Other objects may not directly benefit from having a reputation but may play a part in the system nevertheless.
What inputs will feed into your system? Inputs frequently will take the form of actions that your users may take, but other inputs are possible, and we’ll discuss them in some detail.
In the case of user-expressed opinions and actions, what are the appropriate mechanisms to offer your users? What would be the difference between offering 5-star ratings, thumbs-up voting, or social bookmarking?
In addition, we share a number of practitioner’s tips, as always. This time around, we consider the effects of exclusivity on your reputation system (how stingy, or how generous, should you be when doling out reputations?). We also provide some guidance for determining the appropriate scope of your reputations in relation to context.
The Objects in Your System
To accomplish your reputation-related goals, you’ll have two main weapons—the objects that your software understands and the software tools, or mechanisms, that you provide to users and embed in processes. To put it simply, if you want to build birdhouses, you need wood and nails (the objects) along with saws and hammers (the tools), and you need someone to do the actual construction (the users).
Architect, Understand Thyself
Where will the relevant objects in your reputation system come from? Why, they’re present in your larger application, of course. (Not all objects need be contained within the application—see Relevant external objects—but this will be the majority case.) Let’s start by thinking clearly about the architecture and makeup of your application.
Tip
In places, it may sound as though we’re describing a “brownfield” deployment of your reputation system: that is, that we’re assuming you already have an application in mind or in production and are merely retrofitting a reputation system onto it. That is not at all the case.
You would consider the same questions and dependencies regardless of whether your host application was already live or was still in the planning stages. It’s just much easier for us to talk about reputation as though there were preexisting objects and models to graft it onto. (Planning your application architecture is a whole other book altogether.)
So…what does your application do?
You know your application model, right? You can probably list the five most important objects represented in your system without even breaking a sweat. In fact, a good place to start is by composing an “elevator pitch” for your application; in other words, describe, as succinctly as you can, what your application will do. Here are some examples:
A social site that lets you share recipes and keep and print shopping lists of ingredients
A tool that lets you edit music mashups, build playlists of them, and share those lists with your friends
An intranet application that lets paralegal assistants access and save legal briefs and share them with lawyers in a firm
These are short, sweet, and somewhat vague descriptions of three very different applications, but each one still tells us much of what we need to know to plan our reputation needs. The recipe sharing site likely will benefit from some form of reputation for recipes and will require some way for users to rate them. The shopping lists? Not so much; those are more like utilities for individual users to manage the application data.
Tip
If an artifact or object in your system has an audience of one, you probably don’t need to display a reputation for it. You may, however, opt to keep one or more reputations for those objects’ useful inputs—designed to roll up into the reputations of other, more visible objects.
As for the music site, perhaps it’s not any one track that’s worth assessing but the quality of the playlists. Or maybe what’s relevant is users’ reputations as deejays (their performance, over time, at building and sustaining an audience). Tracking either one will probably also require keeping mashup tracks as an object in the system, but those tracks may not necessarily be treated as primary reputable entities.
In the intranet application for paralegals, the briefs are the primary atomic unit of interest. Who saved what briefs, how are users adding metadata, and how many people attach themselves to a document? These are all useful bits of information that will help filter and rank briefs to present back to other users.
So the first step toward defining the relevant objects in your reputation system is to start with what’s important in the application model, then think forward a little to what types of problems reputation will help your users solve. Then you can start to catalog the elements of your application in a more formal fashion.
Perform an application audit
Although you’ve thought at a high level about the primary objects in your application model, you’ve probably overlooked some smaller-order, secondary objects and concepts. These primary and secondary objects relate to one another in interesting ways that we can make use of in our reputation system. An application audit can help you to fully understand the entities and relationships in your application.
Make a complete inventory of every kind of object in your application model that may have anything to do with accomplishing your goals. Some obvious items are user profile records and data objects that are special to your application model: movies, transactions, landmarks, CDs, cameras, or whatever. All of these are clear candidates for tracking as reputable entities.
It is very important to know what objects will be the targets of reputation statements and any new objects you’ll need to create for that purpose. Make sure you understand the metadata surrounding each object and how your application will access it. How are the objects organized? Are they searchable by attributes? Which attributes? How are the different objects related to one another?
Some objects in your application model will be visually represented in the interface, so one way to start an audit is with a simple survey of screen designs, at whatever fidelity is available. For in-progress projects, early-stage wireframes are fine—if your application is in production, take some screenshots and print them. Figure 6-1 shows an audit-screengrab for a project already in production, Yahoo! Message Boards.
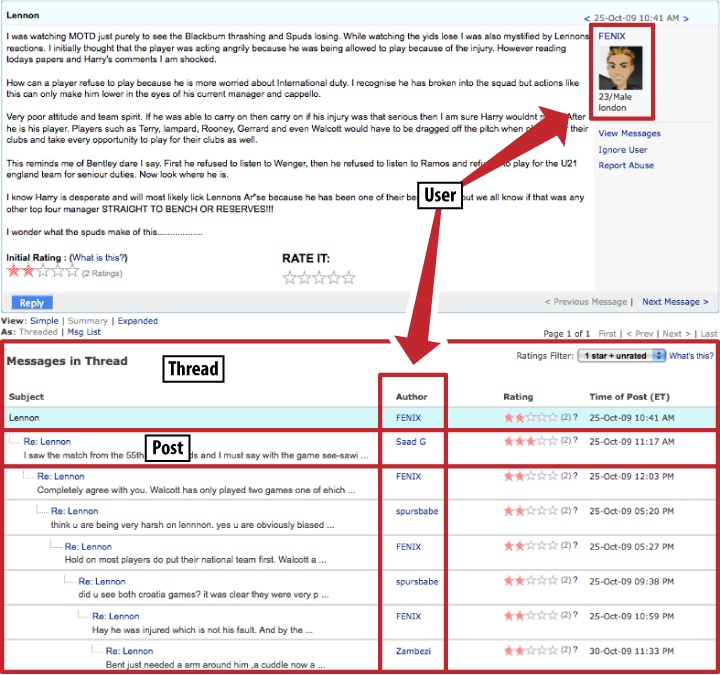
Also be sure to list items whose creation, editing, or content can be used as input into your reputation model. Some common types of such items are:
Categorization systems, such as folders, albums, or collections
Tags
Comments
Uploads
Spend some time considering more nuanced sources of information, such as historical activity data, external reputation information, and special processes that provide application-relevant insight.
As an example, consider a profanity filter applied to user-supplied text messages, replacing positive matches with asterisks (****); the real-time results of applying the filter might provide a way to measure the effects of interface changes on this particular user behavior (the use of profanity).
What Makes for a Good Reputable Entity?
An object that makes a good candidate for tracking as a reputable entity in your system probably has one or more of the characteristics outlined in the following sections.
People are interested in it
This probably should go without saying, but—what the heck—let’s say it anyway. If your entire application offering is built around a specific type of object, social or otherwise, the object is probably a good candidate for tracking as a reputable entity.
And remember, nothing interests people more than…other people. That phenomenon alone is an argument for at least considering using karma (people reputation) in any application that you might build. Users will always want every possible edge in understanding other actors in a community. What motivates them? What actions have they performed in the past? How might they behave in the future?
When you’re considering what objects will be of the most interest to your users, don’t overlook other, related objects that also may benefit users. For example, on a photo-sharing site, it seems natural that you’d track a photo’s reputation. But what about photo albums? They may not be the very first application object that you think of, but in some situations, it’s likely you’ll want to direct users’ attention to high-quality groupings or collections of photos.
The solution is to track both objects. Each may affect the reputation of the other to some degree, but the inputs and weightings you’ll use to generate reputation for each will necessarily differ.
The decision investment is high
Some decisions are easy to make, requiring little investment of time or effort. Likewise, the cost of recovering from such decisions is negligible. For example, suppose I ask myself, “Should I read this blog entry?”
If it’s a short entry, and I’m already engaged in the act of reading blogs, and no other distractions are calling me away from that activity, then, yeah, I’ll probably go ahead and give it a read. (Of course, the content of the entry itself is a big factor. If neither the entry’s title nor a quick skim of the body interests me, I’ll likely pass it up.) And, once I’ve read it, if it turns out not to have been a very good choice? Well, no harm done. I can recover gracefully, move on to the next entry in my feed reader, and proceed on my way.
The level of decision investment is important because it affects the likelihood that a user will make use of available reputation information for an item. In general, the greater the investment in a decision, the more a user will expect (and make use of) robust supporting data (see Figure 6-2).

So for high-investment decisions (such as purchasing or any other decision that is not easily rescinded), offer more robust mechanisms, such as reputation information, for use in decision making.
The entity has some intrinsic value worth enhancing
You can do a lot with design to “ease” the presence of reputation inputs in your application interface. Sites continue to get more and more sophisticated with incorporating explicit and implicit controls for stating an entity value. Furthermore, the web-using public is becoming more and more accepting of, and familiar with, popular voting and favoriting input mechanisms.
Neither of these facts, however, obviates this requirement: reputable entities themselves must have some intrinsic value apart from the reputation system. Ask your users to participate only in ways that are appropriate in relation to that object’s intrinsic value. Don’t ask users for contributions (such as reviews or other metadata) that add value to an object whose intrinsic apparent value is low.
It might be OK, for example, to ask someone to give a thumbs-up rating to someone else’s blog comment (because the cost to the user providing the rating is low—basically a click). But it would be inappropriate to ask for a full-blown review of the comment. Writing the review would require more effort and thought than there was in the initial comment.
The entity should persist for some length of time
Reputable entities must remain in the community pool long enough for all members of the community to cast a vote (Figure 6-3). There’s little use in asking users for metadata for an item if other users cannot come along afterward and enjoy the benefit of that metadata.

Highly ephemeral items, such as news articles that disappear after 48 or 72 hours, probably aren’t good candidates for certain types of reputation inputs. For example, you wouldn’t ask users to author a multi-part review of a news story destined to vanish in less than a day, but you might ask them to click a “Digg this” or “Buzz this” button.
Items with a great deal of persistence (such as real-world establishments like restaurants or businesses) make excellent candidates for reputation. Furthermore, it can be appropriate to ask users for more involved types of inputs for persistent items, because it’s likely that other users will have a chance to benefit from the work that the community puts into contributing content.
Determining Inputs
Now that you have a firm grasp of the objects in your system and you’ve elected a handful as reputable entities, the next step is to decide what’s good and what’s bad. How will you decide? What inputs will you feed into the system to be tabulated and rolled up to establish relative reputations among like objects?
User Actions Make Good Inputs
Now, instead of merely listing the objects that a user might interact with in your application, we’ll enumerate all the actions that she might take in relation to those objects. Again, many actions will be obvious and visible right there in your application interface, as in Figure 6-4, so let’s build on the audit that you performed earlier for objects.
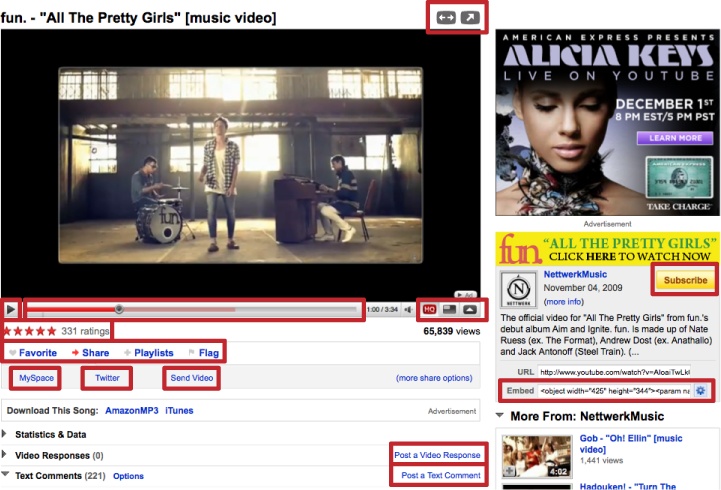
Explicit claims
Explicit claims represent your community’s voice and opinion. They operate through interface elements you provide that solicit users’ opinions about an entity, good or bad. A fundamental difference exists between explicit claims and implicit ones (discussed below), which boils down to user intent and comprehension.
With explicit claims, users should be fully aware that the action they’re performing is intended as an expression of an opinion. That intent differs greatly from the ones for implicit claims, in which users mostly just go about their business, generating valuable reputation information as a side effect.
Implicit claims
Any time a user takes some action in relation to a reputation entity, it is very likely that you can derive valuable reputation information from that action. Recall the discussion of implicit and explicit reputation claims in The Reputation Statement. With implicit reputation claims, we watch not what the user says about the quality of an entity but how they interact with that object. For example, assume that a reputable entity in your system is a text article. You’ll find valuable reputation information in the answers to the following questions:
Does the user read the article? To completion?
Does the user save the article for later use?
By bookmarking it?
By clipping it?
Does the user republish the article to a wider audience?
By sending it to a friend?
By publishing to a tweet-stream?
By embedding it on a blog?
Does the user copy or clone the article for use in writing another article?
You can construct any number of smart, nuanced, and effective reputation models from relevant related action-type claims. Your only real limitation is the level and refinement of instrumentation in your application: are you prepared to capture relevant actions at the right junctures and generate reputation events to share with the system?
Caution
Don’t get too clever with implicit action claims, or you may unduly influence users’ behavior. If you weigh implicit actions into the formulation of an object or a person’s reputation and you make that fact known, you’re likely to actually motivate users to take those actions arbitrarily. This is one of the reasons that many reputation-intensive sites are coy about revealing the types and weightings of claims in their systems. (See the sectionKeep Your Barn Door Closed (but Expect Peeking).)
But Other Types of Inputs Are Important, Too
A reputation system doesn’t exist in a vacuum; it’s part of a bigger application, which itself is part of a bigger ecosystem of applications. Relevant inputs come from many sources other than those generated directly by user actions. Be sure to build, buy, or otherwise include them in your model where needed. Here are some common examples:
External trust databases
Social networking relationships
Relationships may be used to infer positive reputation by proxy.
In many cases, when surfacing an evaluation of a reputable object, relationship should be a primary search criterion: “Your brother recommends this camera.”
Session data
Browser cookies are good for tracking additional metadata about user visits: is a user logged-out? Newly registered? Returning after some amount of time away?
Session cookies can be used to build up a reputation history.
Identity cookies allow various identities, browsers, and sessions to be linked together.
Asynchronous activations
Just-in-time inputs. Many reputation models are real-time systems in which reputations change constantly, even when users aren’t providing any direct input. For example, a mail antispam reputation model for IP addresses could handle irregularly timed, asynchronous inputs about mail volume received over time from an address to allow the reputation to naturally reflect traffic. In this example, the volume of incoming email that isn’t marked as spam would cause the IPs reputation to improve sporadically.
Time-activated inputs. Also called cron jobs (for the Unix tool
cronthat executes them), these often are used to start a reputation process as part of periodic maintenance; for example, a timer can trigger reputation scores to decay or expire. (For one benefit of calculating reputation on a time-delay, see Decay and delay.) Timers may be periodic or scheduled ad hoc by an application.Customer care corrections and operator overrides. When things go wrong, someone’s got to fix it via a special input channel. This is a common reason that many reputation processes are required to be reversible.
Of course, the messages that each reputation process outputs also are potential inputs into other processes. Well-designed karma models don’t usually take direct inputs at all—those processes always take place downstream from other processes that encode the understanding of the relationship between the objects and transform that code into a normalized score.
Good Inputs
Whether your system features explicit reputation claims, implicit ones, or a skillful combination of both, to maintain the quality of the inputs to the system, strive to follow the practices described next.
Emphasize quality, not simple activity
Don’t continue to reward people or objects for performing the same action over and over; rather, try to single out events that indicate that the target of the claim is worth paying attention to. For instance, the act of bookmarking an article is probably a more significant event than a number of page views. Why? Because bookmarking something is a deliberate act—the user has assessed the object in question and decided that it’s worth further action.
Rate the thing, not the person
The process of creating karma is subtly more complex and socially delicate than creating reputation for things. For a deeper explanation, see Karma. Yahoo! has a general community policy of soliciting explicit ratings input only for user-created content—never having users directly rate other users. This is a good practice for a number of reasons:
It keeps the focus of debate on the quality of the content an author produces, which is what’s of value to your community (instead of on the quality of her character, which isn’t).
It reduces ad hominem attacks and makes for a nicer culture within the community.
Reward firsts, but not repetition
It’s often worthwhile to reward firsts for users in your system, perhaps rewarding the first user to “touch” an object (leave a review, comment on a story, or post a link). Or, conversely, you might reward a whole host of firsts for a single user (to encourage him to interact with a wide range of features, for instance).
But once a first has been acknowledged, don’t continue to reward users for more of the same.
Pick events that are hard for users to replicate; this combats gaming of the system. But anticipate these patterns of behavior anyway, and build a way to deal with offenders into your system.
Use the right scale for the job
In Ratings bias effects, we discussed ratings distributions and why it’s important to pay attention to them. If you’re seeing data with poorly actionable distributions (basically, data that doesn’t tell you much), it’s likely that you’re asking for the wrong inputs.
Pay attention to the context in which you’re asking. For example, if interest in the object being rated is relatively low (perhaps it’s official feed content from a staid, corporate source), 5-star ratings are probably overkill. Your users won’t have such a wide range of opinions about the content that they’ll need five stars to judge it.
Match user expectations
Ask for information in a way that’s consistent and appropriate with how you’re going to use it. For example, if your intent is to display the community average rating for a movie on a scale of 1 to 5 stars, it makes the most sense to ask users to enter movie ratings on a scale of 1 to 5 stars. Of course, you can transform reputation scores and present them back to the community in different ways (see the sidebar What Comes in Is Not What Goes Out), but strive to do that only when it makes sense and in a way that doesn’t confuse your users.
Common Explicit Inputs
In Chapter 7, we’ll focus on displaying aggregated reputation, which is partly constructed with the inputs we discuss here, and which has several output formats identical to the inputs (for example, 5 stars in, 5 stars out). But that symmetry exists only for a subset of inputs and an ever-smaller subset of the aggregated outputs. For example, an individual vote may be a yes or a no, but the result is a percentage of the total votes for each.
In this chapter, we’re discussing only claims on the input side—what does a user see when she takes an action that is sent to the reputation model and transformed into a claim?
The following sections outline best practices for the use and deployment of the common explicit input types. The user experience implications of these patterns are also covered in more depth in Christian Crumlish and Erin Malone’s Designing Social Interfaces (O’Reilly).
The ratings life cycle
Before we dive into all the ways in which users might provide explicit feedback about objects in a system, think about the context in which users provide feedback. Remember, this book is organized around the reputation information that users generate—usable metadata about objects and about other people. But users themselves have a different perspective, and their focus is often on other matters altogether (see Figure 6-5). Feeding your reputation system is likely the last thing on their mind.
Given the other priorities, goals, and actions that your users might possibly be focused on at any given point during their interaction with your application, here are some good general guidelines for gathering explicit reputation inputs effectively.
The interface design of reputation inputs
Your application’s interface design can reinforce the presence of input mechanisms in several ways:
Place input mechanisms in comfortable and clear proximity to the target object that they modify. Don’t expect users to find a ratings widget for that television episode when the widget is buried at the bottom of the page. (Or at least don’t expect them to remember which episode it applies to…or why they should click it…or….)
Don’t combine too many different rateable entities on a single screen. You may have perfectly compelling reasons to want users to rate a product, a manufacturer, and a merchant all from the same page—but don’t expect them to do so consistently and without becoming confused.
Carefully strike a balance between the size and proportion of reputation-related mechanisms and any other (perhaps more important) actions that might apply to a reputable object.
For example, in a shopping context, it’s probably appropriate to make “Add to Cart” the predominant call to action and keep the Rate This button less noticeable—even much less noticeable. (Would you rather have a rating, or a sale?)
Make the presentation and formatting of your input mechanisms consistent. You may be tempted to try “fun” variations like making your ratings stars different colors in different product categories, or swapping in a little Santa for your thumb-up and thumb-down icons during the holidays.
In a word: don’t. Your users will have enough work in finding, learning, and coming to appreciate the benefits of interacting with your reputation inputs. Don’t throw unnecessary variations in front of them.
Stars, bars, and letter grades
A number of different input mechanisms let users express an opinion about an object across a range of values. A very typical such mechanism is star ratings. Yahoo! Local (see Figure 6-6) allows users to rate business establishments on a scale of 1 to 5 stars.
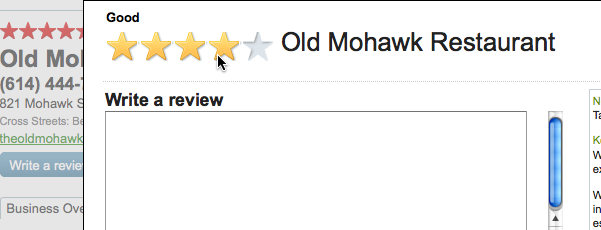
Stars seem like a pretty straightforward mechanism, both for your users to consume (5-star rating systems seem to be everywhere, so users aren’t unfamiliar with them) and for you, the system designer, to plan. Tread carefully, though. Here are some small behavioral and interaction “gotchas” to think about early, during the design phase.
The schizophrenic nature of stars
Star ratings often are displayed back to users in a format very similar to the one in which they’re gathered from users. That arrangement need not be the case—scores generated by stars can be transformed into any number of output formats for display—but as we noted earlier (see Match user expectations), it’s usually what is clearest to users.
As the application designer, you should be wary, however, of making the input-form for stars match too closely their final display presentation. The temptation is strong to design one comprehensive widget that accomplishes both: displaying the current community average rating for an object and accepting user input to cast their own vote.
Slick mouse-over effects or toggle switches that change the state of the widget are some attempts that we’ve seen, but this is tricky to pull off, and almost never done well. You’ll either end up with a widget that does a poor job at displaying the community average or one that doesn’t present a very strong call to action.
The solution that’s most typically used at Yahoo! is to separate these two functions into two entirely different widgets and present them side by side on the page. The widgets are even color-coded to keep their intended uses straight. On Yahoo!, red stars are typically read-only (you can’t interact with them) and always reflect the community average rating for an entity, whereas yellow stars reflect the rating that you as a user entered (or, alternately, empty yellow stars wait eagerly to record your rating).
From a design standpoint, the distinction does introduce additional interactive and visual complexity to any component that displays ratings, but the increase in clarity more than compensates for any additional clutter.
Do I like you, or do I “like” like you
Though it’s a fairly trivial task to determine numerical values for selections along a 5-point scale, there’s no widespread agreement among users on exactly what star ratings represent. Each user applies a subtly different interpretation (complete with biases) to star ratings. Ask yourself the following questions—they’re the questions that users have to ask each time they come across a ratings system:
What does “one star” mean on this scale? Should it express strong dislike? Apathy? Mild “like”? Many star-ratings widgets provide suggested interpretations at each point along the spectrum, such as “Dislike it,” “Like it,” and “Love it.”
The drawback to that approach is that it constrains the uses that individual users might find for the system. The advantage is that it brings the community interpretation of the scale into greater agreement.
What opinion does no rating express? Should the interface provide an explicit option for “no rating?” Yahoo! Music’s 5-star ratings widget feeds a recommender system that suggests new music according to what you’ve liked in the past. The site actually offers a sixth option (not presented as a star) intended to express “Don’t play this track again.”
Can the user change a rating already submitted? Adding such functionality—to change a vote that’s already been cast—is another reason to make an interaction design distinction between rating an item and reviewing the community average. If you support undo or change, now your super-sized universal one-size-fits-all vote and display widget will also need to support that function, too. (Good luck with that.)
Can a rating include half-stars? Often, regardless of whether you allow half-step input for ratings, you will want to allow half-step display of community averages. In any event, notice that the possibility of half-values for stars effectively doubles the expressive range of the scale.
Two-state votes (thumb ratings)
“Thumb” voting (thumb up or thumb down) lets a user quickly rate content in a fun, engaging way (see Figure 6-7). The benefit to the user for voting is primarily related to self-expression (“I love this!” or “I hate this!”). The ratings don’t need to be presented visually as thumbs (in fact, sometimes they shouldn’t), but in this book, we use “thumb” as shorthand for a two-state voting mechanism.
Thumb voting allows users to express strongly polarized opinions about assets. For example, if you can state your question as simply as “Did you like this or not?”, thumb voting may be appropriate. If it seems more natural to state your question as “How much did you like this?”, then star ratings seem more appropriate.
A popular and effective use of two-state voting is as a meta-moderation device for user-submitted opinions, comments, and reviews, as in Figure 6-8. Wherever you solicit user opinions about an object, also consider letting the community voice opinions about that opinion, by providing an easy control such as “Was this helpful?” or “Do you agree?”

Avoid thumb voting for multiple facets of an entity. For example, don’t provide multiple thumb widgets for a product review intended to record users’ satisfaction with the product’s price, quality, design, and features. Generally, a thumb vote should be associated with an object in a one-to-one relationship: one entity gets one thumb up or down. Think of the metaphor, after all: Emperor Nero never would have let a gladiator’s arm survive while putting his leg to death. Think of thumb voting as an all-or-nothing rating.
Consider thumb voting when you want a fun, lightweight rating mechanism. The context for thumb voting should be appropriately fun and lighthearted, too; don’t use thumb voting in contexts where it will appear insensitive or inappropriate.
Caution
An upraised thumb is considered offensive in some cultures. If your site has potential international appeal, watch out.
Don’t use thumb ratings when you want to compare qualitative data among assets. For example, in a long list of movies available for rental, you may want to permit sorting of the list by average rating. If you have been collecting thumb ratings, such sorting wouldn’t be very useful to users. (Instead, consider a 5-star scalar rating style.)
Vote to promote: Digging, liking, and endorsing
Vote to promote fulfills a very specific niche in the world of online opinion-gathering. As users browse a collection or pool of media objects, they mark items as worthwhile using a control consisting of a simple gesture. This pattern has been popularized by social news sites such as Digg, Yahoo! Buzz, and Newsvine.
Typically, these votes accumulate and are used to change the rank of items in the community pool and present winners with more prominence or a higher status, but that’s not an absolute necessity. Facebook offers an “I like this” link (Figure 6-9 ) that simply communicates a user’s good will toward an item.
The names of users who “like” an item are displayed to other users who encounter the item (until the list of vote casters becomes cumbersome, when the display switches to a sort of summary score), but highly liked items aren’t promoted above other items in the news feed in any obvious or overt way.
User reviews
Writing a user review demands a lot of effort from users. It is among the most involved explicit input mechanisms that you can present, usually consisting of detailed, multi-part data entry (see Figure 6-10).
To get good, usable comparison data from user reviews, try to ensure that the objects you offer up for review meet all the criteria that we listed above for good reputable entities (see What Makes for a Good Reputable Entity?). Ask users to write reviews only for objects that are valuable, long-lived, and that have a high-investment decision.
Reviews typically are compound reputation claims, with each review made up of a number of smaller inputs bundled together. You might consider any combination of the following for your user-generated reviews:
You can include a freeform comment field (see Text comments) for users to provide their impressions of the rated object, good or bad. You may impose some standards on this field (for example, checking for profanity or requiring length in a certain character range), but generally this field is provided for users to fill in as they please.
Optionally, the review may feature a title. Also a freeform text entry, the title lets users put their “brand” on a review or give it extra appeal and pizazz. Users often use the title field to grab attention and summarize the tone and overall opinion of the full review.
Consider including an explicit scalar ratings widget, such as a 5-star scale (Stars, bars, and letter grades). It’s almost always a good idea to display one overall rating for the object in question.
For example, even if you’re asking users to rate multiple facets of, say, a movie (direction, acting, plot, and effects), you can provide one prominent rating input for the users’ overall opinion. You could just derive the average from a combination of the facet reviews, but that wouldn’t be as viscerally satisfying for opinionated reviewers.
You may want to let users attach additional media to a review—for example, upload a video testimonial or attach URLs for additional resources (Flickr photos or relevant blog entries). The more participation you can solicit from reviewers, the better. And to bootstrap a review’s quality reputation, you can consider each additional resource as an input.
Common Implicit Inputs
Remember, with implicit reputation inputs, we are going to pay attention to some subtle and nonobvious indicators in our interface. Actions that—when users take them—may indicate a higher level of interest (indicative of higher quality) in the object targeted.
It is difficult to generalize about implicit inputs because they are highly contextual. They depend on the particulars of your application: its object model, interaction styles, and screen designs. However, the following inputs represent the types of inputs you can track.
Favorites, forwarding, and adding to a collection
Any time a user saves an object or marks it for future consideration—either for himself or to pass along to someone else—that could be a reputable event.
This type of input has a lot in common with the explicit vote-to-promote input (see Vote to promote: Digging, liking, and endorsing), but the difference lies in user intent and perception: in a vote-to-promote system, the primary motivator for marking something as worthwhile is to publicly state a preference, and the expectation is that information will be shared with the community. It is a more extrinsic motivation.
By contrast, favorites, forwarding, and adding to a collection are more intrinsically motivated reputation inputs—actions that users take for largely private purposes.
Favorites
To mark an item as a favorite, a user activates some simple control (usually clicking an icon or a link), which adds the item to a list that she can return to later for browsing, reading, or viewing.
Some conceptual overlap exists between the favorites pattern, which can be semipublic (favorites often are displayed to the community as part of a user’s profile) and the liking pattern. Both favorites and liking can be tallied and fed in almost identical ways into an object’s quality reputation.
Forwarding
You might know this input pattern as “send to a friend.” This pattern facilitates a largely private communication between two friends, in which one passes a reputable entity on to another for review. Yahoo! News has long promoted most emailed articles as a type of currency-of-interest proxy reputation. (See Figure 6-11.)
Adding to a collection
Many applications provide ordering mechanisms for users as conveniences: a way to group like items, save them for later, edit them en masse. Depending on the context of your application, and the culture of use that emerges out of how people interact with collections on your site, you may want to consider each “add to collection” action as an implicit reputation statement, akin to favoriting or sending to a friend.
Greater disclosure
Greater disclosure is a highly variable input: there’s a wide range of ways to present it in an interface (and weight it in reputation processes). But if users request “more information” about an object, you might consider those requests as a measure of the interest in that object—especially if users are making the requests after having already evaluated some small component of the object, such as an excerpt, a thumbnail, or a teaser.
A common format for blogs, for instance, is to present a menu of blog entries, with excerpts for each, and “read more” links. Clicks on a link to a post may be a reasonably accurate indicator of interest in the destination article.
But beware—the limitations of a user interface can render such data misleading. In the example in Figure 6-12, the interface may not reveal enough content to allow you to infer the real level of interest from the number of clicks. (Weight such input accordingly.)
Reactions: Comments, photos, and media
One of the very best indicators of interest in an entity is the amount of conversation, rebuttal, and response that it generates. While we’ve cautioned against using activity alone as a reputation input (to the detriment of good quality indicators), we certainly don’t want to imply that conversational activity has no place in your system. Far from it. If an item is a topic of conversation, the item should benefit from that interest.
The operators of some popular websites realize the value of rebuttal mechanisms and have formalized the ability to attach a response to a reputable entity. YouTube’s video responses feature is an example (see Figure 6-13). As with any implicit input, however, be careful; the more your site’s design shows how your system uses those associations, the more tempting it will be for members of your community to misuse them.
Constraining Scope
When you’re considering all the objects that your system will interact with, and all the interactions between those objects and your users, it’s critical to take into account an idea that we have been reinforcing throughout this book: all reputation exists within a limited context, which is always specific to your audience and application. Try to determine the correct scope, or restrictive context, for the reputations in your system. Resist the temptation to lump all reputation-generating interactions into one score—the score will be diluted to the point of meaninglessness. The following example from Yahoo! makes our point perfectly.
Context Is King
This story tells how Yahoo! Sports unsuccessfully tried to integrate social media into its top-tier website. Even seasoned product managers and designers can fall into the trap of making the scope of an application’s objects and interactions much broader than it should be.
Yahoo!’s Sports product managers believed that they should integrate user-generated content quickly across their entire site. They did an audit of their offering, and started to identify candidate objects, reputable entities, and some potential inputs.
The site had sports news articles, and the product team knew that it could tell a lot about what was in each article: the recognized team names, sport names, player names, cities, countries, and other important game-specific terms—in other words, the objects. It knew that users liked to respond to the articles by leaving text comments—the inputs.
It proposed an obvious intersection of the objects and the inputs: every comment on a news article would be a blog post, tagged with the keywords from the article, and optionally by user-generated tags, too. Whenever a tag appeared on another page, such as a different article mentioning the same city, the user’s comment on the original article could be displayed.
At the same time, those comments would be displayed on the team- and player-detail pages for each tag attached to the comment. The product managers even had aspirations to surface comments on the sports portal, not just for the specific sport, but for all sports.
Seems very social, clever, and efficient, right?
No. It’s a horrible design mistake. Consider the following detailed example from British football.
An article reports that a prominent player, Mike Brolly, who plays for the Chelsea team, has been injured and may not be able to play in an upcoming championship football match with Manchester United. Users comment on the article, and their comments are tagged with Manchester United, Chelsea, and Brolly.
Those comments would be surfaced—news feed–style—on the article page itself, the sports home page, the football home page, the team pages, and the player page. One post, six destination pages, each with a different context of use, different social norms, and different communities that they’ve attracted.
Nearly all these contexts are wrong, and the correct contexts aren’t even considered:
There is no all-of-Yahoo! Sports community context. At least, there’s not one with any great cohesion—American tennis fans, for example, don’t care about British football. When an American tennis fan is greeted on the Yahoo! Sports home page with comments about British football, they regard that about as highly as spam.
The team pages are the wrong context for the comments because the fans of different teams don’t mix. At a European football game, the fans for each team are kept on opposite sides of the field, divided by a chain link fence, with police wielding billy clubs alongside. The police are there to keep the fan communities apart.
Online, the cross-posting of the comments on the team pages encourages conflict between fans of the opposing teams. Fans of opposing teams have completely opposite reactions to the injury of a star player, and intermixing those conversations would yield anti-social (if sometimes hilarious) results.
The comments may or may not be relevant on the player page. It depends on whether the user actually responded to the article in the player-centric context—an input that this design didn’t account for.
Even the context of the article itself is poor, at least on Yahoo!. Its deal with the news feed companies, AP and Reuters, limits the amount of time an article may appear on the site to less than 10 days. Attaching comments (and reputation) to such transient objects tells users that their contributions don’t matter in the long run. (See The entity should persist for some length of time.)
Comments, like reputation statements, are created in a context. In the case of comments, the context is a specific target audience for the message. Here are some possible correct contexts for cross-posting comments:
Cross-post when the user has chosen a fan or team page and designated it to be a secondary destination for the comment. Your users will know, better than your system, what some legitimate related contexts are. (Though, of course, this can be abused; some decry the ascension of cross-posting to be a significant event in the devolution of the Usenet community.)
Cross-post back to the commenter’s user profile (with her permission, of course). Or allow her to post it to her personal blog, or send it to a friend—all of these approaches put an emphasis on the user as the context. If someone interests you enough for you to visit her user profile or blog, it’s likely that you might be interested in what she has to say over on Yahoo! Sports.
Cross-post automatically only into well-understood and obviously related contexts. For example, Yahoo! Sports has a completely different context that is still deeply relevant: a Fantasy Football league, where 12 to 16 people build their own virtual teams out of player-entities based on real-player stats.
In this context—where the performance and day-to-day circumstances of real-life players affect the outcome of users’ virtual teams—it might be very useful information to have cross-posted right onto a league’s page.
Caution
Don’t assume that because it’s safe and beneficial to cross-post in one direction, it’s automatically safe to do so in the opposite direction. What if Yahoo! auto-posted comments made in a Fantasy Sports league over to the more staid Sports community site? That would be a huge mistake.
The terms of service for Fantasy Football are so much more lax than the terms of service for public-facing posts. These players swear and taunt and harass each other. A post such as “Ha, Chris—you and the Bay City Bombers are gonna suck my team’s dust tomorrow while Brolly is home sobbing to his mommy!” clearly should not be automatically cross-posted to the main portal page.
Limit Scope: The Rule of Email
When thinking about your objects and user-generated inputs and how to combine them, remember the rule of email: you need a “subject” line and a “to” line (an addressee or a small number of addressees).
Tags for user-generated content act as subject identifiers, but not as addressees. Making your addressees as explicit as possible will encourage people to participate in many different ways.
Sharing content too widely discourages contributions and dilutes content quality and value.
Applying Scope to Yahoo! EuroSport Message Board Reputation
When Yahoo! EuroSport, based in the UK, wanted to revise its message board system to provide feedback on which discussions were the highest quality and incentives for users to contribute better content, it turned for help to reputation systems.
It was clear that the scope of reputation was different for each post and for all the posts in a thread and, as the American Yahoo! Sports team had initially assumed, that each user should have one posting karma: other users would flag the quality of a post and that would roll up to their all-sports-message-boards user reputation.
It did not take long for the product team to realize, however, that having Chelsea fans rate the posts of Manchester fans was folly: users would employ ratings to disagree with any comment by a fan of another team, not to honestly evaluate the quality of the posting.
The right answer, in this case, ended up being a tighter definition of scope for the context: rather than rewarding “all message boards” participation, or “everything within a particular sport,” instead an effort was made to identify the most granular, cohesive units of community possible on the boards, and reward participation only within those narrow scopes.
Yahoo! EuroSport implemented a system of karma medallions (bronze, silver, and gold) rewarding both the quantity and quality of a user’s participation on a per-board basis. This carried different repercussions for different sports on the boards.
Each UK football team has it’s own dedicated message board, so theoretically an active contributor could earn medallions in any number of football contexts: a gold for participating on the Chelsea boards, a bronze for Manchester, etc.
Tip
Bear in mind, however, that it’s the community response to a contributor’s posts that determines reputation accrual on the boards. We did not anticipate that many contributors would acquire reputation in many different team contexts; it’s a rare personality that can freely intermix, and makes friends, among both sides of a rivalry. No, this system was intended to reward and identify good fans and encourage them to keep among themselves.
Tennis and Formula 1 Racing are different stories. Those sports have only one message board each, so contributors to those communities would be rewarded for participating in a sport-wide context, rather than for their team loyalty. Again, this is natural and healthy: different sports, different fans, different contexts.
Many users have only a single medallion, participating mostly on a single board, but some are disciplined and friendly enough to have bronze badges or better in each of multiple boards, and each badge is displayed in a little trophy case when you mouse over the user’s avatar or examine the user’s profile (see Figure 6-14).
Generating Reputation: Selecting the Right Mechanisms
Now you’ve established your goals, listed your objects, categorized your inputs, and taken care to group the objects and inputs in appropriate contexts with appropriate scope. You’re ready to create the reputation mechanisms that will help you reach your goals for the system.
Though it might be tempting to jump straight to designing the display of reputation to your users, we’re going to delay that portion of the discussion until Chapter 7, where we dig into the reasons not to explicitly display some of your most valuable reputation information. Instead of focusing on presentation first, we’re going to take a goal-centered approach.
The Heart of the Machine: Reputation Does Not Stand Alone
Probably the most important thing to remember when you’re thinking about how to generate reputations is the context in which they will be used: your application. You might track bad-user behavior to save money in your customer care flow by prioritizing the worst cases of apparent abuse for quick review. You might also deemphasize cases involving users who are otherwise strong contributors to your bottom line. Likewise, if users evaluate your products and services with ratings and reviews, you will build significant machinery to gather users’ claims and transform your application’s output on the basis of their aggregated opinions.
For every reputation score you generate and display or use, expect at least 10 times as much development effort to adapt your product to accommodate it—including the user interface and coding to gather the events and transform them into reputation inputs, and all the locations that will be influenced by the aggregated results.
Common Reputation Generation Mechanisms and Patterns
Though all reputation is generated from custom-built models, we’ve identified certain common patterns in the course of designing reputation systems and observing systems that others have created. These few patterns are not at all comprehensive, and never could be. We provide them as a starting point for anyone whose application is similar to well-established patterns. We expand on each reputation generation pattern in the rest of this chapter.
This section focuses on calculating reputation, so the patterns don’t describe the methods used to display any user’s inputs back to the user. Typically, the decision to store users’ actions and display them is a function of the application design—for example, users don’t usually get access to a log of all of their clicks through a site, even if some of them are used in a reputation system. On the other hand, heavyweight operations, such as user-created reviews with multiple ratings and text fields, are normally at least readable by the creator, and often editable and/or deletable.
Generating personalization reputation
The desire to optimize their personal experience (see the section Fulfillment incentives) is often the initial driver for many users to go through the effort required to provide input to a reputation system. For example, if you tell an application what your favorite music is, it can customize your Internet radio station, making it worth the effort to teach the application your preferences. The effort required to do this also provides a wonderful side effect: it generates voluminous and accurate input into aggregated community ratings.
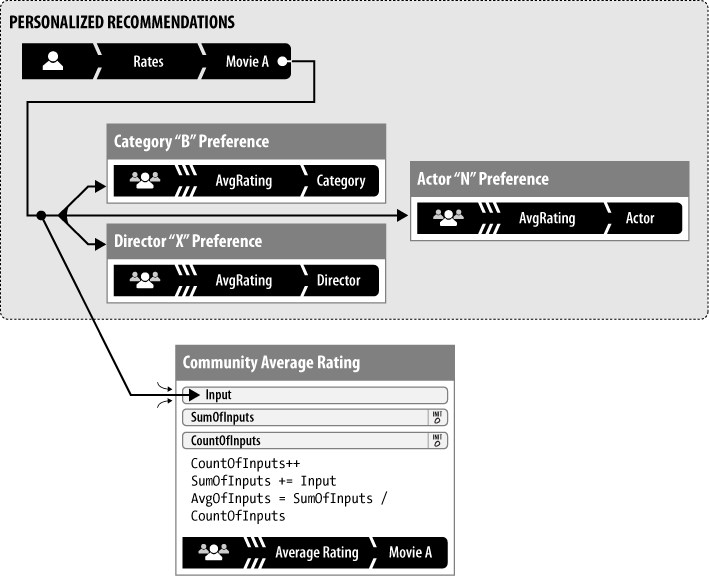
Personalization roll-ups are stored on a per-user basis and generally consist of preference information that is not shared publicly. Often these reputations are attached to very fine-grained contexts derived from metadata attached to the input targets and therefore can be surfaced, in aggregate, to the public (see Figure 6-15). For example, a song by the Foo Fighters may be listed in the “alternative” and “rock” music categories.
When a user marks the song as a favorite, the system would increase the personalization reputation for this user for three entities: “Foo Fighters,” “alternative,” and “rock.” Personalization reputation can require a lot of storage, so plan accordingly, but the benefits to the user experience, and your product offering, may make it well worth the investment. See Table 6-1.
Reputation models | Vote to promote, favorites, flagging, simple ratings, and so on. |
Inputs | Scalar. |
Processes | Counters, accumulators. |
Common uses | Site personalization and display. Input to predictive modeling. Personalized search ranking component. |
Pros | A single click is as low-effort as user-generated content gets. Computation is trivial and speedy. Intended for personalization, these inputs can also be used to generate aggregated community ratings to facilitate nonpersonalized discovery of content. |
Cons | It takes quite a few user inputs before personalization starts working properly, and until then the user experience can be unsatisfactory. (One method of bootstrapping is to create templates of typical user profiles and ask the user to select one to autopopulate a short list of targeted popular objects to rate quickly.) Data storage can be problematic. Potentially keeping a score for every target and category per user is very powerful but also very data intensive. |
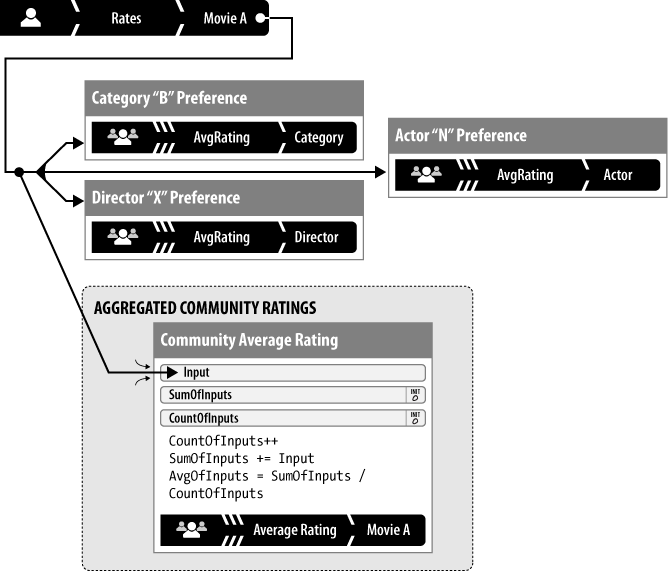
Generating aggregated community ratings
Generating aggregated community ratings is the process of collecting normalized numerical ratings from multiple sources and merging them into a single score, often an average or a percentage of the total, as in Figure 6-16. See Table 6-2.
Reputation models | Vote to promote, favorites, flagging, simple ratings, and so on. |
Inputs | Quantitative (normalized, scalar). |
Processes | Counters, averages, and ratios. |
Common uses | Aggregated rating display. Search ranking component. Quality ranking for moderation . |
Pros | A single click is as low-effort as user-generated content gets. Computation is trivial and speedy. |
Cons | Too many targets can cause low liquidity. Low liquidity limits accuracy and value of the aggregate score. See Liquidity: You Won’t Get Enough Input. Danger exists of using the wrong scalar model. See Bias, Freshness, and Decay. |
Ranking large target sets (preference orders)
One specific form of aggregate community ratings requires special mechanisms to get useful results: when an application needs to rank a large data set of objects completely and only a small number of evaluations can be expected from users. For example, a special mechanism would be required to rank the current year’s players in each sports league of an annual fantasy sports draft. Hundreds of players would be involved, and there would be no reasonable way that each individual user could evaluate each pair against the others. Even rating one pair per second would take many times longer than the available time before the draft. The same is true for community-judged contests in which thousands of users submit content. Letting users rate randomly selected objects on a percentage or star scale doesn’t help at all. (See Bias, Freshness, and Decay.)
This kind of ranking is called preference ordering. When this kind of ranking takes place online, users evaluate successively generated pairs of objects and choose the most appropriate one in each pair. Each participant goes through the process a small number of times, typically less than 10.
The secret sauce is in selecting the pairings. At first, the ranking engine looks for pairs that it knows nothing about, but over time it begins to select pairings that help users sort similarly ranked objects. It also generates pairs to determine whether the user’s evaluations are consistent or not. Consistency is good for the system, because it indicates reliability; if a users evaluations fluctuate wildly or don’t have a consistent pattern, this indicates a pattern of abuse or manipulation of the ranking.
The algorithms for this approach are beyond the scope of this book, but if you are interested, you can find out more in Appendix B. This mechanism is complex and requires expertise in statistics to build, so if a reputation model requires this functionality, we recommend using an existing platform as a model.
Generating participation points
Participation points are typically a kind of karma in which users accumulate varying amounts of publicly displayable points for taking various actions in an application. Many people see these points as a strong incentive to drive participation and the creation of content. But remember, using points as the only motivation for user actions can push out desirable contributions in favor of lower-quality content that users can submit quickly and easily (see First-mover effects). Also see Leaderboards Considered Harmful for a discussion of the challenges associated with competitive displays of participation points.
Participation points karma is a good example of a pattern in which the inputs (various, often trivial, user actions) don’t match the process of reputation generation (accumulating weighted point values) or the output (named levels or raw score); see Tables 6-3 and 6-4.
| Activity | Point award | Maximum/time |
First participation | +10 | +10 |
Log in | +1 | +1 per day |
Rate show | +1 | +15 per day |
Create avatar | +5 | +5 |
Add show or character to profile | +1 | +25 |
Add friend | +1 | +20 |
Be friended | +1 | +50 |
Give best answer | +3 | +3 per question |
Have a review voted helpful | +1 | +5 per review |
Upload a character image | +3 | +5 per show |
Upload a show image | +5 | +5 per show |
Add show description | +3 | +3 per show |
Reputation models | Points |
Inputs | Raw point value (this type of input is risky if disparate applications provide the input; out-of-range values can do significant social damage to your community). An action-type index value for a table lookup of points (this type of input is safer; the points table stays with the model, where it is easier to limit damage and track data trends). |
Processes | (Weighted) accumulator. |
Common uses | Motivation for users to create content. Ranking in leaderboards to engage the most active users. Rewards for specific desirable actions. Corporate use: identification of influencers or abusers for extended support or moderation. In combination with quality karma in creating robust karma (see Robust karma). |
Pros | Setup is easy. Incentive is easy for users to understand. Computation is trivial and speedy. Certain classes of users respond positively and voraciously to this type of incentive. See Egocentric incentives. |
Cons | Getting the points-per-action formulation right is an ongoing process, while users continually look for the sweet spot of minimum level of effort for maximum point gain. The correct formulation takes into account the effort required as well as the value of the behavior. See Egocentric incentives. Points are a discouragement to many users with altruistic motivations. See Altruistic or sharing incentives and Leaderboards Considered Harmful. |
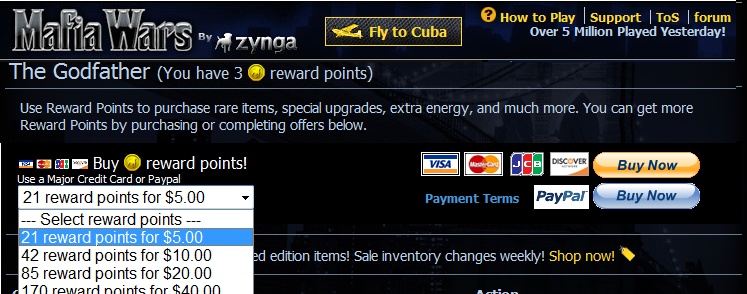
Points as currency
Point systems are increasingly being used as game currencies. Social games offered by developers such as Zynga generate participation points that users can spend on special benefits in the game, such as unique items or power-ups that improve the experience of the game. (See Figure 6-17.) Such systems have exploded with the introduction of the ability to purchase the points for real money.
If you consider any points-as-currency scheme, keep in mind that because the points reflect (and may even be exchangeable for) real money, such schemes place the motivations for using your application further from altruism and more in the range of a commercial driver.
Even if you don’t officially offer the points for sale and your application allows users to spend them only on virtual items in the game, a commercial market may still arise for them. A good historical example of this kind of aftermarket is the sale of game characters for popular online multiplayer games, such as World of Warcraft. Character levels in a game represent participation or experience points, which in turn represent real investments of time and/or money. For more than a decade, people have been power-leveling game characters and selling them on eBay for thousands of dollars.
We recommend against turning reputation points into a currency of any kind unless your application is a game and it is central to your business goals. More discussion of online economies and how they interact with reputation systems is beyond the scope of this book, but an ever-increasing amount of literature on the topic of real-money trading (RMT) is readily available on the Internet.
Generating compound community claims
Compound community claims reflect multiple separate, but related, aggregated claims about a single target and include patterns such as reviews and rated message board posts. But the power of attaching compound inputs of different types from multiple sources lets users understand multiple facets of an object’s reputation.
For example, ConsumerReports.org generates two sets of reputation for objects: the scores generated as a result of the tests and criteria set forth in the labs, and the average user ratings and comments provided by customers on the website. (See Figure 6-18.) These scores can be displayed side by side to allow the site’s users to evaluate a product both on numerous standard measures and on untested and unmeasured criteria. For example, user comments on front-loading clothes washers often mention odors, because former users of top-loading washers don’t necessarily know that a front-loading machine needs to be hand-dried after every load. This kind of subtle feedback can’t be captured in strictly quantitative measures.
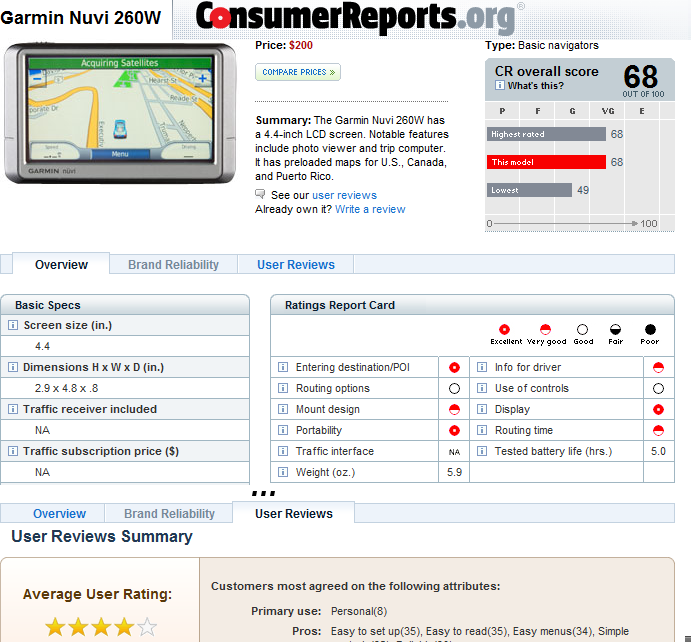
Though compound community claims can be built from diverse inputs from multiple sources, the ratings-and-reviews pattern is well established and deserves special comment here (see Table 6-5). Asking a user to create a multipart review is a very heavyweight activity—it takes time to compose a thoughtful contribution. Users’ time is scarce, and research at Yahoo! and elsewhere has shown that users often abandon the process if extra steps are required, such as logging in, registration for new users, or multiple screens of input.
Even if it’s necessary for business reasons, these barriers to entry will significantly increase the abandon rate for your review creation process. People need a good reason to take time out of their day to create a complex review. Be sure to understand your model (see the section Incentives for User Participation, Quality, and Moderation) and the effects it may have on the tone and quality of your content. For an example of the effects of incentive on compound community claims, see Friendship incentives.
Reputation models | Ratings-and-reviews, eBay merchant feedback, and so on. |
Inputs | All types from multiple sources and source types, as long as they all have the same target. |
Processes | All appropriate process types apply; every compound community claim is custom built. |
Common uses | User-created object reviews. Editor-based roll-ups, such as movie reviews by media critics. Side-by-side combinations of user, process, and editorial claims. |
Pros | This type of input is flexible; any number of claims can be kept together. This type of input provides easy global access; all the claims have the same target. If you know the target ID, you can get all reputations with a single call. Some standard formats for this type of input—for example, the ratings-and-reviews format—are well understood by users. |
Cons | If a user is explicitly asked to create too many inputs, incentive can become a serious impediment to getting a critical mass of contributions on the site. Straying too far from familiar formatting, either for input or output, can create confusion and user fatigue. There is some tension between format familiarity and choosing the correct input scale. See Good Inputs. |
Generating inferred karma
What happens when you want to make a value judgment about a user who’s new to your application? Is there an alternative to the general axiom that “no participation equals no trust”? In many scenarios, you need an inferred reputation score—a lower-confidence number that can be used to help make low-risk decisions about a user’s trustworthiness until she can establish an application-specific karma score. (See Figure 6-19.)
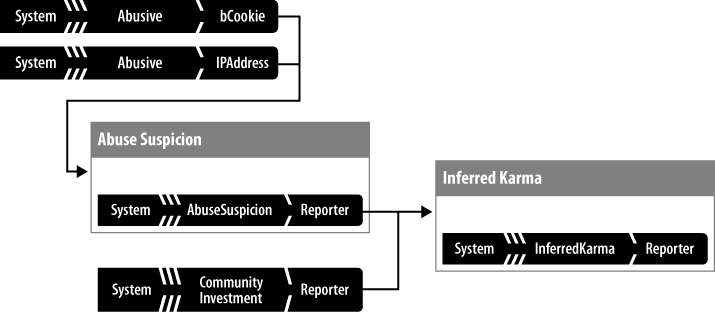
In a web application, proxy reputations may be available even for users who have never created an object, posted a comment, or clicked a single thumb-up. The user’s browser possesses session cookies that can hold simple activity counters even for logged-out users; the user is connected through an IP address that can have a reputation of its own (if it was recently or repeatedly used by a known abuser); and finally the user may have an active history with a related product that could be considered in a proxy reputation.
Remembering that the best karma is positive karma (see the next section Practitioner’s Tips: Negative Public Karma), when an otherwise unknown user evaluates an object in your system and you want to weight the user’s input, you can use the inferences from weak reputations to boost the user’s reputation from 0 to a reasonable fraction (for example, up to 25%) of the maximum value.
A weak karma score should be used only temporarily while a user is establishing robust karma, and, because it is a weak indicator, it should provide a diminishing share of the eventual, final score. (The share of karma provided by inferred karma should diminish as more trustworthy inputs become available to replace it.) One weighting method is to make the inferred share a bonus on top of the total score (the total can exceed 100%) and then clamp the value to 100% at the end. See Table 6-6.
Reputation models | Models are always custom; inferred karma is known to be part of the models in the following applications:
|
Inputs | Application external values; examples include the following:
|
Processes | Custom mixer |
Common uses | Partial karma substitute: separating the partially known from the complete strangers Help system display, giving unknown users extra navigation help Lockout of potentially abused features, such as content editing, until the user has demonstrated familiarity with the application and lack of hostility to it Deciding when to route new contributions to customer care for moderation |
Pros | Allows for a significantly lower barrier for some user contributions than otherwise possible, for example, not requiring registration or login. Provides for corporate (internal use) karma. No user knows this score, and the site operator can change the application’s calculation method freely as the situation evolves and new proxy reputations become available. Helps render your application impervious to accidental damage caused by drive-by users. |
Cons | Inferred karma is, by construction, unreliable. For example, since people can share an IP address over time without knowing it or each other, including it in a reputation can undervalue an otherwise excellent user by accident. However, though it might be tempting for that reason to remove IP reputation from the model, IP address is the strongest indicator of bad users; such users don’t usually go to the trouble of getting a new IP address whenever they want to attack your site. Inferred karma can be expensive to generate. How often do you want to update the supporting reputations, such as IP or cookie reputation? It would be too expensive to update them at very single HTTP roundtrip, so smart design is required. Inferred karma is weak. Don’t trust it alone for any legally or socially significant actions. |
Practitioner’s Tips: Negative Public Karma
Because an underlying karma score is a number, product managers often misunderstand the interaction between numerical values and online identity. The thinking goes something like this:
In our application context, the user’s value will be represented by a single karma, which is a numerical value.
There are good, trustworthy users and bad, untrustworthy users, and everyone would like to know which is which, so we will display their karma.
We should represent good actions as positive numbers and bad actions as negative, and we’ll add them up to make karma.
Good users will have high positive scores (and other users will interact with them), and bad users will have low negative scores (and other users will avoid them).
This thinking—though seemingly intuitive—is impoverished, and is wrong in at least two important ways:
There can be no negative public karma—at least for establishing the trustworthiness of active users. A bad enough public score will simply lead to that user’s abandoning the account and starting a new one, a process we call karma bankruptcy. This setup defeats the primary goal of karma—to publicly identify bad actors. Assuming that a karma starts at zero for a brand-new user that an application has no information about, it can never go below zero, since karma bankruptcy resets it. Just look at the record of eBay sellers with more than three red stars. You’ll see that most haven’t sold anything in months or years, either because the sellers quit or they’re now doing business under different account names.
It’s not a good idea to combine positive and negative inputs in a single public karma score. Say you encounter a user with 75 karma points and another with 69 karma points. Who is more trustworthy? You can’t tell; maybe the first user used to have hundreds of good points but recently accumulated a lot of negative ones, while the second user has never received a negative point at all. If you must have public negative reputation, handle it as a separate score (as in the eBay seller feedback pattern).
Even eBay, with the most well-known example of public negative karma, doesn’t represent how untrustworthy an actual seller might be; it only gives buyers reasons to take specific actions to protect themselves. In general, avoid negative public karma. If you really want to know who the bad guys are, keep the score separate and restrict it to internal use by moderation staff.
Draw Your Diagram
With your goals, objects, inputs, and reputation patterns in hand, you can draw a draft reputation model diagram and sketch out the flows in enough detail to generate the following questions: what data will I need to formulate these reputation scores correctly?; how will I collect the claims and transform them into inputs?; which of those inputs will need to be reversible, and which will be disposable?
If you’re using this book as a guide, try sketching out a model now, before you consider creating screen mock-ups. One approach we’ve often found helpful is to start on the right side of the diagram—with the reputations you want to generate—and work your way back to the inputs. Don’t worry about the calculations at first; just draw a process box with the name of the reputation inside and a short note on the general nature of the formulation, such as aggregated acting average or community player rank.
Once you’ve drawn the boxes, connect them with arrows where appropriate. Then consider what inputs go into which boxes, and don’t forget that the arrows can split and merge as needed.
Then, after you have a good rough diagram, start to dive into the details with your development team. Many mathematical and performance-related details will affect your reputation model design. We’ve found that reputation systems diagrams make excellent requirements documentation and make it easier to generate the technical specification, while also making the overall design accessible to nonengineers.
Of course, your application will consist of displaying or using the reputations you’ve diagrammed (Chapters 7 and 8). Project engineers, architects, and operational team members may want to review Chapter 9 first, as it completes the schedule focused, development-cycle view of any reputation project.