
Chapter 10. Case Study: Yahoo! Answers Community Content Moderation
This chapter is a real-life case study applying many of the theories and practical advice presented in this book. The lessons learned on this project had a significant impact on our thinking about reputation systems, the power of social media moderation, and the need to publish these results in order to share our findings with the greater web application development community.
In the summer of 2007, Yahoo! tried to address some moderation challenges with one of its flagship community products: Yahoo! Answers. The service had fallen victim to its own success and drawn the attention of trolls and spammers in a big way. The Yahoo! Answers team was struggling to keep up with harmful, abusive content that flooded the service, most of which originated with a small number of bad actors on the site.
Ultimately, a clever (but simple) system that was rich in reputation provided the answer to these woes: it was designed to identify bad actors, indemnify honest contributors, and take the overwhelming load off of the customer care team. Here’s how that system came about.
What Is Yahoo! Answers?
Yahoo! Answers debuted in December of 2005 and almost immediately enjoyed massive popularity as a community driven website and a source of shared knowledge.
Yahoo! Answers provides a very simple interface to do, chiefly, two things: pose questions to a large community (potentially, any active, registered Yahoo! user—that’s roughly a half-billion people worldwide); or answer questions that others have asked. Yahoo! Answers was modeled, in part, from similar question-and-answer sites like Korea’s Naver.com Knowledge Search.
The appeal of this format was undeniable. By June of 2006, according to Business 2.0, Yahoo! Answers had already become “the second most popular Internet reference site after Wikipedia and had more than 90% of the domestic question-and-answer market share, as measured by comScore.” Its popularity continues and, owing partly to excellent search engine optimization (SEO), Yahoo! Answers pages frequently appear very near the top of search results pages on Google and Yahoo! for a wide variety of topics.
Yahoo! Answers is by far the most active community site on the Yahoo! network. It logs more than 1.2 million user contributions (questions and answers combined) each day.
A Marketplace for Questions and Yahoo! Answers
Yahoo! Answers is a unique kind of marketplace—one not based on the transfer of goods for monetary reward. No, Yahoo! Answers is a knowledge marketplace, where the currency of exchange is ideas. Furthermore, Yahoo! Answers focuses on a specific kind of knowledge.
Micah Alpern was the user experience lead for early releases of Yahoo! Answers. He refers to the unique focus of Yahoo! Answers as “experiential knowledge”—the exchange of opinions and sharing of common experiences and advice (see Figure 10-1). While verifiable, factual information is indeed exchanged on Yahoo! Answers, a lot of the conversations that take place there are intended to be social in nature.
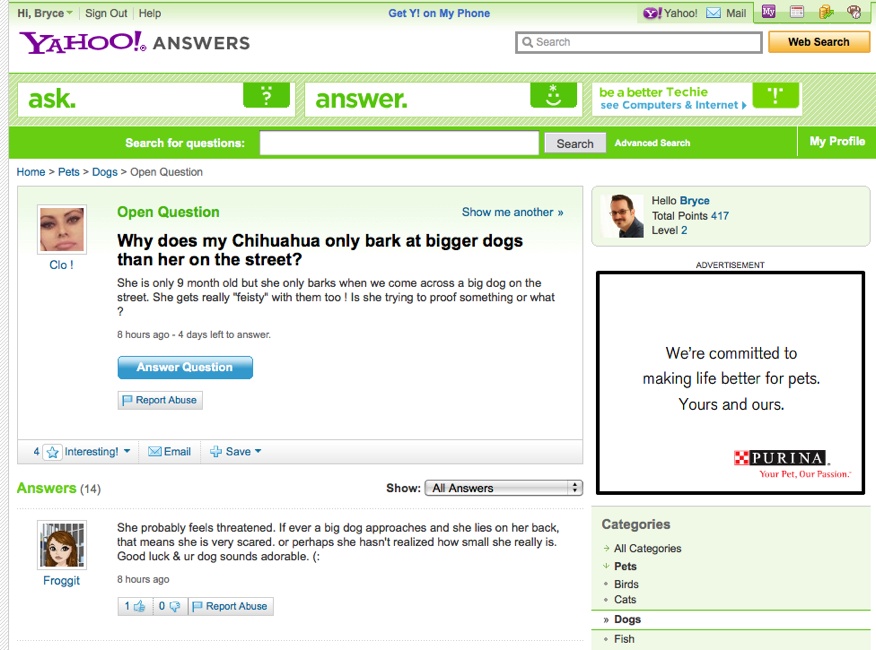
Tip
Micah has published a detailed presentation that covers this project in some depth. You can find it at http://www.slideshare.net/malpern/wikimania-2009-yahoo-answers-community-moderation.
Yahoo! Answers is not a reference site in the sense that Wikipedia is; it is not based on the ambition to provide objective, verifiable information. Rather, its goal is to encourage participation from a wide variety of contributors. That goal is important to keep in mind as we delve further into the problems that Yahoo! Answers was undergoing and the steps needed to solve them. Specifically, keep the following in mind:
The answers on Yahoo! Answers are subjective. It is the community that determines what responses are ultimately “right.” It should not be a goal of any metamoderation system to distinguish right answers from wrong or otherwise place any importance on the objective truth of answers.
In a marketplace for opinions such as Yahoo! Answers, it’s in the best interest of everyone (askers, answerers, and the site operator) to encourage more opinions, not fewer. So the designer of a moderation system intended to weed out abusive content should make every attempt to avoid punishing legitimate questions and answers. False positives can’t be tolerated, and the system must include an appeals process.
Attack of the Trolls
So, exactly what problems was Yahoo! Answers suffering from? Two factors—the time lines with which Yahoo! Answers displayed new content and the overwhelming number of contributions it received—had combined to create an unfortunate environment that was almost irresistible to trolls. Dealing with offensive and antagonistic user content had become the number one feature request from the Yahoo! Answers community.
The Yahoo! Answers team first attempted a machine-learning approach, developing a black-box abuse classifier (lovingly named the “Junk Detector”) to prefilter abuse reports coming in. It was intended to classify the worst of the worst content and put it into a prioritized queue for the attention of customer care agents.
The Junk Detector was mostly a bust. It was moderately successful at detecting obvious spam, but it failed altogether to identify the subtler, more insidious contributions of trolls.
Engineering manager Ori Zaltzman recalls the exact moment he knew for certain that something had to be done about trolls: when he logged onto Yahoo! Answers to see the following question highlighted on the home page: “What is the best sauce to eat with my fried dead baby?” (And, yes, we apologize for the citation—but it certainly illustrates the distasteful effects of letting trolls go unchallenged in your community.)
That question got through the Junk Detector easily. Even though it’s an obviously unwelcome contribution, on the surface, to a machine, it looked like a perfectly legitimate question: grammatically well formed, no SHOUTING, i.e., ALL CAPS. So abusive content could sit on the site with impunity for hours before the staff could respond to abuse reports.
Time was a factor
Because the currency of Yahoo! Answers is the free exchange of opinions, a critical component of “free” in this context is timely. Yahoo! Answers functions best as a near-real-time communication system, and—as a design principle—erred on the side of timely delivery of users’ questions and answers. User contributions are not subject to any type of editorial approval before being pushed to the site.
Tip
Early on, the Yahoo! Answers product plan did call for editor approval of all questions before publishing. This was an early attempt to influence the content quality level by modeling good user behavior. The almost immediate, skyrocketing popularity of the site quickly rendered that part of the plan moot. There simply was no way that any team of Yahoo! content moderators was going to keep up with the levels of use on Yahoo! Answers.
Location, location, location
One particular area of the site became a highly sought-after target for abusers: the high-profile front page of Yahoo! Answers. (See Figure 10-2.)
Any newly asked question could potentially appear in highly trafficked areas, including the following:
The index of open (answerable) questions (http://answers.yahoo.com/dir/index)
The index of the category in which a question was listed
Communities such as Yahoo! Groups, Sports, or Music, where Yahoo! Answers content was syndicated
Built with Reputation
Yahoo! Answers, somewhat famously, already featured a reputation system—a very visible one, designed to encourage and reward ever-greater levels of user participation. On Yahoo! Answers, user activity is rewarded with a detailed point system. (See Points and Accumulators.)
Tip
We say “famously” because the Yahoo! Answers point system is somewhat notorious in reputation system circles, and debate continues to rage over its effectiveness.
At the heart of the debate is this question: does the existence of these points—and the incentive of rewarding people for participation—actually improve the experience of using Yahoo! Answers? Does it make the site a better source of information? Or are the system’s game-like elements promoted too heavily, turning what could be a valuable, informative site into a game for the easily distracted?
We’re mostly steering clear of that discussion here. (We touched on aspects of it in Chapter 7.) This case study deals only with combating obviously abusive content, not with judging good content from bad.
Yahoo! Answers decided to solve the problem through community moderation based on a reputation system that would be completely separate from the existing public participation point system. However, it would have been foolish to ignore the point system; it was a potentially rich source of inputs into any additional system. The new system clearly would have to be influenced by the existence of the point system, but it would have to use the point system input in very specific ways, while the point system continued to function.
Avengers Assemble!
The crew fielded to tackle this problem was a combination of two teams.
The Yahoo! Answers product team had ultimate responsibility for the application. It was made up of domain experts on questions and answers, from the rationale behind the service, to the smallest details of user experience, to building the high-volume scalable systems that supported it. These were the folks who best understood the service, and they were held accountable for preserving the integrity of the user experience. Ori Zaltzman was the engineering manager, Quy Le was product manager, Anirudh Koul was the engineer leading the troll hunt and optimizing the model, and Micah Alpern was the lead user experience designer.
The members of the product team were the primary customers for the technology and advice of another team at Yahoo!, the reputation platform team. The reputation platform was a tier of technology (detailed in Appendix A) that was the basis for many of the concepts and models we have discussed in this book (this book is largely documentation of that experience). Yvonne French was the product manager for the reputation platform, and Randy Farmer, coauthor of this book, was the platform’s primary designer and advised on reputation model and system deployment. A small engineering team built the platform and implemented the reputation models.
Tip
Yahoo! enjoyed an advantage in this situation that many organizations may not: considerable resources and, perhaps more important, specialized resources. For example, it is unlikely that your organization will feature an engineering team specifically dedicated to architecting a reputation platform. However, you might consider drafting one or more members of your team to develop deep knowledge in that area.
Here’s how these combined teams tackled the problem of taming abuse on Yahoo! Answers.
Initial Project Planning
As you’ll recall from Chapter 5, we recommend starting any reputation system project by asking these fundamental questions:
What are your goals for your application?
What is your content control pattern?
Given your goals and the content models, what types of incentives are likely to work well for you?
Setting Goals
As is often the case on community-driven websites, what is good for the community—good content and the freedom to have meaningful, interruption-free exchanges—also just happens to make for good business value for the site owners. This project was no different, but it’s worth discussing the project’s specific goals.
Cutting costs
The first motivation for cleaning up abuse on Yahoo! Answers was cost. The existing system for dealing with abuse was expensive, relying as it did on heavy human-operator intervention. Each and every report of abuse had to be verified by a human operator before action could be taken on it.
Randy Farmer, at the time the community strategy analyst for Yahoo!, pointed out the financial foolhardiness of continuing down the path where the system was leading: “the cost of generating abuse is zero, while we’re spending a million dollars a year on customer care to combat it—and it isn’t even working.” Any new system would have to fight abuse at a cost that was orders of magnitude lower than that of the manual-intervention approach.
Cleaning up the neighborhood
The monetary cost of dealing with abuse on Yahoo! Answers was considerable, but the community cost of not dealing with it would have been far higher. Bad behavior begets bad behavior, and leaving obviously abusive content in high-profile locations on the site would over time absolutely erode the perceived value of social interactions on Yahoo! Answers. (For more, see the sidebar Broken Windows and Online Behavior.)
Of course, Yahoo! hoped that the inverse would also prove true: if Yahoo! Answers addressed the problem forcefully and with great vigor, the community would notice the effort and respond in kind. (See the sidebar Beware Excessive Tuning: The Hawthorne Effect.)
The goals for content quality were twofold:
Reduce the overall amount of abusive content on the site.
Reduce the amount of time it took for content reported as abusive to be pulled down.
Who Controls the Content?
In Chapter 5, we proposed a number of content control patterns as useful models for thinking about the ways in which your content is created, disseminated, and moderated. Let’s revisit those patterns briefly for this project.
Before the community content moderation project, Yahoo! Answers fit nicely in the basic social media pattern. (See Basic social media: Users create and evaluate, staff removes.) While users were given responsibility of creating and editing (voting for or reporting as abusive) questions and answers, final determination for removing content was left up to the staff.
The team’s goal was to move Yahoo! Answers closer to The Full Monty (see The Full Monty: Users create, evaluate, and remove) and put the responsibility of removing or hiding content right into the hands of the community. That responsibility would be mediated by the reputation system, but staff intervention in content quality issues would be necessary only in cases where content contributors appealed the systems’ decisions.
Incentives
We discussed some ways to think about the incentives that could drive community participation on your site in the section Incentives for User Participation, Quality, and Moderation. For Yahoo! Answers, the team decided to devise incentives that took into account a couple of primary motivations:
Some community members would report abuse for altruistic reasons: out of a desire to keep the community clean. (See the section Altruistic or sharing incentives.) Downplaying the contributions of such users would be critical; the more public their deeds became, the less likely they would continue acting out of sheer altruism.
Some community members had egocentric motivations for reporting abuse. The team appealed to those motivations by giving those users an increasingly greater voice in the community.
The High-Level Project Model
The team devised this plan for the new model: a reputation model would sit between the two existing systems—a report mechanism that permitted any user on Yahoo! Answers to flag any other user’s contribution and the (human) customer care system that acted on those reports. (See Figure 10-3.)
This approach was based on two insights:
Customer care could be removed from the loop—in most cases—by shifting the content removal process into the application and giving it to the users, who were already the source of the abuse reports, and then optimizing it to cut the amount of time and offensive posting by 90%.
Customer care could then handle just the exceptions—undoing the removal of content mistakenly identified as abusive. At the time, such false positives made up 10% of all content removal. Even if the exception rate stayed the same, customer care costs would decrease by 90%.
The team would accomplish item 1, removing customer care from the loop, by implementing a new way to remove content from the site—“hiding.” Hiding involved trusting the community members themselves to vote to hide the abusive content. The reputation platform would manage the details of the voting mechanism and any related karma. Because this design required no external authority to remove abusive content from view, it was probably the fastest way to cut display time for abusive content.
As for item 2, dealing with exceptions, the team devised an ingenious mechanism—an appeals process. In the new system, when the community voted to hide a user’s content, the system sent the author an email explaining why, with an invitation to appeal the decision. Customer care would get involved only if the user appealed. The team predicted that this process would limit abuse of the ability to hide content; it would provide an opportunity to inform users about how to use the feature; and, because trolls often don’t give valid email addresses when registering an account, they would simply be unable to appeal because they’d never receive the notices.
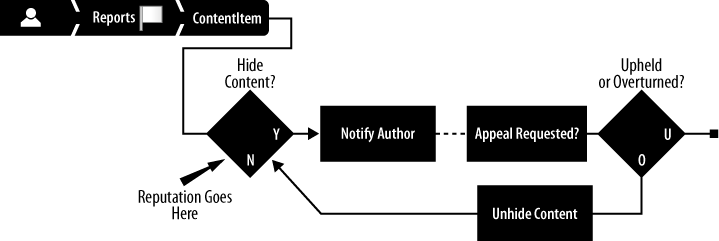
Most of the rest of this chapter details the reputation model designated by the Hide Content? diamond in Figure 10-3. See the patent application for more details about the other (nonreputation) portions of the diagram, such as the Notify Author and Appeals process boxes.
Warning
Yahoo! has applied for a patent on this reputation model, and that application has been published: Trust Based Moderation—Inventors: Ori Zaltzman and Quy Dinh Le. Please consider the patent if you are even thinking about copying this design.
We are grateful to both the Yahoo! Answers and the reputation product teams for sharing their design insights and their continued assistance in preparing this case study.
Objects, Inputs, Scope, and Mechanism
Yahoo! Answers was already a well-established service at the time that the community content moderation model was being designed, with all of the objects and most of the available inputs already well defined. The final model includes dozens of inputs to more than a dozen processes. Out of respect for intellectual property and the need for brevity, we have not detailed every object and input here. But, thanks to the Yahoo! Answers team’s willingness to share, we’re able to provide an accurate overall picture of the reputation system and its application.
The Objects
Here are the objects of interest for designing a community-powered content moderation system:
- User contributions
User contributions are the objects that users make by either adding or evaluating content:
- Questions
Arriving at a rate of almost 100 per minute, questions are the starting point of all Yahoo! Answers activity. New questions are displayed on the home page and on category pages.
- Answers
Answers arrive 6 to 10 times faster than questions and make up the bulk of the reputable entities in the application. All answers are associated with a single question and are displayed in chronological order, oldest first.
- Ratings
After a user makes several contributions, the application encourages the user to rate answers with a simple thumb-up or thumb-down vote. The author of the question is also allowed to select the best answer and give it a rating on a 5-star scale. If the question author does not select a best answer in the allotted time, the community vote is used to determine the best answer.
Users may also mark a question with a star, indicating that the question is a favorite.
Each of these rating schemes already existed at the time the community content moderation system was designed, so for each scheme, the inputs and outputs were both available for the designers’ consideration.
- Users
All users in this application have two data records that can hold and supply information for reputation calculations: an all-Yahoo! global user record, which includes fields for items such as registration data and connection information, and a record for Yahoo! Answers, which stores only application-specific fields.
Developing this model required considering at least two different classifications of users:
- Authors
Authors create the items (questions and answers) that the community can moderate.
- Reporters
Reporters determine that an item (a question or an answer) breaks the rules and should be removed.
- Customer care staff
The customer care staff is the target of the model. The goal is to reduce the staff’s participation in the content moderation process as much as possible but not to zero. Any community content moderation process can be abused: trusted users may decide to abuse their power, or they may simply make a mistake. Customer care would still evaluate appeals in those cases, but the number of such cases would be far less than the total number of abuses.
Customer care agents also have a reputation—for accuracy—though it isn’t calculated by this model. At the start of the Yahoo! Answers community content moderation project, the accuracy of a customer care agent’s evaluation of questions was about 90%. That rate meant that 1 in 10 submissions was either incorrectly deleted or incorrectly allowed to remain on the site. An important measure of the model’s effectiveness was whether users’ evaluations were more accurate than the staff’s.
The design included two noteworthy documents, though they were not formal objects (that is, they neither provided input nor were reputable entities). The Yahoo! Terms of Service and the Yahoo! Answers Community Guidelines (Figure 10-4) are the written standards for questions and answers. Users are supposed to apply these rules in evaluating content.
Limiting Scope
When a reputation model is introduced, users often are confused at first about what the reputation score means. The design of the community content moderation model for Yahoo! Answers is only intended to identify abusive content, not abusive users. Remember that many reasons exist for removing content, and some content items are removed as a result of behaviors that authors are willing to change, if gently instructed to do so.
The inclusion of an appeals process in the application not only provides a way to catch false-positive classification by reporters, it also gives Yahoo! a chance to inform authors of the requirements for participating in Yahoo! Answers, allowing users to learn more about expected behavior.
An Evolving Model
Ideally, in designing a reputation system, you’d start with as comprehensive a list of potential inputs as possible. In practice, when the Yahoo! Answers team was designing the community content moderation model, they used a more incremental approach. As the model evolved, the designers added more subtle objects and inputs. Next, to illustrate an actual model development process, we’ll roughly follow the historical path of the Yahoo! Answers design.
Iteration 1: Abuse reporting
When you develop a reputation model, it’s good practice to start simple; focus only on the main objects, inputs, decisions, and uses. Assume a universe in which the model works exactly as intended. Don’t focus too much on performance or abuse at first; you’ll get to those issues in later iterations. Trying to solve this kind of complex equation in all dimensions simultaneously will just lead to confusion and impede your progress.
For the Yahoo! Answers community content moderation system, the designers started with a very basic model: abuse reports would accumulate against a content item, and when some threshold was reached, the item would be hidden. This model, sometimes called “X-strikes-and-you’re-out,” is quite common in social web applications. Craigslist is a well-known example.
Despite the apparent complexity of the final application, the model’s simple core design remained unchanged: accumulated abuse reports automatically hide content. Having that core design to keep in mind as the key goal helped eliminate complications in the design.
Inputs
From the beginning, the team planned for the primary input to the model to be a user-generated abuse report explicitly about a content item (a question or an answer). This user interface device was the same one already in place for alerting customer care to abuse. Though many other inputs were possible, initially the team considered a model with abuse reports as the only input.
- Abuse reports (user input)
Users could report content that violated the community guidelines or the terms of service. The user interface consisted of a button next to all questions and answers. The button was labeled with a flag icon, and sometimes the action of clicking the button was referred to as “flagging an item.” In the case of questions, the button label also included the phrase “Report Abuse.” The interface then led the user through a short series of pages to explain the process and narrow down the reason for the report.
The abuse report was the only input in the first iteration of the model.
Mechanism and diagram
At the core of the model was a simple, binary decision: should a content item that has just been reported as abusive be hidden? How does the model make the decision, and, if the result is positive, how should the application be notified?
In the first iteration, the model for this decision was
“three strikes and you’re out.” (See Figure 10-5.) Abuse reports fed into a simple
accumulator (see Simple Accumulator). Each
report about a content item was given equal weight; all reports were
added together and stored as AbusiveScore. That score
was sent on to a simple evaluator, which tested it against a
threshold (3) and either terminated it (if the threshold had not
been reached) or alerted the application to hide the item.
Given that performance was a key requirement for this model, the abuse reports were delivered asynchronously, and the outgoing alert to the application used an application-level messaging system.
This iteration of the model did not include karma.
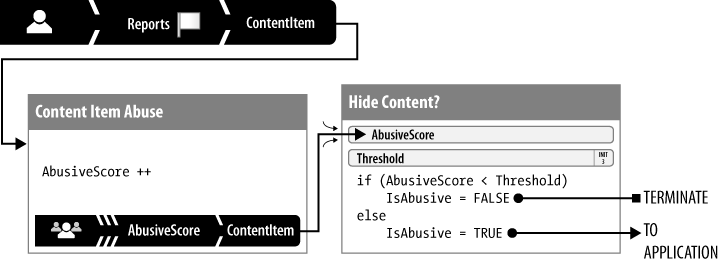
Analysis
This very simple model didn’t really meet the minimum requirement for the application—the fastest possible removal of abusive content. Three strikes is often too many, but one or two is sometimes too few, giving too much power to bad actors.
The model’s main weakness was to give every abuse report equal weight. By giving trusted users more power to hide content and giving unknown users or bad actors less power, the model could improve the speed and accuracy with which abusive content was removed.
The next iteration of the model introduced karma for reporters of abuse.
Iteration 2: Karma for abuse reporters
Ideally, the more abuse a user reports accurately, the greater the trust the system should place in that user’s reports. In the second iteration of the model, shown in Figure 10-6, when a trusted reporter flagged an item, it was hidden immediately. Trusted reporters had proven, over time, that their motivations were pure, their comprehension of community standards was good, and their word could be taken at face value.
Reports by users who had never previously reported an item, with unknown reputation, were all given equal weight, but it was significantly lower than reports by users with a positive history. In this model, individual unknown reporters had less influence on any one content item, but the votes of different individuals could accrue quickly. (At the same time, the individuals accrued their own reporting histories, so unknown reporters didn’t stay unknown for long.)
Though you might think that “bad” reporters (those whose reports were later overturned on appeal) should have less say than unknown users, the model gave equal weight to reports from bad reporters and unknown reporters. (See Practitioner’s Tips: Negative Public Karma.)
Inputs
To the inputs from the previous iteration, the designers added three events related to flagging questions and answers accurately:
- Item hidden (moderation model feedback)
The system sent this input message when the reputation process determined that a question or answer should be hidden, which represented that all users who reported the content item agreed that the item was in violation of either the TOS or the community guidelines.
- Appeal Result: Upheld (customer care input)
After the system hid an item, it contacted the content author via email and enabled the author to start an appeal process, requesting customer care staff to review the decision. If a customer care agent determined that the content was appropriately hidden, the system sent the event
Appeal Result: Upheldto the reputation model.- Appeal Result: Overturned (customer care input)
If a customer care agent determined that the content was inappropriately hidden, the system displayed the content again and sent the event
Appeal Result: Overturnedto the reputation model for corrective adjustments.
Mechanism and diagram
The designers transformed the overly simple “strikes”-based model to account for a user’s abuse report history.
The goals were to decrease the time required to hide abusive content, and reduce the risk of inexperienced or bad actors hiding content inappropriately.
The solution was to add AbuseReporter karma to
record the user’s accuracy in hiding abusive content. Use
AbuseReporter to give greater weight to reports by
users with a history of accurate abuse reporting.
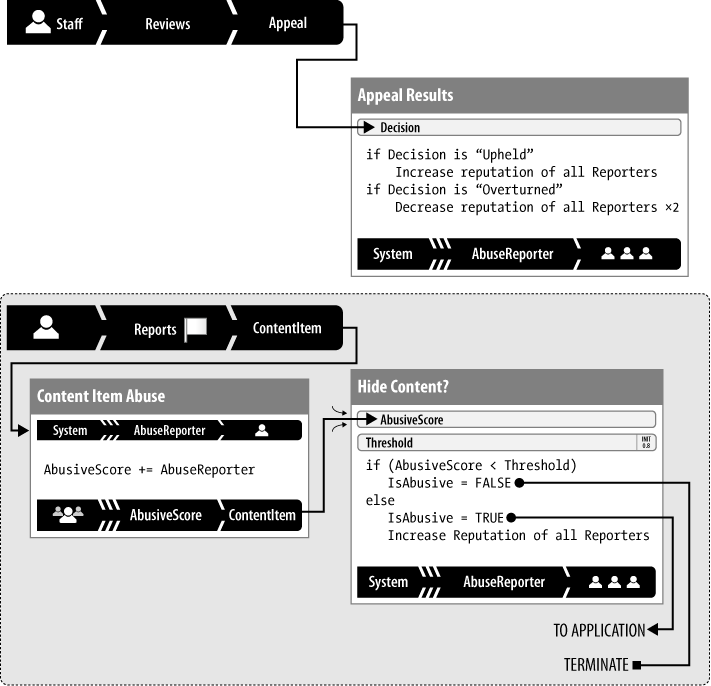
To accommodate the varying weight of abuse reports, the
designers changed the calculation of AbusiveScore from
strikes to a normalized value, where 0.0 represented no abuse
information known and 1.0 represented the maximum abuse value. The
evaluator now compared the AbusiveScore to a normalized
value representing the certainty required before hiding an
item.
The designers added an AbuseReporter reputation
claim, a normalized value, where 0.0 represented a user with no
history of abuse reporting and 1.0 represented a user with a
completely accurate abuse reporting history. A user with a perfect
score of 1.0 could hide any item immediately.
The inputs that increased AbuseReporter were
Item Hidden and Appeal Result: Upheld. The
input Abuse Result: Overturned had a disproportionately
large negative effect on AbuseReporter, providing an
incentive for reporters not to use their power
indiscriminately.
Unlike the first process, the new version of the Content Item
Abuse process did not treat each input the same way. It read the
reporter’s AbuseReporter karma, added a small constant
to AbusiveScore (so that users with no karma made at
least a small contribution to the result), and capped the result at
the maximum. If the result was 1.0, the system hid the item but, in
addition to alerting the application, it updated the
AbuseReporter karma for each user that flagged the
item. This reflected community consensus and, since the vast
majority of hidden items would never be reviewed by customer care,
was often the only opportunity the system had to reinforce the karma
of those users. Very few appeals were anticipated given that trolls
were known to give bogus email addresses when registering. The
incentives for both the legitimate authors and good abuse reporters
discourage abusing the community moderation model.
The system sent appeal results messages asynchronously as part
of the customer care application; the messages could come in at
anytime. After AbuseReporter was adjusted, the system
did not attempt to update other AbusiveScores the
reporter may have contributed to.
Analysis
The second iteration of the model did exactly what it was supposed to do: it allowed trusted reporters to hide abusive content immediately. However, it ignored the value of contributions by authors who might themselves be established, trusted members of the community. As a result, a single mistaken abuse report against a top contributor led to a higher appeal rate, which not only increased costs but generated bad feelings about the site. Furthermore, even before the first iteration of the model had been implemented, trolls already had been using the abuse reporting mechanism to harass top contributors. So in the second iteration, treating all authors equally allowed malicious users (trolls or even just rivals of top contributors) to take down the content of top contributors with just a few puppet accounts.
The designers found that the model needed to account for the
understanding that in cases of alleged abuse, some authors always
deserve a second opinion. In addition, the designers knew that to
hide content posted by casual regular users, the
AbusiveScore required by the model should be lower—and
for content by unknown authors, lower still.
In other words, the model needed karma for author contributions.
Iteration 3: Karma for authors
The third iteration of the model introduced
QuestionAuthor karma and AnswerAuthor karma,
which reflected the quality and quantity of author contributions. The
system compared AbusiveScore to those two reputations
instead of a constant. This change raised the threshold for hiding
content for active, trusted authors and lowered the threshold for
unknown authors and authors known to have contributed abusive content.
Inputs
The new inputs to the model fell into two groups: inputs that indicated the quantity and community reputation of the questions and answers contributed by an author and evidence of any previous abusive contributions.
- Inputs contributing to positive reputation for a question
Numerous events could indicate that a question was valuable to the community. When a reader took any of the following actions on a question, the author’s
QuestionQualityreputation score increased:Added the question to his watch list
Shared the question with a friend
Gave the question a star (marked it as a favorite)
- Inputs contributing to negative reputation for a question
When customer care staff deleted a question, the system set the author’s
QuestionQualityreputation score to 0.0 and adjusted the author’s karma appropriately.Another negative input was the Junk Detector score, which acted as an initial guess about the level of abusive content in the question. Note that a high Junk Detector score would have prevented the question from ever being displayed at all.
- Inputs related to content creation
When an author posted a question, the system increased the total number of questions submitted by that author by 1 (
QuestionsAskedCount). This configuration allowed new contributors to start with a reputation score based on the average quality of all previous contributions to the site, by all authors (AuthorAverageQuestionQuality).When other users answered the question, the question itself inherited the
AverageAnswererQualityreputation score for all users who answered it. (If a lot of good people answer your question, it must be a good question.)- Inputs contributing to positive reputation for an answer
As with a question, several events could indicate that an answer was valuable to the community. When a reader took any of the following actions on an answer, the author’s
AnswerQualityreputation score increased:The author of the original question selected the answer as Best Answer
The community voted the answer Best Answer
The average community rating given for the answer
- Inputs contributing to negative reputation for an answer
If the number of negative ratings of an answer rose significantly higher than the number of positive ratings, the system hid the answer from display, except to users who asked to see all items regardless of rating. The system lowered the
AnswerQualityreputation score of answers that fell below this display threshold. This choked off further negative ratings simply because the item was no longer displayed to most users.When customer care staff deleted an answer, the system reset the
AnswerQualityreputation to 0.0 and adjusted the author’s karma appropriately.Another negative input was the Junk Detector rating, which acted as a rough guess at the level of abusive content in the answer. Note that if the Junk Detector rating was high, the system would already have hidden the answer before even sending it through the reputation process.
- New-answer input
When a user posted an answer, the system increased the total number of answers submitted by that user by 1 (
QuestionsAnsweredCount). In that configuration, each time an author posted a new answer, the system assigned a starting reputation based on the average quality of all answers previously submitted by that author (AuthorAverageAnswerQuality).- Previous abusive history
As part of the revisions accounting for the content author’s reputation when determining whether to hide a flagged contribution, the model needed to calculate and consider the history of previously hidden items (
AbusiveContentkarma). All previously hidden questions or answers had a negative effect on all contributor karmas.
Mechanism and diagram
In the third iteration of the model, the designers created
several new reputation scores for questions and answers and a new
user role with a karma—that of author of the
flagged content. Those additions more than doubled the complexity
compared to the previous iteration, as illustrated in Figure 10-7. But if you consider each iteration as a
separate reputation model (which is logical because each addition
stands alone), each one is simple. By integrating separable small
models, the combination made up a full-blown reputation system. For
example, the karmas introduced by the new
models—QuestionAuthor karma, AnswerAuthor
karma, and AbusiveContent karma—could find uses in
contexts other than hiding abusive content.
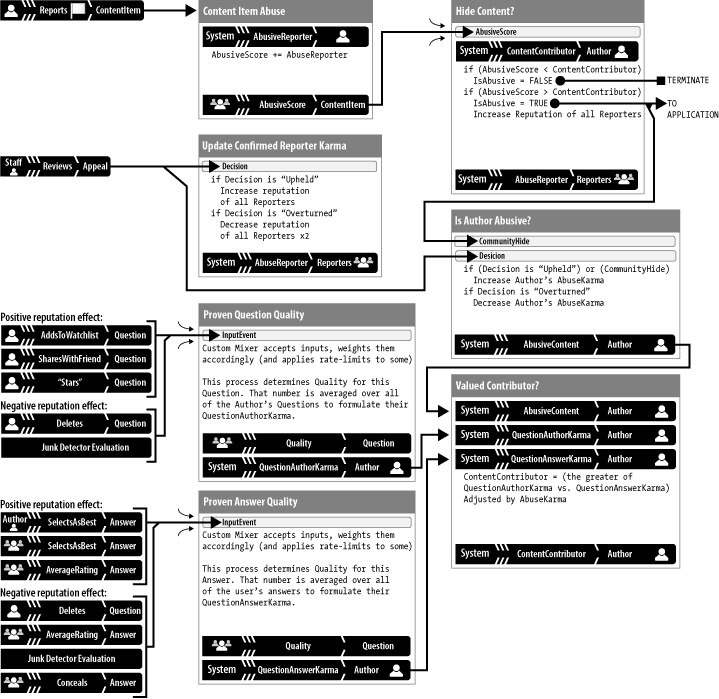
In this iteration the designers added two new main karma tracks, represented by the parallel messaging tracks for question karma and answer karma. The calculations are so similar that we present the description only once, using item to represent either answer or question.
The system gave each item a quality reputation
[QuestionQuality | AnswerQuality], which started as the
average of the quality reputations of the previously contributed
items [AuthorAverageQuestionQuality |
AuthorAverageAnswerQuality] and a bit of the Junk Detector
score. As either positive (stars, ratings, shares) or negative
inputs (items hidden by customer care staff) changed, the scores,
the averages, and karmas in turn were immediately affected. Each
positive input was restricted by weights and limits; for example,
only the first 10 users marking an item as a favorite were
considered, and each could contribute a maximum of 0.5 to the final
quality score. This meant that increasing the item quality
reputation required many different types of positive inputs.
Once the system had assigned a new quality score to an item
and then calculated and stored the item’s overall average quality
score, it sent the process a message with the average score to
calculate the individual item’s quality karma [QuestionAuthor
| AnswerAuthor], subtracting the user’s overall
AbusiveContent karma to generate the final
result.
The system then combined the QuestionAuthor and
AnswerAuthor karmas into ContentAuthor karma, using the best (the
larger) of the two values. That approach reflected the insight of
Yahoo! Answers staff that people who ask good questions are not the
same as people who give good answers.
The designers once again changed the Hide Content? process,
now comparing AbusiveScore to the
new ContentContributor karma to determine whether the
content should be hidden. When an item was hidden, that information
was sent as an input into a new process that updated the
AbusiveContent karma.
The new process for updating AbusiveContent karma
also incorporated the inputs from customer care staff that were
included in iteration 2—appeal results and content removals—which affected the karma
either positively or negatively, as appropriate. Whenever an input
entered that process, the system sent a message with the updated
score to each of the processes for updating question and answer
karma.
Analysis
By adding positive and negative karma scores for authors and effectively requiring a second or third opinion before hiding their content, the designers added protection for established, trusted authors. It also shortened the amount of time that bad content from historically abusive users would appear on the site by allowing single-strike hiding by only lightly experienced abuse reporters. The team was very close to finished.
But it still had a cold-start problem. How could the model protect authors who weren’t abusive but didn’t have a strong history of posting contributions or reporting abuse? They were still too vulnerable to flagging by other users—especially inexperienced or malicious reporters.
The team needed as much outside information as it could get its hands on to provide some protection to new users who deserved it and to expose malicious users from the start.
Final design: Adding inferred karma
The team could have stopped here, but it wanted the system to be as effective as possible as soon as it was deployed. Even before abuse reporters can build up a history of accurately reporting abuse, the team wanted to give the best users a leg up over trolls and spammers, who almost always create accounts solely for the purpose of manipulating content for profit or malice.
In other words, the team wanted to magnify any reasons for trusting or being suspicious of a user from the very beginning, before the user started to develop a history with the reputation system.
To that end, the designers added a model of inferred karma (see Generating inferred karma).
Fortunately, Yahoo! Answers had access to a wealth of data—inferred karma inputs—about users from other contexts.
Inputs
Many of the inferred inputs came from Yahoo! site security features. To maintain that security, some of the inputs have been omitted, and the descriptions of others have been altered to protect proprietary features.
- IP is suspect
More objects are accessible to web applications at the system level. One available object is the IP address for the user’s current connection. Yahoo!, like many large sites, keeps a list of addresses that it doesn’t trust for various reasons. Obviously, any user connected through one of those addresses is suspect.
- Browser cookie is suspect
Yahoo! maintains security information in browser cookies. Cookies may raise suspicion for several reasons—for example, when the same cookie is reused by multiple IP addresses in different ranges in a short period of time.
- Browser cookie age
A new browser cookie reveals nothing, but a valid, long-lived cookie that isn’t suspect may slightly boost trust of a user.
- Junk detector score (for rejected content)
In the final iteration of the model, the model captures the history of Junk Detector scores that caused an item to be automatically hidden as soon as a user posted it. In earlier iterations, only questions and answers that passed the detector were included in reputation calculations.
- Negative evaluations by others
The final iteration of the model included several different evaluations of a user’s content in calculations of inferred karma: poor ratings, abuse reports, and the number of times a user was blocked by others.
- Best-answer percentage
On the positive side, the model included inputs such as the average number of best answers that a user submitted (subject to liquidity limits). See Liquidity: You Won’t Get Enough Input.
- User points level
The level of a user’s participation in Yahoo! provided a significant indicator of the user’s investment in the community. Yahoo! Answers already displayed user participation on the site—a public karma for every user.
- User longevity
Absent any previous participation in Yahoo!, a user’s Yahoo! account registration date provided a minimum indicator of community investment, along with the date of a user’s first interaction with Yahoo! Answers.
- Customer care action
Finally, certain events were a sure sign of abusive behavior. When customer care staff removed content or suspended accounts, those events were tracked as strongly negative inputs to bootstrap karma.
- Appeal results upheld
Whenever an appeal to hide content was upheld, that event was tracked as an additional indicator of possible abuse.
Mechanism and diagram
In the final iteration of the model, shown in Figure 10-8, the designers implemented this simple
idea: until the user had a detailed history in the reputation model,
use a TrustBootstrap reputation as reasonably
trustworthy placeholder. As the number of a user’s abuse reports
increased, the share of TrustBootstrap used in
calculating the user’s reporter and author karmas was decreased.
Over time, the user’s bootstrap reputation faded in significance
until it became computationally irrelevant.
The scores for AbusiveContent karma and
AbuseReporter karma now took the various inferred karma
inputs into account.
AbusiveContent karma was calculated by mixing
what we knew about a user’s karma reporting history
(ConfirmedRerporterKarma) with what could be inferred
about the user’s behavior from other inputs
(TrustBootstrap).
TrustBootstrap was itself made up of three other
new reputations: SuspectedAbuser karma, which reflected
any evidence of abusive behavior; CommunityInvestment
karma, which represented the user’s contributions to Yahoo! Answers
and other communities; and AbusiveContent karma, which
held an author’s record of submitting abusive content.
There were risks in getting the constants wrong—too much power too early could lead to abuse. Depending on the bootstrap too long could lead to distrust when reporters don’t see the effects of their reputation quickly enough.
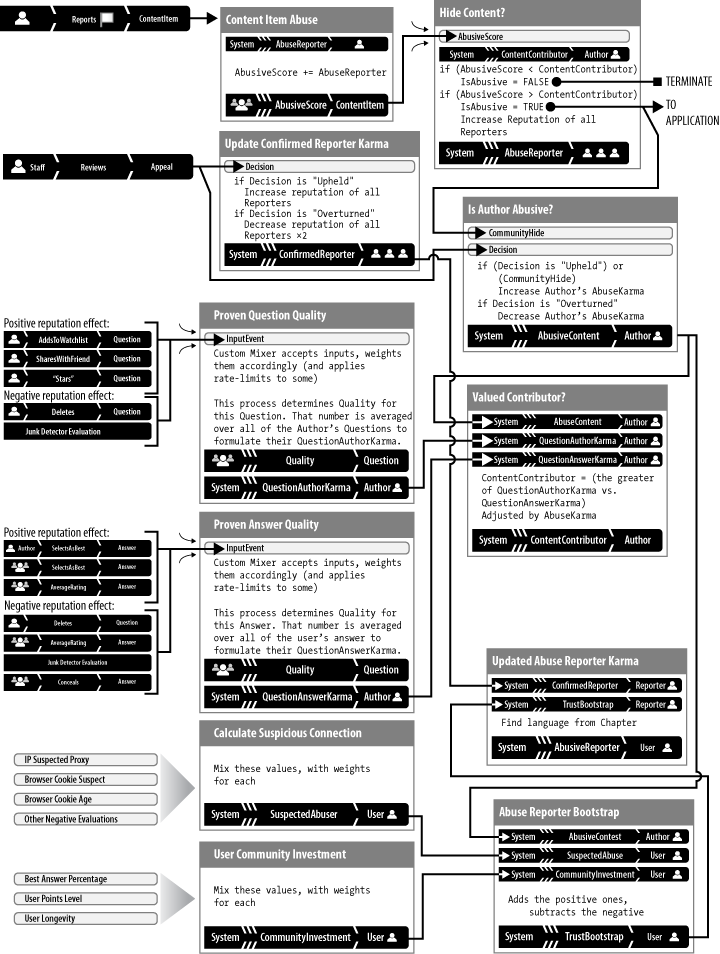
- Process: Calculate Suspicious Connection
When a user takes an action of value, such as asking a question, giving an answer, or evaluating content on the site, the application stores the user’s connection information. If the user’s IP address or browser cookie differed from the one used in a previous session, the application activates this process by sending it the IP and/or browser cookie related inputs. The system updated the
SuspectedAbuserkarma using those values and the history of previous values for the user. Then it sent the value in a message to the Abuse Reporter Bootstrap process.- Process: Calculate User Community Investment
Three different application events triggered this process:
A change (usually upward) in the user’s points
Selection of a best answer to a question—whether or not the user wrote the answer that was selected
The first time the user flags any item as abusive content
This process generated
CommunityInvestmentkarma by accounting for the longevity of the user’s participation in Yahoo! Answers and the age of the user’s Yahoo! account, along with a simple participation value calculation (the user’s level) and an approximation of answer quality—the best answer percentage. Each time this value was changed, the system sent the new value to the Abuse Reporter Bootstrap process.- Process: Is Author Abusive?
The inputs and calculations for this process were the same as in the third iteration of the model—the process remained a repository for all confirmed and nonappealed user content violations. The only difference was that every time the system executed the process and updated
AbusiveContentkarma, it now sent an additional message to the Abuse Reporter Bootstrap process.- Process: Abuse Reporter Bootstrap
This process was the centerpiece of the final iteration of the model. The
TrustBootstrapreputation represented the system’s best guess at the reputation of users without a long history of transactions with the service. It was a weighted mixer process, taking positive input fromCommunityInvestmentkarma and weighing that against two negative scores: the weaker score was the connection-basedSuspectedAbuserkarma, and the stronger score was the user history–basedAbusiveContentkarma. Even though a high value for theTrustBootstrapreputation implied a high level of certainty that a user would violate the rules,AbusiveContentkarma made up only a share of the bootstrap and not all of it. The reason was that the context for the score was content quality, and the context of the bootstrap was reporter reliability; someone who is great at evaluating content might suck at creating it. Each time the bootstrap process was updated, it was passed along to the final process in the model: Update Abuse Reporter Karma.- Process: Valued Contributor?
The input and calculations for this process were the same as in the second iteration of the model—the process updated
ConfirmedRerporterkarma to reflect the accuracy of the user’s abuse reports. The only difference was that the system now sent a message for each reporter to the Update Abuse Reporter Karma process, where the claim value was incorporated into the bootstrap reputation.- Process: Update Abuse Reporter Karma
This process calculated
AbuseReporterkarma, which was used to weight the value of a user’s abuse reports. To determine the value, it combinedTrustBootstrapinferred karma with a verified abuse report accuracy rate as represented byConfirmedRerporter. As a user reported more items, the share ofTrustBootstrapin the calculation decreased. Eventually,AbuseReporterkarma became equal toConfirmedRerporterkarma. Once the calculations were complete, the reputation statement was updated and the model was terminated.
Analysis
With the final iteration, the designers had incorporated all the desired features, giving historically trusted users the power to hide spam and troll-generated content almost instantly while preventing abusive users from hiding content posted by legitimate users. This model was projected to reduce the load on customer care by at least 90% and maybe even as much as 99%. There was little doubt that the worst content would be removed from the site significantly faster than the typical 12+ hour response time. How much faster was difficult to estimate.
In a system with over a dozen processes, more than 20 unproven formulas, and about 50 best-guess constant values, a lot could go wrong. But iteration provided a roadmap for implementation and testing. The team started with one model, developed test data and testing suites for it, made sure it worked as planned, and then built outward from there—one iteration at a time.
Displaying Reputation
The Yahoo! Answers example provides clear answers to many of the questions raised in Chapter 7, where we discussed the visible display of reputation.
Who Will See the Reputation?
All interested parties (content authors, abuse reporters, and other users) certainly could see the effects of the reputations generated by the system at work: content was hidden or reappeared, and appeals and their results generated email notifications. But the designers made no attempt to roll up the reputations and display them back to the community. The reputations definitely were not public reputations.
In fact, even showing the reputations only to the interested parties as personal reputations likely would only have given actual those intending harm more information about how to assault the system. These reputations were best reserved for use as corporate reputations only.
How Will the Reputation Be Used to Modify Your Site’s Output?
The Yahoo! Answers system used the reputation information that it gathered for one purpose only: to make a decision about whether to hide or show content. Some of the other purposes discussed in How Will You Use Reputation to Modify Your Site’s Output? do not apply to this example. Yahoo! Answers already used other, application-specific methods for ordering and promoting content, and the community content moderation system was not intended to interfere with those aspects of the application.
Is This Reputation for a Content Item or a Person?
This question has a simple answer, with a somewhat more complicated clarification. As we mentioned earlier in Limiting Scope, the ultimate target for reputations in this system is content: questions and answers.
It just so happened that in targeting those objects, the model resulted in generation of a number of proven and assumed reputations that pertained to people: the authors of the content in question, and the reporters who flagged it. But judging the character the users of Yahoo! Answers was not the purpose of the moderation system, and the data on those users should never be extended in that way without careful deliberation and design.
Using Reputation: The…Ugly
In Chapter 8, we detailed three main uses for reputation (other than displaying scores directly to users). We only half-jokingly referred to them as the good, the bad, and the ugly. Since the Yahoo! Answers community content moderation model says nothing about the quality of the content itself—only about the users who generate and interact with it—it can’t really rank content from best to worst. These first two use categories—the good and the bad—don’t apply to this moderation model.
The Yahoo! Answers system dealt exclusively with the last category—the ugly—by allowing users to rid the site of content that violated the terms of service or the community guidelines.
The primary result of this system was to hide content as rapidly as possible so that customer support staff could focus on the exceptions (borderline cases and bad calls). After all, at the start of the project, even customer care staff had an error rate as high as 10%.
This single use of the model, if effective, would save the company over $1 million in customer care costs per year. That savings alone made the investment profitable in the first few months after deployment, so any additional uses for the other reputations in the model would be an added bonus.
For example, when a user was confirmed as a content abuser, with a
high value for AbusiveContent karma, Yahoo! Answers could
share that information with the Yahoo! systems that maintained the
trustworthiness of IP addresses and browser cookies, raising the
SuspectedAbuser karma score for that user’s IP address and
browser. That exchange of data made it harder for a spammer or a troll to
create a new account. Users who are technically sophisticated can
circumvent such measures, but the measures have been very effective
against those who aren’t—and who make up the vast majority of Yahoo!
users.
When customer care agents reviewed appeals, the system displayed
ConfirmedReporter karma for each abuse reporter, which acted
as a set of confidence values. An agent could see that several reports
from low-karma users were less reliable than one or two reports from abuse
reporters with higher karma scores. A large enough army of sock puppets,
with no reputation to lose, could still get a nonabusive item hidden, even
if only briefly.
Application Integration, Testing, and Tuning
The approach to rolling out a new reputation-enabled application detailed in Chapter 9 is derived from the one used to deploy all reputation systems at Yahoo!, including the community content moderation system. No matter how many times reputation models had been successfully integrated into applications, the product teams were always nervous about the possible effects of such sweeping changes on their communities, product, and ultimately the bottom line. Given the size of the Yahoo! Answers community, and earlier interactions with community members, the team was even more cautious than most others at Yahoo!. Whereas we’ve previously warned about the danger of over-compressing the integration, testing, and tuning stages to meet a tight deadline, the product team didn’t have that problem. Quite the reverse—they spent more time in testing than was required, which created some challenges with interpreting reputation testing results, and which we will cover in detail.
Application Integration
The full model as shown in Figure 10-8 has dozens of possible inputs, and many different programmers managed the different sections of the application. The designers had to perform a comprehensive review of all of the pages to determine where the new “Report Abuse” buttons should appear. More important, the application had to account for a new internal database status—“hidden”—for every question and answer on every page that displayed content. Hiding an item had important side effects on the application: it had to adjust total counts and revoke points granted, and a policy had to be devised and followed on handling any answers (and associated points) attached to any hidden questions.
Integrating the new model required entirely new flows on the site for reporting abuse and handling appeals. The appeals part of the model required that the application send email to users, functionality previously reserved for opt-in watch lists and marketing-related mailings—appeals mailings were neither. Last, the customer care management application would need to be altered.
Application integration was a very large task that would have to take place in parallel with the testing of the reputation model. Reputation inputs and outputs would need to be completed or at least simulated early on. Some project tasks didn’t generate reputation input and therefore didn’t conflict with testing—for example, functions in the new abuse reporting flows such as informing users about how a new system worked and screens confirming receipt of an abuse report.
Testing Is Harder Than You Think
Just as the design was iterative, so too were the implementation and testing. In Testing Your System, we suggested building and testing a model in pieces. The Yahoo! Answers team did just that, using constant values for the missing processes and inputs. The most important thing to get working was the basic input flow: when a user clicked Report Abuse, that action was tested against a threshold (initially a constant), and when it was exceeded, the reputation system sent a message back to the application to hide the item—effectively removing it from the site.
Once the basic input flow had been stabilized, the engineers added other features and connected additional inputs.
The engineers bench tested the model by inserting a logical test probe into the existing abuse reporting flow and using those reports to feed the reputation system, which they ran in parallel. The system wouldn’t take any action that users would see just yet, but the model would be put through its paces as each change was made to the application.
But the iterative bench-testing approach had a weakness that the team didn’t understand clearly until much later: the output of the reputation process—the hiding of content posted by other users—had a huge and critical influence on the effectiveness of the model. The rapid disappearance of content items changed the site completely, so real-time abuse reporting data from the current application turned out to be nearly useless for drawing conclusions about the behavior of the model.
In the existing application, several users would click on an abusive question in the first few minutes after it appeared on the home page. But once the reputation system was working, few, if any, users would ever even see the item before it was hidden. The shape of inputs to the system was radically altered by the system’s very operation.
Tip
Whenever a reputation system is designed to change user behavior significantly, any simulated input should be based on the assumption that the model accomplishes its goal; in other words, the team should use simulated input, not input from the existing application (in the Yahoo! Answers case, the live event stream from the prereputation version of the application).
The best testing it was possible to perform before the actual integration of the reputation model was stress testing the messaging channels and update rates, and testing using handmade simulated input that approximated the team’s best guess at possible scenarios, legitimate and abusive.
Lessons in Tuning: Users Protecting Their Power
Still unaware that the source of abuse reports was inappropriate, the team inferred from early calculations that the reputation system would be significantly faster and at least as accurate as customer care staff had been to date. It became clear that the nature of the application precluded any significant tuning before release—so release required a significant leap of faith. The code was solid, the performance was good, and the web side of the application was finally ready—but the keys to the kingdom were about to be turned over to the users.
The model was turned on provisionally, but every single abuse report was still sent on to customer care staff to be reviewed, just in case.
I couldn’t sleep the first few nights. I was so afraid that I would come in the next morning to find all of the questions and answers gone, hidden by rogue users! It was like giving the readers of the New York Times the power to delete news stories.
—Ori Zaltzman, Yahoo! community content moderation architect
Ori watched the numbers closely and made numerous adjustments to the various weights in the model. Inputs were added, revised, even eliminated.
For example, the model registered the act of “starring” (marking an item as a favorite) as a positive indicator of content quality. Seems natural, no? It turned out that a high correlation existed between an item being “starred” by a user and that same item eventually being hidden. Digging further, Ori found that many reporters of hidden items also “starred” an item soon before or after reporting it as abuse! Reporters were using the favorites feature to track when an item that they reported was hidden, and consequently they were abusing the favorites feature. As a result, “starring” was removed from the model.
At this time, the folly of evaluating the effectiveness of the model during the testing phase became clear. The results were striking and obvious. Users were much more effective than customer care staff at identifying inappropriate content; not only were they faster, they were more accurate! Having customer care double-check every report was actually decreasing the accuracy rate because they were introducing error by reversing user reports inappropriately.
Users definitely were hiding the worst of the worst content. All the content that violated the terms of service was getting hidden (along with quite a bit of the backlog of older items). But not all the content that violated the community guidelines was getting reported. It seemed that users weren’t reporting items that might be considered borderline violations or disputable. For example, answers with no content related to the question, such as chatty messages or jokes, were not being reported. No matter how Ori tweaked the model, that didn’t change.
In hindsight, the situation is easy to understand. The reputation model penalized disputes (in the form of appeals): if a user hid an item but the decision was overturned on appeal, the user would lose more reputation than he’d gained by hiding the item. That was the correct design, but it had the side effect of nurturing risk avoidance in abuse reporters. Another lesson in the difference between the bad (low-quality content) and the ugly (content that violates the rules)—they each require different tools to mitigate.
Deployment and Results
The final phase of testing and tuning of the Yahoo! Answers community content moderation system was itself a partial deployment—all abuse reports were temporarily verified post-reputation by customer care agents. Full deployment consisted mostly of shutting off the customer care verification feed and completing the few missing pieces of the appeals system. This was all completed within a few weeks of the initial beta-test release.
While the beta-test results were positive, in full deployment the system exceeded all expectations.
Note that we’ve omitted the technical performance metrics in Table 10-1. Without meeting those requirements, the system would never have left the testing phase.
| Metric | Baseline | Goal | Result | Improvement |
Average time before reported content is removed | 18 hours | 1 hour | 30 seconds | 120 times the goal >2000 times the baseline |
Abuse report evaluation error rate | 10% | 10% | <0.1% (appeal result: overturned) | 100× the goal or baseline |
| Customer care costs | 100% $1 million per year | 10% $100,000 per year | <0.1% <$10,000 per year | 10 times the goal 100 times the baseline Saved >$990,000 per year |
Every goal was shattered, and over time the results improved even further. As Yahoo! Answers product designer Micah Alpern put it: “Things got better because things were getting better!”
That phenomenon was perhaps best illustrated by another unexpected result about a month after the full system was deployed: both the number of abuse reports and requests for appeal dropped drastically over a few weeks. At first the team wondered if something was broken—but it didn’t appear so, since a recent quality audit of the service showed that overall quality was still on the rise. User abuse reports resulted in hiding hundreds of items each day, but the total appeals dropped to a single-digit number, usually just 1 or 2, per day. What had happened?
The trolls and many spammers had left. They had simply given up and moved on.
The broken windows theory (see the sidebar Broken Windows and Online Behavior) clearly applied in this context—trolls found that the questions and answers they placed on the service were removed by vigilant reporters faster than they could create the content. Just as graffiti artists in New York stopped vandalizing trains because no one saw their handiwork, the Yahoo! Answers trolls either reformed or moved on to some other social media neighborhood to find their jollies.
Another important characteristic of the design was that, except for a small amount of localized text, the model was not language-dependent. The product team was able to deploy the moderation system to dozens of countries in only a few months, with similar results.
Reputation models fundamentally change the applications into which they’re integrated. You might think of them as coevolving with the needs and community of your site. They may drive some users away. Often, that is exactly what you want.
Operational and Community Adjustments
This system required major adjustments to the Yahoo! Answers operational model, including the following:
The customer care workload for reviewing Yahoo! Answers abuse reports decreased by 99%, resulting in significant staff resource reallocations to other Yahoo! products and some staff reductions. The workload dropped so low that Yahoo! Answers no longer required even a single full-time employee for customer care. (Good thing the customer care tool measured productivity in terms of events processed, not person-days.)
The team changed the customer care tool to provide access to reputation scores for all of the users and items involved in an appeal. The tool can unhide content, and it always sends a message to the reputation model when the agent determines the appeal result. The reputation system was so effective at finding and hiding abusive content that agents had to go through a special training program to learn how to handle appeals, because the items in the Yahoo! Answers customer care event queues were qualitatively so different from those in other Yahoo! services. They were much more likely to be borderline cases requiring a subtle understanding of the terms of service and community guidelines.
Before the reputation system was introduced, the report abuse rate had been used as a crude approximation of the quality of content on the site. With the reputation system in place and the worst of the worst not a factor, that rate was no longer a very strong indicator of quality, and the team had to devise other metrics.
There was little doubt that driving spammers and trolls from the site had a significantly positive effect on the community at large. Again, abuse reporters became very protective of their reputations so that they could instantly take down abusive content. But it took users some time to understand the new model and adapt their behavior. The following are a few best practices for facilitating the transformation from a company-moderated site to full user moderation:
Explain what abuse means in your application.
In the case of Yahoo! Answers, content must obey two different sets of rules: the Terms of Service and the Community Guidelines. Clearly describing each category and teaching the community what is (and isn’t) reportable is critical to getting users to succeed as reporters as well as content creators (see Figure 10-9).
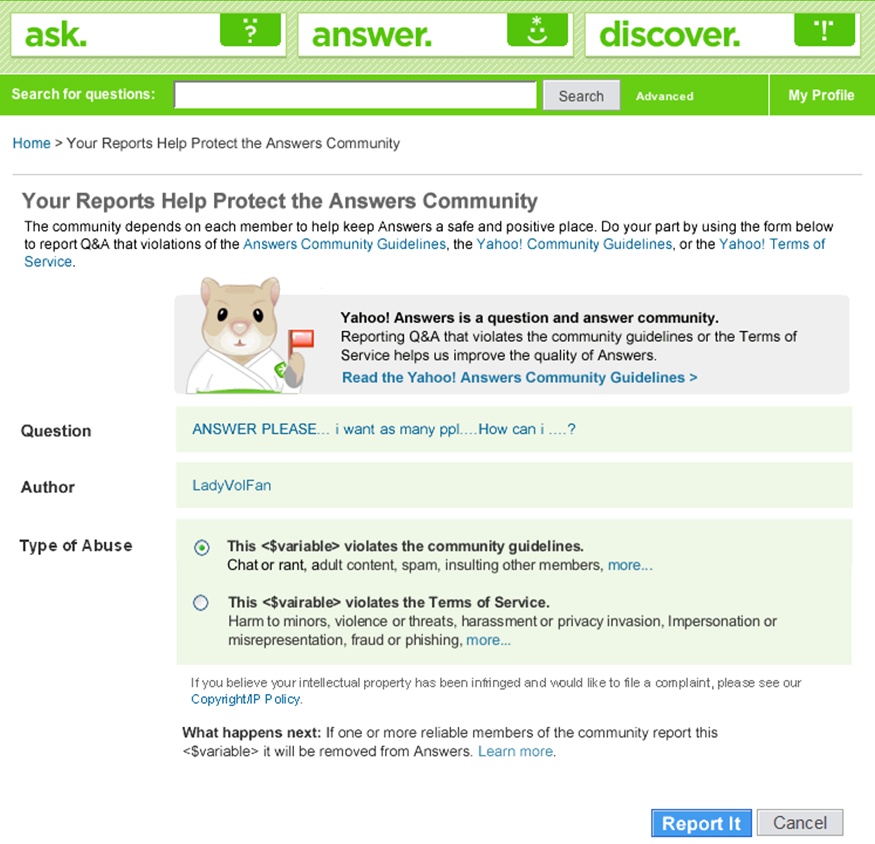
Explain the reputation effects of an abuse report.
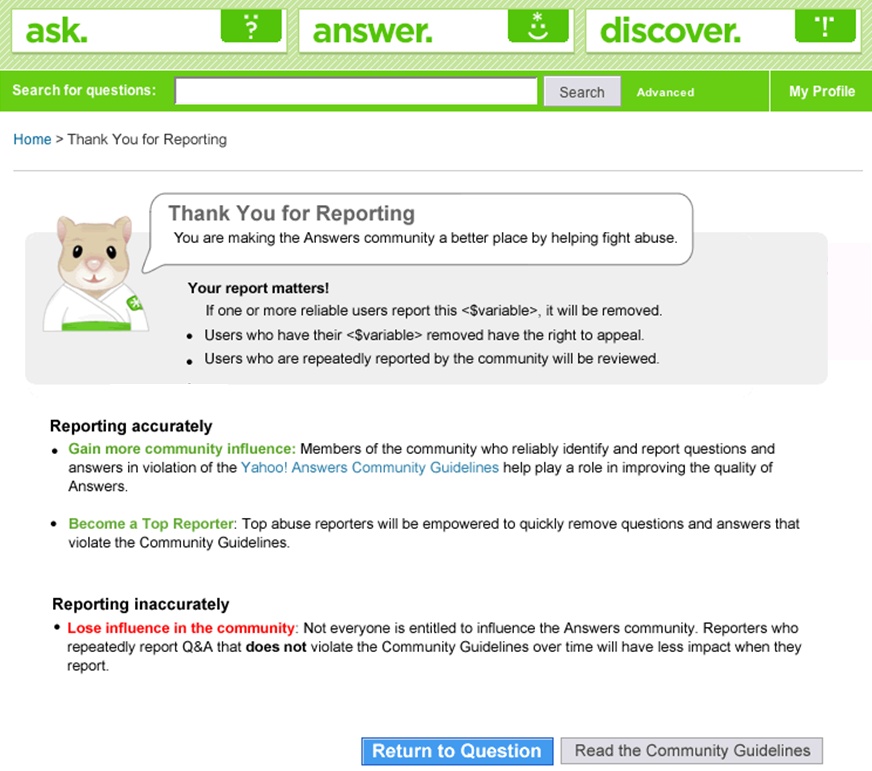
Abuse reporter reputation was not displayed. Reporters didn’t even know their own reputation score. But active users knew the effects of having a good abuse reporter reputation—most content that they reported was hidden instantly. What they didn’t understand was what specific actions would increase or decrease it. As shown in Figure 10-10, the Yahoo! Answers site clearly explained that the site rewarded accuracy of reports, not volume. That was an important distinction because Yahoo! Answers points (and levels) were based mostly on participation karma—where doing more things gets you more karma. Active users understood that relationship. The new abuse reporter karma didn’t work that way. In fact, reporting abuse was one of the few actions the user could take on the site that didn’t generate Yahoo! Answers points.
Adieu
We’ve arrived at the end of the Yahoo! Answers tale and the end of Building Web Reputation Systems. With this case study and with this book we’ve tried to paint as complete and real-world a picture as possible of the process of designing, architecting, and implementing a reputation system.
We covered the real and practical questions that you’re likely to face as you add reputation-enhanced decision making to your own product. We showed you a graphical grammar for representing entities and reputation processes in your own models. Our hope is that you now have a whole new way to think about reputation on the Web.
We encourage you to continue the conversation with us at this book’s companion website.